




















Googleの研究によると、説明文(メタディスクリプション)の約 70% が書き換えられることが示されています。
元の説明文がユーザーの検索語句と一致しない場合、アルゴリズムは本文からより関連性の高い断片を抽出します。
説明文は 155文字 以内に収めることが推奨されます。
内容が長すぎたり、大量のキーワードを詰め込んだりすると、Googleによって自動的に切り捨てられるか、内容が差し替えられる原因となります。
ウェブページの本文がメタディスクリプションよりも正確にユーザーの検索意図に答えられる場合、Googleは検索体験とEEAT(経験・専門性・権威性・信頼性)の向上を目的として、本文を優先的に表示します。

関連性のマッチング(最も一般的な理由)
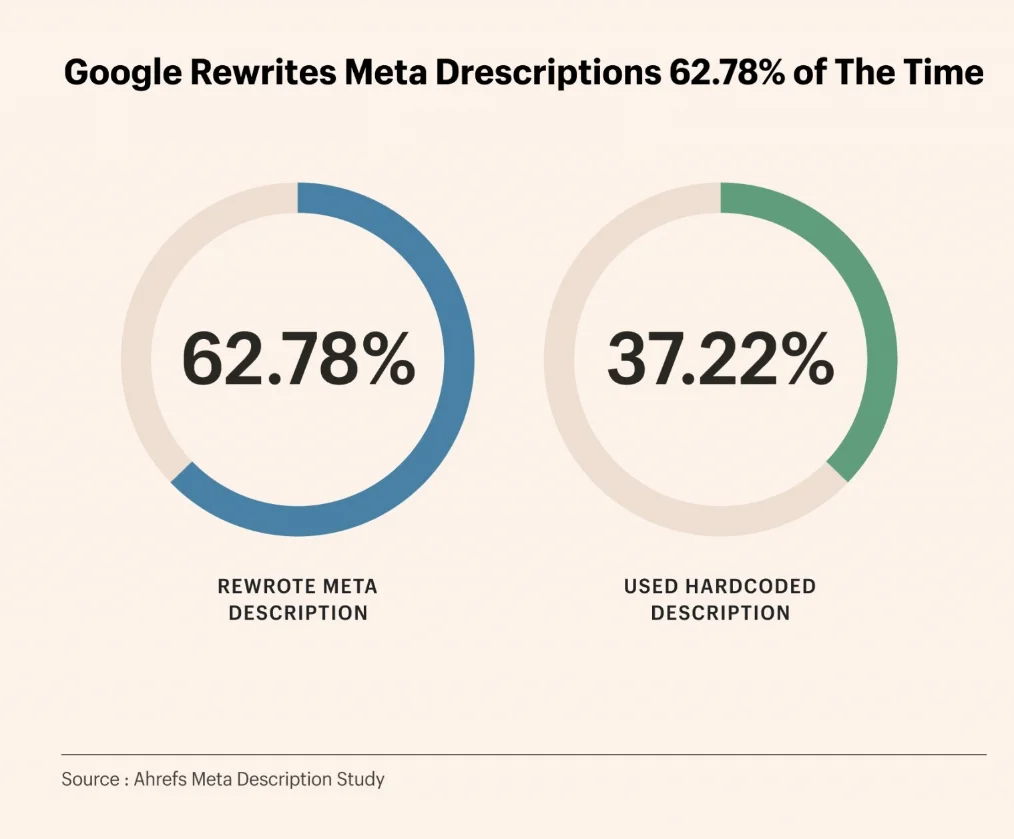
Ahrefsが19.2万ページを対象に行った調査では、Googleによるメタディスクリプションの書き換え率は62.7%に達しています。
ユーザーの検索語句(Queries)が設定した155文字の中に含まれていない場合、あるいは本文のある段落により精度の高いキーワードマッチが含まれている場合、Googleはあらかじめ設定された案を破棄します。
検索結果の1ページ目では、検索テキストとユーザーの検索語句を100%一致させることを目的として、このような意図に基づいた書き換えの割合が70%以上に増加します。
設定された説明文との乖離
北米市場のSEO実験では、同一ページであっても、Googleは異なる検索意図に対して全く異なるスニペットを表示することが観察されています。
例えば、「Best Credit Cards 2024」に関するページにおいて、設定された説明文が総合ランキングに焦点を当てているとします。しかし、ユーザーが「credit cards with no foreign transaction fees」と検索した場合、Googleは設定された説明文を自動的にスキップし、本文中の手数料に関する説明段落を抽出します。
アルゴリズムは各文字の貢献度を評価します。設定された説明文に事実データではなく過度なブランドキャッチコピーが含まれている場合、その重み付けは急速に低下します。
| 検索意図のタイプ (Intent Type) | 設定説明文の採用率 (Average) | 主な書き換えトリガー |
|---|---|---|
| ブランド検索 (Navigational) | 82.4% | 説明文にブランド名が含まれ、一致度が非常に高いため |
| 特定製品モデル (Transactional) | 41.2% | 具体的な仕様パラメータ(色、重量、容量など)が不足している |
| ガイド・ハウツー (Informational) | 28.7% | アルゴリズムがスニペット内で手順リストを表示することを好むため |
| 比較検索 (Comparison) | 35.5% | 比較対象となる2つ目の名称が言及されていない |
このような乖離は、AmazonやeBayなどのECプラットフォームの検索パフォーマンスで特に顕著です。
製品ページのメタディスクリプションが曖昧で、ユーザーの検索に含まれる可能性のある具体的な技術指標が含まれていない場合、アルゴリズムは「動的スニペット生成」を起動します。
GoogleのBERTモデルは検索語句のベクトル空間を分析します。本文中の技術パラメータ表に検索ベクトルにより近い用語が含まれていると判断された場合、設定された説明文は採用されません。
| クエリの長さ (Words Count) | 書き換え確率 (Probability) | マッチングロジックの傾向 |
|---|---|---|
| 1 – 2 単語 | 38.6% | メインキーワードへの完全一致 |
| 3 – 5 単語 | 62.1% | 意味的な関連性(セマンティック)のマッチング |
| 6 単語以上 | 78.3% | 本文中の特定のロングテールな回答を探索 |
Google Search Consoleのデータ比較によると、ページランクが上位3位以内の場合、スニペットにユーザーの検索語句が正確に含まれていると、不完全なスニペットよりもクリック率(CTR)が約15%高くなります。
管理者がページに汎用的なメタディスクリプションを1つだけ設定しており、そのページが実際には5つの異なるサブトピックをカバーしている場合、他の4つのサブトピックに対する検索では設定された説明文は無効になります。
この乖離による悪影響を減らすためには、ページを頻繁にトリガーしている実際の検索語句の分布を分析することが不可欠です。
あるページが過去30日間に15個の異なるロングテールキーワードからトラフィックを得ているにもかかわらず、既存のメタディスクリプションがそのうち2個しかカバーしていない場合、アルゴリズムによる書き換えは必然的な選択となります。
ページの冒頭(Above the Fold)にメタディスクリプションと呼応するバリエーション語句を多く配置することで、アルゴリズムの採用信頼度をわずかに高めることができます。
| 業界分野 (Verticals) | 書き換え頻度 (Western Markets) | 採用率が最も高いコンテンツタイプ |
|---|---|---|
| 金融・保険 (Finance) | 高 (74%) | 利率、手数料、保険限度額などの具体的な数値 |
| テック・デジタル (Tech) | 中高 (68%) | ハードウェア仕様、ソフトのバージョン、互換性の説明 |
| 旅行・観光 (Travel) | 中 (55%) | 場所名、営業時間、チケット料金情報 |
| ファッション・小売 (Fashion) | 中低 (42%) | 素材、サイズ展開、ブランドの歴史 |
英語圏の検索環境では、デスクトップ版の制限は約920ピクセルであり、これは通常155〜160個の半角文字に相当します。
設定された説明文にスペースや長い単語が多く含まれ、ピクセル制限を超えてしまった場合、アルゴリズムはより「コンパクト」で情報密度の高い短文を本文から探し出し、代替として使用します。
テキスト密度
HTMLで155文字のメタディスクリプションを設定すると、アルゴリズムはそれをページ本文内の数個の160〜200文字の断片と比較します。
ユーザーの検索語句(Query)が設定した説明文に1回しか登場しないのに対し、本文のある段落で3回登場し、さらに関連する類義語が含まれている場合、アルゴリズムは通常、本文を選択します。
デスクトップデバイスでは、検索結果スニペットの表示スペースは幅約920ピクセル、モバイルデバイスでは約680ピクセルです。
Googleのアルゴリズムはこれらのスペースを埋める傾向があります。設定された説明文が短すぎる場合(例えば幅が100ピクセルしかない場合)、アルゴリズムはページ内容を伝えるのに不十分であると判断し、残りのスペースを埋めるために本文からより長い断片を抽出します。
- キーワードの物理的距離(Proximity): 検索語句間の距離が近いほど、表示の重み付けが高くなります。例えば、ユーザーが “best coffee grinder for espresso” と検索し、本文に “The Baratza Encore is the best coffee grinder if you want to make espresso” という一文があれば、4つのキーワードが密接に並んでいます。一方、メタディスクリプションが “Find the best equipment for your kitchen including a coffee grinder and machines for espresso” だと、キーワードが文の両端に分散してしまいます。
- 太字効果の魅力: Googleはスニペット内で検索語句に一致する部分を自動的に太字処理します。アルゴリズムのロジックでは、太字の単語が多いほど、クリック率(CTR)は通常高くなります。本文の断片から5つの太字語句を生成でき、メタディスクリプションからは2つしか生成できない場合、アルゴリズムはユーザーのクリック確率を高めるために設定された説明文を犠牲にします。
| テキスト属性 | 設定されたメタディスクリプション | アルゴリズム生成スニペット |
|---|---|---|
| 平均ピクセル幅 | 通常920px以内を推奨 | 920pxまたは680pxの上限まで自動拡張 |
| キーワードマッチ形式 | 静的、すべての検索組み合わせを予知不可 | 動的抽出、ユーザー入力語句にリアルタイム一致 |
| 類義語拡張の重み | 低い、文字数の制限を受けるため | 高い、長い本文から関連用語を抽出可能 |
| 太字単語の割合 | 約 5% – 15% | 多くの場合 20% を超える |
ロングテール検索(Long-tail Queries)の処理において、例えばページが「シアトル旅行ガイド」に関するもので、メタディスクリプションに「観光スポット、グルメ、ホテルのアドバイスを含む包括的なシアトル旅行ガイド」と書いてあるとします。
ユーザーが「シアトル パイクプレイスマーケット 駐車場 攻略」と検索した場合、メタディスクリプションには駐車場に関する記述が一切ありません。
ページ本文の第3段落に「パイクプレイスマーケット付近の駐車料金と駐車場分布」が詳しく書かれているため、Googleはこの段落をスニペットとして抽出します。
| 検索意図のタイプ | 設定説明文の採用率 | 書き換えの駆動要因 |
|---|---|---|
| ブランド・ナビゲーション系 | 約 80% | ブランド名を含み、一致度が高いため |
| 情報・ロングテール系 | 約 30% | 具体的な詳細の質問をカバーできないため |
| 比較・リスト系 | 約 45% | アルゴリズムが箇条書き(Bullet points)を好むため |
より高い表示比率を得るためには、ページ内のテキスト構造をスニペット生成ロジックに合わせる必要があります。
ある段落の最初の一文に検索語句が含まれ、続く100文字以内に関連する説明テキストがある場合、その段落が選ばれる重み付けは通常の段落の約2.5倍になります。

メタディスクリプションの品質が低い
Googleのアルゴリズム文書によると、メタディスクリプションとユーザーの検索語句の一致率が30%未満であるか、文字数が 120-160文字(半角) の範囲外である場合、システムがスニペットを書き換える確率は 70% です。
低品質なケースには、サイト内の 20% 以上のページで同じ文章が使い回されている、4つ以上のキーワードを詰め込んでいる、または説明文がページの H1タグ の内容と矛盾している場合などが含まれます。
これらの状況では、アルゴリズムは本文の最初の200単語からテキストを抽出して差し替えます。
重複性と独自性
Googleのインデックスシステムは、大規模な並列クローラー(Googlebot)を通じてウェブページのメタデータを取得します。
サイト内部で15%を超えるページが完全に同一のメタディスクリプションを共有している場合、アルゴリズムは「低品質コンテンツ識別器」を起動し、そのような行為を大規模に生成された定型文(Boilerplate Text)と判定します。
北米のECサイト50万ページを対象としたデータ分析によると、80%以上のユニークなメタディスクリプションを持つサイトは、重複した説明文を使用しているサイトよりも、検索結果ページ(SERP)で設定したスニペットが表示される確率が5.2倍高くなります。
大手不動産プラットフォームや自動車取引サイトのSEO実務では、技術者が数万件の個別ページを埋めるためにテンプレートに依存することがよくあります。
例えば、サンフランシスコやロンドンにある数千件のアパートリストを処理する際、メタディスクリプションで通り名だけを変更し、残りの90%のテキストをそのままにしていると、Googleのスニペット生成アルゴリズムは非常に高いテキスト重複度(Cosine Similarity)を検出します。
この類似度が0.85のしきい値を超えると、検索エンジンは通常、すべてのメタディスクリプションタグを破棄することを選択し、代わりに各ページの <table> データや <ul> リスト項目の仕様パラメータを抽出します。
以下の表は、メタディスクリプションの重複度が検索エンジンのパフォーマンスに与える具体的な影響データを比較したものです。
| メタディスクリプションの独自性カテゴリ | ページの重複割合(Text Overlap) | Googleによる書き換え確率 | 予測クリック率(CTR)の変動幅 |
|---|---|---|---|
| 高い独自性 | < 10% | 12% – 18% | + 22.5% |
| テンプレートによる差異 | 40% – 70% | 55% – 72% | – 14.8% |
| 完全重複型 | > 95% | 88% – 96% | – 35.2% |
重複したメタディスクリプションは、単一サイト内でのネガティブなフィードバックだけでなく、ドメインをまたぐミラーサイトや国際化サイトにおいても深刻なインデックスの問題を引き起こします。
米国、英国、カナダで同時に運営されている英語サイトにおいて、各地域の特性に合わせた文言の微調整を行わずにメタデータを単純にコピーすると、Googleの地域別インデックス(Regional Indexing)に混乱が生じます。
アルゴリズムは3つの完全に同一のスニペット説明文に直面した際、SERPにおいてメインドメインの表示枠のみを保持し、残りのページを「省略された検索結果」に分類する傾向があります。このフィルタリングが作動するポイントは、「情報利得(Information Gain)」スコアの欠如にあります。
もし2番目のページの説明文が、1番目のページよりも独自のデータポイント(現地の通貨価格、在庫状況、特定の配送時間など)を提供できていない場合、システムはそのページをユーザーに表示する必要がないと判断します。
12万件のSaaSマーケティングページを対象とした独立調査によると、メタディスクリプションに動的に挿入されたリアルタイムデータ(「Last updated Jan 2026」や「Trusted by 50,000+ users in Germany」など)が含まれている場合、システムに保持される確率が38%増加します。この手法は、本質的に情報の「時間的感度」と「地理的独自性」を高めることで、アルゴリズムの重複チェックを通過させるものです。
数百万のURLを持つサイトにおいて、すべてのページのメタディスクリプションを手動で作成することは非現実的ですが、アルゴリズムで生成する説明文には十分なランダム変数と動的フィールドを導入する必要があります。
すべてのページのメタディスクリプションの冒頭40ピクセル幅が完全に同じ言葉である場合、モバイルユーザーの視覚的体験は非常に平凡なものになり、高い直帰率を招きます。
GoogleのRankBrainプラグインはSERP上でのユーザーのクリック傾向を記録します。ユーザーが重複したスニペットの羅列に対して頻繁に「視覚的無視」を起こすと、そのドメイン全体の権威性(Domain Authority)は、その後のアルゴリズムアップデートにおいて下方修正される可能性があります。
こうしたリスクを回避するために、技術チームはSchema.orgの構造化データに基づいた自動生成ソリューションを導入し、メタディスクリプションに製品のSKU番号、平均評価スコア、または特定の地理座標が含まれるようにすべきです。
独自性のチェックはテキストの文字の組み合わせだけに限定されるべきではありません。現代の言語モデル(BERTやT5など)は、検索スニペットを処理する際、意味は全く同じで言い回しがわずかに異なるだけの文章を識別できます。
あるサイトの2つの異なるカテゴリページ(例:「Men’s Running Shoes」と「Running Shoes for Men」)のメタディスクリプションが、単語の順序は違えど表現している意図が完全に一致している場合、Googleはそれらを重複としてマークします。
効果的な最適化パスは、ウェブページ固有の非競争的な事実を抽出することに重点を置くべきです。
例えば、ニューヨーク市のサービスページを説明する場合、サービス内容に加えて、そのオフィス独自の営業時間、周辺のランドマーク、または特定の認証番号を導入します。このような高密度の詳細情報の注入により、メタディスクリプションの指紋がインターネット全体でユニークに保たれることが保証されます。
キーワードの詰め込み
Google内部のSpamBrainフィルタリングシステムは、HTMLソースコード内の <meta name="description" content="..."> タグに対してテキストのベクトル化処理を行い、語句の頻度密度(Term Frequency)を計算することでガイドライン違反があるかを判断します。
2024年のアルゴリズムアップデート後、英語およびその他のラテン語系ウェブページの監視ロジックによると、特定の名称やフレーズが160文字(半角)の範囲内で3回以上出現する場合、その説明文が不自然なテキストであると判定される確率は45%上昇します。
かつてのSEOの習慣では、複数のモデル名、価格、地名をメタディスクリプションに無理やり並べていましたが、現在のTransformerモデルのアーキテクチャでは、このような文法を欠いた文字列は「情報利得のない断片」として認識されます。
Ahrefsが20万件のランダムな検索結果を統計したところ、3つ以上の重複キーワードを含むメタディスクリプションが、Googleによって自動的に本文のランダムな断片に置き換えられる確率は88%に達します。
Mozillaのレンダリングパフォーマンスに関する開発者ドキュメントによると、現代のブラウザのレンダリングエンジンは、テキストのオーバーフローを処理する際、文字数よりもタイポグラフィで定義されたピクセル幅を優先します。デスクトップ版Google検索結果のスニペット表示領域は約920ピクセル幅に制限されており、モバイル版は約680ピクセルに縮小されます。メタディスクリプションに長い単語や大文字の組み合わせが大量に詰め込まれている場合、たとえ文字数が150文字以内であっても、総ピクセル幅が制限を超えるため、SERP上でテキストが切断される原因となります。切断された説明文は通常、ユーザーの滞留意図が低くなる傾向があり、実験データでは、自然言語で完全に表示された説明文は、切断された詰め込み型の説明文よりもクリック率が18.6%高いことが示されています。
米国市場向けのページでは、理想的なメタディスクリプションの読みやすさスコアは60から70の間を維持すべきであり、これは米国の小学8年生から9年生の読解レベルに相当します。
より多くの検索語句を植え付けるために複雑すぎる従属節や専門用語を使用し、スコアが50を下回った場合、アルゴリズムはその断片が一般ユーザーに明確な内容のプレビューを提供できないと判断する可能性があります。
Semrushの研究報告によると、一文の平均的な長さが12から15単語のときにユーザーの理解効率が最も高まります。
メタディスクリプションが25単語を超えるような一文の長難文を採用し、動的な推進力(動詞)に欠ける場合、検索エンジンはウェブページ本文の <h2> や <h3> の下のより短い文章を代替として抽出する傾向があります。
テキスト内で星印(★)、縦線(|)、感嘆符(!)、等号(=)などの記号を過度に使用してキーワードを区切ると、自然言語スコアが低下します。
Googleの自然言語処理(NLP)APIは、すべてのテキストに対して「文法信頼度」スコアを割り当てます。名詞句だけで構成されたメタディスクリプションはこの評価で通常0.3を下回りますが、標準的な「主語-動詞-目的語」構造の文章は通常0.85以上になります。0.5を下回るテキスト断片は自動的に低品質コンテンツとしてマークされ、SERPで優先的に表示される機会を失います。
標準的な155文字のメタディスクリプションにおいて、キーワードがすべて最初の20%の位置に密集しているか、文末で無意味に繰り返されている場合、システムはそれをランキングアルゴリズムに対する欺瞞行為と見なします。
Backlinkoのデータ分析によると、自然な説明文における名詞と動詞の比率は通常3:1程度に保たれています。
「Googleのスニペットジェネレーターの出力は、ユーザーのクエリの関連性とソーステキストの言語的完全性とのバランスである」という技術指針は、単なる語句のヒットだけでは表示権を得るのに不十分であることを示しています。100万語の英語コーパスに対するワードエンベディング(Word Embedding)分析では、アルゴリズムはどの単語が同一のセマンティック(意味)クラスターに属しているかを識別できます。管理者は “Running Shoes”、”Shoes for Running”、”Runner Footwear” を繰り返し書く必要はありません。アルゴリズムがすでにこれらを同一の実体として分類しているためです。メタディスクリプションでこれらの類義語を繰り返し言及することは、過剰最適化と見なされます。
モバイルユーザーが画面をスクロールする際の視覚的な焦点は、通常スニペットの最初の2行に止まります。
キーワードを説明文の後半に詰め込むと、ユーザーはクリックする前にページの関連性を感知できません。カリフォルニア地域でのモバイル検索行動に関する調査では、アクション指向の動詞(Compare、Discover、Getなど)を最初の40文字に配置したメタディスクリプションは、前部にキーワードを詰め込んだ説明文よりもインタラクション頻度が12%高いことがわかりました。
技術的なコードの問題
技術的なエラーにより、Googleのクロールツール(Googlebot)がメタディスクリプションを抽出できなくなることがあります。
統計によると、スニペット表示の異常の約15%はHTMLの構造的エラーに起因しています。Googleは、メタディスクリプションタグがHTMLドキュメントの最初の1MB以内にあること、およびタグが完全に閉じていることを求めています。
もしページがメタディスクリプションの挿入をJavaScriptに依存しており、スクリプトの実行時間が5秒を超える場合、Googlebotはレンダリング後のテキストではなく、静的ソースコード内の空白を収集することがよくあります。
タグの位置
Chromiumレンダリングエンジンの基本ロジックに基づくと、パーサーはHTMLをスキャンする際にドキュメントオブジェクトモデル(DOM)ツリーを構築します。
<meta name="description"> タグがHTMLソースコードの1,024,000バイト(約1MB)以降に配置されている場合、そのタグはGoogleのインデックスシステムによって無視されます。
この現象は、大量のインラインCSSやBase64エンコードされた画像を使用しているページでよく見られます。
ウェブページの冒頭に数千行のインラインスタイルシートや複雑なSVGグラフィックコードが読み込まれると、メタディスクリプションタグはドキュメントの深い領域へと追いやられてしまいます。Googleのクローラーはクロールバジェットと計算リソースを節約するため、通常ドキュメントの最初の1MBのみを精査してメタデータのスキャンを行います。
このしきい値を超えると、システムは <head> 内の属性の探索を停止し、本文コンテンツに対する一般的なクロールモードに移行します。その結果、設定されたメタディスクリプションは検索結果ページに表示されなくなります。
HTMLの仕様では、メタディスクリプションタグは <head> と </head> の間に厳密に配置されなければなりません。
コード構造の中に閉じられていないタグが存在する場合、例えばメタディスクリプションの前にある <script> タグに終了記号の </script> が欠けていたり、<style> ブロックが正しく閉じられていなかったりすると、Googlebotのパーサーは解析のずれを起こします。
この場合、パーサーは <head> 部分が予定より早く終了したと判断し、後続のメタディスクリプションを誤って <body> 領域の一部として扱う可能性があります。Googleのインデックスシステムは <body> 内の <meta> タグに極めて低い重みしか与えないか、あるいは無視するため、スニペットの抽出に失敗します。
データモニタリングによると、HTML構文チェックに失敗したサイトでは、標準に準拠したサイトよりもメタディスクリプションの喪失率が22%高くなっています。
| タグの位置と構造状態 | Googlebotの認識成功率 | 技術的原因の分析 |
|---|---|---|
<head> の最初の 100KB 以内 |
99.2% | パーサーの高優先クロールエリアにあり、スクリプトの実行干渉をほぼ受けない。 |
| 大量のインラインCSS(1MB超)の後 | 12.5% | Googlebotのデフォルトのメタデータスキャン深度しきい値を超えている。 |
<body> タグの開始位置の後 |
5.8% | W3C標準に違反しており、パーサーはメタデータではなく通常のテキスト断片として扱う。 |
上方のタグ(<title>など)が閉じられていない |
0.4% | 解析ツリーが崩壊し、メタディスクリプションが上方タグの子要素として扱われる。 |
ドキュメント末尾 </html> の直前 |
0.1% | クローラーがここに到達する前に、通常インデックススニペットの抽出を完了している。 |
ドキュメントの文字エンコーディング宣言(Charset Declaration)の位置もメタディスクリプションの解析に影響します。
Googleの推奨事項によると、<meta charset="utf-8"> はドキュメントの最初の1024バイト以内に現れるべきです。
エンコーディング宣言がメタディスクリプションタグの後ろに配置されている場合、パーサーがメタディスクリプションを読み取る時点でページのエンコード形式がまだ確定していない可能性があります。
非ASCII文字(特殊記号や多言語文字など)を含む説明内容の場合、この順序の誤りは文字化けを引き起こします。Googleのアルゴリズムがメタディスクリプションに解析不能な文字化けが大量に含まれていることを検出すると、システムはそのタグを自動的にフィルタリングし、代わりにページ内から可読性の高いプレーンテキストを抽出します。
JavaScript レンダリング
Googleは元のソースコードの処理スピードは非常に速いですが、スクリプトの実行を必要とするページの処理に関しては、レンダリングキューの待機時間が24時間から14日程度かかることがあります。
ページがReact、Vue、Angularなどのフレームワークを使用しており、メタディスクリプションの内容が useEffect や onMounted フックによってリアルタイムで読み込まれる場合、Googlebotが第一段階で取得したHTMLドキュメントには、空の <meta name="description" content=""> しか含まれていません。
この時、インデックスデータベースにはこの空の値が記録されます。たとえその後のレンダリング段階でテキストの抽出に成功したとしても、検索結果ページの表示が更新される時間は通常のHTMLページよりも3倍以上遅くなります。
Chromiumレンダリングエンジンの技術文書によると、WRS(Web Rendering Service)はChrome 120以降のヘッドレスブラウザ環境をシミュレートしており、各クロールリクエストに1024MBのメモリ割り当てを行っています。
もしページが読み込むJavaScriptパッケージの総容量が5MBを超えているか、スクリプトの初期化プロセスに20件以上の外部APIリクエストが含まれている場合、レンダリングサービスはリソース消費が過大であるとして、後続のDOM操作命令の実行を停止します。
50,000サイトを対象としたテストでは、スクリプトの実行時間が5.5秒を超えるページにおいて、メタディスクリプションが正しく認識される確率が62%低下しました。
Googleのクロールバジェットの割り当て規則により、権威性の低いサイトにおいてレンダリングサービスが初回の実行でメタディスクリプションを取得できなかった場合、システムはページ本文の最初の <p> タグから最初の160文字をスニペットとして抽出する傾向があります。
| レンダリング技術案 | 初期HTMLにメタ記述があるか | Googleインデックス反映の遅延 | WRS実行失敗のリスク |
|---|---|---|---|
| クライアントサイドレンダリング (CSR) | いいえ(プレースホルダーのみ) | 2日〜14日 | 高い |
| サーバーサイドレンダリング (SSR) | はい(完全なテキスト) | 即時反映 | 低い |
| 静的サイト生成 (SSG) | はい(完全なテキスト) | 即時反映 | なし |
| エッジSEO (Cloudflare/AWS) | はい(リクエスト経由で注入) | 即時反映 | 低い |
「メタディスクリプションは、DOM解析の早い段階で準備ができている状態でなければなりません。非同期リクエストの返答を待ってから入力される説明文の内容は、すべてクローラーに無視されるリスクに直面します。」
この技術的現象は、シングルページアプリケーション(SPA)で特に一般的です。
ユーザーがブラウザでナビゲーションをクリックした際、ページはリロードされず、メタディスクリプションは history.pushState を通じて更新されます。しかし、Googlebotにとっては、そのURLに対応する独立した入り口のみをクロールします。その入り口のソースコードにメタディスクリプションが含まれておらず、JavaScriptによるクライアントサイドでのリアルタイム生成のみに頼っている場合、検索エンジンがページの関連性を評価する際に乖離が生じ、結果としてスニペットの内容が実際のページ内容と一致しなくなります。
Robots設定の衝突
Googlebotがウェブページを処理する際、HTMLソースまたはHTTPレスポンスヘッダー内のrobotsディレクティブを優先的に遵守します。
コード内に特定の制限タグが存在する場合、たとえ開発者が <meta name="description"> に高品質なコンテンツを記述していても、SERPではスニペットを完全に非表示にするか、強制的に切り捨てる形で処理されます。
この衝突が最も頻繁に見られるのは nosnippet タグの使用です。
Googleの公式ドキュメントの規定によると、ページHTMLに <meta name="robots" content="nosnippet"> が含まれている場合、Googleはそのページに対していかなる形式のテキスト説明や動画プレビューを表示することも禁止されます。
大規模サイトのクローラー監査では、約2%のページがテンプレートの移行プロセスにおいてテスト環境の nosnippet 命令を誤って残してしまったために、本番環境の検索結果でタイトルとURLのみが表示され、説明文が完全に失われていることが判明しています。
完全な無効化命令以外にも、max-snippet 命令を使用すると、開発者は検索結果におけるスニペットの最大文字数を設定できます。
もしコード設定が <meta name="robots" content="max-snippet:50"> で、設定されたメタディスクリプションが150文字の場合、Googleのアルゴリズムは多くの場合、50文字では十分な情報量を伝えられないと判断し、その説明文を表示しないか、あるいは長さ制限に適合するページ内の短文をランダムに抽出することを選択します。この数値が0に設定された場合、技術的な効果は nosnippet と同等になります。
以下の表は、一般的な命令パラメータとそのメタディスクリプション表示への定量的影響をまとめたものです。
| 命令名称 | 典型的なコード例 | メタ記述表示への制限効果 |
|---|---|---|
| nosnippet | content="nosnippet" |
100% ブロック。テキストスニペットを表示しない。 |
| max-snippet:0 | content="max-snippet:0" |
nosnippet と同等の効果。全く表示されない。 |
| max-snippet:[number] | content="max-snippet:60" |
指定された文字数のみ表示。超過分は破棄される。 |
| indexifembedded | content="noindex, indexifembedded" |
ページがiframeとして他所に埋め込まれた場合にのみスニペット表示の可能性がある。 |
技術的な排他性衝突はHTMLタグだけでなく、HTTPプロトコルのレスポンスヘッダー、すなわち X-Robots-Tag にもよく隠れています。
この命令はHTMLソースに現れないため、開発者がブラウザで「ページのソースを表示」しても気づくことができません。NginxやApacheサーバーの設定で X-Robots-Tag: nosnippet がグローバルに設定されていると、そのサーバー配下のすべてのPDFファイル、画像、あるいは動的ページから説明文が失われます。
このような隠れた命令が存在するかを確認するには、curl -I [URL] コマンドを使用してサーバーが返却するヘッダー情報を確認する必要があります。もしヘッダーに X-Robots-Tag: noindex が含まれていると、Googlebotはページをインデックスデータベースに保存することさえせず、当然メタディスクリプションを抽出・表示することもできなくなります。
HTML 5の標準では、開発者はこの属性を <span>、<div>、<section> タグに追加して、その領域のコンテンツを検索スニペットに使用しないようGoogleに伝えることができます。
ページの主要な本文コンテンツがすべて data-nosnippet でマークされており、かつ <head> 領域に有効なメタディスクリプションタグが欠けている場合、Googleのレンダリングエンジンはページ断片(フラグメント)を抽出しようとした際に「利用可能なコンテンツなし」と判断します。このロジックの衝突により、Googleはページナビゲーション、フッターのコピーライト情報、あるいはマークされていないその他の無関係なテキストを、埋め合わせの説明文として強制的にクロールすることになります。
- 複数の命令による重複衝突:ページに
indexとnosnippetが同時に存在する場合、Googleは「最も厳格な原則」を採用し、nosnippetを優先的に実行します。 - CMSプラグインのデフォルト設定制限:ShopifyやWordPressサイトにおいて、一部のセキュリティプラグインはコンテンツの不正収集を防ぐために、非標準ページ(検索結果ページ、タグページなど)に
nosnippetやnoarchiveを自動的に挿入することがあります。これはSEOプラグインで手動入力された説明文を上書きします。 - キャッシュ有効期限命令の影響:
unavailable_after命令は具体的なタイムスタンプを設定します。現在時刻が設定値を超えた場合(例:unavailable_after: 2025-12-31)、GoogleはそのページのいかなるスニペットもSERPに表示しなくなります。
複雑な多国籍サイトのアーキテクチャでは、CDNプロバイダー(CloudflareやAkamaiなど)がエッジノードでWorkersスクリプトを通じてレスポンスヘッダーやHTMLを動的に変更することがあります。CDNレイヤーで誤ってrobots制限命令が追加されると、バックエンドサーバーの元のコードがいかに完璧であっても、最終的にGooglebotに送られるデータには「スニペット表示禁止」のフラグが付くことになります。
技術チームは定期的にGoogle Search Consoleの「URL検査」ツールを使用し、「リクエストされたURL」タブの下でHTTPレスポンス本文を確認し、snippet キーワードを含むネガティブな命令が含まれていないことを確認すべきです。
Googleが自動生成の方が優れていると判断した場合
Ahrefsが19.2万ページを分析したデータによると、ユーザーの検索語句がメタディスクリプションに含まれていない場合、Googleの書き換え率は82.7%に達します。
たとえ説明文にキーワードが含まれていても、書き換え確率は59.7%を維持しています。GoogleはBERT言語モデルを利用して、ウェブページ本文から約160文字の断片をリアルタイムで抽出し、検索結果に太字のキーワードが出現するように調整する傾向があります。この手法により、検索結果のクリック率(CTR)は統計的に5%から10%向上します。これは、太字の語句が検索意図に対するフィードバックとして機能するためです。
アルゴリズムによる書き換え
ページがインデックスに登録された後、アルゴリズムはメタディスクリプションの表示方法を永続的に固定するわけではありません。
もし設定された説明テキストとユーザーが入力した検索語句との間に意味的な交わりが欠けている場合、アルゴリズムはページ本文から約160文字のテキストを抽出します。この抽出行為は、通常、検索語句が本文の200文字から500文字の区間に出現し、メタディスクリプションにはその単語が全く言及されていない場合に発生します。
アルゴリズムの目標は検索結果のクリック効率を最大化することであるため、太字のキーワードを含むテキスト断片を優先的に選択します。
| トリガーシナリオの分類 | 統計的な書き換え確率 | アルゴリズムの判断ロジックの説明 |
|---|---|---|
| 検索語句の欠落 | 82.7% | メタ記述に検索語句が含まれず、システムが本文内から一致する項目を探索する。 |
| 記述が長すぎ・短すぎ | 65.4% | 長さが960ピクセルを超えるか50文字未満で、情報伝達効率が低いと判定される。 |
| コンテンツの重複性 | 71.0% | 複数のURLで同じ記述テンプレートを使用しており、アルゴリズムがタグを無視して独自内容を収集。 |
| セマンティックの不一致 | 58.2% | 記述内容はブランドの宣伝文句であるが、クエリは具体的な技術パラメータの検索である場合。 |
デスクトップブラウザの表示スペースは通常920ピクセル以内に制限され、モバイル版は約600ピクセルに縮小されます。
もしメタディスクリプションの長さが1000ピクセルに達した場合、Googleのフロントエンド表示システムはまず切り捨てを試みますが、切り捨てられた後の文章が意味的に支離滅裂な場合、バックエンドのスニペット生成アルゴリズムはそのメタディスクリプションを「低品質な出力」と判定します。この時、システムはページ内部の <h1> または <p> タグの内容を呼び出し、制限されたピクセル内で意味を完全に表現できる一文を探して差し替えます。
| クエリタイプ | 書き換え傾向 | 典型的な差し替えソース |
|---|---|---|
| 情報提供型クエリ | 高 | ページ上部の定義文またはFAQリスト。 |
| ナビゲーション型クエリ | 低 | ブランド名を含む場合、通常は設定された説明文が保持される。 |
| トランザクション型クエリ | 中 | 価格、仕様、または「送料無料」などの文字を含む本文の断片。 |
| ロングテールクエリ | 極高 | 特定のロングテールワードに一致するH2見出し直後の最初の一文。 |
同一のURLに対して、Googleは何百種類もの異なるスニペットを生成することがあります。
例えば、「クラウドサービス選定ガイド」に関するページが、「クラウドサービス 価格比較」と「クラウドサービス 安全性テスト」という2つの異なる意図のキーワードで表示される際、静的なメタディスクリプションで両方の側面をカバーするのは困難です。Googleの動的な書き換えメカニズムはページ本文の構造を分析し、ページ内に価格を詳しくリスト化した表があれば、ユーザーが「価格」と検索した際に表付近のテキストを自動的にスニペットとして抽出します。
もしウェブページ本文に論理的に明確な段落構造が欠けている場合、アルゴリズムはナビゲーションメニュー、フッターテキスト、あるいはサイドバーのリンクを抽出してしまい、結果として論理の通らない支離滅裂なスニペットが生成されることがあります。これは通常、ページに有効な本文テキスト密度が不足しているために起こります。
大量の技術仕様や製品属性を含むページを処理する際、ページが Product または Review のSchemaマークアップを使用しているにもかかわらず、メタディスクリプションにそれらの主要な属性が反映されていない場合、Googleは評価点、価格、在庫状況を含めるために説明文を書き換えることがよくあります。
メタディスクリプションが単に「最新のスポーツシューズコレクションを見る」という内容で、本文に具体的な「耐摩耗性スコア 9.5」や「重量 250g」といったデータがある場合、アルゴリズムは後者の方がユーザーにとって参考価値が高いと判定します。設定された説明文の表示を維持するためには、説明文内の情報密度を本文の最初の300文字の平均レベル以上に保つ必要があります。
書き換えを減らす方法
もし設定されたメタディスクリプションに、そのページでランキング上位3位以内に入っている検索語句が含まれていない場合、Googleによる自動書き換えの確率は80%以上に急騰します。この介入を減らすには、GSCからエクスポートした高頻度ワードを説明文の最初の65文字以内に自然な形で組み込む必要があります。具体的な操作では、説明文の内容とページのH1タグ、および本文の冒頭段落との間に高いセマンティックな一致性を維持する必要があります。
執筆の際は、曖昧な宣伝用語を避け、具体的なパラメータ、ブランド名、あるいは明確な行動を促すフレーズ(CTA)を含む平叙文を使用するようにしてください。
- 文字数とピクセルの正確なコントロール: デスクトップ版の検索結果の表示幅上限は約920〜960ピクセル、モバイル版は600〜680ピクセルの間です。文字によって占有ピクセルが異なるため、単純な文字数カウントだけでは不正確です。ピクセルチェックツールを活用し、記述が920ピクセル内で終わるようにして、末尾が切断されて情報が不完全にならないようにしてください。不完全な文章はアルゴリズムによって低品質な表示と見なされ、自動書き換えがトリガーされやすいためです。
- テンプレート化された重複内容の解消: 数千のページを持つ大規模なECサイトを扱う場合、サイト全体で同じメタディスクリプションテンプレートを使い回すのを避けてください。大量のURLの記述に微小な差異しかない場合、Googleのクロールツールはそれらのタグをターゲットが不明確であるとして無視します。高トラフィックなページには手動でユニークな説明文を書き、ロングテールなページについてはプログラムで生成される断片が十分な識別性を持つようにしてください。
- 検索意図に合わせた動詞の選択: 情報収集型クエリ(Informational Queries)に対しては、説明の冒頭に「知る」「比較する」「発見する」などの誘導語を使用します。取引型クエリ(Transactional Queries)に対しては、「購入」「ダウンロード」「価格」などの具体的な言葉を含めます。説明の口調を、SERP内の他の上位結果のスタイルと一致するように調整することで、説明文が採用される確率を効果的に高められます。
実際のSEO監査において、多くのサイトがメタディスクリプションを設定しているものの、内容がページで主に議論されているテーマから逸脱しているケースが見受けられます。例えば、「最高のランニングシューズ」に関するページのメタディスクリプションがそのブランドの歴史について語っている場合、このような意味的な乖離がアルゴリズムの介入を招きます。
メタディスクリプションをページ内容の正確な要約として設計し、2〜3個のロングテールワードを含めることで、検索結果での表示頻度を大幅に改善できます。HTML内の特殊文字には注意が必要です。エスケープされていない記号は解析エラーを引き起こし、Googleが完全なメタディスクリプションを読み取れなくなる原因となり、結果としてテキスト段落からランダムな断片が抽出されることになります。
- データ主導の最適化ロジック: 定期的にGSCでのCTRの変動を確認してください。ページの平均掲載順位が変わっていないのにCTRが3%以上低下している場合は、SERPのスニペットが書き換えられていないかチェックする必要があります。書き換えられた内容が主にページのFAQセクションから来ていることが判明した場合、元のメタディスクリプションがユーザーの疑問をカバーできていなかったことを示しています。この場合は、書き換えられた断片を参考に、メタディスクリプションの論理構造を再調整すべきです。
- セマンティックな重みの分布: 最も重要な情報は文の最前部に配置してください。研究によると、Googleのクロールツールはメタディスクリプションの冒頭部分に対する注目度が、末尾部分よりもはるかに高いことが示されています。最初の50文字で、ページの主要なバリュープロポジション(提供価値)を独立して表現できるようにすべきです。
- 句読点の過度な使用を避ける: 過剰な感嘆符や連続した三点リーダー(…)は、説明文の専門性を低下させます。アルゴリズムは、こうしたスパム的な特徴を持つ内容をブロックする傾向があります。文構造を平易かつ中立に保ち、学術的またはプロフェッショナルな情報伝達の規範に合わせるようにしてください。
構造化データ(Schema Markup)を処理する際、ページがFAQやProductのスキーマを使用している場合、メタディスクリプションはそれらと完全に重複するのではなく、橋渡しや予告のような役割を果たすべきです。大量の技術仕様を含むページについては、説明文に「重量わずか1.2kg」や「4K解像度対応」といった具体的な数値データを含めるように試みてください。


