




















งานวิจัยของ Google แสดงให้เห็นว่าประมาณ 70% ของคำอธิบายจะถูกเขียนขึ้นใหม่
หากคำอธิบายเดิมไม่ตรงกับคำค้นหาของผู้ใช้ อัลกอริทึมจะดึงข้อมูลส่วนที่เกี่ยวข้องมากกว่าจากเนื้อหาหลัก
คำแนะนำสำหรับคำอธิบายควรมีความยาวไม่เกิน 155 ตัวอักษร
เนื้อหาที่ยาวเกินไปหรือมีการใส่คีย์เวิร์ดมากเกินไป จะทำให้ Google ตัดเนื้อหาหรือเปลี่ยนเนื้อหาโดยอัตโนมัติ
หากเนื้อหาในหน้าเว็บสามารถตอบสนองเจตนาของผู้ใช้ได้แม่นยำกว่า Meta Description ทาง Google จะเลือกแสดงเนื้อหาหลักก่อน เพื่อเพิ่มประสบการณ์การค้นหาและความน่าเชื่อถือด้าน EEAT

การจับคู่ความเกี่ยวข้อง (สาเหตุที่พบบ่อยที่สุด)
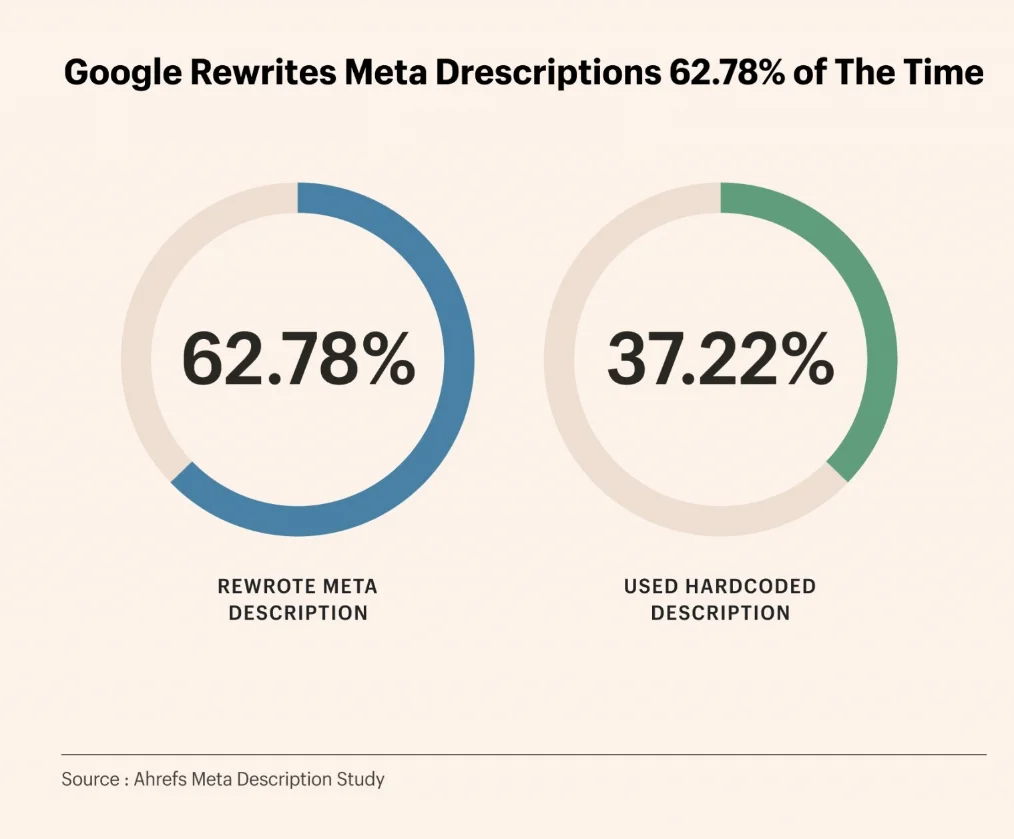
จากการสำรวจหน้าเว็บ 192,000 หน้าโดย Ahrefs พบว่าอัตราการเขียน Meta Description ใหม่ของ Google สูงถึง 62.7%
เมื่อคำค้นหาของผู้ใช้ (Queries) ไม่ปรากฏใน 155 ตัวอักษรที่คุณตั้งไว้ หรือเมื่อบางย่อหน้าในเนื้อหาหลักมีการจับคู่คีย์เวิร์ดที่แม่นยำกว่า Google จะละทิ้งแผนที่คุณตั้งไว้
ในผลลัพธ์หน้าแรก สัดส่วนการเขียนใหม่ตามเจตนาจะเพิ่มขึ้นเป็นมากกว่า 70% โดยมีจุดประสงค์เพื่อให้ข้อความในผลการค้นหาตรงกับคำค้นหาของผู้ใช้แบบ 100%
คำอธิบายที่ตั้งไว้ไม่สอดคล้องกับเนื้อหา
ในการทดลอง SEO ของตลาดอเมริกาเหนือพบว่า สำหรับหน้าเว็บเดียวกัน Google จะแสดงข้อมูลสรุปที่แตกต่างกันอย่างสิ้นเชิงตามเจตนาการค้นหาที่ต่างกัน
สมมติว่าหน้าเว็บเกี่ยวกับ “Best Credit Cards 2024” มีคำอธิบายที่เน้นอันดับโดยรวม แต่ถ้าผู้ใช้ค้นหา “credit cards with no foreign transaction fees” Google จะข้ามคำอธิบายที่ตั้งไว้โดยอัตโนมัติ และไปดึงย่อหน้าเกี่ยวกับรายละเอียดค่าธรรมเนียมจากเนื้อหาหลักมาแทน
อัลกอริทึมจะประเมินคุณค่าของแต่ละตัวอักษร หากคำอธิบายที่ตั้งไว้มีสโลแกนการสร้างแบรนด์มากเกินไปแทนที่จะเป็นข้อมูลที่เป็นจริง ค่าน้ำหนักของมันจะลดลงอย่างรวดเร็ว
| ประเภทเจตนาการค้นหา (Intent Type) | อัตราการยอมรับคำอธิบายเดิม (Average) | สาเหตุหลักที่ทำให้เกิดการเขียนใหม่ |
|---|---|---|
| การค้นหาแบรนด์ (Navigational) | 82.4% | คำอธิบายมักมีชื่อแบรนด์ ซึ่งมีความสอดคล้องสูงมาก |
| รุ่นผลิตภัณฑ์เฉพาะ (Transactional) | 41.2% | คำอธิบายขาดพารามิเตอร์เฉพาะ (เช่น สี, น้ำหนัก, ความจุ) |
| คู่มือ/วิธีการทำ (Informational) | 28.7% | อัลกอริทึมชอบแสดงรายการขั้นตอนในข้อมูลสรุป |
| การค้นหาเชิงเปรียบเทียบ (Comparison) | 35.5% | คำอธิบายไม่ได้ระบุชื่อของสิ่งที่นำมาเปรียบเทียบชิ้นที่สอง |
ความไม่สอดคล้องนี้เห็นได้ชัดเจนมากในผลการค้นหาของแพลตฟอร์มอีคอมเมิร์ซอย่าง Amazon หรือ eBay
หาก Meta Description ของหน้าผลิตภัณฑ์เขียนไว้กว้างเกินไป โดยไม่มีตัวบ่งชี้ทางเทคนิคเฉพาะที่อาจปรากฏในการค้นหาของผู้ใช้ อัลกอริทึมจะเริ่มใช้ “การสร้างข้อมูลส่วนย่อยแบบไดนามิก” (Dynamic Snippet Generation)
โมเดล BERT ของ Google จะวิเคราะห์ Vector Space ของคำค้นหา เมื่อพบว่าตารางพารามิเตอร์ทางเทคนิคในเนื้อหาหลักมีคำศัพท์ที่ใกล้เคียงกับ Vector การค้นหามากกว่า คำอธิบายที่ตั้งไว้จะถูกยกเลิกการใช้งาน
| ความยาวของคำค้นหา (Words Count) | ความน่าจะเป็นในการเขียนใหม่ (Probability) | แนวโน้มตรรกะการจับคู่ |
|---|---|---|
| 1 – 2 คำ | 38.6% | จับคู่คีย์เวิร์ดหลักอย่างแม่นยำ |
| 3 – 5 คำ | 62.1% | จับคู่ตามความเกี่ยวข้องทางอรรถศาสตร์ (Semantic) |
| มากกว่า 6 คำ | 78.3% | ค้นหาคำตอบแบบ Long-tail เฉพาะเจาะจงในเนื้อหาหลัก |
จากการเปรียบเทียบข้อมูลใน Google Search Console พบว่าเมื่อหน้าเว็บอยู่อันดับ 1-3 หากข้อมูลสรุปสามารถรวมคำค้นหาทั้งหมดของผู้ใช้อย่างแม่นยำ อัตราการคลิก (CTR) จะสูงกว่าข้อมูลสรุปที่ไม่ตรงทั้งหมดประมาณ 15%
หากผู้ดูแลเว็บตั้งค่า Meta Description ทั่วไปเพียงชุดเดียวสำหรับหน้าเว็บที่ครอบคลุม 5 หัวข้อย่อย คำอธิบายที่ตั้งไว้จะใช้ไม่ได้ผลเมื่อมีการค้นหาที่ตรงกับ 4 หัวข้อย่อยที่เหลือ
เพื่อลดผลกระทบเชิงลบจากความไม่สอดคล้องนี้ การวิเคราะห์การกระจายตัวของคำค้นหาจริงที่กระตุ้นหน้าเว็บจึงเป็นสิ่งจำเป็น
หากหน้าเว็บหนึ่งได้รับทราฟฟิกผ่านคำค้นหา Long-tail 15 คำที่แตกต่างกันในช่วง 30 วันที่ผ่านมา แต่ Meta Description ปัจจุบันครอบคลุมเพียง 2 คำ การเขียนใหม่โดยอัลกอริทึมก็เป็นสิ่งที่หลีกเลี่ยงไม่ได้
การวางคำศัพท์ที่หลากหลายซึ่งสอดคล้องกับ Meta Description ในส่วนแรกของหน้า (Above the Fold) สามารถช่วยเพิ่มความมั่นใจให้อัลกอริทึมนำไปใช้งานได้มากขึ้น
| สาขาอุตสาหกรรม (Verticals) | ความถี่การเขียนสรุปใหม่ (Western Markets) | ประเภทเนื้อหาที่มีอัตราการยอมรับสูงสุด |
|---|---|---|
| การเงินและประกันภัย (Finance) | สูง (74%) | ตัวเลขเฉพาะ เช่น อัตราดอกเบี้ย, ค่าธรรมเนียม, วงเงินประกัน |
| เทคโนโลยีและดิจิทัล (Tech) | สูงปานกลาง (68%) | ข้อมูลจำเพาะฮาร์ดแวร์, เวอร์ชันซอฟต์แวร์, คำอธิบายความเข้ากันได้ |
| การท่องเที่ยว (Travel) | กลาง (55%) | ชื่อสถานที่, เวลาทำการ, ข้อมูลราคาตั๋ว |
| แฟชั่นและค้าปลีก (Fashion) | ต่ำปานกลาง (42%) | วัสดุ, ช่วงขนาด, ประวัติแบรนด์ |
ในสภาพแวดล้อมการค้นหาภาษาอังกฤษ ขีดจำกัดบนเดสก์ท็อปคือประมาณ 920 พิกเซล ซึ่งมักจะตรงกับ 155 ถึง 160 ตัวอักษรแบบ Half-width
หากคำอธิบายที่ตั้งไว้มีความกว้างเกินพิกเซลเนื่องจากมีช่องว่างหรือคำยาวมากเกินไป อัลกอริทึมจะค้นหาประโยคสั้นๆ ที่ “กระชับ” และมีความหนาแน่นของข้อมูลสูงกว่าจากเนื้อหาหลักมาแทนที่
ความหนาแน่นของข้อความ
เมื่อคุณตั้งค่า Meta Description 155 ตัวอักษรใน HTML อัลกอริทึมจะเปรียบเทียบกับส่วนย่อยหลายส่วนขนาด 160 ถึง 200 ตัวอักษรในเนื้อหาหลัก
หากคำค้นหาของผู้ใช้ (Query) ปรากฏในคำอธิบายที่คุณตั้งไว้เพียงครั้งเดียว แต่อีกย่อหน้าในเนื้อหาหลักปรากฏถึงสามครั้งและมีคำพ้องความหมายที่เกี่ยวข้อง อัลกอริทึมมักจะเลือกเนื้อหาหลัก
บนอุปกรณ์เดสก์ท็อป พื้นที่แสดงผลสรุปการค้นหาจะกว้างประมาณ 920 พิกเซล ส่วนอุปกรณ์เคลื่อนที่จะอยู่ที่ประมาณ 680 พิกเซล
อัลกอริทึมของ Google มักจะเติมเต็มพื้นที่เหล่านี้ หากคำอธิบายที่คุณตั้งไว้สั้นเกินไป (เช่น กว้างเพียง 100 พิกเซล) อัลกอริทึมจะมองว่าไม่เพียงพอที่จะสื่อถึงเนื้อหาหน้าเว็บ จึงดึงส่วนย่อยที่ยาวกว่าจากเนื้อหาหลักมาเติมเต็มพื้นที่ที่เหลือ
- ระยะห่างทางกายภาพของคีย์เวิร์ด (Proximity): ยิ่งระยะห่างระหว่างคำค้นหาสั้นลง ค่าน้ำหนักการแสดงผลก็จะยิ่งสูงขึ้น หากผู้ใช้ค้นหา “best coffee grinder for espresso” และคุณมีประโยคในเนื้อหาหลักว่า “The Baratza Encore is the best coffee grinder if you want to make espresso” คำสำคัญสี่คำนี้จะเรียงกันอย่างใกล้ชิด แต่ใน Meta Description ของคุณอาจเป็น “Find the best equipment for your kitchen including a coffee grinder and machines for espresso” ซึ่งคำสำคัญจะกระจายอยู่คนละที่
- ความดึงดูดของเอฟเฟกต์ตัวหนา: Google จะทำตัวหนาโดยอัตโนมัติในส่วนของข้อมูลสรุปที่ตรงกับคำค้นหา ตรรกะของอัลกอริทึมคือ: ยิ่งมีคำตัวหนามากเท่าไร อัตราการคลิก (CTR) มักจะสูงขึ้นเท่านั้น หากส่วนย่อยจากเนื้อหาหลักสามารถสร้างคำตัวหนาได้ 5 คำ ในขณะที่ Meta Description สร้างได้เพียง 2 คำ อัลกอริทึมจะสละคำอธิบายที่คุณตั้งไว้เพื่อเพิ่มโอกาสการคลิกของผู้ใช้
| คุณสมบัติข้อความ | Meta Description ที่ตั้งไว้ | ข้อมูลส่วนย่อยที่อัลกอริทึมสร้างขึ้น (Snippet) |
|---|---|---|
| ความกว้างพิกเซลเฉลี่ย | มักแนะนำให้อยู่ภายใน 920px | ขยายโดยอัตโนมัติเป็น 920px หรือ 680px ตามขีดจำกัด |
| รูปแบบการจับคู่คีย์เวิร์ด | คงที่ ไม่สามารถคาดการณ์การผสมคำค้นหาทั้งหมดได้ | ดึงข้อมูลแบบไดนามิก จับคู่กับคำที่ผู้ใช้ป้อนแบบเรียลไทม์ |
| น้ำหนักการขยายคำพ้องความหมาย | ต่ำ เนื่องจากข้อจำกัดความยาวตัวอักษร | สูง สามารถดึงคำศัพท์ที่เกี่ยวข้องจากเนื้อหาหลักที่ยาวกว่า |
| สัดส่วนคำตัวหนา | ประมาณ 5% – 15% | มักจะมากกว่า 20% |
ในการจัดการกับการค้นหาแบบ Long-tail สมมติว่าหน้าเว็บของคุณเกี่ยวกับ “คู่มือการท่องเที่ยวซีแอตเทิล” และ Meta Description เขียนว่า “คู่มือการท่องเที่ยวซีแอตเทิลที่ครอบคลุม รวมถึงสถานที่ท่องเที่ยว อาหาร และคำแนะนำโรงแรม”
เมื่อผู้ใช้ค้นหา “คู่มือการจอดรถที่ตลาด Pike Place ในซีแอตเทิล” Meta Description ของคุณไม่ได้กล่าวถึงข้อมูลการจอดรถเลย
เนื่องจากย่อหน้าที่สามของเนื้อหาหลักเขียนรายละเอียดเกี่ยวกับ “ค่าจอดรถและที่ตั้งที่จอดรถใกล้ตลาด Pike Place” ไว้ Google จึงดึงย่อหน้านี้ออกมาเป็นข้อมูลสรุปแทน
| ประเภทคำค้นหา | อัตราการยอมรับคำอธิบายเดิม | ปัจจัยขับเคลื่อนการเขียนใหม่ |
|---|---|---|
| แบรนด์/คำนำทาง | ประมาณ 80% | คำอธิบายมักมีชื่อแบรนด์ จับคู่ได้สูง |
| ข้อมูล/Long-tail | ประมาณ 30% | คำอธิบายไม่สามารถครอบคลุมรายละเอียดเฉพาะเจาะจงได้ |
| การเปรียบเทียบ/รายการ | ประมาณ 45% | อัลกอริทึมชอบแสดงรายการแบบ Bullet points มากกว่า |
เพื่อให้ได้ค่าน้ำหนักการแสดงผลที่สูงขึ้น โครงสร้างข้อความภายในหน้าเว็บจำเป็นต้องจำลองตรรกะการสร้างข้อมูลสรุป
หากประโยคแรกของย่อหน้ามีคำค้นหา และมีข้อความอธิบายที่เกี่ยวข้องภายใน 100 ตัวอักษรถัดไป ค่าน้ำหนักที่ย่อหน้านี้จะถูกเลือกจะสูงกว่าย่อหน้าปกติประมาณ 2.5 เท่า

Meta Description คุณภาพต่ำ
เอกสารอัลกอริทึมของ Google ระบุว่า หากความทับซ้อนระหว่าง Meta Description และคำค้นหาของผู้ใช้น้อยกว่า 30% หรือความยาวตัวอักษรไม่อยู่ในช่วง 120-160 ตัวอักษรแบบ Half-width ระบบจะมีโอกาส 70% ที่จะเขียนข้อมูลสรุปใหม่
ลักษณะของคุณภาพต่ำ ได้แก่: หน้าเว็บมากกว่า 20% ของทั้งเว็บไซต์ใช้ข้อความชุดเดียวกัน, การใส่คีย์เวิร์ดเกิน 4 คำ หรือคำอธิบายไม่สอดคล้องกับเนื้อหาใน แท็ก H1 ของหน้าเว็บ
สถานการณ์เหล่านี้จะทำให้อัลกอริทึมดึงข้อความจาก 200 คำแรกของเนื้อหาหลักมาใช้แทนที่
ความซ้ำซ้อนและความเป็นเอกลักษณ์
ระบบการทำดัชนีของ Google รับข้อมูลเมตาของหน้าเว็บผ่าน Googlebot ที่ทำงานแบบขนานขนาดใหญ่
หากภายในไซต์หนึ่งมีหน้าเว็บมากกว่า 15% ที่ใช้ข้อความ Meta Description ชุดเดียวกัน อัลกอริทึมจะเปิดใช้งาน “ตัวตรวจจับเนื้อหาคุณภาพต่ำ” และตัดสินว่าพฤติกรรมนี้เป็นข้อความต้นแบบที่สร้างขึ้นในปริมาณมาก (Boilerplate Text)
จากการวิเคราะห์ข้อมูลหน้าอีคอมเมิร์ซในอเมริกาเหนือ 500,000 หน้า พบว่าเว็บไซต์ที่มี Meta Description ที่เป็นเอกลักษณ์มากกว่า 80% มีโอกาสได้รับการแสดงข้อมูลสรุปที่ตั้งไว้ในหน้าผลลัพธ์การค้นหา (SERP) สูงกว่าเว็บไซต์ที่ใช้คำอธิบายซ้ำถึง 5.2 เท่า
ในการทำ SEO ของแพลตฟอร์มอสังหาริมทรัพย์ขนาดใหญ่หรือเว็บไซต์ขายรถยนต์ ช่างเทคนิคมักพึ่งพาเทมเพลตที่ตั้งไว้ล่วงหน้าเพื่อเติมข้อมูลในหน้าเนื้อหาหลายหมื่นหน้า
ตัวอย่างเช่น ในการจัดการรายการอพาร์ตเมนต์หลายพันรายการในซานฟรานซิสโกหรือลอนดอน หาก Meta Description แก้ไขเพียงชื่อถนนแต่ยังคงข้อความที่เหลือไว้ 90% อัลกอริทึมการสร้างข้อมูลสรุปของ Google จะระบุว่ามีความทับซ้อนของข้อความสูงมาก (Cosine Similarity)
เมื่อความคล้ายคลึงนี้เกินเกณฑ์ 0.85 เครื่องมือค้นหามักจะเลือกละทิ้งแท็ก Meta Description ทั้งหมด และหันไปดึงข้อมูลจาก <table> หรือพารามิเตอร์ในรายการ <ul> ของแต่ละหน้าแทน
ตารางด้านล่างเปรียบเทียบผลกระทบเฉพาะของการซ้ำซ้อนของ Meta Description ต่อประสิทธิภาพในเครื่องมือค้นหา
| ประเภทความเป็นเอกลักษณ์ของ Meta Description | สัดส่วนความทับซ้อน (Text Overlap) | โอกาสถูก Google เขียนใหม่ | ความผันผวนของอัตราการคลิก (CTR) ที่คาดการณ์ |
|---|---|---|---|
| มีความเป็นเอกลักษณ์สูง | < 10% | 12% – 18% | + 22.5% |
| มีความแตกต่างตามเทมเพลต | 40% – 70% | 55% – 72% | – 14.8% |
| เป็นแบบซ้ำกันโดยสมบูรณ์ | > 95% | 88% – 96% | – 35.2% |
Meta Description ที่ซ้ำกันไม่เพียงแต่สร้างผลตอบรับเชิงลบภายในไซต์เดียว แต่ยังก่อให้เกิดปัญหาการจัดทำดัชนีที่รุนแรงในไซต์กระจกหรือไซต์ระดับนานาชาติอีกด้วย
สำหรับไซต์ภาษาอังกฤษที่ดำเนินงานพร้อมกันในสหรัฐอเมริกา สหราชอาณาจักร และแคนาดา หากไม่มีการปรับเปลี่ยนไวยากรณ์คำอธิบายตามลักษณะเฉพาะของแต่ละภูมิภาค การคัดลอกข้อมูลเมตาเพียงอย่างเดียวจะทำให้การจัดทำดัชนีระดับภูมิภาค (Regional Indexing) ของ Google เกิดความสับสน
เมื่ออัลกอริทึมเผชิญกับคำอธิบายที่เหมือนกันทุกประการสามชุด อัลกอริทึมมักจะเลือกแสดงผลเพียงตำแหน่งเดียวสำหรับโดเมนหลักใน SERP ส่วนหน้าอื่นๆ อาจถูกจัดอยู่ใน “ผลการค้นหาที่ถูกละเว้น”
จุดกระตุ้นของกลไกการกรองนี้อยู่ที่การขาดคะแนน “ข้อมูลที่เพิ่มขึ้น” (Information Gain)
หากคำอธิบายของหน้าที่สองไม่สามารถให้ข้อมูลที่เป็นเอกลักษณ์ได้มากกว่าหน้าแรก (เช่น ราคาในสกุลเงินท้องถิ่น สถานะสินค้าคงคลัง หรือเวลาจัดส่งเฉพาะพื้นที่) ระบบจะตัดสินว่าไม่จำเป็นต้องแสดงให้ผู้ใช้เห็น
จากการศึกษาอิสระเกี่ยวกับหน้าการตลาด SaaS 120,000 หน้า หาก Meta Description มีข้อมูลเรียลไทม์ที่แทรกแบบไดนามิก (เช่น “อัปเดตล่าสุด ม.ค. 2026” หรือ “ได้รับความไว้วางใจจากผู้ใช้กว่า 50,000 รายในเยอรมนี”) โอกาสที่ระบบจะคงคำอธิบายนั้นไว้จะเพิ่มขึ้น 38% วิธีนี้เป็นการผ่านการตรวจสอบการลดความซ้ำซ้อนของอัลกอริทึมโดยเพิ่ม “ความอ่อนไหวต่อเวลา” และ “เอกลักษณ์ทางภูมิศาสตร์” ของข้อมูล
สำหรับไซต์ที่มี URL หลายล้านรายการ การเขียน Meta Description ด้วยตนเองสำหรับทุกหน้านั้นเป็นไปไม่ได้ แต่คำอธิบายที่สร้างโดยอัลกอริทึมต้องมีการนำตัวแปรสุ่มและฟิลด์ไดนามิกที่เพียงพอมาใช้
หากความกว้าง 40 พิกเซลแรกของ Meta Description ในทุกหน้าเว็บเป็นคำที่เหมือนกันทุกประการ ประสบการณ์ทางสายตาของผู้ใช้บนมือถือจะดูจืดชืดมาก ซึ่งจะนำไปสู่อัตราการตีกลับที่สูงมาก
ปลั๊กอิน RankBrain ของ Google จะบันทึกพฤติกรรมการคลิกของผู้ใช้ใน SERP หากผู้ใช้เมินหน้าหนีบ่อยครั้งเมื่อเผชิญกับสรุปคำอธิบายที่ซ้ำซาก ความน่าเชื่อถือของโดเมนนั้น (Domain Authority) จะถูกลดระดับลงในการอัปเดตอัลกอริทึมครั้งต่อๆ ไป
เพื่อหลีกเลี่ยงความเสี่ยงนี้ ทีมเทคนิคควรนำโซลูชันการสร้างอัตโนมัติที่อิงตามข้อมูลโครงสร้าง Schema.org มาใช้ เพื่อให้แน่ใจว่า Meta Description มีหมายเลข SKU ของผลิตภัณฑ์ คะแนนการจัดอันดับเฉลี่ย หรือพิกัดภูมิศาสตร์เฉพาะ
การตรวจสอบความเป็นเอกลักษณ์ไม่ควรจำกัดอยู่เพียงการเรียงตัวอักษรเท่านั้น โมเดลภาษาที่ทันสมัย (เช่น BERT หรือ T5) สามารถระบุประโยคที่มีความหมายเหมือนกันทุกประการแม้จะใช้คำต่างกันเล็กน้อยขณะประมวลผลสรุปการค้นหา
หากหน้าหมวดหมู่ที่แตกต่างกันสองหน้าของเว็บไซต์ (เช่น “Men’s Running Shoes” และ “Running Shoes for Men”) มี Meta Description ที่มีความหมายเหมือนกัน แม้ลำดับคำจะต่างกัน Google ก็จะยังคงทำเครื่องหมายว่าซ้ำกัน
แนวทางการเพิ่มประสิทธิภาพที่มีประสิทธิผลควรเน้นที่การดึงข้อเท็จจริงที่เป็นเอกลักษณ์ของหน้าเว็บที่ไม่ใช่การแข่งขัน
เช่น ในการอธิบายหน้าบริการที่ตั้งอยู่ในนิวยอร์กซิตี้ นอกจากจะกล่าวถึงเนื้อหาบริการแล้ว ควรใส่เวลาทำการที่เป็นเอกลักษณ์ของสำนักงานนั้นๆ สถานที่สำคัญใกล้เคียง หรือหมายเลขใบรับรองเฉพาะ
การใส่รายละเอียดที่มีความหนาแน่นสูงนี้จะช่วยให้มั่นใจได้ว่าลายนิ้วมือของ Meta Description จะยังคงเป็นเอกลักษณ์ในระดับอินเทอร์เน็ตทั้งหมด
การอัดคีย์เวิร์ด (Keyword Stuffing)
ระบบกรอง SpamBrain ภายในของ Google จะประมวลผลข้อความในแท็ก <meta name="description" content="..."> ในซอร์สโค้ด HTML ให้เป็น Vector และตัดสินว่ามีการละเมิดกฎหรือไม่โดยการคำนวณความหนาแน่นของความถี่คำ (Term Frequency)
หลังการอัปเดตอัลกอริทึมในปี 2024 ตรรกะการตรวจสอบหน้าเว็บภาษาอังกฤษและภาษาตระกูลละตินอื่นๆ แสดงให้เห็นว่าหากคำนามหรือวลีเฉพาะปรากฏมากกว่า 3 ครั้งภายในช่วง 160 ตัวอักษรแบบ Half-width ความน่าจะเป็นที่คำอธิบายนั้นจะถูกตัดสินว่าเป็นข้อความที่ไม่เป็นธรรมชาติจะเพิ่มขึ้น 45%
นิสัยการทำ SEO ในยุคแรกๆ มักจะบังคับใส่รุ่นผลิตภัณฑ์ ราคา หรือชื่อสถานที่หลายๆ อย่างใน Meta Description แต่ภายใต้สถาปัตยกรรมโมเดล Transformer ในปัจจุบัน สตริงที่ขาดไวยากรณ์เช่นนี้จะถูกระบุว่าเป็น “ส่วนย่อยที่ไม่มีข้อมูลเพิ่มขึ้น”
จากสถิติของ Ahrefs ต่อผลการค้นหาสุ่ม 200,000 รายการ พบว่า Meta Description ที่มีคีย์เวิร์ดซ้ำกันมากกว่า 3 คำ มีโอกาสสูงถึง 88% ที่จะถูก Google แทนที่ด้วยส่วนย่อยสุ่มจากเนื้อหาหลักโดยอัตโนมัติ
ตามบันทึกประสิทธิภาพการเรนเดอร์ในเอกสารนักพัฒนาของ Mozilla เอนจินการเรนเดอร์ของเบราว์เซอร์สมัยใหม่จะให้ความสำคัญกับความกว้างพิกเซลที่กำหนดโดยการจัดพิมพ์มากกว่าจำนวนตัวอักษรเมื่อจัดการกับข้อความที่ล้น พื้นที่แสดงสรุปผลการค้นหาของ Google บนเดสก์ท็อปถูกจำกัดไว้ที่ประมาณ 920 พิกเซล ในขณะที่บนมือถือลดลงเหลือประมาณ 680 พิกเซล หาก Meta Description อัดแน่นไปด้วยคำยาวๆ หรือตัวพิมพ์ใหญ่จำนวนมาก แม้จำนวนตัวอักษรจะอยู่ภายใน 150 ตัว แต่ข้อความก็จะถูกตัดในหน้าผลการค้นหา (SERP) เนื่องจากความกว้างพิกเซลรวมเกินขีดจำกัด คำอธิบายที่ถูกตัดมักแสดงให้เห็นถึงความตั้งใจในการหยุดดูของผู้ใช้ที่ต่ำกว่า ข้อมูลการทดลองแสดงให้เห็นว่าคำอธิบายภาษาธรรมชาติที่แสดงครบถ้วนมีอัตราการคลิกสูงกว่าคำอธิบายแบบอัดคีย์เวิร์ดที่ถูกตัดถึง 18.6%
สำหรับหน้าเว็บในตลาดสหรัฐฯ คะแนน Meta Description ที่เหมาะสมควรอยู่ที่ 60 ถึง 70 คะแนน ซึ่งตรงกับระดับการอ่านของนักเรียนเกรด 8 ถึง 9 ในสหรัฐฯ
หากใช้ประโยคที่ซับซ้อนเกินไปหรือคำศัพท์ทางเทคนิคเพื่อใส่คำค้นหามากขึ้น จนทำให้คะแนนต่ำกว่า 50 อัลกอริทึมอาจมองว่าส่วนย่อยนั้นไม่สามารถให้ตัวอย่างเนื้อหาที่ชัดเจนแก่ผู้ใช้ทั่วไปได้
รายงานการวิจัยของ Semrush ระบุว่าเมื่อความยาวเฉลี่ยของประโยคอยู่ที่ 12 ถึง 15 คำ ผู้ใช้จะมีประสิทธิภาพในการทำความเข้าใจสูงสุด
เมื่อ Meta Description ใช้ประโยคที่ยาวและยากเพียงประโยคเดียว (มากกว่า 25 คำ) และขาดการขับเคลื่อนด้วยคำกริยา เครื่องมือค้นหามีแนวโน้มที่จะดึงประโยคที่สั้นกว่าจากภายใต้ <h2> หรือ <h3> ของหน้าเว็บมาใช้แทน
การใช้สัญลักษณ์ที่ไม่ใช่ตัวอักษรมากเกินไป เช่น ดอกจัน (*), เส้นตั้ง (|), เครื่องหมายตกใจ (!) หรือเครื่องหมายเท่ากับ (=) เพื่อแยกคีย์เวิร์ด จะช่วยลดคะแนนภาษาธรรมชาติของข้อความ
API การประมวลผลภาษาธรรมชาติ (NLP) ของ Google จะกำหนดคะแนน “ความเชื่อมั่นทางไวยากรณ์” ให้กับข้อความแต่ละส่วน Meta Description ที่ประกอบด้วยวลีนามเพียงอย่างเดียวมักจะได้คะแนนต่ำกว่า 0.3 ในขณะที่ประโยคโครงสร้างมาตรฐาน “ประธาน-กริยา-กรรม” มักจะได้คะแนนสูงกว่า 0.85
ส่วนย่อยข้อความที่ต่ำกว่า 0.5 จะถูกทำด้วยเครื่องหมายโดยอัตโนมัติว่าเป็นเนื้อหาคุณภาพต่ำ และเสียโอกาสในการแสดงผลเป็นอันดับแรกใน SERP
ใน Meta Description มาตรฐาน 155 ตัวอักษร หากคีย์เวิร์ดทั้งหมดไปกระจุกตัวอยู่ที่ 20% แรกของตำแหน่ง หรือมีการซ้ำซ้อนอย่างไร้ความหมายที่ท้ายข้อความ ระบบจะระบุว่าเป็นการกระทำที่หลอกลวงอัลกอริทึมการจัดอันดับ
การวิเคราะห์ข้อมูลของ Backlinko แสดงให้เห็นว่าสัดส่วนของคำนามต่อคำกริยาในคำอธิบายที่เป็นธรรมชาตินักจะอยู่ที่ประมาณ 3:1
“The output of Google’s snippet generator is a balance between user query relevance and the linguistic integrity of the source text.” หลักการทางเทคนิคนี้บ่งบอกว่าการมีคำศัพท์ตรงกันเพียงอย่างเดียวไม่เพียงพอที่จะได้รับสิทธิ์ในการแสดงผล ในการวิเคราะห์ Word Embedding ต่อคลังคำภาษาอังกฤษ 1 ล้านคำ อัลกอริทึมสามารถระบุได้ว่าคำใดอยู่ในกลุ่มความหมายเดียวกัน ผู้ดูแลเว็บไม่จำเป็นต้องเขียนซ้ำๆ ว่า “Running Shoes”, “Shoes for Running” และ “Runner Footwear” เพราะอัลกอริทึมได้จัดประเภทนิพจน์เหล่านี้ให้อยู่ในเอนทิตีเดียวกันแล้ว การกล่าวถึงคำพ้องความหมายเหล่านี้ซ้ำๆ ใน Meta Description จะถือว่าเป็นการปรับแต่งที่มากเกินไป
จุดสนใจทางสายตาของผู้ใช้มือถือขณะเลื่อนหน้าจอมักจะหยุดอยู่ที่สองบรรทัดแรกของสรุปเนื้อหา
หากอัดคีย์เวิร์ดไว้ในครึ่งหลังของคำอธิบาย ผู้ใช้จะไม่สามารถรับรู้ถึงความเกี่ยวข้องของหน้าเว็บก่อนที่จะคลิก
การวิจัยพฤติกรรมการค้นหาบนมือถือในพื้นที่แคลิฟอร์เนียพบว่า การใช้คำกริยาเชิงรุก (เช่น Compare, Discover, Get) ใน 40 ตัวอักษรแรกของ Meta Description มีความถี่ในการโต้ตอบสูงกว่าคำอธิบายที่อัดคีย์เวิร์ดไว้ด้านหน้าถึง 12%
ปัญหาโค้ดทางเทคนิค
ข้อผิดพลาดทางเทคนิคจะทำให้เครื่องมือรวบรวมข้อมูลของ Google (Googlebot) ไม่สามารถดึง Meta Description ออกมาได้
สถิติแสดงให้เห็นว่าประมาณ 15% ของความผิดปกติในการแสดงผลสรุปเกิดจากข้อผิดพลาดของโครงสร้าง HTML Google กำหนดให้แท็ก Meta Description ต้องอยู่ภายใน 1MB แรกของเอกสาร HTML และแท็กต้องปิดอย่างสมบูรณ์
หากหน้าเว็บพึ่งพา JavaScript ในการแทรก Meta Description และเวลาในการเรียกใช้สคริปต์เกิน 5 วินาที Googlebot มักจะรวบรวมเนื้อหาที่ว่างเปล่าในซอร์สโค้ดแบบคงที่แทนที่จะเป็นข้อความหลังการเรนเดอร์
ตำแหน่งแท็ก
ตามตรรกะพื้นฐานของเอนจินการเรนเดอร์ Chromium ตัวแยกส่วน (Parser) จะสร้างต้นไม้ Document Object Model (DOM) เมื่อสแกน HTML
หากแท็ก <meta name="description"> ถูกวางไว้ในซอร์สโค้ด HTML เกินตำแหน่ง 1,024,000 ไบต์ (หรือ 1MB) แท็กนั้นจะถูกระบบจัดทำดัชนีของ Google ละเลย
ปรากฏการณ์นี้พบบ่อยในหน้าเว็บที่ใช้ CSS แบบอินไลน์หรือรูปภาพที่เข้ารหัส Base64 จำนวนมาก
เมื่อส่วนหัวของหน้าเว็บโหลดสไตล์ชีตแบบอินไลน์หลายพันบรรทัดหรือโค้ดกราฟิก SVG ที่ซับซ้อน แท็ก Meta Description จะถูกผลักไปยังพื้นที่ส่วนลึกของเอกสาร
เพื่อประหยัดโควตาการรวบรวมข้อมูลและทรัพยากรการคำนวณ โปรแกรมรวบรวมข้อมูลของ Google มักจะทำการสแกนข้อมูลเมตาอย่างละเอียดเฉพาะใน 1MB แรกของเนื้อหาเอกสารเท่านั้น
เมื่อเกินเกณฑ์นี้ ระบบจะหยุดค้นหาแอตทริบิวต์ใน <head> และเปลี่ยนเข้าสู่โหมดการรวบรวมข้อมูลทั่วไปของเนื้อหาหลักแทน ซึ่งทำให้ Meta Description ที่ตั้งไว้ไม่ปรากฏในหน้าผลการค้นหา
ในข้อกำหนด HTML แท็ก Meta Description จะต้องวางไว้ระหว่าง <head> และ </head> อย่างเคร่งครัด
หากมีแท็กที่ไม่ได้ปิดในโครงสร้างโค้ด เช่น แท็ก <script> ก่อน Meta Description ขาดเครื่องหมายปิด </script> หรือบล็อก <style> ปิดไม่ถูกต้อง ตัวแยกส่วนของ Googlebot จะเกิดความคลาดเคลื่อนในการแยกส่วน
ในกรณีนี้ ตัวแยกส่วนอาจคิดว่าส่วน <head> สิ้นสุดก่อนกำหนด และเข้าใจผิดว่า Meta Description ที่ตามมาเป็นส่วนหนึ่งของพื้นที่ <body>
เนื่องจากระบบจัดทำดัชนีของ Google ให้ค่าน้ำหนักต่ำมากหรือแม้แต่ละเลยแท็ก <meta> ภายใน <body> สิ่งนี้จึงนำไปสู่ความล้มเหลวในการดึงข้อมูลสรุป
การตรวจสอบข้อมูลแสดงให้เห็นว่าในไซต์ที่การตรวจสอบไวยากรณ์ HTML ล้มเหลว อัตราการสูญเสีย Meta Description จะสูงกว่าไซต์ที่เป็นไปตามมาตรฐานถึง 22%
| ตำแหน่งแท็กและสถานะโครงสร้าง | อัตราความสำเร็จในการระบุของ Googlebot | การวิเคราะห์สาเหตุทางเทคนิค |
|---|---|---|
ภายใน 100KB แรกของ <head> |
99.2% | อยู่ในโซนการรวบรวมข้อมูลที่มีลำดับความสำคัญสูงของตัวแยกส่วน แทบไม่ถูกรบกวนจากการรันสคริปต์ |
| อยู่หลัง CSS แบบอินไลน์จำนวนมาก (เกิน 1MB) | 12.5% | เกินเกณฑ์ความลึกในการสแกนข้อมูลเมตาเริ่มต้นของ Googlebot |
อยู่หลังตำแหน่งเริ่มต้นของแท็ก <body> |
5.8% | ละเมิดมาตรฐาน W3C ตัวแยกส่วนมองว่าเป็นส่วนย่อยข้อความธรรมดาแทนที่จะเป็นข้อมูลเมตา |
มีแท็กด้านบนที่ไม่ได้ปิด (เช่น <title>) |
0.4% | ทำให้โครงสร้างต้นไม้แยกส่วนพัง Meta Description ถูกมองว่าเป็นเนื้อหาย่อยของแท็กด้านบน |
อยู่ก่อน </html> ที่ตอนท้ายของเอกสาร |
0.1% | ปกติโปรแกรมรวบรวมข้อมูลจะดึงส่วนย่อยดัชนีเสร็จสิ้นก่อนจะถึงจุดนี้ |
ตำแหน่งการประกาศการเข้ารหัสตัวอักษรของเอกสาร (Charset Declaration) จะส่งผลต่อการแยกส่วนของ Meta Description เช่นกัน
ตามคำแนะนำของ Google <meta charset="utf-8"> ควรปรากฏใน 1,024 ไบต์แรกของเอกสาร
หากการประกาศการเข้ารหัสถูกวางไว้หลังแท็ก Meta Description ตัวแยกส่วนอาจยังไม่กำหนดรูปแบบการเข้ารหัสของหน้าเมื่ออ่าน Meta Description
สำหรับเนื้อหาคำอธิบายที่มีอักขระที่ไม่ใช่ ASCII (เช่น สัญลักษณ์พิเศษหรือตัวอักษรหลายภาษา) ลำดับที่ผิดพลาดนี้จะทำให้อักขระแสดงเป็นภาษาต่างดาว
เมื่ออัลกอริทึมของ Google ตรวจพบว่าเนื้อหา Meta Description มีอักขระภาษาต่างดาวที่ไม่สามารถแยกส่วนได้จำนวนมาก ระบบจะกรองแท็กนั้นออกโดยอัตโนมัติ และดึงข้อความธรรมดาที่อ่านง่ายกว่าจากหน้าเว็บมาใช้แทนที่
การเรนเดอร์ด้วย JavaScript
Google จัดการกับซอร์สโค้ดดั้งเดิมได้รวดเร็วมาก แต่ในการจัดการกับหน้าเว็บที่ต้องเรียกใช้สคริปต์ เวลาในการรอในคิวการเรนเดอร์อาจมีตั้งแต่ 24 ชั่วโมงถึง 14 วัน
หากหน้าเว็บใช้เฟรมเวิร์ก เช่น React, Vue หรือ Angular และเนื้อหา Meta Description ถูกโหลดแบบเรียลไทม์ผ่าน useEffect หรือ onMounted Googlebot จะพบเพียง <meta name="description" content=""> ที่ว่างเปล่าในเอกสาร HTML ที่รวบรวมในขั้นตอนแรก
ในเวลานี้ คลังดัชนีจะบันทึกค่าว่างนี้ไว้
แม้ว่าขั้นตอนการเรนเดอร์ภายหลังจะดึงข้อความสำเร็จ แต่เวลาที่หน้าผลการค้นหาจะอัปเดตการแสดงผลก็จะช้ากว่าหน้า HTML ปกติมากกว่า 3 เท่า
ตามเอกสารทางเทคนิคของเอนจินการเรนเดอร์ Chromium WRS จะจำลองสภาพแวดล้อมเบราว์เซอร์ Headless ของ Chrome เวอร์ชัน 120 ขึ้นไป และจัดสรรโควตาหน่วยความจำ 1,024MB สำหรับแต่ละคำขอการรวบรวมข้อมูล
หากแพ็กเกจ JavaScript ที่โหลดในหน้าเว็บมีขนาดรวมเกิน 5MB หรือกระบวนการเริ่มต้นสคริปต์เกี่ยวข้องกับคำขอ API ภายนอกมากกว่า 20 รายการ ตัวเรนเดอร์จะหยุดดำเนินการคำสั่งแก้ไข DOM ภายหลังเนื่องจากการใช้ทรัพยากรมากเกินไป
ในการทดสอบไซต์ 50,000 แห่ง หน้าเว็บที่มีระยะเวลาการเรียกใช้สคริปต์เกิน 5.5 วินาที จะมีความน่าจะเป็นที่ Meta Description จะถูกระบุอย่างถูกต้องลดลง 62%
เนื่องจากข้อจำกัดของกฎการจัดสรรงบประมาณการรวบรวมข้อมูลของ Google สำหรับไซต์ที่มีค่าน้ำหนักต่ำ หากตัวเรนเดอร์ไม่สามารถรับ Meta Description ในการเรียกใช้ครั้งแรก ระบบจะโน้มเอียงไปทางดึง 160 ตัวอักษรแรกจากแท็ก <p> แรกของเนื้อหาหน้าเว็บมาเป็นข้อมูลสรุป
| โซลูชันเทคโนโลยีการเรนเดอร์ | HTML เริ่มต้นมี Meta Description หรือไม่ | ความล่าช้าในการมีผลของดัชนี Google | ความเสี่ยงความล้มเหลวในการเรียกใช้ WRS |
|---|---|---|---|
| การเรนเดอร์ฝั่งไคลเอนต์ (CSR) | ไม่ (มีเพียงตัวสำรอง) | 2 วันถึง 14 วัน | สูง |
| การเรนเดอร์ฝั่งเซิร์ฟเวอร์ (SSR) | ใช่ (ข้อความครบถ้วน) | มีผลทันที | ต่ำ |
| การสร้างไซต์แบบคงที่ (SSG) | ใช่ (ข้อความครบถ้วน) | มีผลทันที | ไม่มี |
| SEO ระดับ Edge (Cloudflare/AWS) | ใช่ (แทรกผ่านคำขอ) | มีผลทันที | ต่ำ |
“Meta Description จะต้องอยู่ในสถานะพร้อมใช้งานในช่วงแรกของการแยกส่วน DOM เนื้อหาคำอธิบายใดๆ ที่อิงตามคำขอแบบอะซิงโครนัสแล้วค่อยกรอกข้อมูลในภายหลังจะมีความเสี่ยงที่จะถูกเครื่องมือรวบรวมข้อมูลละเลย”
ปรากฏการณ์ทางเทคนิคนี้พบได้ทั่วไปใน Single Page Applications (SPA)
เมื่อผู้ใช้คลิกการนำทางในเบราว์เซอร์ หน้าเว็บจะไม่โหลดใหม่ และ Meta Description จะถูกอัปเดตผ่าน history.pushState แต่สำหรับ Googlebot มันจะรวบรวมเฉพาะทางเข้าที่เป็นอิสระซึ่งตรงกับ URL นั้นๆ เท่านั้น
หากซอร์สโค้ดของทางเข้านั้นไม่มี Meta Description และพึ่งพาเพียงการสร้างแบบเรียลไทม์ทางฝั่งไคลเอนต์ด้วย JavaScript เครื่องมือค้นหาจะเกิดความคลาดเคลื่อนในการประเมินความเกี่ยวข้องของหน้าเว็บ ซึ่งจะส่งผลให้เนื้อหาสรุปไม่ตรงกับเนื้อหาจริงของหน้าเว็บ
ความขัดแย้งของ Robots
เมื่อ Googlebot จัดการกับหน้าเว็บ จะทำตามคำสั่ง robots ในซอร์สโค้ด HTML หรือ HTTP Response Header ก่อน
หากมีแท็กจำกัดเฉพาะเจาะจงในโค้ด แม้ว่านักพัฒนาจะเขียนเนื้อหาคุณภาพสูงใน <meta name="description"> หน้าผลลัพธ์การค้นหา (SERP) จะยังคงจัดการข้อมูลสรุปด้วยการบล็อกโดยสมบูรณ์หรือการบังคับตัดเนื้อหา
ความขัดแย้งนี้พบบ่อยที่สุดในการใช้แท็ก nosnippet
ตามข้อกำหนดในเอกสารอย่างเป็นทางการของ Google เมื่อ HTML ของหน้าประกอบด้วย <meta name="robots" content="nosnippet"> Google จะถูกสั่งห้ามแสดงคำอธิบายข้อความหรือตัวอย่างวิดีโอในรูปแบบใดๆ สำหรับหน้านั้น
ในการตรวจสอบโปรแกรมรวบรวมข้อมูลของไซต์ขนาดใหญ่ พบว่าประมาณ 2% ของหน้าเว็บยังคงคำสั่ง nosnippet จากสภาพแวดล้อมการทดสอบไว้โดยไม่ได้ตั้งใจในระหว่างการโอนย้ายเทมเพลต ส่งผลให้ในหน้าผลการค้นหาของสภาพแวดล้อมการผลิตแสดงเพียงหัวข้อและ URL เท่านั้น โดยสูญเสียข้อความคำอธิบายไปอย่างสิ้นเชิง
นอกเหนือจากคำสั่งที่ห้ามโดยสมบูรณ์แล้ว คำสั่ง max-snippet ยังอนุญาตให้นักพัฒนากำหนดความยาวตัวอักษรสูงสุดของข้อมูลสรุปในผลการค้นหาได้
หากโค้ดตั้งค่าเป็น <meta name="robots" content="max-snippet:50"> แต่ความยาว Meta Description ที่ตั้งไว้คือ 150 ตัวอักษร อัลกอริทึมของ Google ส่วนใหญ่จะมองว่า 50 ตัวอักษรไม่สามารถบรรจุข้อมูลได้เพียงพอ จึงเลือกที่จะไม่แสดงคำอธิบายนั้น หรือสุ่มเลือกประโยคสั้นๆ ภายในหน้าเว็บที่ตรงกับขีดจำกัดความยาว
เมื่อค่านี้ถูกตั้งเป็น 0 ผลทางเทคนิคจะเท่ากับ nosnippet
ตารางด้านล่างแสดงพารามิเตอร์คำสั่งที่พบบ่อยและผลกระทบเชิงปริมาณต่อการแสดงผล Meta Description:
| ชื่อคำสั่ง | ตัวอย่างโค้ดทั่วไป | ผลการจำกัดการแสดงผล Meta Description |
|---|---|---|
| nosnippet | content="nosnippet" |
บล็อก 100% ไม่แสดงสรุปข้อความใดๆ |
| max-snippet:0 | content="max-snippet:0" |
ผลเท่ากับ nosnippet ไม่แสดงผลเลย |
| max-snippet:[number] | content="max-snippet:60" |
แสดงเฉพาะจำนวนตัวอักษรที่กำหนด เนื้อหาที่ยาวเกินไปจะถูกทิ้ง |
| indexifembedded | content="noindex, indexifembedded" |
ข้อมูลสรุปอาจแสดงเฉพาะเมื่อหน้านั้นถูกฝังเป็น iframe ในที่อื่นเท่านั้น |
ความขัดแย้งเชิงขจัดในระดับเทคนิคไม่จำกัดเพียงแท็ก HTML เท่านั้น แต่ยังมักซ่อนอยู่ใน Header ของโปรโตคอล HTTP นั่นคือ X-Robots-Tag
เนื่องจากคำสั่งนี้ไม่ปรากฏในซอร์สโค้ด HTML นักเพัฒนาจึงไม่สามารถรับรู้ได้เมื่อ “ดูซอร์สโค้ดของหน้า” ผ่านเบราว์เซอร์
ในการกำหนดค่าเซิร์ฟเวอร์ Nginx หรือ Apache หากมีการตั้งค่า X-Robots-Tag: nosnippet ทั่วโลก ไฟล์ PDF รูปภาพ หรือหน้าไดนามิกทั้งหมดภายใต้เซิร์ฟเวอร์นั้นจะสูญเสียเนื้อหาคำอธิบายไป
หากต้องการตรวจสอบว่ามีคำสั่งที่ซ่อนอยู่ดังกล่าวหรือไม่ จำเป็นต้องใช้คำสั่ง curl -I [URL] เพื่อดูข้อมูล Header ที่เซิร์ฟเวอร์ส่งกลับมา
หาก Header มี X-Robots-Tag: noindex Googlebot จะไม่นำหน้านั้นเข้าสู่คลังดัชนีเลย และไม่สามารถดึงหรือแสดง Meta Description ได้โดยธรรมชาติ
ภายใต้มาตรฐาน HTML 5 นักพัฒนาสามารถเพิ่มแอตทริบิวต์นี้ลงในแท็ก <span>, <div> หรือ <section> เพื่อแจ้ง Google ไม่ให้ใช้เนื้อหาในส่วนนั้นสำหรับสรุปการค้นหา
หากเนื้อหาหลักของหน้าเว็บถูกทำเครื่องหมายด้วย data-nosnippet และพื้นที่ <head> ขาดแท็ก Meta Description ที่มีประสิทธิภาพ เอนจินการเรนเดอร์ของ Google จะพบว่าไม่มีเนื้อหาให้ใช้งานเมื่อพยายามดึงส่วนย่อยของหน้า (Fragment)
ความขัดแย้งทางตรรกะนี้จะทำให้ Google บังคับรวบรวมแถบนำทางของหน้า ข้อมูลลิขสิทธิ์ที่ส่วนท้ายของหน้า หรือข้อความที่ไม่เกี่ยวข้องอื่นๆ ที่ไม่ได้ถูกทำเครื่องหมาย มาใช้เป็นคำอธิบายแทนที่
- ความขัดแย้งของการซ้อนทับหลายคำสั่ง: เมื่อมีทั้ง
indexและnosnippetในหน้าพร้อมกัน Google จะใช้ “หลักการที่เข้มงวดที่สุด” โดยให้ความสำคัญกับnosnippetก่อน - ข้อจำกัดการตั้งค่าเริ่มต้นของปลั๊กอิน CMS: ในไซต์ Shopify หรือ WordPress ปลั๊กอินความปลอดภัยบางตัวจะแทรก
nosnippetหรือnoarchiveในหน้าที่ไม่ใช่มาตรฐาน (เช่น หน้าผลการค้นหา หน้าแท็ก) โดยอัตโนมัติเพื่อป้องกันไม่ให้เนื้อหาถูกรวบรวมข้อมูล ซึ่งจะเขียนทับคำอธิบายที่ป้อนด้วยตนเองในปลั๊กอิน SEO - ผลกระทบของคำสั่งแคชหมดอายุ: คำสั่ง
unavailable_afterจะกำหนดประทับเวลาที่เจาะจง หากเวลาปัจจุบันเกินค่าที่กำหนด (เช่นunavailable_after: 2025-12-31) Google จะหยุดแสดงข้อมูลสรุปใดๆ ของหน้านั้นใน SERP
ในสถาปัตยกรรมไซต์ข้ามชาติที่ซับซ้อนบางแห่ง ผู้ให้บริการ CDN (เช่น Cloudflare หรือ Akamai) อาจแก้ไข Response Header หรือแทรก HTML แบบไดนามิกผ่านสคริปต์ Workers ที่โหนดปลายทาง (Edge Node)
หากมีการเพิ่มคำสั่งจำกัด robots ในระดับ CDN ไม่ว่าโค้ดดั้งเดิมของเซิร์ฟเวอร์แบ็กเอนด์จะสมบูรณ์แบบเพียงใด ข้อมูลสุดท้ายที่ส่งไปยัง Googlebot จะมีเครื่องหมาย “ห้ามแสดงข้อมูลสรุป”
ทีมเทคนิคควรใช้เครื่องมือ “ตรวจสอบ URL” ของ Google Search Console เป็นประจำ และตรวจสอบเนื้อหาการตอบสนอง HTTP ภายใต้แท็บ “URL ที่ร้องขอ” เพื่อให้แน่ใจว่าไม่มีคำสั่งเชิงลบที่มีคีย์เวิร์ด snippet
Google คิดว่าการสร้างอัตโนมัติของเขานั้นดีกว่า
จากการวิเคราะห์ข้อมูล 192,000 หน้าโดย Ahrefs เมื่อคำค้นหาของผู้ใช้ไม่ได้อยู่ใน Meta Description อัตราการเขียนใหม่ของ Google สูงถึง 82.7%
แม้ว่าคำอธิบายจะมีคีย์เวิร์ดอยู่ แต่อัตราการเขียนใหม่ก็ยังคงอยู่ที่ 59.7% Google มีแนวโน้มที่จะใช้โมเดลภาษา BERT เพื่อดึงส่วนย่อยประมาณ 160 ตัวอักษรจากเนื้อหาหน้าเว็บแบบเรียลไทม์ เพื่อให้แน่ใจว่าคีย์เวิร์ดตัวหนาปรากฏในผลการค้นหา
วิธีนี้สามารถเพิ่มอัตราการคลิก (CTR) ของผลการค้นหาได้ 5% ถึง 10% ตามหลักสถิติ เพราะเป็นการให้ข้อมูลตอบกลับตามเจตนาการค้นหาผ่านคำที่ทำตัวหนา
การเขียนใหม่โดยอัลกอริทึม
เมื่อหน้าเว็บเข้าสู่คลังดัชนีแล้ว อัลกอริทึมจะไม่กำหนดรูปแบบการแสดงผล Meta Description อย่างถาวร
หากข้อความคำอธิบายที่ตั้งไว้ขาดจุดร่วมทางอรรถศาสตร์กับคำค้นหาที่ผู้ใช้ป้อน อัลกอริทึมจะดึงข้อความประมาณ 160 ตัวอักษรจากเนื้อหาหลัก
พฤติกรรมการดึงข้อมูลนี้มักเกิดขึ้นเมื่อคำค้นหาปรากฏในช่วงตัวอักษรที่ 200 ถึง 500 ของเนื้อหาหลัก แต่ใน Meta Description กลับไม่มีการกล่าวถึงคำนั้นเลย
เนื่องจากเป้าหมายของอัลกอริทึมคือการเพิ่มประสิทธิภาพการคลิกของผลการค้นหาให้สูงสุด อัลกอริทึมจะเลือกส่วนย่อยข้อความที่มีคีย์เวิร์ดตัวหนาก่อน
| การจำแนกสถานการณ์การกระตุ้น | สถิติความน่าจะเป็นในการเขียนใหม่ | คำอธิบายตรรกะการตัดสินของอัลกอริทึม |
|---|---|---|
| ขาดคำค้นหา | 82.7% | Meta Description ไม่มีคำค้นหาที่ผู้ใช้ป้อน ระบบจึงหันไปหาคู่ที่ตรงกันในเนื้อหาหลักแทน |
| คำอธิบายยาว/สั้นเกินไป | 65.4% | ความยาวเกิน 960 พิกเซลหรือสั้นกว่า 50 ตัวอักษร ถูกตัดสินว่ามีประสิทธิภาพการสื่อสารต่ำ |
| ความซ้ำซ้อนของเนื้อหา | 71.0% | หลาย URL ใช้เทมเพลตคำอธิบายเดียวกัน อัลกอริทึมจะละเลยแท็กนั้นและดึงเนื้อหาที่เป็นเอกลักษณ์เอง |
| ความหมายไม่ตรงกัน | 58.2% | เนื้อหาคำอธิบายเป็นสโลแกนส่งเสริมแบรนด์ ในขณะที่คำค้นหาคือการค้นหาพารามิเตอร์ทางเทคนิคเฉพาะ |
พื้นที่การแสดงผลของเบราว์เซอร์บนเดสก์ท็อปมักจำกัดอยู่ภายใน 920 พิกเซล ส่วนอุปกรณ์เคลื่อนที่ลดลงเหลือประมาณ 600 พิกเซล
หากความยาวของ Meta Description ถึง 1,000 พิกเซล ระบบการแสดงผลส่วนหน้าของ Google จะพยายามตัดเนื้อหาก่อน แต่ถ้าประโยคหลังการตัดมีความหมายที่แตกแยก อัลกอริทึมการสร้างข้อมูลสรุปส่วนหลังจะตัดสินว่า Meta Description นั้นเป็น “เอาต์พุตคุณภาพต่ำ”
ในเวลานี้ ระบบจะเรียกใช้เนื้อหาแท็ก <h1> หรือ <p> ภายในหน้าเพื่อค้นหาประโยคที่สามารถสื่อความหมายได้ครบถ้วนภายในพิกเซลที่จำกัดมาแทนที่
| ประเภทการค้นหา | แนวโน้มการเขียนใหม่ | แหล่งที่มาของการแทนที่ทั่วไป |
|---|---|---|
| การค้นหาข้อมูล | สูง | ย่อหน้าคำจำกัดความที่ด้านบนของหน้าหรือรายการ FAQ |
| การค้นหานำทาง | ต่ำ | มักจะคงคำอธิบายที่ตั้งไว้ โดยเฉพาะเมื่อมีชื่อแบรนด์ |
| การค้นหาเชิงธุรกรรม | กลาง | ส่วนย่อยเนื้อหาหลักที่มีราคา ข้อมูลจำเพาะ หรือคำว่า “จัดส่งฟรี” |
| การค้นหาแบบ Long-tail | สูงมาก | ประโยคแรกภายใต้หัวข้อ H2 ที่ตรงกับคำ Long-tail เฉพาะ |
สำหรับ URL เดียวกัน Google อาจสร้างสรุปข้อมูลที่แตกต่างกันนับร้อยแบบ
ตัวอย่างเช่น เมื่อหน้าเว็บเกี่ยวกับ “คู่มือการเลือกซื้อบริการคลาวด์” ติดอันดับภายใต้คำที่มีเจตนาต่างกันสองคำคือ “การเปรียบเทียบราคาบริการคลาวด์” และ “การทดสอบความปลอดภัยบริการคลาวด์” Meta Description แบบคงที่จึงยากที่จะครอบคลุมทั้งสองมิตินี้พร้อมกัน
กลไกการเขียนใหม่แบบไดนามิกของ Google จะวิเคราะห์โครงสร้างเนื้อหาของหน้า หากพบว่าในหน้ามีตารางที่แสดงราคาอย่างละเอียด อัลกอริทึมจะดึงข้อความใกล้ตารางมาเป็นข้อมูลสรุปโดยอัตโนมัติเมื่อผู้ใช้ค้นหาคำว่า “ราคา”
หากเนื้อหาหลักของหน้าเว็บขาดโครงสร้างย่อหน้าที่ชัดเจนตามตรรกะ อัลกอริทึมอาจดึงเมนูนำทาง ข้อความที่ส่วนท้ายของหน้า หรือลิงก์แถบข้าง ซึ่งจะทำให้เกิดสรุปการค้นหาที่ไม่มีตรรกะ ซึ่งมักเกิดจากการที่หน้าเว็บขาดความหนาแน่นของข้อความเนื้อหาหลักที่มีประสิทธิภาพ
ในการจัดการหน้าเว็บที่มีข้อมูลจำเพาะทางเทคนิคหรือคุณลักษณะผลิตภัณฑ์จำนวนมาก หากหน้าเว็บใช้มาร์กอัป Schema ของ Product หรือ Review แต่ Meta Description ไม่ได้แสดงคุณลักษณะสำคัญเหล่านี้ Google มักจะเขียนคำอธิบายใหม่เพื่อให้มีคะแนน ราคา หรือสถานะสินค้าคงคลัง
หาก Meta Description เป็นเพียง “ดูคอลเลกชันรองเท้ากีฬาล่าสุดของเรา” แต่ในเนื้อหาหลักมีข้อมูลเฉพาะ เช่น “คะแนนความทนทาน 9.5” หรือ “น้ำหนัก 250 กรัม” อัลกอริทึมจะตัดสินว่าข้อมูลหลังมีคุณค่าในการอ้างอิงสำหรับผู้ใช้มากกว่า
เพื่อรักษาการแสดงผลของคำอธิบายที่ตั้งไว้ จะต้องตรวจสอบให้แน่ใจว่าความหนาแน่นของข้อมูลในคำอธิบายไม่ต่ำกว่าระดับเฉลี่ยของ 300 ตัวอักษรแรกในเนื้อหาหลัก
การลดโอกาสถูกเขียนใหม่
หาก Meta Description ที่ตั้งไว้ไม่มีคำค้นหาที่ติดอันดับสามอันดับแรกของหน้า ความน่าจะเป็นที่ Google จะเขียนใหม่โดยอัตโนมัติจะเพิ่มสูงขึ้นเป็นมากกว่า 80%
เพื่อลดการแทรกแซงนี้ ควรนำคำที่มีความถี่สูงที่ส่งออกจาก GSC มาใส่ไว้ใน 65 ตัวอักษรแรกของคำอธิบายอย่างเป็นธรรมชาติ
ในการดำเนินการจริง จำเป็นต้องรักษาความสอดคล้องทางอรรถศาสตร์ระดับสูงระหว่างเนื้อหาคำอธิบายกับแท็ก H1 ของหน้าและย่อหน้าแรกของเนื้อหาหลัก
ในการเขียนควรหลีกเลี่ยงการใช้คำโฆษณาที่กำกวม และหันมาใช้ประโยคบอกเล่าที่มีพารามิเตอร์เฉพาะ ชื่อแบรนด์ หรือคำสั่งการดำเนินการที่ชัดเจนแทน
- การควบคุมตัวอักษรและพิกเซลอย่างแม่นยำ: ขีดจำกัดความกว้างของการแสดงผลลัพธ์การค้นหาบนเดสก์ท็อปอยู่ที่ประมาณ 920 ถึง 960 พิกเซล และบนมือถืออยู่ที่ระหว่าง 600 ถึง 680 พิกเซล เนื่องจากอักขระที่ต่างกันใช้พิกเซลต่างกัน การนับเพียงจำนวนตัวอักษรจึงไม่แม่นยำ แนะนำให้ใช้เครื่องมือตรวจสอบพิกเซลเพื่อให้แน่ใจว่าคำอธิบายสิ้นสุดภายใน 920 พิกเซล เพื่อป้องกันข้อมูลไม่ครบถ้วนจากการถูกตัดที่ตอนท้าย เพราะประโยคที่ไม่สมบูรณ์มักถูกอัลกอริทึมตัดสินว่าเป็นการแสดงผลคุณภาพต่ำ ซึ่งจะกระตุ้นการเขียนใหม่โดยอัตโนมัติ
- กำจัดเนื้อหาเทมเพลตที่ซ้ำซาก: เมื่อจัดการกับเว็บไซต์อีคอมเมิร์ซขนาดใหญ่ที่มีหน้าเว็บหลายพันหน้า ให้หลีกเลี่ยงการใช้เทมเพลต Meta Description ชุดเดียวกันทั้งไซต์ หากคำอธิบายของ URL จำนวนมากมีความแตกต่างกันเพียงเล็กน้อย เครื่องมือรวบรวมข้อมูลของ Google จะละเลยแท็กเหล่านี้ โดยมองว่าขาดความเฉพาะเจาะจง แนะนำให้เขียนคำอธิบายที่เป็นเอกลักษณ์ด้วยตนเองสำหรับหน้าที่มีทราฟฟิกสูง ส่วนหน้าแบบ Long-tail ควรตรวจสอบให้แน่ใจว่าส่วนย่อยที่สร้างโดยโปรแกรมมีความแตกต่างที่ระบุได้เพียงพอ
- การเลือกคำกริยาที่ตรงกับเจตนาการค้นหา: สำหรับการค้นหาข้อมูล (Informational Queries) ควรใช้คำนำหน้าคำอธิบาย เช่น “เรียนรู้”, “เปรียบเทียบ” หรือ “ค้นพบ” ส่วนการค้นหาเชิงธุรกรรม (Transactional Queries) ควรมีคำเฉพาะ เช่น “ซื้อ”, “ดาวน์โหลด” หรือ “ราคา” การปรับโทนของคำอธิบายให้เข้ากับสไตล์ของผลลัพธ์อันดับต้นๆ อื่นๆ ใน SERP จะช่วยรักษาอัตราการคงอยู่ของคำอธิบายได้อย่างมีประสิทธิภาพ
ในการตรวจสอบ SEO จริง พบว่าหลายไซต์แม้จะมีการตั้งค่า Meta Description แต่เนื้อหากลับมีความคลาดเคลื่อนจากหัวข้อหลักที่หน้าเว็บกำลังสนทนาอยู่
ตัวอย่างเช่น หน้าเว็บเกี่ยวกับ “รองเท้าวิ่งที่ดีที่สุด” แต่ Meta Description กลับกำลังพูดถึงประวัติของแบรนด์ ความแตกแยกทางอรรถศาสตร์นี้จะนำไปสู่การแทรกแซงของอัลกอริทึม
การออกแบบ Meta Description ให้เป็นสรุปเนื้อหาหน้าเว็บที่แม่นยำ และมีคำ Long-tail 2 ถึง 3 คำ จะสามารถเพิ่มความถี่ในการแสดงผลในผลการค้นหาได้อย่างมาก
ควรระวังการหลีกเลี่ยงอักขระพิเศษใน HTML สัญลักษณ์บางอย่างที่ไม่ได้ทำ Escape อาจทำให้เกิดข้อผิดพลาดในการแยกส่วน ทำให้ Google ไม่สามารถอ่าน Meta Description ที่สมบูรณ์ได้ และเลือกที่จะดึงส่วนย่อยสุ่มจากย่อหน้าข้อความแทน
- ตรรกะการเพิ่มประสิทธิภาพที่ขับเคลื่อนด้วยข้อมูล: ตรวจสอบความผันผวนของ CTR ใน GSC เป็นประจำ หากอันดับเฉลี่ยของหน้าไม่เปลี่ยนแต่ CTR ลดลงมากกว่า 3% จำเป็นต้องตรวจสอบว่าข้อมูลสรุปใน SERP ถูกเขียนใหม่หรือไม่ หากพบว่าเนื้อหาที่เขียนใหม่ส่วนมาจากส่วน FAQ ของหน้า แสดงว่า Meta Description เดิมไม่ครอบคลุมคำถามของผู้ใช้ ในเวลานี้ควรปรับโครงสร้างตรรกะของ Meta Description ใหม่โดยอ้างอิงจากส่วนย่อยที่ถูกเขียนใหม่
- การกระจายน้ำหนักทางอรรถศาสตร์: วางข้อมูลที่สำคัญที่สุดไว้ที่ส่วนหน้าสุดของประโยค การวิจัยแสดงให้เห็นว่าเครื่องมือรวบรวมข้อมูลของ Google ให้ความสำคัญกับส่วนเริ่มต้นของ Meta Description สูงกว่าส่วนท้ายมาก 50 ตัวอักษรแรกควรสามารถแสดงคุณค่าหลักของหน้าเว็บได้อย่างเป็นอิสระ
- หลีกเลี่ยงการใช้เครื่องหมายวรรคตอนมากเกินไป: เครื่องหมายตกใจที่มากเกินไปหรือเครื่องหมายจุดไข่ปลาที่ต่อเนื่องกันจะลดระดับความเป็นมืออาชีพของคำอธิบาย และอัลกอริทึมจะมีแนวโน้มที่จะบล็อกเนื้อหาที่มีลักษณะเป็นสแปมประเภทนี้ รักษาโครงสร้างประโยคให้เรียบง่าย เป็นกลาง และสอดคล้องกับมาตรฐานการแสดงออกของข้อมูลเชิงวิชาการหรือวิชาชีพ
เมื่อจัดการกับข้อมูลโครงสร้าง (Schema Markup) หากหน้าเว็บใช้สถาปัตยกรรม FAQ หรือ Product Meta Description ควรทำหน้าที่เชื่อมโยงและแจ้งล่วงหน้า แทนที่จะซ้ำกับข้อมูลเหล่านั้นโดยสิ้นเชิง
สำหรับหน้าเว็บที่มีข้อมูลจำเพาะทางเทคนิคจำนวนมาก ให้พยายามใส่ข้อมูลตัวเลขเฉพาะในคำอธิบาย เช่น “น้ำหนักเพียง 1.2 กก.” หรือ “รองรับความละเอียด 4K”


