




















يستغرق تحديث فهرس Google عادةً ما بين 3-10 أيام.
على الرغم من حذف الصفحة، قد تظل النسخة المخبأة (Cache) موجودة. يُنصح بتقديم طلب “إزالة URL” عبر Google Search Console، حيث يمكن أن يدخل حيز التنفيذ في غضون 24 ساعة كأسرع تقدير. هذه هي الطريقة الأكثر احترافية وكفاءة لتنظيف النتائج المتبقية.
تأخر الزحف (Crawling Lag)
يحدد Googlebot تكرار الزيارات بناءً على مقاييس PageRank وميزانية الزحف (Crawl Budget).
بالنسبة لمعظم الصفحات التي لا تقع في الصفحة الأولى، يتراوح متوسط دورة زيارة Googlebot بين 3 إلى 30 يومًا.
تظهر تقارير إحصائيات الزحف في Google Search Console (GSC) أنه بعد إرجاع الخادم لرمز الحالة 404، لا يتم حذف الفهرس على الفور.
يحتاج النظام إلى ما بين 1 إلى 3 عمليات زحف متكررة للتأكد من أن الصفحة لا يمكن الوصول إليها ليس بسبب عطل مؤقت في الخادم.
في المواقع الكبيرة، تتراوح نسبة التأخر في المزامنة بين قاعدة بيانات الفهرس والخادم المباشر عادةً بين 15% إلى 20%، مما يؤدي إلى بقاء الصفحات المحذوفة في النتائج.
التحقق من رمز 404
عندما يزور Googlebot رابط URL معين ويتلقى استجابة 404 Not Found، فإن منطق الجدولة داخل نظام البحث لا يزيل هذا الإدخال من قاعدة بيانات الفهرس فورًا.
وفقًا للسجلات الأساسية لآلية زحف محرك البحث، يُنظر عادةً إلى الكشف الأولي عن إشارة 404 على أنه “اهتزاز محتمل في الخادم” أو “انقطاع مؤقت في الاتصال بالشبكة”.
لضمان استقرار نتائج البحث، يقوم نظام جدولة Google بتمييز عنوان URL هذا بـ “حالة إعادة المحاولة” ويدفعه إلى طابور مراقبة متخصص.
بالنسبة لموقع متوسط الحجم يبلغ معدل زياراته اليومية حوالي 10,000 عملية زحف، يقوم Googlebot عادةً بإجراء مراجعة ثانية في غضون 24 إلى 48 ساعة من الاكتشاف الأول لرمز 404.
إذا استمرت عملية الزحف الثانية في إرجاع رمز الحالة 404، فسيقوم النظام بخفض أولوية الزحف (Crawl Priority) لهذه الصفحة إلى أدنى مستوياتها، ولكن يظل سجل الفهرس محفوظًا.
يوجد داخل Google عداد منطقي يسمى “عتبة التأكيد”، وعادةً ما يتطلب الأمر ما بين 3 إلى 5 تأكيدات متتالية لرمز 404، تغطي فترة زمنية لا تقل عن 7 إلى 14 يومًا، قبل أن يصدر النظام أمر حذف رسمي لقطع الفهرس (Index Shards).
إذا استخدم مدير الموقع رمز الحالة 410 Gone، فإن سرعة الدخول في عملية الحذف تكون أسرع بنسبة تتراوح بين 25% إلى 40% مقارنة بصفحة 404.
بعد تلقي إشارة 410، غالبًا ما يتخطى Googlebot جزءًا من دورة المراجعة ويزيله من طابور الزحف الرئيسي.
ومع ذلك، لمنع التلاعب الضار أو الأخطاء التشغيلية، لا يزال النظام يحتفظ بفترة تهدئة مدتها 24 ساعة لضمان استقرار رمز الحالة.
عامل طويل المدى آخر يؤدي إلى بقاء النتائج هو تأخير تحديد Soft 404 (404 ناعم).
إذا تم تكوين الخادم بشكل خاطئ واستمر في إرجاع رمز الحالة 200 OK عندما تكون الصفحة غير موجودة، ولكن محتوى الصفحة يعرض نصًا يفيد بـ “تعذر العثور على الصفحة”، فيجب هنا تدخل خدمة عرض الويب من Google (WRS).
تحتاج خدمة WRS إلى استهلاك موارد حوسبة كبيرة لتحليل شجرة DOM واستخدام نماذج التعلم الآلي للحكم على السمات الدلالية للصفحة.
بمجرد تحديدها كـ Soft 404، يتم إخراج هذه الصفحة من مسار الفهرس العادي، ولكن هذه العملية أبطأ من التحقق القياسي لـ 404 بمقدار 5 إلى 10 أيام عمل.
في بنية التخزين الموزعة، تختلف سرعة المزامنة عبر مراكز البيانات العالمية.
حتى لو أكد الفهرس الرئيسي في المقر الرئيسي بالولايات المتحدة حذف سجل معين، فقد لا يزال المستخدمون في لندن أو فرانكفورت قادرين على العثور على المحتوى المحذوف لمدة تتراوح بين 6 إلى 12 ساعة بسبب اختلاف سياسات تحديث ذاكرة التخزين المؤقت في العقد الطرفية (Edge Nodes) العالمية.
عندما تستنفد ميزانية الزحف (Crawl Budget) لموقع ما، قد يتوقف Googlebot مؤقتًا عن مراجعة روابط 404 المعروفة للتركيز على زحف محتوى جديد ذو ثقل أكبر.
يؤدي هذا التوزيع للأولويات إلى بقاء الصفحات القديمة الموجودة في عمق الأدلة (والتي يتجاوز عمق روابطها 5 مستويات) لعدة أشهر في نتائج البحث، حتى لو كانت تعيد رمز 404 منذ فترة طويلة.
“Googlebot ليس مراقبًا في الوقت الفعلي، بل هو نظام جدولة يعتمد على الاحتمالات والأوزان؛ فكل تأكيد لإشارة 404 يتطلب استهلاكًا فعليًا لنطاق الشبكة وتكاليف الحوسبة.”
عند هجرة المواقع الكبيرة أو تغيير المسارات على نطاق واسع، إذا تجاوزت نسبة أخطاء 404 ما قيمته 20% في وقت قصير، فقد يقوم النظام بتفعيل آلية حماية.
في هذه الحالة، ستطول عملية التحقق العادية لـ 404، وستتطلب الخوارزمية مزيدًا من “وقت الإثبات” للتأكد من أن عمليات الحذف هذه هي النية الحقيقية لمدير الموقع.
المعلمات المؤثرة
عندما يقوم Googlebot بمهام الزحف على الإنترنت، فإن سرعة إعادة زيارته لروابط URL القديمة أو اكتشاف رموز حالة جديدة ليست عشوائية، والمعلمة الأكثر أساسية في ذلك هي تأخير استجابة الخادم (Server Latency)، وتحديدًا وقت الوصول لأول بايت (TTFB).
إذا ظل TTFB للخادم لفترة طويلة أقل من 200 مللي ثانية، فسيعتبر Googlebot أن الخادم لديه قدرة استيعابية كافية، وبالتالي سيرفع الحد الأقصى للزحف.
وعلى العكس، بمجرد أن يتجاوز وقت الاستجابة 1000 مللي ثانية، سيقوم الزاحف تلقائيًا بتفعيل آلية تقييد معدل الزحف (Crawl Rate Limit) لحماية الخادم المستهدف من الانهيار بسبب الزيارات عالية التكرار.
على مستوى بنية الموقع، يعد عمق الروابط (Link Depth) هو الميزان المادي لضبط تكرار الزحف.
عناوين URL الموجودة في الدليل الجذر أو التي تبعد 1 إلى 2 نقرة فقط عن الصفحة الرئيسية تحصل على أعلى وزن في PageRank، وتظهر سجلات وصول Googlebot أن تكرار فحص التحديث لهذه الصفحات عادةً ما يكون مرة كل 24 ساعة.
ومع ذلك، عندما تكون الصفحة في المستوى الخامس أو أعمق في بنية الأدلة، فإنه حتى لو تغير محتواها إلى حالة 404، فإن دورة إعادة زيارة الزاحف ستطول بشكل كبير، وأحيانًا تتطلب 30 إلى 60 يومًا لإجراء مراجعة روتينية واحدة.
- طلب الزحف (Crawl Demand): يعتمد هذا على مدى شعبية الصفحة. إذا كان الرابط المحذوف لا يزال يحتوي على عدد كبير من الروابط الخلفية (Backlinks) الواردة من الخارج، أو يتم ذكره بشكل متكرر على منصات التواصل الاجتماعي، فستعتبر خوارزمية Google أن هذا المورد لا يزال ذا قيمة تداولية. حتى لو أعاد رمز 404، ستقوم الخوارزمية بجدولة الزاحف لزيارته بشكل متكرر لتأكيد حالته، وهذا التقييم عالي التكرار يؤدي إلى مزيد من دورات التحقق قبل أن يؤكد النظام “الاختفاء الدائم”.
- صحة الموقع (Site Health): إذا كان الخادم يظهر أخطاء من فئة 5xx بشكل متكرر (مثل 503 Service Unavailable)، فسيقوم Googlebot بسرعة بخفض ميزانية الزحف الإجمالية (Crawl Budget) للموقع. عندما تتجاوز نسبة الخطأ 10% من إجمالي الزحف، يدخل الزاحف في وضع الحماية ويتوقف عن فحص عناوين URL غير الضرورية. في هذه الحالة، ستظل صفحات 404 التي كان يجب تنظيفها عالقة في الفهرس لفترة طويلة بسبب تجميد ميزانية الزحف.
- تكرار تحديث المحتوى (Change Frequency): يسجل محرك البحث تاريخ التغييرات لرابط URL خلال الأشهر الماضية. إذا لم يتم تحديث صفحة ما خلال 365 يومًا الماضية، فسيقوم Googlebot بتمييزها كـ “بيانات باردة” (Cold Data)، وسيتم خفض وزن إعادة الزيارة إلى أدنى مستوياته. عندما تحذف فجأة صفحة غير نشطة لفترة طويلة، قد لا يمر الزاحف عبر هذا المسار بشكل نشط خلال الربع القادم، مما يسبب تأخيرًا مرئيًا في الحذف.
خريطة الموقع (Sitemap) هي ملف توجيهي وليست أمرًا إلزاميًا، ولكن دقة علامة <lastmod> فيها تؤثر على كفاءة زحف الزاحف.
إذا كانت خريطة الموقع لا تزال تحتفظ بروابط تعيد رمز 404، أو إذا لم يتم تحديث الطابع الزمني لـ lastmod وفقًا لإجراء حذف الصفحة، فقد يعتبر Googlebot أن الملف غير موثوق به، وينتقل إلى وضع الفحص الذاتي منخفض الكفاءة.
في التجارب التي أجريت على مواقع إخبارية أمريكية كبيرة، تبين أن تقديم Sitemap يحتوي على أحدث تواريخ lastmod لـ Google، مع استخدام بروتوكول WebSub (المعروف سابقًا بـ PubSubHubbub) للدفع النشط، يمكن أن يقلل الوقت الذي يستغرقه الزاحف لإدراك تغييرات الصفحة بنسبة تتجاوز 70%.
تدعم المواقع التي تستخدم بروتوكولات HTTP/2 أو HTTP/3 (QUIC) تعدد الإرسال (Multiplexing)، حيث يمكن لـ Googlebot طلب حالة عشرات الروابط بشكل متزامن في نفس اتصال TCP.
بالمقارنة، يقتصر بروتوكول HTTP/1.1 التقليدي بعدد الاتصالات، مما يضطر الزاحف للانتظار في طابور عند التعامل مع الآلاف من إشارات 404.
“في أنظمة الزحف الموزعة، يتم احتساب تكلفة كل عملية زحف لرابط URL؛ وغالبًا ما تأتي روابط 404 منخفضة الوزن في نهاية طابور الزحف، ما لم تكن هناك إشارة خارجية ترفع أولويتها قسرًا.”
بما أن Google قد انتقل بالكامل إلى الفهرسة الأولية للأجهزة المحمولة (Mobile-First Indexing)، فإن نشاط زواحف الأجهزة المحمولة عادة ما يكون أعلى بمرتين إلى 3 مرات من زواحف الأجهزة المكتبية.
إذا تم حذف نسخة الهاتف المحمول من الصفحة ولكن نسخة المكتب لا تزال تعيد رمز 200 بسبب خطأ في التكوين، أو العكس، فإن هذا التضارب سيؤدي إلى صراع منطقي في نظام الفهرسة، مما يجعل نتائج البحث تظهر معلومات قديمة ومتبقية بشكل مختلف تمامًا على الأجهزة المختلفة.
ذاكرة التخزين المؤقت للويب (Cache)
ذاكرة التخزين المؤقت للويب هي عبارة عن نسخة طبق الأصل من كود HTML وبعض الموارد الثابتة للصفحة التي يقوم Googlebot بتخزينها في خوادم Google الموزعة عالميًا (مثل مراكز بيانات Google) أثناء عملية الزحف.
حتى لو قام الخادم الأصلي بحذف الصفحة فعليًا، ستظل قاعدة بيانات فهرس Google تحتفظ بهذه اللقطة حتى دورة تحديث الزحف التالية.
عادةً ما يتم احتساب تكرار الزحف للمواقع ذات الثقل العالي بالساعات، بينما قد تحتاج المواقع العادية إلى ما بين 3 إلى 28 يومًا.
نظرًا لأن Google يستخدم عقد الحوسبة الطرفية لمزامنة البيانات، فغالبًا ما يكون هناك تأخير يتراوح بين 24 إلى 72 ساعة بين تحديث الفهرس الرئيسي ومزامنة نتائج البحث في مختلف مناطق العالم.
أسباب الظهور
تدير Google قاعدة بيانات موزعة ضخمة تحتوي على مئات المليارات من صفحات الويب، وتسمى هذه القاعدة بالفهرس (Index).
عندما تقوم بحذف صفحة عبر نظام إدارة المحتوى الخاص بك (مثل WordPress أو Ghost)، فأنت تزيل البيانات فقط من خادم الويب الخاص بك.
في هذه اللحظة، لا تزال مجموعات خوادم Google تحتفظ بآخر سجل لقطة (Snapshot) لعنوان URL هذا.
- توزيع مستويات دورة زحف Googlebot: يقوم Google بتخصيص حصص زحف (Crawl Budget) مختلفة بناءً على سلطة النطاق (Domain Authority) وتكرار التحديث.
- أعلى 1% من المواقع الإخبارية ذات الحركة المرورية العالية (مثل The New York Times أو Reuters) يتم إعادة زحف صفحاتها الشائعة بمعدل دقائق أو ساعات.
- تتراوح دورة زحف المواقع التجارية العادية أو المدونات الشخصية عادةً بين 7 أيام إلى 28 يومًا، وقد تصل فترات إعادة الزحف لبعض المسارات غير الشائعة إلى عدة أشهر.
- إذا تم حذف صفحة في 1 يناير، وكان Googlebot يخطط لإعادة زيارة هذا المسار في 25 يناير فقط، فخلال هذا الفارق الزمني البالغ 24 يومًا، ستعرض نتائج البحث دائمًا المحتوى الذي لم يعد موجودًا.
يستخدم نظام فهرسة “Caffeine” الداخلي في Google آلية تحديث في الوقت الفعلي، لكنها تستهدف بشكل أساسي اكتشاف المحتوى الجديد.
عندما يزور Googlebot عنوان URL محذوفًا، فإن رمز حالة HTTP الذي يعيده الخادم يحدد سرعة إزالة الفهرس.
إذا أعاد الخادم رمز 404 (Not Found)، فعادةً لا يقوم Googlebot بإزالة الصفحة من الفهرس على الفور، لأن الخوارزمية تأخذ في الاعتبار احتمال وجود عطل مؤقت في الخادم أو خطأ في التكوين.
يسجل النظام هذا الفشل ويجدول محاولة ثانية في غضون 48 إلى 72 ساعة.
فقط عندما تعيد عمليات الزحف المتتالية حالة 404، أو عندما تتجاوز مدة هذه الحالة عتبة مراقبة محددة (عادةً ما تكون عدة أسابيع)، يبدأ النظام عملية إزالة الفهرس.
- تقدير سرعة الإزالة بناءً على رموز استجابة HTTP:
| نوع رمز الحالة | الإجراء اللاحق لـ Googlebot | الوقت المتوقع لبقاء الفهرس |
|—|—|—|
| 404 (Not Found) | تمييز كـ “مفقود محتمل”، محاولة إعادة الزحف في غضون 3-5 أيام | ما بين 14 إلى 45 يومًا |
| 410 (Gone) | التعرف كـ “إزالة دائمة”، خفض الأولوية في طابور الزحف | بدء الإزالة في غضون 3 إلى 7 أيام |
| 301 (Redirect) | نقل ثقل الرابط القديم إلى المسار الجديد، الاحتفاظ بالفهرس مع تحديث التوجيه | الاحتفاظ الدائم (يوجه للصفحة الجديدة) |
| Soft 404 | الصفحة تظهر كمحذوفة لكنها تعيد رمز 200، سيعتبرها النظام صفحة منخفضة الجودة | من الصعب جدًا إزالتها تلقائيًا، قد تظل لأشهر |
تدير Google أكثر من 20 مركز بيانات ضخمًا وآلاف العقد الطرفية لتخزين ذاكرة التخزين المؤقت (Edge Nodes) حول العالم.
عندما يقوم خادم الفهرس الرئيسي الموجود في أوريغون بالولايات المتحدة بتحديث حالة حذف صفحة ما، يجب توزيع هذه البيانات عبر شبكة Google العالمية إلى مختلف قواعد بيانات الفهرس الإقليمية في أماكن مثل أيرلندا وفنلندا وسنغافورة.
غالبًا ما يكون هناك تأخير في الانتشار يتراوح بين 24 إلى 72 ساعة للوصول إلى حالة “اتساق البيانات النهائي” (Eventual Consistency).
قد يصل طلب البحث الذي يطلقه مستخدم في لندن إلى خادم طرفي لم تتم مزامنته بعد، مما يجعله يرى رابط اللقطة الذي لا يزال موجودًا.
- عوامل التداخل من الروابط الخارجية وخرائط المواقع:
- الروابط الداخلية المتبقية: إذا كانت الصفحات الداخلية الأخرى للموقع أو مواقع أخرى لا تزال تحتفظ بروابط تشعبية تشير إلى عنوان URL المحذوف، فسيستمر Googlebot في محاولة الوصول عبر هذه المداخل، مما يطيل من عمر هذا المسار في خطة الزحف.
- تأخر تحديث خريطة الموقع XML: الكثير من المواقع لا تقوم بتحديث ملف خريطة الموقع بعد حذف الصفحات. إذا كانت
sitemap.xmlلا تزال تحتوي على الرابط المحذوف، فسيقوم Google بفحصه دوريًا بناءً على ذلك، مما يؤدي إلى استمرار تحديث سجل هذا المسار في الفهرس حتى لو كان يعيد رمز خطأ. - الإشارات الاجتماعية والزيارات المتبقية: إذا كان الرابط المحذوف لا يزال يحصل على زيارات من منصات خارجية مثل Reddit أو X، فإن آلية مراقبة Google ستعتبر أن هذا الرابط لا يزال ذا قيمة، وبالتالي ستعطيه فترة مراقبة أطول في منطق التنظيف التلقائي.
ينقسم فهرس Google إلى فهرس رئيسي (Main Index) وفهرس تكميلي (Supplementary Index).
يحتوي الفهرس الرئيسي على محتوى عالي الجودة ويتم تحديثه بتكرار عالٍ، بينما يحتوي الفهرس التكميلي على كميات كبيرة من صفحات “الذيل الطويل” (Long-tail) والمحتوى المكرر.
إذا كان المحتوى المحذوف موجودًا في الفهرس التكميلي، فإن أولوية إعادة مراجعته من قبل Googlebot تكون منخفضة جدًا.
في حالات كثيرة، قد تختفي صفحة محذوفة من نتائج البحث الرئيسية، ولكن لا يزال بالإمكان العثور عليها في لقطات الفهرس التكميلي عند النقر على “عرض المزيد من النتائج” أو البحث عبر أمر site: المخصص.
معايير الإزالة
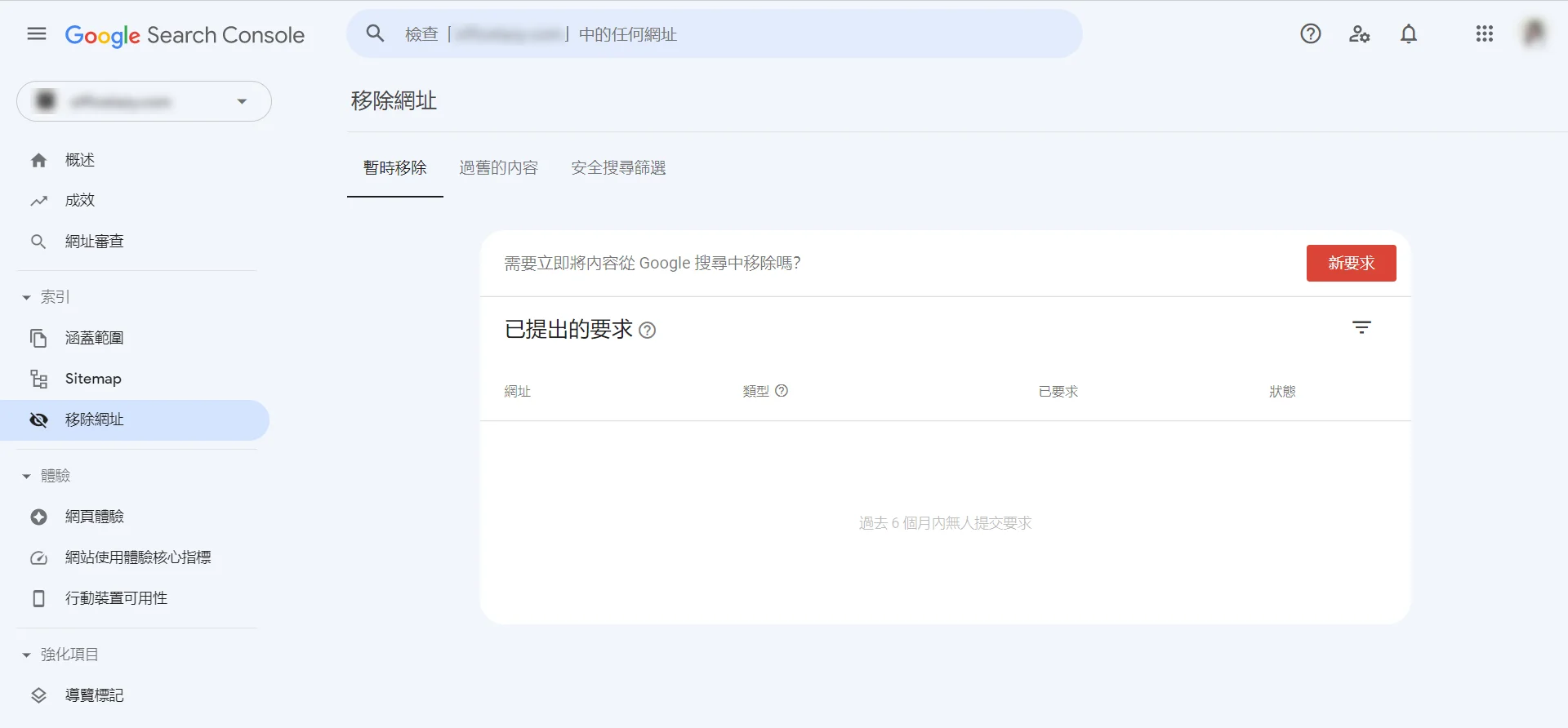
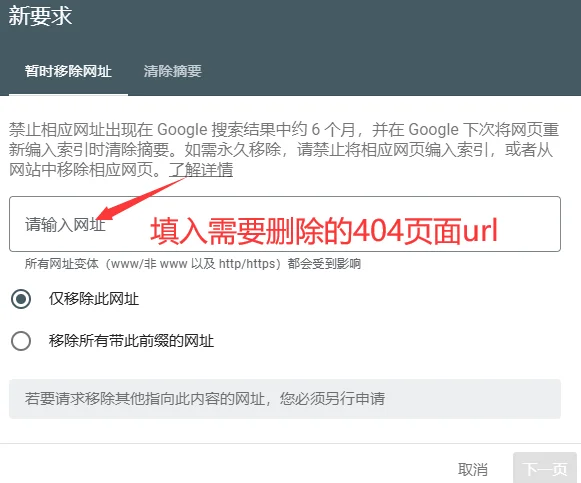
المسار المفضل للتدخل اليدوي هو استخدام أداة “الإزالة” في Google Search Console (GSC)، الموجودة تحت وحدة “الفهرس” في القائمة اليسرى للوحة التحكم.
في علامة تبويب “إزالة مؤقتة”، انقر على “طلب جديد” وأدخل عنوان URL الكامل الذي تريد تنظيفه، حيث يوفر النظام خيارين:
“إزالة عنوان URL مؤقتًا” و “مسح عنوان URL المخزن مؤقتًا فقط”.
الأول سيحجب المسار تمامًا من نتائج البحث في غضون 24 ساعة تقريبًا، ويسري المفعول لمدة تصل إلى 180 يومًا؛
أما الثاني فيحتفظ بمدخل البحث ولكنه يمسح فورًا الروابط التي تشير إلى اللقطة القديمة ووصف النص في مقتطف البحث.
إذا لم يتمكن Googlebot خلال فترة الحجب (180 يومًا) من اكتشاف إشارة اختفاء الصفحة من طرف الخادم، فسيظهر هذا الإدخال مرة أخرى في نتائج البحث بعد انتهاء الفترة.
بالنسبة للفنيين الذين لديهم صلاحيات إدارة الخادم، فإن تكوين رموز استجابة HTTP الصحيحة هو الحل الدائم الأكثر توافقًا مع منطق تحسين محركات البحث (SEO).
عندما يزور Googlebot مسارًا محذوفًا، يجب أن يعيد الخادم رمز الحالة 410 (Gone)، بدلاً من رمز 404 (Not Found) العام.
وفقًا للوثائق التقنية الرسمية لـ Google، يرسل رمز 410 أمرًا واضحًا للزاحف بالحذف الدائم، مما يحفز النظام لإزالة عنوان URL من طابور الزحف بأولوية أعلى.
غالبًا ما يُنظر إلى رمز 404 على أنه خلل مؤقت في الشبكة أو خطأ في التكوين، لذا يميل Googlebot للاحتفاظ بهذا الفهرس ومحاولة التحقق منه مرة ثانية خلال 48 إلى 96 ساعة القادمة.
لمواجهة احتياجات تنظيف الذاكرة المخبأة على نطاق واسع، يمكن في ملف تكوين خادم الويب (مثل Nginx أو Apache) ضبط استجابة 410 بشكل موحد لمجلدات معينة أو لاحقات ملفات محددة، لتوجيه محرك البحث لتسريع تنظيف النتائج القديمة في قاعدة الفهرس العالمية.
| اسم الأداة/الطريقة | حالات الاستخدام | سرعة الاستجابة | حالة بقاء الفهرس | مدة الصلاحية |
|---|---|---|---|---|
| أداة إزالة GSC المؤقتة | الحاجة لحجب فوري لمعلومات حساسة أو صفحات محذوفة | تفعيل خلال 24 ساعة | إخفاء الفهرس مؤقتًا | 180 يومًا (قابلة للإلغاء يدويًا) |
| رمز الحالة HTTP 410 | حذف الصفحة نهائيًا وتوجيه الزاحف للتنظيف | تحديث مع الزحف القادم | إزالة كاملة من قاعدة البيانات | صلاحية دائمة |
| رمز الحالة HTTP 404 | الصفحة غير موجودة، لكن بدون علامة خاصة | تحديث بعد فترة مراقبة | إزالة متأخرة | صلاحية دائمة |
| أداة فحص عنوان URL | عدد قليل من الصفحات يحتاج إعادة زحف إجباري يدوي | من 12 ساعة إلى 3 أيام | تحفيز تحديث الحالة | صلاحية لطلب واحد |
عند تعذر حل مشكلة تأخر ذاكرة التخزين المؤقت عبر الزحف العادي، يمكن إضافة X-Robots-Tag: noarchive في ترويسة استجابة HTTP للخادم، لمنع Google من تخزين أي لقطات لهذه الصفحة على خوادمه.
إذا كنت ترغب في تحكم أدق في وقت بقاء المحتوى، يمكنك استخدام علامة unavailable_after: [RFC 850 date/time]، والتي ستخبر Googlebot بالتوقف عن عرض هذه الصفحة في نتائج البحث بعد التاريخ والوقت المحددين.
| اسم العلامة/الأمر | وصف الوظيفة المحدد | سلوك محرك البحث |
|---|---|---|
| noarchive | تعطيل لقطات ذاكرة التخزين المؤقت | فهرسة الصفحة دون عرض رابط “نسخة مخبأة” |
| nosnippet | تعطيل المقتطفات النصية | عدم إظهار معاينة لمحتوى الصفحة في النتائج |
| noindex | منع الفهرسة تمامًا | إخراج الصفحة من جميع نتائج البحث |
| unavailable_after | ضبط وقت انتهاء تلقائي | تطبيق منطق noindex تلقائيًا عند انتهاء الوقت |
الكثير من المواقع تحتفظ بسجلات عناوين URL المحذوفة في خرائط المواقع، مما يجعل Googlebot يستمر في إجراء عمليات التفتيش الروتينية بناءً على قائمة المسارات القديمة.
يجب أن يتضمن إجراء العمل القياسي إزالة عنوان URL من sitemap.xml فور حذف الصفحة، وتحديث علامة <lastmod> (وقت آخر تعديل) في خريطة الموقع.
بعد ذلك، انتقل إلى صفحة “خرائط المواقع” في Google Search Console وأعد تقديم الملف.
خطأ في التكوين (Soft 404)
عندما يتم حذف صفحتك فعليًا ولكن الخادم لا يزال يرسل استجابة 200 OK لـ Googlebot، يتم إطلاق خطأ “404 ناعم” (Soft 404).
وفقًا لبيانات الزحف في Google Search Console، بما أن هذه الصفحات لم تعد أوامر 404 أو 410، فسيتم التعامل معها من قبل نظام الفهرسة كصفحات ويب عادية.
عادةً، إذا كانت منطقة المحتوى الرئيسية للصفحة أقل من 200 بايت أو كانت تعيد التوجيه إلى الصفحة الرئيسية للموقع، سيقوم Googlebot بتمييزها كـ Soft 404 بعد 2-3 محاولات زحف، مما يؤدي لبقاء الرابط في نتائج البحث لمدة إضافية تتراوح بين 14-30 يومًا.
تضليل رموز الحالة
عندما يزور Googlebot الخادم، فإن الخطوة الأولى هي قراءة رمز الحالة المكون من ثلاثة أرقام في ترويسة استجابة HTTP.
إذا حذفت ملف الصفحة ماديًا ولكن تكوين الخادم كان به خلل جعله يعيد 200 OK لهذا الطلب، فسيقرر Googlebot أن الصفحة لا تزال حية ومحتواها صالح.
بعد تلقي رمز 200، سيقوم نظام الفهرسة بإرسال نص HTML المستخرج (حتى لو كان مكتوبًا فيه “تعذر العثور على المحتوى”) إلى Indexing Pipeline للمعالجة.
إذا استمر هذا الرابط في تقديم إشارة 200، فإن مدة بقائه في فهرس Google ستطول بشكل كبير.
في المواقع الكبيرة، إذا تجاوزت نسبة هذه الروابط المتعطلة 10%، فسيؤدي ذلك لتشتيت Crawl Budget بشكل ملحوظ، مما يقلل من تكرار تحديث الصفحات السليمة.
| رمز حالة HTTP | التعريف التقني لـ Googlebot | إجراء نظام الفهرسة | الأثر المتوقع على ترتيب البحث |
|---|---|---|---|
| 200 OK | نجاح طلب الصفحة، المحتوى كامل | الاستمرار في الزحف وتخزين لقطة الصفحة | الاحتفاظ بالترتيب وعرض المقتطف النصي |
| 404 Not Found | المورد غير موجود، ربما مؤقتًا | التمييز للحذف، الإلغاء بعد تأكيدات متعددة | تراجع الترتيب تدريجيًا حتى الاختفاء |
| 410 Gone | المورد محذوف نهائيًا، لا حاجة لإعادة التأكيد | بدء إجراءات إلغاء الفهرس فورًا | إزالة سريعة من نتائج البحث |
| 301 Permanent | انتقال المورد نهائيًا لمكان جديد | نقل ثقل الرابط القديم للمسار الجديد | اختفاء المسار القديم وحلول الجديد محله |
| 302 Found | انتقال المورد مؤقتًا | الاحتفاظ بفهرس الرابط الأصلي، عدم نقل الثقل | استمرار ظهور الرابط الأصلي في النتائج |
تؤدي إعادة رمز 200 من الخادم إلى تشغيل خوارزمية استكشافية في Google تسمى Soft 404 Detection.
يقوم محرك عرض Google بتحليل المظهر البصري والسمات النصية للصفحة، مثل التحقق مما إذا كانت الصفحة تحتوي على كلمات مثل “404” أو “Not Found” أو “نعتذر”، وما إذا كان المحتوى الفعلي الفعال أقل من 200 بايت.
إذا وجد النظام أن صفحة برمز 200 لا تحتوي في الواقع على أي محتوى حقيقي، فسيحاول تصنيفها كـ Soft 404.
هذا الحكم القائم على الخوارزمية يتسم بتأخر واضح، وعادة ما يتطلب من 3 إلى 5 مرات زحف متكررة ليصبح ساري المفعول.
بالنسبة للمواقع التي تعتمد على بيئة Nginx أو Apache، إذا تم توجيه صفحة خطأ 404 بشكل خاطئ عبر 302 redirect إلى الصفحة الرئيسية، فإن رمز الحالة 200 الخاص بالصفحة الرئيسية سيغطي على إشارة الخطأ الأصلية.
سيعتقد Google أن الرابط الأصلي أصبح محتواه هو الصفحة الرئيسية، مما يؤدي إلى تضارب في المحتوى المكرر وبقاء الرابط القديم لفترة طويلة في SERP.
إذا أظهر حقل
Content-Lengthفي ترويسة الاستجابة قيمة صغيرة ثابتة (مثل أقل من 1024 بايت) مع رمز حالة 200، فغالبًا ما يحفز ذلك Google لإجراء فحص دقيق لمدى ضآلة محتوى هذه الصفحة.
عند التعامل مع مواقع دولية تحتوي على ملايين الروابط، تعد X-Robots-Tag في ترويسة الاستجابة إشارة مساعدة أيضًا.
إذا حذفت صفحة ولكنك لا تستطيع تعديل رمز الحالة فورًا، يمكنك إضافة أمر noindex في ترويسة الاستجابة.
إذا رأى Googlebot أمر noindex بجانب رمز 200، فسيقوم بإزالتها في دورة تحديث الفهرس التالية.
في بنية الخوادم الموزعة النموذجية، إذا قامت شبكة CDN (مثل Cloudflare أو Fastly) بتخزين استجابة 200 الأصلية، فحتى لو قام الخادم الأصلي بتعديلها لـ 404، سيظل الزاحف يرى الحالة القديمة المخزنة مؤقتًا.
هذا التضارب في ذاكرة التخزين المؤقت يؤدي لانفصال بين بيانات فهرس Google وبيانات بيئة الإنتاج الفعلية.
| نوع حقل الترويسة | مثال للمعلمة | رد فعل زاحف Google | اقتراح الإصلاح |
|---|---|---|---|
| Status Line | HTTP/1.1 404 Not Found | التوقف عن تخصيص حصة زحف لهذا الرابط | التأكد من أن الحذف يرافقه هذه الحالة |
| Cache-Control | max-age=0, no-cache | إجبار الزاحف على التحقق الفعلي في كل زيارة | تجنب تخزين استجابة 200 الخاطئة في CDN |
| X-Robots-Tag | noindex, nofollow | عدم السماح بدخول الفهرس حتى مع رمز 200 | استخدامها كإجراء علاجي مؤقت |
| Content-Type | text/html; charset=UTF-8 | تحليل المحتوى كصفحة ويب | التأكد من عدم التعرف على صفحة الخطأ كملف تحميل |
إذا كان الخادم مكونًا بمنطق معقد جدًا لـ If-Modified-Since، واستمر في إرجاع 304 Not Modified بعد حذف الصفحة، فلن يقوم Googlebot بإعادة زحف المحتوى أبدًا، بل سيستمر في استخدام اللقطة القديمة الموجودة في الفهرس منذ أشهر.
تقوم خوارزمية توزيع تكرار الزحف في Google بزيارة النطاقات ذات الثقل العالي عدة مرات يوميًا، بينما قد تزور النطاقات منخفضة الثقل مرة كل 14 إلى 21 يومًا.
إذا استمر الخادم في تقديم إشارات مضللة مثل 200 أو 304 خلال هذه النوافذ، فستصبح الصفحات المحذوفة ضيفًا دائمًا في نتائج البحث.
لحل هذه المشكلة جذريًا، يجب البدء من ملفات تكوين الخادم، وإزالة أي قواعد إعادة كتابة (Rewrite rules) تحول طلبات 404 صامتة إلى استجابة 200، واستخدام أدوات فحص الترويسات للتأكد من أن السطر الأول في تدفق البيانات الخام يحتوي فعليًا على 404 أو 410.
تحديد المعالجة
افتح القائمة اليسرى في Google Search Console، وابحث عن تقرير الصفحات (Pages) تحت فئة الفهرسة (Indexing).
في الجدول الموجود بالأسفل، ابحث عن القيود التي تحمل علامة “عنوان URL الذي تم إرساله يحتوي على خطأ 404 ناعم”.
بعد الدخول، سيعرض النظام قائمة تفصيلية بعناوين URL المتأثرة، ويسجل تاريخ آخر محاولة زحف.
استخدم أداة فحص عنوان URL (URL Inspection Tool) لإدخال المسار المحدد، ثم انقر على “اختبار عنوان URL المباشر” (Test Live URL).
إذا أظهرت نتائج الاختبار أن “عنوان URL متاح لـ Google لتتم فهرسته” ولكن لقطة الشاشة تظهر رسالة خطأ، فهذا يؤكد وجود خطأ في تكوين Soft 404.
يحتفظ نظام بحث Google بسجلات الزحف للـ 16 شهرًا الماضية عند التعامل مع هذه البيانات، ويمكنك تحليل أنماط توزيع المسارات للأخطاء عن طريق تصدير تقرير تفصيلي بصيغة CSV للحكم على ما إذا كانت هناك مشكلة منطقية نظامية في دليل معين (مثل /api/ أو /products/).
فقط عندما يعيد سطر الحالة في ترويسة استجابة HTTP رمزًا مؤكدًا مثل 404 Not Found أو 410 Gone، سيبدأ Googlebot إجراءات إلغاء الفهرس.
يعد استخدام أدوات سطر الأوامر للكشف المباشر من جانب الخادم وسيلة فعالة لاستبعاد التداخلات.
استخدم أمر curl -I https://example.com/deleted-page وراقب السطر الأول من المخرجات.
إذا كانت النتيجة HTTP/1.1 200 OK، فهذا يعني أن تكوين الخادم الخلفي فشل في قطع الطلب بشكل صحيح.
بالنسبة لخوادم الويب التي تستخدم Nginx، يجب فحص أمر error_page في ملف التكوين nginx.conf.
إذا تم ضبط error_page 404 =200 /404.html، فسيؤدي ذلك لإعادة ضبط حالة 404 قسريًا إلى 200.
الإجراء الصحيح هو إزالة علامة المساواة لضمان نقل رمز الحالة كما هو.
بالنسبة لخوادم Apache، افحص ملف .htaccess وتأكد من إعدادات ErrorDocument لتجنب إعادة توجيه الروابط المتعطلة بالجملة إلى الصفحة الرئيسية.
| اسم الأداة | بعد الفحص | نوع البيانات الراجعة | حالات الاستخدام |
|---|---|---|---|
| GSC URL Inspection | حالة الزحف المباشر | صلاحية الفهرسة/لقطة العرض | فحص دقيق لرابط واحد |
| Screaming Frog SEO Spider | رموز حالة HTTP | مصفوفة استجابة الروابط بالجملة | مسح شامل لصفحات الموقع المتبقية |
| Chrome DevTools (Network) | معلومات ترويسة الاستجابة | البيانات الخام لترويسة الخادم | تحليل منطق التفاعل الأمامي |
| Indexing API | طلبات إزالة فورية | رمز حالة استجابة JSON | الصفحات المؤقتة التي تُحدث باستمرار |
إذا تأكد وجود Soft 404، يمكن استخدام أداة Removals من Google للتدخل المؤقت.
توجد هذه الأداة في علامة تبويب “إزالة” بـ Search Console، وتسمح للمستخدمين بتقديم طلبات “إزالة عناوين URL مؤقتًا”.
بعد التقديم، سيختفي عنوان URL المقابل من نتائج البحث لمدة 180 يومًا تقريبًا.
خلال هذه الفترة، سيستمر Googlebot في محاولة زحف هذا العنوان.
بمجرد اكتشاف رمز حالة 404 حقيقي، سيقوم النظام بتحويل الإزالة المؤقتة إلى إلغاء دائم.
تحتوي هذه الأداة على حد أقصى للتقديم كل 24 ساعة، وهي مناسبة عادةً لتنظيف أقل من 1000 سجل متعطل.
إذا تجاوز وقت استجابة الخادم (TTFB) ما قيمته ثانيتين، فقد يتخلى Googlebot عن زحف الحالة الحالية ويستمر في استخدام بيانات الفهرس التاريخية.
من خلال البحث عن User-Agent الخاص بـ Googlebot (الذي يحتوي عادةً على Googlebot/2.1) وشرائح عناوين IP المقابلة، يمكن مراقبة تكرار زيارة الزاحف للصفحات المحذوفة.
إذا أظهرت السجلات أن الزاحف يتلقى رموز 200 عند زيارة هذه الصفحات، بينما حجم الصفحة (Bytes Sent) يكون ثابتًا عادةً بين 5KB إلى 15KB (وهو حجم صفحة الخطأ)، فهذا يشير إلى أن الخادم يقدم “محتوى” غير صالح للزاحف.
بالنسبة لتطبيقات الصفحة الواحدة (SPA)، يجب الانتباه بشكل خاص لحالة DOM بعد العرض الديناميكي.
محرك عرض Googlebot لديه حد قطع للمحتوى يبلغ 15MB، فإذا أدى خطأ في JavaScript إلى توقف عرض الصفحة عند حالة التحميل، فقد يتم الحكم عليها خطأً كصفحة طبيعية.
- سجل الدخول لـ Google Search Console لمراقبة تقرير “خرائط المواقع” (Sitemaps)، وتأكد من أن الروابط المحذوفة ليست في قائمة XML المقدمة.
- استخدم سطر الأوامر لتشغيل
wget --server-response --spiderللحصول على معلومات مفصلة عن مصافحة الاتصال. - في لوحة “الشبكة” بمتصفح Chrome، فعل خيار “تعطيل ذاكرة التخزين المؤقت” (Disable cache) وأعد الطلب لمراقبة ما إذا كانت طبقات التخزين المؤقت مثل
X-CacheأوVarnishفي CDN تعيد استجابة 200 قديمة. - بالنسبة للمواقع الضخمة، استخدم Google Indexing API لإرسال طلبات
URL_DELETED، فسرعة الاستجابة بهذه الطريقة تكون عادةً أسرع من الزحف السلبي.
بعد معالجة تكوين الخادم، يُنصح بالنقر على “التحقق من الإصلاح” في Search Console.
سيؤدي ذلك لتحفيز النظام لإعادة أخذ عينات لجميع عناوين URL المميزة بـ Soft 404.
بما أن Google يوزع الميزانية بناءً على تكرار الزحف التاريخي للصفحة، فإن الصفحات ذات الثقل العالي سيتم تحديث حالتها في غضون 48 ساعة، بينما قد تحتاج المسارات الطرفية ذات الثقل المنخفض إلى ما بين 3 إلى 4 أسابيع لتختفي تمامًا من الفهرس.
من المهم جدًا الحفاظ على ملف robots.txt ليسمح للزواحف بالوصول لهذه الصفحات، لأنه فقط عندما يرى الزاحف رمز 404، يمكن أن يدخل أمر الإلغاء حيز التنفيذ.
إذا قمت بحظر الزاحف مسبقًا، فلن يتمكن من تحديث سجلات حالة 200 القديمة في قاعدة بياناته.
لا تزال الروابط الخارجية موجودة
إذا كان عنوان URL محذوف لا يزال مشارًا إليه من قبل أكثر من 3 نطاقات مستقلة، فسيقوم Googlebot بزيارة هذا العنوان بشكل متكرر بناءً على مسارات الزحف لهذه الروابط.
حتى لو أعادت الصفحة رمز 404، فإن الإشارات التي تجلبها الروابط ستجعل Google يعتقد أن هذا المحتوى قد يكون مجرد عطل مؤقت.
الصفحات التي تمتلك أكثر من 10 روابط خلفية نشطة عادة ما تظل في نتائج البحث لفترة تزيد بـ 12 إلى 20 يومًا عن الصفحات التي لا تمتلك روابط.
تداخل الزيارات الخارجية
عندما ينقر مستخدمو المنصات الخارجية على روابط لصفحات محذوفة، فإن كل نقرة تولد طلب HTTP يرسل إشارة لنظام Google.
إذا ولّد رابط URL يحمل علامة 404 أكثر من 50 نقرة من نطاقات خارجية خلال 24 ساعة، فسيقوم نظام جدولة زحف Googlebot بإعادة هذا الرابط إلى سلسلة المراقبة عالية التكرار.
عندما يدخل عدد كبير من المستخدمين إلى صفحة متعطلة عبر Reddit أو X أو النشرات الإخبارية المهنية، يقوم المتصفح بإرسال سجلات فشل الوصول لقاعدة بيانات Google.
ستحكم خوارزمية محرك البحث بأن هذا الرابط لا يزال يتمتع بدرجة معينة من النشاط، ولمنع فقدان معلومات قيمة بسبب أخطاء تشغيلية من مدير الموقع، ستختار الخوارزمية إطالة مدة بقاء نتيجة البحث هذه بدلاً من إزالتها فورًا.
“في بروتوكولات صيانة الفهرس لدى Google، غالبًا ما يتفوق ثقل إشارات سلوك المستخدم على أوامر رموز حالة HTTP الصرفة. إذا كان مسار قديم يعيد حالة 404 لا يزال يحصل على تدفق زيارات مستقر من وسائل التواصل الاجتماعي الرئيسية أو المدونات ذات الثقل العالي، فسيقوم النظام تلقائيًا بتفعيل نافذة مراقبة تمتد من 7 إلى 14 يومًا. خلال هذه الفترة، سيرسل محرك البحث الزواحف عدة مرات للتأكد من استقرار الحالة وضمان أنها ليست خطأ مؤقتًا في تكوين الخادم.”
يستطيع جانب الخادم في Google التعرف على المصدر الحقيقي للزيارات عبر حقل Referrer في ترويسة HTTP.
إذا كانت الزيارات تأتي أساسًا من منتجات Google نفسها (مثل النقر على الروابط في Gmail) أو من مواقع ذات ترتيب عالمي متقدم، فإن أثر التداخل الناتج سيتضاعف.
يوضح الجدول التالي تأثير بيانات الزيارات بمختلف أبعادها على مدة بقاء فهرس Google:
| متوسط الزيارات الخارجية اليومي (UV) | نوع المصدر الرئيسي | الزيادة المتوقعة في مدة بقاء الفهرس | تغير تكرار زحف Googlebot |
|---|---|---|---|
| 5 – 20 | المفضلات الشخصية أو مدونات منخفضة الثقل | 2 – 4 أيام | الحفاظ على مسح مرة واحدة أسبوعيًا |
| 21 – 100 | منشورات Reddit أو منتديات صناعية متوسطة | 5 – 9 أيام | الرفع إلى مسح مرة كل 3 أيام |
| أكثر من 100 | تريندات X (Twitter) أو وسائل إعلام كبرى | 10 – 20 يومًا | الرفع إلى مسح يومي أو أكثر |
تتعلق هذه الظاهرة أيضًا بتوزيع ميزانية الزحف (Crawl Budget) الخاصة بـ Google.
سيتم هدر موارد الزحف المخصصة أصلاً لاكتشاف المحتوى الجديد على هذه الروابط المتعطلة التي تولد ردود فعل مستمرة من الزيارات.
عندما يلاحظ محرك البحث كثافة عالية من النقرات تتوجه لصفحة 404، سيسجل نظام تقييم الجودة الداخلي لديه “تجربة مستخدم سيئة”.
ومع ذلك، من أجل البحث عن محتوى ذي صلة يمكن أن يحل محل هذه الصفحة، قد يحتفظ Google بنتيجة البحث الأصلية لفترة من الوقت، ويحاول عرض صفحات مشابهة موصى بها أسفل هذه النتيجة، مما يؤدي لمزيد من التأخير في اختفاء الصفحة القديمة.
في اختبار تقني شمل 500 رابط متعطل، وجد أن الصفحات التي استمرت في تلقي نقرات من روابط خلفية خارجية كان تكرار تحديث لقطاتها في خوادم التخزين المؤقت أعلى بـ 3.5 مرة من الصفحات التي لا تمتلك زيارات.
بما أن متصفح Chrome يستحوذ على أكثر من 60% من حصة السوق العالمية، فعندما يقوم المستخدم بإدخال الرابط القديم في شريط العنوان أو الوصول إليه عبر المفضلات، يُعتبر هذا السلوك النشط دليلاً على أن الرابط لا يزال حيًا.
حتى لو أعادت الصفحة خطأ قياسيًا يفيد بعدم العثور على الملف، طالما أن المستخدم لم يغلق نافذة المتصفح خلال 30 ثانية من زيارة الصفحة المتعطلة، أو حاول البحث عن معلومات أخرى تحت نفس النطاق، فسيتم تفسير هذا التفاعل من قبل الخوارزمية على أن الصفحة لا تزال تشغل مكاناً في بنية الإنترنت.
مواقع التجميع (Aggregators)
عندما تتم إزالة صفحة ويب من الخادم الأصلي، فإن أثرها الرقمي لا يختفي بالتزامن من العقد الأخرى على الإنترنت.
تشمل هذه المواقع على سبيل المثال لا الحصر قارئات RSS العالمية (مثل Feedly أو Inoreader)، وأدوات قصاصات الويب (مثل Pocket)، بالإضافة لمؤسسات الأرشفة المهنية (مثل Wayback Machine التابع لـ Archive.org).
حتى لو أعادت الصفحة الأصلية رمز خطأ 404، فإن لقطات HTML الثابتة التي أنشأتها هذه المنصات الخارجية لا تزال توفر مداخل وصول لزواحف Google.
إذا وجد Googlebot مرارًا وتكرارًا روابط تشير لهذا العنوان المتعطل أثناء زحفه لمواقع التجميع ذات الثقل العالي، فسينشأ “تضارب منطقي” داخل خوارزمية إدارة الفهرس لديه، وهو:
على الرغم من أن الموقع الأصلي يبلغ بعدم وجود المحتوى، إلا أن النظام البيئي الخارجي لا يزال يستشهد به.
يسرد الجدول التالي الأثر المحدد لبيانات أنواع التجميع المختلفة على بقاء فهرس Google:
| نوع مصدر التجميع | دورة تحديث البيانات | مدة التداخل مع فهرس Google | شرح منطق الزحف |
|---|---|---|---|
| خلاصات RSS / Atom | مرة كل 10 – 60 دقيقة | 14 – 30 يومًا | تستمر القارئات في طلب ملفات XML، مما يجعل الروابط القديمة تبقى طويلاً في القوائم. |
| منصات أرشفة الويب (Archives) | حفظ النسخ نهائيًا | تداخل طويل المدى | حتى بعد حذف الصفحة الأصلية، فإن حالة “الحياة” لصفحات الأرشفة تغري الزاحف بزيارة المسار القديم. |
| مواقع محتوى المرآة (Mirroring) | مزامنة يومية | 7 – 21 يومًا | تقوم هذه المواقع بالجمع بالجملة عبر API، وروابطها الخلفية تحافظ على نشاط الرابط القديم في الفهرس. |
| ذاكرة تخزين البيانات الوصفية للتواصل الاجتماعي | تُحفز بناءً على طلب المستخدم | 3 – 10 أيام | تُخزن معاينات الصور والأوصاف الناتجة عن بروتوكول Open Graph في خوادم المنصات، لتشكل نقاط زحف ثانوية. |
على المستوى التقني، يقوم نظام الزحف الموزع في Google بتخصيص دورة تخزين مؤقت تسمى TTL (Time To Live) لكل رابط URL يتم اكتشافه.
عندما تولد مواقع التجميع “استشهادات وهمية” مستمرة لهذه الصفحة، يتلقى خادم الفهرس (Index Server) في Google طلبات زحف من عدة قطاعات IP مختلفة.
إذا لم يقم مدير الموقع بإزالة السجلات من خريطة الموقع XML قبل حذف الصفحة، فسيتم تضخيم هذه الدورة بشكل أكبر.
“تحدد السمة اللامركزية للإنترنت أن الحذف الكامل للمعلومات هو عملية تدريجية. عندما يدخل رابط URL في شبكة التجميع العامة، فإنه يخرج عن السيطرة المنفردة للخادم الأصلي. يميل Googlebot عند التعامل مع هذه الإشارات المتضاربة لحماية استمرارية نتائج البحث، أي الاحتفاظ بحالة التخزين في خوادم الذاكرة المخبأة حتى يتأكد من تعطل هذا الرابط في جميع العقد الرئيسية.”
إذا ظل رابط الاستشهاد بصفحة متعطلة نشطًا على منصات ذات ثقل عالٍ مثل Reddit أو Stack Overflow أو Medium، سيعتقد Googlebot أن حالة 404 قد تكون عطلاً مؤقتًا ناتجًا عن صيانة الخادم.
في هذه الحالة، سيستدعي Google Cached Version (النسخة المخبأة) المحفوظة في عقد CDN العالمية الخاصة به ليعرضها للمستخدم.
حوالي 22% من الصفحات المحذوفة تمر بـ “فترة إحياء الذاكرة المخبأة” قبل اختفائها، حيث يحاول محرك البحث ملء فجوة الفهرس عبر محتوى ذاكرة التخزين المؤقت.
- تأخير المزامنة بين مراكز البيانات: تمتلك Google عشرات مراكز البيانات الرئيسية الموزعة عالميًا، وتحديث قاعدة الفهرس في كل مركز لا يتم في الوقت الفعلي. عندما يحفز موقع تجميع في العقدة الأوروبية عملية زحف، فإن مزامنة هذه المعلومة مع العقدة الأمريكية قد تستغرق عدة ساعات أو حتى أيام.
- تضليل طلبات Head: تكتفي العديد من أدوات التجميع بفحص استجابة الخادم عبر طلبات Head فقط دون تحميل نص HTML الكامل. هذا التفاعل الخفيف يجعل من الصعب على خوارزمية Google الحكم على الفقدان الفعلي للمحتوى في اللحظة الأولى.
- الآثار الجانبية لعرض JavaScript: تقوم بعض مواقع التجميع المتقدمة بتشغيل متصفحات بدون واجهة (Headless Browser) لزحف المحتوى الديناميكي. إذا لم يكن تصميم صفحة 404 الخاصة بك بسيطًا بما يكفي (مثلاً يحتوي على الكثير من أشرطة التنقل أو المقالات الموصى بها)، فقد يخطئ الزاحف ويعتقد أن الصفحة لا تزال تحمل معلومات مفيدة.
- الزحف المتكرر لمسارات الاستشهاد: الموقع A يستشهد برابط محذوف، والموقع B يزحف لصفحة القائمة في الموقع A. توفر شبكة الاستشهادات متعددة المستويات هذه تدفقًا مستمرًا من مسارات الزحف لـ Googlebot، مما يجعل الرابط القديم يبقى دائمًا في طابور “قيد المعالجة”.
عندما يصل عدد مواقع التجميع إلى حجم معين، سيتم استهلاك ميزانية الزحف (Crawl Budget) الخاصة بـ Google بهذه المسارات غير الصالحة.
عند التعامل مع هذا النوع من البقاء، يعد استخدام Removals Tool (أداة الإزالة) في Google Search Console أسرع طريقة لكسر هذه الدورة المنطقية.


