




















Sí, los parámetros de URL (como el orden ?sort, el filtrado ?color o los IDs de seguimiento) son los principales desencadenantes de la duplicación de contenido en Google.
Para asegurar que el tráfico de búsqueda se dirija con precisión a la página objetivo, se recomiendan las siguientes acciones:
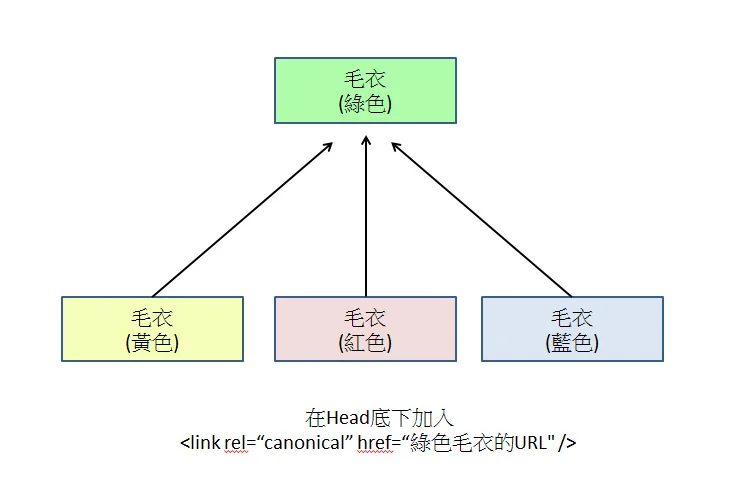
Configurar etiquetas Canonical
Añada rel="canonical" en el HTML de todas las páginas variantes, apuntando a la URL principal única.
Gestionar las rutas de rastreo
Bloquee los parámetros de seguimiento de marketing innecesarios (como utm_*) mediante Robots.txt.
Consolidar las señales de clasificación
Esto ayuda a Google a concentrar el “crédito” de todas las páginas con parámetros en la página principal, evitando caídas de tráfico causadas por la competencia interna.
Redundancia de Contenido
Los parámetros de URL pueden generar una gran cantidad de direcciones duplicadas para la misma página.
Por ejemplo, una página de comercio electrónico con 5 filtros de color y 3 opciones de orden puede derivar en más de 15 URLs diferentes.
En sitios grandes, aproximadamente el 40% de la cuota de rastreo suele estar ocupada por estas variantes de parámetros.
Cuando Google indexa 200 páginas de inicio idénticas con sufijos de seguimiento UTM, la autoridad de búsqueda de la página principal se divide, lo que resulta en una caída del rendimiento en el ranking de aproximadamente un 25%.
Dispersión de Enlaces
En el mecanismo de indexación de Google, las URLs con diferentes sufijos se consideran entidades independientes.
Por ejemplo, si una página de documentación técnica recibe enlaces externos de 50 dominios diferentes, pero 20 de ellos apuntan a la versión con ?utm_medium=email y otros 10 apuntan a la versión con ?ref=footer, la URL principal solo recibe en realidad el 40% del peso total.
Según un análisis de muestreo de datos de Ahrefs, este fenómeno de dilución de autoridad hace que la posición real de la página al competir por términos de alta dificultad sea de 3 a 5 puestos inferior a lo esperado.
Al identificar estas rutas dispersas, los rastreadores no agrupan automáticamente la fuerza de todos los enlaces hacia la página original, a menos que el sitio web configure explícitamente la lógica de procesamiento en el código fuente.
En el modelo de cálculo de PageRank, la transferencia de enlaces sigue una ley matemática basada en un coeficiente de amortiguación de 0.85.
Cada enlace que entra al sitio suma peso a una URL específica.
Cuando este peso se asigna a sufijos generados dinámicamente como ?sessionid o ?click_id, el “puntaje de confianza” de la página principal no logra alcanzar el umbral necesario para aparecer en la primera página de resultados.
En la competencia de la industria SaaS del mercado estadounidense, las tres primeras páginas suelen tener perfiles de enlaces extremadamente limpios.
Si la autoridad de una página se dispersa en más de 5 versiones de parámetros diferentes, Google podría mostrar estas páginas de forma alterna en los resultados de búsqueda, y este estado de competencia interna impedirá que el rendimiento de la página principal sea estable.
Muchas plataformas de comercio electrónico que utilizan arquitecturas como Magento o Salesforce Commerce Cloud generan enlaces internos con una gran cantidad de parámetros en la navegación de migas de pan (breadcrumbs) o filtros laterales.
Si la navegación interna apunta con frecuencia a category?sort=newest en lugar de a la dirección de categoría estática, el flujo de autoridad dentro del sitio se desviará.
Cuando el rastreador encuentra múltiples entradas para el mismo objetivo con diferentes estructuras de URL durante el proceso de rastreo, reducirá el nivel de prioridad de programación para esa página.
Las plataformas de redes sociales y los sistemas publicitarios de terceros suelen añadir forzosamente sus propios parámetros durante el redireccionamiento, como ?fbclid o ?gclid.
Si la página carece de una etiqueta rel=”canonical” eficaz, el algoritmo de Google podría, tras varias semanas de rastreo, seleccionar erróneamente una página con parámetros publicitarios como representante de ese contenido en las búsquedas.
Esta situación puede causar una caída del CTR del 15% aproximadamente, ya que la intención de clic de los usuarios es notablemente menor cuando ven URLs largas y con caracteres aleatorios en los resultados de búsqueda, en comparación con direcciones estáticas y concisas.
Una vez que los enlaces externos se acumulan en estas versiones temporales de parámetros, intentar recuperar totalmente esa fuerza para la página principal mediante soluciones técnicas posteriores suele requerir un proceso de reindexación que dura varios meses.
Efecto Multiplicador de Rutas
En las arquitecturas modernas de comercio electrónico (como Shopify o Magento), cuando una página de categoría básica tiene múltiples atributos de filtrado, cada nueva dimensión de parámetro se combina y permuta con los parámetros existentes.
Tomando como ejemplo una página estándar de categoría de zapatillas deportivas, si ofrece 10 opciones de color, 12 tallas, 5 marcas y 4 tipos de orden de precios, las rutas de URL independientes generadas teóricamente alcanzarán las 10 × 12 × 5 × 4 = 2400.
Si la lógica del programa permite el intercambio de orden de los parámetros (por ejemplo, elegir primero el color y luego la talla frente a elegir primero la talla y luego el color), este número se expandirá aún más.
Bajo este efecto multiplicador de rutas, lo que originalmente era una sola página de contenido real se convierte ante los ojos del rastreador de Google en miles de entradas de acceso diferentes.
Este tipo de rutas redundantes, ante la falta de una gestión eficaz, ocuparán más del 65% de la cuota de rastreo en sitios medianos y grandes, lo que impide que las páginas de detalles de productos que realmente necesitan actualizarse reciban una frecuencia de escaneo suficiente.
| Etapa de combinación de parámetros | Escala de factores variables | Cantidad de URLs únicas generadas | Estimación de ocupación de recursos de rastreo |
|---|---|---|---|
| Página de categoría original | 1 | 1 | 0.01% |
| Filtrado de atributos (color + marca) | 10 x 8 | 80 | 2.5% |
| Superposición de especificaciones (color + marca + talla) | 80 x 12 | 960 | 18.0% |
| Superposición de funciones completas (atributo + especificación + orden + paginación) | 960 x 3 x 10 | 28,800 | Más del 70% |
Cuando Googlebot procesa este “espacio infinito” generado por la acumulación de parámetros y el espacio de URLs de un sitio se infla excesivamente, la proporción de rastreo efectivo que puede completar en una unidad de tiempo cae drásticamente.
En un análisis de registros de un sitio minorista transnacional, se descubrió que el rastreador rastreó 15,000 URLs en 24 horas, pero solo 1,200 eran páginas estáticas con potencial de posicionamiento; el restante 92% de las acciones de rastreo se desperdició en variantes de parámetros compuestas por ?color=, ?size= y ?sort=.
En el proceso en que el algoritmo intenta elegir una “versión canónica” entre 200 rutas similares, si faltan señales técnicas claras que lo guíen, a menudo ocurre que la URL seleccionada no es la página estándar esperada por los desarrolladores, lo que provoca que se muestren direcciones con parámetros extraños en las páginas de resultados de búsqueda.
Cada vez que Googlebot solicita una URL con una combinación compleja de parámetros, la base de datos del backend suele necesitar ejecutar consultas de asociación de múltiples tablas para generar la vista correspondiente.
Bajo la presión de un rastreo de alta frecuencia, demasiadas solicitudes de combinación de parámetros pueden causar que el TTFB (tiempo de respuesta del primer byte) aumente entre 300 ms y 800 ms.
El aumento del retraso en la respuesta activará los mecanismos de protección de Googlebot, reduciendo consecuentemente la frecuencia de rastreo para todo el dominio.
Según un informe de investigación sobre 500 sitios de comercio electrónico globales, las páginas con una profundidad de parámetros de URL superior a 3 niveles tienen una probabilidad un 42% menor de ser indexadas con éxito por Google en comparación con las URLs planas.
El orden aleatorio de los parámetros provoca una desintegración profunda de las señales de enlaces; cuando una página con un parámetro promocional específico ?promo=winter es citada por un sitio externo, mientras la navegación interna apunta a la versión ?sort=new, ambas señales de autoridad están completamente aisladas en la base de datos interna de Google.
En sitios sin estrategias de normalización de URL, cada página de producto popular tiene un promedio de 14 variantes de parámetros diferentes, lo que provoca que el CTR de dicho producto en los resultados de búsqueda se disperse entre las distintas subrutas.
Al tratar con esta redundancia de rutas a gran escala, confiar simplemente en el bloqueo por robots.txt a menudo no soluciona los problemas de indexación ya existentes.
Las recomendaciones oficiales de Google Search Central tienden a favorecer el uso de la etiqueta rel=”canonical” para forzar la consolidación de estas rutas generadas por el efecto multiplicador.
Tras desplegar correctamente las etiquetas canónicas, la visibilidad de búsqueda de las páginas de categorías relevantes aumentó un promedio del 22% en 60 días.
Desperdicio de Presupuesto de Rastreo (Crawl Budget)
Googlebot tiene un límite máximo de solicitudes de rastreo a un sitio en una unidad de tiempo.
Cuando el sistema genera decenas de milies de URLs con parámetros (como ?variant=123 o ?sort=desc), el rastreador priorizará el consumo de estas rutas de baja calidad.
Según el mecanismo de rastreo de Google, si la cantidad de URLs duplicadas supera en 10 veces al contenido real, la frecuencia de rastreo de las páginas importantes caerá más de un 50%.
Este fenómeno provoca que páginas recién publicadas puedan no ser descubiertas incluso después de 72 horas, mientras que la frecuencia de rastreo de las URLs originales no parametrizadas se reduce drásticamente.
Impacto de los Parámetros
El sistema de programación de rastreo de los motores de búsqueda clasifica los parámetros como “parámetros activos” y “parámetros pasivos” según el grado en que cambian realmente el contenido de la página.
Los IDs de sesión (Session IDs) se encuentran entre los parámetros con mayor poder destructivo para los recursos de rastreo.
Estos parámetros, como ?sid=9928374 o ?sessionid=abc123, suelen ser generados dinámicamente por el backend para rastrear usuarios en el protocolo HTTP sin estado.
Dado que cada visitante, e incluso cada visita del rastreador, puede obtener un ID nuevo, esto crea una cantidad teóricamente infinita de URLs para el mismo documento HTML.
En el análisis de los registros del servidor se puede observar que, si no se establecen reglas de filtrado, Googlebot podría intentar rastrear el mismo artículo cientos de veces en 24 horas, usando cada vez una cadena de sesión diferente.
Este comportamiento provoca que en la cola de rastreo se acumulen una gran cantidad de solicitudes inválidas, desplazando la cuota que debería asignarse a las páginas nuevas (Fresh Content).
“En el monitoreo de registros de grandes sitios de comercio electrónico, las solicitudes de rastreo duplicadas causadas por IDs de sesión suelen representar del 30% al 50% del volumen total de rastreo, lo que obliga a Googlebot a activar con frecuencia límites de ‘crawl delay’ para proteger el rendimiento del servidor.”
Cuando un usuario hace clic en opciones como color, tamaño o material, la URL añade sufijos como ?color=blue&size=xl&material=cotton.
Aunque estos parámetros cambian el subconjunto de contenido mostrado, a menudo no generan metadatos completamente nuevos.
Desde una perspectiva técnica, estos parámetros siguen la lógica del producto cartesiano (Cartesian Product).
| Tipo de parámetro | Ejemplo de estructura típica | Impacto en la visibilidad para Googlebot | Grado de desperdicio de recursos de rastreo |
|---|---|---|---|
| Seguimiento de sesión | ?sid=xyz_987 |
Genera rutas de URL duplicadas casi infinitas | Muy alto (9/10) |
| Filtrado múltiple | ?size=m&color=red |
Las rutas crecen exponencialmente, fácil de causar bucles infinitos | Alto (8/10) |
| Lógica de orden | ?sort=price_desc |
Cambia el orden del contenido, sin información nueva sustancial | Medio (5/10) |
| Seguimiento publicitario | ?click_id=ad_01 |
Apunta a contenido 100% idéntico a la página original | Medio-alto (7/10) |
| Idioma/Región | ?lang=es-es |
Apunta a páginas válidas con contenido traducido diferente | Bajo (2/10) |
Los parámetros de orden (Sorting Parameters) como ?sort=highest_price o ?order=newest suelen marcarse con baja prioridad ante Googlebot.
Dado que el cuerpo principal, el título y la metadescripción de la página permanecen iguales tras el ordenamiento, el algoritmo de deduplicación (De-duplication Algorithm) identificará rápidamente que estas URLs son copias de la página canónica (Canonical Page).
Si el sitio no ha configurado correctamente rel="canonical" apuntando a la ruta principal, Googlebot seguirá gastando un 15% de su frecuencia de rastreo para verificar si estas páginas ordenadas tienen actualizaciones de contenido.
Para un sitio minorista con 100,000 SKUs, solo una función de “ordenar por valoración” podría hacer que el rastreador visite 100,000 enlaces sin sentido adicionales.
Los parámetros de seguimiento (Tracking Parameters) como ?utm_source=google o ?affiliate_id=123 afectan negativamente al SEO principalmente por el “coste de conexión”.
Aunque estos parámetros no cambian en absoluto el contenido de la página, Googlebot aún necesita establecer una conexión TCP y enviar una solicitud para determinar si el contenido devuelto por esa URL es el mismo que el de la página principal.
Según la observación de sitios de alto tráfico, si existen muchos enlaces internos con parámetros UTM, la velocidad de descubrimiento de rutas originales válidas cae aproximadamente un 25%.
Googlebot, al procesar estas URLs completamente duplicadas, reducirá gradualmente su frecuencia de rastreo, pero antes de eso, la valiosa “cuota de primer rastreo” ya se habrá agotado debido a estos códigos de seguimiento redundantes.
“Las auditorías técnicas muestran que eliminar los parámetros de seguimiento de los enlaces internos y migrar la lógica estadística al monitoreo de eventos en el lado del navegador puede aumentar el volumen diario de rastreo de páginas de Googlebot en más del 18%.”
Los parámetros de paginación (Pagination Parameters) como ?page=2 tienen un tratamiento lógico algo especial.
Google solía depender de rel="next/prev", pero ahora entiende la estructura de paginación principalmente mediante algoritmos.
Si no se interviene, el rastreador podría profundizar hasta la página 500 o más allá, y el valor de ranking de estas páginas profundas es extremadamente bajo.
Si los parámetros de paginación se combinan con parámetros de filtrado (por ejemplo: camisas azules en la página 5), la complejidad de la URL aumentará de forma exponencial.
Investigación y Control
Al acceder a los registros de acceso del backend del servidor y utilizar expresiones regulares para contar la frecuencia de las URLs que contienen el signo de interrogación (?), se puede observar claramente la trayectoria de acceso del rastreador.
En un sitio de comercio electrónico internacional con más de 100,000 visitas diarias, si los registros muestran que Googlebot realiza más de 40,000 solicitudes diarias a rutas con sufijos como ?sessionid= o ?track_id=, y el contenido de las páginas devueltas coincide totalmente con el HTML original, se evidencia que aproximadamente el 40% de los recursos de rastreo se desperdician en rutas sin sentido.
El equipo técnico debe calcular la “proporción de rastreo efectivo”, es decir:
Número de rastreos de páginas canónicas / Número total de rastreos.
Si este valor es inferior al 20%, generalmente indica que el rastreador está atrapado en un laberinto de URLs generadas por parámetros.
Utilizando herramientas de análisis de registros como Kibana o Splunk, se puede observar la distribución de la presión de rastreo bajo diferentes combinaciones de parámetros, identificando así las rutas que generan cientos de miles de variantes pero no aportan tráfico.
El informe de “Estadísticas de rastreo” en Google Search Console permite obtener la distribución de datos reales desde la perspectiva del motor de búsqueda.
En este informe, es vital centrarse en la dimensión “Rastreos por propósito”:
- Proporción de solicitudes de Descubrimiento (Discovery): Se refiere a la acción del rastreador al encontrar una nueva URL por primera vez. Para sitios que se actualizan con frecuencia, esta proporción debe mantenerse por encima del 30%. Si es demasiado baja, indica que el contenido nuevo está bloqueado por rutas de parámetros antiguos.
- Frecuencia de solicitudes de Actualización (Refresh): Se refiere a la re-visita del rastreador a páginas ya conocidas. Si las solicitudes de actualización se concentran masivamente en URLs con parámetros en lugar de en las páginas troncales del sitio, es señal de una asignación de recursos errónea.
- Indicadores de distribución de códigos de estado de respuesta: Observe la proporción de 200 (OK), 304 (Not Modified) y 404 (Not Found). Si las URLs con parámetros generan muchos errores 404 o redireccionamientos 301, Googlebot bajará el límite de capacidad de rastreo (Crawl Capacity Limit) debido al alto coste de conexión.
- Monitoreo del tiempo promedio de descarga: Si el filtrado de parámetros complejos activa consultas pesadas a la base de datos, causando que el tiempo de carga de la página supere los 2000 ms, Googlebot reducirá rápidamente el número de rastreos concurrentes para evitar sobrecargar el servidor.
Tras confirmar la fuente de los parámetros redundantes, aunque la etiqueta Canonical gestiona la duplicación en la indexación, solo Robots.txt puede interceptar las solicitudes antes de iniciar la conexión HTTP.
Al configurar Disallow: /*?*sort= o Disallow: /*?*price_min=, se puede obligar a Googlebot a dejar de acceder a combinaciones específicas de orden o filtrado de precios.
Este método permite liberar de inmediato el número de conexiones desperdiciadas en estas páginas para las URLs canónicas del Sitemap.xml.
Al configurar reglas, debe evitarse el uso amplio de Disallow: /*?, para no cortar parámetros de idioma beneficiosos para el SEO (como ?hl=es) o parámetros de paginación (como ?p=2).
La lógica de control fino debe combinarse con los resultados del análisis de registros, bloqueando solo aquellos filtros que generen combinaciones de rutas infinitas.
Para la navegación de múltiples facetas (Faceted Navigation), el uso de carga AJAX o la tecnología pushState permite aislar al rastreador.
Cuando el usuario hace clic en el botón de filtro, el contenido de la página cambia pero la URL no genera un sufijo rastreable, o solo utiliza un identificador de fragmento (#) para cambiar la vista. Estas prácticas son transparentes para Googlebot, ya que el rastreador suele ignorar todos los caracteres después del #.
En casos donde el uso de parámetros sea obligatorio, se puede implementar una lógica de limitación de dimensiones:
- Limitación de profundidad de ruta: Estipular en el código que cuando una combinación de parámetros supere tres dimensiones (por ejemplo: color + talla + material), el sistema inserte automáticamente la etiqueta
noindexen la cabecera HTML y asegure que la página no aparezca en ningún enlace interno. - Aplicación del atributo Nofollow: Aplicar
rel="nofollow"en los enlaces de la barra lateral de filtros, enviando una señal al motor de búsqueda de que “esta ruta no es importante”, reduciendo la probabilidad de que el rastreador entre en combinaciones de filtros profundas. - Instrucciones de consolidación canónica: Asegurar que todas las páginas con parámetros apunten a la versión canónica más concisa mediante
rel="canonical", para que incluso si el rastreador las visita, el sistema de indexación combine la autoridad en la ruta principal.
Si la página de inicio o el menú de navegación principal contienen una gran cantidad de enlaces con parámetros de seguimiento UTM, Googlebot priorizará el rastreo de estas rutas con ruido.
Se recomienda migrar todas las estadísticas de tráfico interno al seguimiento de eventos en el lado del navegador, manteniendo así la pureza de la URL. Al gestionar la lógica de paginación, aunque Google ya no use etiquetas de paginación específicas, mantener una estructura de ruta clara (como /page/2/ en lugar de ?page=2) ayuda al algoritmo a identificar las listas de forma más estable.
Tras implementar el bloqueo por Robots.txt o la lógica de consolidación de parámetros, se debe monitorear durante dos semanas el informe de “Cobertura de indexación” en Google Search Console.
La tendencia ideal es:
Una caída significativa en el número de páginas marcadas como “Rastreada: actualmente no indexada” o “Página duplicada”, mientras que la “Hora del último rastreo” de las páginas troncales se vuelve más frecuente.
Si el ciclo de rastreo de una página se reduce de una vez cada 10 días a menos de 24 horas, y las solicitudes con respuesta 200 en los registros del servidor se concentran más en las URLs canónicas, se demuestra que la cuota de rastreo se ha asignado correctamente.
Dilución de Señales
Cuando múltiples URLs que contienen diferentes parámetros (como ?sort=price o ?sessionid=abc) apuntan al mismo contenido, Google las tratará como páginas independientes.
El 100% de la autoridad de enlace original y las señales de clics de los usuarios se dispersarán entre estas variantes.
Si una página genera 5 copias con parámetros, el PageRank obtenido por una sola URL se reducirá al 20%, lo que impedirá que alcance el umbral de peso necesario para entrar en el top 10 de resultados de búsqueda.
En sitios de comercio electrónico con más de 50,000 URLs, los parámetros no gestionados harán que más del 50% de la frecuencia diaria de rastreo de Googlebot se consuma en rutas duplicadas, retrasando la velocidad de indexación de páginas nuevas.
Dispersión de Autoridad
En la lógica original del algoritmo PageRank, la capacidad de ranking de una página viene determinada por la cantidad y calidad de los enlaces que apuntan a esa URL.
Cuando el sitio genera variantes de ruta que contienen ?sort=newest, ?filter=price-low o ?sessionid=xyz, es muy probable que sitios externos enlacen a estas diferentes variantes.
Datos específicos indican que, si la URL original de un producto es example.com/item y externamente el 40% de los enlaces apuntan a example.com/item?source=social, el Grafo de Enlaces de Google registrará estas dos URLs por separado.
Aunque el algoritmo intente realizar una identificación de normalización, en el proceso real de transferencia de peso se pierde aproximadamente entre un 10% y un 15% del valor en este mapeo no estándar.
“Al procesar URLs con parámetros, Googlebot debe decidir en qué entidad específica inyectar el PageRank; si falta una guía Canonical clara, este proceso de inyección se vuelve aleatorio y fragmentado.” — Referencia de las aclaraciones técnicas públicas del equipo de calidad de búsqueda de Google.
En los datos reales de análisis de registros se observa que grandes plataformas de comercio electrónico transnacionales, al gestionar la navegación de facetas múltiples (Faceted Navigation), si no limitan el rastreo de parámetros, la velocidad de acumulación de PageRank de sus páginas de categoría principal es más de un 30% más lenta que la de competidores con rutas únicas.
Cuando 5,000 enlaces internos de todo el sitio apuntan respectivamente a 50 combinaciones de parámetros diferentes, el empuje que originalmente podría haber llevado una página a la primera hoja de resultados se divide en 50 partes, señales débiles insuficientes para generar un ranking.
Cuando la similitud de contenido entre dos URLs alcanza más del 98%, el sistema activa el mecanismo de deduplicación.
Según la observación de 500,000 sitios en América del Norte, las páginas determinadas por Google como “duplicadas” pero no redirigidas físicamente suelen tener su autoridad de enlace original en estado de congelación, sin transferirse automáticamente al 100% a la página principal.
Para sitios con más de 100,000 URLs, las rutas de rastreo inválidas generadas por parámetros limitan la profundidad de acceso de Googlebot.
en sitios que carecen de gestión de parámetros, el tiempo de permanencia del rastreador en páginas de parámetros inválidos representa el 65% del tiempo total de rastreo, lo que provoca que contenido de alta calidad recién publicado pueda tardar 14 días o incluso más en ser indexado, mientras que en sitios optimizados este ciclo se reduce habitualmente a menos de 24 horas.
“Cada cambio de carácter en una URL crea un nuevo nodo en la base de datos; aunque el contenido sea idéntico, estos nodos están en una relación de competencia en lugar de cooperación en las fases iniciales del algoritmo.” — Extracto de un informe experimental de una agencia internacional de investigación de SEO.
En algunas arquitecturas que utilizan balanceo de carga o redes de distribución de contenido (CDN), las solicitudes con parámetros podrían ser cacheadas como copias estáticas diferentes.
Si no se configura correctamente Vary: User-Agent o Link: rel="canonical" en la cabecera de respuesta HTTP, Googlebot podría pensar que estas páginas con parámetros están destinadas a mostrar contenido diferente para usuarios de distintas regiones.
Bajo este error de juicio, el algoritmo descompondrá aún más la autoridad de todo el sitio entre las diversas dimensiones de parámetros, creando una situación de “anemia de autoridad”.
Para cuantificar esta pérdida por dispersión a nivel técnico, se puede consultar el “modelo de pérdida de peso”:
Supongamos que la página principal necesita 100 unidades de señal para entrar en el top 3; si existen 4 variantes de parámetros y cada variante desvía un 15% de la señal, la página principal solo conservará finalmente 40 unidades de señal, dejándola en una posición de extrema desventaja en la competición.
En auditorías técnicas a tiendas internacionales en plataformas como Shopify, tras desactivar en GSC (Google Search Console) parámetros que no cambian el contenido como sort_by, view y page, se observó que el número de impresiones efectivas de las páginas objetivo creció un promedio del 55% en 60 días.
Propuestas de Solución
En arquitecturas de comercio electrónico de nivel empresarial global como Adobe Commerce (antes Magento) o Salesforce Commerce Cloud, el sistema de indexación de Google prioriza la lectura de la directiva rel="canonical" en la cabecera HTML o en la cabecera de respuesta HTTP durante el proceso de rastreo.
Cuando el sistema genera combinaciones de filtros múltiples como ?color=blue&size=xl, el programa del backend obliga a que la dirección canónica de esa página apunte a la URL raíz sin ningún parámetro.
Tras implementar correctamente esta solución, la precisión de Google al identificar contenido duplicado en el sitio puede subir del 60% a más del 99%, y los valores de PageRank dispersos se consolidarán físicamente en un ciclo de actualización de indexación de 2 a 4 semanas.
Para sitios transnacionales con millones de SKUs, esta lógica asegura que la ruta de búsqueda principal obtenga más del 95% de la autoridad de los enlaces internos.
- Declaración de enlaces en cabeceras de respuesta HTTP: Al gestionar documentos PDF o archivos parametrizados que no son HTML, el servidor envía la información de cabecera
Link: <https://example.com/file.pdf>; rel="canonical", evitando que el motor de búsqueda trate los enlaces de descarga con parámetros de seguimiento como contenido nuevo. - Consolidación forzada mediante redireccionamientos permanentes 301: Para parámetros de seguimiento de marketing ya caducados (como un
?utm_campaign=2023_salede hace tres años), la práctica habitual es configurar reglas de comodín (wildcards) a nivel de servidor Nginx o Apache para redirigir permanentemente todas las solicitudes con ese parámetro caducado hacia la página estándar, asegurando la transferencia del 100% de la autoridad acumulada históricamente. - Ignorar parámetros sin estado en el lado del servidor: En el desarrollo backend, se configura el servidor para que despoje el Session ID u otros parámetros usados solo para lógica interna al procesar solicitudes, manteniendo la URL que ven los diferentes usuarios como físicamente única.
- Bloqueo de categorías de parámetros en Google Search Console: En el panel de control de Google, los técnicos marcan los parámetros como “parámetros pasivos” (Passive Parameters), informando explícitamente al rastreador que estos caracteres no cambian el contenido, guiando a Googlebot para que salte proactivamente el rastreo de esas URLs.
En prácticas de SEO a gran escala, para aplicaciones de página única (SPA) con sistemas de filtrado complejos (como plataformas construidas con React o Angular), los desarrolladores tienden a usar Identificadores de Fragmento (#) en lugar de las tradicionales cadenas de consulta (?).
Por ejemplo, cambiar la URL de filtrado de /shoes?brand=nike a /shoes#brand=nike; todas las acciones de clic y filtrado del usuario se realizan en el cliente, mientras que el motor de búsqueda ve siempre la ruta única /shoes.
Al utilizar redes de distribución de contenido (CDN) globales como Cloudflare o Akamai, el equipo técnico configura reglas de “ignorar parámetros en la Cache Key”.
Independientemente de si el usuario accede a example.com/page?id=1 o example.com/page?id=1&from=email, la CDN devolverá la misma copia de caché tanto al motor de búsqueda como al usuario, y normalizará la salida canónica en la cabecera de respuesta.
Para plataformas con volúmenes masivos de datos como Amazon o eBay, su lógica de procesamiento se centra más en la reescritura de la estructura de rutas (URL Rewriting).
El sistema convierte el patrón de parámetros original /product.php?id=123&variant=blue en un patrón de directorios más semántico /product/123/blue/.
En una encuesta de muestreo a 100,000 tiendas independientes internacionales, aquellas que camuflan parámetros funcionales (como orden o cambio de vista) mediante la API window.history.pushState de JavaScript, sin cambiar la dirección de solicitud física, presentan una estabilidad media de ranking 2.8 veces mayor que los sitios comunes.


