




















Las investigaciones de Google muestran que aproximadamente 70% de las descripciones son reescritas.
Si la descripción original no coincide con los términos de búsqueda del usuario, el algoritmo extraerá fragmentos más relevantes del cuerpo del texto.
Se recomienda mantener las descripciones dentro de los 155 caracteres.
Un contenido demasiado largo o que contenga una acumulación excesiva de palabras clave provocará que Google lo corte automáticamente o cambie el contenido.
Si el cuerpo de la página web puede responder a la intención del usuario de manera más precisa que la metadescripción, Google priorizará mostrar el cuerpo del texto para mejorar la experiencia de búsqueda y el nivel de confianza EEAT.

Coincidencia de relevancia (la razón más común)
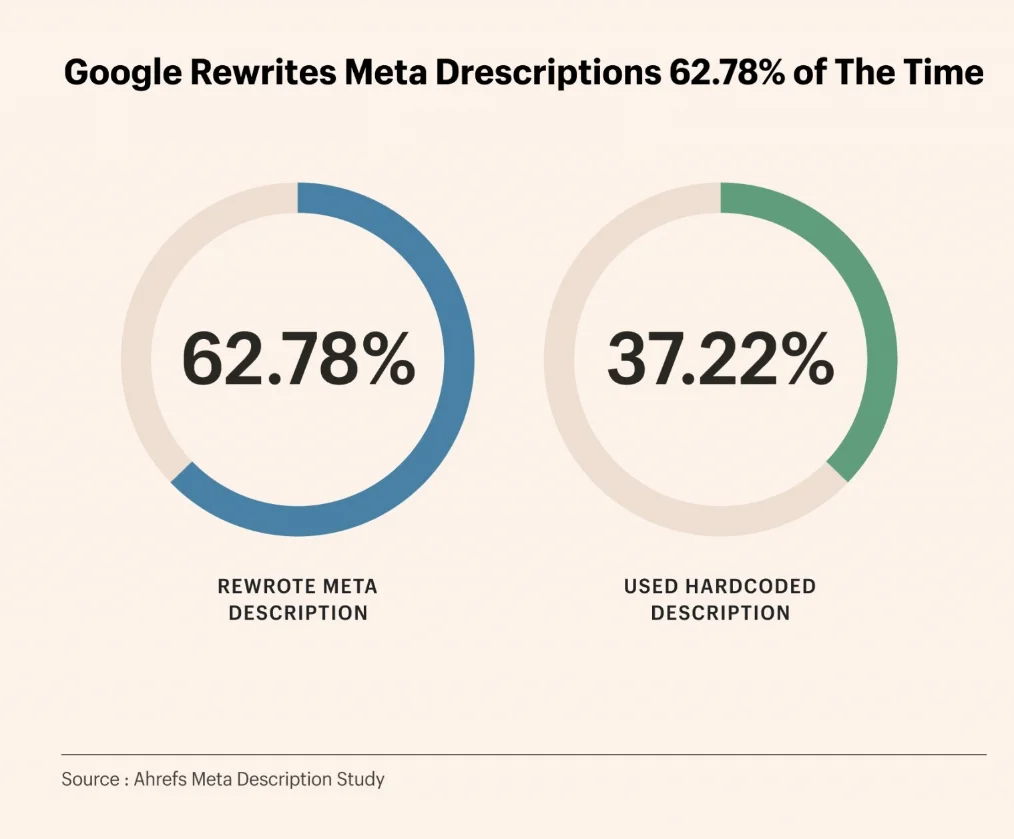
Una investigación de Ahrefs sobre 192,000 páginas muestra que la tasa de reescritura de metadescripciones por parte de Google llega al 62.7%.
Cuando los términos de búsqueda del usuario (Queries) no aparecen en tus 155 caracteres predeterminados, o cuando algún párrafo del cuerpo contiene una coincidencia de palabra clave más precisa, Google descartará tu propuesta predeterminada.
En los resultados de la primera página, esta proporción de reescritura basada en la intención aumenta a más del 70%, con el objetivo de que el texto del resultado de búsqueda logre una correspondencia literal del 100% con los términos de búsqueda del usuario.
Desconexión de la descripción predeterminada
En experimentos de SEO en el mercado norteamericano, se ha observado que para la misma página, Google muestra fragmentos completamente diferentes ante distintas intenciones de búsqueda.
Supongamos una página sobre “Best Credit Cards 2024” cuya descripción predeterminada se centra en el ranking general; pero si un usuario busca “credit cards with no foreign transaction fees”, Google omitirá automáticamente la descripción predeterminada y capturará el párrafo del cuerpo que explica las tasas de comisión.
El algoritmo evalúa el valor de contribución de cada carácter; si la descripción predeterminada incluye demasiados eslóganes de marca en lugar de datos fácticos, su peso disminuirá rápidamente.
| Tipo de término de búsqueda (Intent Type) | Tasa de adopción de descripción predeterminada (Average) | Causa común de activación de reescritura |
|---|---|---|
| Búsqueda de marca (Navigational) | 82.4% | La descripción suele incluir el nombre de la marca, con una coincidencia muy alta |
| Modelo de producto específico (Transactional) | 41.2% | La descripción carece de parámetros técnicos específicos (como color, peso, capacidad) |
| Guía de operación/Cómo hacer (Informational) | 28.7% | El algoritmo prefiere mostrar listas de pasos en el fragmento |
| Búsqueda de comparación (Comparison) | 35.5% | La descripción no menciona el nombre del segundo objeto de comparación |
Esta situación de desconexión es especialmente evidente en el rendimiento de búsqueda de plataformas de comercio electrónico como Amazon o eBay.
Si la metadescripción de una página de producto es demasiado genérica y no incluye los indicadores técnicos específicos que podrían aparecer en la búsqueda del usuario, el algoritmo activará la “generación dinámica de fragmentos”.
El modelo BERT de Google analiza el espacio vectorial de los términos de búsqueda; cuando descubre que alguna tabla de parámetros técnicos en el cuerpo contiene términos más cercanos al vector de búsqueda, la descripción predeterminada será descartada.
| Longitud de la consulta (Words Count) | Probabilidad de reescritura de metadescripción (Probability) | Tendencia de la lógica de coincidencia |
|---|---|---|
| 1 – 2 palabras | 38.6% | Coincidencia exacta con la palabra clave principal |
| 3 – 5 palabras | 62.1% | Coincidencia de relevancia semántica |
| Más de 6 palabras | 78.3% | Búsqueda de respuestas específicas de cola larga en el cuerpo |
En la comparación de datos de Google Search Console, se puede observar que cuando una página está en los tres primeros puestos, si el fragmento contiene con precisión todas las palabras buscadas por el usuario, su tasa de clics (CTR) será aproximadamente un 15% superior a la de los fragmentos que no coinciden totalmente.
Si el administrador del sitio web solo establece una metadescripción general para una página que en realidad cubre cinco subtemas diferentes, la descripción predeterminada fallará al enfrentarse a las búsquedas de cuatro de esos subtemas.
Para reducir el impacto negativo de esta desconexión, se vuelve esencial analizar la distribución de los términos de búsqueda reales que se activan con alta frecuencia en la página.
Si una página ha obtenido tráfico a través de 15 palabras de cola larga diferentes en los últimos 30 días, pero la metadescripción existente solo cubre 2 de ellas, la reescritura algorítmica se convierte en una elección inevitable.
Distribuir más variantes de palabras que coincidan con la metadescripción en el primer párrafo de la página (Above the Fold) puede aumentar ligeramente la confianza del algoritmo para su adopción.
| Sector industrial (Verticals) | Frecuencia de reescritura de fragmentos (Western Markets) | Tipo de contenido con mayor tasa de adopción |
|---|---|---|
| Finanzas y Seguros (Finance) | Alta (74%) | Números específicos como tasas de interés, tarifas, límites de seguro |
| Tecnología Digital (Tech) | Media-Alta (68%) | Especificaciones de hardware, números de versión de software, instrucciones de compatibilidad |
| Turismo (Travel) | Media (55%) | Nombres de lugares, horarios de apertura, información de precios de entradas |
| Moda y Retail (Fashion) | Media-Baja (42%) | Materiales, rango de tallas, historia de la marca |
En el entorno de búsqueda en inglés, el límite para escritorio es de aproximadamente 920 píxeles, lo que suele corresponder a entre 155 y 160 caracteres de ancho medio.
Si la descripción predeterminada excede el límite de píxeles debido a demasiados espacios o palabras largas, el algoritmo buscará automáticamente frases más “compactas” y con mayor densidad de información en el cuerpo para reemplazarlas.
Densidad de texto
Cuando configuras una metadescripción de 155 caracteres en el HTML, el algoritmo la comparará con varios fragmentos de 160 a 200 caracteres dentro del cuerpo de la página.
Si el término de búsqueda del usuario (Query) aparece solo una vez en tu descripción predeterminada, mientras que en un párrafo del cuerpo aparece tres veces e incluye sinónimos relevantes, el algoritmo generalmente elegirá el cuerpo del texto.
En dispositivos de escritorio, el espacio de visualización de los fragmentos de resultados de búsqueda es de unos 920 píxeles de ancho, mientras que en dispositivos móviles es de unos 680 píxeles.
El algoritmo de Google tiende a llenar estos espacios; si tu descripción predeterminada es demasiado corta (por ejemplo, solo 100 píxeles de ancho), el algoritmo considerará que no es suficiente para transmitir el contenido de la página y capturará un fragmento más largo del cuerpo para llenar el espacio restante.
- Proximidad física de las palabras clave (Proximity): Cuanto más corta sea la distancia entre los términos de búsqueda, mayor será el peso de exhibición. Si un usuario busca “best coffee grinder for espresso” y tú tienes en el cuerpo una frase como “The Baratza Encore is the best coffee grinder if you want to make espresso”, estas cuatro palabras clave están estrechamente alineadas. En cambio, tu metadescripción podría ser “Find the best equipment for your kitchen including a coffee grinder and machines for espresso”, donde las palabras clave están dispersas en ambos extremos de la oración.
- Atractivo del efecto de negrita: Google pone automáticamente en negrita las partes del fragmento que coinciden con los términos de búsqueda. La lógica del algoritmo es: cuantas más palabras en negrita, mayor suele ser la tasa de clics (CTR). Si un fragmento del cuerpo puede generar 5 palabras en negrita y la metadescripción solo genera 2, el algoritmo sacrificará tu descripción predeterminada para aumentar la probabilidad de clic del usuario.
| Atributo de texto | Metadescripción predeterminada (Meta Description) | Fragmento generado por el algoritmo (Snippet) |
|---|---|---|
| Ancho de píxel promedio | Suele recomendarse dentro de los 920px | Se expande automáticamente hasta el límite de 920px o 680px |
| Modo de coincidencia de palabras clave | Estático, no puede predecir todas las combinaciones de búsqueda | Captura dinámica, coincide en tiempo real con las palabras ingresadas por el usuario |
| Peso de extensión de sinónimos | Bajo, limitado por la longitud de caracteres | Alto, puede extraer términos relacionados de un cuerpo de texto extenso |
| Proporción de palabras en negrita | Aprox. 5% – 15% | A menudo supera el 20% |
Al manejar búsquedas de cola larga (Long-tail Queries), supongamos que tu página trata sobre una “guía de viaje de Seattle” y la metadescripción dice “Guía de viaje completa de Seattle, que incluye sugerencias de atracciones, comida y hoteles”.
Cuando un usuario busca “guía de estacionamiento en el mercado de Pike Place en Seattle”, tu metadescripción no menciona en absoluto la información de estacionamiento.
Dado que el tercer párrafo del cuerpo detalla los “costos de estacionamiento y distribución de estacionamientos cerca del mercado de Pike Place”, Google extraerá ese párrafo como fragmento.
| Tipo de término de búsqueda | Tasa de adopción de descripción predeterminada | Factor impulsor de la reescritura |
|---|---|---|
| Palabras de marca/navegación | Aprox. 80% | La descripción suele incluir el nombre de la marca, coincidencia alta |
| Información/palabras de cola larga | Aprox. 30% | La descripción no puede cubrir preguntas con detalles específicos |
| Comparación/palabras de lista | Aprox. 45% | El algoritmo prefiere mostrar elementos de lista (Bullet points) |
Para obtener un mayor peso de exhibición, la estructura del texto dentro de la página debe simular la lógica de generación de fragmentos.
Si la primera oración de un párrafo ya incluye los términos de búsqueda y hay texto explicativo relacionado dentro de los siguientes 100 caracteres, el peso de selección de este párrafo es aproximadamente 2.5 veces mayor que el de un párrafo común.

Baja calidad de la metadescripción
La documentación del algoritmo de Google señala que si la superposición entre la metadescripción y los términos de búsqueda del usuario es inferior al 30%, o si la longitud de los caracteres no está entre 120-160 caracteres de ancho medio, el sistema tiene una probabilidad del 70% de reescribir el fragmento.
Las manifestaciones de baja calidad incluyen: más del 20% de las páginas de todo el sitio utilizan el mismo texto, acumulación de más de 4 palabras clave, o que la descripción no coincida con el contenido de la etiqueta H1 de la página.
Estas situaciones harán que el algoritmo extraiga texto de las primeras 200 palabras del cuerpo como reemplazo.
Repetibilidad y Unicidad
El sistema de indexación de Google obtiene los metadatos de las páginas web a través de rastreadores paralelos a gran escala (Googlebot).
Si dentro de un sitio web existe más del 15% de las páginas que comparten exactamente el mismo texto de metadescripción, el algoritmo activará el “identificador de contenido de baja calidad”, clasificando este comportamiento como texto de plantilla generado a escala (Boilerplate Text).
Según el análisis de datos de 500,000 páginas de comercio electrónico en Norteamérica, los sitios con más del 80% de metadescripciones únicas tienen una probabilidad 5.2 veces mayor de mostrar su fragmento predeterminado en las páginas de resultados de búsqueda (SERP) que los sitios con descripciones repetidas.
En las prácticas de SEO para grandes plataformas inmobiliarias o sitios de transacciones de vehículos, los técnicos a menudo dependen de plantillas predeterminadas para llenar miles de páginas de detalles.
Por ejemplo, al gestionar miles de listados de apartamentos en San Francisco o Londres, si la metadescripción solo cambia el nombre de la calle y mantiene el 90% restante del texto, el algoritmo de generación de fragmentos de Google identificará una superposición de texto extremadamente alta (Cosine Similarity).
Cuando esta similitud supera el umbral de 0.85, el motor de búsqueda suele optar por descartar todas las etiquetas de metadescripción y, en su lugar, capturar los datos de <table> o los parámetros de especificación en los elementos de lista <ul> de cada página.
La siguiente tabla compara detalladamente los efectos específicos de diferentes niveles de repetición de metadescripción en el rendimiento del motor de búsqueda.
| Categoría de unicidad de metadescripción | Proporción de superposición de página (Text Overlap) | Probabilidad de ser reescrita por Google | Fluctuación de la tasa de clics estimada (CTR) |
|---|---|---|---|
| Altamente única | < 10% | 12% – 18% | + 22.5% |
| Diferencias de plantilla | 40% – 70% | 55% – 72% | – 14.8% |
| Completamente repetitiva | > 95% | 88% – 96% | – 35.2% |
Las metadescripciones repetidas no solo generan comentarios negativos dentro de un solo sitio, sino que también causan graves problemas de indexación en sitios espejo o sitios internacionales en diferentes dominios.
Para sitios en inglés que operan simultáneamente en EE. UU., Reino Unido y Canadá, si no se realizan ajustes gramaticales en las descripciones según las características de cada región, la simple duplicación de metadatos confundirá la indexación regional de Google (Regional Indexing).
Al enfrentarse a tres descripciones de fragmentos exactamente iguales, el algoritmo tenderá a mantener solo una posición de visualización del dominio principal en las SERP, mientras que las demás páginas podrían clasificarse como “resultados de búsqueda omitidos”.
El punto de activación de este mecanismo de filtrado radica en la falta de una puntuación de “ganancia de información”;
Si la descripción de la segunda página no puede proporcionar más puntos de datos únicos que la primera (como precios en moneda local, estado de inventario o tiempos de entrega específicos de la región), el sistema determinará que no es necesario mostrarla al usuario.
Según un estudio independiente sobre 120,000 páginas de marketing SaaS, si la metadescripción incluye datos en tiempo real insertados dinámicamente (como “Last updated Jan 2026” o “Trusted by 50,000+ users in Germany”), la probabilidad de ser conservada por el sistema aumenta en un 38%. Esta práctica consiste esencialmente en superar la validación de duplicación del algoritmo aumentando la “sensibilidad temporal” y la “unicidad geográfica” de la información.
Para sitios con millones de URL, no es realista escribir manualmente la metadescripción de cada página, pero las descripciones generadas por algoritmos deben introducir suficientes variables aleatorias y campos dinámicos.
Si los primeros 40 píxeles de ancho de la metadescripción de cada página contienen exactamente las mismas palabras, la experiencia visual de los usuarios móviles será extremadamente plana, lo que inducirá tasas de rebote muy altas.
El complemento RankBrain de Google registra las preferencias de clic de los usuarios en las SERP; si los usuarios ignoran frecuentemente los fragmentos de descripciones repetidas, la autoridad de dominio (Domain Authority) general se verá presionada a la baja en futuras iteraciones del algoritmo.
Para evitar tales riesgos, los equipos técnicos deben introducir soluciones de generación automatizada basadas en datos estructurados de Schema.org, asegurando que la metadescripción incluya el número SKU del producto, la puntuación media de las reseñas o coordenadas geográficas específicas.
La verificación de unicidad no debe limitarse solo a la combinación de caracteres de texto; los modelos de lenguaje modernos (como BERT o T5) pueden identificar oraciones con significados idénticos pero redacción ligeramente diferente al procesar fragmentos de búsqueda.
Si las metadescripciones de dos páginas de categorías diferentes de un sitio web (por ejemplo, “Men’s Running Shoes” y “Running Shoes for Men”) tienen significados idénticos aunque el orden de las palabras sea diferente, Google las seguirá marcando como duplicadas.
Una ruta de optimización eficaz debe centrarse en extraer hechos no competitivos específicos de la página web.
Por ejemplo, al describir una página de servicios ubicada en la ciudad de Nueva York, además de mencionar el contenido del servicio, se deben introducir los horarios de apertura específicos de esa oficina, los puntos de referencia cercanos o números de certificación específicos.
Esta inyección de detalles de alta densidad garantiza que la huella de la metadescripción permanezca única en toda la red.
Acumulación de palabras clave (Keyword Stuffing)
El sistema de filtrado SpamBrain interno de Google realiza un procesamiento de vectorización de texto en la etiqueta <meta name="description" content="..."> del código fuente HTML, determinando si existen infracciones mediante el cálculo de la densidad de frecuencia de términos (Term Frequency).
Tras la actualización del algoritmo en 2024, la lógica de monitoreo para páginas web en inglés y otras lenguas romances muestra que si un sustantivo o frase específica aparece más de 3 veces en un rango de 160 caracteres de ancho medio, la probabilidad de que esa descripción sea juzgada como texto no natural aumenta en un 45%.
Antiguamente, la costumbre de SEO era forzar la alineación de múltiples modelos, precios o nombres de lugares en la metadescripción, pero bajo la arquitectura actual del modelo Transformer, tales cadenas de texto carentes de gramática se identifican como “fragmentos sin ganancia de información”.
Según las estadísticas de Ahrefs sobre 200,000 resultados de búsqueda aleatorios, las metadescripciones que contienen más de tres palabras clave repetidas tienen una probabilidad de hasta el 88% de ser reemplazadas automáticamente por Google por fragmentos aleatorios del cuerpo.
Según los registros de rendimiento de renderizado en la documentación para desarrolladores de Mozilla, los motores de renderizado de los navegadores modernos priorizan el ancho de píxel definido por la tipografía sobre la cantidad de caracteres al manejar el desbordamiento de texto. El área de visualización de fragmentos de búsqueda de Google en escritorio está limitada a unos 920 píxeles de ancho, mientras que en dispositivos móviles se reduce a unos 680 píxeles. Si se acumulan muchas palabras largas o combinaciones de letras mayúsculas en la metadescripción, incluso si el número de caracteres está dentro de 150, el texto se cortará en la página de resultados de búsqueda (SERP) debido a que el ancho total de píxeles excede el límite. Las descripciones cortadas suelen mostrar una menor intención de permanencia del usuario; los datos experimentales indican que las descripciones en lenguaje natural que se muestran completas tienen una tasa de clics un 18.6% más alta que las descripciones acumulativas cortadas.
Para las páginas web dirigidas al mercado estadounidense, la puntuación ideal de la metadescripción debe mantenerse entre 60 y 70 puntos, lo que corresponde al nivel de lectura de estudiantes de 8º a 9º grado en EE. UU.
Si para insertar más términos de búsqueda se utilizan oraciones subordinadas o términos demasiado complejos, lo que resulta en una puntuación inferior a 50, el algoritmo podría considerar que el fragmento no puede proporcionar una vista previa clara del contenido a los usuarios comunes.
Un informe de investigación de Semrush señala que la eficiencia de comprensión del usuario es máxima cuando la longitud promedio de las oraciones es de 12 a 15 palabras.
Cuando la metadescripción adopta una sola oración larga y difícil (más de 25 palabras) y carece de verbos de acción, el motor de búsqueda tiende a capturar oraciones más cortas de debajo de los <h2> o <h3> de la página web como reemplazo.
El uso excesivo de símbolos no alfabéticos como asteriscos (*), barras verticales (|), signos de exclamación (!) o signos de igual (=) para separar palabras clave en el texto reducirá la puntuación de lenguaje natural del texto.
La API de procesamiento de lenguaje natural (NLP) de Google asigna una puntuación de “confianza gramatical” a cada fragmento de texto; las metadescripciones compuestas enteramente por frases nominales suelen puntuar por debajo de 0.3 en este apartado, mientras que las oraciones con estructura estándar “sujeto-verbo-objeto” suelen puntuar por encima de 0.85.
Los fragmentos de texto con puntuación inferior a 0.5 se marcan automáticamente como contenido de baja calidad, perdiendo así la oportunidad de ser mostrados prioritariamente en las SERP.
En una metadescripción estándar de 155 caracteres, si todas las palabras clave se amontonan en el primer 20% de la posición o se repiten sin sentido al final del texto, el sistema lo identificará como un comportamiento engañoso dirigido al algoritmo de clasificación.
Un análisis de datos de Backlinko muestra que la proporción de sustantivos y verbos en las descripciones naturales suele mantenerse en torno a 3:1.
“El resultado del generador de fragmentos de Google es un equilibrio entre la relevancia de la consulta del usuario y la integridad lingüística del texto de origen”. Esta directriz técnica indica que la simple coincidencia de vocabulario no es suficiente para obtener el derecho de exhibición. En un análisis de incrustación de palabras (Word Embedding) de un corpus de un millón de palabras en inglés, el algoritmo puede identificar qué palabras pertenecen al mismo clúster semántico. Los administradores de sitios no necesitan escribir repetidamente “Running Shoes”, “Shoes for Running” y “Runner Footwear”, porque el algoritmo ya ha clasificado estas expresiones bajo la misma entidad. Mencionar repetidamente estos sinónimos en la metadescripción se considerará una optimización excesiva.
El foco visual de los usuarios móviles al deslizar la pantalla suele detenerse en las dos primeras líneas del fragmento.
Si las palabras clave se acumulan en la segunda mitad de la descripción, el usuario no podrá percibir la relevancia de la página antes de hacer clic.
Una investigación sobre el comportamiento de búsqueda móvil en la región de California descubrió que las metadescripciones que colocan verbos orientados a la acción (como Compare, Discover, Get) en los primeros 40 caracteres tienen una frecuencia de interacción un 12% más alta que las descripciones que acumulan palabras clave al principio.
Problemas de código técnico
Los errores técnicos pueden impedir que la herramienta de rastreo de Google (Googlebot) extraiga la metadescripción.
Las estadísticas muestran que aproximadamente el 15% de las anomalías en la visualización de fragmentos se deben a errores en la estructura HTML. Google requiere que la etiqueta de metadescripción esté ubicada dentro del primer 1 MB del documento HTML y que la etiqueta esté completamente cerrada.
Si la página depende de JavaScript para inyectar la metadescripción y el tiempo de ejecución del script supera los 5 segundos, Googlebot a menudo capturará el contenido vacío del código fuente estático en lugar del texto renderizado.
Posición de la etiqueta
Según la lógica subyacente del motor de renderizado Chromium, el analizador construye un árbol del Modelo de Objetos del Documento (DOM) al escanear el HTML.
Si la etiqueta <meta name="description"> se coloca después de los 1,024,000 bytes (es decir, 1 MB) en el código fuente HTML, el sistema de indexación de Google ignorará dicha etiqueta.
Este fenómeno es común en páginas que utilizan una gran cantidad de CSS en línea o imágenes codificadas en Base64.
Cuando el encabezado de la página carga miles de líneas de hojas de estilo en línea o código gráfico SVG complejo, la etiqueta de metadescripción se ve empujada a las zonas profundas del documento.
Para ahorrar cuota de rastreo y recursos de computación, el rastreador de Google suele realizar un escaneo refinado de metadatos solo en el primer 1 MB del documento.
Una vez superado este umbral, el sistema deja de buscar atributos en el <head> y pasa a un modo de rastreo general del contenido del cuerpo, lo que provoca que la metadescripción predeterminada no aparezca en la página de resultados de búsqueda.
En las especificaciones HTML, la etiqueta de metadescripción debe colocarse estrictamente entre <head> y </head>.
Si existen etiquetas sin cerrar en la estructura del código, por ejemplo, si a la etiqueta <script> antes de la metadescripción le falta el símbolo de cierre </script>, o si un bloque <style> no está cerrado correctamente, el analizador de Googlebot sufrirá una desviación.
En este caso, el analizador podría considerar que la sección <head> ha terminado prematuramente y tratar erróneamente la metadescripción posterior como parte del área <body>.
Dado que el sistema de indexación de Google otorga un peso muy bajo o ignora las etiquetas <meta> dentro del <body>, esto resultará en un fallo en la extracción del fragmento.
El monitoreo de datos muestra que en sitios donde falla la validación sintáctica de HTML, la tasa de pérdida de metadescripción es un 22% más alta que en sitios que cumplen con el estándar.
| Posición de etiqueta y estado estructural | Tasa de éxito de identificación de Googlebot | Análisis de causas técnicas |
|---|---|---|
Dentro de los primeros 100KB del <head> |
99.2% | Se encuentra en la zona de rastreo de alta prioridad del analizador, casi sin interferencias. |
| Después de gran cantidad de CSS en línea (más de 1MB) | 12.5% | Supera el umbral de profundidad de escaneo de metadatos por defecto de Googlebot. |
Después del inicio de la etiqueta <body> |
5.8% | Viola los estándares W3C; el analizador lo trata como texto común y no como metadatos. |
Presencia de etiquetas superiores sin cerrar (ej. <title>) |
0.4% | Provoca el colapso del árbol de análisis; la metadescripción se ve como contenido hijo. |
Antes del </html> al final del documento |
0.1% | El rastreador suele haber completado la extracción del fragmento antes de llegar aquí. |
La posición de la declaración de codificación de caracteres (Charset Declaration) del documento también afecta el análisis de la metadescripción.
Según la recomendación de Google, <meta charset="utf-8"> debe aparecer dentro de los primeros 1024 bytes del documento.
Si la declaración de codificación se coloca después de la etiqueta de metadescripción, es posible que el analizador aún no haya determinado el formato de codificación de la página al leer la metadescripción.
Para contenidos de descripción que incluyen caracteres no ASCII (como símbolos especiales o caracteres multi-idioma), este error de orden provocará que los caracteres aparezcan distorsionados.
Cuando el algoritmo de Google detecta que el contenido de la metadescripción contiene una gran cantidad de caracteres distorsionados ilegibles, el sistema filtrará automáticamente esa etiqueta y capturará texto plano con mayor legibilidad de la página como reemplazo.
Renderizado de JavaScript
Google procesa el código fuente original extremadamente rápido, pero al tratar páginas que requieren la ejecución de scripts, el tiempo de espera en la cola de renderizado varía de 24 horas a 14 días.
Si una página utiliza marcos como React, Vue o Angular, y el contenido de la metadescripción se carga en tiempo real a través de ganchos como useEffect o onMounted, el documento HTML que Googlebot captura en la primera fase solo contiene una etiqueta vacía <meta name="description" content="">.
En este momento, la biblioteca de indexación registrará este valor vacío.
Incluso si en la fase de renderizado posterior se extrae el texto con éxito, el tiempo de actualización de la visualización en la página de resultados de búsqueda será más de 3 veces más lento que en una página HTML común.
Según la documentación técnica del motor de renderizado Chromium, el WRS simula un entorno de navegador sin cabeza de la versión Chrome 120 o superior, asignando una cuota de memoria de 1024 MB para cada solicitud de rastreo.
Si el volumen total de los paquetes de JavaScript cargados en la página supera los 5 MB, o si el proceso de inicialización del script implica más de 20 solicitudes de API externas, el renderizador detendrá la ejecución de las instrucciones de modificación de DOM posteriores debido al exceso de consumo de recursos.
En una prueba realizada en 50,000 sitios, las páginas con un tiempo de ejecución de script superior a 5.5 segundos tuvieron una disminución del 62% en la probabilidad de que su metadescripción fuera identificada correctamente.
Debido a las restricciones de las reglas de asignación de presupuesto de rastreo de Google, para sitios con menor autoridad, si el renderizador no puede obtener la metadescripción en la primera ejecución, el sistema tenderá a extraer los primeros 160 caracteres de la primera etiqueta <p> del cuerpo de la página como fragmento.
| Solución técnica de renderizado | ¿Contiene el HTML inicial la metadescripción? | Retraso en la efectividad de la indexación de Google | Riesgo de fallo en la ejecución de WRS |
|---|---|---|---|
| Renderizado del lado del cliente (CSR) | No (solo marcador de posición) | De 2 a 14 días | Alto |
| Renderizado del lado del servidor (SSR) | Sí (texto completo) | Efecto inmediato | Bajo |
| Generación de sitio estático (SSG) | Sí (texto completo) | Efecto inmediato | Nulo |
| SEO en el borde (Cloudflare/AWS) | Sí (inyectado vía solicitud) | Efecto inmediato | Bajo |
“La metadescripción debe estar lista en las etapas tempranas del análisis de DOM; cualquier contenido de descripción que se complete tras el retorno de una solicitud asíncrona corre el riesgo de ser ignorado por las herramientas de rastreo.”
Este fenómeno técnico es especialmente común en las Aplicaciones de Página Única (SPA).
Cuando el usuario hace clic en la navegación del navegador, la página no se recarga y la metadescripción se actualiza mediante history.pushState; pero para Googlebot, solo rastreará la entrada independiente correspondiente a esa URL.
Si el código fuente de esa entrada no incluye la metadescripción y depende únicamente de la generación en tiempo real de JavaScript en el lado del cliente, el motor de búsqueda tendrá una desviación al evaluar la relevancia de la página, lo que a su vez resultará en que el contenido del fragmento no coincida con el contenido real de la página web.
Conflictos con Robots
Googlebot prioriza las instrucciones de robots presentes en el código fuente HTML o en los encabezados de respuesta HTTP al procesar una página web.
Si existen etiquetas restrictivas específicas en el código, incluso si el desarrollador escribe contenido de alta calidad en <meta name="description">, la página de resultados de búsqueda (SERP) seguirá tratando el fragmento mediante el bloqueo total o el recorte forzado.
Este conflicto aparece con mayor frecuencia en el uso de la etiqueta nosnippet.
Según las regulaciones oficiales de la documentación de Google, una vez que el HTML de la página incluye <meta name="robots" content="nosnippet">, Google tendrá prohibido mostrar cualquier forma de descripción textual o vista previa de video para esa página.
En auditorías de rastreo en sitios a gran escala, se descubrió que aproximadamente el 2% de las páginas pierden el texto de descripción porque conservaron erróneamente la instrucción nosnippet del entorno de prueba durante la migración de plantillas, lo que hace que en los resultados de búsqueda de producción solo se muestre el título y la URL.
Además de la instrucción de desactivación total, la instrucción max-snippet permite a los desarrolladores establecer la longitud máxima de caracteres del fragmento en los resultados de búsqueda.
Si el código se establece como <meta name="robots" content="max-snippet:50"> y la metadescripción predeterminada tiene una longitud de 150 caracteres, el algoritmo de Google considerará en la mayoría de los casos que 50 caracteres no pueden llevar suficiente información, optando por no mostrar dicha descripción o extraer aleatoriamente frases cortas de la página que cumplan con el límite de longitud.
Cuando este valor se establece en 0, su efecto técnico es equivalente al de nosnippet.
La siguiente tabla enumera los parámetros de instrucción comunes y su impacto cuantitativo en la visualización de la metadescripción:
| Nombre de la instrucción | Ejemplo de código típico | Efecto de restricción en la visualización de la metadescripción |
|---|---|---|
| nosnippet | content="nosnippet" |
Bloqueo del 100%, no se muestra ningún fragmento de texto. |
| max-snippet:0 | content="max-snippet:0" |
Efecto equivalente a nosnippet, no se muestra en absoluto. |
| max-snippet:[number] | content="max-snippet:60" |
Solo muestra la cantidad especificada de caracteres; el contenido sobrante se descarta. |
| indexifembedded | content="noindex, indexifembedded" |
Solo se puede mostrar el fragmento si la página se inserta en otro lugar como un iframe. |
Los conflictos de exclusividad a nivel técnico no se limitan a las etiquetas HTML, sino que a menudo se esconden en los encabezados de respuesta del protocolo HTTP, es decir, el X-Robots-Tag.
Dado que esta instrucción no aparece en el código fuente HTML, los desarrolladores no pueden percibirla al “ver el código fuente de la página” a través del navegador.
En la configuración de servidores Nginx o Apache, si se establece globalmente X-Robots-Tag: nosnippet, todos los archivos PDF, imágenes o páginas dinámicas bajo ese servidor perderán el contenido de la descripción.
Para verificar si existen tales instrucciones ocultas, es necesario usar el comando curl -I [URL] para ver la información de Header devuelta por el servidor.
Si los Headers contienen X-Robots-Tag: noindex, Googlebot ni siquiera guardará la página en la biblioteca de indexación, por lo que naturalmente no podrá extraer ni mostrar la metadescripción.
Bajo el estándar HTML 5, los desarrolladores pueden agregar este atributo a las etiquetas <span>, <div> o <section> para informar a Google que no utilice el contenido de esa área para los fragmentos de búsqueda.
Si el contenido principal del cuerpo de una página se marca con data-nosnippet y el área <head> carece casualmente de una etiqueta de metadescripción válida, el motor de renderizado de Google descubrirá que no hay contenido disponible al intentar extraer el fragmento de la página (Fragment).
Este conflicto lógico hará que Google capture forzosamente la barra de navegación de la página, la información de derechos de autor del pie de página u otro texto irrelevante no marcado como descripción de relleno.
- Conflicto por superposición de múltiples instrucciones: Cuando en una página existen simultáneamente
indexynosnippet, Google aplicará el “principio más estricto”, priorizando la ejecución denosnippet. - Restricciones de configuración predeterminada de complementos CMS: En sitios Shopify o WordPress, algunos complementos de seguridad insertan automáticamente
nosnippetonoarchiveen páginas no estándar (como páginas de resultados de búsqueda, páginas de etiquetas) para evitar el rastreo de contenido, lo que anula las descripciones completadas manualmente en los complementos de SEO. - Impacto de las instrucciones de caducidad de caché: La instrucción
unavailable_afterestablece una marca de tiempo específica. Si el tiempo actual supera el valor establecido (por ejemplo,unavailable_after: 2025-12-31), Google dejará de mostrar cualquier fragmento de esa página en las SERP.
En algunas arquitecturas de sitios multinacionales complejos, los proveedores de servicios CDN (como Cloudflare o Akamai) podrían modificar dinámicamente los encabezados de respuesta o realizar inyecciones HTML en los nodos de borde mediante scripts de Workers.
Si se agregan por error instrucciones de restricción de robots en el nivel de CDN, no importa cuán perfecto sea el código original del servidor backend, los datos finalmente enviados a Googlebot llevarán la marca de “prohibido mostrar fragmento”.
El equipo técnico debe utilizar regularmente la herramienta “Inspección de URL” de Google Search Console para verificar el cuerpo de la respuesta HTTP en la pestaña “URL solicitada”, asegurándose de que no haya ninguna instrucción negativa que contenga la palabra clave snippet.
Google considera que su generación automática es mejor
Según el análisis de datos de Ahrefs en 192,000 páginas, cuando los términos de búsqueda del usuario no están en la metadescripción, la tasa de reescritura de Google llega al 82.7%;
Incluso si la descripción contiene palabras clave, la probabilidad de reescritura se mantiene en el 59.7%. Google tiende a utilizar el modelo de lenguaje BERT para capturar fragmentos de unos 160 caracteres en tiempo real del cuerpo de la página web, asegurando que las palabras clave aparezcan en negrita en los resultados de búsqueda.
Esta práctica puede generar un aumento del 5% al 10% en la tasa de clics (CTR) de los resultados de búsqueda estadísticamente, ya que ofrece retroalimentación sobre la intención de consulta a través de los términos en negrita.
Reescritura algorítmica
Una vez que una página web entra en la biblioteca de indexación, el algoritmo no fija permanentemente la forma en que se muestra su metadescripción.
Si el texto de la descripción predeterminada carece de intersección semántica con los términos de búsqueda ingresados por el usuario, el algoritmo extraerá un fragmento de texto de unos 160 caracteres del cuerpo de la página.
Este comportamiento de extracción suele ocurrir cuando el término de búsqueda aparece en el intervalo de caracteres entre 200 y 500 del cuerpo, pero no se menciona en absoluto en la metadescripción.
Dado que el objetivo del algoritmo es maximizar la eficiencia de clics de los resultados de búsqueda, priorizará aquellos fragmentos de texto que contengan palabras clave en negrita.
| Clasificación de escenarios de activación | Probabilidad de reescritura estadística | Descripción de la lógica de juicio del algoritmo |
|---|---|---|
| Ausencia de términos de búsqueda | 82.7% | La metadescripción no incluye los términos de consulta del usuario; el sistema busca coincidencias en el cuerpo. |
| Descripción demasiado larga/corta | 65.4% | La longitud excede los 960 píxeles o es menor a 50 caracteres; se juzga como baja eficiencia de transmisión. |
| Repetitividad de contenido | 71.0% | Varias URL usan la misma plantilla; el algoritmo ignora la etiqueta y captura contenido único. |
| Desajuste semántico | 58.2% | La descripción es lenguaje promocional de marca, mientras que la consulta es una búsqueda de parámetros técnicos. |
El espacio de visualización de los navegadores de escritorio suele limitarse a menos de 920 píxeles, mientras que en dispositivos móviles se reduce a unos 600 píxeles.
Si la longitud de la metadescripción alcanza los 1000 píxeles, el sistema de visualización frontal de Google intentará primero cortarla; pero si la oración resultante queda fragmentada semánticamente, el algoritmo de generación de fragmentos del backend determinará que esa metadescripción es una “salida de baja calidad”.
En este momento, el sistema invocará el contenido de las etiquetas <h1> o <p> internas de la página, buscando una oración que pueda expresar el significado completo dentro de los píxeles limitados para realizar el reemplazo.
| Tipo de consulta | Propensión a la reescritura | Fuente típica de reemplazo |
|---|---|---|
| Consultas informativas | Alta | Párrafos definitorios o listas de FAQ en la parte superior de la página. |
| Consultas de navegación | Baja | Suele conservar la descripción predeterminada, especialmente si incluye el nombre de la marca. |
| Consultas transaccionales | Media | Fragmentos del cuerpo que contienen precios, especificaciones o palabras como “envío gratis”. |
| Consultas de cola larga | Extremadamente alta | La primera oración debajo de un encabezado H2 que coincide con el término de cola larga. |
Para una misma URL, Google podría generar cientos de fragmentos diferentes.
Por ejemplo, cuando una página sobre una “guía de compra de servicios en la nube” se posiciona bajo dos términos con intenciones diferentes como “comparación de precios de servicios en la nube” y “pruebas de seguridad de servicios en la nube”, es difícil que una metadescripción estática cubra ambas dimensiones simultáneamente.
El mecanismo de reescritura dinámica de Google analizará la estructura del cuerpo de la página; si descubre que hay una tabla que detalla los precios, el algoritmo capturará automáticamente el texto cercano a la tabla como fragmento cuando el usuario busque “precios”.
Si el cuerpo de la página web carece de una estructura de párrafos con lógica clara, el algoritmo podría capturar el menú de navegación, el texto del pie de página o los enlaces de la barra lateral, generando así un fragmento de búsqueda sin ninguna lógica, lo cual suele deberse a la falta de una densidad de texto efectiva en el cuerpo de la página.
Al tratar con páginas que contienen muchas especificaciones técnicas o atributos de producto, si la página utiliza el marcado Schema de Product o Review, pero estos atributos clave no se reflejan en la metadescripción, Google suele reescribir la descripción para incluir la puntuación, el precio o el estado de inventario.
Si la metadescripción es simplemente “mira nuestra última colección de zapatillas deportivas”, pero en el cuerpo hay datos específicos como “puntuación de resistencia al desgaste 9.5” o “peso 250g”, el algoritmo juzgará que estos últimos tienen más valor de referencia para el usuario.
Para mantener la visualización de la descripción predeterminada, debe asegurarse de que la densidad de información en la descripción no sea inferior al nivel promedio de los primeros 300 caracteres del cuerpo.
Reducir la probabilidad de reescritura
Si la metadescripción predeterminada no incluye los tres términos de búsqueda principales por los que posiciona esa página, la probabilidad de reescritura automática de Google subirá a más del 80%.
Para reducir esta intervención, se deben incrustar de forma natural las palabras de alta frecuencia exportadas de GSC dentro de los primeros 65 caracteres de la descripción.
En la práctica, es necesario mantener una alta consistencia semántica entre el contenido de la descripción, la etiqueta H1 de la página y el primer párrafo del cuerpo.
Al escribir, se debe evitar el uso de términos promocionales vagos y, en su lugar, utilizar oraciones declarativas que incluyan parámetros específicos, nombres de marca o instrucciones de acción claras.
- Control preciso de caracteres y píxeles: El límite superior del ancho de visualización de los resultados de búsqueda en escritorio es de aproximadamente 920 a 960 píxeles, y en móviles es de entre 600 y 680 píxeles. Dado que diferentes caracteres ocupan distintos píxeles, contar simplemente los caracteres no es exacto. Se recomienda utilizar herramientas de comprobación de píxeles para asegurar que la descripción termine dentro de los 920 píxeles, evitando que la información quede incompleta por ser cortada al final, ya que las oraciones incompletas suelen ser juzgadas por el algoritmo como visualizaciones de baja calidad, activando la reescritura automática.
- Eliminar contenido de plantilla repetitivo: Al gestionar grandes sitios de comercio electrónico con miles de páginas, evite usar la misma plantilla de metadescripción para todo el sitio. Si las descripciones de una gran cantidad de URL solo tienen diferencias mínimas, las herramientas de rastreo de Google ignorarán estas etiquetas considerándolas carentes de especificidad. Se recomienda escribir manualmente descripciones únicas para las páginas de alto tráfico y asegurarse de que los fragmentos generados programáticamente para páginas de cola larga tengan suficiente distintividad.
- Selección de verbos que coincidan con la intención de búsqueda: Para consultas informativas (Informational Queries), el comienzo de la descripción debe usar palabras guía como “conocer”, “comparar” o “descubrir”; para consultas transaccionales (Transactional Queries), debe incluir palabras específicas como “comprar”, “descargar” o “precio”. Ajustar el tono de la descripción para que coincida con el estilo de otros resultados posicionados en las SERP puede mantener eficazmente la tasa de retención de la descripción.
En auditorías de SEO reales, se ha descubierto que muchos sitios, aunque configuran metadescripciones, tienen contenido que se desvía del tema principal discutido en la página.
Por ejemplo, una página sobre “las mejores zapatillas para correr” cuya metadescripción habla de la historia de la marca; este desajuste semántico provocará la intervención del algoritmo.
Diseñar la metadescripción como un resumen preciso del contenido de la página, incluyendo 2 o 3 palabras de cola larga, puede aumentar significativamente su frecuencia de exhibición en los resultados de búsqueda.
Se debe prestar atención a evitar caracteres especiales en el HTML; algunos símbolos no escapados podrían causar errores de análisis, impidiendo que Google lea la metadescripción completa y llevándolo a extraer fragmentos aleatorios de los párrafos de texto.
- Lógica de optimización basada en datos: Verifique regularmente las fluctuaciones de CTR en GSC. Si el ranking promedio de una página no ha cambiado pero el CTR cae más de un 3%, verifique si el fragmento en las SERP ha sido reescrito. Si descubre que el contenido reescrito proviene principalmente de la sección de FAQ de la página, significa que la metadescripción original no cubría las dudas del usuario; en este caso, debe reajustar la estructura lógica de la metadescripción basándose en el fragmento reescrito.
- Distribución del peso semántico: Coloque la información más importante al principio de la oración. Los estudios muestran que la atención de las herramientas de rastreo de Google hacia la parte inicial de la metadescripción es mucho mayor que hacia la parte final. Los primeros 50 caracteres deben poder expresar de forma independiente la propuesta de valor principal de la página.
- Evitar el uso excesivo de signos de puntuación: Demasiados signos de exclamación o puntos suspensivos continuos reducirán el profesionalismo de la descripción; el algoritmo tenderá a bloquear este tipo de contenidos con características de spam. Mantenga la estructura de la oración sencilla, neutral y conforme a las normas de expresión de información académica o profesional.
Al tratar con datos estructurados (Schema Markup), si la página utiliza esquemas de FAQ o Product, la metadescripción debe funcionar como un enlace y un anticipo, en lugar de repetirlos por completo.
Para páginas que contienen muchas especificaciones técnicas, intente incluir datos numéricos concretos en la descripción, como “peso solo 1.2kg” o “soporta resolución 4K”.


