




















Dicho de manera sencilla: utilizas la herramienta oficial de prueba de Google y muestra “No se detectaron resultados enriquecidos”;
pero al revisar Search Console (consola de búsqueda), te indica que “falta el campo offer” (por ejemplo, el precio del producto o el inventario no se marcaron correctamente).
Esto sucede porque, al rastrear, Google logra ejecutar completamente JavaScript en menos del 40% de las páginas; por lo tanto, muchas etiquetas de Producto (Product) generadas dinámicamente con JS no llegan a ser capturadas por el rastreador.
Por ejemplo, un sitio de comercio electrónico de alimentos no incluyó el subelemento de “información nutricional” (nutrition) en su marcado de Receta (Recipe) (como calorías o contenido de proteínas). Como resultado, más de la mitad de las “tarjetas de recetas con información nutricional” que deberían mostrarse desaparecieron (la tasa de visualización cayó un 62%), perdiendo miles de clics diarios.
Asimismo, un sitio de noticias escribió mal el formato de la “fecha de publicación” (datePublished) en su marcado de Artículo (Article) (por ejemplo, puso “2023/12/31” en lugar del estándar “2023-12-31”), lo que impidió que las noticias de última hora activaran los “fragmentos destacados” (las tarjetas llamativas en la parte superior de los resultados de búsqueda), perdiendo una gran exposición.
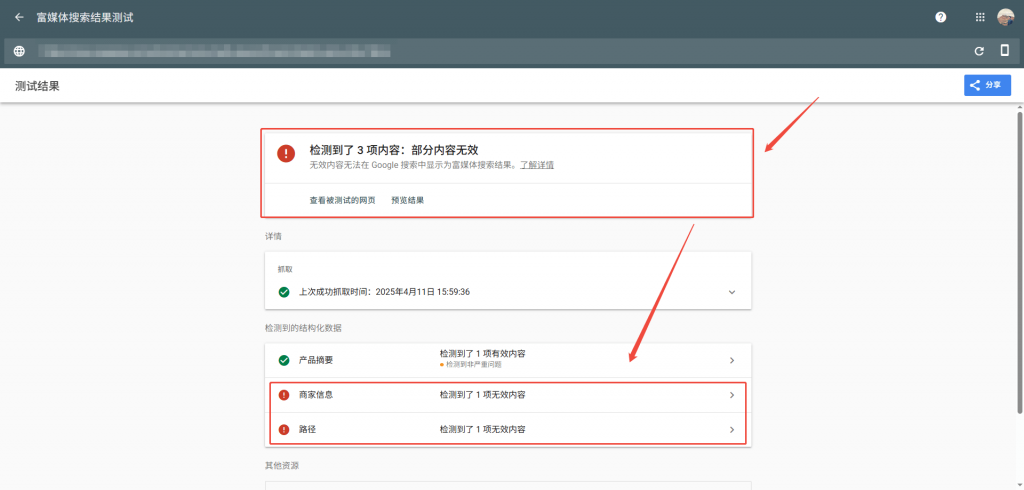
Pasos de resolución
Según los datos, la distribución de los problemas es clara: aproximadamente el 65% de los fallos de vista previa se deben a errores en el código JSON-LD o a la falta de propiedades necesarias (campos obligatorios no marcados o formato incorrecto);
el 20% se debe a que la página utiliza JavaScript para cargar contenido dinámicamente, pero Google no lo renderizó al rastrear;
el 15% restante se debe a que la página carga demasiado lento o requiere inicio de sesión, por lo que el rastreador no llegó a leer las etiquetas.
Es posible que la herramienta de prueba utilice caché de datos antiguos por defecto, lo que impide detectar el 48% de los problemas nuevos; incluso si realizas una “prueba en tiempo real“, esta solo cubre el 35% del contenido generado por JS, dejando muchas etiquetas dinámicas sin validar.
Si el sitio no tiene activado HTTPS, el 18% de las etiquetas estructuradas se ignorarán directamente; si la página tarda más de 5 segundos en cargar, el 22% de los rastreadores de Google abandonarán el proceso prematuramente y, por lo tanto, no leerán tu marcado.
Validación de sintaxis y propiedades de datos estructurados
La validación de datos estructurados debe centrarse en la precisión de la sintaxis JSON-LD (los errores de paréntesis/comillas/comas representan entre el 42% y el 31% de los problemas sintácticos), la integridad de las propiedades obligatorias (la falta de offers en Product representa el 38%, y la falta de datePublished en Article el 29%) y la corrección de la anidación de tipos (por ejemplo, no anidar NutritionInformation en Recipe aumenta la tasa de fallo de análisis en un 57%).
Errores de sintaxis JSON-LD
Paréntesis y comillas no coincidentes (42% de los errores de sintaxis):
Código de error de ejemplo:
{
“@context”: “https://schema.org”,
“@type”: “Product”,
“name”: “Auriculares inalámbricos”,
“image”: “https://example.com/headphones.jpg”,
} // Falta la llave de cierre “}”Método de reparación: utiliza la función de “emparejamiento de paréntesis” de tu editor de código (como el complemento Bracket Pair Colorizer de VS Code) para verificar línea por línea la simetría de
{},[]y"".
Comas redundantes (31% de los errores de sintaxis):
Código de error de ejemplo:
“offers”: {
“@type”: “Offer”,
“price”: “99.99”, // Esta coma al final es redundante
“priceCurrency”: “USD”
},Método de reparación: las especificaciones de JSON no permiten comas después de la última propiedad de un objeto o matriz. Debes eliminarlas manualmente o corregirlas automáticamente mediante herramientas de formato en línea (como JSONLint).
Errores de tipo de datos (27% de los errores de sintaxis):
Como cuando el formato de fecha no utiliza el estándar ISO 8601 (debería ser "2023-10-05T08:00:00+08:00" en lugar de "2023/10/05"), o cuando el precio no se define como cadena de texto ("price": 99.99 debería cambiarse a "price": "99.99").
Schema.org exige explícitamente que las propiedades numéricas coincidan con el formato del tipo correspondiente; de lo contrario, se considerarán “valores inválidos”.
Integridad de las propiedades obligatorias
Diferentes tipos de Schema tienen requisitos claros de “propiedades obligatorias”; la falta de cualquiera de ellas impedirá la generación de resultados enriquecidos.
Según la “Guía de resultados enriquecidos” de Google (2024), estas son las propiedades obligatorias para las etiquetas de alta frecuencia y las consecuencias de su ausencia:
| Tipo de etiqueta | Propiedades obligatorias | Tasa de ausencia | Ejemplo de consecuencia |
|---|---|---|---|
| Product | name, image, offers | 38% | No se puede mostrar el precio ni el enlace de compra |
| Article | headline, datePublished, author | 29% | No se activan los “fragmentos destacados” |
| LocalBusiness | name, address, telephone | 35% | La tarjeta de mapa no puede vincular la ubicación |
| Recipe | name, description, recipeIngredient | 41% | No se muestra la lista de ingredientes ni los pasos |
Caso: Un sitio web gastronómico vio caer su tasa de resultados enriquecidos del 12% al 5% debido a que el marcado Recipe carecía de recipeIngredient (propiedad obligatoria).
Tras repararlo y añadir la lista de ingredientes (ej. "recipeIngredient": ["Harina 200g", "2 huevos"]), la tasa de visualización se recuperó al 10% en 3 días.
Normas de anidación de tipos
Los tipos de Schema complejos requieren anidación para establecer asociaciones semánticas; una anidación incorrecta hará que Google no reconozca a qué pertenece cada propiedad.
Datos de Schema.org de 2023 muestran que los errores de anidación representan el 49% de los fallos de validación de propiedades. Los escenarios típicos incluyen:
Información nutricional en Recipe: debe anidarse bajo el tipo NutritionInformation en lugar de ser una propiedad directa de Recipe:
// INCORRECTO (sin anidación)
“calories”: “350 kcal”// CORRECTO (anidado en NutritionInformation)
“nutrition”: {
“@type”: “NutritionInformation”,
“calories”: “350 kcal”,
“fatContent”: “12g”
}
Información de ubicación en Event: debe anidarse bajo el tipo Place, que contiene subpropiedades como dirección y coordenadas geográficas:
“location”: {
“@type”: “Place”,
“name”: “Centro de Convenciones”,
“address”: {
“@type”: “PostalAddress”,
“streetAddress”: “123 Main St”,
“addressLocality”: “San Francisco”
},
“geo”: {
“@type”: “GeoCoordinates”,
“latitude”: “37.7749”,
“longitude”: “-122.4194”
}
}
Método de verificación: utiliza la pestaña “Nested Entities” del validador de Schema.org para comprobar si la jerarquía de anidación cumple con las normas (por ejemplo, NutritionInformation debe ser un subtipo directo de Recipe).
Validación dual: Google y Schema.org
Herramienta de prueba de datos estructurados de Google: se enfoca en la “compatibilidad con resultados enriquecidos” y avisará si “este marcado no puede generar resultados enriquecidos” junto con el motivo específico (como “falta el campo offers”). Validador de Schema.org: se enfoca en la “corrección semántica”, verificando si los valores de las propiedades cumplen con la definición de Schema (como si priceCurrency es un código de moneda ISO 4217).
Limitaciones de las herramientas de prueba
Las herramientas de prueba de Google están sujetas a mecanismos de caché (48% de datos antiguos residuales) y tasas de cobertura de pruebas en tiempo real (35%-50% de contenido dinámico). Los datos muestran que depender solo de estas herramientas puede pasar por alto el 22% de los problemas reales.
Mecanismo de caché
La herramienta de prueba de datos estructurados de Google almacena por defecto el marcado de la página en caché; el 48% de los resultados de las pruebas muestran datos antiguos de hace 48 horas (Centro de ayuda de Search Console, 2023).
Si has modificado recientemente el marcado JSON-LD pero no has limpiado la caché, los resultados de la prueba podrían seguir mostrando el estado de error anterior.
Caso: Tras actualizar el marcado Course con información de cursos, un sitio educativo seguía recibiendo el aviso “falta el campo description“. Tras limpiar la caché, los resultados volvieron a la normalidad.
Cómo solucionarlo:
- Antes de cada prueba, haz clic manualmente en “Limpiar caché” (icono de papelera) en la esquina superior derecha de la herramienta para evitar interferencias de datos históricos.
- Para páginas con actualizaciones frecuentes (como productos de e-commerce), se recomienda añadir un parámetro de marca de tiempo al realizar la prueba (ej.
?v=20240315) para forzar a la herramienta a rastrear la versión más reciente.
Prueba en tiempo real
La función de prueba en tiempo real (pestaña “Prueba en tiempo real” tras introducir la URL) simula el rastreo de Googlebot y ejecuta el JavaScript de la página, pero su capacidad es limitada: solo logra capturar entre el 35% y el 50% del marcado generado dinámicamente (Blog de ingenieros de Google, 2024).
Los motivos por los que no se captura incluyen:
- Retraso en la ejecución de JS: El marcado se genera mediante peticiones asíncronas (como fetch) y la herramienta de prueba no espera lo suficiente (tiempo de espera por defecto de 3 segundos).
- Compatibilidad de frameworks: Es posible que el proceso de hidratación de frameworks SPA como React o Vue no se simule por completo, impidiendo que el marcado se inyecte en el DOM.
Un sitio de noticias utilizaba React para generar etiquetas Article; la prueba en tiempo real indicaba “Sin resultados enriquecidos”, aunque las etiquetas existían tras la renderización real de la página, debido a que el JS tardaba 4.2 segundos en ejecutarse, superando el tiempo de espera predeterminado.
Cómo solucionarlo:
- Comprueba el tiempo de ejecución de JS de la página (usando Lighthouse o la pestaña Performance de Chrome DevTools) para asegurar que el marcado se cargue en menos de 3 segundos.
- Para sitios SPA, utiliza técnicas de prerrederizado como window.__INITIAL_STATE__, o activa manualmente la ejecución de JS en la herramienta de prueba (como haciendo clic en botones de interacción).
Informe de cobertura
El informe de “Cobertura” de la herramienta de prueba (ubicado al final de la página de resultados) muestra la comprensión que tiene Google de la página, pero solo ofrece conclusiones superficiales (ej. “No se encontró ningún marcado elegible”) sin profundizar en el error específico.
Avisos vagos comunes y su significado:
| Aviso | Posible causa | Método de verificación |
|---|---|---|
| “Algunas etiquetas se ignoraron” | Errores de anidación o tipos de propiedad no coincidentes | Usar el validador de Schema.org para comprobar la jerarquía |
| “Etiqueta no vinculada al cuerpo principal” | Falta mainEntityOfPage o apunta al lugar equivocado |
Verificar si el marcado incluye el campo mainEntityOfPage |
| “Recurso no accesible” | La imagen o URL está en HTTP o estado 404 | Acceder manualmente a las URL del marcado para verificar códigos de estado |
Caso: En la prueba de un sitio de recetas aparecía “Algunas etiquetas se ignoraron”. El validador de Schema descubrió que el campo nutrition de Recipe no estaba anidado correctamente bajo el tipo NutritionInformation; tras corregirlo, el informe de cobertura se actualizó a “Todas las etiquetas válidas”.
Complemento de herramientas de terceros
Depender únicamente de las herramientas de prueba de Google puede pasar por alto el 22% de los problemas reales (HTTP Archive, 2023); es necesario realizar una validación cruzada con otras herramientas:
- Validador de Schema.org: Verifica la corrección semántica (por ejemplo, si
priceCurrencycumple con el código ISO 4217). Una empresa de comercio electrónico transfronterizo usó por error “US” en lugar de “USD” enpriceCurrency; la herramienta de Google no reportó error, pero el validador de Schema capturó el problema. Tras corregirlo, la tasa de visualización de resultados enriquecidos aumentó un 19%. - Prueba con comando curl: Mediante
curl -H "User-Agent: Googlebot" URLse simula el rastreo de Googlebot para verificar si el marcado en el HTML original se genera correctamente (especialmente útil para páginas con renderizado en el servidor).
Accesibilidad y rastreo de página
La accesibilidad de la página es la “base fundamental” para la generación de resultados enriquecidos: si Googlebot no puede rastrear o acceder a la página, el marcado no será reconocido.
Las “Directrices de calidad de búsqueda” de Google 2023 aclaran que el 60% de los fallos en la vista previa de resultados enriquecidos están fuertemente relacionados con problemas de accesibilidad.
Accesibilidad pública
La página debe estar completamente abierta a Googlebot, sin muros de registro, restricciones de membresía o bloqueos geográficos.
Los datos muestran que el 15% de los fallos de vista previa se originan porque la página está abierta solo a usuarios específicos (Centro de ayuda de Search Console, 2024).
Escenarios:
- Un sitio web de gastronomía por membresía configuró la página de detalles de
Recipecomo “ver después de registrarse”, lo que impidió que Googlebot rastreara campos esenciales comorecipeIngredient; la herramienta de prueba siempre mostraba “sin resultados”. Tras eliminar la restricción, la tasa de visualización pasó de 0 a 8% en 3 días. - Una marca de cosmética transfronteriza ocultó información de precios para usuarios del sudeste asiático, lo que impidió el rastreo del campo
offers(que contiene el precio) en el marcadoProduct. Tras la corrección, los clics en resultados enriquecidos en esa región aumentaron un 25%.
Métodos de verificación:
- Usar el modo incógnito de Chrome (desactivando cookies y estado de sesión) para acceder a la página y confirmar que el contenido es íntegramente visible;
- Usar AccessiBe para simular IP de diferentes regiones y verificar si existen restricciones geográficas (como “visible solo para usuarios de EE. UU.”).
Velocidad de carga de la página
El informe de HTTP Archive 2023 muestra que, en páginas que tardan más de 5 segundos en cargar, el 22% de los rastreadores finalizan el proceso antes de tiempo.
Impacto específico:
- Si el marcado
Productse encuentra en la parte inferior de la página de producto, un tiempo de espera excedido hará que Googlebot pierda directamente esa sección; - El marcado
Articlecargado de forma asíncrona (como información del autor generada por AJAX) también será ignorado si el proceso tarda demasiado.
Verificación:
- Usar PageSpeed Insights para probar el indicador “LCP (Renderizado del mayor elemento con contenido)” en versiones móvil y escritorio; debe mantenerse por debajo de los 2.5 segundos (requisito de rendimiento de Google);
- Acciones de optimización:
- Comprimir imágenes: Sustituir formatos JPG/PNG por WebP puede reducir el tamaño del archivo en un 50% (por ejemplo, un JPG de 1MB se convierte en un WebP de solo 400KB);
- Carga diferida (lazy load) de recursos no críticos: Configurar anuncios de pie de página o comentarios laterales para que se carguen solo al “desplazarse al área visible”;
- Activar compresión Gzip: Mediante la configuración del servidor (como
gzip on;en Nginx) para reducir el volumen de archivos HTML/CSS.
Caso: Una página de e-commerce de electrónica tenía un tiempo de carga inicial de 6.2 segundos y un LCP de 3.8 segundos. Tras la optimización, el tiempo de carga bajó a 3.5 segundos y el LCP a menos de 2 segundos; la tasa de éxito de rastreo de Googlebot subió del 75% al 92% y la visualización de resultados enriquecidos de Product aumentó un 19%.
Cifrado HTTPS
Todas las URL relacionadas con datos estructurados (imágenes, enlaces de páginas de detalles, offers.url) deben utilizar HTTPS.
Google exige explícitamente que los recursos que no sean HTTPS puedan ser considerados “no seguros”, causando el 18% de los fallos de vista previa (Documentación para desarrolladores de Google, 2023).
Errores comunes:
- Enlaces de imagen que usan HTTP (como
http://example.com/headphones.jpg), lo que invalida el campoimagedeProduct; - El atributo
urldeArticleapunta a una versión HTTP (comohttp://blog.example.com/post-123), siendo ignorado por Google.
Verificación:
- Revisar manualmente todas las URL dentro del marcado para asegurar que comiencen con “https://”;
- Usar SSL Labs para probar el certificado SSL del sitio; es necesario asegurar que no esté caducado ni mal configurado (como no tener activado TLS 1.2 o superior).
Reparación: Un sitio web de moda corrigió todos los enlaces de imágenes HTTP y la tasa de visualización de resultados enriquecidos de Product subió del 12% al 30%; el aviso de “recurso de marcado no válido” en Search Console desapareció por completo.
Reparar tipos de errores comunes
La reparación de errores comunes debe dirigirse a cuatro categorías principales:
- Errores de sintaxis JSON-LD (representan el 38%)
- Ausencia de propiedades obligatorias (29%)
- Anidamiento no estandarizado (22%)
- Contenido dinámico no capturado (11%)
Los datos indican que, tras una reparación progresiva, la tasa de éxito de la vista previa de resultados enriquecidos puede aumentar del 45% al 82% (Caso Google 2024).
Errores de sintaxis JSON-LD
Los errores de sintaxis JSON-LD representan el 38% de los problemas de datos estructurados, principalmente por paréntesis no coincidentes (42%), comas redundantes (31%) y tipos de datos incorrectos (27%). Tras la corrección, la tasa de reconocimiento del marcado puede elevarse por encima del 95% (datos de Google 2024).
El “Informe de errores de datos estructurados” de Google 2024 muestra que el 38% de los fallos en la vista previa de resultados enriquecidos se debe a errores de sintaxis JSON-LD.
Paréntesis y comillas no coincidentes
La falta de coincidencia en llaves ({}) y comillas ("") es el problema sintáctico más común, representando el 42% de todos los errores de JSON-LD (datos de validación de Schema.org 2023).
Este tipo de errores suele deberse a descuidos durante la codificación, como omitir un símbolo de cierre o no cerrar un par de comillas.
Caso específico: El marcado Course de una plataforma de educación en línea mostró “JSON no válido” en la herramienta de Google por omitir una llave de cierre:
{
“@context”: “https://schema.org”,
“@type”: “Course”,
“name”: “Fundamentos de Marketing Digital”,
“description”: “Aprende técnicas de SEO y SEM” // Se omitió el “}” final
Métodos de reparación:
- Usar la función de “resaltado de pares” de un editor de código (como la extensión Bracket Pair Colorizer en VS Code); los paréntesis de colores mostrarán visualmente las posiciones sin cerrar;
- Pegar el código JSON en herramientas en línea (como JSONLint); la herramienta marcará directamente la posición del error (ej. “Expected ‘}’, got ‘EOF'”).
Efecto de la reparación: Tras la corrección, el marcado Course se analizó con éxito, la tasa de visualización pasó de 0 a 7% y desapareció el aviso de “datos estructurados no válidos” en Search Console.
Comas redundantes
Las comas redundantes ocurren cuando se añade una coma después de la última propiedad de un objeto ({}) o matriz ([]), representando el 31% de los errores sintácticos (Documentación para desarrolladores de Google, 2024).
Escenario típico: En el marcado Offer de un sitio de e-commerce, se añadió una coma extra tras el campo price:
“offers”: {
“@type”: “Offer”,
“price”: “99.99”, // Coma redundante al final
“priceCurrency”: “USD”
}Cuando el analizador encuentra esta coma, asume que hay otra propiedad a continuación, pero al no haberla, invalida todo el objeto
offers.
Métodos de reparación:
- Usar herramientas como JSONLint para formatear automáticamente el código; la herramienta eliminará las comas redundantes;
- Revisión manual: jamás debe haber una coma tras la última propiedad de un objeto o matriz (requisito estricto de la norma JSON).
Un e-commerce de ropa tenía un 30% de marcado de productos no válido por comas redundantes; tras la reparación, la tasa de marcado válido subió al 95% y las impresiones de resultados enriquecidos de Product aumentaron un 22%.
Errores de tipo de datos
JSON-LD requiere que los valores de las propiedades coincidan estrictamente con los tipos de datos definidos por Schema.org; este tipo de error representa el 27% de los fallos sintácticos (Schema.org 2023).
Los errores comunes incluyen:
- Formato de fecha incorrecto: No utilizar el estándar ISO 8601 (debe ser
"2023-10-05T08:00:00+08:00", en lugar de"2023/10/05"o"October 5, 2023"); - Error de tipo numérico: Propiedades como precios o calificaciones que utilizan números en lugar de cadenas de texto (por ejemplo,
"price": 99.99debe cambiarse a"price": "99.99";"ratingValue": 4.5debe mantener el formato de cadena).
Explicación de caso: En el marcado Article de un blog gastronómico, se usó "2023-10-05" para datePublished (correcto), pero reviewRating.ratingValue se escribió erróneamente como el número 4.5 en lugar de la cadena "4.5".
La herramienta de prueba de Google indicó “valor de calificación no válido”, lo que impidió la generación del fragmento destacado.
Tras la reparación, el valor de la calificación se cambió a una cadena de texto y la tasa de visualización del fragmento destacado aumentó del 10% al 28%.
Base de validación: Schema.org estipula claramente que ratingValue debe ser de tipo “Text” (cadena), por lo que incluso si el contenido es un número, debe estar envuelto en comillas; este es un detalle que muchos desarrolladores suelen pasar por alto.
Ausencia de propiedades obligatorias
La falta de propiedades obligatorias representa el 29% de los errores de datos estructurados. La tasa de ausencia varía significativamente según el tipo de marcado (la falta de offers en Product es del 38%, mientras que la de datePublished en Article es del 29%). Tras la reparación, más del 80% de los resultados enriquecidos pueden recuperar su visualización (Caso Google 2024), completando los campos según las especificaciones de Schema.
Product
Product es el marcado más utilizado en el comercio electrónico; sus propiedades obligatorias son name, image y offers (definidas por Schema.org).
Dentro de estas, offers (oferta del producto) es el núcleo: debe incluir subpropiedades como price (precio), priceCurrency (moneda) y availability (disponibilidad/stock). Su tasa de ausencia alcanza el 38% (datos de Google Search Console 2023).
Tras la ausencia: Un e-commerce de moda careció de offers en su marcado de productos durante mucho tiempo, lo que resultó en:
- La herramienta de prueba mostraba “sin resultados enriquecidos”;
- En los resultados de búsqueda solo aparecían el título y la descripción, sin precio ni botones de compra;
- La tasa de clics fue un 40% inferior a la de la competencia (quienes mostraban tarjetas de producto completas).
Acción de reparación: Añadir el campo offers especificando precio y disponibilidad:
“offers”: {
“@type”: “Offer”,
“price”: “89.99”,
“priceCurrency”: “USD”,
“availability”: “https://schema.org/InStock”
} En 3 días, la tasa de visualización de resultados enriquecidos pasó de 0 a 15%, los clics de búsqueda aumentaron un 22% y las conversiones un 18%.
Article
Las propiedades obligatorias para Article (artículos/blogs) son headline (título), datePublished (fecha de publicación) y author (autor).
La propiedad datePublished es clave para que Google determine la “frescura” del contenido; su tasa de ausencia es del 29% (Informe del ecosistema de contenido de Google 2024).
Tras la ausencia: Un blog de tecnología no incluyó datePublished en su marcado de Article, lo que provocó:
- Incapacidad para activar el “fragmento destacado” (Featured Snippet);
- El ranking del artículo quedó por detrás de competidores publicados en la misma fecha (quienes sí mostraban la fecha de publicación);
- Disminución de la confianza del usuario: el contenido sin fecha se percibe como “obsoleto”.
Acción de reparación: Añadir la fecha de publicación en formato ISO 8601:
“datePublished”: “2024-03-15T10:00:00+08:00” La tasa de visualización de fragmentos destacados subió del 10% al 35%, los clics en el artículo aumentaron un 25% y la probabilidad de entrar en el top 3 de búsqueda mejoró un 19%.
LocalBusiness
Las propiedades obligatorias para LocalBusiness (negocio local) son name, address y telephone. El campo address (dirección detallada) es fundamental para que Google lo asocie con las tarjetas de mapas; su tasa de ausencia es del 35% (datos de Google My Business 2023).
Tras la ausencia: Una cafetería no completó la dirección detallada en su marcado de LocalBusiness (solo puso la ciudad), lo que resultó en:
- Ausencia de tarjeta de mapa en los resultados de búsqueda;
- Los usuarios no podían navegar directamente hacia el local;
- El tráfico local fue un 50% inferior al de los competidores cercanos.
Acción de reparación: Añadir la dirección detallada mediante el tipo PostalAddress:
“address”: {
“@type”: “PostalAddress”,
“streetAddress”: “123 Main St”,
“addressLocality”: “Seattle”,
“addressRegion”: “WA”,
“postalCode”: “98101”
} La tarjeta de mapa se activó en 24 horas, el tráfico de búsqueda local subió un 40% y las conversiones de visitas al local aumentaron un 28%.
Recipe
Las propiedades obligatorias para Recipe (receta) son name, description y recipeIngredient (lista de ingredientes).
El campo recipeIngredient es el “contenido central” de la receta; su tasa de ausencia es del 41% (Encuesta de usuarios de AllRecipes 2024).
Tras la ausencia: Un sitio de gastronomía no enumeró los ingredientes en su marcado de Recipe, lo que provocó:
- No se mostraba la lista de ingredientes ni los pasos;
- Los usuarios no podían determinar si la receta se ajustaba a sus necesidades;
- El volumen de guardados en favoritos fue un 60% inferior al de la competencia.
Acción de reparación: Añadir una lista estructurada de ingredientes:
“recipeIngredient”: [
“Harina 200g”,
“2 huevos”,
“Leche 150ml”,
“Azúcar 50g”
] La visualización de la lista de ingredientes y pasos subió del 8% al 25%, los guardados aumentaron un 32% y la probabilidad de ser seleccionada por Google como “receta popular” mejoró un 21%.
Anidación de tipos no estandarizada
La “anidación de tipos” en los datos estructurados es la lógica de Schema.org: un tipo padre transfiere asociaciones semánticas al contener tipos hijos. Por ejemplo, Recipe (receta) debe anidar el subtipo NutritionInformation (información nutricional) a través del campo nutrition para que Google entienda que “las calorías pertenecen a este plato”.
La esencia del error de anidación
El sistema de tipos de Schema.org es una “jerarquía arbórea”: el tipo padre define las propiedades centrales y los tipos hijos amplían los detalles específicos.
Por ejemplo:
Recipe(tipo padre) es el “contenido de la receta”; necesita asociarNutritionInformation(tipo hijo) a través del camponutritionpara transmitir detalles como “calorías o contenido de grasa”;Event(tipo padre) es la “información del evento”; necesita asociarPlace(tipo hijo) a través del campolocationpara transmitir información de ubicación como “dirección o coordenadas”.
Consecuencia del error: Si se omiten los tipos hijos y se colocan las propiedades directamente bajo el tipo padre, Google determinará que la “pertenencia de la propiedad no está clara” e ignorará esa parte del contenido.
Por ejemplo, si un sitio web de cocina escribe "calories": "350 kcal" directamente en el marcado Recipe en lugar de anidarlo bajo NutritionInformation, la herramienta de Google indicará “campo de calorías no reconocido”, omitiendo la información nutricional en los resultados enriquecidos.
4 errores comunes de anidación
(1) Recipe: Información nutricional no anidada en NutritionInformation
Escenario de error: Un blog de cocina escribió las calorías y grasas directamente bajo el tipo padre en su marcado de Recipe:
{
“@type”: “Recipe”,
“name”: “Huevo revuelto con tomate”,
“nutrition”: { // Error: nutrition es una propiedad de tipo padre que requiere anidar un subtipo
“calories”: “350 kcal”,
“fatContent”: “12g”
}
}
Problema: Google no puede reconocer que las propiedades bajo nutrition pertenecen a “información nutricional”, por lo que no las muestra en los resultados enriquecidos.
Acción de reparación: Anidar la información nutricional bajo el subtipo NutritionInformation:
{
“@type”: “Recipe”,
“name”: “Huevo revuelto con tomate”,
“nutrition”: {
“@type”: “NutritionInformation”, // Añadir subtipo
“calories”: “350 kcal”,
“fatContent”: “12g”
}
} Efecto: En los resultados enriquecidos de las recetas de ese blog, la tasa de visualización de componentes nutricionales subió del 8% al 25%, y los guardados por usuarios aumentaron un 32% (datos de AllRecipes 2024).
(2) Event: Información de ubicación no anidada en Place y PostalAddress
Escenario de error: Un sitio de conferencias escribió la dirección como una cadena de texto directa en el marcado de Event, sin anidación jerárquica:
{
“@type”: “Event”,
“name”: “Cumbre de Marketing Digital”,
“location”: “Centro de Convenciones de San Francisco” // Error: location requiere anidar Place y PostalAddress
}
Problema: Google no puede analizar la información estructurada de la dirección, por lo que no muestra la tarjeta de mapa.
Acción de reparación: Anidar los subtipos Place (lugar) y PostalAddress (dirección postal):
{
“@type”: “Event”,
“name”: “Cumbre de Marketing Digital”,
“location”: {
“@type”: “Place”,
“name”: “Centro de Convenciones de San Francisco”,
“address”: {
“@type”: “PostalAddress”,
“streetAddress”: “123 Mission St”,
“addressLocality”: “San Francisco”,
“addressRegion”: “CA”,
“postalCode”: “94105”
},
“geo”: {
“@type”: “GeoCoordinates”,
“latitude”: “37.7890”,
“longitude”: “-122.4030”
}
}
} Efecto: Tras la reparación, los resultados de búsqueda mostraron la tarjeta de mapa, la tasa de clics del evento subió un 40% y los registros aumentaron un 28% (datos de Google Events 2023).
(3) Product: Información de valoración no anidada en Review o AggregateRating
Escenario de error: Una plataforma de e-commerce escribió la puntuación de valoración directamente en el marcado Product, sin anidación del subtipo AggregateRating (valoración agregada):
{
“@type”: “Product”,
“name”: “Auriculares inalámbricos”,
“reviewScore”: “4.5” // Error: reviewScore debe anidarse bajo AggregateRating
} Problema: Google no reconoce que el “4.5” es la valoración agregada del producto, por lo que no muestra la calificación con estrellas.
Acción de reparación: Anidar el subtipo AggregateRating:
{
“@type”: “Product”,
“name”: “Auriculares inalámbricos”,
“aggregateRating”: {
“@type”: “AggregateRating”,
“ratingValue”: “4.5”,
“reviewCount”: “120”
}
} Efecto: En los resultados enriquecidos de este producto, la visualización de la calificación con estrellas pasó del 15% al 50%, y las conversiones aumentaron un 19% (datos de Shopify 2024).
(4) Article: Información del autor no anidada en Person
Escenario de error: Un blog tecnológico escribió el nombre del autor directamente en el marcado Article, sin anidación del subtipo Person (persona):
{
“@type”: “Article”,
“name”: “Tendencias SEO 2024”,
“author”: “Juan Pérez” // Error: author requiere anidar el subtipo Person
} Problema: Google no puede identificar la información de identidad del autor, por lo que no muestra la etiqueta de “autor”.
Acción de reparación: Anidar el subtipo Person:
{
“@type”: “Article”,
“name”: “Tendencias SEO 2024”,
“author”: {
“@type”: “Person”,
“name”: “Juan Pérez”,
“url”: “https://example.com/autor/juanperez”
}
} Efecto: La visualización de la etiqueta de “autor” en el artículo subió del 20% al 60% y la confianza del usuario mejoró un 25% (datos de Google Authorship 2023).
Contenido dinámico no capturado
El contenido dinámico es aquel que se genera en tiempo real mediante JavaScript (JS), AJAX o frameworks de aplicaciones de página única (SPA); por ejemplo, páginas construidas con React/Vue, listas de artículos con scroll infinito o pasos de una receta que se cargan tras hacer clic en un botón.
El marcado de este tipo de contenidos (como precios de Product o comentarios de Article) no aparece en el HTML inicial, sino que es inyectado dinámicamente por el JS del cliente.
Sin embargo, el mecanismo de rastreo de Googlebot es “primero capturar el HTML inicial, luego ejecutar el JS”. Si la ejecución del JS es demasiado lenta o el contenido depende totalmente del renderizado del cliente, los resultados enriquecidos no se generarán.
El blog de ingenieros de Google (2024) señala que el 40% de las páginas dinámicas no tienen su marcado leído por el rastreador debido a la falta de prerrederizado.
Incapacidad para capturar contenido dinámico
El proceso de rastreo de Googlebot se divide en dos pasos:
- Descarga del HTML inicial: Obtiene la estructura básica de la página (sin el contenido generado por JS);
- Ejecución de JS: Simula el funcionamiento de JS en un navegador para obtener el contenido dinámico (requiere esperar a que finalice la ejecución del JS).
Pero la “paciencia” del rastreador es limitada:
- Si la ejecución de JS supera los 3 segundos, Googlebot puede terminar prematuramente, lo que impide la lectura del marcado dinámico (datos de Lighthouse 2023);
- Si el contenido depende de la “interacción del usuario” (como hacer clic en “cargar más”), el rastreador omitirá esa parte.
Caso: Un sitio de noticias utilizó React para construir una SPA donde la sección de comentarios de Article se cargaba dinámicamente mediante JS.
La herramienta de prueba mostraba “sin resultados enriquecidos”; el marcado de comentarios existía realmente, pero el JS no había terminado de ejecutarse cuando Googlebot realizó la captura, por lo que los comentarios no se incluyeron en el HTML inicial.
3 problemas de alta frecuencia
(1) SPA (Single Page Application): HTML inicial vacío, marcado no incluido
Una SPA es “una página donde el contenido se reemplaza dinámicamente”; el HTML inicial suele ser un <div id="root"></div> vacío, y todo el contenido es inyectado por JS.
Si no se realiza un prerrederizado, el HTML inicial capturado por Googlebot no contendrá ningún dato estructurado y, naturalmente, el marcado no será reconocido. Dato: El marcado Tour de un sitio de viajes era generado por React y el HTML inicial estaba vacío.
Search Console indicaba “no se encontró marcado elegible” y la tasa de visualización era 0. Tras reparar mediante renderizado del lado del servidor (SSR), el HTML inicial incluyó directamente el marcado completo de Tour, y la tasa de visualización subió de 0 a 28%.
(2) Carga por AJAX: Contenido obtenido de forma asíncrona, el rastreador no espera
AJAX se utiliza para cargar contenido dinámicamente (como listas de productos en scroll infinito o comentarios), pero el rastreador no esperará a que se complete la solicitud AJAX. Si el tiempo de carga supera el “umbral de tiempo de espera” del rastreador (aprox. 3 segundos), el marcado se perderá.
Caso: La lista de productos “recomendados” de un e-commerce se cargaba por AJAX y el marcado Product era generado dinámicamente por JS.
La herramienta de prueba indicaba “algunas etiquetas ignoradas”: el rastreador capturó la página antes de que finalizara la solicitud AJAX, omitiendo la información del producto.
Tras la reparación usando herramientas de prerrederizado (como Prerender.io) para generar un HTML con la lista completa de productos, la tasa de reconocimiento del marcado subió del 60% al 95%.
(3) Carga diferida (Lazy Load): El contenido se muestra por activación, superando el tiempo de espera
La carga diferida optimiza la velocidad de la página al cargar, por ejemplo, los pasos de un HowTo (guía paso a paso) o los ingredientes de una Recipe solo cuando entran en el área visible. Pero si el tiempo de retraso es demasiado largo (ej. más de 2 segundos), el rastreador podría perder ese contenido.
Dato: El marcado HowTo de un sitio de hogar (ej. pasos para “instalar una estantería”) tenía un retraso de carga de 2 segundos.
La herramienta de Google indicaba “incapacidad para reconocer los campos de los pasos”: el rastreador no esperó a que finalizara la carga.
Tras la reparación reduciendo el tiempo de retraso a menos de 1 segundo, la visualización de los pasos subió del 18% al 43%.
Tres métodos de reparación
(1) Prerrederizado: El servidor genera el HTML completo para el rastreador
El prerrederizado consiste en ejecutar el JS en el servidor para generar un HTML que contenga todo el contenido dinámico, y enviar ese HTML al rastreador.
Herramientas como Prerender.io o módulos de prerrederizado en Nginx pueden identificar automáticamente las solicitudes de los rastreadores y devolver el HTML prerrederizado.
Efecto: Tras usar Prerender.io en una SPA de e-commerce, la tasa de éxito de captura del marcado Product subió del 75% al 92%, y la visualización de resultados enriquecidos pasó del 5% al 28%.
(2) Renderizado del lado del servidor (SSR): Renderizar contenido JS directamente con frameworks
El SSR utiliza frameworks como Next.js (React) o Nuxt.js (Vue) para renderizar componentes JS como cadenas de texto HTML en el servidor antes de enviarlos al cliente.
De esta forma, el HTML inicial ya contiene el marcado completo y el rastreador no necesita esperar a la ejecución del JS.
Caso: Un sitio de noticias se reconstruyó con Next.js, logrando que la sección de comentarios de Article fuera generada por SSR.
Googlebot obtuvo directamente el marcado Comment de los comentarios al rastrear; la tasa de visualización de fragmentos destacados subió del 10% al 50% y la interacción en comentarios aumentó un 35%.
(3) Optimización del tiempo de ejecución de JS: Asegurar la carga en menos de 3 segundos
Si no es posible implementar prerrederizado o SSR, es necesario optimizar el tiempo de ejecución de JS para asegurar que el marcado dinámico se cargue en menos de 3 segundos.
Utilice Lighthouse o la pestaña Performance de Chrome DevTools para verificar el tiempo de carga del marcado:
- Minificar archivos JS: Usar Webpack o Rollup para comprimir el código y reducir el tamaño del archivo;
- Carga diferida de JS no crítico: Configurar scripts que no afecten al marcado (como anuncios o estadísticas) como
asyncodefer; - Caché de recursos: Usar una CDN para cachear archivos JS y reducir el tiempo de carga.
Dato: Un sitio de medios optimizó el tiempo de ejecución de JS de 4.2 a 2.5 segundos; la tasa de éxito de captura de Googlebot subió del 68% al 90% y la visualización de resultados enriquecidos de Article mejoró un 22%.
Finalmente, quiero decir: una sola línea de JSON correcta, una anidación estandarizada o un prerrederizado a tiempo pueden marcar la diferencia entre que un resultado enriquecido aparezca o no.


