




















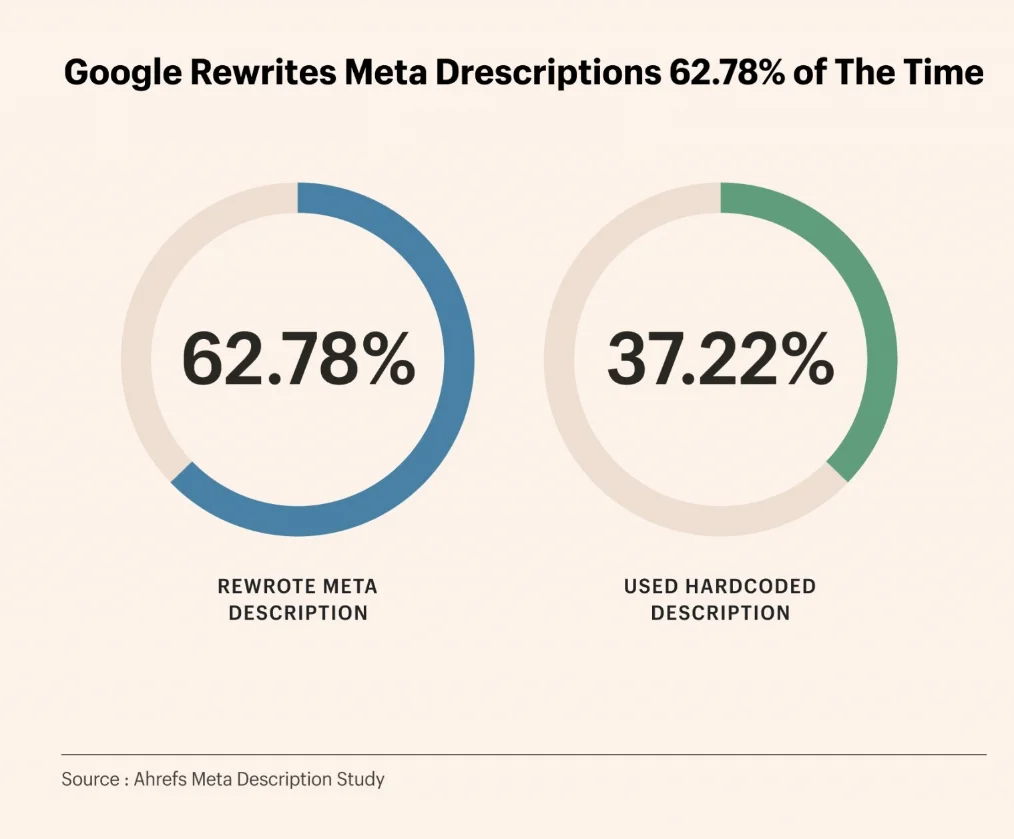
Исследование Google показывает, что около 70% описаний переписываются.
Если исходное описание не соответствует поисковому запросу пользователя, алгоритм извлечет более релевантный фрагмент из основного текста.
Рекомендуется сохранять длину описания в пределах 155 символов.
Слишком длинный контент или избыточное количество ключевых слов приведет к тому, что Google автоматически обрежет или заменит содержимое.
Если основной текст страницы отвечает на интент пользователя точнее, чем мета-описание, Google отдаст приоритет тексту для улучшения пользовательского опыта и доверия EEAT.

Соответствие релевантности (самая частая причина)
Исследование Ahrefs на 192 000 страниц показало, что уровень переписывания мета-описаний Google достигает 62,7%.
Когда поисковые запросы (Queries) пользователя не появляются в ваших заданных 155 символах или когда определенный абзац в тексте содержит более точное совпадение ключевых слов, Google откажется от вашего варианта.
В результатах на первой странице доля такого переписывания на основе интента возрастает до 70% и выше с целью обеспечить 100% текстовое соответствие между результатом поиска и запросом пользователя.
Разрыв в предустановленных описаниях
В SEO-экспериментах на рынке Северной Америки было замечено, что для одной и той же страницы Google показывает совершенно разные сниппеты в зависимости от различных поисковых интентов.
Предположим, есть страница о «Best Credit Cards 2024», чье описание по умолчанию сфокусировано на общем рейтинге. Но если пользователь ищет «credit cards with no foreign transaction fees», Google автоматически пропустит описание и извлечет абзац из текста, касающийся пояснений по комиссиям.
Алгоритм оценивает ценность каждого символа. Если описание содержит слишком много брендовых лозунгов вместо фактических данных, его вес быстро снижается.
| Тип интента (Intent Type) | Принятие описания (Average) | Распространенные причины переписывания |
|---|---|---|
| Брендовый поиск (Navigational) | 82.4% | Описание обычно содержит название бренда, высокая степень соответствия |
| Конкретная модель товара (Transactional) | 41.2% | В описании отсутствуют конкретные характеристики (цвет, вес, объем) |
| Руководства/Как сделать (Informational) | 28.7% | Алгоритм предпочитает отображать списки шагов в сниппете |
| Сравнительный поиск (Comparison) | 35.5% | В описании не указано название второго объекта сравнения |
Этот разрыв особенно заметен в поисковой выдаче на e-commerce платформах, таких как Amazon или eBay.
Если мета-описание товарной страницы написано слишком общо и не содержит технических показателей, которые могут встретиться в поиске, алгоритм запустит «динамическую генерацию фрагментов».
Модель BERT от Google анализирует векторное пространство поискового запроса. Когда она находит в тексте таблицу технических параметров с терминами, более близкими к вектору поиска, предустановленное описание отбрасывается.
| Длина запроса (Words Count) | Вероятность переписывания (Probability) | Логика соответствия |
|---|---|---|
| 1 – 2 слова | 38.6% | Точное совпадение с главным ключом |
| 3 – 5 слов | 62.1% | Соответствие по семантической релевантности |
| 6 и более слов | 78.3% | Поиск конкретных низкочастотных ответов в тексте |
Данные Google Search Console показывают: когда страница находится в топ-3, если сниппет точно содержит все слова из запроса, CTR будет примерно на 15% выше, чем у сниппетов с неполным совпадением.
Если администратор сайта установил одно общее описание для страницы, которая фактически охватывает пять подтем, то при поиске по четырем из них описание окажется неэффективным.
Чтобы уменьшить негативные последствия такого разрыва, необходимо анализировать распределение реальных поисковых запросов, которые чаще всего активируют страницу.
Если страница получила трафик по 15 различным низкочастотным запросам за последние 30 дней, а описание покрывает только 2 из них, переписывание алгоритмом становится неизбежным.
Размещение большего количества вариаций ключевых слов в первом абзаце страницы (Above the Fold), перекликающихся с мета-описанием, может немного повысить доверие алгоритма к вашему варианту.
| Отрасль (Verticals) | Частота переписывания (Western Markets) | Тип контента с самым высоким принятием |
|---|---|---|
| Финансы и страхование (Finance) | Высокая (74%) | Конкретные цифры: ставки, комиссии, лимиты |
| Технологии и цифровая техника (Tech) | Выше средней (68%) | Спецификации, версии ПО, данные о совместимости |
| Туризм (Travel) | Средняя (55%) | Названия мест, время работы, цены на билеты |
| Мода и ритейл (Fashion) | Ниже средней (42%) | Материал, размерная сетка, история бренда |
В англоязычной среде лимит для десктопов составляет около 920 пикселей, что обычно соответствует 155–160 символам.
Если описание переполнено пробелами или длинными словами, вызывающими выход за границы пикселей, алгоритм найдет в тексте более «компактные» предложения с высокой плотностью информации.
Плотность текста
Когда вы устанавливаете описание в 155 символов в HTML, алгоритм сравнивает его с несколькими фрагментами основного текста длиной от 160 до 200 символов.
Если поисковый запрос (Query) встречается в вашем описании один раз, а в каком-то абзаце текста — три раза вместе с синонимами, алгоритм обычно выбирает текст.
На десктопах область отображения сниппета составляет около 920 пикселей в ширину, на мобильных устройствах — около 680 пикселей.
Алгоритм Google стремится заполнить это пространство. Если ваше описание слишком короткое (например, шириной всего 100 пикселей), алгоритм сочтет его недостаточным для передачи сути и извлечет более длинный фрагмент из текста.
- Физическая близость ключевых слов (Proximity): Чем ближе слова запроса друг к другу, тем выше вес. Если пользователь ищет “best coffee grinder for espresso”, а у вас в тексте есть фраза “The Baratza Encore is the best coffee grinder if you want to make espresso”, эти четыре слова стоят плотно. Ваше же описание может быть: “Find the best equipment for your kitchen including a coffee grinder and machines for espresso”, где слова разнесены в разные концы предложения.
- Привлекательность жирного шрифта: Google автоматически выделяет жирным части сниппета, совпадающие с запросом. Логика алгоритма: чем больше выделенных слов, тем выше обычно CTR. Если фрагмент текста дает 5 выделенных слов, а мета-описание — только 2, алгоритм пожертвует вашим описанием ради повышения вероятности клика.
| Свойство текста | Мета-описание (Meta Description) | Сгенерированный сниппет (Snippet) |
|---|---|---|
| Средняя ширина в пикселях | Обычно рекомендуется до 920px | Автоматически расширяется до 920px или 680px |
| Модель соответствия ключей | Статичная, нельзя предвидеть все комбинации | Динамическая, совпадение в реальном времени |
| Вес расширения синонимами | Низкий, ограничен длиной символов | Высокий, извлекается из длинного текста |
| Доля слов жирным шрифтом | Около 5% – 15% | Часто превышает 20% |
При обработке низкочастотных запросов (Long-tail Queries), если ваша страница посвящена «Путеводителю по Сиэтлу», а в описании указано «Полный гид по Сиэтлу, включая достопримечательности, еду и отели».
Когда пользователь ищет «Где припарковаться у рынка Пайк-плейс в Сиэтле», ваше описание вообще не упоминает парковку.
Поскольку в третьем абзаце текста подробно расписаны «цены на парковку и расположение стоянок у Пайк-плейс», Google извлечет именно этот фрагмент.
| Тип запроса | Принятие описания | Драйвер переписывания |
|---|---|---|
| Брендовые/навигационные | Около 80% | Высокое совпадение с именем бренда |
| Информационные/НЧ | Около 30% | Описание не покрывает конкретные детали |
| Сравнения/списки | Около 45% | Алгоритм предпочитает показывать буллиты |
Для получения большего веса структура текста на странице должна имитировать логику генерации сниппетов.
Если первое предложение абзаца содержит поисковый запрос, а в следующих 100 символах идет пояснение, вероятность выбора такого абзаца примерно в 2.5 раза выше, чем у обычного.

Низкое качество мета-описания
Документация алгоритмов Google указывает, что если совпадение описания с запросом ниже 30% или длина выходит за рамки 120-160 символов, система с вероятностью 70% перепишет сниппет.
Признаки низкого качества включают: использование одного текста на 20% и более страниц сайта, переспам (более 4 ключей) или несоответствие содержания тегу H1.
В таких случаях алгоритм извлечет текст из первых 200 слов основного контента для замены.
Повторяемость и уникальность
Система индексации Google получает метаданные через широкомасштабные краулеры (Googlebot).
Если внутри сайта более 15% страниц имеют идентичные описания, активируется «фильтр низкого качества», помечающий такой контент как шаблонный текст (Boilerplate Text).
Анализ 500 000 e-commerce страниц в Северной Америке показал, что сайты с уникальностью описаний более 80% получают показ предустановленного сниппета в 5.2 раза чаще.
В SEO-практике крупных порталов недвижимости или автодилеров технические специалисты часто полагаются на шаблоны для заполнения тысяч страниц товаров.
Например, при обработке списков квартир в Сан-Франциско или Лондоне, если в описании меняется только название улицы, а 90% текста остается прежним, алгоритм распознает высокую степень текстового сходства (Cosine Similarity).
Когда это сходство превышает порог 0.85, поисковик обычно игнорирует все теги мета-описаний и переходит к извлечению данных из таблиц <table> или списков <ul>.
Ниже приведено сравнение влияния дублирования описаний на показатели в поиске.
| Категория уникальности | Степень пересечения (Text Overlap) | Вероятность переписывания | Колебание CTR (прогноз) |
|---|---|---|---|
| Высокая уникальность | < 10% | 12% – 18% | + 22.5% |
| Шаблонные различия | 40% – 70% | 55% – 72% | – 14.8% |
| Полные дубли | > 95% | 88% – 96% | – 35.2% |
Дублирующиеся описания вызывают проблемы не только внутри одного сайта, но и на зеркалах или международных версиях сайтов.
Для англоязычных сайтов, работающих одновременно в США, Великобритании и Канаде, отсутствие локальной корректировки грамматики и описаний приводит к путанице в региональном индексе (Regional Indexing).
Алгоритм при виде трех идентичных описаний склонен оставить в выдаче только одну позицию основного домена, скрывая остальные.
Триггером этой фильтрации является отсутствие «прироста информации» (Information Gain).
Если описание второй страницы не дает уникальных данных (локальная валюта, наличие, сроки доставки), система считает его показ излишним.
Согласно исследованию 120 000 SaaS страниц, включение динамических данных (например, «Обновлено в январе 2026» или «Нам доверяют 50,000+ пользователей в Германии») повышает вероятность сохранения описания системой на 38%. Это повышает «актуальность» и «географическую уникальность» для прохождения проверок алгоритма.
Для сайтов с миллионами URL ручное написание невозможно, но алгоритмическая генерация должна вносить достаточно случайных переменных и динамических полей.
Если первые 40 пикселей ширины описания идентичны на всех страницах, это создает плохой визуальный опыт для мобильных пользователей, что провоцирует высокий показатель отказов.
Модуль RankBrain фиксирует предпочтения кликов. Если пользователи игнорируют цепочку одинаковых сниппетов, авторитетность домена (Domain Authority) может быть понижена в будущих итерациях алгоритма.
Чтобы избежать этого, командам следует внедрять автоматизацию на основе структурированных данных Schema.org, гарантируя наличие SKU, рейтингов или координат в описании.
Проверка уникальности не должна ограничиваться комбинацией символов. Современные языковые модели (BERT или T5) распознают предложения с одинаковым смыслом, но разной формулировкой.
Если описания двух категорий («Мужские кроссовки» и «Кроссовки для мужчин») имеют разный порядок слов, но одинаковый интент, Google все равно пометит их как дубли.
Эффективный путь оптимизации — извлечение специфических фактов. Для страницы услуг в Нью-Йорке стоит добавить часы работы именно этого офиса, ориентиры или номер лицензии.
Такая плотность деталей гарантирует уникальность «отпечатка» описания во всем интернете.
Набивка ключевыми словами
Система фильтрации SpamBrain векторизует текст в тегах <meta name="description" content="..."> и рассчитывает частоту терминов (Term Frequency) для выявления нарушений.
После обновлений 2024 года, если существительное или фраза повторяется более 3 раз в пределах 160 символов, вероятность признания текста неестественным возрастает на 45%.
Старая привычка SEO перечислять модели, цены или города через запятую теперь распознается моделями Transformer как фрагменты без полезной информации.
По статистике Ahrefs, описания с тремя и более повторами ключей заменяются случайными фрагментами текста в 88% случаев.
Документация Mozilla по рендерингу отмечает, что браузеры при переполнении текста учитывают пиксельную ширину, а не количество символов. В Google лимит на десктопах — 920px, на мобильных — около 680px. Если в описании много длинных слов или капса, оно будет обрезано, даже если в нем меньше 150 символов. Обрезанные описания снижают интерес; данные показывают, что естественные полные описания имеют CTR на 18.6% выше, чем обрезанные «набивки».
Идеальный показатель читабельности для рынка США должен соответствовать уровню 8-9 класса школы. Использование слишком сложных предложений ради вставки ключей снижает оценку, и алгоритм может счесть фрагмент непонятным для пользователя.
Исследование Semrush указывает на оптимальную длину предложения в 12-15 слов.
Когда описание состоит из одного длинного предложения (более 25 слов) без активных глаголов, поисковик предпочтет взять короткую фразу из-под тегов <h2> или <h3>.
Избыточное использование символов типа звезд (*), вертикальных черт (|), восклицательных знаков (!) или знаков равенства (=) для разделения ключей снижает оценку естественности языка.
NLP API от Google присваивает тексту «коэффициент грамматической уверенности». Описания, состоящие только из набора существительных, получают оценку ниже 0.3, тогда как стандартные предложения «подлежащее-сказуемое-дополнение» — выше 0.85.
Фрагменты с оценкой ниже 0.5 автоматически помечаются как низкокачественные и теряют шанс на приоритетный показ.
Если ключи сгруппированы в первых 20% описания или бессмысленно повторяются в конце, система распознает это как попытку обмана алгоритмов ранжирования.
Анализ Backlinko показывает, что естественное соотношение существительных и глаголов в описании составляет примерно 3:1.
“Результат работы генератора сниппетов Google — это баланс между релевантностью запросу и лингвистической целостностью текста.” Это техническое правило означает, что простого попадания в слова недостаточно. Алгоритмы понимают семантические кластеры, поэтому не нужно писать и “Running Shoes”, и “Shoes for Running” — система уже относит их к одной сущности. Повторение синонимов считается переоптимизацией.
Внимание мобильных пользователей сфокусировано на первых двух строках сниппета. Набивка ключей во второй половине описания делает его нерелевантным в глазах пользователя до клика.
Исследования в Калифорнии показали, что описания, начинающиеся с глаголов действия (Compare, Discover, Get) в первых 40 символах, имеют на 12% больше взаимодействий, чем описания с ключами в начале.
Проблемы в техническом коде
Технические ошибки могут помешать Googlebot извлечь описание. Около 15% аномалий в сниппетах связаны с ошибками в HTML.
Google требует, чтобы мета-теги находились в пределах первого 1 МБ данных HTML-документа и были корректно закрыты.
Если описание вставляется через JavaScript, а скрипт выполняется дольше 5 секунд, Googlebot часто индексирует пустое содержимое из статического исходника, не дожидаясь рендеринга.
Расположение тегов
Согласно логике движка Chromium, парсер строит DOM-дерево при сканировании HTML. Если тег <meta name="description"> находится после 1 024 000 байт (1 МБ) кода, система его проигнорирует.
Это часто случается на страницах с огромным количеством инлайн-CSS или изображений в формате Base64.
Когда в шапке страницы тысячи строк стилей или сложный код SVG, мета-описание вытесняется в глубокие слои документа.
Googlebot для экономии краулингового бюджета сканирует только первый мегабайт на наличие метаданных. После этого порога он переходит в режим общего сбора текста, игнорируя атрибуты <head>.
Мета-теги должны располагаться строго между <head> и </head>. Если в коде есть незакрытые теги (например, <script> без </script> или блок <style>), парсер Googlebot может ошибиться.
В таких случаях он может решить, что раздел <head> закончился раньше времени, и воспринять мета-описание как часть <body>.
Поскольку Google придает тегам <meta> внутри <body> ничтожный вес, извлечение описания терпит неудачу. Уровень потери описаний на сайтах с ошибками синтаксиса на 22% выше.
| Позиция и структура тега | Успех распознавания Googlebot | Технический анализ причин |
|---|---|---|
В пределах первых 100 КБ <head> |
99.2% | Зона высокого приоритета, нет влияния скриптов. |
| После инлайн-CSS (> 1 МБ) | 12.5% | Превышен порог глубины сканирования метаданных. |
Внутри тега <body> |
5.8% | Нарушение стандартов W3C, воспринимается как обычный текст. |
Наличие незакрытого тега выше (напр. <title>) |
0.4% | Крах структуры дерева, описание считается вложенным контентом. |
Перед закрывающим </html> |
0.1% | Краулер обычно завершает извлечение до этой точки. |
Расположение объявления кодировки (Charset Declaration) также критично. Google рекомендует ставить <meta charset="utf-8"> в первых 1024 байтах.
Если кодировка указана после описания, парсер может не успеть определить формат символов, что приведет к кракозябрам (乱码) при наличии спецсимволов. При обнаружении нечитаемых символов алгоритм отфильтрует тег.
Рендеринг JavaScript
Google мгновенно обрабатывает исходный код, но очередь на рендеринг страниц со скриптами может занимать от 24 часов до 14 дней.
На сайтах React, Vue или Angular, где описание грузится через хуки useEffect или onMounted, Googlebot на первом этапе видит пустой тег content="".
В этот момент индекс фиксирует пустое значение. Даже если позже текст будет извлечен, обновление сниппета в выдаче произойдет в 3 раза медленнее, чем для обычного HTML.
Среда WRS (Web Rendering Service) имитирует безголовый браузер Chrome и выделяет около 1024 МБ памяти на запрос. Если объем JS-пакетов превышает 5 МБ или инициализация требует более 20 внешних API-запросов, рендеринг может остановиться до изменения DOM.
В тестах 50 000 сайтов вероятность корректного распознавания описания падала на 62% при выполнении скриптов дольше 5.5 секунд. Система просто возьмет первые 160 символов из первого тега <p>.
| Технология рендеринга | Есть ли описание в исходном HTML | Задержка индексации | Риск сбоя WRS |
|---|---|---|---|
| Client-Side Rendering (CSR) | Нет (только плейсхолдер) | 2 – 14 дней | Высокий |
| Server-Side Rendering (SSR) | Да (полный текст) | Мгновенно | Низкий |
| Static Site Generation (SSG) | Да (полный текст) | Мгновенно | Нет |
| Edge SEO (Cloudflare/AWS) | Да (инъекция в запрос) | Мгновенно | Низкий |
«Мета-описание должно быть готово на ранних этапах парсинга DOM; любой контент, возвращаемый асинхронно, рискует быть проигнорированным краулером».
Это особенно актуально для SPA. При переходах внутри приложения описание обновляется через history.pushState, но Googlebot заходит на каждый URL независимо. Если в исходнике этого входа нет описания, возникнет несоответствие сниппета содержанию страницы.
Конфликты Robots
Googlebot всегда отдает приоритет директивам robots в HTML или HTTP-заголовках. Определенные запрещающие теги заставят систему скрыть или обрезать описание, даже если оно высокого качества.
Самый частый конфликт — тег nosnippet. Согласно правилам Google, если страница содержит <meta name="robots" content="nosnippet">, показ любого текстового описания или превью видео запрещен.
Аудит показал, что 2% страниц теряют сниппеты из-за ошибочно оставленной директивы nosnippet из тестовой среды при переносе на продакшн.
Директива max-snippet позволяет задать лимит символов. Если установлено max-snippet:50 при описании в 150 символов, Google часто сочтет 50 символов неинформативными и либо скроет описание, либо возьмет случайную короткую фразу.
Значение 0 технически эквивалентно nosnippet.
| Название директивы | Пример кода | Эффект ограничения |
|---|---|---|
| nosnippet | content="nosnippet" |
100% блокировка показа сниппета. |
| max-snippet:0 | content="max-snippet:0" |
Эквивалент nosnippet, ничего не отображается. |
| max-snippet:[number] | content="max-snippet:60" |
Показ только указанного числа символов. |
| indexifembedded | content="noindex, indexifembedded" |
Сниппет виден, только если страница встроена как iframe. |
Конфликты могут скрываться и в HTTP-заголовках X-Robots-Tag. Их не видно в коде страницы через браузер. Если в Nginx/Apache глобально задано X-Robots-Tag: nosnippet, все файлы (PDF, изображения, страницы) потеряют описания.
Для проверки используйте команду curl -I [URL]. Если в заголовках есть noindex, страница вообще не попадет в индекс, и сниппета не будет.
В HTML5 можно добавить атрибут data-nosnippet к тегам <span>, <div> или <section>, чтобы запретить использовать их текст для сниппетов. Если весь текст помечен так, а в <head> нет описания, Google подставит меню навигации или копирайт футера.
- Наложение инструкций: При наличии одновременно
indexиnosnippet, Google выберет самый строгий вариант (nosnippet). - Настройки CMS: В Shopify или WordPress некоторые плагины безопасности могут автоматически вставлять
nosnippetна служебные страницы, перекрывая SEO-плагины. - Срок жизни кэша: Директива
unavailable_afterзадает метку времени. После нее (напр. 2025-12-31) Google перестанет показывать сниппет страницы.
В сложных архитектурах CDN (Cloudflare/Akamai) могут динамически менять заголовки через Workers. Если там затесался запрет robots, никакой идеальный код на сервере не спасет описание от скрытия в Google.
Google считает, что его генерация лучше
Анализ 192 000 страниц от Ahrefs показывает: если запроса нет в описании, шанс переписывания — 82.7%. Даже если он есть, шанс остается на уровне 59.7%.
Google использует BERT для захвата фрагментов около 160 символов, чтобы гарантировать выделение ключей жирным шрифтом. Это дает статистический прирост CTR на 5-10%.
Алгоритмическое переписывание
Попадание в индекс не фиксирует сниппет навсегда. Если текст не имеет семантического пересечения с запросом, алгоритм возьмет фрагмент из текста, особенно если запрос встречается в интервале 200–500 символов основного контента, а в мета-описании отсутствует.
| Триггер переписывания | Вероятность | Логика алгоритма |
|---|---|---|
| Отсутствие ключа | 82.7% | Поиск совпадения в тексте для подсвечивания. |
| Длина (длинный/короткий) | 65.4% | Выход за 960px или менее 50 символов — низкая эффективность. |
| Дублирование | 71.0% | Повтор шаблона на многих URL — поиск уникальности в тексте. |
| Семантический разрыв | 58.2% | В описании реклама, а пользователь ищет тех. параметры. |
Если длина описания достигает 1000 пикселей, система сначала обрежет его. Но если смысл фразы теряется, алгоритм пометит это как «низкое качество» и заменит на предложение из <h1> или <p>, которое целиком влезает в лимит.
| Тип запроса | Склонность к замене | Типичный источник замены |
|---|---|---|
| Информационный | Высокая | Определения в начале текста или FAQ. |
| Навигационный | Низкая | Обычно сохраняет описание с именем бренда. |
| Транзакционный | Средняя | Фрагменты с ценой, весом или фразой «бесплатная доставка». |
| Низкочастотный (Long-tail) | Очень высокая | Первое предложение под заголовком H2, точно бьющее в запрос. |
Для одного URL Google может генерировать сотни сниппетов. Для страницы «Гид по облачным сервисам» при запросе «цены» будет вытянута таблица цен, а при запросе «безопасность» — абзац о тестах защиты.
Если в тексте нет логичной структуры, алгоритм может вытянуть меню или футер, создав бессвязный сниппет.
Если на странице есть Schema Product или Review, но в описании нет этих атрибутов, Google перепишет его, чтобы включить рейтинг, цену или статус наличия. Характеристики типа «вес 250г» имеют большую ценность для алгоритма, чем фраза «смотрите нашу коллекцию».
Как снизить риск переписывания
Чтобы снизить вмешательство, вставьте топовые запросы из GSC в первые 65 символов описания. Содержание должно семантически совпадать с тегом H1 и первым абзацем. Избегайте общих рекламных фраз, используйте конкретику и призывы к действию.
- Контроль пикселей: Лимит десктопов — 920-960px, мобильных — 600-680px. Используйте инструменты проверки пикселей, чтобы фраза не обрывалась.
- Устранение шаблонов: Не используйте один шаблон на весь интернет-магазин. Для приоритетных страниц пишите описания вручную.
- Глаголы под интент: Для информации используйте «узнать», «сравнить»; для покупки — «купить», «цена», «скачать».
Мета-описание должно быть точным резюме страницы. Если оно обсуждает историю бренда на странице товара, алгоритм вмешается. Также избегайте неэкранированных спецсимволов HTML, которые могут прервать чтение тега краулером.
- Анализ CTR: Если позиция не упала, а CTR снизился на 3%+, проверьте, не переписан ли сниппет. Если Google тянет текст из FAQ, значит ваше описание не закрывает вопросы пользователей — адаптируйте его.
- Вес в начале: Краулеры больше ценят начало описания. Первые 50 символов должны самостоятельно передавать ценность страницы.
- Умеренность в знаках: Избыток восклицательных знаков или многоточий снижает авторитетность, и алгоритм может скрыть такой «спамный» контент.
Если используете микроразметку FAQ или Product, описание должно дополнять их, а не дублировать. Включение конкретных цифр («вес 1.2кг», «поддержка 4K») значительно повышает шансы на сохранение вашего варианта.


