




















Le ricerche di Google mostrano che circa 70% delle descrizioni vengono riscritte.
Se la descrizione originale non corrisponde ai termini di ricerca dell’utente, l’algoritmo estrapolerà frammenti più pertinenti dal corpo del testo.
Si consiglia di mantenere le descrizioni entro 155 caratteri.
Contenuti troppo lunghi o con un eccessivo accumulo di parole chiave porteranno Google a troncare automaticamente o a sostituire il contenuto.
Se il corpo della pagina risponde all’intento dell’utente in modo più preciso rispetto al meta description, Google darà priorità al testo della pagina per migliorare l’esperienza di ricerca e il livello di fiducia EEAT.

Corrispondenza di pertinenza (causa più comune)
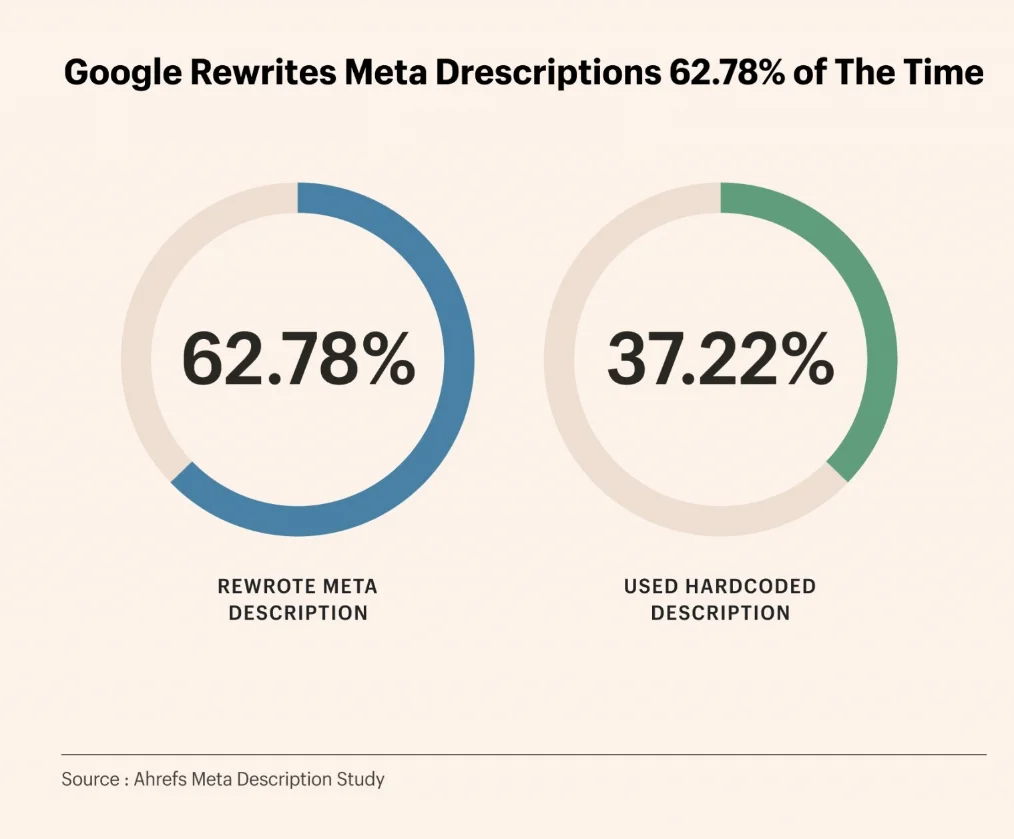
Un’indagine di Ahrefs su 192.000 pagine mostra che il tasso di riscrittura dei meta description da parte di Google raggiunge il 62,7%.
Quando i termini di ricerca dell’utente (Queries) non appaiono nei 155 caratteri preimpostati, o quando un paragrafo del testo contiene una corrispondenza di parole chiave più precisa, Google scarterà la tua soluzione predefinita.
Nei risultati della prima pagina, questa percentuale di riscrittura basata sull’intento sale a oltre il 70%, con l’obiettivo di far corrispondere letteralmente al 100% il testo dei risultati di ricerca con i termini cercati dall’utente.
Scollegamento della descrizione preimpostata
In esperimenti SEO sul mercato nordamericano, è stato osservato che per la stessa pagina, Google mostra snippet completamente diversi a seconda dei differenti intenti di ricerca.
Supponiamo una pagina su “Best Credit Cards 2024” la cui descrizione predefinita si concentra sulla classifica generale; se un utente cerca “credit cards with no foreign transaction fees”, Google salterà automaticamente la descrizione preimpostata per catturare il paragrafo relativo alle spiegazioni delle commissioni nel testo.
L’algoritmo valuta il valore di contributo di ogni carattere; se la descrizione preimpostata contiene troppi slogan pubblicitari del brand invece di dati fattuali, il suo peso diminuirà rapidamente.
| Tipo di termine di ricerca (Intent Type) | Tasso di adozione descrizione predefinita (Average) | Causa comune di riscrittura |
|---|---|---|
| Ricerca di brand (Navigational) | 82.4% | La descrizione solitamente contiene il nome del brand, alta corrispondenza |
| Modello specifico di prodotto (Transactional) | 41.2% | Mancanza di parametri tecnici specifici (es. colore, peso, capacità) |
| Guide/How-to (Informational) | 28.7% | L’algoritmo tende a mostrare elenchi di passaggi nello snippet |
| Ricerche comparative (Comparison) | 35.5% | La descrizione non menziona il nome del secondo oggetto di confronto |
Questa situazione di scollegamento è particolarmente evidente nelle performance di ricerca di piattaforme e-commerce come Amazon o eBay.
Se la meta description di una pagina prodotto è scritta in modo troppo generico e non include gli indicatori tecnici specifici che potrebbero apparire nella ricerca dell’utente, l’algoritmo attiverà la “generazione dinamica di frammenti”.
Il modello BERT di Google analizza lo spazio vettoriale dei termini di ricerca; quando scopre che una tabella di parametri tecnici nel testo contiene termini più vicini al vettore di ricerca, la descrizione preimpostata verrà abbandonata.
| Lunghezza query (Words Count) | Probabilità riscrittura meta description (Probability) | Tendenza logica di corrispondenza |
|---|---|---|
| 1 – 2 parole | 38.6% | Corrispondenza esatta della parola chiave principale |
| 3 – 5 parole | 62.1% | Corrispondenza per pertinenza semantica |
| Oltre 6 parole | 78.3% | Ricerca di risposte specifiche long-tail nel testo |
Nel confronto dei dati di Google Search Console, si nota che quando una pagina si trova tra le prime tre posizioni, se lo snippet include con precisione tutti i termini cercati dall’utente, il suo tasso di clic (CTR) è superiore di circa il 15% rispetto a uno snippet con corrispondenza incompleta.
Se un amministratore di sito imposta solo una meta description generica per una pagina che in realtà copre cinque diversi sotto-argomenti, la descrizione preimpostata fallirà di fronte alle ricerche riguardanti quattro di quei sotto-argomenti.
Per ridurre l’impatto negativo di questo scollegamento, diventa necessario analizzare la distribuzione dei termini di ricerca reali che attivano frequentemente la pagina.
Se una pagina ha ottenuto traffico attraverso 15 diverse parole chiave long-tail negli ultimi 30 giorni, ma la meta description attuale ne copre solo 2, la riscrittura dell’algoritmo è una scelta inevitabile.
Disporre più varianti di termini che richiamano la meta description nel primo paragrafo della pagina (Above the Fold) può aumentare leggermente la fiducia dell’algoritmo nell’adozione della stessa.
| Settore (Verticals) | Frequenza riscrittura snippet (Western Markets) | Tipo di contenuto con più alto tasso di adozione |
|---|---|---|
| Finanza e Assicurazioni (Finance) | Alta (74%) | Numeri specifici come tassi di interesse, tariffe, massimali |
| Tecnologia e Digitale (Tech) | Medio-Alta (68%) | Specifiche hardware, numeri di versione software, compatibilità |
| Turismo (Travel) | Media (55%) | Nomi di luoghi, orari di apertura, informazioni sui prezzi |
| Moda e Retail (Fashion) | Medio-Bassa (42%) | Materiali, range di taglie, storia del brand |
In un ambiente di ricerca in inglese, il limite per desktop è di circa 920 pixel, il che corrisponde solitamente a 155-160 caratteri a mezza larghezza.
Se la descrizione preimpostata eccede i pixel a causa di troppi spazi o parole lunghe, l’algoritmo cercherà automaticamente nel testo frasi più “compatte” e con maggiore densità informativa.
Densità del testo
Quando imposti una meta description di 155 caratteri in HTML, l’algoritmo la confronterà con diversi frammenti da 160 a 200 caratteri presenti nel testo della pagina.
Se il termine di ricerca dell’utente (Query) appare solo una volta nella tua descrizione preimpostata, mentre in un paragrafo del testo appare tre volte e include sinonimi pertinenti, l’algoritmo sceglierà solitamente il testo della pagina.
Sui dispositivi desktop, lo spazio di visualizzazione dello snippet nei risultati di ricerca è largo circa 920 pixel, mentre sui dispositivi mobili è di circa 680 pixel.
L’algoritmo di Google tende a riempire questi spazi; se la tua descrizione preimpostata è troppo corta (ad esempio solo 100 pixel di larghezza), l’algoritmo riterrà che non sia sufficiente a comunicare il contenuto della pagina, catturando quindi frammenti più lunghi dal testo per riempire lo spazio rimanente.
- Prossimità fisica delle parole chiave (Proximity): Più vicini sono i termini di ricerca tra loro, maggiore è il peso della visualizzazione. Se un utente cerca “best coffee grinder for espresso” e tu nel testo hai una frase come “The Baratza Encore is the best coffee grinder if you want to make espresso”, queste quattro parole chiave sono strettamente allineate. La tua meta description potrebbe essere invece “Find the best equipment for your kitchen including a coffee grinder and machines for espresso”, dove le parole chiave sono sparse alle due estremità della frase.
- Attrattiva dell’effetto grassetto: Google applica automaticamente il grassetto alle parti dello snippet che corrispondono ai termini di ricerca. La logica dell’algoritmo è: più parole in grassetto ci sono, più alto è solitamente il CTR. Se un frammento di testo può generare 5 parole in grassetto mentre la meta description ne genera solo 2, l’algoritmo sacrificherà la tua descrizione preimpostata per aumentare la probabilità di clic dell’utente.
| Attributi del testo | Meta Description predefinita | Snippet generato dall’algoritmo |
|---|---|---|
| Larghezza media in pixel | Solitamente consigliata entro 920px | Estensione automatica al limite di 920px o 680px |
| Modalità corrispondenza parole chiave | Statica, impossibile prevedere tutte le combinazioni | Cattura dinamica, corrispondenza in tempo reale |
| Peso estensione sinonimi | Basso, limitato dalla lunghezza caratteri | Alto, può estrarre termini correlati dal testo lungo |
| Percentuale parole in grassetto | Circa 5% – 15% | Spesso oltre il 20% |
Nel gestire ricerche long-tail, supponiamo che la tua pagina riguardi una “Guida turistica di Seattle” e la meta description sia “Guida completa ai viaggi a Seattle, include suggerimenti su attrazioni, cibo e hotel”.
Quando un utente cerca “Guida parcheggio Pike Place Market Seattle”, la tua meta description non menziona affatto le informazioni sui parcheggi.
Poiché il terzo paragrafo del testo descrive dettagliatamente “costi del parcheggio e distribuzione dei parcheggi vicino al Pike Place Market”, Google estrarrà questo paragrafo come snippet.
| Tipo di termine di ricerca | Tasso adozione descrizione predefinita | Fattori trainanti della riscrittura |
|---|---|---|
| Brand / Parole di navigazione | Circa 80% | La descrizione contiene spesso il brand, alta corrispondenza |
| Informativo / Parole long-tail | Circa 30% | La descrizione non copre dettagli specifici |
| Confronto / Elenchi | Circa 45% | L’algoritmo preferisce mostrare elenchi puntati (Bullet points) |
Per ottenere un peso di visualizzazione maggiore, la struttura del testo all’interno della pagina deve simulare la logica di generazione degli snippet.
Se la prima frase di un paragrafo contiene i termini di ricerca e i successivi 100 caratteri contengono testo esplicativo pertinente, la probabilità che questo paragrafo venga scelto è circa 2,5 volte superiore rispetto a un paragrafo normale.

Meta description di bassa qualità
La documentazione dell’algoritmo di Google indica che se la sovrapposizione tra la meta description e i termini di ricerca dell’utente è inferiore al 30%, o se la lunghezza non è compresa tra 120-160 caratteri a mezza larghezza, il sistema ha una probabilità del 70% di riscrivere lo snippet.
Segnali di bassa qualità includono: oltre il 20% delle pagine del sito che usano lo stesso testo, accumulo di oltre 4 parole chiave, o descrizione non coerente con il tag H1 della pagina.
Queste situazioni portano l’algoritmo a estrarre testo dalle prime 200 parole del corpo della pagina come sostituto.
Ripetitività e unicità
Il sistema di indicizzazione di Google ottiene i metadati delle pagine web attraverso crawler paralleli su larga scala (Googlebot).
Se all’interno di un sito oltre il 15% delle pagine condivide lo stesso identico testo di meta description, l’algoritmo attiverà il “rilevatore di contenuti di bassa qualità”, classificando tale comportamento come testo predefinito generato su scala (Boilerplate Text).
Secondo l’analisi dei dati di 500.000 pagine e-commerce nordamericane, i siti con oltre l’80% di meta description uniche hanno una probabilità di mostrare lo snippet preimpostato nei risultati di ricerca (SERP) 5,2 volte superiore rispetto ai siti che utilizzano descrizioni duplicate.
Nelle pratiche SEO di grandi piattaforme immobiliari o siti di compravendita auto, i tecnici spesso si affidano a template predefiniti per riempire migliaia di pagine di dettaglio.
Ad esempio, nel gestire migliaia di annunci di appartamenti a San Francisco o Londra, se la meta description cambia solo il nome della via mantenendo il restante 90% del testo, l’algoritmo di generazione degli snippet di Google identificherà un’altissima sovrapposizione testuale (Cosine Similarity).
Quando questa somiglianza supera la soglia dello 0,85, il motore di ricerca sceglierà solitamente di ignorare tutti i tag meta description, passando a catturare i dati dalle <table> o i parametri tecnici dagli elenchi <ul> di ogni pagina.
La tabella seguente confronta nel dettaglio l’impatto di diversi gradi di ripetizione delle meta description sulle performance del motore di ricerca.
| Categoria di unicità meta description | Percentuale sovrapposizione (Text Overlap) | Probabilità di riscrittura Google | Fluttuazione CTR stimata |
|---|---|---|---|
| Altamente unica | < 10% | 12% – 18% | + 22.5% |
| Differenze da template | 40% – 70% | 55% – 72% | – 14.8% |
| Completamente ripetitiva | > 95% | 88% – 96% | – 35.2% |
Le meta description duplicate non generano feedback negativi solo all’interno di un singolo sito, ma causano seri problemi di indicizzazione anche in siti mirror o siti internazionali su domini diversi.
Per i siti in inglese operanti simultaneamente negli Stati Uniti, nel Regno Unito e in Canada, se la grammatica della descrizione non viene ottimizzata per le caratteristiche locali, la semplice copia dei metadati confonderà l’indicizzazione regionale (Regional Indexing) di Google.
L’algoritmo, di fronte a tre descrizioni snippet identiche, tenderà a mantenere solo la posizione di un dominio principale nella SERP, mentre le altre pagine potrebbero essere incluse nei “risultati omessi”.
Il punto di attivazione di questo meccanismo di filtraggio è la mancanza di punteggio di “guadagno informativo” (Information Gain);
se la descrizione della seconda pagina non fornisce più punti dati unici rispetto alla prima (come prezzi in valuta locale, stato delle scorte o tempi di consegna specifici per regione), il sistema deciderà che non è necessario mostrarla all’utente.
Secondo uno studio indipendente su 120.000 pagine di marketing SaaS, se la meta description include dati in tempo reale inseriti dinamicamente (come “Last updated Jan 2026” o “Trusted by 50,000+ users in Germany”), la probabilità che venga mantenuta dal sistema aumenta del 38%. Questa pratica consiste essenzialmente nel superare il controllo anti-duplicazione dell’algoritmo migliorando la “sensibilità temporale” e l’“unicità geografica” dell’informazione.
Per i siti con milioni di URL, scrivere manualmente la meta description di ogni pagina è irrealistico, ma le descrizioni generate algoritmicamente devono introdurre sufficienti variabili casuali e campi dinamici.
Se i primi 40 pixel di larghezza della meta description di ogni pagina sono identici, l’esperienza visiva degli utenti mobile diventerà estremamente mediocre, inducendo un tasso di rimbalzo molto alto.
Il plugin RankBrain di Google registra le preferenze di clic degli utenti sulla SERP; se gli utenti ignorano frequentemente una serie di snippet ripetitivi, l’autorità complessiva del dominio (Domain Authority) verrà declassata nei successivi aggiornamenti algoritmici.
Per evitare tali rischi, i team tecnici dovrebbero introdurre soluzioni di generazione automatica basate sui dati strutturati di Schema.org, garantendo che la meta description includa il codice SKU del prodotto, il punteggio medio delle recensioni o coordinate geografiche specifiche.
Il controllo dell’unicità non deve limitarsi alla combinazione di caratteri; i moderni modelli linguistici (come BERT o T5), nel processare gli snippet di ricerca, sono in grado di identificare frasi con lo stesso significato ma formulazioni leggermente diverse.
Se due diverse pagine di categoria di un sito (ad esempio “Men’s Running Shoes” e “Running Shoes for Men”) hanno meta description con ordine delle parole diverso ma intento identico, Google continuerà a contrassegnarle come duplicate.
Un percorso di ottimizzazione efficace dovrebbe concentrarsi sull’estrazione di fatti non competitivi specifici della pagina web.
Per esempio, nel descrivere una pagina di servizio a New York City, oltre a menzionare il servizio, si dovrebbero inserire gli orari di apertura specifici di quell’ufficio, i punti di riferimento circostanti o specifici numeri di certificazione.
Questa iniezione di dettagli ad alta densità assicura che l’impronta digitale della meta description rimanga unica in tutto il web.
Accumulo di parole chiave (Keyword Stuffing)
Il sistema di filtraggio SpamBrain interno a Google esegue la vettorializzazione testuale del tag <meta name="description" content="..."> nel codice HTML, valutando se esistono violazioni attraverso il calcolo della densità delle parole (Term Frequency).
Dopo gli aggiornamenti algoritmici del 2024, la logica di monitoraggio per le pagine in inglese e altre lingue latine mostra che se un sostantivo o una frase specifica appare più di 3 volte entro 160 caratteri a mezza larghezza, la probabilità che la descrizione sia giudicata come testo non naturale aumenta del 45%.
La vecchia abitudine SEO di allineare forzatamente più modelli, prezzi o nomi di luoghi nella meta description viene oggi identificata come “frammento senza guadagno informativo” dai modelli Transformer.
Secondo le statistiche di Ahrefs su 200.000 risultati di ricerca casuali, le meta description contenenti più di tre parole chiave ripetute hanno una probabilità dell’88% di essere sostituite automaticamente da Google con frammenti casuali del testo.
In base alla documentazione per sviluppatori Mozilla sulle performance di rendering, i motori di rendering dei browser moderni prioritizzano la larghezza in pixel definita dalla tipografia rispetto al numero di caratteri. L’area di visualizzazione dello snippet nei risultati di ricerca desktop di Google è limitata a circa 920 pixel, mentre su mobile scende a circa 680 pixel. Se la meta description è infarcita di parole lunghe o combinazioni di lettere maiuscole, anche se il numero di caratteri è inferiore a 150, il testo verrà troncato nella SERP a causa del superamento della larghezza in pixel. Le descrizioni troncate mostrano solitamente una minore intenzione di sosta dell’utente; i dati sperimentali mostrano che descrizioni in linguaggio naturale visualizzate integralmente hanno un CTR superiore del 18,6% rispetto a descrizioni accumulate e troncate.
Per le pagine del mercato statunitense, il punteggio ideale della meta description dovrebbe mantenersi tra 60 e 70, corrispondente al livello di lettura degli studenti dell’8° o 9° grado negli Stati Uniti.
Se per inserire più termini di ricerca si usano subordinate o terminologie troppo complesse, facendo scendere il punteggio sotto 50, l’algoritmo potrebbe ritenere che il frammento non offra un’anteprima chiara all’utente medio.
Un report di Semrush indica che l’efficienza di comprensione dell’utente è massima quando la lunghezza media della frase è tra 12 e 15 parole.
Quando la meta description adotta un’unica frase lunga e complessa (oltre 25 parole) priva di verbi d’azione, il motore di ricerca tende a catturare frasi più brevi da sotto i tag <h2> o <h3> della pagina.
L’uso eccessivo di simboli non alfabetici come asterischi (*), barre verticali (|), punti esclamativi (!) o segni di uguale (=) per separare le parole chiave riduce il punteggio di linguaggio naturale del testo.
L’API di elaborazione del linguaggio naturale (NLP) di Google assegna a ogni frammento di testo un punteggio di “fiducia grammaticale”; le meta description composte interamente da frasi nominali solitamente ottengono meno di 0,3, mentre frasi standard con struttura “Soggetto-Verbo-Oggetto” superano solitamente lo 0,85.
Frammenti con punteggio inferiore a 0,5 vengono automaticamente contrassegnati come contenuti di bassa qualità, perdendo l’opportunità di essere mostrati prioritariamente nella SERP.
In una meta description standard di 155 caratteri, se le parole chiave sono tutte ammassate nel primo 20% della posizione, o ripetute senza senso alla fine, il sistema lo identificherà come un tentativo di ingannare l’algoritmo di posizionamento.
Un’analisi di Backlinko mostra che nelle descrizioni naturali il rapporto tra nomi e verbi si mantiene solitamente intorno a 3:1.
“L’output del generatore di snippet di Google è un equilibrio tra la pertinenza alla query dell’utente e l’integrità linguistica del testo sorgente.” Questo principio tecnico indica che la semplice corrispondenza dei termini non è sufficiente per ottenere il diritto alla visualizzazione. Nelle analisi di Word Embedding su un corpus di un milione di parole inglesi, l’algoritmo è in grado di riconoscere quali termini appartengono allo stesso cluster semantico. Gli amministratori non hanno bisogno di scrivere ripetutamente “Running Shoes”, “Shoes for Running” e “Runner Footwear”, poiché l’algoritmo ha già classificato queste espressioni come la stessa entità. Menzionare ripetutamente questi sinonimi nella meta description verrà considerato come sovra-ottimizzazione.
Il focus visivo degli utenti mobile durante lo scorrimento dello schermo si ferma solitamente sulle prime due righe dello snippet.
Se le parole chiave sono accumulate nella seconda metà della descrizione, l’utente non percepirà la pertinenza della pagina prima di cliccare.
Uno studio sul comportamento di ricerca mobile in California ha rilevato che meta description con verbi orientati all’azione (come Compare, Discover, Get) nei primi 40 caratteri hanno una frequenza di interazione superiore del 12% rispetto a quelle che accumulano parole chiave all’inizio.
Problemi di codice tecnico
Errori tecnici possono impedire agli strumenti di scansione di Google (Googlebot) di estrarre la meta description.
Le statistiche mostrano che circa il 15% delle anomalie nella visualizzazione degli snippet deriva da errori nella struttura HTML. Google richiede che il tag meta description si trovi entro il primo 1MB del documento HTML e che il tag sia correttamente chiuso.
Se la pagina si affida a JavaScript per inserire la meta description e il tempo di esecuzione dello script supera i 5 secondi, Googlebot spesso catturerà il contenuto vuoto del codice sorgente statico invece del testo renderizzato.
Posizione del tag
Secondo la logica di base del motore di rendering Chromium, il parser costruisce un albero del Document Object Model (DOM) durante la scansione dell’HTML.
Se il tag <meta name="description"> viene posizionato dopo 1.024.000 byte (ovvero 1MB) nel codice sorgente HTML, il tag verrà ignorato dal sistema di indicizzazione di Google.
Questo fenomeno è comune nelle pagine che utilizzano grandi quantità di CSS inline o immagini codificate in Base64.
Quando l’intestazione della pagina carica migliaia di righe di fogli di stile inline o complessi codici grafici SVG, il tag meta description viene spinto nelle aree profonde del documento.
Per risparmiare budget di scansione e risorse computazionali, i crawler di Google eseguono solitamente una scansione dettagliata dei metadati solo per il primo 1MB di contenuto.
Una volta superata questa soglia, il sistema smette di cercare attributi in <head> e passa alla modalità di scansione generica del corpo del testo, impedendo alla meta description preimpostata di apparire nella SERP.
Nelle specifiche HTML, il tag meta description deve essere posizionato rigorosamente tra <head> e </head>.
Se nella struttura del codice sono presenti tag non chiusi, come un tag <script> prima della meta description a cui manca il simbolo di chiusura </script>, o un blocco <style> non chiuso correttamente, il parser di Googlebot produrrà una deviazione nell’analisi.
In questo caso, il parser potrebbe ritenere che la sezione <head> sia terminata in anticipo e considerare erroneamente la meta description successiva come parte dell’area <body>.
Poiché il sistema di indicizzazione di Google assegna un peso estremamente basso o ignora i tag <meta> all’interno di <body>, ciò causerà il fallimento dell’estrazione dello snippet.
Il monitoraggio dei dati mostra che nei siti con errori di validazione della sintassi HTML, il tasso di perdita della meta description è superiore del 22% rispetto ai siti conformi agli standard.
| Posizione tag e stato strutturale | Tasso successo riconoscimento Googlebot | Analisi cause tecniche |
|---|---|---|
Entro i primi 100KB di <head> |
99.2% | Area ad alta priorità per il parser, quasi immune da interferenze di script. |
| Dopo grandi quantità di CSS inline (oltre 1MB) | 12.5% | Superamento della soglia predefinita di scansione metadati di Googlebot. |
Dopo l’inizio del tag <body> |
5.8% | Violazione degli standard W3C, il parser lo vede come testo normale. |
Tag superiori non chiusi (es. <title>) |
0.4% | Collasso della struttura dell’albero; la meta description è vista come sotto-contenuto. |
Alla fine del documento prima di </html> |
0.1% | Il crawler ha solitamente già completato l’estrazione degli snippet prima di arrivare qui. |
Anche la posizione della dichiarazione del set di caratteri (Charset Declaration) influisce sull’analisi della meta description.
Secondo i suggerimenti di Google, <meta charset="utf-8"> dovrebbe apparire entro i primi 1024 byte del documento.
Se la dichiarazione del charset viene posta dopo il tag meta description, il parser potrebbe non aver ancora determinato il formato di codifica della pagina durante la lettura della descrizione.
Per contenuti che includono caratteri non ASCII (come simboli speciali o caratteri multilingue), questo errore d’ordine causerà la visualizzazione di caratteri distorti (mojibake).
Quando l’algoritmo di Google rileva che il contenuto della meta description contiene molti caratteri illeggibili, filtrerà automaticamente il tag catturando testo puro più leggibile dalla pagina.
Rendering JavaScript
Google processa il codice sorgente originale molto velocemente, ma per le pagine che richiedono l’esecuzione di script, il tempo di attesa nella coda di rendering può variare da 24 ore a 14 giorni.
Se una pagina usa framework come React, Vue o Angular e il contenuto della meta description viene caricato in tempo reale tramite hook come useEffect o onMounted, Googlebot nella prima fase di scansione HTML troverà solo un tag vuoto: <meta name="description" content="">.
A quel punto, il database dell’indice registrerà questo valore vuoto.
Anche se la fase di rendering successiva estrae con successo il testo, l’aggiornamento della visualizzazione nella SERP sarà oltre 3 volte più lento rispetto a una normale pagina HTML.
Secondo i documenti tecnici del motore di rendering Chromium, il WRS simula un ambiente browser headless basato su Chrome 120+, assegnando una quota di memoria di 1024MB per ogni richiesta di scansione.
Se il pacchetto JavaScript caricato supera i 5MB complessivi, o se il processo di inizializzazione dello script coinvolge più di 20 richieste API esterne, il renderer interromperà l’esecuzione dei comandi di modifica del DOM a causa dell’eccessivo consumo di risorse.
In un test su 50.000 siti, le pagine con un tempo di esecuzione degli script superiore a 5,5 secondi hanno visto scendere del 62% la probabilità di corretto riconoscimento della meta description.
A causa dei limiti di budget di scansione, per i siti con bassa autorità, se il renderer non riesce a ottenere la meta description alla prima esecuzione, il sistema tenderà a estrarre i primi 160 caratteri dal primo tag <p> del corpo della pagina.
| Soluzione tecnica di rendering | HTML iniziale con meta description | Ritardo indicizzazione Google | Rischio fallimento esecuzione WRS |
|---|---|---|---|
| Client-Side Rendering (CSR) | No (solo segnaposto) | Da 2 a 14 giorni | Alto |
| Server-Side Rendering (SSR) | Sì (testo completo) | Immediato | Basso |
| Static Site Generation (SSG) | Sì (testo completo) | Immediato | Nessuno |
| Edge SEO (Cloudflare/AWS) | Sì (tramite iniezione richiesta) | Immediato | Basso |
“La meta description deve essere pronta nelle prime fasi dell’analisi del DOM; qualsiasi contenuto compilato dopo il ritorno di una richiesta asincrona rischia di essere ignorato dagli strumenti di scansione.”
Questo fenomeno tecnico è particolarmente diffuso nelle Single Page Applications (SPA).
Quando un utente clicca sulla navigazione nel browser, la pagina non si ricarica e la meta description viene aggiornata tramite history.pushState; tuttavia, per Googlebot, esso scansionerà solo l’ingresso indipendente corrispondente a quell’URL.
Se il codice sorgente di quell’ingresso non contiene la meta description, affidandosi solo alla generazione in tempo reale lato client, il motore di ricerca avrà una deviazione nella valutazione della pertinenza, portando a snippet non corrispondenti al contenuto reale della pagina.
Conflitti Robots
Googlebot, nel processare le pagine web, segue prioritariamente le istruzioni robots presenti nel codice sorgente HTML o negli header delle risposte HTTP.
Se nel codice sono presenti tag restrittivi specifici, anche se lo sviluppatore scrive contenuti di alta qualità in <meta name="description">, la SERP gestirà lo snippet tramite blocco totale o troncamento forzato.
Questo conflitto appare più spesso con l’uso del tag nosnippet.
Secondo le regole della documentazione ufficiale di Google, una volta che l’HTML della pagina include <meta name="robots" content="nosnippet">, a Google sarà proibito mostrare qualsiasi forma di descrizione testuale o anteprima video per quella pagina.
In audit di crawler su siti su larga scala, si è scoperto che circa il 2% delle pagine, a causa di errori nel mantenimento delle istruzioni nosnippet dall’ambiente di test durante la migrazione dei template, mostrava solo titolo e URL nei risultati di ricerca in produzione, perdendo completamente il testo descrittivo.
Oltre alle istruzioni di disattivazione totale, l’istruzione max-snippet permette agli sviluppatori di impostare la lunghezza massima dei caratteri dello snippet nei risultati di ricerca.
Se il codice è impostato su <meta name="robots" content="max-snippet:50"> e la meta description preimpostata è di 150 caratteri, l’algoritmo di Google riterrà nella maggior parte dei casi che 50 caratteri non siano sufficienti a veicolare abbastanza informazioni, scegliendo di non mostrare la descrizione o di estrarre frasi brevi che rispettino il limite.
Quando questo valore è impostato a 0, l’effetto tecnico è identico a nosnippet.
La tabella seguente elenca i parametri comuni delle istruzioni e il loro impatto quantificabile sulla visualizzazione delle meta description:
| Nome istruzione | Esempio di codice tipico | Effetto limitante sulla visualizzazione |
|---|---|---|
| nosnippet | content="nosnippet" |
Blocco al 100%, nessuna descrizione mostrata. |
| max-snippet:0 | content="max-snippet:0" |
Effetto uguale a nosnippet, nessuna visualizzazione. |
| max-snippet:[numero] | content="max-snippet:60" |
Mostra solo il numero indicato; il contenuto in eccesso è scartato. |
| indexifembedded | content="noindex, indexifembedded" |
Snippet mostrato solo se la pagina è incorporata come iframe altrove. |
I conflitti di esclusività a livello tecnico non si limitano ai tag HTML, ma si nascondono spesso negli header delle risposte del protocollo HTTP, ovvero X-Robots-Tag.
Poiché questa istruzione non appare nel codice sorgente HTML, gli sviluppatori non possono rilevarla tramite “Visualizza sorgente pagina” nel browser.
Nelle configurazioni dei server Nginx o Apache, se viene impostato globalmente X-Robots-Tag: nosnippet, tutti i file PDF, le immagini o le pagine dinamiche sotto quel server perderanno la descrizione.
Per verificare la presenza di tali istruzioni nascoste, è necessario usare il comando curl -I [URL] per visualizzare le informazioni Header restituite dal server.
Se negli Headers è presente X-Robots-Tag: noindex, Googlebot non inserirà nemmeno la pagina nel database dell’indice, rendendo impossibile l’estrazione e la visualizzazione della meta description.
Sotto lo standard HTML 5, gli sviluppatori possono aggiungere l’attributo data-nosnippet ai tag <span>, <div> o <section> per indicare a Google di non usare il contenuto di quell’area per lo snippet di ricerca.
Se il contenuto principale del corpo di una pagina è contrassegnato con data-nosnippet e l’area <head> manca di un tag meta description valido, il motore di rendering di Google non troverà alcun contenuto disponibile durante il tentativo di estrarre un frammento (Fragment).
Questo conflitto logico porterà Google a catturare forzatamente la barra di navigazione, le informazioni sul copyright nel footer o altro testo irrilevante non contrassegnato come descrizione di ripiego.
- Conflitto di sovrapposizione di istruzioni multiple: Quando in una pagina coesistono
indexenosnippet, Google adotterà il “principio più restrittivo”, dando priorità anosnippet. - Limitazioni impostazioni predefinite dei plugin CMS: In siti Shopify o WordPress, alcuni plugin di sicurezza, per prevenire lo scraping dei contenuti, inseriscono automaticamente
nosnippetonoarchivein pagine non standard (come risultati di ricerca interni o tag cloud), sovrascrivendo le descrizioni inserite manualmente nei plugin SEO. - Impatto istruzione di scadenza cache: L’istruzione
unavailable_afterimposta un timestamp specifico. Se l’ora corrente supera il valore impostato (ad esempiounavailable_after: 2025-12-31), Google smetterà di mostrare qualsiasi snippet per quella pagina nella SERP.
In alcune architetture di siti multinazionali complessi, i fornitori di servizi CDN (come Cloudflare o Akamai) potrebbero modificare dinamicamente gli header di risposta o iniettare HTML tramite script Workers sui nodi edge.
Se al livello CDN vengono aggiunte erroneamente istruzioni restrittive robots, non importa quanto sia perfetto il codice originale del server backend, i dati inviati a Googlebot porteranno il marchio “vietata visualizzazione snippet”.
I team tecnici dovrebbero utilizzare regolarmente lo strumento “Controllo URL” di Google Search Console per esaminare il corpo della risposta HTTP nella scheda “URL richiesto”, assicurandosi che non ci siano istruzioni negative contenenti la parola chiave snippet.
Google ritiene che la sua generazione automatica sia migliore
Secondo l’analisi dei dati di Ahrefs su 192.000 pagine, quando i termini di ricerca dell’utente non sono nella meta description, il tasso di riscrittura di Google è dell’82,7%;
anche quando la descrizione contiene le parole chiave, la probabilità di riscrittura rimane al 59,7%. Google tende a sfruttare il modello linguistico BERT per catturare frammenti di circa 160 caratteri in tempo reale dal testo della pagina, assicurando che le parole chiave appaiano in grassetto nei risultati di ricerca.
Questa pratica può generare un aumento statistico del CTR tra il 5% e il 10%, poiché fornisce un feedback immediato sull’intento di ricerca tramite i termini evidenziati.
Riscrittura algoritmica
Una volta che una pagina entra nell’indice, l’algoritmo non fissa permanentemente la modalità di visualizzazione della sua meta description.
Se il testo descrittivo preimpostato manca di intersezione semantica con i termini cercati dall’utente, l’algoritmo estrarrà circa 160 caratteri dal testo della pagina.
Questa estrazione avviene solitamente quando i termini di ricerca appaiono nell’intervallo tra il 200° e il 500° carattere del corpo del testo, mentre la meta description non li menziona affatto.
Poiché l’obiettivo dell’algoritmo è massimizzare l’efficienza dei clic, darà priorità ai frammenti di testo che contengono parole chiave in grassetto.
| Classificazione scenari di attivazione | Probabilità statistica riscrittura | Descrizione logica giudizio algoritmo |
|---|---|---|
| Assenza termini di ricerca | 82.7% | La meta description non contiene i termini dell’utente; il sistema cerca nel testo. |
| Descrizione troppo lunga/corta | 65.4% | Lunghezza fuori dai 960px o sotto i 50 caratteri; efficienza informativa bassa. |
| Ripetitività contenuti | 71.0% | Più URL usano lo stesso template; l’algoritmo ignora il tag e cattura testo unico. |
| Mancata corrispondenza semantica | 58.2% | La descrizione è uno slogan promozionale, la query è una ricerca tecnica specifica. |
Lo spazio di visualizzazione dei browser desktop è limitato a circa 920 pixel, mentre sui dispositivi mobili si riduce a circa 600 pixel.
Se la lunghezza della meta description raggiunge i 1000 pixel, il sistema di visualizzazione frontend di Google proverà prima a troncarla; tuttavia, se la frase troncata risulta semanticamente frammentata, l’algoritmo di generazione degli snippet classificherà la descrizione come “output di bassa qualità”.
A quel punto, il sistema richiamerà i tag <h1> o <p> interni alla pagina per cercare una frase che possa esprimere un significato completo entro i limiti di pixel stabiliti.
| Tipo di query | Tendenza alla riscrittura | Origine tipica della sostituzione |
|---|---|---|
| Query informative | Alta | Paragrafi definitori in alto o elenchi FAQ. |
| Query di navigazione | Bassa | Solitamente mantiene la descrizione, specie se include il brand. |
| Query transazionali | Media | Frammenti con prezzi, specifiche o “consegna gratuita”. |
| Query long-tail | Altissima | Prima frase sotto l’intestazione H2 che corrisponde alla parola long-tail. |
Per lo stesso URL, Google potrebbe generare centinaia di snippet diversi.
Ad esempio, quando una pagina su “Guida all’acquisto di servizi cloud” si posiziona sia per “confronto prezzi cloud” che per “test sicurezza cloud”, una meta description statica difficilmente coprirà entrambi gli aspetti.
Il meccanismo di riscrittura dinamica di Google analizzerà la struttura della pagina; se trova una tabella con i prezzi, l’algoritmo catturerà automaticamente il testo vicino alla tabella quando l’utente cerca “prezzi”.
Se il corpo della pagina manca di una struttura logica chiara nei paragrafi, l’algoritmo potrebbe catturare menu di navigazione, testo nel footer o link della barra laterale, producendo uno snippet senza senso; questo è solitamente causato da una scarsa densità di testo utile nella pagina.
Nel gestire pagine con molte specifiche tecniche o attributi prodotto, se la pagina usa i markup Schema Product o Review ma la meta description non riflette questi attributi, Google spesso riscriverà la descrizione per includere valutazioni, prezzi o disponibilità.
Se la meta description è semplicemente “scopri la nostra ultima collezione di scarpe” ma nel testo ci sono dati come “resistenza 9.5” o “peso 250g”, l’algoritmo deciderà che questi ultimi hanno più valore per l’utente.
Per mantenere la visualizzazione della descrizione preimpostata, bisogna assicurarsi che la sua densità informativa non sia inferiore alla media dei primi 300 caratteri del testo.
Ridurre la riscrittura
Se la meta description predefinita non contiene i primi tre termini di ricerca per cui la pagina si posiziona, la probabilità di riscrittura automatica sale oltre l’80%.
Per ridurre questa interferenza, occorre inserire naturalmente i termini ad alta frequenza esportati da GSC nei primi 65 caratteri della descrizione.
Operativamente, è necessario mantenere un’alta coerenza semantica tra la descrizione, il tag H1 della pagina e il primo paragrafo del testo.
Nella stesura, evitate linguaggi promozionali vaghi, preferendo frasi dichiarative che includano parametri specifici, nomi di brand o istruzioni d’azione chiare.
- Controllo preciso di caratteri e pixel: Il limite di larghezza su desktop è circa 920-960 pixel, su mobile 600-680 pixel. Poiché caratteri diversi occupano pixel diversi, il solo conteggio dei caratteri non è accurato. Si consiglia di usare strumenti di controllo pixel per garantire che la descrizione termini entro i 920 pixel, evitando troncamenti che l’algoritmo giudicherebbe come visualizzazione di bassa qualità.
- Eliminazione dei contenuti duplicati da template: Per grandi siti e-commerce con migliaia di pagine, evitate di usare lo stesso template per tutto il sito. Se le descrizioni di molti URL hanno solo minime differenze, i crawler di Google le ignoreranno. Si consiglia di scrivere descrizioni uniche per le pagine ad alto traffico e assicurarsi che per le pagine long-tail i frammenti generati siano sufficientemente distintivi.
- Scelta di verbi che corrispondono all’intento: Per query informative (Informational Queries), l’inizio della descrizione dovrebbe usare verbi come “scopri”, “confronta” o “impara”; per query transazionali (Transactional Queries), dovrebbe includere “acquista”, “scarica” o “prezzo”. Adattare il tono della descrizione allo stile dei primi risultati della SERP può aiutare a mantenere la descrizione originale.
In audit SEO reali, si scopre che molti siti impostano meta description che deviano dal tema principale trattato nella pagina.
Ad esempio, una pagina su “migliori scarpe da corsa” la cui descrizione parla della storia del brand subirà l’intervento dell’algoritmo per scollegamento semantico.
Progettare la meta description come un riassunto preciso del contenuto, includendo 2 o 3 parole long-tail, può aumentare significativamente la frequenza di visualizzazione originale.
Attenzione ai caratteri speciali in HTML; alcuni simboli non convertiti correttamente possono causare errori di analisi, rendendo la meta description illeggibile per Google, che sceglierà frammenti casuali dal testo.
- Logica di ottimizzazione guidata dai dati: Controllate regolarmente le fluttuazioni del CTR in GSC. Se la posizione media di una pagina non cambia ma il CTR scende di oltre il 3%, verificate se lo snippet è stato riscritto. Se la riscrittura proviene dalla sezione FAQ, significa che la descrizione originale non copriva i dubbi degli utenti; in tal caso, riadattate la logica della descrizione basandovi sul frammento riscritto da Google.
- Distribuzione del peso semantico: Mettete le informazioni più importanti all’inizio della frase. La ricerca mostra che i crawler di Google prestano molta più attenzione alla parte iniziale della meta description rispetto alla fine. I primi 50 caratteri dovrebbero poter esprimere autonomamente la proposta di valore della pagina.
- Evitare l’uso eccessivo di punteggiatura: Troppi punti esclamativi o puntini di sospensione consecutivi riducono la professionalità della descrizione; l’algoritmo tenderà a filtrare questi contenuti simili a spam. Mantenete una struttura della frase piana, neutra e conforme agli standard di comunicazione professionale.
Nella gestione dei dati strutturati (Schema Markup), se la pagina usa architetture FAQ o Product, la meta description dovrebbe fungere da collegamento e anteprima, non essere una ripetizione esatta.
Per le pagine con molte specifiche tecniche, provate a inserire dati numerici concreti nella descrizione, come “peso solo 1.2kg” o “supporta risoluzione 4K”.


