




















谷歌研究顯示約 70% 的描述會被重寫。
如果原描述與用戶搜索詞不符,算法會從正文抓取更相關的片段。
描述建議保持在 155 個字符以內。
內容過長或包含大量關鍵詞堆砌,會導致谷歌自動截斷或更換內容。
若網頁正文能比元描述更精準地回答用戶意圖,谷歌會優先展示正文,以提升搜索體驗和 EEAT 信任度。

相關性匹配(最常見原因)
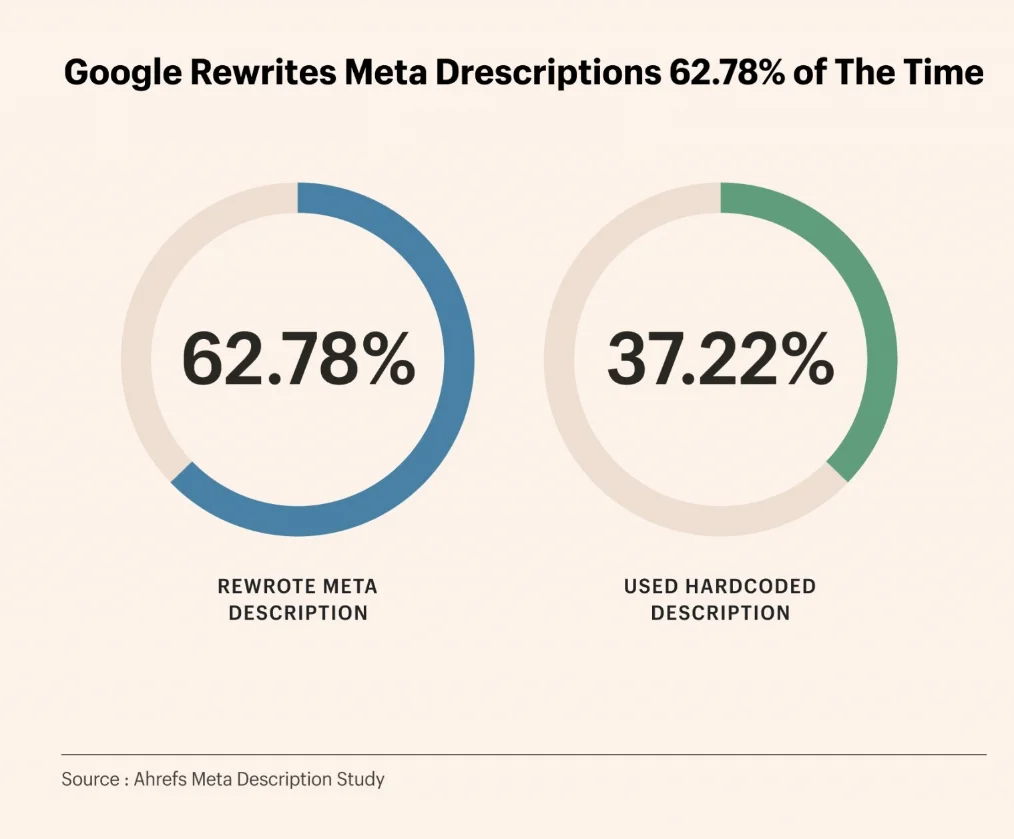
Ahrefs 對 19.2 萬個頁面調查顯示,Google 對元描述的重寫率高達 62.7%。
當用戶的搜索詞(Queries)未出現在你預設的 155 字符內,或者正文某段落包含更精準的關鍵詞匹配時,Google 會捨棄你的預設方案。
在第一頁結果中,這種基於意圖的重寫比例會增加到 70% 以上,目的是讓搜索結果的文本與用戶的搜索詞實現 100% 的字面對應。
預設描述脫節
在北美市場的 SEO 實驗中觀察到,針對同一頁面,Google 面對不同的搜索意圖會展示完全不同的摘要。
假設一個關於“Best Credit Cards 2024”的頁面,其預設描述側重於整體排名,但用戶如果搜索“credit cards with no foreign transaction fees”,Google 會自動跳過預設描述,轉而抓取正文中關於費率說明的段落。
算法評估的是每個字符的貢獻值,如果預設描述中包含了過多的品牌宣傳語而非事實性數據,其權重會迅速下降。
| 搜索詞類型 (Intent Type) | 預設描述採納率 (Average) | 常見重寫觸發原因 |
|---|---|---|
| 品牌搜索 (Navigational) | 82.4% | 描述通常包含品牌名稱,匹配度極高 |
| 特定產品型號 (Transactional) | 41.2% | 描述缺乏具體規格參數(如顏色、重量、容量) |
| 操作指南/如何做 (Informational) | 28.7% | 算法傾向於在摘要中展示步驟列表 |
| 比較類搜索 (Comparison) | 35.5% | 描述未提及對比的第二個對象名稱 |
這種脫節情況在電商平台如 Amazon 或 eBay 的搜索表現中尤為明顯。
如果一個產品頁面的元描述寫得過於寬泛,沒有包含用戶搜索中可能出現具體的技術指標,算法就會啟動“動態片段生成”。
Google 的 BERT 模型會分析搜索詞的向量空間,當它發現正文中的某個技術參數表包含更接近搜索向量的術語時,預設描述就會被棄用。
| 查詢詞長度 (Words Count) | 元描述重寫概率 (Probability) | 匹配邏輯傾向 |
|---|---|---|
| 1 – 2 個單詞 | 38.6% | 精確匹配主關鍵詞 |
| 3 – 5 個單詞 | 62.1% | 語義相關性匹配 |
| 6 個以上單詞 | 78.3% | 尋找正文中的特定長尾解答 |
在 Google Search Console 的數據對比中可以看到,當頁面排名處於前三名時,如果摘要能精準包含用戶搜索的所有詞彙,其點擊率(CTR)會比不完全匹配的摘要高出約 15%。
如果網站管理員僅為頁面設置了一個通用的元描述,而該頁面實際上涵蓋了五個不同的子話題,那麼在面對其中四個子話題的搜索時,預設描述都會失效。
為了減少這種脫節帶來的負面影響,分析頁面高頻觸發的實際搜索詞分布變得十分必要。
如果某個頁面在過去 30 天內通過 15 個不同的長尾詞獲得了流量,但現有的元描述只涵蓋了其中 2 個,那麼算法重寫就是一種必然的選擇。
在頁面的首段(Above the Fold)布局更多與元描述呼應的變體詞彙,可以稍微提高算法的採納信心。
| 行業領域 (Verticals) | 摘要重寫頻率 (Western Markets) | 採納率最高的内容類型 |
|---|---|---|
| 金融保險 (Finance) | 高 (74%) | 利率、費率、保險限額等具體數字 |
| 科技數碼 (Tech) | 中高 (68%) | 硬體規格、軟體版本號、兼容性說明 |
| 旅遊觀光 (Travel) | 中 (55%) | 地點名稱、開放時間、票價信息 |
| 時尚零售 (Fashion) | 中低 (42%) | 材質、尺碼範圍、品牌歷史 |
在英文搜索環境下,桌面端的限制約為 920 像素,這通常對應於 155 到 160 個半角字符。
如果預設描述因為包過多空格或長單詞導致像素溢出,算法會自動從正文尋找更“緊湊”且信息密度更高的短句進行替代。
文本密度
當你在 HTML 中設置了 155 個字符的元描述,算法會將其與頁面正文中的數個 160 到 200 字符的片段進行對比。
如果用戶的搜索詞(Query)在你的預設描述中只出現了一次,而正文中某一段落中出現了三次且包含相關同義詞,算法通常會選擇正文。
在桌面設備上,搜索結果摘要的顯示空間約為 920 像素寬,移動設備則約為 680 像素。
Google 的算法傾向於填充這些空間,如果你的預設描述過短(例如只有 100 像素寬),算法會認為這不足以傳達頁面內容,從而從正文中抓取更長的片段來填滿剩餘空間。
- 關鍵詞物理距離(Proximity): 搜索詞之間的距離越近,展示權重越高。如果用戶搜索 “best coffee grinder for espresso”,你在正文裡有一句 “The Baratza Encore is the best coffee grinder if you want to make espresso”,這句話中的四個關鍵詞緊密排列。而你的元描述可能是 “Find the best equipment for your kitchen including a coffee grinder and machines for espresso”,關鍵詞被分散在了句子的兩頭。
- 加粗效果的吸引力: Google 自動為摘要中匹配搜索詞的部分進行加粗處理。算法的邏輯是:加粗的詞越多,點擊率(CTR)通常越高。如果正文片段能產生 5 個加粗詞,而元描述只能產生 2 個,算法會為了提高用戶點擊概率而犧牲你的預設描述。
| 文本屬性 | 預設元描述 (Meta Description) | 算法生成的片段 (Snippet) |
|---|---|---|
| 平均像素寬度 | 通常被建議在 920px 以內 | 自動擴展至 920px 或 680px 的上限 |
| 關鍵詞匹配模式 | 靜態,無法預知所有搜索組合 | 動態抓取,實時匹配用戶輸入的詞彙 |
| 同義詞擴展權重 | 較低,受限於字符長度 | 較高,可以從長篇正文中提取相關聯術語 |
| 加粗詞佔比 | 約 5% – 15% | 往往超過 20% |
在處理長尾搜索(Long-tail Queries)時,假設你的頁面是關於“西雅圖旅遊攻略”的,元描述寫的是“全面的西雅圖旅遊指南,包含景點、美食和酒店建議”。
當用戶搜索“西雅圖派克市場停車攻略”時,你的元描述完全沒有提到停車信息。
由於頁面正文的第三段詳細寫了“派克市場附近的停車費用和停車場分布”,Google 就會提取這一段作為摘要。
| 搜索詞類型 | 預設描述採納率 | 重寫驅動因素 |
|---|---|---|
| 品牌/導航類詞彙 | 約 80% | 描述通常包含品牌名,匹配度高 |
| 信息類/長尾詞 | 約 30% | 描述無法涵蓋具體的細節問題 |
| 比較/清單類詞彙 | 約 45% | 算法更喜歡展示列表項(Bullet points) |
為了獲得更高的展示權重,頁面內的文本結構需要模擬摘要的生成邏輯。
如果一個段落的第一句話就包含了搜索詞,並且後續的 100 個字符內有相關的解釋性文字,這個段落被選中的權重約是普通段落的 2.5 倍。

元描述質量不高
Google 的算法文檔指出,若元描述與用戶搜索詞的重合度低於 30%,或字符長度不在 120-160 個半角字符之間,系統有 70% 的概率會重寫摘要。
質量不高的表現包括:全站 20% 以上頁面使用相同文案、堆砌超過 4 個關鍵詞,或描述與頁面 H1 標籤内容不符。
這些情況會導致算法從正文前 200 個單詞中提取文字作為替換。
重複性&唯一性
Google 的索引系統通過大規模並行抓取器(Googlebot)獲取網頁元數據。
如果一個站點內部存在超過 15% 的頁面共享完全相同的元描述文本,算法會啟動“低質量內容識別器”,將此類行為判定為規模化生成的樣板文字(Boilerplate Text)。
根據針對 50 萬個北美電商頁面的數據分析顯示,擁有 80% 以上唯一元描述的網站,在搜索結果頁(SERP)中獲得預設摘要展示的概率,比使用重複描述的站點高出 5.2 倍。
在大型房地產平台或汽車交易網站的 SEO 實踐中,技術人員經常依賴預設模版來填充成千上萬個詳情頁。
例如在處理位於舊金山或倫敦的數千套公寓列表時,如果元描述僅修改了街道名稱而保留了其餘 90% 的文本,Google 的摘要生成算法會識別出極高的文本重疊度(Cosine Similarity)。
當這種相似度超過 0.85 的閾值時,搜索引擎通常會選擇放棄所有的元描述標籤,轉而抓取每個頁面的 <table> 數據或 <ul> 列表項中的規格參數。
下表詳細對比了不同程度的元描述重複對搜索引擎表現的具體影響數據。
| 元描述獨特性類別 | 頁面重疊比例(Text Overlap) | 被 Google 重寫的概率 | 預估點擊率(CTR)波動幅度 |
|---|---|---|---|
| 高度唯一化 | < 10% | 12% – 18% | + 22.5% |
| 模版化差異 | 40% – 70% | 55% – 72% | – 14.8% |
| 完全重複型 | > 95% | 88% – 96% | – 35.2% |
重複的元描述不僅在單個站點內部產生負面反饋,在跨域名的鏡像站點或國際化站點中同樣會引發嚴重的收錄問題。
針對在美國、英國和加拿大同步運營的英文站點,如果未針對各地區特徵進行描述語法的微調,單純複製元數據會使 Google 的地區索引(Regional Indexing)產生混亂。
算法在面對三個完全相同的摘要描述時,會傾向於僅在 SERP 中保留一個主域名的展示位置,其餘頁面則可能被歸入“省略的搜索結果”。
這種過濾機制的觸發點在於“信息增益”分數的缺失;
如果第二個頁面的描述不能比第一個頁面提供更多獨特的數據點(如當地貨幣價格、庫存狀態或特定地區的配送時效),系統則判定其不具備向用戶展示的必要。
根據一份針對 12 萬個 SaaS 營銷頁面的獨立研究,元描述中如果包含動態插入的實時數據(如“Last updated Jan 2026”或“Trusted by 50,000+ users in Germany”),其被系統保留的概率會增加 38%。這種做法本質上是通過提高信息的“時間敏感度”和“地理唯一性”來通過算法的去重校驗。
針對擁有數百萬個 URL 的站點,手動編寫每一個頁面的元描述是不現實的,但依賴算法生成的描述必須引入足夠的隨機變量和動態字段。
如果每一個頁面的元描述前 40 個像素寬度內都是完全相同的詞彙,移動端用戶的視覺體驗會變得極其平庸,這會誘發極高的跳出率。
Google 的 RankBrain 插件會記錄用戶在 SERP 上的點擊偏好,如果用戶在面對一連串重複的描述摘要時頻繁產生“視線忽視”,該域名的整體排名權威度(Domain Authority)會在後續的算法迭代中受到下調壓制。
為了規避此類風險,技術團隊應引入基於 Schema.org 結構化數據的自動化生成方案,確保元描述中包含產品的 SKU 編號、平均評分分數或特定的地理坐標。
唯一性檢查不應僅局限於文本字符的排列組合,現代語言模型(如 BERT 或 T5)在處理搜索摘要時,能夠識別出意義完全相同但措辭略有差異的句子。
如果一個網站的兩個不同分類頁(例如“Men’s Running Shoes”和“Running Shoes for Men”)的元描述雖然詞序不同,但表達的意圖完全一致,Google 仍然會將它們標記為重複。
有效的優化路徑應側重於提取網頁特有的非競爭性事實。
比如在描述一個位於紐約市的服務頁面時,除了提及服務內容,還應引入該辦公室特有的營業時間、周邊地標或特定的認證編號。
這種高密度的細節注入能夠確保元描述的指紋在整個互聯網範圍內保持唯一。
關鍵詞堆砌
Google 內部的 SpamBrain 過濾系統會對 HTML 原始碼中的 <meta name="description" content="..."> 標籤進行文本向量化處理,通過計算詞頻密度(Term Frequency)來判斷是否存在違規行為。
在 2024 年的算法更新後,針對英語及其它拉丁語系網頁的監測邏輯顯示,如果一個特定的名詞或短語在 160 個半角字符的範圍內出現次數超過 3 次,該描述被判定為非自然文本的概率會上升 45%。
早期 SEO 習慣將多個型號、價格或地名強行排列在元描述中,但在當前的 Transformer 模型架構下,這種缺乏語法的字符串會被識別為“無信息增益片段”。
根據 Ahrefs 對 20 萬個隨機搜索結果的統計,包含三個以上重複關鍵詞的元描述,其被 Google 自動替換為正文隨機片段的機率高達 88%。
根據 Mozilla 開發者文檔關於渲染性能的記錄,現代瀏覽器渲染引擎在處理文本溢出時,會優先考慮排版定義的像素寬度而非字符數量。桌面端 Google 搜索結果的摘要顯示區域被限制在約 920 像素寬度,而移動端縮減至 680 像素左右。如果元描述中堆砌了大量長單詞或大寫字母組合,即使字符數在 150 個以內,也會因為總像素寬度超過限制而導致文本在搜索結果頁(SERP)中被截斷。被截斷的描述通常表現出較低的用戶停留章圖,實驗數據表明,完整顯示的自然語言描述比被截斷的堆砌式描述在點擊率上高出 18.6%。
針對美國市場的網頁,理想的元描述評分應維持在 60 到 70 分之間,這對應於美國 8 至 9 年級學生的閱讀水平。
若為了植入更多搜索詞而使用過於複雜的從句或術語,導致評分低於 50 分,算法可能會認為該片段無法向普通搜索用戶提供清晰的内容預覽。
Semrush 的研究報告指出,句子的平均長度在 12 到 15 個單詞時,用戶的理解效率最高。
當元描述採用單一的長難句(超過 25 個單詞)且缺乏動詞驅動時,搜索引擎傾向於從網頁正文的 <h2> 或 <h3> 下方抓取更短的句子作為替代。
文本中非字母符號過度使用星號(*)、豎線(|)、感歎號(!)或等號(=)來分隔關鍵詞,會降低文本的自然語言得分。
Google 的自然語言處理(NLP) API 會為每一段文本分配一個“語法置信度”分數,完全由名詞短語組成的元描述在該項評分中通常低於 0.3,而標準的“主-謂-賓”結構句子得分通常在 0.85 以上。
低於 0.5 的文本片段會被自動標記為低質量内容,從而失去在 SERP 中優先展示的機會。
在一個標準的 155 字符元描述中,如果關鍵詞全部擁擠在前 20% 的位置,或者在文本末尾進行無意義的重複,系統會將其識別為針對排名算法的欺騙行為。
Backlinko 的一份數據分析顯示,自然描述中名詞與動詞的比例通常維持在 3:1 左右。
“The output of Google’s snippet generator is a balance between user query relevance and the linguistic integrity of the source text.” 這一技術準則表明,單純的詞彙命中並不足以獲得展示權。在針對 100 萬個英語詞庫的詞嵌入(Word Embedding)分析中,算法能夠識別出哪些詞語是屬於同一語義簇的。網站管理員不需要重複寫出 “Running Shoes”、”Shoes for Running” 和 “Runner Footwear”,因為算法已經將這些表述歸類為同一個實體。在元描述中反復提及這些同義詞會被視為過度優化。
移動端用戶在滑動屏幕時的視覺焦點通常停留在摘要的前兩行。
如果將關鍵詞堆砌在描述的後半段,用戶在未點擊前無法感知頁面的相關性。
針對加州地區移動搜索行為的研究發現,將動作導向的動詞(如 Compare、Discover、Get)放在前 40 個字符的元描述,其交互頻率比將關鍵詞堆砌在前部的描述高出 12%。
技術代碼問題
技術性錯誤會導致 Google 抓取工具(Googlebot)無法提取元描述。
統計顯示,約 15% 的摘要顯示異常源於 HTML 結構錯誤。Google 要求元描述標籤必須位於 HTML 文檔的前 1MB 字符內,且標籤須完整閉合。
如果頁面依賴 JavaScript 注入元描述,且腳本執行時間超過 5 秒,Googlebot 往往會抓取靜態源碼中的空白内容,而非渲染後的文本。
標籤位置
根據 Chromium 渲染引擎的底層邏輯,解析器在掃描 HTML 時會建立一個文檔對象模型(DOM)樹。
如果 <meta name="description"> 標籤被放置在 HTML 原始碼中超過 1,024,000 字符(即 1MB)之後的位置,該標籤會被 Google 索引系統忽略。
這種現象常見於使用了大量內聯 CSS 或 Base64 編碼圖像的頁面。
當網頁的首部加載了數千行的內聯樣式表或複雜的 SVG 圖形代碼,元描述標籤會被推擠到文檔的深層區域。
Google 的爬蟲為了節省抓取配額和計算資源,通常只對文檔的前 1MB 內容進行精細化的元數據掃描。
一旦超過這個閾值,系統會停止尋找 <head> 中的屬性,轉而進入對正文內容的通用抓取模式,這導致預設的元描述無法出現在搜索結果頁。
在 HTML 規範中,元描述標籤必須嚴格放置在 <head> 與 </head> 之間。
如果代碼結構中存在未閉合的標籤,例如在元描述之前的 <script> 標籤缺少結束符號 </script>,或者 <style> 塊未正確閉合,Googlebot 的解析器會產生解析偏離。
在這種情況下,解析器可能認為 <head> 部分已經提前結束,並錯誤地將後續的元描述視為 <body> 區域的一部分。
由於 Google 索引系統對 <body> 內的 <meta> 標籤賦予極低的權重甚至忽略,這會導致摘要提取失敗。
數據監測顯示,在 HTML 語法校驗失敗的站點中,元描述的丟失率比標準合規站點高出 22%。
| 標籤位置與結構狀態 | Googlebot 識別成功率 | 技術性原因分析 |
|---|---|---|
<head> 前 100KB 字符内 |
99.2% | 處於解析器的高優先抓取區,幾乎不受腳本執行干擾。 |
| 位於大量內聯 CSS (超過 1MB) 之後 | 12.5% | 超過了 Googlebot 默認的元數據掃描深度閾值。 |
位於 <body> 標籤起始位置之後 |
5.8% | 違反 W3C 標準,解析器將其視為普通文本片段而非元數據。 |
存在未閉合的上方標籤 (如 <title>) |
0.4% | 導致解析樹結構崩潰,元描述被視為上方標籤的子内容。 |
位於文檔末尾 </html> 之前 |
0.1% | 爬蟲在到達此處前通常已完成索引片段的提取。 |
文檔的字符編碼聲明(Charset Declaration)位置同樣會影響元描述的解析。
根據 Google 的建議,<meta charset="utf-8"> 應當出現在文檔的前 1024 個字符内。
如果編碼聲明被放置在元描述標籤之後,解析器在讀取元描述時可能尚未確定頁面的編碼格式。
對於包含非 ASCII 字符(如特殊符號或多語言字符)的描述內容,這種順序錯誤會導致字符出現亂碼。
當 Google 的算法檢測到元描述內容包含大量無法解析的亂碼字符時,系統會自動過濾該標籤,並從頁面中抓取可讀性更高的純文本作為替代。
JavaScript 渲染
Google 對原始原始碼的處理速度極快,但在處理需要執行腳本的頁面時,渲染隊列的等待時間從 24 小時到 14 天不等。
如果一個頁面使用 React、Vue 或 Angular 等框架,且元描述內容通過 useEffect 或 onMounted 鉤子實時加載,Googlebot 在第一階段抓取的 HTML 文檔中只包含一個空的 <meta name="description" content="">。
此時,索引庫會記錄下這個空值。
即便後續渲染階段成功提取了文字,搜索結果頁更新顯示的時間也會比普通 HTML 頁面慢 3 倍以上。
根據 Chromium 渲染引擎的技术文檔,WRS 模擬的是 Chrome 120 以上版本的無頭瀏覽器環境,並為每個抓取請求分配了 1024MB 的內存配額。
如果頁面加載的 JavaScript 包總體積超過 5MB,或者腳本初始化過程涉及超過 20 個外部 API 請求,渲染器會因為資源消耗過大而停止執行後續的 DOM 修改指令。
在一項針對 50,000 個站點的測試中,腳本執行時長超過 5.5 秒的頁面,其元描述被正確識別的概率下降了 62%。
由於 Google 的抓取預算分配規則限制,對於權重較低的站點,如果渲染器無法在首次執行時獲取元描述,系統會傾向於從頁面正文的第一個 <p> 標籤中提取前 160 個字符作為摘要。
| 渲染技術方案 | 初始 HTML 是否含元描述 | Google 索引生效延遲 | WRS 執行失敗風險 |
|---|---|---|---|
| 客户端渲染 (CSR) | 否(僅有佔位符) | 2 天至 14 天 | 高 |
| 服務端渲染 (SSR) | 是(完整文本) | 即刻生效 | 低 |
| 靜態站點生成 (SSG) | 是(完整文本) | 即刻生效 | 無 |
| 邊緣 SEO (Cloudflare/AWS) | 是(通過請求注入) | 即刻生效 | 低 |
“元描述必須在 DOM 解析的早期階段就處於就緒狀態,任何基於異步請求返回後再填寫的描述内容都會面臨被抓取工具忽略的風險。”
這種技術現象在單頁面應用(SPA)中尤為普遍。
當用戶在瀏覽器中點擊導航時,頁面不會重新加載,元描述通過 history.pushState 進行更新;但對於 Googlebot 而言,它只會抓取該 URL 對應的獨立入口。
如果該入口的原始碼中不包含元描述,僅僅依靠 JavaScript 在客戶端的實時生成,搜索引擎在評估頁面相關性時就會出現偏差,進而導致摘要內容與網頁實際內容不符。
Robots衝突
Googlebot 在處理網頁時,會優先遵循 HTML 原始碼或 HTTP 響應頭中的 robots 指令。
如果代碼中存在特定的限制性標籤,即便開發者在 <meta name="description"> 中撰寫了高質量内容,搜索結果頁(SERP)依然會通過完全屏蔽或強制截斷的方式處理摘要。
這種衝突最常出現在 nosnippet 標籤的使用上。
根據 Google 的官方文檔規定,一旦頁面 HTML 中包含 <meta name="robots" content="nosnippet">,Google 將被禁止為該頁面顯示任何形式的文字說明或視頻預覽。
在針對大規模站點的爬蟲審計中發現,約有 2% 的頁面因為在模板遷移過程中錯誤保留了測試環境的 nosnippet 指令,導致其在生產環境的搜索結果中僅顯示標題和 URL,完全失去了描述文本。
除了完全禁用的指令,max-snippet 指令允許開發者設定搜索結果中摘要的最大字符長度。
如果代碼設定為 <meta name="robots" content="max-snippet:50">,而預設的元描述長度為 150 個字符,Google 算法在多數情況下會認為 50 個字符無法承載足夠的信息量,從而選擇不顯示該描述,或者隨機抽取頁面内符合長度限制的短句。
當該數值被設為 0 時,其技術效果等同於 nosnippet。
下表列出了常見的指令參數及其對元描述顯示的量化影響:
| 指令名稱 | 典型代碼示例 | 對元描述顯示的限制效果 |
|---|---|---|
| nosnippet | content="nosnippet" |
100% 屏蔽,不顯示任何文字摘要。 |
| max-snippet:0 | content="max-snippet:0" |
效果等同於 nosnippet,完全不顯示。 |
| max-snippet:[number] | content="max-snippet:60" |
僅顯示指定數量的字符,超長內容會被丟棄。 |
| indexifembedded | content="noindex, indexifembedded" |
僅在頁面作為 iframe 嵌入他處時才可能顯示摘要。 |
技術層面的排他性衝突不僅限於 HTML 標籤,還經常隱藏在 HTTP 協議的響應頭中,即 X-Robots-Tag。
由於該指令不出現在 HTML 原始碼裡,開發者在通過瀏覽器“查看網頁原始碼”時無法察覺。
在 Nginx 或 Apache 服務器配置中,如果全局設置了 X-Robots-Tag: nosnippet,那麼該服務器下的所有 PDF 文件、圖像或動態頁面都會丟失描述內容。
要核實是否存在此類隱藏指令,需要使用 curl -I [URL] 命令查看服務器返回的 Header 信息。
如果 Headers 中包含 X-Robots-Tag: noindex,Googlebot 甚至不會將頁面存入索引庫,自然也就無法提取和展示元描述。
在 HTML 5 的標準下,開發者可以將該屬性添加到 <span>、<div> 或 <section> 標籤上,告知 Google 不要將該區域的內容用於搜索摘要。
如果一個頁面的主要正文內容都被標記了 data-nosnippet,而 <head> 區域又恰好缺少有效的元描述標籤,Google 渲染引擎在嘗試提取頁面片段(Fragment)時會發現無內容可用。
這種邏輯衝突會導致 Google 強制抓取頁面導覽欄、頁尾版權信息或者其他未被標記的無關文字作為補位描述。
- 多重指令疊加衝突:當頁面同時存在
index和nosnippet時,Google 會採取“最嚴格原則”,優先執行nosnippet。 - CMS 插件默認設置限制:在 Shopify 或 WordPress 站點中,某些安全插件為了防止內容被抓取,會自動在非標準頁面(如搜索結果頁、標籤頁)注入
nosnippet或noarchive,這會覆蓋 SEO 插件手動填寫的描述。 - 緩存過期指令影響:
unavailable_after指令會設定一個具體的時間戳。如果當前時間超過了設定值(例如unavailable_after: 2025-12-31),Google 會停止在 SERP 中展示該頁面的任何摘要。
在某些複雜的跨國站點架構中,CDN 服務商(如 Cloudflare 或 Akamai)可能會在邊緣節點通過 Workers 腳本動態修改響應頭或 HTML 注入。
如果在 CDN 層級誤加了 robots 限制指令,那麼無論後端服務器的原始代碼多麼完美,最終推送到 Googlebot 的數據都會帶有“禁止顯示摘要”的標記。
技術團隊應當定期使用 Google Search Console 的“網址檢查”工具,在“已請求的 URL”選項卡下檢查 HTTP 響應正文,確保沒有任何包含 snippet 關鍵詞的負面指令。
Google 認為它的自動生成更好
根據 Ahrefs 對 19.2 萬個頁面的數據分析,當用戶搜索詞不在元描述中時,Google 的重寫率高達 82.7%;
即使描述中包含關鍵詞,重寫概率依然維持在 59.7%。Google 傾向於利用 BERT 語言模型,從網頁正文中實時抓取約 160 個字符的片段,以確保搜索結果中出現加粗的關鍵詞。
這種做法能讓搜索結果的點擊率(CTR)在統計學上產生 5% 到 10% 的提升,因為它通過加粗詞項反饋了查詢意圖。
算法重寫
當網頁進入索引庫後,算法並不會永久固定其元描述的展示方式。
如果預設的描述文字與用戶輸入的搜索詞缺乏語義交集,算法會從頁面正文中提取約 160 個字符的文本。
這種提取行為通常發生在搜索詞出現在正文第 200 到 500 個字符區間,而元描述中卻完全未提及該詞的情況下。
由於算法的目標是最大化搜索結果的點擊效率,它會優先選擇那些包含加粗關鍵詞的文本片段。
| 觸發場景分類 | 統計重寫概率 | 算法判斷邏輯描述 |
|---|---|---|
| 搜索詞缺失 | 82.7% | 元描述未包含用戶輸入的查詢詞,系統轉而在正文中尋找匹配項。 |
| 描述過長/過短 | 65.4% | 長度超出 960 像素或短於 50 個字符,被判定為信息傳遞效率低。 |
| 內容重複性 | 71.0% | 多個 URL 使用相同的描述模板,算法忽略該標籤並自行抓取獨特內容。 |
| 語義不匹配 | 58.2% | 描述內容屬於品牌推廣語,而查詢詞屬於具體的技術參數檢索。 |
端瀏覽器的展示空間通常限制在 920 像素以內,移動端則縮減至約 600 像素。
如果元描述的長度達到 1000 像素,Google 的前端展示系統會先嘗試截斷,但如果截斷後的句子在語義上支離破碎,後端的摘要生成算法就會判定該元描述為“低質量輸出”。
此時,系統會調用頁面內部的 <h1> 或 <p> 標籤内容,尋找一個能夠在限定像素内完整表達意思的句子進行替換。
| 查詢類型 | 重寫傾向度 | 典型替換來源 |
|---|---|---|
| 信息類查詢 | 高 | 頁面頂部的定義性段落或 FAQ 列表。 |
| 導航類查詢 | 低 | 通常保留預設描述,尤其是包含品牌名時。 |
| 交易類查詢 | 中 | 包含價格、規格或“免費配送”字樣的正文片段。 |
| 長尾詞查詢 | 極高 | 匹配特定長尾詞的 H2 標題下方的首個句子。 |
針對同一個 URL,Google 可能會生成上百種不同的摘要。
例如,當一個關於“雲服務選購指南”的頁面排在“雲服務價格對比”和“雲服務安全性測試”這兩個不同意圖的詞下時,靜態的元描述很難同時覆蓋這兩個維度。
Google 的動態重寫機制會分析頁面正文的結構,如果發現頁面中有一個表格詳細列出了價格,算法就會在用戶搜索“價格”時,自動抓取表格附近的文字作為摘要。
如果網頁正文缺乏邏輯清晰的段落結構,算法可能會抓取導覽菜單、頁尾文字或側邊欄連結,從而產生一段毫無邏輯的搜索摘要,這通常是由於頁面缺乏有效的正文文本密度導致的。
在處理包含大量技術規格或產品屬性的頁面時,如果頁面使用了 Product 或 Review 的 Schema 標記,但元描述中沒有體現這些關鍵屬性,Google 往往會重寫描述以包含評分、價格或庫存狀態。
如果元描述僅僅是“查看我們最新的運動鞋系列”,而正文中有具體的“耐磨性評分 9.5”或“重量 250g”等數據,算法會判定後者對用戶更有參考價值。
為了維持預設描述的顯示,必須確保描述中的信息密度不低於正文前 300 個字符的平均水平。
降低被重寫
如果預設的元描述中沒有包含該頁面排名前三的搜索詞,Google 自動重寫的概率會攀升至 80% 以上。
為了降低這種干預,應將 GSC 導出的高頻詞彙自然嵌入到描述的前 65 個字符內。
具體操作中,需要保持描述內容與頁面 H1 標籤及正文首段的高度語義一致性。
在編寫時,應避免使用模糊的推廣用語,轉而使用包含具體參數、品牌名稱或明確行動指令的陳述句。
- 字符與像素的精確控制: 桌面端搜索結果的顯示寬度上限約為 920 至 960 像素,移動端則在 600 至 680 像素之間。由於不同字符所佔像素不同,單純統計字符數並不準確。建議利用像素檢查工具確保描述在 920 像素內結束,防止因末尾被截斷導致的信息不完整,因為不完整的句子往往會被算法判定為低質量展示,從而觸發自動重寫。
- 消除重複的模板化內容: 在處理擁有數千個頁面的大型電子商務網站時,避免全站共用同一個元描述模板。如果大量 URL 的描述僅有微小差異,Google 抓取工具會忽略這些標籤,認為它們缺乏針對性。建議為高流量頁面人工撰寫唯一的描述,而對於長尾頁面,應確保程序生成的片段具有足夠的辨識度。
- 匹配搜索意圖的動詞選擇: 針對信息類查詢(Informational Queries),描述開頭應使用“了解”、“比較”或“發現”等引導詞;針對交易類查詢(Transactional Queries),則應包含“購買”、“下載”或“價格”等具體詞彙。將描述的語氣調整為與 SERP 中其他排名靠前結果的風格相匹配,能有效維持描述的留存率。
在實際的 SEO 審計中,發現許多站點雖然設置了元描述,但内容與頁面主要討論的主題存在偏差。
例如,一個關於“最佳運行鞋”的頁面,其元描述卻在討論該品牌的歷史,這種語義脫節會導致算法介入。
將元描述設計成一個對頁面内容的精準概括,並包含 2 到 3 個長尾詞,能夠顯著提高其在搜索結果中的展示頻率。
要注意避開 HTML 中的特殊字符,某些未轉義的符號可能會導致解析錯誤,使 Google 無法讀取完整的元描述內容,進而選擇從文本段落中提取隨機片段。
- 數據驅動的優化邏輯: 定期檢查 GSC 中的 CTR 波動。如果一個頁面的平均排名未變但 CTR 出現 3% 以上的下滑,需檢查 SERP 中的摘要是否被重寫。如果發現重寫後的內容主要來自頁面的 FAQ 部分,則說明原有的元描述未能涵蓋用戶的疑問,此時應參考重寫後的片段重新調整元描述的邏輯結構。
- 語義權重的分布: 將最重要的信息放在句子最前方。研究表明,Google 抓取工具對元描述開頭部分的關注度遠高於結尾部分。前 50 個字符應能獨立表達頁面的主要價值主張。
- 避免過度使用標點符號: 過多的感歎號或連續的省略號會降低描述的專業度,算法會傾向於屏蔽這類帶有垃圾信息特徵的內容。保持句子結構平實、中性,符合學術或專業資訊的表達規範。
在處理結構化數據(Schema Markup)時,如果頁面使用了 FAQ 或 Product 架構,元描述應起到銜接和預告的作用,而不是與之完全重複。
對於包含大量技術規格的頁面,嘗試在描述中加入具體的數值數據,如“重量僅 1.2kg”或“支持 4K 分辨率”。


