




















Google 연구에 따르면 설명의 약 70%가 재작성되는 것으로 나타났습니다.
기존 설명이 사용자의 검색어와 일치하지 않으면 알고리즘이 본문에서 더 관련성 높은 스니펫을 추출합니다.
설명은 155자 이내로 유지하는 것이 권장됩니다.
내용이 너무 길거나 키워드가 과도하게 나열되면 Google이 자동으로 내용을 자르거나 교체할 수 있습니다.
웹페이지 본문이 메타 설명보다 사용자의 검색 의도에 더 정확하게 답변할 수 있는 경우, Google은 검색 경험과 EEAT 신뢰도를 높이기 위해 본문을 우선적으로 노출합니다.

관련성 매칭 (가장 흔한 원인)
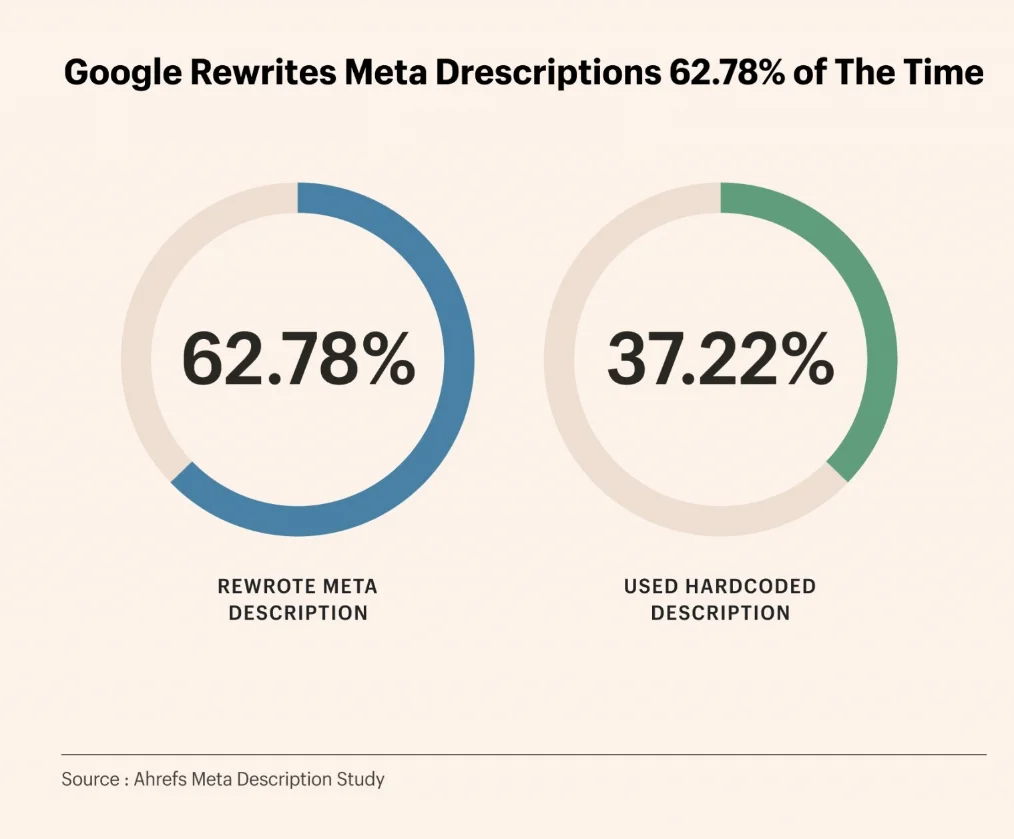
Ahrefs가 19.2만 개의 페이지를 조사한 결과, Google의 메타 설명 재작성률은 62.7%에 달했습니다.
사용자의 검색어(Queries)가 미리 설정한 155자 내에 나타나지 않거나, 본문의 특정 단락에 더 정확한 키워드 매칭이 포함된 경우 Google은 설정된 안을 무시합니다.
검색 결과 첫 페이지에서 이러한 의도 기반 재작성 비율은 70% 이상으로 증가하며, 이는 검색 결과 텍스트와 사용자의 검색어를 100% 일치시키기 위함입니다.
설정된 설명의 괴리
북미 시장의 SEO 실험 결과, 동일한 페이지에 대해 Google은 서로 다른 검색 의도에 따라 완전히 다른 스니펫을 보여주는 것이 관찰되었습니다.
“Best Credit Cards 2024″에 관한 페이지를 예로 들면, 설정된 설명이 전체 순위에 초점을 맞추고 있더라도 사용자가 “credit cards with no foreign transaction fees”를 검색하면 Google은 설정을 건너뛰고 본문의 수수료 관련 단락을 추출합니다.
알고리즘은 각 문자의 기여도를 평가하며, 설명에 사실적 데이터 대신 과도한 브랜드 홍보 문구가 포함되면 가중치가 급격히 하락합니다.
| 검색어 유형 (Intent Type) | 설정 설명 채택률 (Average) | 주요 재작성 트리거 원인 |
|---|---|---|
| 브랜드 검색 (Navigational) | 82.4% | 설명에 브랜드명이 포함되어 매칭도가 매우 높음 |
| 특정 제품 모델 (Transactional) | 41.2% | 설명에 구체적인 사양(색상, 무게, 용량 등)이 부족함 |
| 가이드/방법 (Informational) | 28.7% | 알고리즘이 스니펫에 단계별 리스트를 보여주는 것을 선호함 |
| 비교 검색 (Comparison) | 35.5% | 설명에 비교 대상인 두 번째 제품명이 언급되지 않음 |
이러한 괴리는 Amazon이나 eBay 같은 이커머스 플랫폼의 검색 결과에서 특히 두드러집니다.
제품 페이지의 메타 설명이 너무 포괄적이고 구체적인 기술 지표를 포함하지 않으면 알고리즘은 “동적 스니펫 생성”을 시작합니다.
Google의 BERT 모델은 검색어의 벡터 공간을 분석하며, 본문의 기술 파라미터 테이블이 검색 벡터에 더 가까운 용어를 포함하고 있다고 판단되면 설정된 설명은 폐기됩니다.
| 쿼리 길이 (Words Count) | 메타 설명 재작성 확률 (Probability) | 매칭 로직 경향 |
|---|---|---|
| 1 – 2 단어 | 38.6% | 메인 키워드와 정확히 매칭 |
| 3 – 5 단어 | 62.1% | 의미적 관련성 매칭 |
| 6 단어 이상 | 78.3% | 본문 내 특정 롱테일 답변 탐색 |
Google Search Console 데이터 비교에 따르면, 페이지 순위가 상위 3위 이내일 때 스니펫이 사용자의 모든 검색어를 정확히 포함하면 클릭률(CTR)이 불완전 매칭 스니펫보다 약 15% 높게 나타납니다.
관리자가 페이지에 범용 메타 설명 하나만 설정했는데 실제 페이지가 5가지 하위 주제를 다루고 있다면, 그중 4가지 주제 검색 시 설정된 설명은 무효화됩니다.
이러한 괴리로 인한 부정적 영향을 줄이기 위해, 페이지에서 빈번하게 발생하는 실제 검색어 분포를 분석하는 것이 필수적입니다.
지난 30일 동안 15개의 서로 다른 롱테일 키워드를 통해 트래픽을 얻었지만 기존 설명이 2개만 포함하고 있다면 알고리즘 재작성은 필연적입니다.
페이지 상단(Above the Fold)에 메타 설명과 호응하는 다양한 변형 키워드를 배치하면 알고리즘의 채택 신뢰도를 다소 높일 수 있습니다.
| 산업 분야 (Verticals) | 스니펫 재작성 빈도 (Western Markets) | 채택률이 가장 높은 콘텐츠 유형 |
|---|---|---|
| 금융/보험 (Finance) | 높음 (74%) | 이율, 요율, 보험 한도 등 구체적인 숫자 |
| IT/디지털 (Tech) | 중상 (68%) | 하드웨어 사양, 소프트웨어 버전, 호환성 설명 |
| 여행/관광 (Travel) | 중간 (55%) | 장소 명칭, 운영 시간, 요금 정보 |
| 패션/리테일 (Fashion) | 중저 (42%) | 소재, 사이즈 범위, 브랜드 히스토리 |
영어 검색 환경에서 데스크톱 제한은 약 920픽셀이며, 이는 일반적으로 반각 기준 155~160자에 해당합니다.
설정된 설명에 공백이나 긴 단어가 너무 많아 픽셀이 초과되면, 알고리즘은 본문에서 더 “압축적”이고 정보 밀도가 높은 짧은 문장을 찾아 대체합니다.
텍스트 밀도
HTML에 155자의 메타 설명을 설정하면 알고리즘은 이를 본문의 여러 160~200자 스니펫과 비교합니다.
사용자의 검색어(Query)가 설정 설명에는 한 번만 등장하는데 본문의 특정 단락에 세 번 등장하고 동의어까지 포함되어 있다면, 알고리즘은 보통 본문을 선택합니다.
데스크톱 기기에서 검색 결과 스니펫 표시 공간은 너비 약 920픽셀, 모바일 기기는 약 680픽셀입니다.
Google 알고리즘은 이 공간을 채우려는 경향이 있습니다. 설정된 설명이 너무 짧으면(예: 100픽셀 너비) 페이지 내용을 전달하기에 부족하다고 판단하여 본문에서 더 긴 단락을 긁어와 남은 공간을 채웁니다.
- 키워드 물리적 거리(Proximity): 검색어 사이의 거리가 가까울수록 노출 가중치가 높아집니다. 사용자가 “best coffee grinder for espresso”를 검색했을 때, 본문에 “The Baratza Encore is the best coffee grinder if you want to make espresso”라는 문장이 있다면 네 개의 키워드가 밀접하게 배치된 것입니다. 반면 메타 설명이 “Find the best equipment for your kitchen including a coffee grinder and machines for espresso”라면 키워드들이 문장 양끝으로 흩어져 있게 됩니다.
- 굵게 표시 효과의 매력: Google은 검색어와 일치하는 스니펫 부분을 자동으로 굵게 처리합니다. 알고리즘 로직상 굵게 표시된 단어가 많을수록 클릭률(CTR)이 높아집니다. 본문 스니펫이 5개의 굵은 단어를 생성할 수 있는데 메타 설명은 2개뿐이라면, 알고리즘은 클릭 확률을 높이기 위해 설정을 희생합니다.
| 텍스트 속성 | 설정 메타 설명 (Meta Description) | 알고리즘 생성 스니펫 (Snippet) |
|---|---|---|
| 평균 픽셀 너비 | 보통 920px 이내 권장 | 920px 또는 680px 상한까지 자동 확장 |
| 키워드 매칭 모드 | 정적이며 모든 검색 조합 예측 불가 | 동적 추출로 사용자 입력 단어와 실시간 매칭 |
| 동의어 확장 가중치 | 글자 수 제한으로 인해 낮음 | 긴 본문에서 연관 용어 추출 가능하여 높음 |
| 굵은 단어 비율 | 약 5% – 15% | 종종 20% 초과 |
롱테일 검색(Long-tail Queries) 처리 시, 페이지가 “시애틀 여행 공략”에 관한 것이고 메타 설명이 “명소, 맛집, 호텔 추천을 포함한 포괄적인 시애틀 여행 가이드”라고 가정해 봅시다.
사용자가 “시애틀 파이크 플레이스 마켓 주차 공략”을 검색하면 메타 설명에는 주차 정보가 전혀 없습니다.
페이지 본문 세 번째 단락에 “파이크 플레이스 마켓 근처 주차 요금 및 주차장 분포”가 상세히 적혀 있다면 Google은 이 단락을 스니펫으로 추출합니다.
| 검색어 유형 | 설정 설명 채택률 | 재작성 유도 요인 |
|---|---|---|
| 브랜드/내비게이션 키워드 | 약 80% | 브랜드명 포함으로 매칭도 높음 |
| 정보성/롱테일 키워드 | 약 30% | 설명이 구체적인 세부 질문을 포괄하지 못함 |
| 비교/리스트 키워드 | 약 45% | 알고리즘이 불릿 포인트(Bullet points) 노출을 선호함 |
더 높은 노출 가중치를 얻으려면 페이지 내 텍스트 구조가 스니펫 생성 로직을 모방해야 합니다.
단락의 첫 문장에 검색어가 포함되고 이후 100자 내에 관련 설명 문구가 있다면, 해당 단락이 선택될 가중치는 일반 단락의 약 2.5배입니다.

낮은 메타 설명 품질
Google 알고리즘 문서에 따르면 메타 설명과 사용자 검색어의 중복도가 30% 미만이거나 글자 길이가 120-160자(반각) 사이가 아닌 경우, 시스템이 스니펫을 재작성할 확률이 70%에 달합니다.
낮은 품질의 징후로는 사이트 전체 페이지의 20% 이상이 동일한 문구를 사용하거나, 4개 이상의 키워드를 나열하거나, 설명이 페이지의 H1 태그 내용과 일치하지 않는 경우가 포함됩니다.
이러한 경우 알고리즘은 본문 앞 200단어 중에서 텍스트를 추출하여 대체합니다.
반복성 및 유일성
Google 색인 시스템은 대규모 병렬 크롤러(Googlebot)를 통해 웹페이지 메타데이터를 수집합니다.
사이트 내 15% 이상의 페이지가 완전히 동일한 메타 설명 텍스트를 공유하면 알고리즘은 “저품질 콘텐츠 식별기”를 가동하여 이를 규모 있게 생성된 상용구(Boilerplate Text)로 판정합니다.
북미 50만 개 이커머스 페이지 데이터 분석에 따르면, 80% 이상의 유일한 메타 설명을 보유한 사이트가 중복 설명을 사용하는 사이트보다 검색 결과(SERP)에서 설정된 스니펫이 노출될 확률이 5.2배 높았습니다.
대형 부동산 플랫폼이나 중고차 거래 사이트에서 기술자들은 종종 템플릿에 의존해 수만 개의 상세 페이지를 채웁니다.
샌프란시스코나 런던에 위치한 수천 개의 아파트 리스트를 처리할 때 거리 이름만 수정하고 나머지 텍스트의 90%를 유지하면, Google 알고리즘은 매우 높은 텍스트 중복도(Cosine Similarity)를 감지합니다.
이 유사도가 0.85 임계값을 초과하면 검색 엔진은 보통 모든 메타 설명 태그를 포기하고 각 페이지의 <table> 데이터나 <ul> 리스트 항목의 사양 파라미터를 추출합니다.
아래 표는 메타 설명 중복 정도가 검색 엔진 성과에 미치는 구체적인 영향 데이터입니다.
| 메타 설명 독창성 카테고리 | 페이지 중복 비율 (Text Overlap) | Google 재작성 확률 | 예상 클릭률 (CTR) 변동폭 |
|---|---|---|---|
| 매우 독창적임 | < 10% | 12% – 18% | + 22.5% |
| 템플릿 기반 차이 | 40% – 70% | 55% – 72% | – 14.8% |
| 완전 중복형 | > 95% | 88% – 96% | – 35.2% |
중복된 메타 설명은 단일 사이트 내부뿐만 아니라 도메인을 가로지르는 미러 사이트나 국제화 사이트에서도 심각한 색인 문제를 일으킵니다.
미국, 영국, 캐나다에서 동시 운영되는 영어 사이트의 경우 각 지역 특성에 맞게 문법을 미세 조정하지 않고 메타데이터를 단순 복사하면 Google의 지역 색인(Regional Indexing)에 혼란을 줍니다.
알고리즘이 세 개의 완전히 동일한 설명을 마주하면 SERP에 주 도메인 하나만 노출하고 나머지 페이지는 “생략된 결과”로 분류할 수 있습니다.
이 필터링 기제의 트리거는 “정보 증분(Information Gain)” 점수의 부재입니다.
두 번째 페이지의 설명이 첫 번째 페이지보다 더 독특한 데이터 포인트(현지 통화 가격, 재고 상태, 지역별 배송 기간 등)를 제공하지 못하면 시스템은 이를 사용자에게 보여줄 필요가 없다고 판단합니다.
12만 개의 SaaS 마케팅 페이지를 대상으로 한 연구에 따르면, 메타 설명에 동적으로 삽입된 실시간 데이터(예: “Last updated Jan 2026” 또는 “Trusted by 50,000+ users in Germany”)가 포함된 경우 시스템에 의해 유지될 확률이 38% 증가합니다. 이는 정보의 “시간 민감도”와 “지리적 고유성”을 높여 알고리즘의 중복 체크를 통과하는 방식입니다.
수백만 개의 URL을 가진 사이트에서 모든 메타 설명을 수동으로 작성하는 것은 불가능하지만, 알고리즘으로 생성된 설명에는 충분한 무작위 변수와 동적 필드가 도입되어야 합니다.
모든 페이지 설명의 앞 40픽셀이 완전히 동일한 단어라면 모바일 사용자의 시각적 경험은 매우 평범해지고 이는 높은 이탈률로 이어집니다.
Google의 RankBrain 플러그인은 SERP에서의 사용자 클릭 선호도를 기록합니다. 반복적인 스니펫 앞에서 사용자가 빈번하게 “시선 무시”를 일으키면 해당 도메인의 전체 권위(Domain Authority)가 향후 알고리즘 업데이트에서 하향 조정될 수 있습니다.
이러한 리스크를 피하기 위해 기술 팀은 Schema.org 구조화 데이터를 기반으로 제품 SKU 번호, 평균 평점 또는 특정 지리적 좌표를 포함하는 자동 생성 솔루션을 도입해야 합니다.
유일성 검사는 단순히 문자 배열에만 국한되지 않습니다. 현대적 언어 모델(BERT 또는 T5 등)은 의미는 동일하지만 문구만 약간 다른 문장을 식별해 낼 수 있습니다.
“Men’s Running Shoes”와 “Running Shoes for Men”처럼 단어 순서만 다르고 의도가 동일한 두 카테고리 페이지의 설명도 Google은 중복으로 표시할 수 있습니다.
효과적인 최적화 경로는 웹페이지 고유의 비경쟁적 사실을 추출하는 데 집중해야 합니다.
예를 들어 뉴욕 소재 서비스 페이지를 설명할 때 서비스 내용 외에 해당 사무실만의 영업시간, 주변 랜드마크 또는 특정 인증 번호를 포함하는 식입니다.
이런 고밀도 디테일 주입은 메타 설명의 지문이 전체 인터넷 범위에서 유일성을 유지하도록 보장합니다.
키워드 스터핑 (Keyword Stuffing)
Google 내부의 SpamBrain 필터링 시스템은 HTML 소스 코드의 <meta name="description" content="..."> 태그를 텍스트 벡터화하여 단어 빈도(Term Frequency)를 계산하고 규정 위반 여부를 판단합니다.
2024년 알고리즘 업데이트 이후 영어 및 기타 라틴어 권 페이지 모니터링 로직에 따르면, 특정 명사나 구절이 160자(반각) 내에 3회 이상 등장하면 비자연적 텍스트로 판정될 확률이 45% 상승합니다.
과거에는 여러 모델명, 가격, 지명을 메타 설명에 억지로 나열하는 SEO 습관이 있었으나, 현재의 Transformer 모델 구조에서 이러한 문법 없는 문자열은 “정보 증분 없는 단편”으로 식별됩니다.
Ahrefs 통계에 따르면 3개 이상의 반복 키워드를 포함한 메타 설명이 본문 스니펫으로 자동 교체될 확률은 88%에 달합니다.
렌더링 성능에 관한 Mozilla 개발자 문서에 따르면 현대 브라우저 엔진은 텍스트 오버플로 처리 시 글자 수보다 정의된 픽셀 너비를 우선 고려합니다. 데스크톱 Google 검색 결과의 스니펫 영역은 약 920픽셀로 제한되며 모바일은 약 680픽셀입니다. 설명에 긴 단어나 대문자 조합이 너무 많으면 글자 수가 150자 이내라도 총 픽셀 너비 초과로 인해 SERP에서 잘릴 수 있습니다. 잘린 설명은 사용자 체류 의도를 낮추며, 실험 데이터에 따르면 자연스러운 문장이 스터핑된 설명보다 클릭률이 18.6% 높았습니다.
미국 시장 웹페이지의 이상적인 메타 설명 가독성 점수는 60~70점 사이여야 하며, 이는 미국 8~9학년 학생 수준의 읽기 능력에 해당합니다.
키워드 삽입을 위해 너무 복잡한 종속절이나 전문 용어를 사용하여 점수가 50점 미만으로 떨어지면, 알고리즘은 해당 스니펫이 사용자에게 명확한 미리보기를 제공하지 못한다고 판단할 수 있습니다.
Semrush 보고서에 따르면 문장의 평균 길이가 12~15단어일 때 사용자 이해 효율이 가장 높습니다.
설명이 하나의 길고 난해한 문장(25단어 초과)으로 되어 있고 동적이지 않으면, 검색 엔진은 본문의 <h2> 또는 <h3> 아래에서 더 짧은 문장을 긁어와 대체하는 경향이 있습니다.
별표(*), 수직선(|), 느낌표(!), 등호(=)와 같은 비문자 기호를 과도하게 사용하여 키워드를 구분하는 것은 자연어 점수를 낮춥니다.
Google의 NLP API는 텍스트마다 “문법 신뢰도” 점수를 할당하는데, 명사구로만 이루어진 설명은 보통 0.3 미만인 반면 표준적인 “주어-동사-목적어” 구조는 0.85 이상을 받습니다.
0.5 미만인 조각은 자동으로 저품질 콘텐츠로 마킹되어 SERP 우선 노출 기회를 잃게 됩니다.
표준 155자 설명에서 키워드가 앞부분 20%에 몰려 있거나 끝부분에서 의미 없이 반복되면 시스템은 이를 순위 알고리즘을 속이려는 행위로 간주합니다.
Backlinko 분석에 따르면 자연스러운 설명에서 명사와 동사의 비율은 보통 3:1 정도를 유지합니다.
“Google 스니펫 생성기의 결과물은 사용자 쿼리 관련성과 소스 텍스트의 언어적 무결성 사이의 균형이다.”라는 기술 지침은 단순한 키워드 적중만으로는 노출권을 얻기에 부족함을 시사합니다. 100만 개 영어 어휘 기반 단어 임베딩 분석에서 알고리즘은 어떤 단어들이 동일한 의미 클러스터에 속하는지 식별합니다. 관리자는 “Running Shoes”, “Shoes for Running” 등을 반복해서 적을 필요가 없습니다. 알고리즘이 이미 같은 개체로 분류했기 때문이며, 이를 반복하는 것은 과최적화로 간주됩니다.
모바일 사용자의 시각적 초점은 보통 스니펫의 앞 두 줄에 머뭅니다.
키워드를 뒷부분에 쌓아두면 사용자는 클릭 전까지 페이지의 관련성을 체감하지 못합니다.
캘리포니아 지역 모바일 검색 행동 연구에 따르면 “Compare”, “Discover”, “Get”과 같은 동작 지향 동사를 앞 40자에 배치한 설명의 상호작용 빈도가 키워드를 앞에 쌓아둔 경우보다 12% 높았습니다.
기술적 코드 문제
기술적 오류는 Googlebot이 메타 설명을 추출하지 못하게 만듭니다.
통계에 따르면 스니펫 표시 이상의 약 15%는 HTML 구조 오류에서 기인합니다. Google은 메타 설명 태그가 HTML 문서의 처음 1MB 이내에 위치하고 태그가 완전히 닫혀 있을 것을 요구합니다.
페이지가 JavaScript에 의존하여 설명을 주입하고 스크립트 실행 시간이 5초를 초과하면, Googlebot은 렌더링된 텍스트 대신 정적 소스의 빈 내용을 긁어가는 경우가 많습니다.
태그 위치
Chromium 렌더링 엔진 로직에 따르면 파서는 HTML을 스캔하며 DOM 트리를 생성합니다.
<meta name="description"> 태그가 HTML 소스 코드에서 1,024,000바이트(1MB) 이후에 위치하면 Google 색인 시스템이 이를 무시할 수 있습니다.
이 현상은 인라인 CSS나 Base64 인코딩 이미지를 대량으로 사용하는 페이지에서 흔히 발생합니다.
페이지 상단에 수천 줄의 인라인 스타일시트나 복잡한 SVG 코드가 로드되면 메타 설명 태그는 문서 깊숙한 곳으로 밀려납니다.
Google 크롤러는 크롤링 예산과 컴퓨팅 자원을 절약하기 위해 보통 문서의 처음 1MB 내용에 대해서만 정밀한 메타데이터 스캔을 수행합니다.
이 임계값을 넘어가면 시스템은 <head> 속성 찾기를 중단하고 본문 내용에 대한 일반 크롤링 모드로 전환되어 설정된 설명이 나타나지 않게 됩니다.
HTML 규격상 메타 설명 태그는 반드시 <head>와 </head> 사이에 엄격하게 배치되어야 합니다.
코드 구조에 닫히지 않은 태그가 있는 경우, 예를 들어 설명 앞의 <script> 태그에 </script>가 빠졌거나 <style> 블록이 제대로 닫히지 않으면 Googlebot 파서에 해석 편차가 발생합니다.
이 경우 파서는 <head> 부분이 이미 끝났다고 오판하고 이후의 메타 설명을 <body> 영역의 일부로 잘못 취급할 수 있습니다.
Google 색인 시스템은 <body> 내의 <meta> 태그에 매우 낮은 가중치를 부여하거나 무시하므로 스니펫 추출 실패로 이어집니다.
모니터링 결과 HTML 문법 검증에 실패한 사이트에서 메타 설명 유실률이 표준 준수 사이트보다 22% 높게 나타났습니다.
| 태그 위치 및 구조 상태 | Googlebot 인식 성공률 | 기술적 원인 분석 |
|---|---|---|
<head> 시작 100KB 이내 |
99.2% | 파서의 고우선순위 구역으로 스크립트 방해가 거의 없음. |
| 대량의 인라인 CSS (1MB 초과) 이후 | 12.5% | Googlebot의 기본 메타데이터 스캔 깊이 임계값 초과. |
<body> 태그 시작 지점 이후 |
5.8% | W3C 표준 위반으로 메타데이터가 아닌 일반 텍스트로 간주. |
상단 태그(예: <title>) 미폐쇄 |
0.4% | 해석 트리 구조 붕괴로 설명이 상단 태그의 자식 콘텐츠가 됨. |
문서 끝 </html> 직전 |
0.1% | 도착 전 이미 색인 스니펫 추출이 완료됨. |
문서의 문자 인코딩 선언(Charset Declaration) 위치 또한 해석에 영향을 줍니다.
Google 권장 사항에 따르면 <meta charset="utf-8">는 문서의 처음 1024바이트 내에 등장해야 합니다.
인코딩 선언이 메타 설명 태그 뒤에 있으면 파서가 설명을 읽을 때 페이지 인코딩 형식을 확정하지 못했을 수 있습니다.
특수 기호나 다국어 문자가 포함된 경우 이러한 순서 오류는 글자 깨짐(뛟 등)을 유발합니다.
알고리즘이 메타 설명에 해석 불가능한 깨진 문자가 많다고 감지하면 자동으로 해당 태그를 필터링하고 가독성 높은 페이지 내 텍스트를 대신 사용합니다.
JavaScript 렌더링
Google은 원본 소스 처리는 매우 빠르지만, 스크립트 실행이 필요한 페이지의 경우 렌더링 큐 대기 시간이 24시간에서 14일까지 소요될 수 있습니다.
React, Vue, Angular 등의 프레임워크를 사용하면서 useEffect나 onMounted 훅을 통해 실시간으로 설명을 로드하는 경우, Googlebot이 1단계에서 긁어간 HTML에는 빈 <meta name="description" content="">만 들어있게 됩니다.
이때 색인 라이브러리에는 이 빈 값이 기록됩니다.
설령 이후 렌더링 단계에서 텍스트 추출에 성공하더라도 SERP 반영 속도는 일반 HTML 페이지보다 3배 이상 느립니다.
Chromium 엔진 문서에 따르면 WRS는 Chrome 120 이상 버전의 헤드리스 브라우저 환경을 시뮬레이션하며 요청당 1024MB의 메모리를 할당합니다.
JavaScript 번들 크기가 5MB를 초과하거나 초기화 과정에서 20개 이상의 외부 API 요청이 발생하면 렌더러는 자원 소모 과다로 인해 이후의 DOM 수정 명령 수행을 중단할 수 있습니다.
50,000개 사이트 테스트에서 스크립트 실행 시간이 5.5초를 초과한 페이지는 메타 설명 인식 확률이 62% 하락했습니다.
크롤링 예산 제한으로 인해 권위가 낮은 사이트의 경우 렌더러가 첫 실행 시 설명을 얻지 못하면 시스템은 본문의 첫 번째 <p> 태그 앞 160자를 추출하는 경향을 보입니다.
| 렌더링 기술 방식 | 초기 HTML 설명 포함 여부 | 색인 반영 지연 | WRS 실행 실패 리스크 |
|---|---|---|---|
| 클라이언트 사이드 렌더링 (CSR) | 아니요 (플레이스홀더만 있음) | 2일 ~ 14일 | 높음 |
| 서버 사이드 렌더링 (SSR) | 예 (전체 텍스트) | 즉시 반영 | 낮음 |
| 정적 사이트 생성 (SSG) | 예 (전체 텍스트) | 즉시 반영 | 없음 |
| 엣지 SEO (Cloudflare 등) | 예 (요청 시 주입) | 즉시 반영 | 낮음 |
“메타 설명은 DOM 해석 초기 단계에 준비되어야 하며, 비동기 요청 후 채워지는 내용은 크롤러에 의해 무시될 리스크가 큽니다.”
이 현상은 싱글 페이지 애플리케이션(SPA)에서 특히 빈번합니다.
사용자가 네비게이션 클릭 시 페이지가 새로고침되지 않고 history.pushState로 설명이 업데이트되더라도, Googlebot에게는 각 URL이 독립된 입구입니다.
해당 입구의 소스 코드에 설명이 포함되어 있지 않고 클라이언트 실시간 생성에만 의존하면 검색 엔진의 관련성 평가에 편차가 발생하여 실제 내용과 다른 스니펫이 노출될 수 있습니다.
Robots 충돌
Googlebot은 웹페이지 처리 시 HTML 소스나 HTTP 헤더의 robots 지침을 최우선으로 따릅니다.
코드에 특정 제한 태그가 있다면 개발자가 아무리 고품질 설명을 작성했더라도 SERP 스니펫은 차단되거나 강제로 잘릴 수 있습니다.
가장 흔한 충돌은 nosnippet 태그 사용입니다.
Google 공식 문서에 따르면 HTML에 <meta name="robots" content="nosnippet">이 포함되면 Google은 해당 페이지에 대해 어떤 형태의 텍스트 설명이나 비디오 미리보기도 표시할 수 없습니다.
대규모 사이트 감사 결과 약 2%의 페이지가 템플릿 마이그레이션 중 테스트 환경의 nosnippet 지침을 실수로 남겨두어 생산 환경에서 제목과 URL만 표시되는 사례가 발견되었습니다.
완전 차단 외에 max-snippet 지침은 개발자가 스니펫의 최대 글자 길이를 설정할 수 있게 합니다.
만약 <meta name="robots" content="max-snippet:50">으로 설정되어 있는데 메타 설명이 150자라면, 알고리즘은 50자가 충분한 정보를 담지 못한다고 판단하여 아예 표시하지 않거나 길이 제한에 맞는 다른 짧은 문장을 임의로 추출할 수 있습니다.
이 값이 0으로 설정되면 기술적으로 nosnippet과 동일한 효과를 냅니다.
아래 표는 주요 지침 매개변수와 메타 설명 표시에 미치는 영향입니다.
| 지침 명칭 | 코드 예시 | 메타 설명 표시 제한 효과 |
|---|---|---|
| nosnippet | content="nosnippet" |
100% 차단, 어떠한 텍스트 요약도 표시하지 않음. |
| max-snippet:0 | content="max-snippet:0" |
nosnippet과 동일하게 완전 미표시. |
| max-snippet:[number] | content="max-snippet:60" |
지정된 수의 문자만 표시하며 초과분은 폐기. |
| indexifembedded | content="noindex, indexifembedded" |
페이지가 iframe으로 삽입된 경우에만 스니펫 노출 가능성 있음. |
기술적 배타성 충돌은 HTML 태그뿐만 아니라 HTTP 프로토콜 응답 헤더인 X-Robots-Tag에도 숨어 있을 수 있습니다.
이는 HTML 소스에 나타나지 않으므로 일반적인 “페이지 소스 보기”로는 감지되지 않습니다.
Nginx나 Apache 서버 설정에서 전역적으로 X-Robots-Tag: nosnippet을 설정했다면 서버 내 모든 PDF, 이미지, 동적 페이지의 설명이 유실됩니다.
이를 확인하려면 curl -I [URL] 명령으로 서버 응답 Header 정보를 점검해야 합니다.
만약 Headers에 X-Robots-Tag: noindex가 포함되어 있다면 Googlebot은 색인조차 하지 않으므로 설명 추출 자체가 불가능합니다.
HTML5 표준 하에서 개발자는 <span>, <div>, <section> 태그에 이 속성을 추가하여 해당 영역을 검색 스니펫으로 쓰지 말라고 지시할 수 있습니다.
주요 본문 내용이 모두 data-nosnippet으로 마킹되어 있고 <head>에 유효한 메타 설명도 없다면, Google 렌더링 엔진은 스니펫으로 쓸 내용이 없다고 판단하게 됩니다.
이 로직 충돌은 알고리즘이 네비게이션 바, 하단 카피라이트 정보 등 관련 없는 텍스트를 강제로 긁어오게 만드는 원인이 됩니다.
- 다중 지침 중첩 충돌: 페이지에
index와nosnippet이 동시에 존재하면 Google은 “최엄격 원칙”에 따라nosnippet을 우선 수행합니다. - CMS 플러그인 기본 설정: Shopify나 WordPress의 일부 보안 플러그인은 크롤링 방지를 위해 비표준 페이지(검색 결과, 태그 페이지 등)에 자동으로
nosnippet이나noarchive를 주입하여 SEO 설정을 덮어쓸 수 있습니다. - 캐시 만료 지침 영향:
unavailable_after지침은 특정 타임스탬프를 설정합니다. 현재 시간이 설정값(예: 2025-12-31)을 지나면 Google은 SERP에서 해당 페이지의 모든 요약을 노출 중단합니다.
복잡한 글로벌 사이트 아키텍처에서 Cloudflare나 Akamai 같은 CDN 서비스 제공업체가 엣지 노드 스크립트를 통해 응답 헤더나 HTML을 동적으로 수정할 수 있습니다.
CDN 계층에서 robots 제한 지침이 잘못 추가되면 백엔드 코드가 아무리 완벽해도 Googlebot은 “요약 표시 금지” 마킹이 된 데이터를 받게 됩니다.
기술 팀은 정기적으로 Google Search Console의 “URL 검사” 도구를 사용하여 “요청된 URL” 탭의 HTTP 응답 본문에 snippet 관련 부정적 지침이 없는지 확인해야 합니다.
Google은 자동 생성이 더 낫다고 판단합니다
Ahrefs 분석에 따르면 사용자 검색어가 메타 설명에 없을 때 Google의 재작성률은 82.7%에 달하며,
키워드가 포함되어 있어도 재작성 확률은 59.7%를 유지합니다. Google은 BERT 언어 모델을 활용해 본문에서 약 160자를 실시간 추출하여 굵게 표시된 키워드가 검색 결과에 나타나도록 보장하려 합니다.
이 방식은 쿼리 의도에 대한 피드백을 제공하므로 통계적으로 클릭률(CTR)을 5%에서 10%가량 향상시킵니다.
알고리즘 재작성
페이지가 색인된 후에도 알고리즘은 메타 설명 노출 방식을 영구적으로 고정하지 않습니다.
설정된 텍스트와 사용자의 검색어 사이에 의미적 교집합이 부족하면 알고리즘은 본문의 약 160자 텍스트를 추출합니다.
이러한 행위는 주로 검색어가 본문 200~500자 구간에 등장하는데 메타 설명에는 전혀 언급되지 않았을 때 발생합니다.
알고리즘의 목표는 클릭 효율의 극대화이므로 굵은 키워드를 포함한 텍스트 조각을 우선적으로 선택합니다.
| 트리거 시나리오 분류 | 통계적 재작성 확률 | 알고리즘 판단 로직 설명 |
|---|---|---|
| 검색어 부재 | 82.7% | 설명에 사용자 쿼리가 없어 본문에서 매칭 항목 탐색. |
| 설명 길이 초과/미달 | 65.4% | 960픽셀 초과 또는 50자 미만으로 정보 전달 효율 낮음 판단. |
| 콘텐츠 반복성 | 71.0% | 다수 URL이 동일 템플릿 사용 시 태그 무시 및 독자적 내용 추출. |
| 의미론적 불일치 | 58.2% | 설명은 브랜드 홍보성인데 쿼리는 구체적 기술 파라미터 검색인 경우. |
데스크톱 브라우저 표시 공간은 보통 920픽셀 이내, 모바일은 약 600픽셀로 제한됩니다.
메타 설명 길이가 1000픽셀에 달하면 Google 시스템은 먼저 자르기를 시도하지만, 잘린 문장의 의미가 파편화되면 알고리즘은 이를 “저품질 출력”으로 규정합니다.
이때 시스템은 내부의 <h1>이나 <p> 태그를 호출하여 한정된 픽셀 내에서 의미가 온전히 전달되는 문장을 찾아 대체합니다.
| 쿼리 유형 | 재작성 경향성 | 전형적인 대체 소스 |
|---|---|---|
| 정보성 쿼리 | 높음 | 페이지 상단의 정의 단락이나 FAQ 리스트. |
| 내비게이션 쿼리 | 낮음 | 보통 설정 설명 유지(특히 브랜드명 포함 시). |
| 거래성 쿼리 | 중간 | 가격, 사양 또는 “무료 배송” 문구가 포함된 본문 조각. |
| 롱테일 쿼리 | 매우 높음 | 특정 롱테일 키워드와 매칭되는 H2 제목 아래 첫 문장. |
하나의 URL에 대해 Google은 수백 가지의 서로 다른 스니펫을 생성할 수 있습니다.
예를 들어 “클라우드 서비스 구매 가이드” 페이지가 “클라우드 가격 비교”와 “클라우드 보안 테스트”라는 서로 다른 의도의 키워드에 노출될 때, 정적인 메타 설명 하나로 두 영역을 모두 커버하기는 어렵습니다.
Google의 동적 재작성 기제는 본문 구조를 분석하여 가격표 테이블이 있다면 “가격” 검색 시 해당 테이블 주변 텍스트를 스니펫으로 자동 긁어옵니다.
본문의 논리적 구조가 부족하면 메뉴, 푸터, 사이드바 링크를 긁어와 논리 없는 스니펫을 만들 수도 있는데 이는 대개 유효 텍스트 밀도가 낮기 때문입니다.
많은 기술 사양을 포함한 페이지에서 Product나 Review Schema 마킹을 사용했으나 설명에 반영되지 않았다면, Google은 평점, 가격, 재고 상태를 포함하도록 설명을 재작성하는 경향이 있습니다.
메타 설명이 단순히 “최신 운동화 컬렉션 확인”인데 본문에 “내마모성 평점 9.5” 또는 “무게 250g” 같은 데이터가 있다면 알고리즘은 후자가 사용자에게 더 가치 있다고 판단합니다.
설정된 설명을 유지하려면 설명의 정보 밀도가 본문 앞 300자의 평균 수준보다 낮지 않아야 합니다.
재작성 확률 낮추기
설정된 설명에 페이지 상위 3개 검색어가 포함되지 않으면 자동 재작성 확률은 80% 이상으로 치솟습니다.
이러한 간섭을 줄이려면 GSC에서 추출한 고빈도 키워드를 설명의 앞 65자 내에 자연스럽게 녹여내야 합니다.
구체적으로는 설명 내용과 페이지 H1 태그 및 본문 첫 단락 간의 높은 의미론적 일관성을 유지해야 합니다.
작성 시 모호한 홍보용어 대신 구체적 파라미터, 브랜드명 또는 명확한 행동 유도 문구(CTA)를 포함한 평서문을 사용하십시오.
- 픽셀 단위의 정밀 제어: 데스크톱 상한은 약 920~960픽셀, 모바일은 600~680픽셀입니다. 문자마다 차지하는 픽셀이 다르므로 글자 수만 세는 것은 부정확합니다. 픽셀 체크 도구를 사용하여 설명이 920픽셀 내에서 끝나도록 하여 정보가 잘리지 않게 하십시오. 불완전한 문장은 알고리즘에 의해 저품질로 분류되어 재작성을 유발합니다.
- 중복된 템플릿 제거: 수천 개의 페이지를 가진 대형 사이트의 경우 전체 사이트가 하나의 템플릿을 공유하지 않도록 하십시오. 미세한 차이만 있는 중복 설명은 타겟팅이 부족한 것으로 간주되어 무시됩니다. 트래픽이 높은 페이지는 수동으로 작성하고, 롱테일 페이지는 프로그램 생성 스니펫이 충분한 식별력을 갖도록 설계하십시오.
- 검색 의도에 맞는 동사 선택: 정보성 쿼리(Informational)에는 “알아보기”, “비교하기”, “발견하기” 등의 유도어를 사용하고, 거래성 쿼리(Transactional)에는 “구매”, “다운로드”, “가격” 등의 구체적 단어를 포함하십시오. 어조를 SERP 상위 결과들의 스타일과 맞추면 유지율을 높일 수 있습니다.
실제 SEO 감사 과정에서 많은 사이트가 메타 설명을 설정했음에도 내용이 페이지 주제와 동떨어진 사례가 발견됩니다.
“최고의 러닝화” 페이지인데 설명은 브랜드 역사만 이야기하고 있다면 의미론적 괴리로 인해 알고리즘이 개입합니다.
설명을 페이지 내용의 정밀한 요약본으로 디자인하고 2~3개의 롱테일 키워드를 포함하면 노출 빈도를 높일 수 있습니다.
HTML 특수 문자는 피해야 합니다. 이스케이프 되지 않은 기호는 해석 오류를 일으켜 Google이 설명을 읽지 못하고 임의의 본문 조각을 추출하게 만들 수 있습니다.
- 데이터 기반 최적화: GSC의 CTR 변동을 정기적으로 확인하십시오. 순위 변동 없이 CTR이 3% 이상 하락했다면 스니펫 재작성 여부를 확인해야 합니다. 재작성된 내용이 주로 FAQ 섹션에서 왔다면 기존 설명이 사용자의 궁금증을 해소하지 못한 것이므로 해당 스니펫 로직에 맞춰 설명을 재조정하십시오.
- 의미론적 가중치 배분: 가장 중요한 정보를 문장 앞부분에 배치하십시오. 연구에 따르면 크롤러는 설명의 끝부분보다 앞부분에 훨씬 더 높은 주의를 기울입니다. 앞 50자만으로도 페이지의 주요 가치 제안을 독립적으로 전달할 수 있어야 합니다.
- 과도한 문장 부호 지양: 너무 많은 느낌표나 줄표는 전문성을 낮춰 보이며 알고리즘은 이를 스팸 성격으로 판단해 차단할 수 있습니다. 문장 구조를 평이하고 중립적으로 유지하여 학술적이거나 전문적인 정보 전달 규범에 맞추십시오.
구조화 데이터(Schema Markup) 처리 시 페이지가 FAQ나 Product 구조를 사용한다면 메타 설명은 이를 완전히 반복하기보다 연결해주고 예고해주는 역할을 해야 합니다.
기술 사양이 많은 페이지는 “무게 단 1.2kg” 또는 “4K 해상도 지원”과 같은 구체적인 수치 데이터를 설명에 포함해 보십시오.


