




















ใช่ครับ พารามิเตอร์ URL (เช่น การเรียงลำดับ ?sort, การกรอง ?color หรือรหัสติดตาม) เป็นสาเหตุหลักที่ทำให้ Google จัดทำดัชนีซ้ำซ้อน
เพื่อให้แน่ใจว่าทราฟฟิกการค้นหาจะถูกนำไปยังหน้าเป้าหมายอย่างแม่นยำ ขอแนะนำให้ดำเนินการดังนี้:
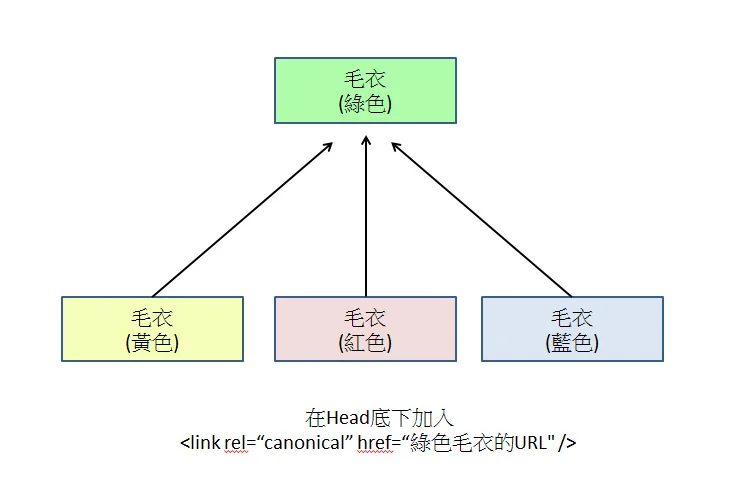
ตั้งค่า Canonical Tag
เพิ่ม rel="canonical" ใน HTML ของหน้าตัวแปรทั้งหมด โดยชี้ไปยัง URL หลักเพียงหนึ่งเดียว
จัดการเส้นทางการรวบรวมข้อมูล (Crawl Path)
บล็อกพารามิเตอร์การติดตามการตลาดที่ไม่จำเป็น (เช่น utm_) ผ่าน Robots.txt
รวมสัญญาณการจัดอันดับ
สิ่งนี้จะช่วยให้ Google รวม “คะแนนความน่าเชื่อถือ” ของหน้าพารามิเตอร์ทั้งหมดไว้ที่หน้าหลัก เพื่อป้องกันไม่ให้อันดับลดลงจากการแข่งขันภายในเว็บไซต์เอง
ความซ้ำซ้อนของเนื้อหา
พารามิเตอร์ URL อาจทำให้เกิดที่อยู่ซ้ำซ้อนจำนวนมากสำหรับหน้าเดียวกัน
ตัวอย่างเช่น หน้าอีคอมเมิร์ซที่มีตัวกรองสี 5 แบบและวิธีการเรียงลำดับ 3 แบบ จะทำให้เกิด URL ที่แตกต่างกันมากกว่า 15 รายการ
ไซต์ขนาดใหญ่มักถูกพารามิเตอร์ตัวแปรเหล่านี้แย่งชิงโควตาการรวบรวมข้อมูล (Crawl Budget) ไปประมาณ 40%
เมื่อ Google จัดทำดัชนีหน้าแรกที่เหมือนกัน 200 หน้าซึ่งมีส่วนขยายติดตาม UTM น้ำหนักการค้นหาของหน้าหลักจะถูกแบ่งออก ส่งผลให้อันดับลดลงประมาณ 25%
ลิงก์กระจัดกระจาย
ในกลไกการจัดทำดัชนีของ Google URL ที่มีส่วนขยายต่างกันจะถูกมองว่าเป็นเอนทิตีที่แยกจากกัน
ตัวอย่างเช่น หากหน้าเอกสารทางเทคนิคหน้าหนึ่งได้รับแบ็คลิงก์จากโดเมนที่แตกต่างกัน 50 โดเมน แต่ในจำนวนนั้น 20 ลิงก์ชี้ไปยังเวอร์ชันที่มี ?utm_medium=email และอีก 10 ลิงก์ชี้ไปยังเวอร์ชันที่มี ?ref=footer URL หลักจะได้รับน้ำหนักรวมเพียง 40% เท่านั้น
จากการวิเคราะห์ข้อมูลสุ่มของ Ahrefs ปรากฏการณ์การเจือจางน้ำหนักนี้จะทำให้หน้าเว็บมีอันดับต่ำกว่าที่คาดไว้ 3 ถึง 5 อันดับเมื่อแข่งขันในคำค้นหาที่มีความยากสูง
บอทจะไม่รวบรวมพลังของลิงก์ทั้งหมดไปยังหน้าต้นฉบับโดยอัตโนมัติเมื่อระบุเส้นทางที่กระจัดกระจายเหล่านี้ เว้นแต่เว็บไซต์จะมีการกำหนดค่าลอจิกการจัดการไว้อย่างชัดเจนในซอร์สโค้ด
ในโมเดลการคำนวณ PageRank การส่งต่อลิงก์จะเป็นไปตามกฎทางคณิตศาสตร์ที่อ้างอิงจากค่าสัมประสิทธิ์การลดทอน 0.85
ทุกลิงก์ที่เข้ามาในไซต์จะเพิ่มน้ำหนักให้กับ URL ที่เฉพาะเจาะจง
เมื่อน้ำหนักนี้ถูกจัดสรรให้กับส่วนขยายที่ไม่ได้สร้างขึ้นแบบคงที่ เช่น ?sessionid หรือ ?click_id “คะแนนความเชื่อถือ” ของหน้าหลักจะไม่ถึงเกณฑ์ที่กำหนดเพื่อกระตุ้นให้อันดับแสดงในหน้าแรก
ในการแข่งขันในอุตสาหกรรม SaaS ของตลาดสหรัฐฯ หน้าสามอันดับแรกมักจะมีลักษณะลิงก์ที่สะอาดมาก
หากน้ำหนักของหน้าเว็บถูกแบ่งไปยังเวอร์ชันพารามิเตอร์ที่ต่างกันมากกว่า 5 เวอร์ชัน Google อาจสลับการแสดงหน้าเหล่านี้ในผลการค้นหา ซึ่งสถานะการแข่งขันภายในนี้จะทำให้ประสิทธิภาพของหน้าหลักไม่เสถียร
แพลตฟอร์มอีคอมเมิร์ซหลายแห่งที่ใช้สถาปัตยกรรม Magento หรือ Salesforce Commerce Cloud จะสร้างลิงก์ภายในที่มีพารามิเตอร์จำนวนมากในแถบนำทาง (Breadcrumb) หรือตัวกรองแถบข้าง
หากการนำทางภายในชี้ไปยัง category?sort=newest บ่อยครั้งแทนที่จะเป็นที่อยู่หมวดหมู่แบบคงที่ การไหลเวียนของน้ำหนักภายในไซต์จะเกิดการเบี่ยงเบน
เมื่อบอทพบว่าเป้าหมายเดียวกันมีทางเข้าหลายทางและโครงสร้าง URL แตกต่างกันในระหว่างการรวบรวมข้อมูล ระดับลำดับความสำคัญในการจัดตารางเวลาสำหรับหน้าดังกล่าวจะลดลง
แพลตฟอร์มโซเชียลมีเดียและระบบโฆษณาบุคคลที่สามมักจะบังคับเพิ่มพารามิเตอร์ของตนเองในระหว่างการเปลี่ยนเส้นทาง เช่น ?fbclid หรือ ?gclid
หากหน้าเว็บขาด rel=”canonical” tag ที่มีประสิทธิภาพ อัลกอริทึมของ Google อาจเลือกหน้าที่มีพารามิเตอร์โฆษณาเป็นตัวแทนการค้นหาของเนื้อหานั้นโดยผิดพลาดหลังจากรอบการรวบรวมข้อมูลหลายสัปดาห์
สถานการณ์นี้จะทำให้คลิกเรต (CTR) ลดลงประมาณ 15% เนื่องจากเมื่อผู้ใช้เห็น URL ที่ยาวและดูเหมือนมีรหัสที่อ่านไม่รู้เรื่องในผลการค้นหา ความตั้งใจในการคลิกจะต่ำกว่าที่อยู่แบบคงที่ที่กระชับอย่างชัดเจน
เมื่อลิงก์ภายนอกถูกรวบรวมไว้ในเวอร์ชันพารามิเตอร์ชั่วคราวเหล่านี้ การพยายามดึงพลังเหล่านี้กลับคืนสู่หน้าหลักด้วยวิธีการทางเทคนิคในภายหลังมักจะต้องใช้กระบวนการจัดทำดัชนีใหม่ที่ยาวนานหลายเดือน
ผลกระทบจากการคูณเส้นทาง (Path Multiplication Effect)
ในสถาปัตยกรรมพาณิชย์อิเล็กทรอนิกส์สมัยใหม่ (เช่น Shopify หรือ Magento) เมื่อหน้าหมวดหมู่พื้นฐานมีคุณลักษณะการกรองหลายแบบ มิติของพารามิเตอร์ใหม่แต่ละมิติจะถูกนำมาจัดหมู่และเรียงลำดับกับพารามิเตอร์ที่มีอยู่
ตัวอย่างเช่น หน้าหมวดหมู่รองเท้ากีฬามาตรฐาน หากหน้านี้มีตัวเลือกสี 10 แบบ, ขนาด 12 ไซส์, ตัวกรองแบรนด์ 5 แบรนด์ และการเรียงลำดับช่วงราคา 4 แบบ เส้นทาง URL อิสระที่สร้างขึ้นตามทฤษฎีจะสูงถึง 10 × 12 × 5 × 4 = 2,400 รายการ
หากลอจิกของโปรแกรมอนุญาตให้สลับลำดับพารามิเตอร์ได้ (เช่น เส้นทางการเลือกสีก่อนแล้วตามด้วยไซส์ แตกต่างจากเส้นทางการเลือกไซส์ก่อนแล้วตามด้วยสี) ตัวเลขนี้จะพองตัวขึ้นไปอีก
ภายใต้ผลกระทบจากการคูณเส้นทางนี้ หน้าเว็บที่มีเนื้อหาจริงเพียงหน้าเดียวจะกลายเป็นทางเข้าถึงที่แตกต่างกันหลายพันทางในสายตาของบอท Google
เส้นทางที่ซ้ำซ้อนเหล่านี้ หากขาดการจัดการที่มีประสิทธิภาพ จะแย่งชิงโควตาการรวบรวมข้อมูลมากกว่า 65% ของไซต์ขนาดกลางและขนาดใหญ่ ส่งผลให้หน้าหน้าแสดงรายละเอียดสินค้าที่จำเป็นต้องอัปเดตจริงๆ ไม่ได้รับความถี่ในการสแกนที่เพียงพอ
| ขั้นตอนการรวมพารามิเตอร์ | ขนาดของตัวแปร | จำนวน URL ที่ไม่ซ้ำกันที่สร้างขึ้น | การประมาณการใช้ทรัพยากรการรวบรวมข้อมูล |
|---|---|---|---|
| หน้าหมวดหมู่เดิม | 1 | 1 | 0.01% |
| การกรองคุณสมบัติ (สี+แบรนด์) | 10 x 8 | 80 | 2.5% |
| การซ้อนทับข้อมูลจำเพาะ (สี+แบรนด์+ไซส์) | 80 x 12 | 960 | 18.0% |
| การซ้อนทับฟังก์ชันเต็มรูปแบบ (คุณสมบัติ+ข้อมูลจำเพาะ+การเรียงลำดับ+การแบ่งหน้า) | 960 x 3 x 10 | 28,800 | มากกว่า 70% |
เมื่อ Googlebot จัดการกับ “พื้นที่ไม่มีที่สิ้นสุด” ที่เกิดจากการซ้อนทับของพารามิเตอร์เหล่านี้ หากพื้นที่ URL ของไซต์ขยายตัวมากเกินไปเนื่องจากการซ้อนทับของพารามิเตอร์ สัดส่วนการรวบรวมข้อมูลที่มีประสิทธิภาพซึ่งบอทสามารถทำได้ในหน่วยเวลาจะลดลงอย่างมาก
จากการวิเคราะห์บันทึก (Log) ของไซต์ค้าปลีกข้ามชาติแห่งหนึ่ง พบว่าบอทรวบรวมข้อมูล 15,000 URL ภายใน 24 ชั่วโมง แต่มีเพียง 1,200 URL เท่านั้นที่เป็นหน้าคงที่ที่มีศักยภาพในการจัดอันดับ พฤติกรรมการรวบรวมข้อมูลส่วนที่เหลืออีก 92% ถูกใช้ไปกับตัวแปรพารามิเตอร์ที่เกิดจากการรวมกันของ ?color=, ?size= และ ?sort=
ในกระบวนการที่อัลกอริทึมพยายามเลือก “เวอร์ชันมาตรฐาน” จากเส้นทางที่คล้ายกัน 200 เส้นทาง หากขาดสัญญาณทางเทคนิคที่ชัดเจนเพื่อชี้นำ มักจะปรากฏว่า URL ที่ถูกเลือกไม่ใช่หน้ามาตรฐานที่นักพัฒนาคาดหวัง ส่งผลให้ที่อยู่ที่มีพารามิเตอร์อ่านไม่รู้เรื่องแสดงในหน้าผลการค้นหา
ทุกครั้งที่ Googlebot ร้องขอ URL ที่มีพารามิเตอร์รวมกันที่ซับซ้อน ฐานข้อมูลหลังบ้านมักจะต้องดำเนินการค้นหาแบบเชื่อมโยงหลายตาราง (Multi-table join query) เพื่อสร้างมุมมองที่เกี่ยวข้อง
ภายใต้แรงกดดันจากการรวบรวมข้อมูลที่มีความถี่สูง การร้องขอพารามิเตอร์ที่รวมกันมากเกินไปจะทำให้ TTFB (Time to First Byte) เพิ่มขึ้น 300 มิลลิวินาทีถึง 800 มิลลิวินาที
ความล่าช้าในการตอบสนองที่เพิ่มขึ้นจะกระตุ้นกลไกการป้องกันของ Googlebot ซึ่งจะทำให้อัตราความถี่ในการรวบรวมข้อมูลทั่วทั้งโดเมนลดลง
ตามรายงานการวิจัยเกี่ยวกับไซต์อีคอมเมิร์ซทั่วโลก 500 แห่ง หน้าเว็บที่มีพารามิเตอร์ URL ลึกเกิน 3 ชั้น มีโอกาสที่ Google จะจัดทำดัชนีได้สำเร็จต่ำกว่า URL แบบแบนถึง 42%
การเรียงลำดับพารามิเตอร์ที่ไม่มีระเบียบจะนำไปสู่การล่มสลายของสัญญาณลิงก์ในเชิงลึก เมื่อหน้าเว็บที่มีพารามิเตอร์โปรโมชันเฉพาะ ?promo=winter ถูกอ้างอิงโดยเว็บไซต์ภายนอก ขณะที่การนำทางภายในไซต์ชี้ไปยังเวอร์ชัน ?sort=new สัญญาณน้ำหนักของทั้งสองจะถูกแยกออกจากกันโดยสิ้นเชิงในฐานข้อมูลภายในของ Google
ในไซต์ที่ไม่มีการใช้กลยุทธ์การทำให้ URL เป็นมาตรฐาน (Normalization) โดยเฉลี่ยหน้าสินค้าประเภทยอดนิยมจะมีตัวแปรพารามิเตอร์ที่แตกต่างกัน 14 แบบ ซึ่งส่งผลให้อัตราการคลิกของสินค้านั้นในผลการค้นหากระจัดกระจายไปยังเส้นทางย่อยต่างๆ
ในการจัดการกับเส้นทางที่ซ้ำซ้อนขนาดใหญ่นี้ การพึ่งพาเพียง robots.txt เพื่อบล็อกมักจะไม่สามารถแก้ปัญหาการจัดทำดัชนีที่มีอยู่แล้วได้
คำแนะนำอย่างเป็นทางการของ Google Search Central มีแนวโน้มที่จะแนะนำให้ใช้ rel=”canonical” tag เพื่อบังคับรวมเส้นทางที่เกิดจากผลกระทบจากการคูณเหล่านี้
หลังจากปรับใช้แท็กมาตรฐานอย่างถูกต้อง ความสามารถในการมองเห็นการค้นหาของหน้าหมวดหมู่ที่เกี่ยวข้องเพิ่มขึ้นเฉลี่ย 22% ภายใน 60 วัน
การสิ้นเปลืองโควตาการรวบรวมข้อมูล (Crawl Budget)
Googlebot มีขีดจำกัดสูงสุดในการร้องขอรวบรวมข้อมูลไซต์ในหน่วยเวลา
เมื่อระบบสร้าง URL ที่มีพารามิเตอร์หลายหมื่นรายการ (เช่น ?variant=123 หรือ ?sort=desc) บอทจะเลือกใช้เส้นทางคุณภาพต่ำเหล่านี้ก่อน
ตามกลไกการรวบรวมข้อมูลของ Google หากจำนวน URL ที่ซ้ำกันมากกว่าเนื้อหาจริง 10 เท่า ความถี่ในการรวบรวมข้อมูลของหน้าสำคัญจะลดลงมากกว่า 50%
ปรากฏการณ์นี้ส่งผลให้หน้าเว็บที่เพิ่งเผยแพร่ใหม่อาจยังไม่ถูกค้นพบภายใน 72 ชั่วโมง ขณะที่ความถี่ในการรวบรวมข้อมูลของ URL ต้นฉบับที่ไม่มีพารามิเตอร์จะถูกลดลงอย่างมาก
ผลกระทบของพารามิเตอร์
ระบบจัดตารางเวลาการรวบรวมข้อมูลของเครื่องมือค้นหาจะแบ่งพารามิเตอร์ออกเป็น “พารามิเตอร์เชิงรุก” (Active Parameters) และ “พารามิเตอร์เชิงรับ” (Passive Parameters) ตามระดับที่พารามิเตอร์นั้นเปลี่ยนเนื้อหาจริงของหน้าเว็บ
เซสชันไอดี (Session IDs) จัดเป็นพารามิเตอร์ที่มีพลังทำลายล้างทรัพยากรการรวบรวมข้อมูลสูงที่สุดในบรรดาพารามิเตอร์ทุกประเภท
พารามิเตอร์ประเภทนี้ เช่น ?sid=9928374 หรือ ?sessionid=abc123 มักจะถูกสร้างขึ้นแบบไดนามิกโดยหลังบ้าน เพื่อติดตามผู้ใช้ในโปรโตคอล HTTP ที่ไม่มีสถานะ (Stateless)
เนื่องจากผู้เยี่ยมชมแต่ละคนหรือแม้แต่การเข้าชมแต่ละครั้งของบอทอาจได้รับไอดีใหม่ สิ่งนี้จะสร้าง URL จำนวนไม่สิ้นสุดตามทฤษฎีสำหรับเอกสาร HTML เดียวกัน
ในการวิเคราะห์บันทึกของเซิร์ฟเวอร์ จะเห็นได้ว่าหากไม่มีการตั้งค่ากฎการกรอง Googlebot อาจพยายามรวบรวมข้อมูลบทความเดียวกันหลายร้อยครั้งภายใน 24 ชั่วโมง โดยแต่ละครั้งจะใช้สตริงเซสชันที่แตกต่างกัน
พฤติกรรมนี้จะทำให้เกิดการสะสมคำร้องขอที่ไม่มีประสิทธิภาพจำนวนมากในคิวการรวบรวมข้อมูล แย่งชิงโควตาที่ควรจัดสรรให้กับหน้าเว็บที่เพิ่งเผยแพร่ใหม่ (Fresh Content)
“ในการตรวจสอบบันทึกของไซต์อีคอมเมิร์ซขนาดใหญ่ คำร้องขอรวบรวมข้อมูลซ้ำซ้อนที่เกิดจากเซสชันไอดีมักจะคิดเป็น 30% ถึง 50% ของปริมาณการรวบรวมข้อมูลทั้งหมด ซึ่งบีบให้ Googlebot ต้องกระตุ้นขีดจำกัด ‘ความล่าช้าในการรวบรวมข้อมูล’ บ่อยครั้งเพื่อปกป้องประสิทธิภาพของเซิร์ฟเวอร์”
เมื่อผู้ใช้คลิกเลือกสี ขนาด วัสดุ และตัวเลือกอื่นๆ URL จะซ้อนทับส่วนขยายเช่น ?color=blue&size=xl&material=cotton
พารามิเตอร์ประเภทนี้แม้จะเปลี่ยนชุดย่อยของเนื้อหาที่แสดงในหน้าเว็บ แต่มักจะไม่สร้างข้อมูลเมตา (Metadata) ใหม่ทั้งหมด
จากมุมมองทางเทคนิค พารามิเตอร์เหล่านี้เป็นไปตามลอจิกผลคูณคาร์ทีเซียน (Cartesian Product)
| ประเภทพารามิเตอร์ | ตัวอย่างโครงสร้างทั่วไป | ผลกระทบต่อการมองเห็นของ Googlebot | ระดับการสิ้นเปลืองทรัพยากรการรวบรวมข้อมูล |
|---|---|---|---|
| การติดตามเซสชัน | ?sid=xyz_987 |
สร้างเส้นทาง URL ซ้ำซ้อนเกือบไม่สิ้นสุด | สูงมาก (9/10) |
| การกรองหลายชั้น | ?size=m&color=red |
เส้นทางเพิ่มขึ้นเป็นทวีคูณ ง่ายต่อการเกิดลูปไม่สิ้นสุด | สูง (8/10) |
| ลอจิกการเรียงลำดับ | ?sort=price_desc |
ลำดับเนื้อหาในหน้าเปลี่ยนไป ไม่มีข้อมูลใหม่ที่แท้จริง | ปานกลาง (5/10) |
| การติดตามโฆษณา | ?click_id=ad_01 |
ชี้ไปยังเนื้อหาที่เหมือนกับหน้าเดิม 100% | ปานกลางถึงสูง (7/10) |
| ภาษา/ภูมิภาค | ?lang=en-us |
ชี้ไปยังหน้าเว็บที่ถูกต้องซึ่งมีเนื้อหาแปลที่แตกต่างกัน | ต่ำ (2/10) |
พารามิเตอร์การเรียงลำดับ (Sorting Parameters) เช่น ?sort=highest_price หรือ ?order=newest มักถูกทำเครื่องหมายว่าเป็นลำดับความสำคัญต่ำในสายตาของ Googlebot
เนื่องจากส่วนหลัก หัวข้อ และคำอธิบายเมตาของหน้ายังคงเดิมหลังจากเรียงลำดับ อัลกอริทึมการขจัดความซ้ำซ้อน (De-duplication Algorithm) จะระบุได้อย่างรวดเร็วว่า URL เหล่านี้เป็นสำเนาของหน้ามาตรฐาน (Canonical Page)
หากไซต์ไม่มีการกำหนดค่า rel="canonical" อย่างถูกต้องเพื่อชี้ไปยังเส้นทางหลัก Googlebot จะยังคงใช้ความถี่ในการรวบรวมข้อมูลประมาณ 15% เพื่อตรวจสอบว่าหน้าเรียงลำดับเหล่านี้มีการอัปเดตเนื้อหาหรือไม่
สำหรับเว็บไซต์ค้าปลีกที่มี SKU 100,000 รายการ เพียงแค่ฟังก์ชัน “เรียงลำดับตามคะแนน” อย่างเดียว ก็อาจทำให้บอทต้องเข้าเยี่ยมชมลิงก์ที่ไม่มีความหมายเพิ่มอีก 100,000 ลิงก์
พารามิเตอร์ติดตาม (Tracking Parameters) เช่น ?utm_source=google หรือ ?affiliate_id=123 ส่งผลเสียต่อ SEO โดยเฉพาะในเรื่องของ “ภาระการเชื่อมต่อ” (Connection Overhead)
แม้ว่าพารามิเตอร์เหล่านี้จะไม่เปลี่ยนเนื้อหาหน้าเว็บเลย แต่ Googlebot ยังคงต้องสร้างการเชื่อมต่อ TCP และส่งคำร้องขอเพื่อยืนยันว่าเนื้อหาที่ URL นั้นส่งคืนมาสอดคล้องกับหน้าหลักหรือไม่
จากการสังเกตไซต์ที่มีทราฟฟิกสูง หากมีการใช้ลิงก์ภายในที่มีพารามิเตอร์ UTM จำนวนมาก ความเร็วในการค้นหาเส้นทางต้นฉบับที่มีประสิทธิภาพของบอทจะลดลงประมาณ 25%
Googlebot จะค่อยๆ ลดความถี่ในการรวบรวมข้อมูล URL ที่ซ้ำซ้อนโดยสมบูรณ์เหล่านี้ลง แต่ก่อนหน้านั้น “โควตาการรวบรวมข้อมูลครั้งแรก” อันมีค่าก็ได้ถูกใช้ไปจนหมดสิ้นเนื่องจากรหัสติดตามที่ซ้ำซ้อนเหล่านี้
“การตรวจสอบทางเทคนิคแสดงให้เห็นว่า การลบพารามิเตอร์ติดตามออกจากลิงก์ภายในไซต์ และย้ายลอจิกสถิติไปยังการรับฟังเหตุการณ์ (Event Listening) ฝั่งเบราว์เซอร์ สามารถเพิ่มปริมาณการรวบรวมข้อมูลหน้าเว็บรายวันของ Googlebot ได้มากกว่า 18%”
พารามิเตอร์การแบ่งหน้า (Pagination Parameters) เช่น ?page=2 มีความพิเศษในลอจิกการจัดการ
ในอดีต Google พึ่งพา rel="next/prev" แต่ปัจจุบันหันมาทำความเข้าใจโครงสร้างการแบ่งหน้าผ่านอัลกอริทึมเป็นหลัก
หากไม่มีการแทรกแซง บอทอาจรวบรวมข้อมูลลึกลงไปถึงหน้าที่ 500 หรือลึกกว่านั้น ซึ่งหน้าชั้นลึกเหล่านี้มีมูลค่าการจัดอันดับต่ำมาก
หากพารามิเตอร์การแบ่งหน้าถูกนำมารวมกับพารามิเตอร์การกรอง (เช่น: เสื้อเชิ้ตสีน้ำเงินในหน้าที่ 5) ความซับซ้อนของ URL จะเพิ่มขึ้นแบบทวีคูณ
การตรวจสอบและการควบคุม
ด้วยการเข้าถึงบันทึกการเข้าชมหลังบ้านของเซิร์ฟเวอร์ และการใช้ Regular Expression เพื่อจัดทำสถิติความถี่ของ URL ที่มีเครื่องหมายคำถาม (?) จะช่วยให้เห็นร่องรอยการเข้าชมของบอทได้อย่างชัดเจน
ในไซต์อีคอมเมิร์ซระดับสากลที่มีทราฟฟิกรายวันมากกว่า 100,000 ครั้ง หากบันทึกแสดงว่า Googlebot ส่งคำร้องขอไปยังเส้นทางที่มีส่วนขยาย ?sessionid= หรือ ?track_id= มากกว่า 40,000 ครั้งต่อวัน โดยที่เนื้อหาหน้าที่ส่งคืนมาเหมือนกับ HTML ต้นฉบับทุกประการ จะเห็นได้ว่าทรัพยากรการรวบรวมข้อมูลประมาณ 40% สูญเสียไปกับเส้นทางที่ไม่มีความหมาย
ทีมเทคนิคควรคำนวณ “สัดส่วนการรวบรวมข้อมูลที่มีประสิทธิภาพ” นั่นคือ:
จำนวนครั้งที่รวบรวมข้อมูลหน้ามาตรฐาน / จำนวนครั้งที่รวบรวมข้อมูลทั้งหมด
หากค่านี้ต่ำกว่า 20% มักจะแสดงว่าบอทติดอยู่ในเขาวงกต URL ที่สร้างโดยพารามิเตอร์
การใช้เครื่องมือวิเคราะห์บันทึก เช่น Kibana หรือ Splunk จะช่วยให้สังเกตการกระจายของแรงกดดันในการรวบรวมข้อมูลภายใต้พารามิเตอร์ที่รวมกันแบบต่างๆ เพื่อระบุเส้นทางที่สร้างตัวแปรหลายแสนรายการแต่ไม่สร้างทราฟฟิก
สามารถใช้รายงาน “สถิติการรวบรวมข้อมูล” ใน Google Search Console เพื่อรับข้อมูลการกระจายที่แท้จริงจากมุมมองของเครื่องมือค้นหา
ในรายงานนี้ จำเป็นต้องให้ความสำคัญกับมิติ “การรวบรวมข้อมูลแยกตามวัตถุประสงค์” ดังนี้:
- สัดส่วนคำร้องขอการค้นพบ (Discovery): หมายถึงพฤติกรรมที่บอทพบ URL ใหม่เป็นครั้งแรก สำหรับไซต์ที่มีการอัปเดตบ่อย สัดส่วนนี้ควรอยู่ที่ 30% ขึ้นไป หากสัดส่วนต่ำเกินไป แสดงว่าเนื้อหาใหม่ถูกขวางกั้นโดยเส้นทางพารามิเตอร์เก่า
- ความถี่ของคำร้องขอการรีเฟรช (Refresh): หมายถึงการกลับมาเยี่ยมชมหน้าเว็บที่รู้จักแล้วอีกครั้งของบอท หากคำร้องขอรีเฟรชกระจุกตัวอยู่ที่ URL ที่มีพารามิเตอร์จำนวนมาก แทนที่จะเป็นหน้าหลักของไซต์ แสดงว่าการจัดสรรทรัพยากรมีความผิดพลาด
- ตัวบ่งชี้การกระจายรหัสสถานะการตอบสนอง: สังเกตสัดส่วนของ 200 (OK), 304 (Not Modified) และ 404 (Not Found) หาก URL ที่มีพารามิเตอร์สร้างข้อผิดพลาด 404 หรือการเปลี่ยนเส้นทาง 301 จำนวนมาก Googlebot จะลดระดับขีดจำกัดการรวบรวมข้อมูลสูงสุด (Crawl Capacity Limit) ลงเนื่องจากต้นทุนการเชื่อมต่อสูงเกินไป
- การตรวจสอบเวลาดาวน์โหลดเฉลี่ย: หากการกรองพารามิเตอร์ที่ซับซ้อนกระตุ้นให้เกิดการค้นหาฐานข้อมูลที่หนักหน่วง ส่งผลให้เวลาโหลดหน้าเว็บเกิน 2,000 มิลลิวินาที Googlebot จะลดจำนวนการรวบรวมข้อมูลพร้อมกันลงอย่างรวดเร็วเพื่อหลีกเลี่ยงการทำให้เซิร์ฟเวอร์ทำงานหนักเกินไป
หลังจากยืนยันแหล่งที่มาของพารามิเตอร์ที่ซ้ำซ้อนแล้ว แม้ว่า Canonical tag จะจัดการกับความซ้ำซ้อนในฝั่งการจัดทำดัชนีได้ แต่มีเพียง Robots.txt เท่านั้นที่สามารถสกัดกั้นคำร้องขอก่อนที่จะเริ่มการเชื่อมต่อ HTTP
การตั้งค่า Disallow: /?sort= หรือ Disallow: /?price_min= จะสามารถบังคับให้ Googlebot หยุดเข้าถึงการรวมการเรียงลำดับหรือการกรองราคาเฉพาะเจาะจงได้
วิธีนี้จะช่วยคืนจำนวนการเชื่อมต่อที่เดิมทีสูญเสียไปกับหน้าเหล่านี้ให้กับ URL มาตรฐานใน Sitemap.xml ทันที
ในการกำหนดค่ากฎควรหลีกเลี่ยงการใช้ Disallow: /? แบบกว้างๆ เพื่อไม่ให้เป็นการตัดพารามิเตอร์ภาษาที่เป็นประโยชน์ต่อ SEO (เช่น ?hl=en) หรือพารามิเตอร์การแบ่งหน้า (เช่น ?p=2)
ลอจิกการควบคุมที่ละเอียดควรผสมผสานกับผลการวิเคราะห์บันทึก โดยบล็อกเฉพาะตัวกรองที่สร้างการรวมเส้นทางที่ไม่มีที่สิ้นสุดเท่านั้น
สำหรับแถบนำทางแบบการกรองหลายชั้น (Faceted Navigation) การใช้เทคโนโลยี AJAX loading หรือ pushState จะช่วยแยกบอทออกไปได้
เมื่อผู้ใช้คลิกปุ่มกรอง เนื้อหาหน้าเว็บจะเปลี่ยนไปแต่ URL จะไม่สร้างส่วนขยายที่สามารถรวบรวมข้อมูลได้ หรือใช้เพียง Fragment Identifier (#) เพื่อเปลี่ยนมุมมอง วิธีการนี้จะโปร่งใสสำหรับ Googlebot เพราะปกติแล้วบอทจะละเลยอักขระทั้งหมดที่อยู่หลัง #
ในกรณีที่จำเป็นต้องใช้พารามิเตอร์ สามารถใช้ลอจิกการจำกัดมิติได้ดังนี้:
- การจำกัดความลึกของเส้นทาง: กำหนดในรหัสโปรแกรมว่าเมื่อพารามิเตอร์รวมกันเกินสามมิติ (เช่น: สี+ขนาด+วัสดุ) ระบบจะแทรก
noindextag ในส่วนหัว HTML โดยอัตโนมัติ และตรวจสอบให้แน่ใจว่าหน้านี้ไม่ปรากฏในลิงก์ภายในไซต์ใดๆ - การประยุกต์ใช้ Nofollow attribute: ใช้
rel="nofollow"ในลิงก์ของแถบข้างตัวกรอง เพื่อส่งสัญญาณ “เส้นทางนี้ไม่สำคัญ” ไปยังเครื่องมือค้นหา ช่วยลดโอกาสที่บอทจะเข้าสู่การรวมตัวกรองชั้นลึก - คำสั่งการรวมมาตรฐาน (Canonicalization): ตรวจสอบให้แน่ใจว่าหน้าเว็บที่มีพารามิเตอร์ทั้งหมดชี้ไปยังเวอร์ชันมาตรฐานที่กระชับที่สุดผ่าน
rel="canonical"แม้ว่าบอทจะทำการรวบรวมข้อมูล ก็จะเป็นการชี้นำให้ระบบจัดทำดัชนีรวมน้ำหนักไว้ที่เส้นทางหลัก
หากหน้าแรกหรือแถบนำทางหลักประกอบด้วยลิงก์ที่มีพารามิเตอร์ติดตาม UTM จำนวนมาก Googlebot จะเลือกรวบรวมข้อมูลเส้นทางที่มีสัญญาณรบกวนเหล่านี้ก่อน
แนะนำให้ย้ายสถิติทราฟฟิกภายในทั้งหมดไปยังการติดตามเหตุการณ์ฝั่งเบราว์เซอร์ เพื่อรักษา URL ให้สะอาด ในการจัดการลอจิกการแบ่งหน้า แม้ว่า Google จะไม่ใช้แท็กการแบ่งหน้าเฉพาะแล้ว แต่การรักษาโครงสร้างเส้นทางที่ชัดเจน (เช่น /page/2/ แทนที่จะเป็น ?page=2) จะช่วยให้อัลกอริทึมจดจำรายการได้เสถียรกว่า
ภายในสองสัปดาห์หลังจากการปรับใช้ Robots.txt หรือลอจิกการรวมพารามิเตอร์ ควรตรวจสอบรายงาน “ความครอบคลุมของดัชนี” ใน Google Search Console อย่างต่อเนื่อง
แนวโน้มที่เหมาะสมคือ:
จำนวนหน้าที่ถูกทำเครื่องหมายเป็น “รวบรวมข้อมูลแล้ว – ยังไม่ได้จัดทำดัชนี” หรือ “หน้าซ้ำ” ลดลงอย่างเห็นได้ชัด ขณะที่ “เวลาที่รวบรวมข้อมูลล่าสุด” ของหน้าหลักมีความถี่มากขึ้น
หากรอบการรวบรวมข้อมูลของหน้าหนึ่งสั้นลงจาก 10 วันต่อครั้งเป็นภายใน 24 ชั่วโมง และคำร้องขอตอบสนอง 200 ในบันทึกเซิร์ฟเวอร์กระจุกตัวอยู่ที่ URL มาตรฐานมากขึ้น แสดงว่าโควตาการรวบรวมข้อมูลได้รับการจัดสรรอย่างเหมาะสมแล้ว
การเจือจางสัญญาณ
เมื่อ URL หลายรายการที่มีพารามิเตอร์ต่างกัน (เช่น ?sort=price หรือ ?sessionid=abc) ชี้ไปยังเนื้อหาเดียวกัน Google จะมองว่าเป็นหน้าอิสระที่แยกจากกัน
เดิมทีอำนาจของลิงก์และสัญญาณการคลิกของผู้ใช้ 100% จะถูกกระจายไปยังตัวแปรเหล่านี้
หากหน้าเว็บหนึ่งสร้างพารามิเตอร์ซ้ำซ้อน 5 รายการ PageRank ที่ URL เดียวจะได้รับจะเหลือเพียง 20% ส่งผลให้ไม่สามารถบรรลุเกณฑ์น้ำหนักเพื่อเข้าสู่ 10 อันดับแรกของผลการค้นหาได้
ในไซต์อีคอมเมิร์ซที่มี URL มากกว่า 50,000 รายการ พารามิเตอร์ที่ไม่ได้รับการจัดการจะทำให้ Googlebot เสียความถี่ในการรวบรวมข้อมูลรายวันมากกว่า 50% ไปกับเส้นทางที่ซ้ำซ้อน ซึ่งจะทำให้การจัดทำดัชนีหน้าใหม่ล่าช้าออกไป
การกระจายน้ำหนัก
ในลอจิกดั้งเดิมของอัลกอริทึม PageRank ความสามารถในการจัดอันดับของหน้าหน้าหนึ่งจะถูกกำหนดโดยจำนวนและคุณภาพของลิงก์ที่ชี้ไปยัง URL นั้น
เมื่อเว็บไซต์สร้างเส้นทางตัวแปรที่มี ?sort=newest, ?filter=price-low หรือ ?sessionid=xyz จะมีโอกาสสูงมากที่ไซต์ภายนอกจะลิงก์ไปยังตัวแปรที่แตกต่างกันเหล่านี้
ข้อมูลเฉพาะระบุว่า หาก URL ต้นฉบับของผลิตภัณฑ์คือ example.com/item แต่ภายนอกมีลิงก์ 40% ที่ชี้ไปยัง example.com/item?source=social ที่มีพารามิเตอร์ Link Graph ของ Google จะบันทึก URL ทั้งสองนี้แยกกัน
แม้ว่าอัลกอริทึมจะพยายามระบุตัวตนมาตรฐาน แต่ในกระบวนการส่งต่อน้ำหนักจริง จะมีคะแนนสูญหายไปประมาณ 10% ถึง 15% ในการทำแผนที่ที่ไม่เป็นมาตรฐานนี้
“ในการจัดการกับ URL ที่มีพารามิเตอร์ Googlebot จะต้องตัดสินใจว่าจะป้อน PageRank เข้าไปยังเอนทิตีเฉพาะรายการใด หากขาดการชี้นำของ Canonical ที่ชัดเจน กระบวนการป้อนข้อมูลนี้จะกลายเป็นการสุ่มและกระจัดกระจาย” — อ้างอิงจากคำชี้แจงทางเทคนิคอย่างเป็นทางการของทีมคุณภาพการค้นหาของ Google
ข้อมูลจากการวิเคราะห์บันทึกจริงพบว่า แพลตฟอร์มอีคอมเมิร์ซข้ามชาติขนาดใหญ่หากไม่จำกัดการรวบรวมข้อมูลพารามิเตอร์ในระหว่างการจัดการแถบนำทางแบบการกรองหลายชั้น (Faceted Navigation) ความเร็วในการสะสม PageRank ของหน้าหมวดหมู่หลักจะช้ากว่าคู่แข่งที่มีเส้นทางเดียวมากกว่า 30%
เมื่อลิงก์ภายใน 5,000 ลิงก์ของทั้งไซต์ชี้ไปยังพารามิเตอร์ที่ต่างกัน 50 แบบ แรงผลักดันที่เดิมทีสามารถส่งหน้าหน้าหนึ่งไปยังหน้าแรกของผลการค้นหาได้ กลับถูกแบ่งออกเป็น 50 ส่วนที่ไม่เพียงพอต่อการสร้างอันดับ
เมื่อความเหมือนของเนื้อหาระหว่าง URL สองรายการถึง 98% ขึ้นไป ระบบจะเริ่มกลไกการขจัดความซ้ำซ้อน
จากการสังเกตไซต์ในอเมริกาเหนือ 500,000 แห่ง หน้าเว็บที่ Google ตัดสินว่าเป็น “ซ้ำซ้อน” แต่ไม่มีการเปลี่ยนเส้นทางทางกายภาพ น้ำหนักลิงก์ดั้งเดิมมักจะอยู่ในสถานะถูกแช่แข็ง และจะไม่โอนไปยังหน้าหลักโดยอัตโนมัติ 100%
สำหรับไซต์ที่มี URL มากกว่า 100,000 รายการ เส้นทางการรวบรวมข้อมูลที่ไม่มีประสิทธิภาพซึ่งเกิดจากพารามิเตอร์จะทำให้ความลึกในการเข้าชมของ Googlebot ถูกจำกัด
ในไซต์ที่ขาดการจัดการพารามิเตอร์ เวลาที่บอทใช้ในหน้าพารามิเตอร์ที่ไม่มีประสิทธิภาพจะคิดเป็น 65% ของเวลารวบรวมข้อมูลทั้งหมด ส่งผลให้เนื้อหาคุณภาพสูงที่เพิ่งเผยแพร่อาจต้องใช้เวลาถึง 14 วันหรือนานกว่านั้นในการถูกจัดทำดัชนี ขณะที่ไซต์ที่ผ่านการเพิ่มประสิทธิภาพ รอบเวลานี้มักจะสั้นลงเหลือภายใน 24 ชั่วโมง
“ทุกการเปลี่ยนแปลงอักขระใน URL จะสร้างโหนดใหม่ในฐานข้อมูล แม้ว่าเนื้อหาจะคล้ายกัน แต่โหนดเหล่านี้จะเป็นคู่แข่งกันมากกว่าที่จะร่วมมือกันในช่วงแรกของอัลกอริทึม” — คัดมาจากรายงานการทดลองของสถาบันวิจัย SEO ระดับสากลแห่งหนึ่ง
ในสถาปัตยกรรมบางอย่างที่ใช้การโหลดบาลานซ์หรือเครือข่ายการกระจายเนื้อหาระดับโลก (CDN) คำร้องขอที่มีพารามิเตอร์อาจถูกแคชเป็นสำเนาคงที่ที่แตกต่างกัน
หากไม่มีการกำหนดค่า Vary: User-Agent หรือ Link: rel="canonical" อย่างถูกต้องในส่วนหัวการตอบสนอง HTTP Googlebot อาจคิดว่าหน้าพารามิเตอร์เหล่านี้จัดทำขึ้นเพื่อแสดงเนื้อหาที่ต่างกันสำหรับผู้ใช้ในภูมิภาคต่างๆ
ภายใต้การตัดสินที่ผิดพลาดนี้ อัลกอริทึมจะแยกอำนาจของทั้งไซต์ออกไปยังมิติของพารามิเตอร์ต่างๆ มากขึ้น ก่อให้เกิดสถานการณ์ “น้ำหนักโลหิตจาง”
เพื่อวัดปริมาณการสูญเสียจากการกระจายนี้ในระดับเทคนิค สามารถอ้างอิงถึง “โมเดลการสูญเสียน้ำหนัก”:
สมมติว่าหน้าหลักต้องการสัญญาณ 100 หน่วยเพื่อเข้าสู่สามอันดับแรก หากมีตัวแปรพารามิเตอร์ 4 รายการ และแต่ละรายการแบ่งสัญญาณไป 15% ในที่สุดหน้าหลักจะเหลือสัญญาณเพียง 40 หน่วย ทำให้หน้านั้นเสียเปรียบอย่างมากในการแข่งขัน
ในการตรวจสอบทางเทคนิคของร้านค้าต่างประเทศบนแพลตฟอร์มเช่น Shopify หลังจากปิดการใช้งานพารามิเตอร์ที่ไม่เปลี่ยนเนื้อหา เช่น sort_by, view และ page ใน GSC (Google Search Console) พบว่าจำนวนการแสดงผลที่มีประสิทธิภาพของหน้าเป้าหมายเพิ่มขึ้นเฉลี่ย 55% ภายใน 60 วัน
แนวทางการจัดการ
ในสถาปัตยกรรมอีคอมเมิร์ซระดับองค์กรทั่วโลก เช่น Adobe Commerce (เดิมคือ Magento) หรือ Salesforce Commerce Cloud ระบบจัดทำดัชนีของ Google จะอ่านคำสั่ง rel="canonical" ในส่วนหัว HTML หรือส่วนหัวการตอบสนอง HTTP ก่อนเป็นอันดับแรกในระหว่างการรวบรวมข้อมูล
เมื่อระบบสร้างการรวมตัวกรองหลายชั้น เช่น ?color=blue&size=xl โปรแกรมหลังบ้านจะบังคับให้ที่อยู่มาตรฐานของหน้านั้นชี้ไปยัง URL รากที่ไม่มีพารามิเตอร์ใดๆ
หลังจากการปรับใช้วิธีนี้อย่างถูกต้อง ความแม่นยำในการจดจำเนื้อหาซ้ำซ้อนของ Google จะเพิ่มขึ้นจาก 60% เป็นมากกว่า 99% และคะแนน PageRank ที่กระจัดกระจายอยู่ตามที่ต่างๆ จะถูกรวบรวมทางกายภาพภายในรอบการอัปเดตดัชนี 2 ถึง 4 สัปดาห์
สำหรับไซต์ข้ามชาติที่มี SKU ระดับล้านรายการ ลอจิกนี้จะช่วยให้แน่ใจว่าเส้นทางการค้นหาหลักจะได้รับอำนาจลิงก์ภายในไซต์มากกว่า 95%
- การประกาศลิงก์ในส่วนหัวการตอบสนอง HTTP: ในการจัดการเอกสาร PDF หรือไฟล์ที่มีพารามิเตอร์ซึ่งไม่ใช่รูปแบบ HTML เซิร์ฟเวอร์จะส่งข้อมูลส่วนหัว
Link: <https://example.com/file.pdf>; rel="canonical"เพื่อป้องกันไม่ให้เครื่องมือค้นหามองว่าลิงก์ดาวน์โหลดที่มีพารามิเตอร์ติดตามเป็นเนื้อหาใหม่ - การรวมแบบบังคับด้วยการเปลี่ยนเส้นทางถาวร 301: สำหรับพารามิเตอร์ติดตามการตลาดที่เลิกใช้แล้ว (เช่น
?utm_campaign=2023_saleเมื่อสามปีก่อน) วิธีการทั่วไปคือกำหนดค่ากฎ Wildcard ในระดับเซิร์ฟเวอร์ Nginx หรือ Apache เพื่อเปลี่ยนเส้นทางคำร้องขอทั้งหมดที่มีพารามิเตอร์ที่หมดอายุนั้นไปยังหน้ามาตรฐานอย่างถาวร ซึ่งจะช่วยให้แน่ใจว่าน้ำหนักของลิงก์ภายนอกที่สะสมมาในอดีตจะถูกโอนย้ายไป 100% - การละเลยพารามิเตอร์แบบไร้สถานะในฝั่งเซิร์ฟเวอร์: ในการพัฒนาหลังบ้าน มีการกำหนดค่าเพื่อให้เซิร์ฟเวอร์ตัด Session ID หรือพารามิเตอร์อื่นๆ ที่ใช้สำหรับลอจิกภายในเท่านั้นออกเมื่อประมวลผลคำร้องขอ เพื่อรักษา URL ที่ผู้ใช้แต่ละคนเห็นให้มีความเป็นเอกลักษณ์ทางกายภาพ
- การบล็อกการแบ่งประเภทพารามิเตอร์ใน Google Search Console: ในระบบจัดการหลังบ้านของ Google เจ้าหน้าที่ด้านเทคนิคจะทำเครื่องหมายพารามิเตอร์เป็น “พารามิเตอร์เชิงรับ” (Passive Parameters) เพื่อแจ้งให้บอททราบอย่างชัดเจนว่าอักขระเหล่านี้ไม่เปลี่ยนเนื้อหาหน้าเว็บ จึงเป็นการชี้นำให้ Googlebot ข้ามการรวบรวมข้อมูล URL เหล่านี้โดยสมัครใจ
ในการปฏิบัติ SEO ขนาดใหญ่ สำหรับแอปพลิเคชันหน้าเดียว (SPA) ที่มีระบบกรองที่ซับซ้อน เช่น แพลตฟอร์มที่สร้างด้วย React หรือ Angular นักพัฒนามักจะใช้ Fragment Identifier (#) มาแทนที่ Query String แบบเดิม (?)
ตัวอย่างเช่น เปลี่ยน URL การกรองจาก /shoes?brand=nike เป็น /shoes#brand=nike การคลิกและการกรองทั้งหมดของผู้ใช้จะเสร็จสิ้นที่ฝั่งไคลเอนต์ ขณะที่เครื่องมือค้นหาจะมองเห็นเส้นทาง /shoes เพียงเส้นทางเดียวเสมอ
เมื่อใช้เครือข่ายการกระจายเนื้อหาระดับโลก (CDN) เช่น Cloudflare หรือ Akamai ทีมเทคนิคจะกำหนดค่ากฎ “Cache Key ignore parameters”
ไม่ว่าผู้ใช้จะเข้าชม example.com/page?id=1 หรือ example.com/page?id=1&from=email CDN จะส่งคืนสำเนาแคชเดียวกันให้กับเครื่องมือค้นหาและผู้ใช้ และส่งออกข้อมูลที่ทำให้เป็นมาตรฐานเดียวกันในส่วนหัวการตอบสนอง
สำหรับแพลตฟอร์มที่มีข้อมูลมหาศาลอย่าง Amazon หรือ eBay ลอจิกการจัดการจะเน้นไปที่การเขียนโครงสร้างเส้นทางใหม่ (URL Rewriting)
ระบบจะเปลี่ยนรูปแบบพารามิเตอร์เดิม /product.php?id=123&variant=blue ให้เป็นรูปแบบไดเรกทอรีที่มีความหมายมากขึ้น /product/123/blue/
จากการสำรวจสุ่มตัวอย่างไซต์อิสระในต่างประเทศ 100,000 แห่ง ไซต์ที่ปลอมแปลงพารามิเตอร์การทำงาน (เช่น การเรียงลำดับ การสลับมุมมอง) ผ่าน window.history.pushState API ของ JavaScript โดยไม่เปลี่ยนที่อยู่การร้องขอทางกายภาพ จะมีความเสถียรของอันดับหน้าโดยเฉลี่ยสูงกว่าไซต์ทั่วไปถึง 2.8 เท่า


