




















Google cập nhật chỉ mục thường mất từ 3-10 ngày.
Mặc dù trang đã xóa nhưng bộ nhớ tạm (cache) vẫn còn tồn tại, bạn nên gửi yêu cầu “Xóa URL” thông qua Google Search Console. Yêu cầu này có thể có hiệu lực nhanh nhất trong vòng 24 giờ, đây là phương pháp chuyên nghiệp và hiệu quả nhất để dọn dẹp các kết quả còn sót lại.
Trình thu thập dữ liệu chưa truy cập lại (Crawling Lag)
Googlebot thiết lập tần suất truy cập lại dựa trên chỉ số PageRank và ngân sách thu thập dữ liệu (Crawl Budget).
Đối với hầu hết các trang không nằm ở vị trí ưu tiên, chu kỳ truy cập lại trung bình của Googlebot dao động từ 3 đến 30 ngày.
Báo cáo thống kê thu thập dữ liệu của Google Search Console (GSC) cho thấy, sau khi máy chủ trả về mã trạng thái 404, chỉ mục sẽ không bị xóa ngay lập tức.
Hệ thống cần từ 1 đến 3 lần thu thập dữ liệu lặp lại để xác nhận rằng trang web thực sự không thể truy cập, chứ không phải do lỗi máy chủ tạm thời.
Trong các trang web quy mô lớn, tỷ lệ trễ đồng bộ hóa giữa kho chỉ mục và máy chủ thời gian thực thường nằm trong khoảng 15% đến 20%, dẫn đến việc các trang đã xóa vẫn còn sót lại trong kết quả tìm kiếm.
Xác minh 404
Khi Googlebot truy cập một URL cụ thể và nhận được mã phản hồi 404 Not Found, logic điều phối nội bộ của hệ thống tìm kiếm sẽ không loại bỏ mục đó khỏi kho chỉ mục ngay lập tức.
Theo cơ chế thu thập dữ liệu cơ bản của công cụ tìm kiếm, việc phát hiện tín hiệu 404 lần đầu thường được coi là “máy chủ bị chập chờn tiềm ẩn” hoặc “ngắt kết nối mạng tạm thời”.
Để đảm bảo tính ổn định của kết quả tìm kiếm, hệ thống điều phối của Google sẽ đánh dấu URL đó là “trạng thái thử lại” và đưa nó vào một hàng đợi quan sát chuyên biệt.
Đối với một trang web quy mô trung bình có khoảng 10.000 lượt thu thập dữ liệu mỗi ngày, Googlebot thường sẽ tiến hành kiểm tra lần thứ hai trong vòng 24 đến 48 giờ sau khi phát hiện lỗi 404 lần đầu.
Nếu lần thu thập thứ hai vẫn trả về mã trạng thái 404, hệ thống sẽ hạ mức ưu tiên thu thập dữ liệu (Crawl Priority) của trang đó xuống mức thấp nhất, nhưng hồ sơ chỉ mục vẫn được giữ lại.
Google có một bộ đếm logic nội bộ gọi là “ngưỡng xác nhận”, thường yêu cầu từ 3 đến 5 lần xác nhận 404 liên tiếp, với khoảng thời gian kéo dài ít nhất từ 7 đến 14 ngày, trước khi hệ thống gửi lệnh xóa chính thức đến các phân mảnh chỉ mục (Index Shards).
Nếu quản trị viên web sử dụng mã trạng thái 410 Gone, tốc độ đi vào quy trình xóa sẽ nhanh hơn khoảng 25% đến 40% so với trang 404.
Sau khi nhận được tín hiệu 410, Googlebot thường bỏ qua một số chu kỳ kiểm tra lại và loại bỏ nó khỏi hàng đợi thu thập dữ liệu chính.
Mặc dù vậy, để ngăn chặn việc giả mạo ác ý hoặc thao tác sai, hệ thống vẫn giữ một khoảng thời gian chờ (cooling period) 24 giờ để đảm bảo tính ổn định của mã trạng thái.
Một yếu tố “đuôi dài” khác dẫn đến việc tồn đọng là độ trễ trong việc xác định Soft 404 (404 mềm).
Nếu máy chủ cấu hình sai, vẫn trả về mã trạng thái 200 OK khi trang không tồn tại, nhưng nội dung trang hiển thị thông báo văn bản là “Không tìm thấy trang”, thì dịch vụ kết xuất web (WRS) của Google phải can thiệp.
WRS cần tiêu tốn một lượng lớn tài nguyên tính toán để phân tích cây DOM và sử dụng mô hình học máy để phán đoán đặc điểm ngữ nghĩa của trang.
Một khi được xác định là Soft 404, trang đó sẽ bị đưa ra khỏi quỹ đạo chỉ mục thông thường, nhưng quá trình này chậm hơn so với xác minh 404 tiêu chuẩn từ 5 đến 10 ngày làm việc.
Trong kiến trúc lưu trữ phân tán, tốc độ đồng bộ hóa của các trung tâm dữ liệu trên toàn cầu cũng không đồng nhất.
Ngay cả khi kho chỉ mục chính tại trụ sở Hoa Kỳ đã xác nhận xóa một bản ghi, do chiến lược làm mới bộ nhớ tạm của các nút biên (Edge Nodes) toàn cầu khác nhau, người dùng ở London hoặc Frankfurt vẫn có thể tìm thấy nội dung đã xóa trong vòng 6 đến 12 giờ.
Khi ngân sách thu thập dữ liệu (Crawl Budget) của một trang web cạn kiệt, Googlebot thậm chí sẽ tạm dừng việc kiểm tra lại các liên kết 404 đã biết để tập trung thu thập nội dung mới có trọng số cao hơn.
Việc phân bổ ưu tiên này khiến những trang cũ nằm sâu trong thư mục, với độ sâu liên kết vượt quá 5 tầng, có thể tồn tại trong kết quả tìm kiếm hàng tháng trời mặc dù đã trả về lỗi 404 từ lâu.
“Googlebot không phải là một trình giám sát thời gian thực, nó là một hệ thống điều phối dựa trên xác suất và trọng số. Mỗi việc xác nhận tín hiệu 404 đều tiêu tốn băng thông và chi phí tính toán thực sự.”
Khi di chuyển trang web quy mô lớn hoặc thay đổi đường dẫn hàng loạt, nếu tỷ lệ lỗi 404 vượt quá 20% trong thời gian ngắn, hệ thống có thể kích hoạt cơ chế bảo vệ.
Tại thời điểm này, quy trình xác minh 404 thông thường sẽ bị kéo dài, thuật toán sẽ yêu cầu nhiều “thời gian chứng minh” hơn để xác nhận rằng các thao tác xóa này thực sự là ý định thực của người quản trị trang web.
Tham số ảnh hưởng
Khi Googlebot thực hiện nhiệm vụ thu thập dữ liệu trên internet, tốc độ truy cập lại các URL cũ hoặc phát hiện mã trạng thái mới không phải là ngẫu nhiên. Tham số cơ bản nhất là độ trễ phản hồi của máy chủ (Server Latency), cụ thể là thời gian phản hồi byte đầu tiên (TTFB).
Nếu TTFB của một máy chủ duy trì ở mức dưới 200 mili giây trong thời gian dài, Googlebot sẽ coi máy chủ đó có khả năng chịu tải tốt, từ đó nâng hạn mức thu thập dữ liệu.
Ngược lại, một khi thời gian phản hồi vượt quá 1000 mili giây, để bảo vệ máy chủ mục tiêu không bị sập do truy cập tần suất cao, trình thu thập sẽ tự động kích hoạt cơ chế giới hạn tỷ lệ thu thập (Crawl Rate Limit).
Ở cấp độ kiến trúc trang web, độ sâu liên kết (Link Depth) là cán cân vật lý điều chỉnh tần suất thu thập dữ liệu.
Các URL nằm trong thư mục gốc hoặc chỉ cách trang chủ từ 1 đến 2 lần nhấp chuột sẽ nhận được trọng số PageRank cao nhất. Nhật ký truy cập của Googlebot cho thấy tần suất kiểm tra cập nhật của các trang này thường là 24 giờ một lần.
Tuy nhiên, khi một trang nằm ở tầng thứ 5 hoặc sâu hơn trong cấu trúc thư mục, ngay cả khi nội dung đã đổi sang trạng thái 404, chu kỳ truy cập lại của trình thu thập sẽ kéo dài theo cấp số nhân, đôi khi cần từ 30 đến 60 ngày mới tiến hành kiểm tra định kỳ một lần.
- Nhu cầu thu thập dữ liệu (Crawl Demand): Điều này phụ thuộc vào mức độ phổ biến của trang. Nếu một URL đã xóa vẫn có số lượng lớn liên kết ngược (Backlinks) trỏ vào, hoặc được nhắc đến thường xuyên trên mạng xã hội, thuật toán của Google sẽ coi tài nguyên đó vẫn còn giá trị lưu thông. Ngay cả khi nó trả về 404, thuật toán vẫn sẽ thường xuyên điều phối trình thu thập truy cập lại để xác nhận trạng thái. Việc đánh giá lại với tần suất cao này dẫn đến việc hệ thống thực hiện nhiều vòng xác minh hơn trước khi xác nhận là “biến mất vĩnh viễn”.
- Sức khỏe trang web (Site Health): Nếu máy chủ thường xuyên xuất hiện lỗi dòng 5xx (như 503 Service Unavailable), Googlebot sẽ nhanh chóng cắt giảm tổng ngân sách thu thập dữ liệu (Crawl Budget) của trang web đó. Khi tỷ lệ lỗi vượt quá 10% tổng lượng thu thập, trình thu thập sẽ chuyển sang chế độ bảo vệ, ngừng dò tìm các URL không thiết yếu. Trong trường hợp này, những trang 404 lẽ ra phải được dọn dẹp sẽ lưu lại trong kho chỉ mục lâu hơn do ngân sách thu thập bị đóng băng.
- Tần suất cập nhật nội dung (Change Frequency): Công cụ tìm kiếm ghi lại lịch sử thay đổi của một URL trong nhiều tháng qua. Nếu một trang chưa từng được cập nhật trong 365 ngày qua, Googlebot sẽ đánh dấu nó là “dữ liệu lạnh”, trọng số truy cập lại sẽ được điều chỉnh xuống mức thấp nhất. Khi bạn đột ngột xóa một trang không hoạt động trong thời gian dài, trình thu thập có thể sẽ không chủ động đi qua đường dẫn đó trong quý tới, dẫn đến sự chậm trễ trong việc xóa hiển thị.
Sitemap là một tệp hướng dẫn chứ không phải là lệnh bắt buộc, nhưng độ chính xác của thẻ <lastmod> trong đó ảnh hưởng đến hiệu quả thu thập dữ liệu của trình thu thập.
Nếu sơ đồ trang web vẫn giữ các liên kết đã trả về 404, hoặc dấu thời gian lastmod không được cập nhật theo thao tác xóa trang, Googlebot có thể coi tệp đó là không đáng tin cậy, từ đó chuyển sang chế độ dò tìm tự động kém hiệu quả hơn.
Trong các thử nghiệm trên các trang tin tức lớn ở Bắc Mỹ, việc gửi Sitemap chứa ngày lastmod mới nhất cho Google, kết hợp với giao thức WebSub (trước đây là PubSubHubbub) để đẩy chủ động, có thể rút ngắn thời gian trình thu thập nhận biết thay đổi trang web hơn 70%.
Các trang web sử dụng giao thức HTTP/2 hoặc HTTP/3 (QUIC) hỗ trợ đa luồng (Multiplexing), cho phép Googlebot gửi yêu cầu trạng thái của hàng chục URL đồng thời trong cùng một kết nối TCP.
Ngược lại, giao thức HTTP/1.1 truyền thống bị giới hạn bởi số lượng kết nối, trình thu thập phải xếp hàng chờ đợi khi xử lý hàng nghìn tín hiệu 404.
“Trong hệ thống thu thập dữ liệu phân tán, mỗi hành động thu thập một URL đều được tính toán chi phí. Các URL 404 có trọng số thấp thường nằm ở cuối hàng đợi thu thập, trừ khi có tín hiệu bên ngoài nâng cao mức ưu tiên của chúng.”
Do Google đã chuyển hoàn toàn sang lập chỉ mục ưu tiên thiết bị di động (Mobile-First Indexing), hoạt động của trình thu thập thiết bị di động thường cao hơn từ 2 đến 3 lần so với thiết bị máy tính để bàn.
Nếu phiên bản di động của một trang đã bị xóa nhưng phiên bản máy tính để bàn vẫn trả về 200 do cấu hình sai, hoặc ngược lại, sự không nhất quán này sẽ gây ra xung đột logic trong hệ thống chỉ mục, khiến kết quả tìm kiếm hiển thị thông tin lỗi thời khác nhau trên các thiết bị khác nhau.
Bộ nhớ tạm của trang web (Cache)
Bộ nhớ tạm của trang web là hình ảnh chụp nhanh (snapshot) mã HTML và một phần tài nguyên tĩnh của trang được Googlebot lưu trữ trong các máy chủ phân tán toàn cầu của Google (như Google Data Centers) trong quá trình thu thập dữ liệu.
Ngay cả khi máy chủ gốc đã xóa trang về mặt vật lý, cơ sở dữ liệu chỉ mục của Google vẫn giữ lại bản chụp nhanh đó cho đến khi chu kỳ thu thập dữ liệu tiếp theo làm mới.
Thông thường, tần suất thu thập dữ liệu của các trang web có trọng số cao được tính bằng giờ, trong khi các trang web thông thường có thể mất từ 3 đến 28 ngày.
Do Google sử dụng các nút tính toán biên để đồng bộ hóa dữ liệu, việc cập nhật chỉ mục chính và đồng bộ hóa kết quả tìm kiếm ở các khu vực trên toàn cầu thường có độ trễ từ 24 đến 72 giờ.
Lý do hiển thị
Google duy trì một cơ sở dữ liệu phân tán khổng lồ chứa hàng trăm tỷ trang web, kho lưu trữ này được gọi là Chỉ mục (Index).
Khi bạn xóa một trang thông qua hệ thống quản lý nội dung (như WordPress hoặc Ghost), bạn chỉ mới gỡ bỏ dữ liệu khỏi máy chủ Web của riêng mình.
Tại thời điểm này, các cụm máy chủ của Google vẫn giữ lại bản ghi chụp nhanh cuối cùng của URL đó.
- Phân bổ phân cấp chu kỳ thu thập dữ liệu của Googlebot: Google phân bổ các định mức thu thập dữ liệu (Crawl Budget) khác nhau dựa trên độ uy tín của trang web (Domain Authority) và tần suất cập nhật.
- Đối với 1% các trang tin tức có lưu lượng truy cập cao nhất (như The New York Times hoặc Reuters), tần suất thu thập lại các trang phổ biến được tính bằng phút hoặc giờ.
- Chu kỳ thu thập dữ liệu của các trang web kinh doanh thông thường hoặc blog cá nhân thường nằm trong khoảng từ 7 đến 28 ngày, một số đường dẫn ít phổ biến thậm chí có khoảng cách thu thập lại kéo dài hàng tháng.
- Nếu trang bị xóa vào ngày 1 tháng 1, nhưng Googlebot dự kiến đến ngày 25 tháng 1 mới truy cập lại đường dẫn đó, thì trong khoảng thời gian chênh lệch 24 ngày này, kết quả tìm kiếm sẽ luôn hiển thị nội dung đã hết hạn.
Hệ thống chỉ mục “Caffeine” nội bộ của Google áp dụng cơ chế cập nhật thời gian thực, nhưng nó chủ yếu nhắm vào việc phát hiện nội dung mới.
Khi Googlebot truy cập một URL đã xóa, mã trạng thái HTTP do máy chủ trả về sẽ quyết định tốc độ loại bỏ chỉ mục.
Nếu máy chủ trả về 404 (Not Found), Googlebot thường không loại bỏ trang đó khỏi chỉ mục ngay lập tức vì thuật toán sẽ xem xét khả năng máy chủ bị lỗi tạm thời hoặc cấu hình sai.
Hệ thống sẽ ghi lại lần thất bại này và sắp xếp thử lại lần thứ hai trong vòng 48 đến 72 giờ.
Chỉ khi nhiều lần thu thập dữ liệu liên tiếp đều trả về trạng thái 404, hoặc trạng thái đó kéo dài vượt quá một ngưỡng quan sát nhất định (thường là vài tuần), hệ thống mới bắt đầu quy trình loại bỏ chỉ mục.
- Định lượng ảnh hưởng của mã trạng thái phản hồi HTTP đến tốc độ loại bỏ😐 Loại mã trạng thái | Hành động tiếp theo của Googlebot | Dự kiến thời gian giữ lại chỉ mục |
|—|—|—|
| 404 (Not Found) | Đánh dấu là “có khả năng thiếu”, thử thu thập lại trong 3-5 ngày | Từ 14 đến 45 ngày |
| 410 (Gone) | Nhận diện là “đã gỡ bỏ vĩnh viễn”, hạ mức ưu tiên trong hàng đợi | Bắt đầu gỡ bỏ trong 3 đến 7 ngày |
| 301 (Redirect) | Chuyển trọng số của URL cũ sang đường dẫn mới, giữ chỉ mục nhưng cập nhật hướng trỏ | Giữ vĩnh viễn (trỏ sang trang mới) |
| Soft 404 | Trang hiển thị đã xóa nhưng trả về mã 200, hệ thống coi là trang chất lượng thấp | Rất khó tự động loại bỏ, có thể tồn đọng hàng tháng |
Google vận hành hơn 20 trung tâm dữ liệu lớn và hàng nghìn nút bộ nhớ tạm biên (Edge Nodes) trên toàn thế giới.
Khi máy chủ chỉ mục chính đặt tại Oregon, Hoa Kỳ cập nhật trạng thái xóa của một trang nào đó, phần dữ liệu này cần được phân phối thông qua mạng lưới xương sống toàn cầu của Google đến các kho chỉ mục khu vực tại Ireland, Phần Lan, Singapore, v.v.
Quá trình đạt được sự nhất quán dữ liệu này (Eventual Consistency) thường có độ trễ lan truyền từ 24 đến 72 giờ.
Yêu cầu tìm kiếm của người dùng tại London có thể chạm tới các máy chủ biên chưa được đồng bộ hóa cập nhật, từ đó vẫn thấy liên kết bản chụp nhanh đang tồn tại.
- Các yếu tố gây nhiễu từ liên kết ngoài và sơ đồ trang web:
- Liên kết nội bộ hiện có: Nếu các trang khác trong trang web hoặc các trang web khác vẫn giữ siêu liên kết trỏ đến URL đã xóa, Googlebot sẽ tiếp tục cố gắng truy cập thông qua các lối vào này, từ đó kéo dài sự tồn tại của đường dẫn đó trong kế hoạch thu thập dữ liệu.
- Sự chậm trễ của sơ đồ trang web XML (Sitemap): Nhiều trang web không cập nhật tệp sơ đồ trang web sau khi xóa trang. Nếu
sitemap.xmlvẫn chứa URL đã xóa, Google sẽ định kỳ dựa vào đó để kiểm tra trang, dẫn đến kho chỉ mục liên tục làm mới bản ghi của đường dẫn đó ngay cả khi nó đã trả về mã lỗi. - Tín hiệu xã hội và lưu lượng truy cập còn sót lại: Nếu một URL đã xóa vẫn nhận được lưu lượng truy cập nhấp chuột từ các nền tảng bên ngoài như Reddit hoặc X (trước đây là Twitter), cơ chế giám sát của Google sẽ cho rằng URL đó vẫn còn giá trị tồn tại, từ đó dành cho nó thời gian quan sát lâu hơn trong logic dọn dẹp tự động.
Chỉ mục của Google được chia thành Chỉ mục chính (Main Index) và Chỉ mục bổ sung (Supplementary Index).
Chỉ mục chính chứa nội dung chất lượng cao, cập nhật thường xuyên, trong khi chỉ mục bổ sung lưu trữ một lượng lớn các trang web “đuôi dài” và nội dung trùng lặp.
Nếu nội dung bị xóa nằm trong chỉ mục bổ sung, mức ưu tiên để Googlebot kiểm tra lại là cực kỳ thấp.
Trong nhiều trường hợp, một trang đã xóa có thể biến mất khỏi kết quả tìm kiếm chính, nhưng khi nhấp vào “Xem thêm kết quả” hoặc tìm kiếm thông qua lệnh site: cụ thể, nó vẫn có thể được tìm thấy trong bản chụp nhanh của chỉ mục bổ sung.
Tiêu chuẩn loại bỏ
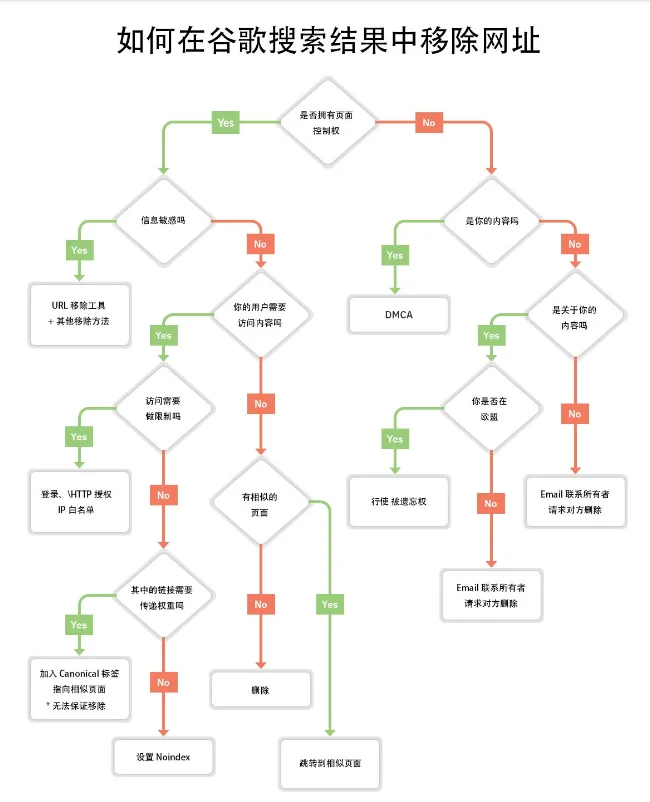
Lựa chọn hàng đầu để can thiệp thủ công là sử dụng công cụ “Xóa” trong Google Search Console (GSC), chức năng này nằm trong mục “Chỉ mục” ở menu bên trái của bảng điều khiển.
Trong tab “Xóa tạm thời”, nhấp vào “Yêu cầu mới” và nhập URL đầy đủ cần dọn dẹp, hệ thống cung cấp hai lựa chọn:
“Xóa tạm thời URL” và “Chỉ xóa URL được lưu trong bộ nhớ tạm”.
Lựa chọn đầu tiên sẽ chặn hoàn toàn đường dẫn đó khỏi kết quả tìm kiếm trong khoảng 24 giờ, có hiệu lực lên đến 180 ngày;
Lựa chọn sau giữ lại mục tìm kiếm nhưng sẽ lập tức xóa bỏ liên kết trỏ đến bản chụp nhanh cũ cũng như mô tả văn bản trong đoạn trích tìm kiếm.
Nếu trong thời hạn chặn 180 ngày, Googlebot vẫn không thể phát hiện tín hiệu trang đã biến mất ở phía máy chủ, mục đó sẽ xuất hiện lại trong kết quả tìm kiếm sau khi thời hạn chặn kết thúc.
Đối với nhân viên kỹ thuật có quyền quản trị máy chủ, việc cấu hình mã trạng thái phản hồi HTTP chính xác là giải pháp xử lý lâu dài phù hợp nhất với logic tối ưu hóa công cụ tìm kiếm (SEO).
Khi Googlebot truy cập một đường dẫn đã xóa, máy chủ nên trả về mã trạng thái 410 (Gone) thay vì mã 404 (Not Found) chung chung.
Theo tài liệu kỹ thuật chính thức của Google, mã trạng thái 410 gửi một lệnh xóa vĩnh viễn rõ ràng cho trình thu thập, điều này sẽ thúc đẩy hệ thống loại bỏ URL đó khỏi hàng đợi thu thập dữ liệu với mức ưu tiên cao hơn.
Mã trạng thái 404 thường được coi là lỗi mạng hoặc lỗi cấu hình tạm thời, Googlebot thường giữ lại chỉ mục đó và cố gắng thực hiện xác minh lần hai trong vòng 48 đến 96 giờ tới.
Đối với nhu cầu dọn dẹp bộ nhớ tạm quy mô lớn, bạn có thể thiết lập phản hồi 410 thống nhất cho các thư mục hoặc hậu tố tệp cụ thể trong tệp cấu hình của máy chủ Web (như Nginx hoặc Apache), từ đó hướng dẫn công cụ tìm kiếm đẩy nhanh việc dọn dẹp các tàn dư cũ trong kho chỉ mục toàn cầu.
| Tên công cụ/phương pháp | Kịch bản áp dụng | Tốc độ phản hồi | Trạng thái giữ lại chỉ mục | Thời hạn hiệu lực |
|---|---|---|---|---|
| Công cụ xóa tạm thời GSC | Cần chặn thông tin nhạy cảm hoặc trang đã xóa ngay lập tức | Có hiệu lực trong 24 giờ | Chỉ mục bị ẩn tạm thời | 180 ngày (có thể hủy thủ công) |
| Mã trạng thái HTTP 410 | Trang xóa vĩnh viễn, cần hướng dẫn trình thu thập dọn dẹp | Cập nhật theo lần thu thập tới | Loại bỏ hoàn toàn khỏi cơ sở dữ liệu | Có hiệu lực vĩnh viễn |
| Mã trạng thái HTTP 404 | Trang không tồn tại nhưng không có đánh dấu đặc biệt | Cập nhật sau thời gian quan sát | Loại bỏ có độ trễ | Có hiệu lực vĩnh viễn |
| Công cụ kiểm tra URL | Số lượng ít trang cần ép buộc thu thập lại thủ công | Từ 12 giờ đến 3 ngày | Kích hoạt cập nhật trạng thái | Có hiệu lực cho một lần yêu cầu |
Khi không thể giải quyết tình trạng trễ bộ nhớ tạm thông qua thu thập dữ liệu thông thường, bằng cách thêm X-Robots-Tag: noarchive vào tiêu đề phản hồi HTTP của máy chủ, bạn có thể ngăn Google lưu trữ bất kỳ bản chụp nhanh nào của trang đó trên máy chủ của họ.
Nếu muốn kiểm soát chi tiết hơn thời gian tồn tại của nội dung, bạn có thể sử dụng thẻ unavailable_after: [RFC 850 date/time], thẻ này sẽ thông báo cho Googlebot ngừng hiển thị trang web đó trong kết quả tìm kiếm sau ngày và giờ đã chỉ định.
| Tên thẻ/lệnh | Mô tả chức năng cụ thể | Hành vi của công cụ tìm kiếm |
|---|---|---|
| noarchive | Cấm/Bật bản chụp nhanh bộ nhớ tạm | Lập chỉ mục trang nhưng không hiển thị liên kết “Bản lưu” |
| nosnippet | Cấm đoạn trích văn bản | Kết quả tìm kiếm không hiển thị bản xem trước nội dung trang |
| noindex | Cấm lập chỉ mục hoàn toàn | Loại bỏ trang khỏi tất cả kết quả tìm kiếm |
| unavailable_after | Thiết lập thời gian hết hạn tự động | Tự động thực hiện logic noindex sau khi hết hạn |
Nhiều trang web sau khi xóa trang vẫn giữ lại bản ghi của URL đó trong sơ đồ trang web, dẫn đến việc Googlebot tiếp tục thực hiện kiểm tra định kỳ theo danh sách đường dẫn cũ.
Quy trình vận hành chuẩn nên là loại bỏ URL đó khỏi sitemap.xml đồng thời với việc xóa trang, và cập nhật thẻ <lastmod> (thời gian sửa đổi cuối cùng) của sơ đồ trang web.
Sau đó, đi đến trang “Sơ đồ trang web” trong Google Search Console để gửi lại tệp đó.
Cấu hình sai (Soft 404)
Khi trang của bạn đã bị xóa về mặt vật lý, nhưng máy chủ vẫn phản hồi mã trạng thái 200 OK cho Googlebot, nó sẽ kích hoạt lỗi Soft 404.
Theo dữ liệu thu thập từ Google Search Console, những trang này vì không trả về lệnh 404 hoặc 410 nên sẽ được hệ thống chỉ mục xử lý như một trang web bình thường.
Thông thường, nếu vùng nội dung chính của trang ít hơn 200 byte hoặc chuyển hướng về trang chủ của trang web, Googlebot sẽ đánh dấu nó là Soft 404 sau 2-3 lần thử thu thập dữ liệu, điều này dẫn đến việc URL đó tồn tại lâu hơn trong kết quả tìm kiếm từ 14-30 ngày.
Mã trạng thái gây hiểu lầm
Khi Googlebot truy cập máy chủ, bước đầu tiên là đọc mã trạng thái ba chữ số ở tiêu đề phản hồi HTTP.
Nếu bạn đã xóa tệp trang web về mặt vật lý, nhưng cấu hình máy chủ bị lệch khiến nó vẫn trả về 200 OK cho yêu cầu đó, Googlebot sẽ phán đoán rằng trang đó vẫn còn sống và nội dung vẫn hợp lệ.
Hệ thống chỉ mục của Google sau khi nhận được mã 200 sẽ đưa văn bản HTML thu thập được từ trang (ngay cả khi trên trang chỉ viết “Không tìm thấy nội dung”) vào Indexing Pipeline để xử lý.
Nếu URL lẽ ra phải biến mất này tiếp tục cung cấp tín hiệu 200, thời gian tồn tại của nó trong kho chỉ mục của Google sẽ bị kéo dài đáng kể.
Trong các trang web lớn, nếu tỷ lệ các URL bị lỗi như vậy vượt quá 10%, nó sẽ làm phân tán đáng kể Crawl Budget, dẫn đến tần suất cập nhật của các trang bình thường bị giảm xuống.
| Mã trạng thái HTTP | Định nghĩa kỹ thuật của Googlebot | Hành động xử lý của kho chỉ mục | Ảnh hưởng dự kiến đến thứ hạng tìm kiếm |
|---|---|---|---|
| 200 OK | Yêu cầu trang thành công, nội dung đầy đủ | Tiếp tục thu thập và lưu trữ bản chụp nhanh | Giữ lại thứ hạng và hiển thị đoạn trích văn bản |
| 404 Not Found | Tài nguyên không tìm thấy, có thể là tạm thời | Đánh dấu chờ loại bỏ, xác nhận sau nhiều lần | Thứ hạng giảm dần cho đến khi biến mất |
| 410 Gone | Tài nguyên xóa vĩnh viễn, không cần xác nhận lại | Lập tức bắt đầu quy trình hủy chỉ mục | Nhanh chóng loại bỏ khỏi kết quả tìm kiếm |
| 301 Permanent | Tài nguyên di chuyển vĩnh viễn sang vị trí mới | Chuyển trọng số URL cũ sang đường dẫn mới | Đường dẫn cũ biến mất, đường dẫn mới thay thế |
| 302 Found | Tài nguyên di chuyển tạm thời | Giữ lại chỉ mục URL cũ, không chuyển trọng số | URL cũ tiếp tục xuất hiện trong kết quả tìm kiếm |
Việc máy chủ trả về mã 200 sẽ khiến Google kích hoạt một thuật toán phán đoán gọi là Phát hiện Soft 404.
Công cụ kết xuất của Google sẽ phân tích trình bày hình ảnh và đặc điểm văn bản của trang, ví dụ như kiểm tra xem trang có chứa các từ như “404”, “Not Found” hoặc “Xin lỗi” hay không, cũng như liệu nội dung chính hữu ích của trang có ít hơn 200 byte hay không.
Nếu hệ thống phát hiện một trang có mã trạng thái 200 nhưng thực tế không có nội dung thực chất, nó sẽ cố gắng phân loại trang đó là Soft 404.
Việc phán đoán dựa trên thuật toán này có độ trễ rõ rệt, thường cần 3 đến 5 lần thu thập dữ liệu lặp lại mới có hiệu lực.
Đối với các trang web phụ thuộc vào môi trường Nginx hoặc Apache, nếu cấu hình sai dẫn đến việc trang lỗi 404 được dẫn hướng đến trang chủ thông qua 302 redirect, trạng thái 200 của trang chủ sẽ ghi đè lên tín hiệu báo lỗi ban đầu.
Google sẽ cho rằng URL ban đầu hiện tại đã đổi nội dung thành trang chủ, dẫn đến xung đột nội dung trùng lặp, khiến liên kết cũ tồn đọng lâu dài trong SERP.
Trường
Content-Lengthtrong tiêu đề phản hồi nếu hiển thị một giá trị nhỏ cố định (ví dụ dưới 1024 byte) mà mã trạng thái là 200, thường sẽ kích hoạt việc Google kiểm tra sâu độ mỏng của nội dung trang đó.
Khi xử lý các trang web quốc tế hóa với hàng triệu URL, X-Robots-Tag trong tiêu đề phản hồi máy chủ cũng là một tín hiệu bổ trợ.
Nếu bạn đã xóa trang nhưng không thể sửa mã trạng thái ngay lập tức, bạn có thể thêm lệnh noindex vào tiêu đề phản hồi.
Googlebot khi đọc được mã 200 đồng thời thấy noindex, sẽ loại bỏ nó trong chu kỳ cập nhật chỉ mục tiếp theo.
Trong kiến trúc máy chủ phân tán điển hình, nếu CDN phía trước (như Cloudflare hoặc Fastly) lưu bộ nhớ tạm phản hồi 200 ban đầu, ngay cả khi máy chủ nguồn phía sau đã sửa thành 404, những gì trình thu thập thấy vẫn là trạng thái cũ trong bộ nhớ tạm.
Sự không nhất quán của bộ nhớ tạm này sẽ dẫn đến việc dữ liệu chỉ mục của Google bị tách rời khỏi dữ liệu môi trường sản xuất thực tế.
| Loại trường tiêu đề | Ví dụ tham số | Phản hồi hành vi của trình thu thập Google | Đề xuất sửa chữa |
|---|---|---|---|
| Status Line | HTTP/1.1 404 Not Found | Ngừng phân bổ ngân sách thu thập cho URL này | Đảm bảo thao tác xóa đi kèm trạng thái này |
| Cache-Control | max-age=0, no-cache | Ép trình thu thập xác thực thời gian thực mỗi lần truy cập | Tránh CDN lưu bộ nhớ tạm phản hồi 200 sai |
| X-Robots-Tag | noindex, nofollow | Không cho phép vào chỉ mục ngay cả khi trả về 200 | Sử dụng như một biện pháp khắc phục tạm thời |
| Content-Type | text/html; charset=UTF-8 | Phân tích nội dung theo định dạng trang web | Xác nhận trang lỗi không bị nhận diện là tệp tải về |
Nếu máy chủ cấu hình logic If-Modified-Since quá phức tạp và vẫn trả về 304 Not Modified sau khi xóa trang, Googlebot sẽ không bao giờ thu thập lại nội dung mà sẽ tiếp tục sử dụng bản chụp nhanh cũ từ vài tháng trước trong kho chỉ mục.
Thuật toán phân bổ tần suất thu thập dữ liệu của Google sẽ thực hiện truy cập nhiều lần mỗi ngày đối với các tên miền có trọng số cao, trong khi đối với các tên miền trọng số thấp có thể chỉ truy cập một lần sau mỗi 14 đến 21 ngày.
Nếu máy chủ liên tục đưa ra tín hiệu 200 hoặc 304 gây hiểu lầm trong các cửa sổ truy cập này, các trang đã xóa sẽ trở thành “khách quen” trong kết quả tìm kiếm.
Để giải quyết triệt để vấn đề này, cần bắt đầu từ tệp cấu hình máy chủ, loại bỏ bất kỳ quy tắc viết lại (rewrite rules) toàn cục nào chuyển âm thầm các yêu cầu 404 thành phản hồi 200, và sử dụng công cụ kiểm tra Headers để xác nhận rằng trong luồng dữ liệu thô xuất ra, dòng đầu tiên thực sự chứa dòng chữ 404 hoặc 410.
Nhận diện xử lý
Mở menu bên trái của Google Search Console, tìm báo cáo Trang (Pages) trong danh mục Chỉ mục (Indexing).
Trong bảng bên dưới, tìm các mục có trạng thái được đánh dấu là “URL đã gửi có lỗi Soft 404”.
Sau khi nhấp vào, hệ thống sẽ hiển thị danh sách chi tiết các URL bị ảnh hưởng, ghi lại ngày thực hiện lần thu thập dữ liệu gần nhất.
Thông qua công cụ Kiểm tra URL (URL Inspection Tool), nhập đường dẫn cụ thể, nhấp vào “Kiểm tra URL trực tiếp” (Test Live URL).
Nếu kết quả kiểm tra cho thấy “URL có thể được Google lập chỉ mục” nhưng ảnh chụp màn hình trang hiển thị thông báo lỗi, thì xác nhận đó là cấu hình sai Soft 404.
Hệ thống tìm kiếm của Google khi xử lý loại dữ liệu này sẽ giữ lại hồ sơ thu thập dữ liệu của 16 tháng qua, bạn có thể phân tích quy luật phân bổ đường dẫn của các URL lỗi bằng cách xuất báo cáo chi tiết định dạng CSV, để phán đoán xem đó là vấn đề logic hệ thống trong các thư mục cụ thể (ví dụ /api/ hoặc /products/).
Chỉ khi dòng trạng thái của tiêu đề phản hồi HTTP trả về chính xác 404 Not Found hoặc 410 Gone, Googlebot mới bắt đầu quy trình hủy chỉ mục.
Việc thực hiện kiểm tra không qua trung gian bằng các công cụ dòng lệnh ở phía máy chủ là một phương tiện hiệu quả để loại bỏ các yếu tố gây nhiễu.
Sử dụng lệnh curl -I https://example.com/deleted-page, quan sát dòng đầu tiên của kết quả xuất ra.
Nếu trả về HTTP/1.1 200 OK, điều đó có nghĩa là cấu hình máy chủ phía sau đã không thể cắt đứt yêu cầu một cách chính xác.
Đối với máy chủ Web sử dụng Nginx, cần kiểm tra lệnh error_page trong tệp cấu hình nginx.conf.
Nếu thiết lập error_page 404 =200 /404.html, điều này sẽ ép buộc đặt lại trạng thái 404 thành 200. Cách làm đúng là loại bỏ dấu bằng, đảm bảo mã trạng thái được truyền đi nguyên trạng.
Đối với máy chủ Apache, hãy kiểm tra cấu hình ErrorDocument trong tệp .htaccess, tránh việc chuyển hướng hàng loạt các URL không còn hiệu lực về trang chủ.
| Tên công cụ | Chiều kích kiểm tra | Loại phản hồi dữ liệu | Kịch bản áp dụng |
|---|---|---|---|
| GSC URL Inspection | Trạng thái thu thập thời gian thực | Khả dụng chỉ mục/Ảnh chụp kết xuất | Điều tra sâu từng URL đơn lẻ |
| Screaming Frog SEO Spider | Mã trạng thái HTTP | Ma trận phản hồi hàng loạt URL | Quét toàn bộ các trang hiện có của site |
| Chrome DevTools (Network) | Thông tin tiêu đề phản hồi | Dữ liệu thô Server Header | Phân tích logic tương tác phía trước |
| Indexing API | Yêu cầu loại bỏ thời gian thực | Mã trạng thái phản hồi JSON | Các trang tạm thời được cập nhật thường xuyên |
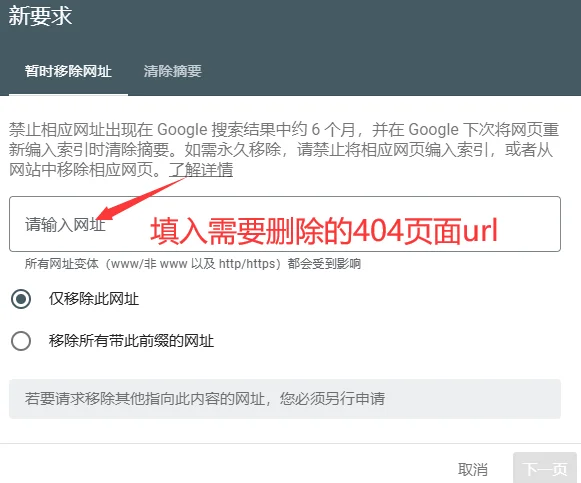
Nếu xác nhận là Soft 404, bạn có thể sử dụng công cụ Removals của Google để can thiệp tạm thời.
Công cụ này nằm trong tab “Xóa” của Search Console, cho phép người dùng gửi yêu cầu “Xóa tạm thời URL”.
Sau khi gửi, URL tương ứng sẽ biến mất khỏi kết quả tìm kiếm trong khoảng 180 ngày.
Trong khoảng thời gian này, Googlebot vẫn sẽ cố gắng thu thập dữ liệu địa chỉ đó. Một khi phát hiện mã trạng thái 404 thực sự, hệ thống sẽ chuyển việc xóa tạm thời thành hủy bỏ vĩnh viễn.
Công cụ này có giới hạn gửi yêu cầu mỗi 24 giờ, thường áp dụng để dọn dẹp dưới 1000 bản ghi không còn hiệu lực.
Thời gian phản hồi của máy chủ (Time to First Byte, TTFB) nếu vượt quá 2 giây, có thể dẫn đến việc Googlebot từ bỏ việc thu thập trạng thái hiện tại và tiếp tục sử dụng dữ liệu chỉ mục lịch sử.
Bằng cách tìm kiếm User-Agent của Googlebot (thường chứa Googlebot/2.1) và các dải địa chỉ IP tương ứng, bạn có thể quan sát tần suất trình thu thập truy cập các trang đã xóa.
Nếu nhật ký cho thấy trình thu thập nhận được toàn bộ mã 200 khi truy cập các trang này, trong khi kích thước trang (Bytes Sent) thường cố định trong khoảng từ 5KB đến 15KB (tức là kích thước của trang lỗi), điều này chứng tỏ máy chủ đang cung cấp “nội dung” không hợp lệ cho trình thu thập.
Đối với các ứng dụng trang đơn (SPA), cần đặc biệt chú ý đến trạng thái DOM sau khi kết xuất động. Công cụ kết xuất của Googlebot có giới hạn cắt bỏ nội dung là 15MB, nếu lỗi JavaScript dẫn đến việc kết xuất trang dừng lại ở trạng thái đang tải, nó cũng sẽ bị phán đoán nhầm là trang bình thường.
- Đăng nhập Google Search Console để giám sát báo cáo “Sơ đồ trang web” (Sitemaps), xác nhận các URL đã xóa không nằm trong danh sách XML đã gửi.
- Sử dụng thiết bị đầu cuối chạy
wget --server-response --spiderđể lấy thông tin bắt tay kết nối chi tiết. - Trong bảng “Mạng” (Network) của trình duyệt Chrome, tích chọn “Vô hiệu hóa bộ nhớ tạm” (Disable cache) để gửi lại yêu cầu, quan sát xem các lớp bộ nhớ tạm CDN như
X-CachehoặcVarnishcó trả về phản hồi 200 đã quá hạn hay không. - Đối với các trang web có lượng dữ liệu lớn, sử dụng Google Indexing API để gửi yêu cầu
URL_DELETED, phương thức này thường có tốc độ phản hồi nhanh hơn thu thập dữ liệu thụ động.
Sau khi xử lý xong cấu hình máy chủ, bạn nên nhấp vào “Xác thực việc sửa chữa” trong Search Console.
Điều này sẽ kích hoạt hệ thống lấy mẫu lại tất cả các URL được đánh dấu là Soft 404. Do Google phân bổ ngân sách dựa trên tần suất thu thập lịch sử của trang, các trang có trọng số cao sẽ hoàn thành cập nhật trạng thái trong vòng 48 giờ, trong khi các đường dẫn biên có trọng số thấp có thể mất từ 3 đến 4 tuần mới được xóa sạch khỏi kho chỉ mục.
Việc giữ cho robots.txt cho phép trình thu thập truy cập các trang này là cực kỳ quan trọng, bởi vì chỉ khi để trình thu thập thấy mã 404, lệnh hủy bỏ mới có thể có hiệu lực. Nếu bạn chặn trình thu thập sớm, nó sẽ không thể cập nhật bản ghi cũ có trạng thái 200 trong cơ sở dữ liệu của mình.
Liên kết ngoài vẫn tồn tại
Nếu một URL đã xóa vẫn được trỏ đến bởi hơn 3 tên miền độc lập, Googlebot sẽ dựa trên các đường dẫn thu thập dữ liệu của những liên kết này để truy cập lại địa chỉ đó nhiều lần.
Ngay cả khi trang trả về 404, các tín hiệu do liên kết mang lại sẽ khiến Google cho rằng nội dung đó có thể chỉ gặp lỗi tạm thời.
Các trang có trên 10 liên kết ngược (backlinks) đang hoạt động thường có thời gian tồn đọng trong kết quả tìm kiếm lâu hơn các trang không có liên kết từ 12 đến 20 ngày.
Sự can thiệp của lưu lượng truy cập bên ngoài
Khi người dùng từ các nền tảng bên ngoài nhấp vào liên kết của trang đã xóa, mỗi lần nhấp chuột tạo ra một yêu cầu HTTP sẽ gửi tín hiệu đến hệ thống của Google.
Nếu một URL được đánh dấu là 404 tạo ra hơn 50 lần nhấp chuột từ các tên miền bên ngoài trong vòng 24 giờ, hệ thống điều phối thu thập dữ liệu của Googlebot sẽ đưa URL đó trở lại chuỗi quan sát tần suất cao.
Khi một lượng lớn người dùng nhấp vào một trang không còn hiệu lực thông qua Reddit, X hoặc các bản tin email chuyên ngành, trình duyệt sẽ phản hồi hồ sơ truy cập thất bại về cơ sở dữ liệu của Google.
Thuật toán của công cụ tìm kiếm sẽ phán đoán rằng URL đó vẫn có một mức độ hoạt động nhất định. Để ngăn chặn việc mất thông tin có giá trị do thao tác sai của quản trị viên trang web, thuật toán sẽ chọn kéo dài thời gian giữ lại kết quả tìm kiếm đó thay vì loại bỏ ngay lập tức.
“Trong giao thức bảo trì chỉ mục của Google, trọng số của các tín hiệu hành vi người dùng thường ghi đè lên các lệnh mã trạng thái HTTP đơn thuần. Nếu một đường dẫn cũ trả về trạng thái 404 vẫn có thể nhận được lưu lượng truy cập ổn định từ các phương tiện truyền thông xã hội chính thống hoặc các blog có trọng số cao, hệ thống sẽ tự động kích hoạt một cửa sổ quan sát từ 7 đến 14 ngày. Trong giai đoạn này, công cụ tìm kiếm sẽ nhiều lần cử trình thu thập xác nhận tính ổn định của trạng thái đó để đảm bảo không phải do lỗi cấu hình máy chủ tạm thời.”
Phía máy chủ của Google sẽ nhận diện nguồn lưu lượng truy cập thực tế thông qua trường Referrer trong HTTP Header.
Nếu lưu lượng truy cập chủ yếu đến từ các sản phẩm trong hệ sinh thái của chính Google (như nhấp vào liên kết trong Gmail) hoặc từ các trang web xếp hạng hàng đầu thế giới, tác động gây nhiễu của nó sẽ tăng lên gấp bội.
Bảng dưới đây hiển thị thời gian ảnh hưởng của dữ liệu lưu lượng truy cập ở các chiều kích khác nhau đối với hành động dọn dẹp chỉ mục của Google:
| Lưu lượng truy cập bên ngoài trung bình ngày (UV) | Loại nguồn chính | Giá trị tăng thêm dự kiến của thời gian tồn đọng chỉ mục | Thay đổi tần suất thu thập dữ liệu của Googlebot |
|---|---|---|---|
| 5 – 20 | Dấu trang cá nhân hoặc blog trọng số thấp | 2 – 4 ngày | Duy trì quét 1 lần mỗi tuần |
| 21 – 100 | Bài thảo luận Reddit hoặc diễn đàn ngành quy mô vừa | 5 – 9 ngày | Tăng lên quét 1 lần mỗi 3 ngày |
| Trên 100 | Xu hướng hot trên X (Twitter) hoặc truyền thông trọng số cao | 10 – 20 ngày | Tăng lên quét 1 lần mỗi ngày hoặc nhiều lần mỗi ngày |
Hiện tượng này còn liên quan đến việc phân bổ ngân sách thu thập dữ liệu (Crawl Budget) của Google.
Các tài nguyên thu thập dữ liệu vốn dùng để phát hiện nội dung mới sẽ bị lãng phí vào các URL không còn hiệu lực nhưng liên tục tạo ra phản hồi lưu lượng truy cập này.
Khi công cụ tìm kiếm quan sát thấy mật độ nhấp chuột cao hướng về một trang 404, hệ thống chấm điểm chất lượng nội bộ của nó sẽ ghi lại “trải nghiệm người dùng không tốt” này.
Tuy nhiên, để tìm kiếm nội dung liên quan có thể thay thế trang đó, Google có thể giữ lại kết quả tìm kiếm gốc trong một thời gian và cố gắng hiển thị các trang đề xuất tương tự bên dưới kết quả đó, cơ chế này càng khiến trang cũ không thể biến mất khỏi trang kết quả tìm kiếm.
Trong một thử nghiệm kỹ thuật trên 500 URL không còn hiệu lực, người ta nhận thấy những trang liên tục nhận được nhấp chuột từ liên kết ngược bên ngoài có tần suất cập nhật bản chụp nhanh trong máy chủ bộ nhớ tạm cao hơn 3,5 lần so với các trang không có lưu lượng truy cập.
Do trình duyệt Chrome chiếm hơn 60% thị phần toàn cầu, khi người dùng nhập URL cũ vào thanh địa chỉ trình duyệt hoặc truy cập từ thanh dấu trang, hành vi truy cập chủ động này được coi là bằng chứng cho thấy URL đó vẫn còn sức sống.
Ngay cả khi trang web trả về lỗi không tìm thấy tệp tiêu chuẩn, chỉ cần người dùng không đóng cửa sổ trình duyệt trong vòng 30 giây sau khi truy cập trang lỗi đó, hoặc cố gắng tìm kiếm thông tin khác dưới cùng một tên miền, các hành vi tương tác này đều sẽ được thuật toán giải thích là trang đó vẫn chiếm một vị trí trong cấu trúc liên kết internet.
Trang web tổng hợp
Khi một trang web bị gỡ bỏ khỏi máy chủ gốc, dấu vết kỹ thuật số của nó sẽ không biến mất đồng thời tại các nút khác của internet.
Các loại trang web này bao gồm nhưng không giới hạn ở các trình đọc RSS toàn cầu (như Feedly hoặc Inoreader), các công cụ cắt dán web (như Pocket) cũng như các cơ quan lưu trữ mạng chuyên nghiệp (như Wayback Machine của Archive.org).
Ngay cả khi trang gốc trả về mã lỗi 404, các bản chụp nhanh HTML tĩnh do các nền tảng bên thứ ba này tạo ra vẫn đang cung cấp lối vào truy cập cho trình thu thập dữ liệu của Google.
Nếu Googlebot lặp lại việc phát hiện các liên kết trỏ đến URL không còn hiệu lực đó khi thu thập dữ liệu các trang tổng hợp có trọng số cao, thuật toán quản lý chỉ mục nội bộ của nó sẽ tạo ra một loại “mâu thuẫn logic”, cụ thể là:
Mặc dù trang web gốc báo cáo nội dung không tồn tại, nhưng hệ sinh thái bên ngoài vẫn đang trích dẫn nội dung đó.
Bảng dưới đây liệt kê các tác động dữ liệu cụ thể của các loại hành vi tổng hợp khác nhau đối với sự tồn đọng chỉ mục của Google:
| Loại nguồn tổng hợp | Chu kỳ làm mới dữ liệu | Thời gian gây nhiễu đối với chỉ mục Google | Giải thích logic thu thập dữ liệu |
|---|---|---|---|
| Nguồn cấp dữ liệu RSS / Atom | Một lần mỗi 10 – 60 phút | 14 – 30 ngày | Trình đăng ký sẽ liên tục yêu cầu tệp XML, khiến URL cũ tồn đọng lâu dài trong danh sách. |
| Nền tảng lưu trữ web (Archives) | Lưu giữ phiên bản vĩnh viễn | Gây nhiễu lâu dài | Ngay cả khi trang web gốc bị xóa, trạng thái “còn sống” của trang lưu trữ sẽ dẫn dụ trình thu thập truy cập lại đường dẫn cũ. |
| Trang web sao chép nội dung (Mirror sites) | Đồng bộ hóa mỗi ngày một lần | 7 – 21 ngày | Loại trang web này thu thập hàng loạt thông qua API, các liên kết ngược của chúng sẽ duy trì hoạt động của URL cũ trong kho chỉ mục. |
| Bộ nhớ tạm siêu dữ liệu mạng xã hội | Kích hoạt theo yêu cầu người dùng | 3 – 10 ngày | Ảnh xem trước và mô tả do giao thức Open Graph tạo ra được lưu trên máy chủ nền tảng, tạo thành điểm thu thập thứ hai. |
Ở cấp độ kỹ thuật, hệ thống thu thập dữ liệu phân tán của Google sẽ phân bổ một chu kỳ bộ nhớ tạm gọi là TTL (Time To Live) cho mỗi URL được phát hiện.
Khi các trang tổng hợp liên tục tạo ra “trích dẫn giả” đối với trang đó, máy chủ chỉ mục (Index Server) của Google sẽ nhận được các yêu cầu thu thập dữ liệu từ nhiều dải IP khác nhau.
Nếu quản trị viên trang web không loại bỏ bản ghi trong sơ đồ trang web XML (Sitemap) trước khi xóa trang, vòng lặp này sẽ càng được phóng đại.
“Đặc điểm phi tập trung của internet quyết định rằng việc xóa bỏ hoàn toàn thông tin là một quá trình dần dần. Khi một URL đã đi vào mạng lưới tổng hợp công cộng, nó sẽ thoát khỏi sự kiểm soát đơn lẻ của máy chủ gốc. Khi xử lý các tín hiệu xung đột loại này, Googlebot có xu hướng bảo vệ tính liên tục của kết quả tìm kiếm, nghĩa là duy trì trạng thái lưu trữ của nó trong máy chủ bộ nhớ tạm cho đến khi xác nhận rằng URL đó không còn hiệu lực tại tất cả các nút chính.”
Nếu một trang không còn hiệu lực có liên kết trích dẫn vẫn đang hoạt động trên các nền tảng trọng số cao như Reddit, Stack Overflow hoặc Medium, Googlebot sẽ cho rằng trạng thái 404 đó có thể là lỗi tạm thời do bảo trì máy chủ gây ra.
Trong trường hợp này, Google sẽ điều động Cached Version (Phiên bản lưu) được lưu trong các nút CDN toàn cầu của mình để hiển thị cho người dùng.
Khoảng 22% các trang đã xóa sẽ trải qua một “giai đoạn phục hồi bộ nhớ tạm” trước khi biến mất, tức là công cụ tìm kiếm đang cố gắng sử dụng nội dung bộ nhớ tạm để lấp đầy khoảng trống chỉ mục.
- Độ trễ đồng bộ hóa của các trung tâm dữ liệu: Google có hàng chục trung tâm dữ liệu chính trên toàn thế giới, việc cập nhật kho chỉ mục của mỗi trung tâm không phải là thời gian thực. Khi một trang tổng hợp nào đó kích hoạt thu thập dữ liệu tại nút châu Âu, việc đồng bộ hóa thông tin đó sang nút Bắc Mỹ có thể có độ trễ vài giờ hoặc thậm chí vài ngày.
- Tính gây hiểu lầm của yêu cầu Head: Nhiều công cụ tổng hợp chỉ kiểm tra phản hồi máy chủ thông qua yêu cầu Head mà không tải xuống toàn bộ văn bản HTML. Sự tương tác nhẹ nhàng này khiến thuật toán của Google khó có thể phán đoán sự thiếu hụt thực tế của nội dung ngay từ đầu.
- Tác dụng phụ của kết xuất JavaScript: Một số trang tổng hợp cao cấp sẽ chạy trình duyệt không đầu (Headless Browser) để thu thập nội dung động. Nếu thiết kế trang 404 của bạn không đủ đơn giản (ví dụ chứa lượng lớn thanh điều hướng hoặc bài viết đề xuất), trình thu thập có thể nhầm tưởng rằng trang đó vẫn mang thông tin hữu ích.
- Thu thập đệ quy các đường dẫn trích dẫn: Trang A trích dẫn URL đã xóa, trang B lại thu thập trang danh sách của trang A. Mạng lưới trích dẫn nhiều tầng này cung cấp nguồn đường dẫn thu thập liên tục cho Googlebot, khiến URL cũ luôn nằm trong hàng đợi “chờ xử lý”.
Khi số lượng các trang web tổng hợp đạt đến một quy mô nhất định, ngân sách thu thập dữ liệu (Crawl Budget) của Google sẽ bị chiếm dụng bởi các đường dẫn không còn hiệu lực này.
Trong việc xử lý sự tồn đọng này, sử dụng Removals Tool (Công cụ xóa) của Google Search Console là cách nhanh nhất để phá vỡ vòng lặp logic này.


