




















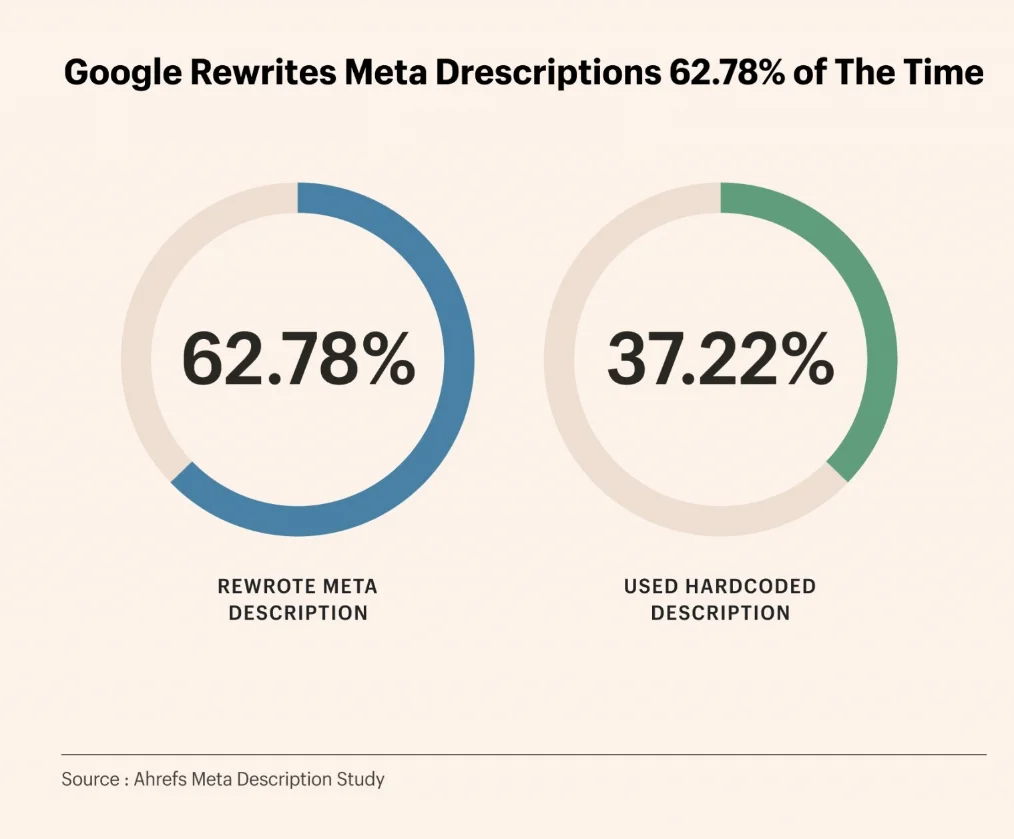
Nghiên cứu của Google cho thấy khoảng 70% nội dung mô tả sẽ bị viết lại.
Nếu mô tả gốc không khớp với từ khóa tìm kiếm của người dùng, thuật toán sẽ trích xuất các phân đoạn liên quan hơn từ nội dung chính.
Mô tả được khuyến nghị nên duy trì trong khoảng 155 ký tự.
Nội dung quá dài hoặc chứa quá nhiều từ khóa nhồi nhét sẽ khiến Google tự động cắt bớt hoặc thay đổi nội dung.
Nếu nội dung chính của trang web có thể trả lời ý định của người dùng chính xác hơn thẻ meta description, Google sẽ ưu tiên hiển thị nội dung chính để cải thiện trải nghiệm tìm kiếm và độ tin cậy EEAT.

Khớp nối mức độ liên quan (Nguyên nhân phổ biến nhất)
Khảo sát của Ahrefs trên 192.000 trang cho thấy tỷ lệ viết lại meta description của Google lên tới 62,7%.
Khi các từ khóa tìm kiếm (Queries) của người dùng không xuất hiện trong 155 ký tự bạn thiết lập, hoặc khi một đoạn nào đó trong nội dung chính chứa kết quả khớp từ khóa chính xác hơn, Google sẽ từ bỏ phương án thiết lập sẵn của bạn.
Trong kết quả trang đầu tiên, tỷ lệ viết lại dựa trên ý định này sẽ tăng lên hơn 70%, mục tiêu là làm cho văn bản kết quả tìm kiếm tương ứng 100% về mặt chữ với từ khóa tìm kiếm của người dùng.
Sự rời rạc của mô tả thiết lập sẵn
Trong các thử nghiệm SEO tại thị trường Bắc Mỹ, quan sát thấy rằng đối với cùng một trang, Google sẽ hiển thị các đoạn trích hoàn toàn khác nhau đối với các ý định tìm kiếm khác nhau.
Giả sử một trang về “Best Credit Cards 2024”, mô tả thiết lập sẵn của nó tập trung vào xếp hạng tổng thể, nhưng nếu người dùng tìm kiếm “credit cards with no foreign transaction fees”, Google sẽ tự động bỏ qua mô tả thiết lập sẵn và thay vào đó trích xuất đoạn văn về giải thích phí trong nội dung chính.
Thuật toán đánh giá giá trị đóng góp của từng ký tự, nếu mô tả thiết lập sẵn chứa quá nhiều lời quảng cáo thương hiệu thay vì dữ liệu thực tế, trọng số của nó sẽ giảm xuống nhanh chóng.
| Loại từ khóa tìm kiếm (Intent Type) | Tỷ lệ chấp nhận mô tả thiết lập sẵn (Average) | Nguyên nhân kích hoạt viết lại thường gặp |
|---|---|---|
| Tìm kiếm thương hiệu (Navigational) | 82.4% | Mô tả thường chứa tên thương hiệu, mức độ khớp rất cao |
| Mã sản phẩm cụ thể (Transactional) | 41.2% | Mô tả thiếu các thông số kỹ thuật cụ thể (như màu sắc, trọng lượng, dung lượng) |
| Hướng dẫn thao tác/Làm thế nào (Informational) | 28.7% | Thuật toán có xu hướng hiển thị danh sách các bước trong đoạn trích |
| Tìm kiếm so sánh (Comparison) | 35.5% | Mô tả không đề cập đến tên đối tượng thứ hai được so sánh |
Tình trạng rời rạc này đặc biệt rõ ràng trong hiệu suất tìm kiếm của các nền tảng thương mại điện tử như Amazon hoặc eBay.
Nếu meta description của một trang sản phẩm được viết quá rộng quát, không bao gồm các chỉ số kỹ thuật cụ thể có thể xuất hiện trong tìm kiếm của người dùng, thuật toán sẽ kích hoạt “tạo đoạn trích động”.
Mô hình BERT của Google sẽ phân tích không gian vector của từ khóa tìm kiếm, khi nó phát hiện một bảng thông số kỹ thuật trong nội dung chính chứa các thuật ngữ gần với vector tìm kiếm hơn, mô tả thiết lập sẵn sẽ bị loại bỏ.
| Độ dài từ khóa tìm kiếm (Words Count) | Xác suất viết lại meta description (Probability) | Xu hướng logic khớp nối |
|---|---|---|
| 1 – 2 từ | 38.6% | Khớp chính xác từ khóa chính |
| 3 – 5 từ | 62.1% | Khớp nối liên quan về ngữ nghĩa |
| Trên 6 từ | 78.3% | Tìm kiếm câu trả lời đuôi dài cụ thể trong nội dung chính |
Trong so sánh dữ liệu của Google Search Console, có thể thấy rằng khi thứ hạng trang nằm trong top 3, nếu đoạn trích có thể bao gồm chính xác tất cả các từ mà người dùng tìm kiếm, tỷ lệ nhấp (CTR) của nó sẽ cao hơn khoảng 15% so với đoạn trích không khớp hoàn toàn.
Nếu quản trị viên trang web chỉ thiết lập một meta description chung cho trang, trong khi trang đó thực tế bao gồm năm chủ đề phụ khác nhau, thì khi đối mặt với tìm kiếm của bốn chủ đề phụ trong số đó, mô tả thiết lập sẵn đều sẽ mất hiệu lực.
Để giảm thiểu tác động tiêu cực do sự rời rạc này mang lại, việc phân tích sự phân bổ các từ khóa tìm kiếm thực tế được kích hoạt với tần suất cao trên trang trở nên rất cần thiết.
Nếu một trang nhất định đã nhận được lưu lượng truy cập thông qua 15 từ khóa đuôi dài khác nhau trong 30 ngày qua, nhưng meta description hiện tại chỉ bao gồm 2 trong số đó, thì việc thuật toán viết lại là một lựa chọn tất yếu.
Bố trí nhiều biến thể từ khóa tương ứng với meta description hơn trong đoạn đầu của trang (Above the Fold) có thể nâng cao một chút sự tin tưởng chấp nhận của thuật toán.
| Lĩnh vực ngành nghề (Verticals) | Tần suất viết lại đoạn trích (Western Markets) | Loại nội dung có tỷ lệ chấp nhận cao nhất |
|---|---|---|
| Tài chính bảo hiểm (Finance) | Cao (74%) | Các con số cụ thể như lãi suất, tỷ lệ phí, hạn mức bảo hiểm |
| Công nghệ kỹ thuật số (Tech) | Trung bình cao (68%) | Thông số phần cứng, số phiên bản phần mềm, hướng dẫn tương thích |
| Du lịch tham quan (Travel) | Trung bình (55%) | Tên địa điểm, thời gian mở cửa, thông tin giá vé |
| Bán lẻ thời trang (Fashion) | Trung bình thấp (42%) | Chất liệu, phạm vi kích cỡ, lịch sử thương hiệu |
Trong môi trường tìm kiếm tiếng Anh, giới hạn trên máy tính để bàn là khoảng 920 pixel, thường tương ứng với 155 đến 160 ký tự nửa chiều (half-width).
Nếu mô tả thiết lập sẵn dẫn đến tràn pixel do chứa quá nhiều khoảng trắng hoặc từ dài, thuật toán sẽ tự động tìm kiếm các câu ngắn “gọn gàng” hơn và có mật độ thông tin cao hơn từ nội dung chính để thay thế.
Mật độ văn bản
Khi bạn thiết lập meta description 155 ký tự trong HTML, thuật toán sẽ so sánh nó với một số phân đoạn 160 đến 200 ký tự trong nội dung chính của trang.
Nếu từ khóa tìm kiếm của người dùng (Query) chỉ xuất hiện một lần trong mô tả thiết lập sẵn của bạn, trong khi nó xuất hiện ba lần trong một đoạn nhất định của nội dung chính và chứa các từ đồng nghĩa liên quan, thuật toán thường sẽ chọn nội dung chính.
Trên các thiết bị máy tính để bàn, không gian hiển thị đoạn trích kết quả tìm kiếm rộng khoảng 920 pixel, trong khi thiết bị di động là khoảng 680 pixel.
Thuật toán của Google có xu hướng lấp đầy các không gian này, nếu mô tả thiết lập sẵn của bạn quá ngắn (ví dụ chỉ rộng 100 pixel), thuật toán sẽ cho rằng điều này không đủ để truyền đạt nội dung trang, từ đó trích xuất đoạn dài hơn từ nội dung chính để lấp đầy không gian còn lại.
- Khoảng cách vật lý từ khóa (Proximity): Khoảng cách giữa các từ khóa tìm kiếm càng gần thì trọng số hiển thị càng cao. Nếu người dùng tìm kiếm “best coffee grinder for espresso”, bạn có một câu trong nội dung chính “The Baratza Encore is the best coffee grinder if you want to make espresso”, bốn từ khóa trong câu này được sắp xếp chặt chẽ. Trong khi meta description của bạn có thể là “Find the best equipment for your kitchen including a coffee grinder and machines for espresso”, các từ khóa bị phân tán ở hai đầu câu.
- Sức hút của hiệu ứng in đậm: Google tự động in đậm các phần khớp với từ khóa tìm kiếm trong đoạn trích. Logic của thuật toán là: Càng nhiều từ in đậm, tỷ lệ nhấp (CTR) thường càng cao. Nếu đoạn trích nội dung chính có thể tạo ra 5 từ in đậm, trong khi meta description chỉ có thể tạo ra 2 từ, thuật toán sẽ hy sinh mô tả thiết lập sẵn của bạn để tăng xác suất nhấp chuột của người dùng.
| Thuộc tính văn bản | Meta Description thiết lập sẵn | Đoạn trích do thuật toán tạo ra (Snippet) |
|---|---|---|
| Chiều rộng pixel trung bình | Thường được khuyến nghị trong vòng 920px | Tự động mở rộng đến giới hạn 920px hoặc 680px |
| Chế độ khớp từ khóa | Tĩnh, không thể dự đoán tất cả các tổ hợp tìm kiếm | Trích xuất động, khớp thời gian thực với các từ người dùng nhập |
| Trọng số mở rộng từ đồng nghĩa | Thấp, bị giới hạn bởi độ dài ký tự | Cao, có thể trích xuất các thuật ngữ liên quan từ nội dung chính dài |
| Tỷ lệ từ in đậm | Khoảng 5% – 15% | Thường vượt quá 20% |
Khi xử lý tìm kiếm đuôi dài (Long-tail Queries), giả sử trang của bạn nói về “Cẩm nang du lịch Seattle”, meta description viết là “Hướng dẫn du lịch Seattle toàn diện, bao gồm các gợi ý về điểm tham quan, ẩm thực và khách sạn”.
Khi người dùng tìm kiếm “Cẩm nang đỗ xe chợ Pike Place Seattle”, meta description của bạn hoàn toàn không đề cập đến thông tin đỗ xe.
Do đoạn thứ ba của nội dung chính trang viết chi tiết về “Phí đỗ xe và phân bổ bãi đỗ xe gần chợ Pike Place”, Google sẽ trích xuất đoạn này làm đoạn trích.
| Loại từ khóa tìm kiếm | Tỷ lệ chấp nhận mô tả thiết lập sẵn | Nhân tố thúc đẩy viết lại |
|---|---|---|
| Từ khóa thương hiệu/điều hướng | Khoảng 80% | Mô tả thường chứa tên thương hiệu, mức độ khớp cao |
| Từ khóa thông tin/đuôi dài | Khoảng 30% | Mô tả không thể bao gồm các vấn đề chi tiết cụ thể |
| Từ khóa so sánh/danh sách | Khoảng 45% | Thuật toán thích hiển thị các mục danh sách (Bullet points) hơn |
Để đạt được trọng số hiển thị cao hơn, cấu trúc văn bản trong trang cần mô phỏng logic tạo đoạn trích.
Nếu câu đầu tiên của một đoạn văn chứa từ khóa tìm kiếm và có văn bản giải thích liên quan trong vòng 100 ký tự tiếp theo, trọng số đoạn văn này được chọn cao gấp khoảng 2,5 lần so với đoạn văn thông thường.

Chất lượng meta description không cao
Tài liệu thuật toán của Google chỉ ra rằng, nếu mức độ trùng lặp giữa meta description và từ khóa tìm kiếm của người dùng thấp hơn 30%, hoặc độ dài ký tự không nằm trong khoảng 120-160 ký tự nửa chiều, hệ thống có xác suất 70% sẽ viết lại đoạn trích.
Biểu hiện của chất lượng không cao bao gồm: hơn 20% số trang trên toàn trang web sử dụng cùng một nội dung, nhồi nhét hơn 4 từ khóa, hoặc mô tả không khớp với nội dung thẻ H1 của trang.
Những trường hợp này sẽ dẫn đến việc thuật toán trích xuất văn bản từ 200 từ đầu tiên của nội dung chính để thay thế.
Tính lặp lại & Tính độc nhất
Hệ thống lập chỉ mục của Google thu thập siêu dữ liệu trang web thông qua các trình thu thập song song quy mô lớn (Googlebot).
Nếu trong một trang web có hơn 15% số trang chia sẻ văn bản meta description hoàn toàn giống nhau, thuật toán sẽ kích hoạt “bộ nhận diện nội dung chất lượng thấp”, coi hành vi này là văn bản mẫu được tạo ra hàng loạt (Boilerplate Text).
Theo phân tích dữ liệu trên 500.000 trang thương mại điện tử Bắc Mỹ, các trang web có hơn 80% meta description độc nhất có xác suất nhận được hiển thị đoạn trích thiết lập sẵn trong trang kết quả tìm kiếm (SERP) cao gấp 5,2 lần so với các trang web sử dụng mô tả lặp lại.
Trong thực tiễn SEO của các nền tảng bất động sản lớn hoặc trang web giao dịch ô tô, nhân viên kỹ thuật thường dựa vào các mẫu thiết lập sẵn để lấp đầy hàng nghìn trang chi tiết.
Ví dụ, khi xử lý hàng nghìn danh sách căn hộ tại San Francisco hoặc London, nếu meta description chỉ thay đổi tên đường mà giữ nguyên 90% văn bản còn lại, thuật toán tạo đoạn trích của Google sẽ nhận diện được mức độ trùng lặp văn bản cực cao (Cosine Similarity).
Khi độ tương đồng này vượt quá ngưỡng 0,85, công cụ tìm kiếm thường chọn từ bỏ tất cả các thẻ meta description và thay vào đó trích xuất dữ liệu <table> hoặc các thông số kỹ thuật trong các mục danh sách <ul> của mỗi trang.
Bảng dưới đây so sánh chi tiết tác động cụ thể của các mức độ lặp lại meta description khác nhau đối với hiệu suất của công cụ tìm kiếm.
| Loại tính độc nhất của meta description | Tỷ lệ trùng lặp trang (Text Overlap) | Xác suất bị Google viết lại | Biên độ dao động tỷ lệ nhấp dự kiến (CTR) |
|---|---|---|---|
| Tính độc nhất cao | < 10% | 12% – 18% | + 22.5% |
| Khác biệt theo mẫu | 40% – 70% | 55% – 72% | – 14.8% |
| Loại lặp lại hoàn toàn | > 95% | 88% – 96% | – 35.2% |
Meta description lặp lại không chỉ tạo ra phản hồi tiêu cực bên trong một trang web đơn lẻ, mà còn gây ra các vấn đề thu thập nghiêm trọng trong các trang web sao chép xuyên tên miền hoặc các trang web quốc tế hóa.
Đối với các trang web tiếng Anh hoạt động đồng thời tại Mỹ, Anh và Canada, nếu không thực hiện điều chỉnh nhỏ về ngữ pháp mô tả theo đặc điểm từng vùng, việc sao chép đơn thuần siêu dữ liệu sẽ khiến chỉ mục khu vực (Regional Indexing) của Google bị nhầm lẫn.
Khi đối mặt với ba mô tả đoạn trích hoàn toàn giống nhau, thuật toán sẽ có xu hướng chỉ giữ lại một vị trí hiển thị của tên miền chính trong SERP, các trang còn lại có thể bị đưa vào “kết quả tìm kiếm bị lược bỏ”.
Điểm kích hoạt của cơ chế lọc này nằm ở việc thiếu điểm “gia tăng thông tin”;
Nếu mô tả của trang thứ hai không thể cung cấp nhiều điểm dữ liệu độc đáo hơn trang thứ nhất (như giá bằng đồng tiền địa phương, tình trạng kho hàng hoặc thời gian giao hàng cụ thể theo khu vực), hệ thống sẽ xác định rằng nó không cần thiết phải hiển thị cho người dùng.
Theo một nghiên cứu độc lập trên 120.000 trang tiếp thị SaaS, nếu meta description chứa dữ liệu thời gian thực được chèn động (như “Cập nhật lần cuối tháng 1 năm 2026” hoặc “Được tin dùng bởi hơn 50.000 người dùng tại Đức”), xác suất nó được hệ thống giữ lại sẽ tăng 38%. Cách làm này về bản chất là vượt qua kiểm tra chống trùng lặp của thuật toán bằng cách nâng cao “tính nhạy cảm thời gian” và “tính độc nhất địa lý” của thông tin.
Đối với các trang web có hàng triệu URL, việc viết thủ công meta description cho từng trang là không thực tế, nhưng các mô tả dựa trên thuật toán tạo ra phải đưa vào đủ các biến ngẫu nhiên và các trường động.
Nếu trong vòng 40 pixel chiều rộng đầu tiên của meta description của mỗi trang đều là những từ hoàn toàn giống nhau, trải nghiệm thị giác của người dùng di động sẽ trở nên cực kỳ tầm thường, điều này sẽ dẫn đến tỷ lệ thoát cực cao.
Tiện ích RankBrain của Google ghi lại sở thích nhấp chuột của người dùng trên SERP, nếu người dùng thường xuyên nảy sinh “sự thờ ơ thị giác” khi đối mặt với một loạt các mô tả đoạn trích lặp lại, thẩm quyền xếp hạng tổng thể của tên miền đó (Domain Authority) sẽ bị đè nén trong các lần lặp lại thuật toán tiếp theo.
Để tránh các rủi ro như vậy, nhóm kỹ thuật nên đưa vào các giải pháp tạo tự động dựa trên dữ liệu có cấu trúc Schema.org, đảm bảo meta description chứa số SKU của sản phẩm, điểm đánh giá trung bình hoặc tọa độ địa lý cụ thể.
Kiểm tra tính độc nhất không nên chỉ giới hạn ở sự sắp xếp và kết hợp các ký tự văn bản, các mô hình ngôn ngữ hiện đại (như BERT hoặc T5) khi xử lý đoạn trích tìm kiếm có thể nhận diện các câu có ý nghĩa hoàn toàn giống nhau nhưng cách diễn đạt hơi khác nhau.
Nếu hai trang danh mục khác nhau của một trang web (ví dụ: “Giày chạy bộ nam” và “Giày chạy cho nam”) có meta description mặc dù thứ tự từ khác nhau nhưng ý định diễn đạt hoàn toàn nhất quán, Google vẫn sẽ đánh dấu chúng là lặp lại.
Lộ trình tối ưu hóa hiệu quả nên tập trung vào việc trích xuất các sự thật không mang tính cạnh tranh đặc thù của trang web.
Ví dụ, khi mô tả một trang dịch vụ đặt tại thành phố New York, ngoài việc đề cập đến nội dung dịch vụ, cũng nên đưa vào giờ mở cửa đặc thù của văn phòng đó, các địa danh lân cận hoặc số chứng nhận cụ thể.
Việc đưa vào các chi tiết mật độ cao như vậy có thể đảm bảo dấu vân tay của meta description duy trì tính độc nhất trong toàn bộ phạm vi Internet.
Nhồi nhét từ khóa
Hệ thống lọc SpamBrain bên trong của Google sẽ thực hiện xử lý vector hóa văn bản đối với thẻ <meta name="description" content="..."> trong mã nguồn HTML, đánh giá xem có hành vi vi phạm hay không bằng cách tính toán mật độ tần suất từ (Term Frequency).
Sau bản cập nhật thuật toán năm 2024, logic giám sát đối với các trang web tiếng Anh và các ngữ hệ Latinh khác cho thấy, nếu một danh từ hoặc cụm từ cụ thể xuất hiện quá 3 lần trong phạm vi 160 ký tự nửa chiều, xác suất mô tả đó bị đánh giá là văn bản không tự nhiên sẽ tăng 45%.
Thói quen SEO trước đây là cưỡng ép sắp xếp nhiều mẫu mã, giá cả hoặc địa danh trong meta description, nhưng dưới kiến trúc mô hình Transformer hiện tại, các chuỗi ký tự thiếu ngữ pháp này sẽ bị nhận diện là “phân đoạn không gia tăng thông tin”.
Theo thống kê của Ahrefs trên 200.000 kết quả tìm kiếm ngẫu nhiên, các meta description chứa hơn ba từ khóa lặp lại có tỷ lệ bị Google tự động thay thế bằng các đoạn trích ngẫu nhiên từ nội dung chính lên tới 88%.
Theo hồ sơ tài liệu nhà phát triển Mozilla về hiệu suất kết xuất, các công cụ kết xuất trình duyệt hiện đại khi xử lý tràn văn bản sẽ ưu tiên xem xét chiều rộng pixel được định nghĩa bởi kiểu chữ hơn là số lượng ký tự. Vùng hiển thị đoạn trích kết quả tìm kiếm Google trên máy tính để bàn bị giới hạn ở chiều rộng khoảng 920 pixel, trong khi trên di động giảm xuống còn khoảng 680 pixel. Nếu meta description nhồi nhét một lượng lớn các từ dài hoặc tổ hợp chữ cái viết hoa, ngay cả khi số lượng ký tự trong vòng 150, văn bản cũng sẽ bị cắt bớt trong trang kết quả tìm kiếm (SERP) do tổng chiều rộng pixel vượt quá giới hạn. Các mô tả bị cắt bớt thường biểu hiện ý định dừng lại của người dùng thấp hơn, dữ liệu thực nghiệm cho thấy các mô tả ngôn ngữ tự nhiên hiển thị đầy đủ có tỷ lệ nhấp cao hơn 18,6% so với các mô tả nhồi nhét bị cắt bớt.
Đối với các trang web nhắm đến thị trường Mỹ, điểm số meta description lý tưởng nên duy trì trong khoảng 60 đến 70 điểm, tương ứng với trình độ đọc của học sinh lớp 8 đến lớp 9 tại Mỹ.
Nếu sử dụng các mệnh đề phụ hoặc thuật ngữ quá phức tạp để lồng ghép nhiều từ khóa tìm kiếm hơn, dẫn đến điểm số thấp hơn 50, thuật toán có thể cho rằng phân đoạn này không thể cung cấp bản xem trước nội dung rõ ràng cho người dùng tìm kiếm thông thường.
Báo cáo nghiên cứu của Semrush chỉ ra rằng, khi độ dài trung bình của câu từ 12 đến 15 từ, hiệu quả hiểu của người dùng là cao nhất.
Khi meta description sử dụng một câu dài và khó duy nhất (vượt quá 25 từ) và thiếu động từ thúc đẩy, công cụ tìm kiếm có xu hướng trích xuất các câu ngắn hơn từ phía dưới <h2> hoặc <h3> của trang web để thay thế.
Việc sử dụng quá mức các ký hiệu phi chữ cái như dấu sao (*), dấu gạch đứng (|), dấu chấm than (!) hoặc dấu bằng (=) để ngăn cách các từ khóa trong văn bản sẽ làm giảm điểm số ngôn ngữ tự nhiên của văn bản.
API Xử lý Ngôn ngữ Tự nhiên (NLP) của Google sẽ gán một điểm số “độ tin cậy ngữ pháp” cho mỗi đoạn văn bản, các meta description hoàn toàn bao gồm các cụm danh từ thường thấp hơn 0,3 trong hạng mục điểm số này, trong khi các câu cấu trúc “Chủ-Vị-Tân” tiêu chuẩn thường có điểm số trên 0,85.
Các đoạn văn bản thấp hơn 0,5 sẽ bị tự động đánh dấu là nội dung chất lượng thấp, từ đó mất đi cơ hội được ưu tiên hiển thị trong SERP.
Trong một meta description 155 ký tự tiêu chuẩn, nếu tất cả các từ khóa đều tập trung ở 20% vị trí đầu tiên, hoặc lặp lại vô nghĩa ở cuối văn bản, hệ thống sẽ nhận diện đó là hành vi lừa dối đối với thuật toán xếp hạng.
Một phân tích dữ liệu của Backlinko cho thấy, tỷ lệ danh từ và động từ trong các mô tả tự nhiên thường duy trì ở mức khoảng 3:1.
“Đầu ra của trình tạo đoạn trích của Google là sự cân bằng giữa mức độ liên quan của truy vấn người dùng và tính toàn vẹn ngôn ngữ của văn bản nguồn.” Nguyên tắc kỹ thuật này cho thấy việc chỉ khớp các từ vựng là không đủ để có được quyền hiển thị. Trong phân tích nhúng từ (Word Embedding) đối với kho từ vựng 1 triệu từ tiếng Anh, thuật toán có thể nhận diện được những từ nào thuộc cùng một cụm ngữ nghĩa. Quản trị viên trang web không cần lặp lại “Running Shoes”, “Shoes for Running” và “Runner Footwear”, vì thuật toán đã phân loại các diễn đạt này vào cùng một thực thể. Việc lặp lại các từ đồng nghĩa này trong meta description sẽ bị coi là tối ưu hóa quá mức.
Tiêu điểm thị giác của người dùng di động khi lướt màn hình thường dừng lại ở hai dòng đầu tiên của đoạn trích.
Nếu nhồi nhét từ khóa vào nửa sau của mô tả, người dùng không thể cảm nhận được mức độ liên quan của trang trước khi nhấp chuột.
Nghiên cứu về hành vi tìm kiếm di động tại khu vực California cho thấy, việc đặt các động từ hướng hành động (như Compare, Discover, Get) vào 40 ký tự đầu tiên của meta description có tần suất tương tác cao hơn 12% so với các mô tả nhồi nhét từ khóa ở phần đầu.
Vấn đề mã kỹ thuật
Các lỗi kỹ thuật sẽ khiến công cụ thu thập của Google (Googlebot) không thể trích xuất meta description.
Thống kê cho thấy khoảng 15% các trường hợp hiển thị đoạn trích bất thường bắt nguồn từ lỗi cấu trúc HTML. Google yêu cầu thẻ meta description phải nằm trong vòng 1MB đầu tiên của tài liệu HTML và thẻ phải được đóng hoàn chỉnh.
Nếu trang dựa vào JavaScript để chèn meta description và thời gian thực thi tập lệnh vượt quá 5 giây, Googlebot thường sẽ thu thập nội dung trống trong mã nguồn tĩnh thay vì văn bản sau khi kết xuất.
Vị trí thẻ
Theo logic cơ bản của công cụ kết xuất Chromium, trình phân tích cú pháp khi quét HTML sẽ thiết lập một cây mô hình đối tượng tài liệu (DOM).
Nếu thẻ <meta name="description"> được đặt ở vị trí sau 1.024.000 byte (tức 1MB) trong mã nguồn HTML, thẻ đó sẽ bị hệ thống lập chỉ mục của Google bỏ qua.
Hiện tượng này thường gặp ở các trang sử dụng một lượng lớn CSS nội tuyến (inline) hoặc hình ảnh mã hóa Base64.
Khi phần đầu của trang web tải hàng nghìn dòng bảng kiểu nội tuyến hoặc mã đồ họa SVG phức tạp, thẻ meta description sẽ bị đẩy vào vùng sâu của tài liệu.
Để tiết kiệm hạn ngạch thu thập và tài nguyên tính toán, trình thu thập của Google thường chỉ thực hiện quét siêu dữ liệu tinh xảo đối với 1MB nội dung đầu tiên của tài liệu.
Một khi vượt quá ngưỡng này, hệ thống sẽ ngừng tìm kiếm các thuộc tính trong <head> và chuyển sang chế độ thu thập thông thường đối với nội dung chính, điều này khiến meta description thiết lập sẵn không thể xuất hiện trong trang kết quả tìm kiếm.
Trong quy chuẩn HTML, thẻ meta description phải được đặt nghiêm ngặt giữa <head> và </head>.
Nếu trong cấu trúc mã tồn tại các thẻ chưa đóng, ví dụ thẻ <script> trước meta description thiếu ký hiệu kết thúc </script>, hoặc khối <style> không được đóng đúng cách, trình phân tích cú pháp của Googlebot sẽ nảy sinh sai lệch phân tích.
Trong trường hợp này, trình phân tích cú pháp có thể cho rằng phần <head> đã kết thúc sớm và coi nhầm meta description tiếp theo là một phần của vùng <body>.
Do hệ thống lập chỉ mục của Google gán trọng số cực thấp cho thẻ <meta> bên trong <body> hoặc thậm chí bỏ qua, điều này sẽ dẫn đến việc trích xuất đoạn trích thất bại.
Giám sát dữ liệu cho thấy, trong các trang web thất bại khi kiểm tra cú pháp HTML, tỷ lệ mất meta description cao hơn 22% so với các trang web tuân thủ tiêu chuẩn.
| Vị trí và trạng thái cấu trúc thẻ | Tỷ lệ nhận diện thành công của Googlebot | Phân tích nguyên nhân kỹ thuật |
|---|---|---|
Trong vòng 100KB đầu tiên của <head> |
99.2% | Nằm trong vùng thu thập ưu tiên cao của trình phân tích, hầu như không bị ảnh hưởng bởi việc thực thi tập lệnh. |
| Nằm sau lượng lớn CSS nội tuyến (quá 1MB) | 12.5% | Vượt quá ngưỡng độ sâu quét siêu dữ liệu mặc định của Googlebot. |
Nằm sau vị trí bắt đầu của thẻ <body> |
5.8% | Vi phạm tiêu chuẩn W3C, trình phân tích coi đó là phân đoạn văn bản thông thường thay vì siêu dữ liệu. |
Tồn tại thẻ phía trên chưa đóng (như <title>) |
0.4% | Dẫn đến cấu trúc cây phân tích bị sụp đổ, meta description bị coi là nội dung con của thẻ phía trên. |
Nằm trước </html> ở cuối tài liệu |
0.1% | Trình thu thập thường đã hoàn thành việc trích xuất đoạn trích chỉ mục trước khi đến đây. |
Vị trí khai báo bảng mã ký tự (Charset Declaration) của tài liệu cũng ảnh hưởng đến việc phân tích meta description.
Theo khuyến nghị của Google, <meta charset="utf-8"> nên xuất hiện trong vòng 1024 byte đầu tiên của tài liệu.
Nếu khai báo bảng mã được đặt sau thẻ meta description, trình phân tích cú pháp khi đọc meta description có thể vẫn chưa xác định được định dạng bảng mã của trang.
Đối với nội dung mô tả chứa các ký tự không phải ASCII (như các ký hiệu đặc biệt hoặc ký tự đa ngôn ngữ), lỗi thứ tự này sẽ dẫn đến ký tự bị lỗi font (乱码).
Khi thuật toán của Google phát hiện nội dung meta description chứa một lượng lớn các ký tự lỗi không thể phân tích, hệ thống sẽ tự động lọc thẻ đó và trích xuất văn bản thuần có khả năng đọc cao hơn từ trang để thay thế.
Kết xuất JavaScript
Google xử lý mã nguồn gốc cực nhanh, nhưng khi xử lý các trang cần thực thi tập lệnh, thời gian chờ trong hàng đợi kết xuất dao động từ 24 giờ đến 14 ngày.
Nếu một trang sử dụng các khung như React, Vue hoặc Angular và nội dung meta description được tải theo thời gian thực thông qua các hook useEffect hoặc onMounted, Googlebot trong giai đoạn đầu thu thập tài liệu HTML sẽ chỉ chứa một thẻ <meta name="description" content=""> trống.
Lúc này, kho chỉ mục sẽ ghi lại giá trị trống này.
Ngay cả khi giai đoạn kết xuất sau đó trích xuất văn bản thành công, thời gian cập nhật hiển thị trang kết quả tìm kiếm cũng sẽ chậm hơn gấp 3 lần trở lên so với trang HTML thông thường.
Theo tài liệu kỹ thuật của công cụ kết xuất Chromium, WRS mô phỏng môi trường trình duyệt không đầu (headless) phiên bản Chrome 120 trở lên và gán hạn ngạch bộ nhớ 1024MB cho mỗi yêu cầu thu thập.
Nếu tổng dung lượng gói JavaScript mà trang tải vượt quá 5MB, hoặc quá trình khởi tạo tập lệnh liên quan đến hơn 20 yêu cầu API bên ngoài, trình kết xuất sẽ ngừng thực hiện các lệnh sửa đổi DOM tiếp theo do tiêu tốn quá nhiều tài nguyên.
Trong một thử nghiệm trên 50.000 trang web, các trang có thời gian thực thi tập lệnh vượt quá 5,5 giây có xác suất meta description được nhận diện chính xác giảm 62%.
Do giới hạn quy tắc phân bổ ngân sách thu thập của Google, đối với các trang web có trọng số thấp, nếu trình kết xuất không thể lấy được meta description trong lần thực thi đầu tiên, hệ thống sẽ có xu hướng trích xuất 160 ký tự đầu tiên từ thẻ <p> đầu tiên trong nội dung chính của trang làm đoạn trích.
| Giải pháp kỹ thuật kết xuất | HTML ban đầu có chứa meta description không | Độ trễ có hiệu lực chỉ mục Google | Rủi ro thất bại thực thi WRS |
|---|---|---|---|
| Kết xuất phía máy khách (CSR) | Không (chỉ có trình giữ chỗ) | 2 ngày đến 14 ngày | Cao |
| Kết xuất phía máy chủ (SSR) | Có (văn bản đầy đủ) | Có hiệu lực ngay lập tức | Thấp |
| Tạo trang tĩnh (SSG) | Có (văn bản đầy đủ) | Có hiệu lực ngay lập tức | Không |
| SEO tại biên (Cloudflare/AWS) | Có (chèn qua yêu cầu) | Có hiệu lực ngay lập tức | Thấp |
“Meta description phải ở trạng thái sẵn sàng ngay trong giai đoạn đầu của quá trình phân tích DOM, bất kỳ nội dung mô tả nào được điền sau khi yêu cầu không đồng bộ trả về đều phải đối mặt với rủi ro bị công cụ thu thập bỏ qua.”
Hiện tượng kỹ thuật này đặc biệt phổ biến trong các ứng dụng đơn trang (SPA).
Khi người dùng nhấp vào điều hướng trong trình duyệt, trang sẽ không tải lại, meta description được cập nhật thông qua history.pushState; nhưng đối với Googlebot, nó chỉ thu thập lối vào độc lập tương ứng với URL đó.
Nếu mã nguồn của lối vào đó không chứa meta description, chỉ dựa vào việc tạo thời gian thực của JavaScript ở phía máy khách, công cụ tìm kiếm sẽ nảy sinh sai lệch khi đánh giá mức độ liên quan của trang, từ đó dẫn đến nội dung đoạn trích không khớp với nội dung thực tế của trang web.
Xung đột Robots
Googlebot khi xử lý trang web sẽ ưu tiên tuân thủ các chỉ thị robots trong mã nguồn HTML hoặc tiêu đề phản hồi HTTP.
Nếu trong mã tồn tại các thẻ hạn chế cụ thể, ngay cả khi nhà phát triển viết nội dung chất lượng cao trong <meta name="description">, trang kết quả tìm kiếm (SERP) vẫn sẽ xử lý đoạn trích bằng cách chặn hoàn toàn hoặc cưỡng ép cắt bớt.
Xung đột này thường thấy nhất ở việc sử dụng thẻ nosnippet.
Theo quy định trong tài liệu chính thức của Google, một khi HTML của trang chứa <meta name="robots" content="nosnippet">, Google sẽ bị cấm hiển thị bất kỳ hình thức mô tả văn bản hoặc xem trước video nào cho trang đó.
Trong các cuộc kiểm tra trình thu thập đối với các trang web quy mô lớn, phát hiện thấy khoảng 2% số trang do giữ lại nhầm chỉ thị nosnippet từ môi trường thử nghiệm trong quá trình di chuyển mẫu, dẫn đến kết quả tìm kiếm trong môi trường sản xuất chỉ hiển thị tiêu đề và URL, mất hoàn toàn văn bản mô tả.
Ngoài chỉ thị cấm hoàn toàn, chỉ thị max-snippet cho phép nhà phát triển thiết lập độ dài ký tự tối đa của đoạn trích trong kết quả tìm kiếm.
Nếu mã được thiết lập là <meta name="robots" content="max-snippet:50">, trong khi độ dài meta description thiết lập sẵn là 150 ký tự, thuật toán Google trong hầu hết các trường hợp sẽ cho rằng 50 ký tự không thể mang lại đủ lượng thông tin, từ đó chọn không hiển thị mô tả đó, hoặc trích xuất ngẫu nhiên các câu ngắn trong trang khớp với giới hạn độ dài.
Khi giá trị này được thiết lập thành 0, hiệu quả kỹ thuật của nó tương đương với nosnippet.
Bảng dưới đây liệt kê các tham số chỉ thị phổ biến và tác động định lượng của chúng đối với việc hiển thị meta description:
| Tên chỉ thị | Ví dụ mã điển hình | Hiệu quả hạn chế đối với hiển thị meta description |
|---|---|---|
| nosnippet | content="nosnippet" |
Chặn 100%, không hiển thị bất kỳ đoạn trích văn bản nào. |
| max-snippet:0 | content="max-snippet:0" |
Hiệu quả tương đương nosnippet, hoàn toàn không hiển thị. |
| max-snippet:[number] | content="max-snippet:60" |
Chỉ hiển thị số lượng ký tự được chỉ định, nội dung quá dài sẽ bị bỏ đi. |
| indexifembedded | content="noindex, indexifembedded" |
Chỉ có thể hiển thị đoạn trích khi trang được nhúng vào nơi khác dưới dạng iframe. |
Xung đột mang tính loại trừ ở tầng kỹ thuật không chỉ giới hạn ở thẻ HTML, mà còn thường ẩn giấu trong tiêu đề phản hồi của giao thức HTTP, tức là X-Robots-Tag.
Do chỉ thị này không xuất hiện trong mã nguồn HTML, nhà phát triển không thể nhận ra khi “xem mã nguồn trang” qua trình duyệt.
Trong cấu hình máy chủ Nginx hoặc Apache, nếu thiết lập toàn cục X-Robots-Tag: nosnippet, thì tất cả các tệp PDF, hình ảnh hoặc trang động dưới máy chủ đó sẽ mất nội dung mô tả.
Để xác minh xem có tồn tại chỉ thị ẩn như vậy hay không, cần sử dụng lệnh curl -I [URL] để xem thông tin Header do máy chủ trả về.
Nếu trong Headers chứa X-Robots-Tag: noindex, Googlebot thậm chí sẽ không đưa trang vào kho chỉ mục, và lẽ tự nhiên là không thể trích xuất và hiển thị meta description.
Dưới tiêu chuẩn HTML 5, nhà phát triển có thể thêm thuộc tính này vào các thẻ <span>, <div> hoặc <section> để thông báo cho Google không sử dụng nội dung vùng đó cho đoạn trích tìm kiếm.
Nếu nội dung chính của một trang đều được đánh dấu data-nosnippet, trong khi vùng <head> lại tình cờ thiếu thẻ meta description hiệu quả, công cụ kết xuất của Google khi cố gắng trích xuất phân đoạn trang (Fragment) sẽ thấy không có nội dung khả dụng.
Xung đột logic này sẽ dẫn đến việc Google cưỡng ép thu thập thanh điều hướng trang, thông tin bản quyền chân trang hoặc các văn bản không liên quan khác chưa được đánh dấu làm mô tả thay thế.
- Xung đột chồng chéo nhiều chỉ thị: Khi trang đồng thời tồn tại
indexvànosnippet, Google sẽ áp dụng “nguyên tắc nghiêm ngặt nhất”, ưu tiên thực thinosnippet. - Hạn chế thiết lập mặc định của plugin CMS: Trong các trang web Shopify hoặc WordPress, một số plugin bảo mật để ngăn chặn nội dung bị thu thập sẽ tự động chèn
nosnippethoặcnoarchivevào các trang phi tiêu chuẩn (như trang kết quả tìm kiếm, trang thẻ), điều này sẽ ghi đè lên mô tả do plugin SEO điền thủ công. - Ảnh hưởng của chỉ thị hết hạn bộ nhớ đệm: Chỉ thị
unavailable_aftersẽ thiết lập một dấu thời gian cụ thể. Nếu thời gian hiện tại vượt quá giá trị thiết lập (ví dụunavailable_after: 2025-12-31), Google sẽ ngừng hiển thị bất kỳ đoạn trích nào của trang đó trong SERP.
Trong một số kiến trúc trang web đa quốc gia phức tạp, các nhà cung cấp dịch vụ CDN (như Cloudflare hoặc Akamai) có thể sửa đổi động tiêu đề phản hồi hoặc chèn HTML thông qua các tập lệnh Workers tại các nút biên.
Nếu vô tình thêm chỉ thị hạn chế robots ở cấp độ CDN, thì bất kể mã gốc của máy chủ phụ trợ hoàn hảo đến đâu, dữ liệu cuối cùng được đẩy tới Googlebot đều sẽ mang nhãn “cấm hiển thị đoạn trích”.
Nhóm kỹ thuật nên định kỳ sử dụng công cụ “Kiểm tra URL” của Google Search Console, kiểm tra thân phản hồi HTTP trong tab “URL đã yêu cầu” để đảm bảo không có bất kỳ chỉ thị tiêu cực nào chứa từ khóa snippet.
Google cho rằng việc tự động tạo ra của nó tốt hơn
Dựa trên phân tích dữ liệu của Ahrefs trên 192.000 trang, khi từ khóa tìm kiếm của người dùng không có trong meta description, tỷ lệ viết lại của Google cao tới 82,7%;
Ngay cả khi mô tả chứa từ khóa, xác suất viết lại vẫn duy trì ở mức 59,7%. Google có xu hướng tận dụng mô hình ngôn ngữ BERT để trích xuất các phân đoạn khoảng 160 ký tự từ nội dung chính trang theo thời gian thực, nhằm đảm bảo các từ khóa in đậm xuất hiện trong kết quả tìm kiếm.
Cách làm này có thể làm cho tỷ lệ nhấp (CTR) của kết quả tìm kiếm tăng từ 5% đến 10% về mặt thống kê, vì nó phản hồi ý định truy vấn thông qua các mục từ in đậm.
Viết lại bằng thuật toán
Khi trang web đi vào kho chỉ mục, thuật toán sẽ không cố định vĩnh viễn phương thức hiển thị meta description của nó.
Nếu văn bản mô tả thiết lập sẵn thiếu sự giao thoa ngữ nghĩa với từ khóa tìm kiếm do người dùng nhập, thuật toán sẽ trích xuất văn bản khoảng 160 ký tự từ nội dung chính của trang.
Hành vi trích xuất này thường xảy ra khi từ khóa tìm kiếm xuất hiện trong khoảng từ 200 đến 500 ký tự của nội dung chính, trong khi meta description lại hoàn toàn không đề cập đến từ đó.
Do mục tiêu của thuật toán là tối đa hóa hiệu quả nhấp chuột của kết quả tìm kiếm, nó sẽ ưu tiên chọn những phân đoạn văn bản chứa các từ khóa in đậm.
| Phân loại kịch bản kích hoạt | Xác suất viết lại thống kê | Mô tả logic phán đoán của thuật toán |
|---|---|---|
| Thiếu từ khóa tìm kiếm | 82.7% | Meta description không chứa từ truy vấn người dùng nhập, hệ thống chuyển sang tìm kiếm kết quả khớp trong nội dung chính. |
| Mô tả quá dài/quá ngắn | 65.4% | Độ dài vượt quá 960 pixel hoặc ngắn hơn 50 ký tự, bị đánh giá là hiệu quả truyền đạt thông tin thấp. |
| Tính lặp lại nội dung | 71.0% | Nhiều URL sử dụng cùng một mẫu mô tả, thuật toán bỏ qua thẻ đó và tự mình trích xuất nội dung độc đáo. |
| Ngữ nghĩa không khớp | 58.2% | Nội dung mô tả thuộc về lời quảng bá thương hiệu, trong khi từ truy vấn thuộc về tìm kiếm thông số kỹ thuật cụ thể. |
Không gian hiển thị của trình duyệt máy tính thường giới hạn trong vòng 920 pixel, trong khi di động giảm xuống còn khoảng 600 pixel.
Nếu độ dài của meta description đạt tới 1000 pixel, hệ thống hiển thị phía trước của Google sẽ cố gắng cắt bớt trước, nhưng nếu câu sau khi cắt bớt bị rời rạc về ngữ nghĩa, thuật toán tạo đoạn trích phía sau sẽ đánh giá meta description đó là “đầu ra chất lượng thấp”.
Lúc này, hệ thống sẽ gọi nội dung thẻ <h1> hoặc <p> bên trong trang, tìm kiếm một câu có thể diễn đạt đầy đủ ý nghĩa trong số pixel giới hạn để thay thế.
| Loại truy vấn | Xu hướng viết lại | Nguồn thay thế điển hình |
|---|---|---|
| Truy vấn thông tin | Cao | Đoạn văn mang tính định nghĩa hoặc danh sách FAQ ở đầu trang. |
| Truy vấn điều hướng | Thấp | Thường giữ lại mô tả thiết lập sẵn, đặc biệt là khi chứa tên thương hiệu. |
| Truy vấn giao dịch | Trung bình | Phân đoạn nội dung chính chứa giá cả, quy cách hoặc dòng chữ “giao hàng miễn phí”. |
| Truy vấn từ đuôi dài | Cực cao | Câu đầu tiên phía dưới tiêu đề H2 khớp với từ đuôi dài cụ thể. |
Đối với cùng một URL, Google có thể tạo ra hàng trăm loại đoạn trích khác nhau.
Ví dụ, khi một trang về “Cẩm nang chọn mua dịch vụ đám mây” xếp hạng dưới hai từ khóa có ý định khác nhau là “So sánh giá dịch vụ đám mây” và “Kiểm tra tính an toàn dịch vụ đám mây”, meta description tĩnh rất khó bao phủ đồng thời cả hai khía cạnh này.
Cơ chế viết lại động của Google sẽ phân tích cấu trúc nội dung chính của trang, nếu phát hiện trong trang có một bảng liệt kê chi tiết giá cả, thuật toán sẽ tự động trích xuất văn bản gần bảng đó làm đoạn trích khi người dùng tìm kiếm “giá cả”.
Nếu nội dung chính của trang web thiếu cấu trúc đoạn văn logic rõ ràng, thuật toán có thể trích xuất menu điều hướng, văn bản chân trang hoặc các liên kết thanh bên, từ đó tạo ra một đoạn trích tìm kiếm hoàn toàn thiếu logic, điều này thường do trang web thiếu mật độ văn bản nội dung chính hiệu quả gây ra.
Khi xử lý các trang chứa một lượng lớn quy cách kỹ thuật hoặc thuộc tính sản phẩm, nếu trang sử dụng đánh dấu Schema của Product hoặc Review, nhưng meta description không thể hiện các thuộc tính then chốt này, Google thường sẽ viết lại mô tả để bao gồm điểm số, giá cả hoặc trạng thái kho hàng.
Nếu meta description chỉ là “Xem bộ sưu tập giày thể thao mới nhất của chúng tôi”, trong khi nội dung chính có các dữ liệu cụ thể như “Điểm chống mài mòn 9.5” hoặc “Trọng lượng 250g”, thuật toán sẽ đánh giá cái sau có giá trị tham khảo hơn cho người dùng.
Để duy trì việc hiển thị mô tả thiết lập sẵn, phải đảm bảo mật độ thông tin trong mô tả không thấp hơn mức trung bình của 300 ký tự đầu tiên trong nội dung chính.
Giảm thiểu việc bị viết lại
Nếu meta description thiết lập sẵn không chứa ba từ khóa tìm kiếm hàng đầu của trang đó, xác suất Google tự động viết lại sẽ tăng lên hơn 80%.
Để giảm thiểu sự can thiệp này, nên lồng ghép một cách tự nhiên các từ vựng tần suất cao được xuất ra từ GSC vào 65 ký tự đầu tiên của mô tả.
Trong thao tác cụ thể, cần duy trì sự nhất quán cao về ngữ nghĩa giữa nội dung mô tả với thẻ H1 của trang và đoạn đầu của nội dung chính.
Khi viết, nên tránh sử dụng các từ ngữ quảng bá mơ hồ, thay vào đó sử dụng các câu trần thuật chứa các thông số cụ thể, tên thương hiệu hoặc các lệnh hành động rõ ràng.
- Kiểm soát chính xác ký tự và pixel: Giới hạn trên của chiều rộng hiển thị kết quả tìm kiếm trên máy tính để bàn là khoảng 920 đến 960 pixel, trên di động là từ 600 đến 680 pixel. Do các ký tự khác nhau chiếm số pixel khác nhau, việc chỉ thống kê số lượng ký tự là không chính xác. Khuyến nghị tận dụng các công cụ kiểm tra pixel để đảm bảo mô tả kết thúc trong vòng 920 pixel, ngăn ngừa việc thông tin không đầy đủ do bị cắt bớt ở cuối, vì các câu không hoàn chỉnh thường bị thuật toán đánh giá là hiển thị chất lượng thấp, từ đó kích hoạt việc viết lại tự động.
- Loại bỏ nội dung mẫu lặp lại: Khi xử lý các trang web thương mại điện tử lớn có hàng nghìn trang, tránh việc dùng chung một mẫu meta description cho toàn trang. Nếu mô tả của một lượng lớn URL chỉ có sự khác biệt nhỏ, công cụ thu thập của Google sẽ bỏ qua các thẻ này, cho rằng chúng thiếu tính mục tiêu. Khuyến nghị viết thủ công các mô tả duy nhất cho các trang có lưu lượng truy cập cao, còn đối với các trang đuôi dài, nên đảm bảo các phân đoạn do chương trình tạo ra có đủ khả năng nhận diện.
- Lựa chọn động từ phù hợp với ý định tìm kiếm: Đối với các truy vấn thông tin (Informational Queries), phần đầu mô tả nên sử dụng các từ dẫn dắt như “Tìm hiểu”, “So sánh” hoặc “Khám phá”; đối với các truy vấn giao dịch (Transactional Queries), nên bao gồm các từ cụ thể như “Mua”, “Tải về” hoặc “Giá cả”. Việc điều chỉnh giọng điệu của mô tả cho khớp với phong cách của các kết quả xếp hạng cao khác trong SERP có thể duy trì tỷ lệ giữ lại mô tả một cách hiệu quả.
Trong các cuộc kiểm tra SEO thực tế, phát hiện thấy nhiều trang web mặc dù đã thiết lập meta description, nhưng nội dung lại có sai lệch so với chủ đề chính mà trang thảo luận.
Ví dụ, một trang về “Giày chạy bộ tốt nhất”, nhưng meta description lại đang thảo luận về lịch sử của thương hiệu đó, sự rời rạc về ngữ nghĩa này sẽ dẫn đến việc thuật toán can thiệp.
Thiết kế meta description thành một bản tóm tắt chính xác về nội dung trang và bao gồm 2 đến 3 từ khóa đuôi dài có thể nâng cao đáng kể tần suất hiển thị của nó trong kết quả tìm kiếm.
Cần lưu ý tránh các ký tự đặc biệt trong HTML, một số ký hiệu chưa được thoát (unescaped) có thể dẫn đến lỗi phân tích, khiến Google không thể đọc được toàn bộ nội dung meta description, từ đó chọn trích xuất các phân đoạn ngẫu nhiên từ các đoạn văn bản.
- Logic tối ưu hóa dựa trên dữ liệu: Định kỳ kiểm tra sự biến động của CTR trong GSC. Nếu thứ hạng trung bình của một trang không đổi nhưng CTR xuất hiện mức sụt giảm trên 3%, cần kiểm tra xem đoạn trích trong SERP có bị viết lại hay không. Nếu phát hiện nội dung sau khi viết lại chủ yếu đến từ phần FAQ của trang, điều đó cho thấy meta description ban đầu không bao quát được thắc mắc của người dùng, lúc này nên tham khảo phân đoạn sau khi viết lại để điều chỉnh lại cấu trúc logic của meta description.
- Phân bổ trọng số ngữ nghĩa: Đặt thông tin quan trọng nhất ở phía trước câu. Nghiên cứu cho thấy công cụ thu thập của Google chú ý đến phần đầu của meta description cao hơn nhiều so với phần cuối. 50 ký tự đầu tiên nên có thể diễn đạt độc lập tuyên bố giá trị chính của trang.
- Tránh sử dụng quá mức các dấu câu: Quá nhiều dấu chấm than hoặc các dấu chấm lửng liên tiếp sẽ làm giảm tính chuyên nghiệp của mô tả, thuật toán sẽ có xu hướng chặn loại nội dung mang đặc trưng thông tin rác này. Duy trì cấu trúc câu bình dị, trung tính, phù hợp với quy phạm diễn đạt thông tin học thuật hoặc chuyên nghiệp.
Khi xử lý dữ liệu có cấu trúc (Schema Markup), nếu trang sử dụng cấu trúc FAQ hoặc Product, meta description nên đóng vai trò kết nối và thông báo trước, chứ không phải là lặp lại hoàn toàn với nó.
Đối với các trang chứa một lượng lớn quy cách kỹ thuật, hãy thử thêm các dữ liệu số cụ thể vào mô tả, như “Trọng lượng chỉ 1.2kg” hoặc “Hỗ trợ độ phân giải 4K”.


