




















GSC-URL-Prüfung
Geben Sie die URL in die Search Console ein, klicken Sie auf “Gecrawlte Seite anzeigen”, vergleichen Sie den HTML-Quellcode und bestätigen Sie, ob Kerninhalte nach dem Rendering verschwinden.
Textdifferenz-Vergleich
Vergleichen Sie die Anzahl der Textzeichen in “Seitenquelltext anzeigen” mit “Element untersuchen”. Wenn die Textdifferenzrate > 20 % beträgt, besteht ein extrem hohes Risiko für die Indexierung.
Test auf reiche Suchergebnisse (Rich Results Test)
Verwenden Sie das Google-Tool für Tests auf reiche Suchergebnisse, um den Screenshot zu prüfen und sicherzustellen, dass die kritischen Inhalte “Above the Fold” innerhalb des 5-Sekunden-Rendering-Fensters vollständig geladen werden.
Offizielle Google-Tools
Das URL-Prüfungstool in der Google Search Console (GSC) ist das Portal, um den Live-Status des Googlebot-Crawlings abzurufen.
Durch “Live-URL testen” kann innerhalb von 60-90 Sekunden der WRS (Web Rendering Service) aufgerufen werden, um die vollständige DOM-Struktur zu generieren.
Die GSC liefert das gerenderte HTML, einen Screenshot sowie eine Liste der geladenen Ressourcen.
Derzeit verwendet der Googlebot den neuesten stabilen Chrome-Kernel, setzt jedoch einen Schwellenwert von ca. 5 Sekunden für die Skriptausführung auf einer einzelnen Seite fest.
In Kombination mit dem “Test auf reiche Suchergebnisse” lassen sich Byte-Unterschiede zwischen der ursprünglichen Antwort und dem endgültigen Rendering-Ergebnis vergleichen sowie Skript-Ladefehler (403 oder 404) identifizieren, die durch Blockaden in der Robots.txt verursacht werden.
Google Search Console
Wenn Sie in der Seitenleiste der Google Search Console eine spezifische URL eingeben, ruft das System einen Schnappschuss der letzten Crawling-Daten aus der Google-Indexdatenbank ab.
Falls der Seitenstatus “URL ist auf Google” anzeigt, können Sie sehen, ob zum Zeitpunkt des Crawlings HTML-Parsing-Fehler oder Probleme mit der mobilen Optimierung vorlagen.
Um tiefergehend zu untersuchen, ob Inhalte aufgrund von JavaScript-Rendering fehlen, müssen Sie auf die Schaltfläche “Live-URL testen” klicken.
Dieser Vorgang veranlasst den WRS (Web Rendering Service), einen Headless-Browser auf Basis des neuesten stabilen Chromium-Kernels zu starten, um die Zielseite in Echtzeit aufzurufen.
Beim Rendering setzt der WRS die Viewport-Breite auf 1280 Pixel fest und verfolgt eine Mobile-First-Crawling-Strategie.
Im Bereich “Gerenderte Seite anzeigen” zeigt der HTML-Tab die vollständige DOM-Struktur nach Ausführung der Skripte an.
Techniker sollten die hier angezeigte Anzahl der HTML-Zeilen oder Byte-Mengen quantitativ mit dem “Seitenquelltext” (ursprüngliche Serverantwort), der über den Rechtsklick im Browser einsehbar ist, vergleichen.
Wenn das ursprüngliche HTML nur 2 KB groß ist, das gerenderte HTML jedoch auf 50 KB anwächst, deutet dies darauf hin, dass die Seite stark vom Client-Side-Rendering abhängt.
Falls im gerenderten HTML der Haupttext oder Produktlisten-Tags fehlen, wird dies als Rendering-Fehler eingestuft.
Der Googlebot weist der Skriptausführung auf einer einzelnen Seite begrenzte Rechenressourcen zu. Obwohl es offiziell keine absolute Frist gibt, zeigen zahlreiche Experimente, dass bei einer Ladezeit von über 5 Sekunden die Wahrscheinlichkeit massiv steigt, dass dieser Teil der Daten in der Indexierungsphase ausgelassen wird.
“Der Googlebot wartet nicht unbegrenzt darauf, dass JavaScript alle asynchronen Aufgaben abschließt. Sein Rendering-Budget ist durch die Ladegeschwindigkeit der Seite, die Server-Antwortverzögerung (TTFB) und die Komplexität des Skript-Parsings begrenzt. Wenn die API-Antwortzeit 2000 Millisekunden überschreitet, führt dies oft dazu, dass Inhalte im Moment der Screenshot-Erstellung noch im Ladezustand verbleiben.”
Im Tab “Weitere Informationen” unter “Seitenressourcen” werden alle JS- und CSS-Dateien aufgelistet, die nicht geladen werden konnten.
Statuscodes wie 403 oder 404 deuten klar auf Fehlkonfigurationen der Serverberechtigungen oder ungültige Ressourcenpfade hin. Besondere Aufmerksamkeit verdient jedoch der Status “Durch Robots.txt blockiert”.
Da viele Single-Page-Applications (SPA) die Routing- und Rendering-Logik in spezifischen Skriptdateien kapseln, kann der WRS keinen vollständigen DOM-Baum aufbauen, wenn die /robots.txt Regeln wie Disallow: /assets/ enthält, die den Zugriff auf Hauptskripte verhindern.
Das Ergebnis ist, dass die Seite in der Sicht des Crawlers leer sein oder nur das Basis-Framework enthalten kann, selbst wenn sie für Benutzer im Browser vollständig erscheint.
Die Fehlersuche bei Skripten sollte sich auf den Bereich “JavaScript-Konsolennachrichten” konzentrieren.
Hier werden Ausnahmen protokolliert, die der WRS während der Codeausführung ausgibt.
Wenn das Entwicklungsteam neue ES6+-Features ohne Polyfills verwendet (wie BigInt, ResizeObserver usw.) und die entsprechende Chromium-Version zum Zeitpunkt des Crawlings bestimmte nicht-standardisierte APIs noch nicht unterstützt, erscheinen in der Konsole Fehler wie Uncaught ReferenceError oder SyntaxError.
Solche Fehler führen zum Abbruch des gesamten Skript-Parsing-Prozesses, wodurch die gesamte nachfolgende Inhaltsinjektion fehlschlägt.
Durch die Beobachtung der in den Fehlerprotokollen genannten Zeilennummern und Dateinamen lässt sich präzise lokalisieren, welche Bibliotheksdatei oder welcher Logikblock das Crawling behindert.
Der gerenderte “Screenshot” ist ein weiteres quantitatives Prüfmittel.
Beispielsweise berechnen manche Skripte die Höhe oder Transparenz von Elementen dynamisch. Wenn der Screenshot große weiße Flächen zeigt, könnte der Google-Algorithmus die Seite als nutzerunfreundlich einstufen und die Indexierungspriorität senken, selbst wenn Text in den HTML-Tags vorhanden ist.
Bei hochdynamischen Websites muss sichergestellt werden, dass alle Inhalte “Above the Fold” innerhalb von 2 Sekunden fertig gerendert sind.
Test auf reiche Suchergebnisse
Das Tool für Tests auf reiche Suchergebnisse ist eine öffentliche Testumgebung von Google. Im Gegensatz zur Search Console, die eine Bestätigung der Inhaberschaft erfordert, ermöglicht dieses Tool jedem die Analyse beliebiger URLs oder eingefügter Code-Snippets.
Nach Eingabe der URL und Start des Tests wird ein Headless-Browser auf Basis des neuesten stabilen Chromium-Kernels gestartet, der den Zugriff eines Googlebot Smartphone oder Googlebot Desktop simuliert.
Für Single-Page-Applications (SPA), die stark auf JavaScript-Frameworks wie React, Angular oder Vue.js setzen, ist die Funktion “Getestete Seite anzeigen” der Standard, um zu beurteilen, ob Inhalte erfolgreich in den DOM-Baum gelangt sind.
Da der Googlebot beim Verarbeiten von Skripten ein Ressourcenlimit hat, kann es sein, dass der WRS das HTML-Crawling beendet, bevor die Skripte fertig ausgeführt sind, falls die Seite in der Initialisierungsphase massive Berechnungen durchführt oder mehr als 20 asynchrone API-Anfragen stellt.
Bei der Echtzeitprüfung generiert das System einen Schnappschuss des gerenderten HTML.
Anhand dieses Schnappschusses können Techniker die Byte-Differenz zwischen der ursprünglichen Serverantwort und dem endgültigen Rendering genau vergleichen.
Beispielsweise hat eine reine Client-Side-Rendering (CSR) Seite oft nur weniger als 5 KB Basiscode im ursprünglichen HTML. Wenn das gerenderte HTML über 100 KB erreicht, bedeutet dies, dass der Googlebot die Skripte erfolgreich ausgeführt und dynamische Inhalte geladen hat.
Bleibt das gerenderte HTML hingegen bei etwa 5 KB ohne die Hauptinhalte, wurde die Skriptausführung auf WRS-Ebene unterbrochen.
Die Google-Rendering-Engine hat strikte Timeouts für den Download einzelner Ressourcen; normalerweise sollte die Ladezeit einer einzelnen JS-Datei 2000 Millisekunden nicht überschreiten.
Wenn referenzierte Drittanbieter-Bibliotheken oder APIs zu langsam antworten, markiert der Tab “Seitenressourcen” im Testergebnis den entsprechenden Fehlerstatus.
- Code-Snippet-Testmodus: Unterstützt das Einfügen von unveröffentlichtem HTML-Code. Dies ist entscheidend, um in der Staging-Phase zu prüfen, ob die JS-Rendering-Logik den Crawling-Standards entspricht. So kann vor dem Mergen des Codes geprüft werden, ob dynamisch generierte Schema-Markups korrekt erkannt werden.
- User-Agent-Simulation: Standardmäßig wird mit dem Smartphone-Crawler getestet. Bei komplexer responsiver Logik kann jedoch das Umschalten auf Desktop-Geräte aufzeigen, wie die CSS-Ladepriorität die JS-Ausführungsreihenfolge beeinflusst.
- Rendering-Schnappschuss-Vergleich: Die bereitgestellten Screenshots dienen nicht nur der visuellen Referenz, sondern helfen auch zu beurteilen, ob “Content-Shift” oder Layout-Instabilitäten auftreten, da massive Layoutänderungen dazu führen können, dass der Googlebot die Nutzbarkeit der Seite falsch bewertet.
“Der Test auf reiche Suchergebnisse validiert nicht nur strukturierte Daten, sondern ist ein Labor für die Sichtbarkeit dynamischer Inhalte. Wenn Texte asynchron über JS geladen werden, ist die Suche nach diesem Text in ‘Getestete Seite anzeigen’ der schnellste Weg, um die Erfolgsrate der SEO-Indexierung zu verifizieren.”
Wenn eine Seite über Skripte injiziertes JSON-LD oder Microdata enthält, extrahiert das Tool diese strukturierten Informationen aus dem gerenderten DOM.
Falls Syntaxfehler vorliegen oder das Skript vor der Injektion der Schema-Markups aufgrund eines Fehlers stoppt, meldet das Tool “Keine reichen Suchergebnisse erkannt”.
Dies ist besonders wichtig für E-Commerce- oder Bewertungsportale, da Google Preise, Lagerstatus und Bewertungen beim Indexieren erkennen muss.
Fehlen diese Attribute im HTML der “Getesteten Seite”, werden in den Suchergebnissen (SERP) keine Sterne oder Preisvorschauen angezeigt, selbst wenn das Frontend für Benutzer normal aussieht.
Besonderes Augenmerk sollte auf die Konsolenfehler gelegt werden, da der Speicherbedarf in der WRS-Umgebung strenger limitiert ist als in einem normalen Benutzerbrowser.
Wenn ein Skript zu viel CPU-Ressourcen verbraucht, bricht der Googlebot das Rendering unter Umständen ab und behält nur ein leeres Template im Index.
- Gesamtzahl der geladenen Ressourcen: Es wird empfohlen, die JS-Ressourcen pro Seite auf unter 50 zu begrenzen. Zu viele parallele Anfragen führen zu WRS-Verzögerungen und erhöhen das Risiko von Rendering-Fehlern.
- Überwachung von Skriptfehlern: Das Tool erfasst fatale Ausnahmen wie
ReferenceErroroderTypeError. Wenn Inkompatibilitäten aufgrund fehlender Polyfills für ES-Standards auftreten, sollte das Build-Tool angepasst werden. - Gültigkeit der API-Antworten: Prüfen Sie alle API-Endpunkte für dynamische Inhalte. Status wie “Blockiert” oder “Timeout” bedeuten, dass der Googlebot von einer Firewall aufgehalten wird oder die API-Performance nicht ausreicht.
Jede “Warnung” oder jeder “Fehler” im Bericht spiegelt das Verhalten des Googlebots in der realen Indexierungsumgebung wider.
Wenn das Tool meldet, dass bestimmte Skripte nicht geladen werden konnten, muss dies ernst genommen werden, auch wenn sie im normalen Chrome-Browser funktionieren. Es könnte sein, dass die Crawler-IPs von Google einer Ratenbegrenzung (Rate Limiting) durch den Server unterliegen.
Chrome DevTools
In der lokalen Entwicklungsumgebung ist das Panel “Netzwerkbedingungen” (Network conditions) in den Chrome DevTools der Ausgangspunkt, um das Verhalten des Googlebots zu simulieren.
Öffnen Sie die Tools mit F12, gehen Sie über das Drei-Punkt-Menü oben rechts zu More tools -> Network conditions.
Deaktivieren Sie “Browser-Standardeinstellungen verwenden” (Use browser default) und wählen Sie manuell “Googlebot” aus der Liste aus.
Dies ändert den User-Agent-String des Browsers (z. B. in Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)).
Dies dient dazu, zu prüfen, ob der Server eine spezielle Logik für Crawler implementiert hat.
Falls der Server je nach UA unterschiedlichen HTML-Code ausliefert, wird die lokale Umgebung sofort ein anderes Ergebnis als bei einem normalen Zugriff zeigen.
Techniker sollten die Header-Informationen vergleichen und prüfen, ob sich der Content-Type oder die Cache-Control-Anweisungen geändert haben.
Falls der Server dem Googlebot ein 403 (Verboten) oder ein unerwartetes 301 (Redirect) sendet, wird die Indexierung bereits auf Serverebene blockiert.
Um die “erste Indexierungswelle” (First-wave indexing) des Googlebots zu simulieren, muss die Seite mit deaktiviertem JavaScript getestet werden.
Gehen Sie in die Einstellungen (Settings) der DevTools, suchen Sie unter “Präferenzen” den Bereich “Debugger” und aktivieren Sie “JavaScript deaktivieren” (Disable JavaScript).
Nach einem Refresh zeigt der Browser nur noch die vom Server gelieferte ursprüngliche HTML-Struktur an.
Bei SPAs führt dies oft zu einer komplett weißen Seite oder nur einer Lade-Animation.
Verschwinden Haupttexte, Navigationsmenüs oder Produktlisten bei deaktiviertem Skript, muss die Suchmaschine die komplexe “zweite Indexierungswelle” (WRS-Rendering) durchlaufen, um Inhalte zu erfassen.
Notieren Sie die Byte-Zahl des ursprünglichen HTML (z. B. 15 KB Basiscode) und vergleichen Sie diese mit dem vollständig gerenderten DOM, um das Ausmaß der JS-Injektionen zu bestimmen.
“In der lokalen Simulation ist das Deaktivieren von JavaScript der effektivste Stresstest. Wenn im ursprünglichen HTML einer Seite H1-Tags oder Textabschnitte mit wichtigen semantischen Informationen fehlen, ist das Risiko extrem hoch, dass die Seite bei Netzschwankungen oder knappen Rendering-Budgets als leere Seite indexiert wird.”
Die Umgebung des Googlebots ist kein Hochleistungsrechner. Mit dem “Performance”-Panel der DevTools lässt sich die Rechenleistung des Googlebots realistischer simulieren.
Stellen Sie unter den Performance-Einstellungen die CPU-Drosselung (CPU Throttling) auf 4-fache oder 6-fache Verlangsamung (4x or 6x slowdown) ein.
Wenn eine Rendering-Aufgabe auf einem MacBook 800 ms dauert, bei 6-facher Drosselung jedoch auf 5500 ms ansteigt, berührt dies bereits den typischen 5-Sekunden-Schwellenwert des Googlebots.
Anhand von “Long Tasks” im Flame-Graph lässt sich erkennen, welche großen JS-Bibliotheken den Hauptthread blockieren und das Rendering verzögern.
Eine Total Blocking Time (TBT) von über 2000 ms in dieser Umgebung deutet darauf hin, dass der Googlebot möglicherweise nicht auf die vollständige Generierung wartet, sondern einen unvollständigen DOM-Schnappschuss erfasst.
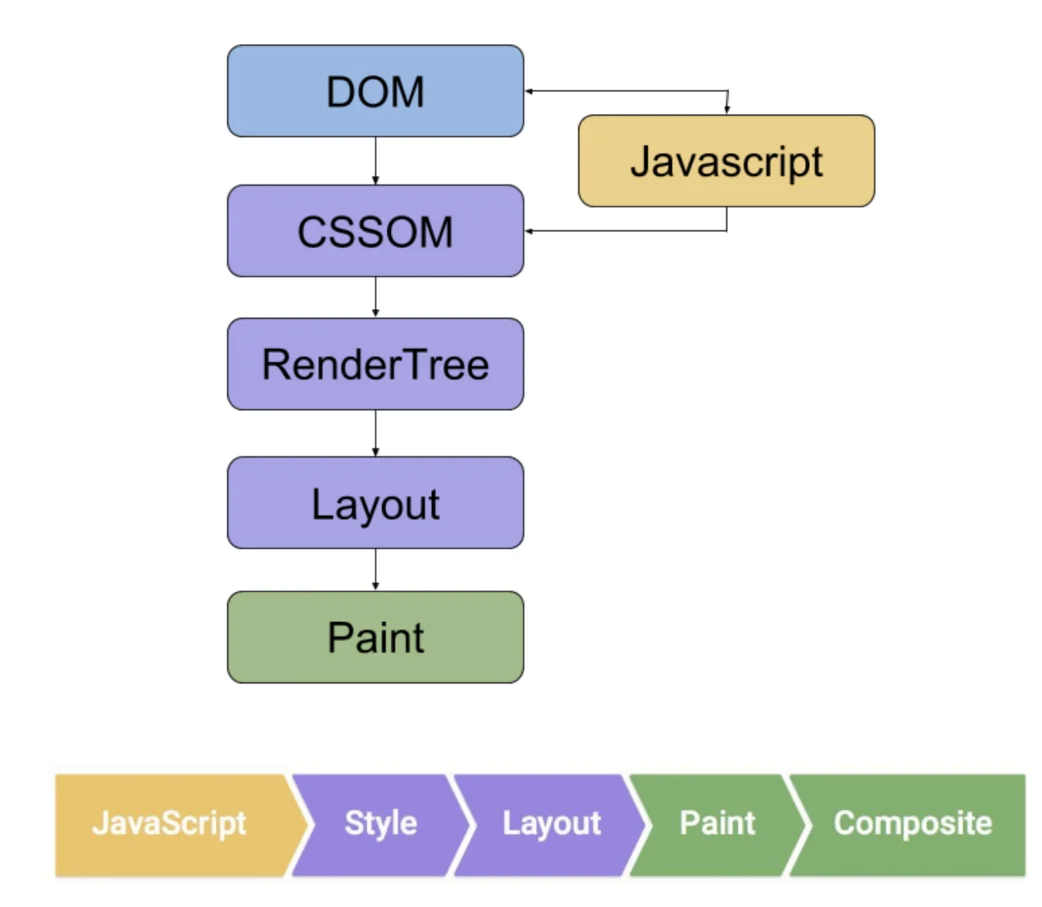
Manuelle Browser-Validierung
Die manuelle Validierung bestätigt den Rendering-Status durch den Vergleich der Datendifferenz zwischen Initial HTML und Rendered DOM.
Der Googlebot nutzt die neueste Chrome-Engine. Wenn jedoch die JS-Ausführung den 5-Sekunden-Schwellenwert überschreitet oder mehr als 50 Ressourcenanfragen pro Seite gestellt werden, können Inhalte unter Umständen nicht indexiert werden.
Bei manuellen Tests sollte die Ressourcen-Ladekette beachtet werden. Stellen Sie sicher, dass das href-Attribut von <a>-Tags im HTML-Quellcode vorhanden ist und nicht dynamisch über onclick-Events generiert wird, um die Erreichbarkeit für Crawler zu garantieren.
Quellcode vs. Echtzeit-DOM
Der über view-source im Browser angezeigte Code spiegelt den ursprünglichen Textstrom vom Server wider, während das Elements-Panel der Entwicklertools das Speicherobjektmodell (DOM) zeigt, nachdem es von der Rendering-Engine verarbeitet, Skripte ausgeführt und Fehler korrigiert wurden.
Bei SPAs enthält der ursprüngliche Quellcode oft nur einen leeren Container wie id="app" oder id="root" sowie Skriptreferenzen mit einer Gesamtgröße von über 500 KB.
Wenn das Verhältnis der Textzeichen im Quellcode zu denen im gerenderten DOM 1:20 überschreitet (z. B. 100 Wörter im Original vs. 2000 Wörter gerendert), kann die erste Crawling-Welle kaum semantische Informationen erfassen.
Dies führt dazu, dass die Seite initial in einem Inhalts-Vakuum verbleibt und auf die zweite Verarbeitung in der Rendering-Warteschlange warten muss.
| Vergleichsdimension | Initial HTML (Datenmerkmale) | Rendered DOM (Datenmerkmale) | Auswirkung auf die Indexierung |
|---|---|---|---|
| DOM-Knoten gesamt | Meist < 50 Knoten, flache Struktur. | Oft > 1500 Knoten, tiefere Hierarchie. | Massive Zunahme zeigt Abhängigkeit von JS. |
| Status der Meta-Tags | Generische Titel oder Platzhalter. | Seitenspezifische SEO-Tags via Skript. | Crawler könnten initial falsche Metadaten erfassen. |
| Canonical-Tag | Fehlt oder zeigt auf die Startseite. | Dynamisch auf die absolute URL aktualisiert. | Inkonsistenzen führen zu Parsing-Konflikten. |
| JSON-LD Daten | Leer oder nur Basis-Framework. | Vollständige Produkt-/Preisdaten vorhanden. | Bestimmt die Anzeige von Rich Snippets in SERPs. |
| Interne Links | Navigationsleiste oft leer. | Vollständige <a>-Tags vorhanden. |
Beeinflusst die Effizienz beim Finden tiefer URLs. |
Ein tiefergehender Vergleich kann über die Konsole mit document.body.innerText.length erfolgen, um die aktuelle Zeichenzahl mit der Byte-Größe der Quellcodedatei abzugleichen.
Wenn die Quelldatei 30 KB groß ist, der innerText nach dem Rendering jedoch 15.000 Zeichen erreicht, liegt das Hauptgewicht der Inhalte in der Rendering-Ebene.
Falls hierbei eine Funktion mehr als 200 ms benötigt oder externe APIs länger als 2,0 s zum Laden brauchen, stoppt die Googlebot-Engine die Aufzeichnung möglicherweise vorzeitig.
| Quantitative Metrik | Risikoschwellenwert | Folgen für Crawling & Indexierung |
|---|---|---|
| Text Ratio Gap | > 80 % des Textes via JS generiert | Hohes Risiko für “Thin Content” Einstufung ohne JS. |
| Link-Extraktionsrate | < 5 valide <a>-Tags im Quellcode |
Crawl-Budget wird durch Warten verschwendet. |
| Speicherbedarf Skripte | > 50 MB Heap-Speicherverbrauch | Rendering-Server könnte Task wegen Memory-Limits abbrechen. |
| HTML-Vollständigkeit | < 10 % Hauptinhalt im Quellcode sichtbar | Lange White-Screen-Zeiten schaden Ranking-Signalen. |
Prüfen Sie im Elements-Panel die Navigationsmenüs. Ein Link wie <a href="javascript:void(0)" onclick="navigateTo('/page')"> sieht zwar aus wie ein Link, ist für Crawler jedoch eine Sackgasse.
Standard-href-Attribute müssen bereits im ursprünglichen HTML existieren oder nach der Skriptausführung als Standard-<a href="/ziel-pfad"> vorliegen.
Websites mit vollständigen Linkstrukturen im ursprünglichen HTML werden oft 40 % bis 70 % schneller indexiert als solche, die rein auf JS-Injektionen setzen.
Falls im Quellcode ein noindex-Tag vorhanden ist, den ein Skript später in index ändern möchte, ist dies meist wirkungslos. Suchmaschinen priorisieren in der Regel die Anweisungen aus dem initialen HTML.
Validierung der Umgebungssimulation
Öffnen Sie die DevTools in Chrome, nutzen Sie Ctrl+Shift+P und geben Sie “Disable JavaScript” ein. Dies simuliert den ersten Crawling-Zustand.
Laden Sie die Seite neu. Bleibt der Bildschirm leer, enthält das Initial HTML keine substanziellen Inhalte.
Wenn bei einer 100 KB HTML-Datei 90 % des Inhalts von einem 2 MB JS-Paket abhängen, wird bei Netzwerkfehlern höchstwahrscheinlich nur ein leerer Container indexiert.
| Simulationsparameter | Standardwert | Beobachtung & Indikatoren |
|---|---|---|
| Network Throttling | Fast 3G (1.5 Mbps, 40ms Latenz) | Rendering > 5000 ms führt oft zum Abbruch durch Google. |
| CPU Throttling | 4x slowdown (Mobiler Prozessor) | Script Evaluation > 1.5 s verzögert das Rendering kritisch. |
| User-Agent Simulation | Googlebot Smartphone | Prüfen auf 403-Fehler oder spezifische Mobil-Adaptionen. |
| Viewport-Größe | 411 x 731 Pixel (Standard Mobil) | Inhalt muss ohne Interaktion (Klick/Scroll) laden. |
Ändern Sie den User-Agent auf den aktuellen Googlebot-String und aktivieren Sie “Disable cache” im Network-Panel, um die Ladekette unter Googlebot-Identität zu beobachten.
Im Standard-Prozess lädt der Googlebot oft nicht alle Mediendateien, sondern priorisiert Text und strukturierte Daten.
Falls die Seite je nach UA andere Logiken ausführt (z. B. APIs für Crawler sperrt), unterscheidet sich das DOM im Elements-Panel drastisch von der User-Ansicht.
Googlebot-Server verfügen über begrenzte Ressourcen. Nutzen Sie das Performance-Panel, um den Hauptthread (Main) zu analysieren.
Wenn “Evaluate Script” Aufgaben (Long Tasks) länger als 50 ms dauern und 70 % des Ladezyklus einnehmen, wird in der Realität oft ein unvollständiger Schnappschuss erstellt.
Ein Intervall zwischen First Contentful Paint (FCP) und Largest Contentful Paint (LCP) von mehr als 3 Sekunden erhöht die Chance auf eine unvollständige Indexierung um etwa 40 %.
Nutzen Sie den Tab Sensors, um Standorte wie San Francisco zu simulieren. Googlebot-Knoten sitzen primär in den USA; IP-basierte Weiterleitungen könnten dazu führen, dass eine falsche Sprachversion indexiert wird.
Prüfen Sie Konsolenfehler wie ReferenceError oder TypeError. Da die Google-Engine (Evergreen Googlebot) zwar aktuell ist, aber bei ganz neuen Web-APIs (wie WebGPU) Unterschiede aufweisen kann, führt fehlende Polyfill-Kompatibilität zum Skriptabbruch.
- Anzahl der Anfragen: Halten Sie die Anfragen für JS/CSS unter 50. Zu viele parallele Requests führen zu Verzögerungen.
- Shadow DOM: Prüfen Sie auf
#shadow-root (closed). Googlebot liest nur Open Shadow DOM. - Link-Format: Suchen Sie im DOM nach
<a. Standard-Anker sind für die Crawling-Tiefe essenziell;window.location.href-Steuerungen werden oft nicht verfolgt. - Lazy Load:
<img>-Tags solltenloading="lazy"verwenden, statt auf komplexescroll-Event-Listener zu setzen.
Beträgt die Textdifferenz zwischen Initial HTML und gerendertem DOM mehr als 80 %, hängt die SEO-Stabilität komplett von der Rendering-Effizienz ab.
Ein Total Blocking Time (TBT) Wert von über 300 ms deutet darauf hin, dass die Skriptausführung das DOM-Parsing behindert.
Mit dem Coverage-Panel in Chrome lässt sich die Nutzung der JS-Dateien prüfen. Wenn 80 % eines 500 KB Skripts beim ersten Laden ungenutzt bleiben, verschwendet dies unnötig Rechenleistung der Rendering-Server.
Professionelle Crawler-Tools
Professionelle Tools können Chrome-Umgebungen simulieren (z. B. Screaming Frog v20+).
Daten zeigen, dass das Ausführen von Skripten etwa 20-mal mehr Ressourcen verbraucht als statisches HTML. Wenn die Wortzahl-Differenz zwischen “Vor Rendering” und “Nach Rendering” 10 % oder die Link-Differenz 5 % übersteigt, sinkt die Indexierungschance.
Screaming Frog SEO Spider
In Screaming Frog aktiviert das Umschalten von “Text Only” auf “JavaScript” eine vollständige Browser-Simulation via Headless Chrome.
Dies erhöht den RAM-Bedarf um den Faktor 5 bis 10. Bei 100.000 Seiten sollten mindestens 16 GB bis 32 GB RAM zugewiesen werden.
| Metrik-Kategorie | Original HTML (Source) | Rendered HTML | Empfohlener Schwellenwert |
|---|---|---|---|
| Wortzahl (Word Count) | Nur Basis-Framework | Inkl. asynchroner Inhalte | Differenz > 15 % prüfen |
| Interne Links | Minimal | Dynamisch generiert | Differenz > 0 ist ein Risiko |
| Canonical-Tag | Ggf. Platzhalter | Finale Version via JS | Gerenderte Version zählt |
| Seitengröße | Meist < 50 KB | Oft 500 KB – 2 MB | Zu groß führt zu Kürzungen |
Der Standard-AJAX-Timeout liegt oft bei 5 Sekunden. Ist eine API langsamer, wird nur eine “leere Hülle” gecrawlt.
Die “JavaScript Rendering Table” im Bulk-Export ermöglicht es, Unterschiede bei Title, Meta-Description und H1-Tags für die gesamte Website zu analysieren. Erscheint dort ein “Loading…” als H1, wurde nur ein Zwischenzustand erfasst.
Statuscodes von Skripten im “Resource”-Tab sind wichtig: Ein 403 Forbidden deutet oft auf eine Firewall (WAF) hin, die den Headless-Browser blockiert.
| Ressourcenstatus | Ursache | Auswirkung |
|---|---|---|
| Blocked by robots.txt | Pfad auf Disallow gesetzt | Rendering schlägt fehl |
| Status Code: 429 | Zu hohe Frequenz (Rate Limit) | Inhalte fehlen teilweise |
| Status Code: 404 | Skriptpfad ungültig | Komponenten fehlen |
| Timeout (> 5s) | Langsame API / komplexe Logik | HTML ist leer oder fehlerhaft |
Lumar (DeepCrawl)
Lumar nutzt Cloud-Power für Millionen von URLs. Lokale Tools schaffen oft nur 20-50 parallele Rendering-Threads; Lumar kann auf über 500 skalieren, um 1 Million Seiten in 24h zu rendern.
Seiten mit Skriptlaufzeiten über 5000 ms werden als “High-Cost-Pages” markiert. Bei SPAs kann der DOM-Baum von 5 KB auf 800 KB anschwellen, was eine extreme Abhängigkeit zeigt.
Wenn die DOM Node Count den Google-Richtwert von 1500 überschreitet, sinkt die Effizienz. Berichte über den Rendering Gap zeigen: Bei Lücken von über 80 % verzögert sich die Indexierung oft um 3 bis 7 Tage.
Fehlen bei deaktiviertem JS alle Links (Rückgang von 200 auf 0), ist die Auffindbarkeit neuer Seiten gefährdet. Lumar vergleicht zudem die Wortzahl (Rendered vs. Source) – je größer die Diskrepanz, desto instabiler das Crawling.


