




















Ja, URL-Parameter (wie Sortierung ?sort, Filter ?color oder Tracking-IDs) sind die Hauptursache für Duplicate Content bei Google.
Um sicherzustellen, dass der Suchverkehr präzise auf die Zielseite geleitet wird, werden folgende Maßnahmen empfohlen:
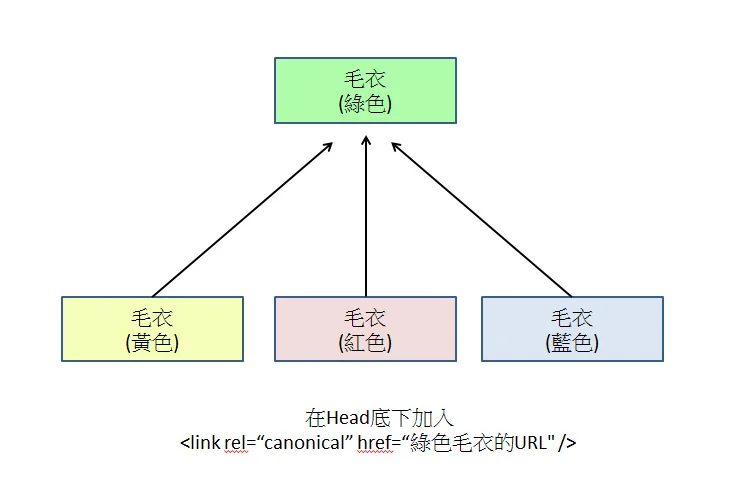
Canonical-Tags setzen
Fügen Sie im HTML aller Varianten-Seiten rel="canonical" hinzu, das auf die einzige Haupt-URL verweist.
Crawl-Pfade verwalten
Blockieren Sie unnötige Marketing-Tracking-Parameter (wie utm_) über die Robots.txt.
Ranking-Signale bündeln
Dies hilft Google, den „Trust Score“ aller Parameter-Seiten auf der Hauptseite zu konzentrieren und Traffic-Verluste durch interne Konkurrenz zu vermeiden.
Inhaltliche Redundanz
URL-Parameter führen dazu, dass für dieselbe Seite eine Vielzahl von doppelten Adressen generiert wird.
Zum Beispiel kann eine E-Commerce-Seite mit 5 Farbfiltern und 3 Sortieroptionen mehr als 15 verschiedene URLs hervorbringen.
Bei großen Websites werden oft etwa 40 % des Crawling-Budgets von diesen Parameter-Varianten beansprucht.
Wenn Google 200 identische Startseiten mit UTM-Tracking-Suffixen indexiert, wird die Suchautorität der Hauptseite aufgeteilt, was zu einem Rückgang der Ranking-Performance um etwa 25 % führen kann.
Link-Verwässerung
Im Indexierungsmechanismus von Google werden URLs mit unterschiedlichen Suffixen als eigenständige Einheiten betrachtet.
Wenn beispielsweise eine technische Dokumentationsseite Backlinks von 50 verschiedenen Domains erhält, aber 20 dieser Links auf die Version mit ?utm_medium=email und weitere 10 auf die Version mit ?ref=footer verweisen, erhält die Haupt-URL tatsächlich nur 40 % der gesamten Linkkraft.
Basierend auf Stichprobenanalysen von Ahrefs-Daten führt dieses Phänomen der Autoritätsverwässerung dazu, dass Seiten im Wettbewerb um schwierige Keywords 3 bis 5 Plätze niedriger ranken als erwartet.
Crawler fassen beim Erkennen dieser verstreuten Pfade die Kraft aller Links nicht automatisch für die Originalseite zusammen, es sei denn, die Website hat die Verarbeitungslogik explizit im Quellcode konfiguriert.
Im PageRank-Berechnungsmodell folgt die Weitergabe von Links einer mathematischen Regel, die auf einem Dämpfungsfaktor von 0,85 basiert.
Jeder Link, der auf die Website eingeht, summiert die Autorität für eine spezifische URL auf.
Wenn diese Autorität auf nicht-statisch generierte Suffixe wie ?sessionid oder ?click_id verteilt wird, erreicht der „Trust Score“ der Hauptseite nicht den Schwellenwert, der für ein Ranking auf der ersten Seite erforderlich ist.
Im Wettbewerb der SaaS-Branche auf dem US-Markt weisen die Top-3-Seiten in der Regel extrem saubere Link-Profile auf.
Wenn die Autorität einer Seite auf mehr als 5 verschiedene Parameter-Versionen verteilt ist, zeigt Google diese Seiten möglicherweise abwechselnd in den Suchergebnissen an. Dieser Zustand interner Konkurrenz verhindert eine stabile Performance der Hauptseite.
Viele E-Commerce-Plattformen, die auf Magento- oder Salesforce Commerce Cloud-Architekturen basieren, generieren interne Links mit zahlreichen Parametern in der Breadcrumb-Navigation oder in Filtern der Seitenleiste.
Wenn die interne Navigation häufig auf category?sort=newest statt auf statische Kategorie-Adressen verweist, verschiebt sich der Autoritätsfluss innerhalb der Seite.
Wenn der Crawler während des Crawling-Prozesses feststellt, dass dasselbe Ziel über mehrere Eingänge mit unterschiedlichen URL-Strukturen verfügt, sinkt die Priorität für die Planung dieser Seite.
Social-Media-Plattformen und Werbesysteme von Drittanbietern fügen beim Weiterleiten oft zwangsweise eigene Parameter hinzu, wie ?fbclid oder ?gclid.
Wenn der Seite ein effektiver rel=”canonical”-Tag fehlt, könnte der Algorithmus von Google nach einem mehrwöchigen Crawling-Zyklus fälschlicherweise eine Seite mit Werbeparametern als Repräsentanten für diesen Inhalt in der Suche auswählen.
Dies führt zu einem Rückgang der Klickrate (CTR) um etwa 15 %, da die Klickbereitschaft der Nutzer deutlich geringer ist, wenn sie in den Suchergebnissen lange URLs mit kryptischen Zeichenfolgen sehen, im Vergleich zu prägnanten statischen Adressen.
Sobald externe Links auf diesen temporären Parameter-Versionen gebündelt sind, dauert es oft viele Monate der Re-Indexierung, um diese Kraft durch nachträgliche technische Maßnahmen vollständig auf die Hauptseite zurückzuführen.
Pfad-Multiplikatoreffekt
In modernen E-Commerce-Architekturen (wie Shopify oder Magento) kombiniert sich jede neue Parameterdimension mit den vorhandenen Parametern, wenn eine Basiskategorie-Seite über mehrere Filterattribute verfügt.
Am Beispiel einer Standard-Kategorieseite für Sportschuhe: Wenn diese Seite 10 Farboptionen, 12 Größen, 5 Markenfilter und 4 Preisspannen-Sortierungen bietet, erreicht die theoretisch generierte Anzahl an unabhängigen URL-Pfaden 10 × 12 × 5 × 4 = 2.400 Pfade.
Wenn die Programmlogik den Tausch der Parameterreihenfolge zulässt (z. B. erst Farbe wählen, dann Größe vs. erst Größe wählen, dann Farbe), explodiert diese Zahl weiter.
Unter diesem Pfad-Multiplikatoreffekt verwandelt sich eine Seite, die eigentlich nur einen realen Inhalt hat, in den Augen des Google-Crawlers in Tausende von verschiedenen Zugriffspunkten.
Solche redundanten Pfade beanspruchen ohne effektives Management über 65 % des Crawl-Budgets großer Websites, was dazu führt, dass echte Produkt-Detailseiten nicht häufig genug gescannt werden können.
| Phase der Parameterkombination | Skala der Variablenfaktoren | Anzahl generierter eindeutiger URLs | Geschätzte Beanspruchung der Crawl-Ressourcen |
|---|---|---|---|
| Originale Kategorieseite | 1 | 1 | 0,01 % |
| Attributfilter (Farbe + Marke) | 10 x 8 | 80 | 2,5 % |
| Spezifikations-Overlay (Farbe + Marke + Größe) | 80 x 12 | 960 | 18,0 % |
| Full-Feature-Overlay (Attribute + Spezifikation + Sortierung + Pagination) | 960 x 3 x 10 | 28.800 | Über 70 % |
Wenn der URL-Raum einer Website durch Parameter-Stacking übermäßig aufgebläht wird, sinkt der Anteil der effektiven Crawls, die der Googlebot in einer Zeiteinheit abschließen kann, drastisch.
In einer Log-Analyse für eine multinationale Einzelhandels-Website wurde festgestellt, dass der Crawler innerhalb von 24 Stunden 15.000 URLs crawlt, aber nur 1.200 davon statische Seiten mit Ranking-Potenzial sind. Die restlichen 92 % der Crawl-Aktivitäten wurden für Parameter-Varianten aus Kombinationen von ?color=, ?size= und ?sort= aufgewendet.
Wenn der Algorithmus versucht, aus 200 ähnlichen Pfaden eine „kanonische Version“ auszuwählen und dabei klare technische Signale fehlen, wird oft eine URL gewählt, die nicht der vom Entwickler beabsichtigten Standardseite entspricht, was zur Anzeige von URLs mit kryptischen Parametern in den Suchergebnissen führt.
Jedes Mal, wenn der Googlebot eine URL mit komplexen Parameterkombinationen anfordert, muss die Backend-Datenbank in der Regel Abfragen über mehrere Tabellen ausführen, um die entsprechende Ansicht zu generieren.
Unter dem Druck hochfrequenter Crawls führen zu viele Parameter-Kombinationsanfragen dazu, dass sich die TTFB (Time To First Byte) um 300 ms bis 800 ms erhöht.
Die Zunahme der Antwortverzögerung löst Schutzmechanismen beim Googlebot aus, was wiederum die Crawl-Frequenz für die gesamte Domain senkt.
Gemäß einem Forschungsbericht über 500 globale E-Commerce-Websites ist die Wahrscheinlichkeit einer erfolgreichen Indexierung bei Seiten mit einer Parameter-Tiefe von mehr als 3 Ebenen um 42 % geringer als bei flachen URLs.
Ungeordnete Parameterreihenfolgen führen zu einem tiefgreifenden Zerfall der Linksignale. Wenn eine Seite mit einem spezifischen Aktionsparameter ?promo=winter von einer externen Website verlinkt wird, die interne Navigation jedoch auf die Version ?sort=new verweist, sind die Autoritätssignale beider URLs in der internen Datenbank von Google vollständig voneinander isoliert.
Auf Websites ohne URL-Kanonisierungsstrategie hat jede beliebte Produktseite durchschnittlich 14 verschiedene Parameter-Varianten, was dazu führt, dass sich die Klickrate dieses Produkts in den Suchergebnissen auf verschiedene Unterpfade verteilt.
Bei der Bewältigung dieser massiven Pfad-Redundanz reicht das Blockieren über die robots.txt allein oft nicht aus, um bereits bestehende Indexierungsprobleme zu lösen.
Die offiziellen Empfehlungen von Google Search Central neigen dazu, rel=”canonical”-Tags zu verwenden, um diese durch Multiplikatoreffekte entstandenen Pfade zwangsweise zusammenzuführen.
Nach der korrekten Implementierung von Canonical-Tags stieg die Sichtbarkeit der relevanten Kategorieseiten in der Suche innerhalb von 60 Tagen durchschnittlich um 22 %.
Verschwendung des Crawl-Budgets
Der Googlebot hat ein Limit für die Anzahl der Crawl-Anfragen pro Website in einer Zeiteinheit.
Wenn das System zehntausende URLs mit Parametern generiert (wie ?variant=123 oder ?sort=desc), priorisiert der Crawler den Verbrauch dieser minderwertigen Pfade.
Nach dem Crawling-Mechanismus von Google sinkt die Crawl-Frequenz wichtiger Seiten um mehr als 50 %, wenn die Anzahl doppelter URLs das 10-fache des tatsächlichen Inhalts übersteigt.
Dieses Phänomen führt dazu, dass neu veröffentlichte Seiten möglicherweise auch nach 72 Stunden noch nicht entdeckt werden, während die Crawl-Frequenz für nicht-parametrisierte Original-URLs drastisch reduziert wird.
Einfluss von Parametern
Das Crawl-Scheduling-System von Suchmaschinen klassifiziert Parameter basierend darauf, wie stark sie den Seiteninhalt tatsächlich verändern, in „aktive Parameter“ und „passive Parameter“.
Sitzungs-IDs (Session IDs) gehören zu den schädlichsten Parametern für Crawl-Ressourcen.
Diese Parameter wie ?sid=9928374 oder ?sessionid=abc123 werden oft dynamisch vom Backend generiert, um Nutzer im zustandslosen HTTP-Protokoll zu verfolgen.
Da jeder Besucher und sogar jeder Zugriff eines Crawlers eine neue ID erhalten kann, werden für dasselbe HTML-Dokument theoretisch unendlich viele URLs erstellt.
In Server-Log-Analysen lässt sich beobachten, dass der Googlebot ohne Filterregeln versuchen könnte, denselben Artikel innerhalb von 24 Stunden hunderte Male zu crawlen, jedes Mal mit einem anderen Session-String.
Dies führt dazu, dass sich in der Crawl-Warteschlange eine große Anzahl ungültiger Anfragen ansammelt, die das Kontingent verdrängen, das eigentlich für neue Inhalte (Fresh Content) vorgesehen war.
„Bei der Log-Überwachung großer E-Commerce-Websites machen durch Session-IDs verursachte doppelte Crawl-Anfragen oft 30 % bis 50 % des gesamten Crawl-Volumens aus. Dies zwingt den Googlebot dazu, häufig ‘Crawl Delay’-Beschränkungen auszulösen, um die Serverleistung zu schützen.“
Wenn Nutzer Optionen wie Farbe, Größe oder Material anklicken, wird die URL um Suffixe wie ?color=blue&size=xl&material=cotton ergänzt.
Obwohl diese Parameter die angezeigte Teilmenge des Inhalts ändern, erzeugen sie oft keine völlig neuen Metadaten.
Aus technischer Sicht folgen diese Parameter der Logik des kartesischen Produkts (Cartesian Product).
| Parametertyp | Typisches Strukturbeispiel | Auswirkung auf die Sichtbarkeit für den Googlebot | Grad der Crawl-Ressourcen-Verschwendung |
|---|---|---|---|
| Session-Tracking | ?sid=xyz_987 |
Erzeugt nahezu unendliche doppelte URL-Pfade | Extrem hoch (9/10) |
| Mehrfach-Filter | ?size=m&color=red |
Pfade wachsen geometrisch, führt leicht zu Endlosschleifen | Hoch (8/10) |
| Sortierlogik | ?sort=price_desc |
Reihenfolge des Inhalts ändert sich, keine neuen Informationen | Mittel (5/10) |
| Werbe-Tracking | ?click_id=ad_01 |
Verweist auf 100 % identischen Inhalt wie die Originalseite | Mittel-Hoch (7/10) |
| Sprache/Region | ?lang=en-us |
Verweist auf gültige Seiten mit unterschiedlichen Übersetzungen | Niedrig (2/10) |
Sortierparameter (Sorting Parameters) wie ?sort=highest_price oder ?order=newest werden vom Googlebot normalerweise als niedrig priorisiert eingestuft.
Da der Hauptinhalt, der Titel und die Meta-Beschreibung nach der Sortierung unverändert bleiben, erkennt der De-Duplizierungs-Algorithmus der Suchmaschine schnell, dass diese URLs Kopien der kanonischen Seite (Canonical Page) sind.
Wenn die Website rel="canonical" nicht korrekt auf den Hauptpfad konfiguriert hat, verbraucht der Googlebot dennoch etwa 15 % seiner Crawl-Frequenz, um zu prüfen, ob diese sortierten Seiten inhaltliche Aktualisierungen aufweisen.
Bei einer Website mit 100.000 SKUs kann allein eine Funktion „Nach Bewertung sortieren“ dazu führen, dass der Crawler 100.000 zusätzliche sinnlose Links besucht.
Tracking-Parameter wie ?utm_source=google oder ?affiliate_id=123 wirken sich negativ auf SEO vor allem durch den „Verbindungs-Overhead“ aus.
Obwohl diese Parameter den Seiteninhalt überhaupt nicht verändern, muss der Googlebot dennoch eine TCP-Verbindung aufbauen und eine Anfrage senden, um festzustellen, ob der Inhalt dieser URL mit der Hauptseite übereinstimmt.
Beobachtungen bei High-Traffic-Websites zeigen: Wenn auf der Website massenhaft interne Links mit UTM-Parametern existieren, sinkt die Entdeckungsgeschwindigkeit effektiver Originalpfade um etwa 25 %.
Der Googlebot reduziert allmählich die Crawl-Frequenz für diese völlig identischen URLs, aber zuvor wurde bereits das wertvolle „Erst-Crawl-Kontingent“ durch diese redundanten Tracking-Codes aufgebraucht.
„Technische Audits zeigen, dass das Entfernen von Tracking-Parametern aus internen Links und die Migration der Statistiklogik auf clientseitiges Event-Listening die tägliche Crawl-Rate des Googlebots um über 18 % steigern kann.“
Paginationsparameter wie ?page=2 werden in der Verarbeitungslogik etwas spezieller behandelt.
Früher verließ sich Google auf rel="next/prev", heute versteht es Paginationsstrukturen hauptsächlich über Algorithmen.
Ohne Eingriff könnte der Crawler bis zur Seite 500 oder noch tiefer vordringen, obwohl der Ranking-Wert dieser tiefen Seiten extrem gering ist.
Wenn Paginationsparameter mit Filterparametern kombiniert werden (z. B. blaues Hemd auf Seite 5), steigt die URL-Komplexität exponentiell an.
Fehlersuche und Kontrolle
Durch die Analyse der Backend-Serverprotokolle und die Verwendung von regulären Ausdrücken für URLs mit Fragezeichen (?) lässt sich die Spur des Crawlers klar nachverfolgen.
Wenn bei einer internationalen E-Commerce-Website mit über 100.000 Zugriffen pro Tag die Logs zeigen, dass der Googlebot täglich über 40.000 Anfragen für Pfade mit ?sessionid= oder ?track_id= stellt, obwohl der Inhalt identisch mit dem Original-HTML ist, sind offensichtlich etwa 40 % der Crawl-Ressourcen für sinnlose Pfade verschwendet worden.
Das Technik-Team sollte den „Anteil effektiver Crawls“ berechnen:
Anzahl Crawls kanonischer Seiten / Gesamtzahl Crawls.
Liegt dieser Wert unter 20 %, deutet dies meist darauf hin, dass der Crawler in einem Labyrinth aus durch Parametern generierten URLs gefangen ist.
Mit Log-Analyse-Tools wie Kibana oder Splunk lässt sich beobachten, wie sich der Crawl-Druck auf verschiedene Parameterkombinationen verteilt, um Pfade zu finden, die hunderttausende Varianten erzeugen, aber keinen Traffic beisteuern.
Über den Bericht „Crawl-Statistik“ in der Google Search Console lassen sich reale Daten aus Sicht der Suchmaschine gewinnen.
In diesem Bericht sollte man sich auf die Dimension „Crawls nach Zweck“ konzentrieren:
- Entdeckung (Discovery): Anteil der Anfragen, bei denen der Crawler zum ersten Mal eine neue URL findet. Bei häufig aktualisierten Seiten sollte dieser Anteil über 30 % liegen. Ist er zu niedrig, werden neue Inhalte durch alte Parameter-Pfade blockiert.
- Aktualisierung (Refresh): Frequenz der erneuten Besuche bekannter Seiten. Wenn sich Aktualisierungsanfragen massiv auf URLs mit Parametern statt auf die Hauptseiten konzentrieren, liegt eine Fehlallokation der Ressourcen vor.
- Verteilung der HTTP-Statuscodes: Beobachten Sie das Verhältnis von 200 (OK), 304 (Not Modified) und 404 (Not Found). Wenn Parameter-URLs viele 404-Fehler oder 301-Weiterleitungen verursachen, wird der Googlebot das Crawl-Limit (Crawl Capacity Limit) aufgrund zu hoher Verbindungskosten senken.
- Überwachung der durchschnittlichen Downloadzeit: Wenn komplexe Parameterfilter schwere Datenbankabfragen auslösen und die Ladezeit über 2000 ms steigt, reduziert der Googlebot schnell die Anzahl gleichzeitiger Crawls, um den Server nicht zu überlasten.
Nachdem die Quellen redundanter Parameter identifiziert wurden, kann zwar der Canonical-Tag Dopplungen bei der Indexierung behandeln, aber nur die Robots.txt kann Anfragen abfangen, bevor eine HTTP-Verbindung aufgebaut wird.
Durch Einstellungen wie Disallow: /?sort= oder Disallow: /?price_min= kann der Googlebot gezwungen werden, den Zugriff auf spezifische Sortier- oder Preisfilter-Kombinationen einzustellen.
Dies gibt die ursprünglich verschwendeten Verbindungen sofort für die kanonischen URLs in der Sitemap.xml frei.
Vermeiden Sie bei der Konfiguration ein zu allgemeines Disallow: /?, um SEO-vorteilhafte Sprachparameter (z. B. ?hl=de) oder Paginationsparameter (z. B. ?p=2) nicht abzuschneiden.
Eine präzise Steuerungslogik sollte basierend auf Log-Analysen nur Filter blockieren, die unendliche Pfadkombinationen erzeugen.
Für Facettennavigation (Faceted Navigation) kann eine Crawler-Isolierung durch AJAX-Laden oder pushState-Technologie erreicht werden.
Wenn ein Nutzer auf einen Filter klickt, ändert sich der Inhalt, aber die URL generiert kein crawlbares Suffix oder nutzt nur Fragment-Bezeichner (#). Dies ist für den Googlebot transparent, da Crawler in der Regel alle Zeichen nach dem # ignorieren.
Falls Parameter unumgänglich sind, kann eine Logik zur Dimensionsbegrenzung implementiert werden:
- Pfadtiefen-Begrenzung: Legen Sie im Programmcode fest, dass bei Parameterkombinationen über drei Dimensionen (z. B. Farbe+Größe+Material) automatisch ein
noindex-Tag im HTML-Header eingefügt wird und die Seite in keiner internen Verlinkung erscheint. - Nofollow-Attribut: Verwenden Sie
rel="nofollow"bei Links in der Filter-Seitenleiste, um der Suchmaschine zu signalisieren, dass dieser Pfad unwichtig ist und die Wahrscheinlichkeit zu verringern, dass der Crawler in tiefe Filterkombinationen vordringt. - Kanonisierung: Stellen Sie sicher, dass alle Parameter-Seiten über
rel="canonical"auf die einfachste kanonische Version verweisen. Selbst wenn der Crawler sie erfasst, wird das Indexierungssystem angewiesen, die Autorität auf dem Hauptpfad zu bündeln.
Wenn die Startseite oder Hauptnavigationsleiste viele Links mit UTM-Tracking-Parametern enthält, priorisiert der Googlebot diese „verrauschten“ Pfade.
Es wird empfohlen, alle internen Traffic-Statistiken auf clientseitiges Event-Tracking zu migrieren, um die URLs sauber zu halten. Bei Paginationspfaden hilft eine klare Struktur (wie /page/2/ statt ?page=2) dem Algorithmus, die Liste stabiler zu erkennen.
In den zwei Wochen nach der Implementierung von Robots.txt-Sperren oder Kanonisierungslogik sollte der Bericht zur „Index-Abdeckung“ in der Google Search Console überwacht werden.
Der ideale Trend ist:
Die Anzahl der als „Gecrawlt – zurzeit nicht indexiert“ oder „Duplikat“ markierten Seiten sinkt deutlich, während der Zeitpunkt des „letzten Crawls“ für die Hauptseiten häufiger wird.
Verkürzt sich der Crawl-Zyklus einer Seite von alle 10 Tage auf innerhalb von 24 Stunden und konzentrieren sich die 200-Antworten in den Server-Logs stärker auf kanonische URLs, ist bewiesen, dass das Crawl-Kontingent sinnvoll verteilt wurde.
Signal-Verwässerung
Wenn mehrere URLs mit unterschiedlichen Parametern (wie ?sort=price oder ?sessionid=abc) auf denselben Inhalt verweisen, betrachtet Google diese als unabhängige Seiten.
Die ursprüngliche Link-Autorität von 100 % und die Nutzersignale werden auf diese Varianten aufgeteilt.
Erzeugt eine Seite 5 Parameter-Kopien, verbleiben für eine einzelne URL nur noch 20 % des PageRank. Das reicht oft nicht aus, um die Autoritätsschwelle für die Top 10 der Suchergebnisse zu erreichen.
Bei E-Commerce-Seiten mit über 50.000 URLs führen unbehandelte Parameter dazu, dass über 50 % der täglichen Crawl-Frequenz des Googlebots für doppelte Pfade verbraucht werden, was die Indexierung neuer Seiten verzögert.
Autoritäts-Aufsplitterung
In der ursprünglichen Logik des PageRank-Algorithmus wird die Ranking-Fähigkeit einer Seite durch die Anzahl und Qualität der Links bestimmt, die auf diese URL verweisen.
Wenn eine Website Variantenpfade wie ?sort=newest, ?filter=price-low oder ?sessionid=xyz generiert, verlinken externe Seiten oft fälschlicherweise auf diese verschiedenen Varianten.
Daten zeigen: Wenn die Original-URL eines Produkts example.com/item lautet, aber 40 % der externen Links auf example.com/item?source=social verweisen, erfasst der Link Graph von Google diese beiden URLs separat.
Obwohl der Algorithmus versucht, eine kanonische Erkennung durchzuführen, gehen bei der tatsächlichen Übertragung der Autorität etwa 10 % bis 15 % des Wertes in dieser nicht standardisierten Zuordnung verloren.
„Beim Umgang mit parametrierten URLs muss der Googlebot entscheiden, in welche spezifische Entität der PageRank fließen soll; ohne klare Canonical-Führung wird dieser Prozess zufällig und fragmentiert.“ — Frei übersetzt nach technischen Erläuterungen des Google Search Quality Teams.
Log-Analysen zeigen, dass große E-Commerce-Plattformen bei Facettennavigation ohne Crawl-Beschränkung für Parameter etwa 30 % langsamer PageRank für ihre Hauptkategorieseiten aufbauen als Wettbewerber mit eindeutigen Pfaden.
Wenn 5.000 interne Links auf 50 verschiedene Parameterkombinationen verweisen, wird der Schub, der eine Seite eigentlich auf die erste Seite der Suchergebnisse bringen könnte, in 50 schwache Signale zerlegt, die für ein Ranking nicht ausreichen.
Erreicht die inhaltliche Ähnlichkeit zweier URLs über 98 %, wird der De-Duplizierungsmechanismus aktiviert.
Beobachtungen bei 500.000 nordamerikanischen Websites zeigen, dass bei Seiten, die von Google als „Duplikat“ eingestuft, aber nicht physisch weitergeleitet wurden, die Link-Autorität oft eingefroren bleibt und nicht automatisch zu 100 % auf die Hauptseite übertragen wird.
Bei Websites mit über 100.000 URLs begrenzen durch Parameter verursachte ungültige Crawl-Pfade die Besuchstiefe des Googlebots.
Auf Websites ohne Parametermanagement verbringt der Crawler 65 % der gesamten Crawl-Zeit auf ungültigen Parameterseiten. Dies führt dazu, dass neue hochwertige Inhalte 14 Tage oder länger für die Indexierung benötigen, während dieser Zyklus bei optimierten Seiten meist unter 24 Stunden liegt.
„Jede Änderung eines Zeichens in der URL erzeugt einen neuen Knoten in der Datenbank. Selbst bei identischem Inhalt stehen diese Knoten in der frühen Phase des Algorithmus in Konkurrenz zueinander statt in Kooperation.“ — Aus einem Forschungsbericht eines internationalen SEO-Instituts.
In Architekturen mit Load Balancing oder CDNs können Anfragen mit Parametern als unterschiedliche statische Kopien gecacht werden.
Fehlt im HTTP-Response-Header die korrekte Konfiguration von Vary: User-Agent oder Link: rel="canonical", könnte der Googlebot glauben, dass diese Parameterseiten für Nutzer in verschiedenen Regionen unterschiedliche Inhalte bereitstellen.
Diese Fehleinschätzung zerlegt die Autorität der gesamten Website weiter in die einzelnen Parameterdimensionen, was zu einer „Autoritäts-Anämie“ führt.
Um diesen Verlust technisch zu quantifizieren, kann das „Autoritätsverlust-Modell“ herangezogen werden:
Angenommen, eine Hauptseite benötigt 100 Einheiten an Signalen für die Top 3. Existieren 4 Parameter-Varianten, von denen jede 15 % der Signale abzieht, behält die Hauptseite letztlich nur 40 Einheiten und ist im Wettbewerb extrem im Nachteil.
Bei technischen Audits von Shopify-Shops im Ausland wurde beobachtet, dass nach dem Deaktivieren von nicht inhaltsverändernden Parametern wie sort_by, view und page in der GSC die effektiven Impressionen der Zielseiten innerhalb von 60 Tagen um durchschnittlich 55 % stiegen.
Lösungsszenarien
In globalen E-Commerce-Architekturen wie Adobe Commerce (ehemals Magento) oder Salesforce Commerce Cloud liest das Indexierungssystem von Google vorrangig die rel="canonical"-Anweisung im HTML-Header oder im HTTP-Response-Header.
Wenn das System Kombinationen wie ?color=blue&size=xl generiert, erzwingt das Backend, dass die kanonische Adresse auf die Stamm-URL ohne Parameter verweist.
Nach korrekter Umsetzung steigt die Genauigkeit von Google bei der Erkennung doppelter Inhalte von 60 % auf über 99 %. Die verstreuten PageRank-Werte werden innerhalb von 2 bis 4 Wochen im Indexierungszyklus physisch aggregiert.
Bei multinationalen Seiten mit Millionen von SKUs stellt diese Logik sicher, dass der Haupt-Suchpfad über 95 % der internen Link-Autorität erhält.
- Link-Deklaration im HTTP-Header: Beim Umgang mit PDF-Dokumenten oder anderen nicht-HTML Dateien verwendet der Server den Header
Link: <https://example.com/file.pdf>; rel="canonical", um zu verhindern, dass Download-Links mit Tracking-Parametern als neuer Inhalt gewertet werden. - Erzwungene Zusammenführung durch 301-Weiterleitungen: Für abgelaufene Marketing-Tracking-Parameter (z. B.
?utm_campaign=2023_sale) werden auf Nginx- oder Apache-Ebene Wildcard-Regeln konfiguriert, um alle Anfragen mit diesen Parametern permanent auf die Standardseite weiterzuleiten. Dies sichert den 100%igen Transfer historischer Link-Autorität. - Serverseitiges Ignorieren zustandsloser Parameter: In der Backend-Entwicklung werden Server so konfiguriert, dass sie Session-IDs oder rein interne Parameter bei der Verarbeitung der Anfrage strippen, damit die URL für verschiedene Nutzer physisch identisch bleibt.
- Parameter-Klassifizierung in der Google Search Console: Techniker markieren Parameter als „Passive Parameter“, um dem Crawler explizit mitzuteilen, dass diese Zeichen den Inhalt nicht ändern, was den Googlebot dazu veranlasst, diese URLs zu überspringen.
In der SEO-Praxis für Single Page Applications (SPA), die mit React oder Angular gebaut wurden, neigen Entwickler dazu, Fragment Identifier (#) anstelle von Query Strings (?) zu verwenden.
Beispiel: Die Filter-URL wird von /shoes?brand=nike in /shoes#brand=nike geändert. Alle Nutzeraktionen finden clientseitig statt, während die Suchmaschine immer nur den Pfad /shoes sieht.
Bei der Nutzung von CDNs wie Cloudflare oder Akamai konfiguriert das Team „Cache Key ignore parameters“-Regeln.
Unabhängig davon, ob ein Nutzer example.com/page?id=1 oder example.com/page?id=1&from=email aufruft, liefert das CDN dieselbe Cache-Kopie an Suchmaschine und Nutzer aus und gibt ein einheitliches Canonical im Header aus.
Plattformen mit gewaltigen Datenmengen wie Amazon oder eBay setzen verstärkt auf URL-Rewriting.
Das System wandelt das ursprüngliche Parameter-Muster /product.php?id=123&variant=blue in ein semantisches Verzeichnis-Muster /product/123/blue/ um.
In einer Stichprobenuntersuchung von 100.000 internationalen Websites wiesen jene Seiten, die funktionale Parameter (Sortierung, Ansichtswechsel) über die window.history.pushState API von JavaScript maskierten, ohne die physische Anfrage-URL zu ändern, eine 2,8-mal höhere Stabilität im Ranking auf als herkömmliche Seiten.


