




















Inspection d’URL GSC
Saisissez l’URL dans la Search Console, cliquez sur “Afficher la page explorée”, comparez le code source HTML et confirmez si le contenu essentiel disparaît après le rendu.
Comparaison des différences textuelles
Comparez le nombre de caractères textuels entre “Afficher le code source de la page” et “Inspecter l’élément”. Si le taux de différence textuelle est > 20 %, le risque d’indexation est extrêmement élevé.
Test des résultats enrichis
Utilisez l’outil de test des résultats enrichis de Google pour examiner la capture d’écran et vous assurer que le contenu critique au-dessus de la ligne de flottaison est intégralement chargé dans la fenêtre de rendu de 5 secondes.
Outils officiels de Google
L’outil d’inspection d’URL de Google Search Console (GSC) est la porte d’entrée pour obtenir l’état réel de l’exploration par Googlebot.
Grâce au “Test d’URL en direct”, il est possible d’appeler le WRS (Web Rendering Service) en 60 à 90 secondes pour générer une structure DOM complète.
La GSC fournit le HTML après rendu, des captures d’écran et une liste de chargement des ressources.
Actuellement, Googlebot utilise le dernier noyau stable de Chrome, mais impose un seuil d’environ 5 secondes pour l’exécution des scripts sur une seule page.
En combinant cela avec le “Test des résultats enrichis”, vous pouvez comparer les différences d’octets entre la réponse originale et le rendu final, et identifier les échecs de chargement de scripts 403 ou 404 causés par un blocage via le fichier Robots.txt.
Google Search Console
Dans la navigation latérale de Google Search Console, après avoir saisi une URL spécifique, le système extrait un instantané des données de la dernière exploration depuis la base de données d’indexation de Google.
Si l’état de la page indique “L’URL est sur Google”, vous pouvez vérifier s’il existait des erreurs d’analyse HTML ou des problèmes d’optimisation mobile lors de l’exploration.
Pour approfondir l’investigation sur le contenu manquant dû au rendu JavaScript, vous devez impérativement cliquer sur le bouton “Tester l’URL en direct”.
Cette opération déclenche le WRS (Web Rendering Service) qui lance un navigateur sans interface (headless) basé sur le dernier noyau Chromium stable pour accéder à la page cible en temps réel.
Lors de l’exécution du rendu, le WRS définit la largeur de la fenêtre d’affichage à 1280 pixels et adopte une stratégie d’exploration axée sur le mobile en priorité.
Dans le panneau “Afficher la page rendue”, l’onglet HTML présente la structure DOM complète une fois les scripts exécutés.
Le personnel technique doit comparer quantitativement le nombre de lignes de code HTML ou le volume d’octets affiché ici avec le “Code source de la page” (réponse originale du serveur) visible via un clic droit dans le navigateur.
Si le HTML original ne fait que 2 Ko alors que le HTML après rendu passe à 50 Ko, cela indique que la page dépend fortement du rendu côté client.
Si le HTML après rendu manque de contenu textuel principal ou de balises de liste de produits, il est considéré comme un échec de rendu.
Googlebot alloue des ressources de calcul limitées à l’exécution des scripts pour chaque page. Bien qu’aucun délai absolu ne soit officiellement communiqué, de nombreuses expériences montrent que si le temps de chargement du contenu dépasse 5 secondes, la probabilité que ces données soient omises lors de la phase d’indexation augmente considérablement.
“Googlebot n’attend pas indéfiniment que JavaScript termine toutes ses tâches asynchrones ; son budget de rendu est limité par la vitesse de chargement de la page, le délai de réponse du serveur (TTFB) et la complexité de l’analyse des scripts. Si le temps de réponse d’une interface API dépasse 2000 millisecondes, cela conduit souvent à ce que le contenu soit encore en état de ‘Chargement’ au moment de la génération de l’instantané du rendu.”
Dans l’onglet “Plus d’informations”, sous la liste “Ressources de la page”, tous les fichiers JS et CSS dont le chargement a échoué sont répertoriés.
Les codes d’état 403 ou 404 pointent clairement vers une erreur de configuration des permissions du serveur ou un chemin de ressource invalide. Cependant, l’état le plus préoccupant est “Bloqué par Robots.txt”.
Comme de nombreuses applications monopages (SPA) encapsulent la logique de routage et de rendu des données dans des fichiers de scripts spécifiques, si le fichier /robots.txt du site contient une règle Disallow: /assets/ ou similaire empêchant Googlebot d’accéder aux scripts principaux, le WRS ne pourra pas construire l’arbre DOM complet.
Le résultat est que, même si la page semble complète pour l’utilisateur dans son navigateur, elle peut n’être qu’un espace vide ou ne contenir que le cadre de base pour le moteur de recherche.
L’analyse des erreurs de script doit se concentrer sur la zone “Messages de la console JavaScript”.
C’est ici que sont enregistrées les exceptions levées par le WRS lors de l’exécution du code.
Si l’équipe de développement utilise de nouvelles fonctionnalités ES6+ sans Polyfill (telles que BigInt, ResizeObserver, etc.) et que la version de Chromium correspondante lors de l’exploration n’est pas encore totalement compatible avec certaines API non standard, la console affichera des erreurs de type Uncaught ReferenceError ou SyntaxError.
Ces erreurs provoquent l’interruption de tout le processus d’analyse du script, rendant caduque toute la logique d’injection de contenu ultérieure.
En observant les numéros de ligne et les noms de fichiers spécifiques mentionnés dans les journaux d’erreurs, il est possible de localiser précisément quel fichier de bibliothèque ou quel bloc de logique métier entrave l’exploration.
La “capture d’écran” après rendu est un autre moyen de détection quantitative.
Par exemple, certains scripts calculent dynamiquement la hauteur ou la transparence des éléments. Si la capture d’écran montre de grandes zones blanches, même si du texte est présent dans les balises HTML, l’algorithme de Google pourrait juger la page peu conviviale pour l’utilisateur, réduisant ainsi sa priorité d’indexation.
Lors de la gestion de sites hautement dynamiques, il est nécessaire de s’assurer que tout le contenu situé au-dessus de la ligne de flottaison (Above the Fold) termine son rendu en moins de 2 secondes.
Test des résultats enrichis
L’outil de test des résultats enrichis est un environnement de détection public fourni par Google. Contrairement à la Search Console qui nécessite une validation de propriété du site, cet outil permet à quiconque d’analyser n’importe quelle URL publique ou fragment de code collé.
Après avoir saisi l’URL et lancé le test, le système démarre un navigateur headless basé sur le dernier noyau Chromium stable, simulant le comportement d’accès de Googlebot Smartphone ou Googlebot Desktop.
Pour les applications monopages (SPA) reposant fortement sur des frameworks JavaScript tels que React, Angular ou Vue.js, la fonction “Afficher la page testée” fournie par cet outil est la référence pour déterminer si le contenu a réussi à entrer dans l’arbre DOM.
Étant donné que Googlebot a un plafond de ressources allouées lors du traitement des scripts, si la page nécessite une grande quantité de calculs intensifs ou lance plus de 20 requêtes API asynchrones lors de la phase d’initialisation, le WRS pourrait terminer la capture du HTML avant la fin de l’exécution des scripts.
Lors d’une détection en temps réel, le système génère un instantané HTML après rendu.
Grâce à cet instantané, les techniciens peuvent comparer avec précision la différence entre les octets renvoyés par le serveur original et les octets finaux après rendu.
Par exemple, une page en rendu côté client (CSR) pur n’a souvent qu’un code de modèle de base de moins de 5 Ko dans son HTML original. Si le HTML rendu par cet outil atteint plus de 100 Ko, cela signifie que Googlebot a exécuté les scripts avec succès et a extrait le contenu dynamique.
À l’inverse, si le HTML rendu reste aux alentours de 5 Ko et ne contient pas les balises de texte principal, cela indique que l’exécution du script a été interrompue au niveau du WRS.
Le moteur de rendu de Google définit des mécanismes d’expiration stricts pour le téléchargement de chaque ressource ; généralement, le temps de chargement d’un seul fichier JS ne doit pas dépasser 2000 millisecondes.
Si les bibliothèques tierces ou les interfaces API référencées par la page répondent trop lentement, l’onglet “Ressources de la page” dans les résultats du test signalera l’échec de chargement correspondant.
- Mode test de fragment de code : Permet de coller une logique de code HTML non publiée. C’est crucial pour vérifier si la logique de rendu JS est conforme aux normes d’exploration pendant la phase d’environnement de pré-production (Staging). De cette manière, on peut détecter quantitativement si certains balisages Schema générés dynamiquement peuvent être correctement analysés avant de fusionner le code sur la branche principale.
- Simulation de changement de User-Agent : Bien que l’exploration mobile soit adoptée par défaut, lors du traitement de sites ayant une logique adaptative (responsive) complexe, basculer vers une simulation d’appareil de bureau peut révéler l’impact de la priorité de chargement CSS sur l’ordre d’exécution JS.
- Comparaison d’instantanés de rendu : Les captures d’écran fournies par le système ne sont pas seulement des références visuelles, elles servent aussi de base pour juger si la page présente un “déplacement de contenu” (layout shift) ou une instabilité de mise en page, car des changements brutaux de disposition peuvent amener Googlebot à mal juger l’utilisabilité de la page.
“Le test des résultats enrichis ne valide pas seulement les données structurées, c’est aussi un laboratoire pour tester la visibilité du contenu dynamique. Si le texte de la page est chargé de manière asynchrone via JS, rechercher la présence de ce texte dans ‘Afficher la page testée’ est la méthode la plus rapide pour vérifier le taux de réussite de l’indexation SEO.”
Lorsque la page contient du JSON-LD ou des microdonnées (Microdata) injectés par script, l’outil extrait ces informations structurées du DOM après rendu.
S’il existe des erreurs de syntaxe dans le code, ou si le script s’arrête avant d’injecter le balisage Schema à cause d’une erreur JS, l’outil affichera le message “Aucun résultat enrichi détecté”.
Cette détection est particulièrement importante pour les sites de commerce électronique ou les sites d’avis, car Google doit identifier des attributs spécifiques tels que le prix, l’état des stocks et les notes lors de l’indexation.
Si ces attributs sont absents du HTML de la “Page testée”, même si la page frontale s’affiche normalement, les pages de résultats de recherche (SERP) n’afficheront pas les étoiles ou les aperçus de prix.
Une attention particulière doit être portée aux journaux d’erreurs de la console, car l’environnement WRS impose des limites de consommation de mémoire plus strictes que les navigateurs des utilisateurs ordinaires.
Si un script consomme trop de ressources CPU, Googlebot peut abandonner le rendu de la page, ce qui ne laisse dans l’index qu’un modèle de structure vide.
- Nombre total de ressources chargées : Il est conseillé de limiter les ressources JS demandées par une seule page à moins de 50. Trop de requêtes parallèles entraînent des retards d’ordonnancement du WRS, augmentant le risque d’échec du rendu.
- Surveillance des erreurs d’exécution de script : L’outil capture des exceptions fatales telles que
ReferenceErrorouTypeErrorqui brisent la chaîne de rendu. Si vous voyez des erreurs d’incompatibilité avec les normes ES dues à l’absence de Polyfill, vous devez immédiatement ajuster la cible de compilation de vos outils de construction (build tools). - Validité des réponses API : Vérifiez tous les points de terminaison (endpoints) API qui extraient dynamiquement du contenu via la liste des ressources. Si le code d’état affiche “Bloqué” ou “Délai dépassé”, cela signifie que Googlebot est intercepté par un pare-feu ou que les performances de l’API ne satisfont pas au seuil d’exploration.
Chaque “Avertissement” ou “Erreur” dans le rapport généré par cet outil correspond au comportement de Googlebot dans un environnement d’indexation réel.
Si l’outil indique “Impossible de charger certains scripts”, même si ces scripts fonctionnent normalement dans le navigateur Chrome d’un utilisateur, cela doit être pris au sérieux. Il est possible que les plages d’adresses IP des robots de Google aient subi une limitation de débit (Rate Limiting) de la part du serveur lors de l’accès à ces ressources.
Chrome DevTools
Dans un environnement de développement local, le panneau “Conditions du réseau” (Network conditions) des Chrome DevTools est le point de départ pour simuler le comportement d’exploration de Googlebot.
En appuyant sur F12 ou par clic droit “Inspecter” pour ouvrir la barre d’outils, accédez à More tools -> Network conditions dans le menu des trois points en haut à droite.
Dans ce panneau, décochez “Utiliser les paramètres par défaut du navigateur” (Use browser default) et sélectionnez manuellement Googlebot dans la liste déroulante.
Cette opération modifie la chaîne User-Agent envoyée par le navigateur, par exemple en la changeant pour Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html).
L’intérêt de cette étape est de vérifier si le serveur contient une logique spécifique pour les robots.
Si le serveur est configuré pour renvoyer un code HTML différent selon l’UA, l’environnement local présentera immédiatement des résultats de réponse radicalement différents de ceux d’un accès utilisateur normal.
Le personnel technique doit comparer les informations d’en-tête de réponse à ce moment-là, en vérifiant si le Content-Type ou les instructions de contrôle du cache (Cache-Control) ont changé.
Si le serveur renvoie un accès refusé 403 ou une redirection inattendue 301 pour Googlebot, cela signifie que le chemin d’indexation du moteur de recherche a été bloqué au niveau du serveur.
Pour simuler la “première vague d’indexation” (First-wave indexing) de Googlebot, il est impératif de tester le comportement de la page en désactivant JavaScript.
Accédez à la page des paramètres (Settings) de DevTools, trouvez la section Débogueur (Debugger) dans les préférences, et cochez “Désactiver JavaScript” (Disable JavaScript).
Après avoir rafraîchi la page, le navigateur ne présentera que la structure HTML brute envoyée par le serveur.
Pour les sites utilisant une architecture d’application monopage (SPA), cette opération entraîne souvent l’affichage d’une page totalement blanche ou affichant uniquement une animation de chargement.
Si les informations textuelles principales, le menu de navigation ou la liste des produits disparaissent après la désactivation des scripts, cela signifie que le moteur de recherche doit impérativement passer par la phase complexe de la “deuxième vague d’indexation”, à savoir le rendu WRS, pour obtenir le contenu.
À ce stade, il convient de noter le nombre d’octets du HTML original, par exemple 15 Ko de code cadre de base, et de le comparer avec le DOM après rendu complet pour déterminer l’ampleur du contenu injecté par JS.
“Dans un environnement de simulation local, désactiver JavaScript est le test de résistance le plus efficace. Si le HTML original d’une page manque de balises H1 ou de paragraphes de texte contenant les informations sémantiques principales, alors cette page court un risque extrêmement élevé d’être indexée comme une page blanche lors de fluctuations du réseau ou de saturation des quotas de rendu de Google.”
L’environnement dans lequel s’exécute Googlebot n’est pas un ordinateur de bureau haute performance. En utilisant le panneau “Performance” de DevTools, on peut simuler plus fidèlement la capacité de calcul de Googlebot.
Dans les paramètres de performance, réglez la limite du processeur (CPU Throttling) sur un ralentissement de 4x ou 6x.
Si une tâche de rendu qui ne prend que 800 millisecondes sur un MacBook haute performance passe à 5500 millisecondes avec un ralentissement de 6x, elle a déjà atteint le seuil courant de rendu de 5 secondes de Googlebot.
En examinant les tâches longues (Long Tasks) dans le graphique “Flame”, on peut identifier quels bibliothèques JS volumineuses bloquent le thread principal, causant ainsi des retards de rendu.
Si des indicateurs quantitatifs tels que le temps de blocage total (TBT) dépassent 2000 millisecondes dans cet environnement, cela présage généralement que Googlebot pourrait abandonner l’attente avant que le contenu ne soit totalement généré, pour capturer à la place un instantané DOM incomplet.
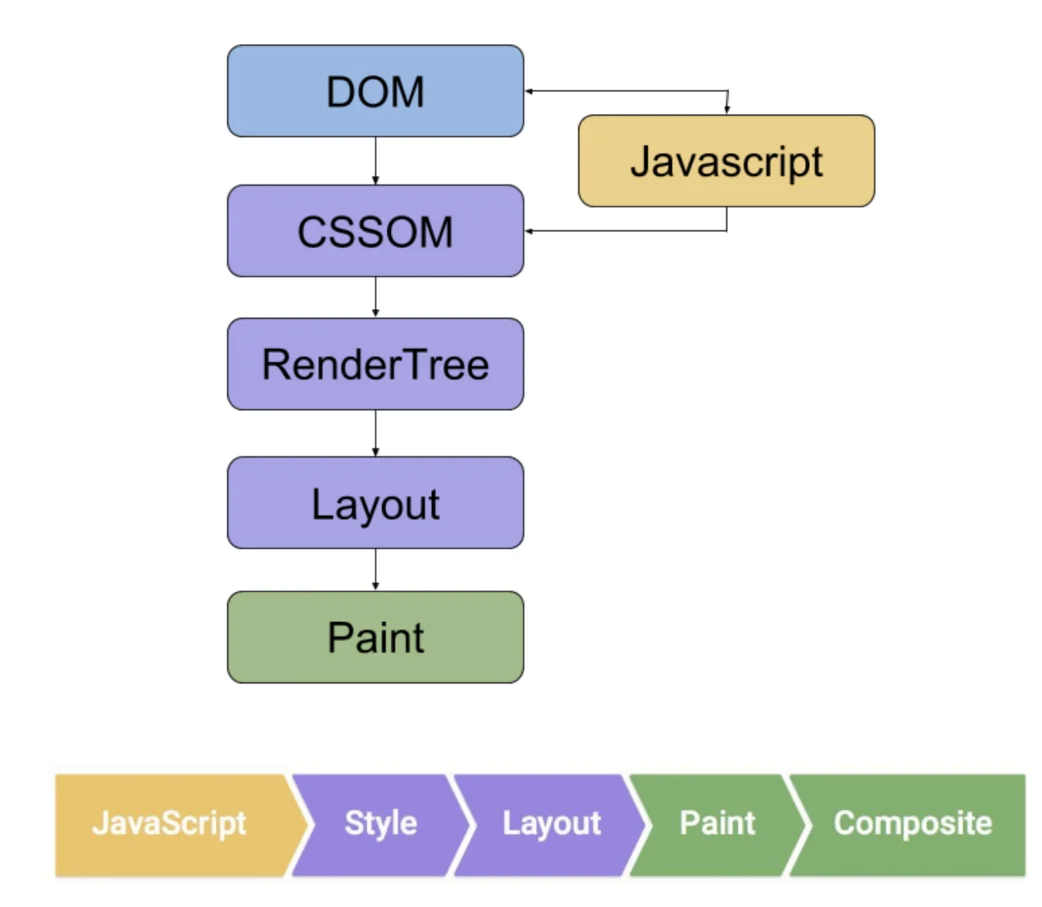
Validation manuelle par navigateur
La validation manuelle confirme l’état du rendu en comparant les différences de données entre le HTML initial et le DOM rendu.
Googlebot utilise le dernier moteur de rendu Chrome, mais si l’exécution JS dépasse le seuil de 5 secondes ou si les requêtes de ressources par page dépassent 50, le contenu risque de ne pas être indexé.
Le test manuel doit porter sur la chaîne de chargement des ressources, en s’assurant que l’attribut href des balises <a> est prévisible dans le code source HTML, et non généré dynamiquement via des événements onclick, afin de garantir la connectivité du chemin d’exploration.
Code source et DOM en temps réel
Le code consulté via view-source dans un navigateur reflète le flux de texte brut envoyé par le serveur, tandis que le panneau Elements des outils de développement affiche le modèle d’objet de document (DOM) en mémoire après analyse par le moteur de rendu, exécution des scripts et correction d’erreurs.
Pour les sites utilisant une architecture d’application monopage (SPA), le code source original ne contient souvent qu’une balise conteneur vide avec id="app" ou id="root" ainsi que plusieurs références de scripts dont la taille totale dépasse 500 Ko.
En comparant le nombre de caractères de texte brut dans le code source avec celui du DOM rendu, lorsque ce rapport dépasse 1:20 (c’est-à-dire que le HTML original n’a que 100 mots alors que le rendu en atteint 2000), la première vague d’exploration du moteur de recherche ne pourra pratiquement obtenir aucune information sémantique valide.
Cette différence entraînera un état de vide de contenu pour la page au début de l’indexation, devant attendre le traitement secondaire de la file d’attente de rendu.
| Dimension de comparaison | Caractéristiques des données du code source original (HTML initial) | Caractéristiques des données du DOM après rendu (DOM rendu) | Impact de la différence technique sur l’indexation |
|---|---|---|---|
| Nombre total de nœuds DOM | Généralement moins de 50 nœuds, structure extrêmement plate. | Peut dépasser 1500 nœuds, profondeur de hiérarchie accrue. | L’augmentation spectaculaire des nœuds indique que la génération de contenu dépend entièrement de JS. |
| État des balises Meta | Contient des titres génériques ou des descriptions de remplacement codées en dur. | Contient des balises SEO spécifiques à la page injectées dynamiquement par script. | Les outils d’exploration peuvent enregistrer des métadonnées de page erronées avant l’exécution du script. |
| Balise Canonical | Absente ou pointant vers l’URL fixe de la page d’accueil du site. | Mise à jour dynamique vers le chemin absolu standard de la page actuelle. | Une incohérence des balises entraînera des conflits d’analyse des attributs de page pour le moteur de recherche. |
| Données structurées JSON-LD | Vide ou contenant seulement un cadre Schema de base dans le fragment de code. | Rempli avec les données complètes de prix des produits, d’avis ou de stock. | Détermine si la page de résultats de recherche (SERP) peut afficher des extraits enrichis. |
| Liens internes | La barre de navigation peut être vide, les liens ne sont pas encore générés. | Contient des balises <a> complètes et des chemins de catégories dynamiques. |
Affecte l’efficacité du robot pour découvrir d’autres URL profondes sur le site. |
Lors d’une comparaison approfondie, en saisissant document.body.innerText.length dans la console, on peut obtenir le nombre total de caractères après rendu et le comparer à la taille en octets du fichier de code source.
Si la taille du code source est de 30 Ko mais que l’innerText après rendu atteint 15 000 caractères, le poids textuel principal est entièrement concentré sur la couche de rendu.
À ce moment-là, s’il existe dans le script une fonction récursive prenant plus de 200 ms d’exécution, ou si une API externe avec un temps de chargement supérieur à 2,0 s est référencée, le moteur de rendu de Googlebot pourrait arrêter l’enregistrement avant l’injection complète du contenu à cause de sa stratégie d’allocation des ressources.
| Indicateur quantitatif | Seuil de risque | Conséquences réelles sur l’exploration et l’indexation |
|---|---|---|
| Écart de ratio de texte (Text Ratio Gap) | > 80 % du texte généré par JS | La page est très susceptible d’être jugée comme ayant un “contenu pauvre” dans un environnement sans script. |
| Taux de réussite de l’extraction de liens | < 5 balises <a> valides dans le code source |
Le budget d’exploration (Crawl Budget) sera gaspillé dans une attente infinie. |
| Occupation mémoire de l’exécution de script | Consommation de mémoire de pile supérieure à 50 Mo | Le serveur de rendu pourrait interrompre de force la tâche de rendu en raison de limites de mémoire. |
| Intégrité du HTML au-dessus de la ligne de flottaison | < 10 % du contenu visuel principal visible dans le code source | L’utilisateur verra un écran blanc prolongé sur un réseau lent, nuisant aux signaux de classement. |
Vérifiez le menu de navigation dans le panneau Elements. Si un lien s’affiche sous la forme <a href="javascript:void(0)" onclick="navigateTo('/page')">, cela ressemble à un lien dans le DOM rendu, mais pour les robots des moteurs de recherche, c’est une impasse intraçable.
L’attribut href standard doit déjà exister dans le HTML original renvoyé par le serveur, ou être généré au format standard <a href="/chemin-cible"> après l’exécution du script.
Les sites possédant une structure de liens HTML originaux complète voient leurs nouvelles pages indexées généralement 40 % à 70 % plus rapidement que les sites dépendant entièrement de l’injection de liens par JS.
S’il existe une balise meta noindex dans le code source et que la logique du script tente de la supprimer pour la remplacer par index après le rendu, cette pratique est souvent inefficace.
Les moteurs de recherche respectent généralement en priorité les instructions trouvées dans le HTML initial, empêchant la page d’entrer dans le processus d’indexation normal.
Validation par simulation d’environnement
Ouvrez les outils de développement (DevTools) dans le navigateur Chrome, appuyez sur Ctrl+Shift+P pour appeler le menu de commande, saisissez Disable JavaScript et validez. C’est le point de départ pour simuler le premier état d’exploration du moteur de recherche.
Rechargez la page avec les scripts désactivés. Si l’écran devient blanc ou n’affiche que le cadre de base, cela signifie que le HTML initial côté serveur ne contient aucun contenu textuel substantiel.
Pour un fichier HTML de 100 Ko, si 90 % de son contenu textuel dépend d’un pack JavaScript de 2 Mo chargé ultérieurement, alors en cas de latence réseau ou d’erreur d’exécution de script, le moteur de recherche ne risque d’enregistrer qu’une balise conteneur vide.
| Paramètre de simulation | Norme de configuration et valeur | Résultats observés et indicateurs de données |
|---|---|---|
| Limitation du réseau (Network Throttling) | Fast 3G (simule 1,5 Mbps en descente, 40 ms de latence) | Si le rendu du contenu principal prend plus de 5000 ms (5 secondes), la file d’attente de rendu de Google pourrait cesser d’attendre. |
| Limitation du processeur (CPU Throttling) | Ralentissement 4x (simule les performances d’un processeur mobile) | Lorsque le temps d’analyse du script (Script Evaluation) dépasse 1,5 seconde, l’occupation prolongée du thread principal retarde le rendu du contenu. |
| Simulation de User-Agent | Googlebot Smartphone (Chrome/W.X.Y.Z) | Vérifie si le serveur renvoie une erreur 403 ou un code d’adaptation mobile spécifique. |
| Taille de la fenêtre d’affichage (Viewport) | 411 x 731 pixels (largeur mobile standard) | Confirme si le contenu se charge automatiquement sans interactions de type clic ou défilement (scroll). |
Remplacez la chaîne User-Agent du navigateur par Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html).
Cochez Disable cache dans le panneau Network et observez la chaîne de chargement des ressources sous l’identité de Googlebot.
Dans un processus d’exploration standard, Googlebot ne charge généralement pas tous les fichiers multimédias ; il priorise l’analyse du texte et des données structurées.
Si la page détecte le User-Agent par script et applique une logique différente, par exemple en fermant certaines interfaces asynchrones pour les robots, la structure DOM dans le panneau Elements sera totalement différente de celle vue par un utilisateur normal.
Réglez manuellement la vitesse du réseau sur Fast 3G et limitez les performances du processeur à un ralentissement 4x dans le panneau Network.
Le serveur de rendu de Googlebot, traitant des centaines de millions de pages web à travers le monde, alloue des ressources de calcul limitées à chaque page. Enregistrez le processus de chargement via le panneau Performance et examinez particulièrement l’activité du thread Main.
Si les tâches longues (Long Tasks) générées par Evaluate Script dépassent 50 millisecondes et occupent plus de 70 % du cycle de chargement au total, alors dans un environnement d’exploration réel, le moteur de rendu pourrait terminer l’enregistrement de l’instantané avant que le contenu ne soit totalement injecté.
Si l’intervalle entre le First Contentful Paint (FCP) et le Largest Contentful Paint (LCP) s’étire à plus de 3 secondes à cause d’une exécution JS trop longue, la probabilité que le moteur de recherche capture une page incomplète augmente d’environ 40 %.
Utilisez l’onglet Sensors en bas des outils de développement pour simuler manuellement différentes positions géographiques (comme San Francisco ou Londres).
Les nœuds d’exploration de Googlebot sont principalement répartis sur le territoire américain. Si la logique JS du site contient des redirections automatiques basées sur l’adresse IP ou une génération de contenu basée sur l’horodatage local, cela peut amener à explorer une version de page ne correspondant pas à la région de l’audience cible.
Vérifiez les messages d’erreur dans le panneau Console, en particulier ReferenceError ou TypeError.
Bien que la version du moteur de rendu de Google (Evergreen Googlebot) reste à jour, il peut exister des différences de support pour certaines API Web très récentes (telles que les dernières WebGPU ou certaines versions de WebAssembly).
Si la compatibilité Polyfill n’est pas bien gérée dans le code, le script plantera à mi-chemin, entraînant l’arrêt de la construction de l’arbre DOM.
- Limite du nombre de requêtes : Comptez le nombre total de requêtes réseau émises avant la fin du rendu. Si une seule page demande plus de 50 ressources JS ou CSS, en raison des limites de simultanéité du navigateur et des quotas de ressources des robots, certains scripts pourraient ne pas être chargés à temps.
- État du Shadow DOM : Vérifiez la présence de balises
#shadow-root (closed)dans le panneau Elements. Googlebot peut analyser le Shadow DOM en mode Open, mais le contenu en mode Closed est invisible pour les robots ; assurez-vous que tous les Web Components sont en mode Open. - Validation du format des liens : Dans le DOM rendu, utilisez
Ctrl+Fpour rechercher les balises<a. Assurez-vous que tous les liens de redirection contiennent un attributhrefcomplet. Si la redirection est contrôlée par des événements JS tels quewindow.location.hrefourouter.pushsans laisser d’ancres standard dans le HTML, le moteur de recherche ne pourra pas découvrir ces sous-pages. - Lazy Load des images : Vérifiez si les balises
<img>ont déjà remplacé le contenu dedata-srcpar l’attributsrcsans faire défiler la page. Googlebot peut simuler un défilement partiel, mais pour les scripts dépendant d’écouteurs d’événementsscrollcomplexes, l’efficacité de l’exploration est instable. Utiliser l’attribut standardloading="lazy"est une pratique plus sûre.
Comparez la taille en octets et le nombre de nœuds de texte entre le HTML initial et le DOM rendu.
Si la différence de taux de couverture textuelle entre les deux dépasse 80 % et que la majeure partie du contenu textuel n’est injectée qu’après l’événement DOMContentLoaded, cela signifie que le SEO du site dépend fortement de l’efficacité du rendu.
Il est conseillé d’enregistrer le Total Blocking Time (TBT) lors des tests ; si cette valeur dépasse 300 ms, cela présage généralement que le processus d’exécution des scripts entravera l’analyse du DOM par le robot.
Consultez le taux d’utilisation des fichiers JS via le panneau Coverage de Chrome. Si 80 % du code d’un script de 500 Ko n’est pas exécuté lors du chargement de l’écran initial, ce code redondant consommera inutilement les capacités de calcul du serveur de rendu, affectant ainsi la vitesse d’indexation du contenu.
Outils de robots professionnels
Des outils d’exploration professionnels peuvent simuler l’environnement Chrome (comme Screaming Frog v20+).
Les données indiquent que le coût d’exploration avec exécution de scripts est 20 fois plus élevé que celui du HTML statique.
Lorsque la différence de nombre de mots HTML entre “avant rendu” et “après rendu” dépasse 10 %, ou que la différence de nombre de liens internes identifiés dépasse 5 %, le taux de réussite de l’indexation diminue généralement.
La détection doit se concentrer sur le taux de réussite du rendu dans les 5 secondes, et vérifier si le chargement des scripts a échoué en raison d’un code d’état 403.
Screaming Frog SEO Spider
Lors d’une exploration à grande échelle avec Screaming Frog, passer le mode de rendu de “Texte uniquement (Text Only)” à “JavaScript” transforme le comportement du robot d’une simple requête HTTP en une simulation complète de navigateur.
Le logiciel lance une instance Headless Chrome sous-jacente pour analyser chaque fichier de script sur les pages web.
Concernant la configuration technique, l’utilisateur doit explicitement sélectionner l’option JavaScript dans le menu Configuration > Spider > Rendering.
Les changements au niveau des données sont très significatifs : le processus d’exploration avec exécution de JavaScript augmente généralement les besoins en mémoire vive (RAM) de 5 à 10 fois.
Par exemple, lors de l’exploration de 100 000 pages contenant des frameworks complexes comme React ou Angular, il est conseillé d’allouer au moins 16 Go à 32 Go de mémoire au logiciel, sinon le processus de rendu Chrome risque de planter par manque de ressources.
Le robot simule la version du moteur de rendu de Chrome pendant son fonctionnement, garantissant que la structure DOM explorée reste cohérente avec l'”Evergreen Chrome” actuellement utilisé par Googlebot.
| Catégorie d’indicateur | HTML original (Source) | HTML après rendu (Rendered) | Seuil de différence suggéré |
|---|---|---|---|
| Nombre de mots (Word Count) | Contient seulement le cadre de base et les métadonnées | Contient le texte chargé de manière asynchrone | Différence > 15 % nécessite une vérification manuelle |
| Nombre de liens internes (Internal Links) | 0 ou très peu de liens de remplacement | Liens de navigation et de produits générés dynamiquement | Différence > 0 indique un risque d’exploration |
| Balise Canonical | Peut être absente ou pointer vers une valeur par défaut | Version finale modifiée via JS | Doit se baser sur la version après rendu |
| Taille de la page (Size) | Généralement < 50 Ko | Peut augmenter jusqu’à 500 Ko – 2 Mo | Une taille excessive peut entraîner une troncature par Google |
Lorsque le logiciel simule l’exécution des scripts, le AJAX Timeout (Délai d’attente du chargement asynchrone) est généralement réglé par défaut sur 5 secondes, ce qui est similaire à la stratégie de Googlebot pour traiter les scripts.
Si l’interface de données d’une page répond lentement, faisant que le contenu n’est inséré dans le DOM qu’après 5 secondes, alors le résultat exploré par Screaming Frog sera une page “coquille vide”.
En comparant les données de la colonne Word Count, on peut quantifier ce phénomène :
Si le nombre de mots après rendu est inférieur à celui du code source, ou si les deux sont identiques alors que la page contient en réalité beaucoup de texte, cela indique généralement que le script de rendu n’a pas pu terminer son exécution dans le temps imparti.
Pour les tests sur des sites de commerce électronique, si la liste des produits est chargée par défilement dynamique, le robot peut également déclencher l’exécution des scripts en configurant “Window Size” ou en simulant un défilement vers le bas, permettant ainsi de capturer les informations sur les produits initialement cachés.
Pour l’audit technique de grands sites, l’utilisation de la “JavaScript Rendering Table” dans la fonction “Bulk Export” permet d’exporter un rapport sur les différences de rendu de l’ensemble du site.
Ce rapport liste ligne par ligne les changements de Title, Meta Description et balises H1 pour chaque URL avant et après rendu.
Dans des cas réels, si l’on découvre que la balise H1 après rendu devient “Loading…” ou “Undefined”, cela prouve que le moteur de recherche a capturé un code d’état intermédiaire et non le contenu final.
L’onglet “Resource” du logiciel enregistre le code d’état HTTP de chaque fichier de script (.js) et feuille de style (.css).
Si certains scripts fonctionnels renvoient un 403 Forbidden, c’est généralement parce que le pare-feu du serveur (WAF) a identifié à tort le comportement Headless Chrome du robot comme une attaque malveillante et l’a intercepté, empêchant ainsi la mise en page et le contenu de s’afficher normalement.
| État de la ressource de rendu | Cause de l’occurrence | Impact sur l’exploration |
|---|---|---|
| Blocked by robots.txt | Le chemin du script est défini sur Disallow | Googlebot ne peut pas lire le script, échec du rendu |
| Status Code: 429 | La fréquence des requêtes est trop élevée, déclenchant une limitation | Certaines ressources de la page ne sont pas totalement chargées, contenu manquant |
| Status Code: 404 | Le chemin du fichier de script est invalide | Les composants dynamiques dépendant de ce script ne peuvent pas s’afficher |
| Timeout (Exceeded 5s) | Réponse de l’interface lente ou logique de script complexe | Le HTML exploré est vide ou contient des messages d’erreur |
La vue “Rendered Page” fournie par le logiciel permet aux utilisateurs de comparer côte à côte l’instantané du code original et l’instantané visuel après rendu.
De cette manière, on peut découvrir intuitivement les contenus cachés par JavaScript, comme le texte situé dans des onglets (Tabs) qui ne s’affichent qu’après un clic.
Si le contenu textuel d’une page représente moins de 20 % dans le HTML original, et que 80 % du contenu dépend du rendu, alors la stabilité de cette page dans la base d’indexation de Google sera mise à l’épreuve.
Screaming Frog peut également capturer les Console Errors (erreurs de console) ; si une erreur de syntaxe JavaScript fatale survient lors du chargement de la page, le logiciel l’affichera en surbrillance dans le rapport.
Lors du traitement de centaines de milliers d’adresses web, il est conseillé d’activer les options “Store Images” et “Store Rendered HTML”, ce qui permet de consulter à tout moment un instantané de rendu de n’importe quelle page une fois l’exploration terminée.
En analysant les différences de “Link Discovery”, on peut calculer quel pourcentage de liens internes nécessite l’exécution de scripts pour être découvert.
Si ce pourcentage dépasse 30 %, la profondeur d’exploration (Crawl Depth) du site deviendra incontrôlable à cause des délais d’exécution des scripts.
Lumar (DeepCrawl)
Lumar utilise une puissance de calcul distribuée dans le cloud, spécialisée dans l’analyse automatisée pour les grands sites possédant des millions d’URL.
Lors du traitement de tâches nécessitant l’exécution de JavaScript, le système fonctionne via des milliers d’instances de navigateurs simulés en arrière-plan.
Les outils locaux classiques sont limités par la mémoire physique ; par exemple, un ordinateur avec 32 Go de RAM ne peut généralement supporter que 20 à 50 threads parallèles en mode rendu.
En revanche, Lumar fonctionne sur des serveurs cloud et peut s’étendre automatiquement à plus de 500 threads selon l’ampleur de la tâche, garantissant l’achèvement de l’exploration avec rendu complet de 1 million de pages en 24 heures.
Si l’exécution d’un script sur une page dépasse 5000 millisecondes (soit 5 secondes), le système marquera cette URL comme “page à coût élevé”, car Googlebot n’attend généralement pas trop longtemps pour une ressource individuelle lors d’un accès réel, ce qui peut entraîner un vide de contenu dans l’index.
Dans un projet React ou Vue standard, le HTML original peut ne contenir que 2 Ko à 5 Ko de code cadre de base, alors que l’arbre DOM (DOM Tree) après rendu peut gonfler jusqu’à 300 Ko à 800 Ko.
Cette augmentation d’octets de plus de 100 fois montre que la page web dépend énormément des scripts.
Les indicateurs fournis par Lumar incluent le nombre total de nœuds DOM (DOM Node Count) ; si ce nombre dépasse les 1500 nœuds suggérés par Google, l’efficacité du rendu diminuera considérablement.
En enregistrant le Time to Interactive (temps avant interactivité) et le Total Blocking Time (temps de blocage total) dans le cloud, cet outil peut identifier quels fichiers JS (par exemple, un pack vendor.js dépassant 500 Ko) entravent l’affichage normal du contenu.
Pour le commerce électronique à grande échelle ou les sites multinationaux, en lançant des requêtes depuis des nœuds de serveurs dans différentes régions, il est possible de détecter si certains scripts responsables du rendu de contenu ne parviennent pas à se charger dans des zones spécifiques à cause d’une erreur de configuration CDN.
Le rapport de données listera le pourcentage de ressources de scripts avec des codes d’état 4xx et 5xx.
Si 20 % des requêtes de scripts d’une page renvoient une erreur 403 (généralement à cause d’un blocage robots.txt ou d’un pare-feu), le résultat du rendu de cette page sera incomplet.
Le système de rapports de Lumar génère une “carte des différences de rendu”, indiquant en détail les changements du nombre de liens internes de la page selon que JavaScript est activé ou désactivé.
Si, après avoir désactivé les scripts, le nombre de liens sur la page passe de 200 à 0, cela prouve que la structure d’adressage du site dépend entièrement de l’exécution dynamique, ce qui a un impact négatif sur la vitesse à laquelle Googlebot découvre de nouvelles pages.
La plateforme permet également d’intégrer les données de rendu explorées avec l’API de Google Search Console.
Si les données montrent que le nombre de mots a augmenté de 300 % après rendu, mais que le trafic de recherche n’a pas progressé en conséquence, cela peut signifier que le contenu inséré dynamiquement n’a pas été identifié efficacement par Google.
Lumar produit l’indicateur Rendered Page Word Count et le compare au Source HTML Word Count.
Plus l’écart de ratio (Ratio Gap) est grand, plus la page a tendance à être instable en termes de fréquence d’exploration. En observant plus de 500 000 échantillons, lorsque le Rendering Gap dépasse 80 %, le délai d’indexation de la page augmente généralement de 3 à 7 jours.


