




















Oui, les paramètres d’URL (tels que le tri ?sort, le filtrage ?color ou les identifiants de suivi) sont les principaux facteurs provoquant l’indexation de contenu dupliqué par Google.
Pour garantir que le trafic de recherche est dirigé avec précision vers la page cible, les actions suivantes sont recommandées :
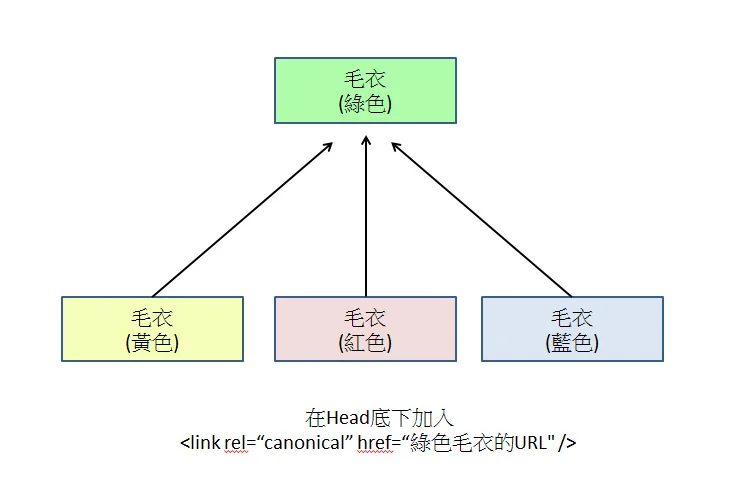
Configurer les balises Canoniques
Ajoutez rel="canonical" dans le code HTML de toutes les pages variantes, pointant vers l’URL principale unique.
Gérer les chemins d’exploration
Bloquez les paramètres de suivi marketing inutiles (tels que utm_) via le fichier Robots.txt.
Consolider les signaux de classement
Cela aide Google à concentrer le « score de confiance » de toutes les pages de paramètres sur la page principale, évitant ainsi une baisse de trafic due à la concurrence interne.
Redondance du contenu
Les paramètres d’URL peuvent entraîner la génération d’un grand nombre d’adresses dupliquées pour une même page.
Par exemple, une page de commerce électronique dotée de 5 filtres de couleur et de 3 méthodes de tri générera plus de 15 URL différentes.
Environ 40 % du budget d’exploration des grands sites est souvent consommé par ces variantes de paramètres.
Lorsque Google indexe 200 pages d’accueil identiques avec des suffixes de suivi UTM, l’autorité de recherche de la page principale est diluée, ce qui entraîne une baisse des performances de classement d’environ 25 %.
Dispersion des liens
Dans le mécanisme d’indexation de Google, les URL avec différents suffixes sont considérées comme des entités indépendantes.
Par exemple, si une page de documentation technique reçoit des backlinks de 50 domaines différents, mais que 20 de ces liens pointent vers la version avec ?utm_medium=email et 10 autres pointent vers la version avec ?ref=footer, l’URL principale ne recevra en réalité que 40 % de l’autorité totale.
Selon l’analyse d’échantillons de données Ahrefs, ce phénomène de dilution de l’autorité peut faire chuter le classement réel d’une page de 3 à 5 places par rapport aux prévisions lors de la compétition sur des mots-clés de haute difficulté.
Lorsqu’ils identifient ces chemins dispersés, les robots d’exploration ne regroupent pas automatiquement la force de tous les liens vers la page d’origine, à moins que le site n’ait explicitement configuré la logique de traitement dans le code source.
Dans le modèle de calcul du PageRank, la transmission des liens suit une règle mathématique basée sur un facteur d’amortissement de 0,85.
Chaque lien entrant dans le site accumule de l’autorité pour une URL spécifique.
Lorsque cette autorité est allouée à des suffixes générés de manière non statique tels que ?sessionid ou ?click_id, le « score de confiance » de la page principale ne parvient pas à atteindre le seuil nécessaire pour déclencher un classement en première page.
Dans la compétition du secteur SaaS sur le marché américain, les trois premières pages possèdent généralement des profils de liens extrêmement propres.
Si l’autorité d’une page est dispersée sur plus de 5 versions de paramètres différentes, Google peut afficher ces pages alternativement dans les résultats de recherche. Cet état de concurrence interne empêche les performances de la page principale de se stabiliser.
De nombreuses plateformes de commerce électronique utilisant les architectures Magento ou Salesforce Commerce Cloud génèrent des liens internes avec un grand nombre de paramètres dans la navigation par fil d’Ariane ou les filtres latéraux.
Si la navigation interne pointe fréquemment vers category?sort=newest au lieu d’une adresse de catégorie statique, le flux d’autorité au sein du site sera dévié.
Lorsqu’un robot d’exploration découvre lors du processus d’exploration qu’une même cible possède plusieurs entrées avec des structures d’URL différentes, le niveau de priorité de planification pour cette page diminue.
Les plateformes de médias sociaux et les systèmes publicitaires tiers imposent souvent l’ajout de leurs propres paramètres lors du processus de redirection, tels que ?fbclid ou ?gclid.
Si la page manque d’une balise rel=”canonical” efficace, l’algorithme de Google pourrait, après un cycle d’exploration de plusieurs semaines, sélectionner par erreur une page avec des paramètres publicitaires comme représentant de recherche pour ce contenu.
Cette situation peut entraîner une baisse du taux de clic d’environ 15 %, car les utilisateurs sont nettement moins enclins à cliquer lorsqu’ils voient des URL longues et confuses dans les résultats de recherche que lorsqu’ils voient des adresses statiques concises.
Une fois que les liens externes sont regroupés sur ces versions de paramètres temporaires, tenter de récupérer totalement cette force vers la page principale par des moyens techniques ultérieurs nécessite souvent un processus de ré-indexation pouvant durer plusieurs mois.
Effet multiplicateur de chemin
Dans les architectures de commerce électronique modernes (comme Shopify ou Magento), lorsqu’une page de catégorie de base possède plusieurs attributs de filtrage, chaque nouvelle dimension de paramètre se combinera avec les paramètres existants.
Prenons l’exemple d’une page de catégorie de chaussures de sport standard : si cette page propose 10 options de couleur, 12 spécifications de taille, 5 filtres de marque et 4 tris par plage de prix, les chemins d’URL indépendants générés théoriquement atteindront 10 × 12 × 5 × 4 = 2400.
Si la logique du programme permet l’inversion de l’ordre des paramètres (par exemple, le chemin pour choisir d’abord la couleur puis la taille est différent de celui pour choisir d’abord la taille puis la couleur), ce nombre augmentera encore plus.
Sous cet effet multiplicateur de chemin, ce qui était à l’origine une page avec un seul contenu réel se transforme, aux yeux du robot Google, en des milliers de points d’entrée différents.
Ces chemins redondants, en l’absence d’une gestion efficace, occuperont plus de 65 % du quota d’exploration des sites de grande taille, empêchant les pages de détails de produits qui ont réellement besoin d’être mises à jour d’obtenir une fréquence de balayage suffisante.
| Étape de combinaison des paramètres | Échelle des facteurs variables | Nombre d’URL uniques générées | Estimation de l’occupation des ressources d’exploration |
|---|---|---|---|
| Page de catégorie originale | 1 | 1 | 0,01% |
| Filtrage par attributs (Couleur + Marque) | 10 x 8 | 80 | 2,5% |
| Superposition de spécifications (Couleur + Marque + Taille) | 80 x 12 | 960 | 18,0% |
| Superposition de toutes les fonctionnalités (Attributs + Spécifications + Tri + Pagination) | 960 x 3 x 10 | 28 800 | Plus de 70% |
Lorsque Googlebot traite cet « espace infini » généré par l’empilement de paramètres, et que l’espace d’URL d’un site devient excessivement gonflé, la proportion d’explorations efficaces que le robot peut effectuer par unité de temps chute considérablement.
Une analyse des logs d’un site de vente au détail multinational a révélé que le robot a exploré 15 000 URL en 24 heures, mais que seulement 1 200 d’entre elles étaient des pages statiques ayant un potentiel de classement. Les 92 % restants des comportements d’exploration ont été gaspillés sur des variantes de paramètres composées de ?color=, ?size= et ?sort=.
Dans le processus où l’algorithme tente de choisir une « version canonique » parmi 200 chemins similaires, si des signaux techniques clairs font défaut, l’URL sélectionnée n’est souvent pas la page standard attendue par les développeurs, ce qui provoque l’affichage d’adresses avec des paramètres désordonnés dans les pages de résultats de recherche.
Chaque fois que Googlebot demande une URL avec des combinaisons complexes de paramètres, la base de données backend doit généralement exécuter des requêtes de jointure multi-tables pour générer la vue correspondante.
Sous la pression d’une exploration à haute fréquence, trop de demandes de combinaisons de paramètres entraîneront une augmentation du TTFB (Time to First Byte) de 300 à 800 millisecondes.
L’augmentation du délai de réponse déclenchera les mécanismes de protection de Googlebot, réduisant ainsi la fréquence d’exploration de l’ensemble du domaine.
Selon un rapport d’étude portant sur 500 sites de commerce électronique mondiaux, les pages dont la profondeur de paramètres dépasse 3 couches ont une probabilité d’être indexées avec succès par Google inférieure de 42 % à celle des URL simplifiées.
L’arrangement désordonné des paramètres entraîne une désintégration profonde des signaux de liens. Lorsqu’une page avec un paramètre promotionnel spécifique ?promo=winter est citée par un site externe, alors que la navigation interne pointe vers la version ?sort=new, les signaux d’autorité des deux sont totalement isolés dans la base de données interne de Google.
Dans les sites où aucune stratégie de canonisation d’URL n’a été mise en œuvre, chaque page de produit populaire possède en moyenne 14 variantes de paramètres différentes, ce qui entraîne une dispersion du taux de clic de ce produit vers les différents sous-chemins dans les résultats de recherche.
Lors du traitement de cette redondance massive de chemins, le simple fait de s’appuyer sur le blocage par robots.txt ne parvient souvent pas à résoudre les problèmes d’indexation déjà existants.
Les recommandations officielles de Google Search Central préconisent l’utilisation de la balise rel=”canonical” pour forcer la fusion de ces chemins générés par l’effet multiplicateur.
Après un déploiement correct des balises canoniques, la visibilité de recherche des pages de catégories concernées a augmenté en moyenne de 22 % en 60 jours.
Gaspillage du budget d’exploration
Le nombre de requêtes d’exploration que Googlebot peut effectuer sur un site par unité de temps est limité.
Lorsque le système génère des dizaines de milliers d’URL avec paramètres (telles que ?variant=123 ou ?sort=desc), le robot explorera ces chemins de faible qualité en priorité.
Selon le mécanisme d’exploration de Google, si le nombre d’URL dupliquées dépasse de 10 fois le contenu réel, la fréquence d’exploration des pages importantes chutera de plus de 50 %.
Ce phénomène fait que les pages nouvellement publiées peuvent ne pas être découvertes pendant 72 heures, tandis que la fréquence d’exploration des URL d’origine non paramétrées sera considérablement réduite.
Impact des paramètres
Le système de planification d’exploration des moteurs de recherche classera les paramètres en « paramètres actifs » et « paramètres passifs » selon le degré de modification réelle du contenu de la page par ces derniers.
Les identifiants de session (Session IDs) figurent parmi les paramètres les plus destructeurs pour les ressources d’exploration.
Ces paramètres tels que ?sid=9928374 ou ?sessionid=abc123 sont généralement générés dynamiquement par le backend pour suivre les utilisateurs dans le protocole HTTP sans état.
Comme chaque visiteur, voire chaque visite d’un robot, peut obtenir un nouvel identifiant, cela crée un nombre théoriquement infini d’URL pour le même document HTML.
L’analyse des logs du serveur montre que si aucune règle de filtrage n’est définie, Googlebot peut tenter d’explorer le même article des centaines de fois en 24 heures, en utilisant à chaque fois une chaîne de session différente.
Ce comportement entraîne l’accumulation d’un grand nombre de requêtes invalides dans la file d’attente d’exploration, évincant le quota qui aurait dû être alloué aux pages nouvellement publiées (Fresh Content).
« Dans la surveillance des logs des grands sites de commerce électronique, les requêtes d’exploration dupliquées causées par les identifiants de session représentent souvent 30 % à 50 % du volume total d’exploration, forçant Googlebot à déclencher fréquemment des limites de “délai d’exploration” pour protéger les performances du serveur. »
Lorsqu’un utilisateur clique sur des options telles que la couleur, la taille ou le matériau, l’URL se voit ajouter des suffixes tels que ?color=blue&size=xl&material=cotton.
Bien que ces paramètres modifient le sous-ensemble de contenu affiché sur la page, ils ne génèrent souvent pas de nouvelles métadonnées.
D’un point de vue technique, ces paramètres suivent la logique du produit cartésien (Cartesian Product).
| Type de paramètre | Exemple de structure typique | Impact sur la visibilité pour Googlebot | Degré de gaspillage des ressources d’exploration |
|---|---|---|---|
| Suivi de session | ?sid=xyz_987 |
Génère des chemins d’URL dupliqués quasi infinis | Extrêmement élevé (9/10) |
| Filtrage multiple | ?size=m&color=red |
Croissance géométrique des chemins, risque de boucles infinies | Élevé (8/10) |
| Logique de tri | ?sort=price_desc |
Changement de l’ordre du contenu, aucune information nouvelle substantielle | Moyen (5/10) |
| Suivi publicitaire | ?click_id=ad_01 |
Pointe vers un contenu 100 % identique à la page d’origine | Moyen-élevé (7/10) |
| Langue/Région | ?lang=fr-fr |
Pointe vers des pages valides avec un contenu traduit différent | Faible (2/10) |
Les paramètres de tri (Sorting Parameters) tels que ?sort=highest_price ou ?order=newest sont généralement marqués comme basse priorité aux yeux de Googlebot.
Comme le corps de la page, le titre et la méta-description restent inchangés après le tri, l’algorithme de déduplication du moteur de recherche identifiera rapidement que ces URL sont des copies de la page canonique (Canonical Page).
Si le site n’a pas correctement configuré rel="canonical" pointant vers le chemin principal, Googlebot consacrera tout de même environ 15 % de sa fréquence d’exploration à vérifier si ces pages de tri ont des mises à jour de contenu.
Pour un site de vente au détail comptant 100 000 SKU, une simple fonction « trier par note » peut amener le robot à visiter 100 000 liens inutiles supplémentaires.
Les paramètres de suivi (Tracking Parameters) tels que ?utm_source=google ou ?affiliate_id=123 ont un impact négatif sur le SEO principalement au niveau du « coût de connexion ».
Bien que ces paramètres ne modifient absolument pas le contenu de la page, Googlebot doit tout de même établir une connexion TCP et envoyer une requête pour déterminer si le contenu renvoyé par cette URL est identique à la page principale.
Selon l’observation de sites à fort trafic, s’il existe un grand nombre de liens internes avec des paramètres UTM au sein du site, la vitesse de découverte des chemins d’origine valides par le robot d’exploration diminuera d’environ 25 %.
Lorsqu’il traite ces URL complètement dupliquées, Googlebot réduit progressivement sa fréquence d’exploration, mais avant cela, le précieux « quota de première exploration » a déjà été épuisé par ces codes de suivi redondants.
« Les audits techniques montrent que la suppression des paramètres de suivi des liens internes et la migration de la logique statistique vers l’écoute d’événements côté navigateur peuvent augmenter le volume total d’exploration quotidienne des pages par Googlebot de plus de 18 %. »
Les paramètres de pagination (Pagination Parameters) tels que ?page=2 sont traités de manière relativement spéciale.
Google s’appuyait autrefois sur rel="next/prev", mais il comprend désormais principalement la structure de pagination via des algorithmes.
Sans intervention, le robot pourrait explorer en profondeur jusqu’à la page 500 ou plus, alors que la valeur de classement de ces pages profondes est extrêmement faible.
Si les paramètres de pagination sont combinés avec des paramètres de filtrage (par exemple : chemise bleue à la page 5), la complexité de l’URL augmentera de manière exponentielle.
Dépannage et Contrôle
En accédant aux registres d’accès du backend du serveur et en utilisant des expressions régulières pour effectuer des statistiques de fréquence sur les URL contenant un point d’interrogation (?), on peut observer clairement la trajectoire de visite du robot.
Dans un site de commerce électronique international avec plus de 100 000 visites quotidiennes, si les logs montrent que Googlebot lance plus de 40 000 requêtes par jour vers des chemins avec des suffixes ?sessionid= ou ?track_id=, alors que le contenu renvoyé est identique au HTML d’origine, on peut en déduire qu’environ 40 % des ressources d’exploration sont gaspillées sur des chemins inutiles.
L’équipe technique doit calculer le « ratio d’exploration efficace », à savoir :
Nombre d’explorations des pages canoniques / Nombre total d’explorations.
Si cette valeur est inférieure à 20 %, cela indique généralement que le robot est piégé dans un labyrinthe d’URL générées par des paramètres.
L’utilisation d’outis d’analyse de logs tels que Kibana ou Splunk permet d’observer la distribution de la pression d’exploration sous différentes combinaisons de paramètres, identifiant ainsi les chemins qui génèrent des centaines de milliers de variantes sans contribuer au trafic.
L’utilisation du rapport « Statistiques d’exploration » dans Google Search Console permet d’obtenir des données réelles du point de vue du moteur de recherche.
Dans ce rapport, il convient de prêter une attention particulière à la dimension « Exploration par objectif » :
- Ratio de requêtes de découverte (Discovery) : Se réfère à l’action du robot trouvant une nouvelle URL pour la première fois. Pour les sites fréquemment mis à jour, ce ratio doit rester supérieur à 30 %. S’il est trop bas, cela signifie que le nouveau contenu est bloqué par des chemins de paramètres anciens.
- Fréquence des requêtes d’actualisation (Refresh) : Se réfère aux nouvelles visites du robot sur des pages connues. Si les requêtes d’actualisation se concentrent massivement sur des URL avec paramètres plutôt que sur les pages maîtresses du site, il s’agit d’une mauvaise allocation des ressources.
- Indicateurs de distribution des codes d’état de réponse : Observez la proportion de 200 (OK), 304 (Not Modified) et 404 (Not Found). Si les URL avec paramètres génèrent un grand nombre d’erreurs 404 ou de redirections 301, Googlebot abaissera la limite supérieure d’exploration du site (Crawl Capacity Limit) en raison de coûts de connexion trop élevés.
- Surveillance du temps de téléchargement moyen : Si des filtrages de paramètres complexes déclenchent des requêtes de base de données lourdes, entraînant un temps de chargement des pages supérieur à 2000 millisecondes, Googlebot réduira rapidement le nombre d’explorations simultanées pour éviter de saturer le serveur.
Une fois la source des paramètres redondants confirmée, bien que la balise Canonique puisse traiter les doublons au niveau de l’indexation, seul le fichier Robots.txt peut intercepter les requêtes avant d’initier une connexion HTTP.
En configurant Disallow: /?sort= ou Disallow: /?price_min=, on peut forcer Googlebot à cesser de visiter des combinaisons spécifiques de tri ou de filtrage par prix.
Cette méthode permet de libérer immédiatement le nombre de connexions initialement gaspillées sur ces pages au profit des URL canoniques présentes dans le Sitemap.xml.
Lors de la configuration des règles, évitez d’utiliser un Disallow: /? trop large, afin de ne pas couper l’accès aux paramètres de langue bénéfiques pour le SEO (comme ?hl=fr) ou aux paramètres de pagination (comme ?p=2).
Une logique de contrôle fine doit s’appuyer sur les résultats de l’analyse des logs pour ne bloquer que les filtres générant des combinaisons de chemins infinies.
Pour la navigation à facettes (Faceted Navigation), l’utilisation du chargement AJAX ou de la technologie pushState permet d’isoler les robots.
Lorsque l’utilisateur clique sur un bouton de filtre, le contenu de la page change mais l’URL ne génère pas de suffixe explorale, ou utilise simplement un identifiant de fragment (#) pour changer la vue. De telles pratiques sont transparentes pour Googlebot, car les robots ignorent généralement tous les caractères après le #.
Dans les cas où l’utilisation de paramètres est indispensable, une logique de limitation des dimensions peut être mise en œuvre :
- Limitation de la profondeur du chemin : Stipuler dans le code du programme que lorsque la combinaison de paramètres dépasse trois dimensions (par exemple : couleur + taille + matériau), le système insère automatiquement une balise
noindexdans l’en-tête HTML et s’assure que cette page n’apparaît dans aucun lien interne du site. - Application de l’attribut Nofollow : Appliquer
rel="nofollow"sur les liens de la barre latérale des filtres pour signaler au moteur de recherche que « ce chemin n’est pas important », réduisant ainsi la probabilité que le robot entre dans des combinaisons de filtrage profondes. - Instruction de fusion de normalisation : S’assurer que toutes les pages avec paramètres pointent vers la version canonique la plus concise via
rel="canonical". Même si le robot effectue l’exploration, cela guidera le système d’indexation pour fusionner l’autorité vers le chemin principal.
Si la page d’accueil ou la barre de navigation principale contient un grand nombre de liens avec des paramètres de suivi UTM, Googlebot explorera en priorité ces chemins bruyants.
Il est conseillé de migrer toutes les statistiques de trafic interne vers le suivi d’événements côté navigateur, afin de garder les URL pures. Lors du traitement de la logique de pagination, bien que Google n’utilise plus de balises de pagination spécifiques, le maintien d’une structure de chemin claire (telle que /page/2/ plutôt que ?page=2) aide l’algorithme à identifier les listes de manière plus stable.
Dans les deux semaines suivant la mise en œuvre du blocage par Robots.txt ou de la logique de fusion des paramètres, le rapport « Couverture de l’index » dans Google Search Console doit être surveillé en continu.
La tendance idéale est la suivante :
Le nombre de pages marquées comme « explorées, mais non indexées » ou « pages dupliquées » diminue considérablement, tandis que l’heure de la « dernière exploration » des pages maîtresses devient plus fréquente.
Si le cycle d’exploration d’une page passe de 10 jours à moins de 24 heures, et que les requêtes avec réponse 200 dans les logs du serveur se concentrent davantage sur les URL canoniques, cela prouve que le quota d’exploration a été alloué de manière raisonnable.
Dilution des signaux
Lorsque plusieurs URL contenant différents paramètres (tels que ?sort=price ou ?sessionid=abc) pointent vers le même contenu, Google les considérera comme des pages indépendantes.
L’autorité des liens et les signaux de clic des utilisateurs, initialement à 100 %, seront dispersés parmi ces variantes.
Si une page génère 5 copies de paramètres, le PageRank obtenu par une URL unique ne sera plus que de 20 %, ce qui l’empêche d’atteindre le seuil d’autorité nécessaire pour entrer dans le top 10 des résultats de recherche.
Dans les sites de commerce électronique comptant plus de 50 000 URL, les paramètres non traités entraîneront une consommation de plus de 50 % de la fréquence d’exploration quotidienne de Googlebot sur des chemins dupliqués, retardant ainsi la vitesse d’indexation des nouvelles pages.
Dispersion de l’autorité
Dans la logique originale de l’algorithme PageRank, la capacité de classement d’une page est déterminée par le nombre et la qualité des liens pointant vers cette URL.
Lorsque le site génère des variantes de chemins contenant ?sort=newest, ?filter=price-low ou ?sessionid=xyz, il est très fréquent que des sites externes fassent des liens vers ces différentes variantes.
Les données spécifiques indiquent que si l’URL d’origine d’un produit est example.com/item et que 40 % des liens externes pointent vers example.com/item?source=social avec paramètres, le graphe de liens de Google enregistrera ces deux URL séparément.
Bien que l’algorithme tente d’effectuer une identification de normalisation, environ 10 % à 15 % de la valeur sera perdue dans ce mappage non standard lors de la transmission réelle de l’autorité.
« Lors du traitement des URL paramétrées, Googlebot doit décider dans quelle entité spécifique injecter le PageRank ; en l’absence d’un guidage Canonique clair, ce processus d’injection deviendra aléatoire et fragmenté. » — Référence aux explications techniques publiques de l’équipe de qualité de recherche de Google.
Les données d’analyse de logs réelles révèlent que les grandes plateformes de commerce électronique multinationales, lorsqu’elles traitent la navigation à facettes multiples (Faceted Navigation) sans limiter l’exploration des paramètres, voient la vitesse d’accumulation du PageRank de leurs pages de catégories principales être plus lente de 30 % par rapport à des concurrents ayant des chemins uniques.
Lorsque 5 000 liens internes d’un site pointent respectivement vers 50 combinaisons de paramètres différentes, la poussée qui aurait pu propulser une page vers la première page des résultats de recherche est divisée en 50 signaux faibles insuffisants pour générer un classement.
Lorsque la similitude de contenu entre deux URL atteint plus de 98 %, le système active un mécanisme de déduplication.
D’après l’observation de 500 000 sites nord-américains, l’autorité des liens originaux des pages jugées comme « dupliquées » par Google mais non redirigées physiquement reste souvent dans un état gelé, sans être transférée automatiquement à 100 % à la page principale.
Pour les sites comptant plus de 100 000 URL, les chemins d’exploration invalides générés par les paramètres limiteront la profondeur de visite de Googlebot.
Dans les sites manquant de gestion des paramètres, le temps passé par le robot sur les pages de paramètres invalides représente 65 % du temps total d’exploration, ce qui signifie que le nouveau contenu de haute qualité peut mettre 14 jours ou plus avant d’être indexé, alors que ce cycle est généralement réduit à moins de 24 heures pour les sites optimisés.
« Chaque modification d’un caractère de l’URL crée un nouveau nœud dans la base de données ; même si le contenu est identique, ces nœuds sont en relation de concurrence plutôt que de collaboration au début de l’algorithme. » — Extrait d’un rapport d’expérimentation d’un institut de recherche SEO international.
Dans certaines architectures utilisant l’équilibrage de charge ou des réseaux de distribution de contenu (CDN), les requêtes avec paramètres peuvent être mises en cache sous forme de copies statiques différentes.
Si l’en-tête de réponse HTTP ne configure pas correctement Vary: User-Agent ou Link: rel="canonical", Googlebot pourrait penser que ces pages de paramètres sont destinées à afficher des contenus différents pour des utilisateurs de différentes régions.
Sous cette erreur de jugement, l’algorithme décomposera davantage l’autorité de l’ensemble du site dans chaque dimension de paramètre, créant ainsi une situation d’« anémie d’autorité ».
Pour quantifier techniquement la perte causée par cette dispersion, on peut se référer au « modèle de perte d’autorité » :
Supposons que la page principale ait besoin de 100 unités de signaux pour entrer dans le top 3. S’il existe 4 variantes de paramètres et que chaque variante détourne 15 % des signaux, alors la page principale ne pourra finalement conserver que 40 unités de signaux, plaçant cette page dans une position de désavantage extrême dans la compétition.
Lors d’audits techniques de boutiques Shopify à l’étranger, en désactivant dans GSC (Google Search Console) les paramètres ne modifiant pas le contenu tels que sort_by, view et page, on a observé que le nombre d’impressions efficaces des pages cibles a augmenté en moyenne de 55 % en 60 jours.
Solutions de traitement
Dans les architectures de commerce électronique d’entreprise mondiales telles qu’Adobe Commerce (anciennement Magento) ou Salesforce Commerce Cloud, le système d’indexation de Google lira en priorité l’instruction rel="canonical" dans l’en-tête HTML ou l’en-tête de réponse HTTP pendant le processus d’exploration.
Lorsque le système génère des combinaisons de filtrage multiples telles que ?color=blue&size=xl, le programme backend force l’adresse canonique de cette page à pointer vers l’URL racine sans aucun paramètre.
Après une mise en œuvre correcte de cette solution, le taux de précision de Google pour identifier le contenu dupliqué du site peut passer de 60 % à plus de 99 %. Les valeurs de PageRank initialement dispersées seront fusionnées physiquement au cours d’un cycle de mise à jour de l’index de 2 à 4 semaines.
Pour les sites multinationaux comptant des millions de SKU, cette logique garantit que le chemin de recherche principal obtient plus de 95 % de l’autorité des liens internes.
- Déclaration de lien dans l’en-tête de réponse HTTP : Lors du traitement de documents PDF ou de fichiers paramétrés au format non-HTML, le serveur envoie une information d’en-tête
Link: https://example.com/file.pdf; rel="canonical"pour empêcher le moteur de recherche de considérer les liens de téléchargement avec paramètres de suivi comme un nouveau contenu. - Fusion forcée par redirection permanente 301 : Pour les paramètres de suivi marketing déjà obsolètes (comme
?utm_campaign=2023_saled’il y a trois ans), la pratique courante consiste à configurer des règles de caractères génériques au niveau du serveur Nginx ou Apache pour rediriger en permanence toutes les requêtes contenant ce paramètre expiré vers la page standard. Cela garantit un transfert à 100 % de l’autorité des liens externes accumulés historiquement. - Ignorer les paramètres sans état côté serveur : Dans le développement backend, configurer le serveur pour qu’il supprime le Session ID ou d’autres paramètres utilisés uniquement pour la logique interne lors du traitement de la requête, afin que l’URL vue par les différents utilisateurs reste physiquement unique.
- Blocage par catégorie de paramètres dans Google Search Console : Dans l’interface de gestion de Google, les techniciens marqueront les paramètres comme « paramètres passifs » (Passive Parameters), informant explicitement les robots que ces caractères ne modifient pas le contenu de la page, guidant ainsi Googlebot à sauter activement l’exploration de ces URL.
Dans les pratiques SEO à grande échelle, pour les applications monopages (SPA) dotées de systèmes de filtrage complexes, comme celles construites avec React ou Angular, les développeurs ont tendance à utiliser l’identifiant de fragment (#) pour remplacer la chaîne de requête traditionnelle (?).
Par exemple, changer l’URL de filtrage de /shoes?brand=nike à /shoes#brand=nike. Tous les clics et opérations de filtrage des utilisateurs sont effectués côté client, tandis que le moteur de recherche voit toujours le chemin unique /shoes.
Lors de l’utilisation de réseaux de distribution de contenu (CDN) mondiaux tels que Cloudflare ou Akamai, l’équipe technique configurera des règles de type « Cache Key ignorant les paramètres ».
Que l’utilisateur accède à example.com/page?id=1 ou à example.com/page?id=1&from=email, le CDN renverra la même copie de cache au moteur de recherche et à l’utilisateur, et produira une sortie normalisée uniforme dans l’en-tête de réponse.
Pour les plateformes de données massives comme Amazon ou eBay, leur logique de traitement se concentre davantage sur la réécriture de la structure du chemin (URL Rewriting).
Le système convertira le modèle de paramètre original /product.php?id=123&variant=blue en un modèle de répertoire plus sémantique /product/123/blue/.
Dans une enquête par sondage portant sur 100 000 sites indépendants à l’étranger, les sites ayant déguisé les paramètres fonctionnels (tels que le tri ou le changement de vue) via l’API window.history.pushState de JavaScript, sans changer l’adresse de la requête physique, présentaient une stabilité de classement moyenne de leurs pages 2,8 fois supérieure à celle des sites ordinaires.


