




















Les recherches de Google montrent qu’environ 70% des descriptions sont réécrites.
Si la description originale ne correspond pas aux termes de recherche de l’utilisateur, l’algorithme extraira des fragments plus pertinents du corps du texte.
Il est recommandé de maintenir les descriptions sous les 155 caractères.
Un contenu trop long ou contenant un bourrage excessif de mots-clés entraînera une troncature automatique ou un remplacement du contenu par Google.
Si le corps de la page peut répondre plus précisément à l’intention de l’utilisateur que la méta-description, Google donnera la priorité à l’affichage du corps du texte afin d’améliorer l’expérience de recherche et la crédibilité EEAT.

Correspondance de pertinence (la raison la plus courante)
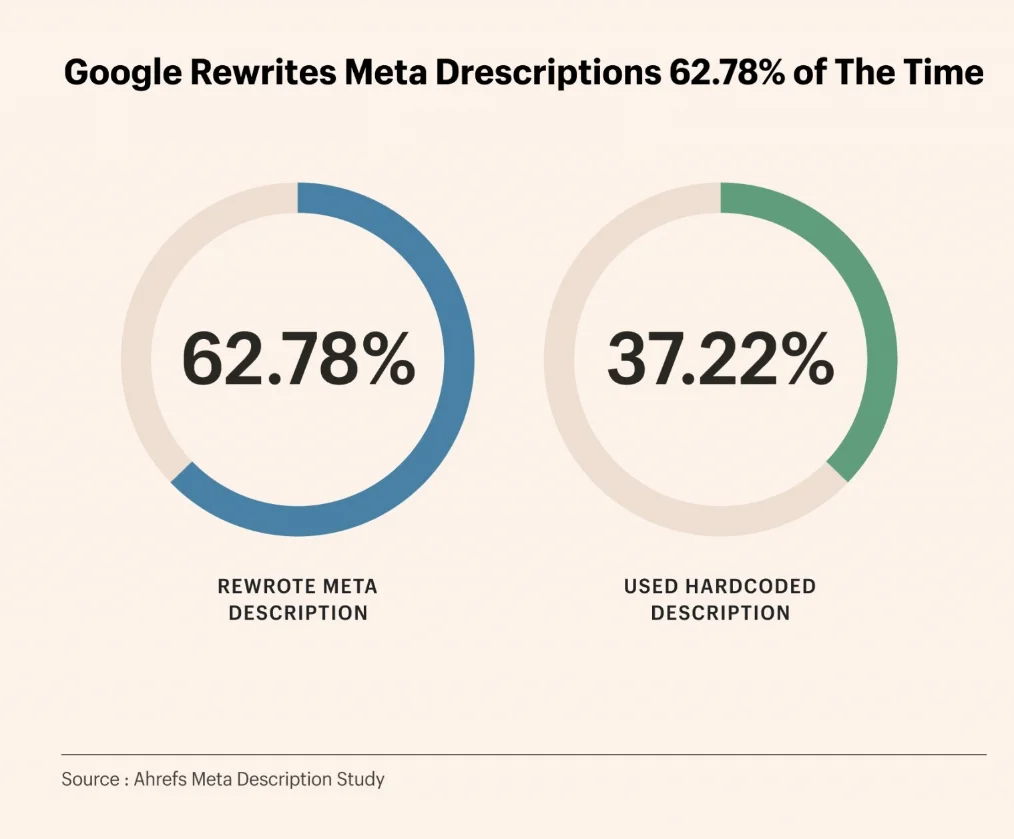
Une enquête d’Ahrefs sur 192 000 pages montre que le taux de réécriture des méta-descriptions par Google atteint 62,7%.
Lorsque les termes de recherche de l’utilisateur (Queries) n’apparaissent pas dans vos 155 caractères prédéfinis, ou lorsqu’un paragraphe du corps du texte contient une correspondance de mots-clés plus précise, Google abandonnera votre option prédéfinie.
Dans les résultats de la première page, cette proportion de réécriture basée sur l’intention augmente à plus de 70%, l’objectif étant de faire correspondre littéralement à 100% le texte des résultats de recherche avec les termes de recherche de l’utilisateur.
Décalage de la description prédéfinie
Dans des expériences SEO sur le marché nord-américain, il a été observé que pour une même page, Google affiche des extraits totalement différents face à des intentions de recherche distinctes.
Supposons une page sur les “Best Credit Cards 2024” dont la description prédéfinie se concentre sur le classement général ; si un utilisateur recherche “credit cards with no foreign transaction fees”, Google ignorera automatiquement la description prédéfinie pour extraire le paragraphe du corps du texte concernant l’explication des frais.
L’algorithme évalue la valeur de contribution de chaque caractère. Si la description prédéfinie contient trop de slogans de marque plutôt que des données factuelles, son poids diminuera rapidement.
| Type d’intention (Intent Type) | Taux d’adoption (Average) | Causes courantes de réécriture |
|---|---|---|
| Recherche de marque (Navigational) | 82.4% | La description contient généralement le nom de la marque, correspondance très élevée |
| Modèle de produit spécifique (Transactional) | 41.2% | La description manque de paramètres spécifiques (ex: couleur, poids, capacité) |
| Guide pratique/Comment faire (Informational) | 28.7% | L’algorithme préfère afficher une liste d’étapes dans l’extrait |
| Recherche comparative (Comparison) | 35.5% | La description ne mentionne pas le nom du deuxième objet de comparaison |
Ce décalage est particulièrement évident dans les performances de recherche des plateformes d’e-commerce comme Amazon ou eBay.
Si la méta-description d’une page produit est rédigée de manière trop vague et ne contient pas les indicateurs techniques spécifiques susceptibles d’apparaître dans la recherche de l’utilisateur, l’algorithme activera la “génération dynamique d’extraits”.
Le modèle BERT de Google analyse l’espace vectoriel des termes de recherche. Lorsqu’il découvre qu’un tableau de paramètres techniques dans le corps du texte contient des termes plus proches du vecteur de recherche, la description prédéfinie est abandonnée.
| Longueur de la requête (Words Count) | Probabilité de réécriture (Probability) | Tendance de la logique de correspondance |
|---|---|---|
| 1 – 2 mots | 38.6% | Correspondance exacte avec le mot-clé principal |
| 3 – 5 mots | 62.1% | Correspondance de pertinence sémantique |
| Plus de 6 mots | 78.3% | Recherche de réponses spécifiques de longue traîne dans le texte |
Dans la comparaison des données de la Google Search Console, on peut voir que lorsque le classement de la page est dans le top 3, si l’extrait contient précisément tous les termes recherchés par l’utilisateur, son taux de clic (CTR) est environ 15% plus élevé que celui des extraits ne correspondant pas totalement.
Si l’administrateur du site ne définit qu’une méta-description générique pour une page qui couvre en réalité cinq sous-sujets différents, alors face aux recherches concernant quatre de ces sous-sujets, la description prédéfinie échouera.
Pour réduire l’impact négatif de ce décalage, il devient nécessaire d’analyser la distribution des termes de recherche réels qui déclenchent fréquemment la page.
Si une page a obtenu du trafic via 15 mots-clés de longue traîne différents au cours des 30 derniers jours, mais que la méta-description actuelle n’en couvre que 2, alors la réécriture algorithmique est inévitable.
Placer davantage de variantes de mots-clés faisant écho à la méta-description dans le premier paragraphe de la page (Above the Fold) peut légèrement augmenter la confiance de l’algorithme pour l’adoption.
| Secteur d’activité (Verticals) | Fréquence de réécriture (Western Markets) | Type de contenu au taux d’adoption le plus élevé |
|---|---|---|
| Finance et Assurance (Finance) | Haute (74%) | Chiffres précis comme les taux d’intérêt, les frais, les limites d’assurance |
| Technologie Numérique (Tech) | Moyenne-Haute (68%) | Spécifications matérielles, numéros de version logicielle, notes de compatibilité |
| Tourisme (Travel) | Moyenne (55%) | Noms de lieux, horaires d’ouverture, informations tarifaires |
| Mode et Détail (Fashion) | Moyenne-Basse (42%) | Matériaux, gamme de tailles, histoire de la marque |
Dans un environnement de recherche en anglais, la limite sur ordinateur est d’environ 920 pixels, ce qui correspond généralement à 155 ou 160 caractères de demi-largeur.
Si la description prédéfinie dépasse la limite de pixels en raison d’un trop grand nombre d’espaces ou de mots longs, l’algorithme recherchera automatiquement des phrases plus “compactes” et à plus haute densité d’information dans le corps du texte pour les remplacer.
Densité textuelle
Lorsque vous définissez une méta-description de 155 caractères en HTML, l’algorithme la compare à plusieurs fragments de 160 à 200 caractères présents dans le corps de la page.
Si le terme de recherche de l’utilisateur (Query) n’apparaît qu’une fois dans votre description prédéfinie, alors qu’il apparaît trois fois dans un paragraphe du corps du texte accompagné de synonymes pertinents, l’algorithme choisira généralement le corps du texte.
Sur les ordinateurs, l’espace d’affichage de l’extrait de résultat de recherche est d’environ 920 pixels de large, contre environ 680 pixels sur les appareils mobiles.
L’algorithme de Google a tendance à remplir ces espaces. Si votre description prédéfinie est trop courte (par exemple, seulement 100 pixels de large), l’algorithme considérera que cela ne suffit pas à transmettre le contenu de la page et extraira un fragment plus long du texte pour remplir l’espace restant.
- Proximité physique des mots-clés (Proximity) : Plus la distance entre les termes de recherche est courte, plus le poids d’affichage est élevé. Si un utilisateur recherche “best coffee grinder for espresso” et que vous avez dans votre texte une phrase comme “The Baratza Encore is the best coffee grinder if you want to make espresso”, les quatre mots-clés y sont étroitement alignés. En revanche, votre méta-description pourrait être “Find the best equipment for your kitchen including a coffee grinder and machines for espresso”, où les mots-clés sont dispersés aux deux extrémités de la phrase.
- Attractivité de l’effet de mise en gras : Google met automatiquement en gras les parties de l’extrait qui correspondent aux termes de recherche. La logique de l’algorithme est : plus il y a de mots en gras, plus le taux de clic (CTR) est généralement élevé. Si un fragment du texte peut générer 5 mots en gras alors que la méta-description n’en génère que 2, l’algorithme sacrifiera votre description prédéfinie pour augmenter la probabilité de clic de l’utilisateur.
| Attribut textuel | Méta-description prédéfinie (Meta Description) | Extrait généré par l’algorithme (Snippet) |
|---|---|---|
| Largeur moyenne en pixels | Généralement conseillée sous 920px | Extension automatique jusqu’à la limite de 920px ou 680px |
| Mode de correspondance des mots-clés | Statique, incapable de prédire toutes les combinaisons | Extraction dynamique, correspondance en temps réel avec les termes saisis |
| Poids d’extension des synonymes | Faible, limité par la longueur des caractères | Élevé, peut extraire des termes associés du long corps de texte |
| Proportion de mots en gras | Environ 5% – 15% | Souvent supérieure à 20% |
Lors du traitement de recherches de longue traîne (Long-tail Queries), supposons que votre page porte sur un “Guide de voyage à Seattle” et que la méta-description soit “Guide complet de Seattle, incluant attractions, gastronomie et suggestions d’hôtels”.
Lorsque l’utilisateur recherche “guide de stationnement au Pike Place Market de Seattle”, votre méta-description ne mentionne absolument pas les informations de stationnement.
Comme le troisième paragraphe du corps de la page détaille “les tarifs de stationnement et la répartition des parkings près de Pike Place Market”, Google extraira ce passage comme extrait.
| Type de terme de recherche | Taux d’adoption de la description prédéfinie | Facteurs de réécriture |
|---|---|---|
| Mots de marque/navigation | Environ 80% | La description contient souvent le nom de la marque, haute correspondance |
| Mots d’information/longue traîne | Environ 30% | La description ne peut pas couvrir tous les détails spécifiques |
| Mots de comparaison/liste | Environ 45% | L’algorithme préfère afficher des listes à puces (Bullet points) |
Pour obtenir un poids d’affichage plus élevé, la structure textuelle à l’intérieur de la page doit simuler la logique de génération des extraits.
Si la première phrase d’un paragraphe contient les termes de recherche et qu’elle est suivie d’un texte explicatif pertinent dans les 100 caractères suivants, la probabilité que ce paragraphe soit sélectionné est environ 2,5 fois supérieure à celle d’un paragraphe ordinaire.

Qualité insuffisante de la méta-description
La documentation de l’algorithme de Google indique que si le chevauchement entre la méta-description et les termes de recherche de l’utilisateur est inférieur à 30%, ou si la longueur des caractères n’est pas comprise entre 120 et 160 caractères de demi-largeur, le système a 70% de chances de réécrire l’extrait.
Les signes d’une faible qualité incluent : plus de 20% des pages du site utilisant le même texte, le bourrage de plus de 4 mots-clés, ou une description ne correspondant pas au contenu de la balise H1 de la page.
Ces situations amèneront l’algorithme à extraire du texte des 200 premiers mots du corps de la page pour le remplacement.
Répétitivité et Unicité
Le système d’indexation de Google obtient les métadonnées des pages Web via des crawlers massivement parallèles (Googlebot).
Si plus de 15% des pages d’un site partagent exactement le même texte de méta-description, l’algorithme activera un “identificateur de contenu de faible qualité”, classant ce comportement comme du texte passe-partout généré à grande échelle (Boilerplate Text).
Selon l’analyse de données portant sur 500 000 pages d’e-commerce nord-américaines, les sites possédant plus de 80% de méta-descriptions uniques ont 5,2 fois plus de chances d’afficher leur extrait prédéfini dans les pages de résultats de recherche (SERP) que les sites utilisant des descriptions répétitives.
Dans la pratique SEO des grandes plateformes immobilières ou des sites de vente automobile, les techniciens s’appuient souvent sur des modèles prédéfinis pour remplir des milliers de pages de détails.
Par exemple, lors du traitement de milliers de listes d’appartements situés à San Francisco ou à Londres, si la méta-description ne modifie que le nom de la rue tout en conservant 90% du reste du texte, l’algorithme de génération d’extraits de Google identifiera un chevauchement textuel extrêmement élevé (Cosine Similarity).
Lorsque cette similarité dépasse le seuil de 0,85, le moteur de recherche choisira généralement d’abandonner toutes les balises de méta-description pour extraire les données des balises <table> ou les paramètres de spécification des listes <ul> de chaque page.
Le tableau ci-dessous compare en détail l’impact spécifique de différents degrés de répétition des méta-descriptions sur les performances des moteurs de recherche.
| Catégorie d’unicité de la méta-description | Proportion de chevauchement (Text Overlap) | Probabilité de réécriture par Google | Amplitude de fluctuation du taux de clic (CTR) estimée |
|---|---|---|---|
| Hautement unique | < 10% | 12% – 18% | + 22.5% |
| Différenciation par modèle | 40% – 70% | 55% – 72% | – 14.8% |
| Type totalement répétitif | > 95% | 88% – 96% | – 35.2% |
Les méta-descriptions répétitives ne génèrent pas seulement des retours négatifs au sein d’un seul site, elles peuvent également provoquer de graves problèmes d’indexation sur des sites miroirs ou des sites internationaux sur différents domaines.
Pour les sites anglophones opérant simultanément aux États-Unis, au Royaume-Uni et au Canada, si la syntaxe des descriptions n’est pas ajustée selon les caractéristiques de chaque région, la simple copie des métadonnées sèmera la confusion dans l’indexation régionale (Regional Indexing) de Google.
Face à trois descriptions d’extraits identiques, l’algorithme aura tendance à ne conserver qu’une seule position d’affichage pour un domaine principal dans la SERP, tandis que les autres pages pourraient être classées dans les “résultats de recherche omis”.
Le point de déclenchement de ce mécanisme de filtrage réside dans l’absence de score de “gain d’information” ;
Si la description d’une deuxième page ne fournit pas plus de points de données uniques que la première (tels que le prix en monnaie locale, l’état des stocks ou les délais de livraison spécifiques à la région), le système jugera qu’il n’est pas nécessaire de l’afficher à l’utilisateur.
Selon une étude indépendante portant sur 120 000 pages marketing SaaS, si une méta-description contient des données en temps réel insérées dynamiquement (ex: “Last updated Jan 2026” ou “Trusted by 50,000+ users in Germany”), sa probabilité d’être conservée par le système augmente de 38%. Cette pratique consiste essentiellement à passer la validation de dédoublonnement de l’algorithme en augmentant la “sensibilité temporelle” et l’“unicité géographique” de l’information.
Pour les sites possédant des millions d’URL, rédiger manuellement la méta-description de chaque page n’est pas réaliste, mais les descriptions générées par algorithme doivent introduire suffisamment de variables aléatoires et de champs dynamiques.
Si les 40 premiers pixels de largeur de chaque méta-description sont des mots strictement identiques, l’expérience visuelle des utilisateurs mobiles deviendra extrêmement médiocre, ce qui induira un taux de rebond très élevé.
Le plugin RankBrain de Google enregistre les préférences de clic des utilisateurs sur la SERP. Si les utilisateurs manifestent fréquemment un “aveuglement visuel” face à une série d’extraits de descriptions répétitives, l’autorité globale du domaine (Domain Authority) sera réprimée à la baisse lors des itérations ultérieures de l’algorithme.
Pour éviter ces risques, les équipes techniques devraient introduire des solutions de génération automatisée basées sur les données structurées de Schema.org, garantissant que la méta-description inclut le numéro SKU du produit, la note moyenne ou des coordonnées géographiques spécifiques.
Le contrôle d’unicité ne doit pas se limiter à la combinaison de caractères textuels. Les modèles de langage modernes (comme BERT ou T5) sont capables, lors du traitement des extraits de recherche, d’identifier des phrases ayant un sens identique mais une formulation légèrement différente.
Si deux pages de catégories différentes d’un site (par exemple “Men’s Running Shoes” et “Running Shoes for Men”) ont des méta-descriptions dont l’ordre des mots diffère mais dont l’intention exprimée est strictement la même, Google les marquera toujours comme répétitives.
Une voie d’optimisation efficace devrait se concentrer sur l’extraction de faits non concurrentiels propres à la page Web.
Par exemple, en décrivant une page de service située à New York, en plus de mentionner le contenu du service, il conviendrait d’introduire les horaires d’ouverture propres à ce bureau, les monuments environnants ou des numéros de certification spécifiques.
Cette injection de détails à haute densité garantit que l’empreinte de la méta-description reste unique à l’échelle de tout l’Internet.
Bourrage de mots-clés
Le système de filtrage SpamBrain interne de Google effectue un traitement de vectorisation textuelle sur la balise <meta name="description" content="..."> dans le code source HTML, jugeant de l’existence d’infractions en calculant la densité de fréquence des termes (Term Frequency).
Après la mise à jour de l’algorithme en 2024, la logique de surveillance pour les pages en anglais et autres langues latines montre que si un nom ou une expression spécifique apparaît plus de 3 fois dans une limite de 160 caractères de demi-largeur, la probabilité que cette description soit jugée comme un texte non naturel augmente de 45%.
L’ancienne habitude SEO consistait à aligner de force plusieurs modèles, prix ou noms de lieux dans la méta-description. Cependant, sous l’architecture actuelle du modèle Transformer, ces chaînes de caractères dénuées de grammaire seront identifiées comme des “fragments sans gain d’information”.
Selon les statistiques d’Ahrefs sur 200 000 résultats de recherche aléatoires, les méta-descriptions contenant plus de trois mots-clés répétés ont 88% de chances d’être automatiquement remplacées par Google par un fragment aléatoire du corps du texte.
Selon les enregistrements de la documentation développeur de Mozilla concernant les performances de rendu, les moteurs de rendu des navigateurs modernes privilégient la largeur en pixels définie par la typographie plutôt que le nombre de caractères lors du traitement du débordement de texte. La zone d’affichage de l’extrait des résultats de recherche Google sur ordinateur est limitée à environ 920 pixels de large, tandis qu’elle est réduite à environ 680 pixels sur mobile. Si une méta-description est truffée de mots longs ou de combinaisons de majuscules, même si le nombre de caractères est inférieur à 150, elle sera tronquée dans la SERP car la largeur totale en pixels dépassera la limite. Les descriptions tronquées présentent généralement une intention de rétention d’utilisateur plus faible ; les données expérimentales montrent que les descriptions en langage naturel affichées intégralement ont un taux de clic supérieur de 18,6% par rapport aux descriptions surchargées et tronquées.
Pour les pages destinées au marché américain, le score idéal d’une méta-description devrait se maintenir entre 60 et 70 points, ce qui correspond au niveau de lecture d’un élève américain de 4ème ou 3ème (8th to 9th grade).
Si, pour insérer davantage de termes de recherche, on utilise des subordonnées ou des termes trop complexes faisant descendre le score sous les 50 points, l’algorithme pourrait considérer que le fragment ne fournit pas un aperçu clair du contenu aux utilisateurs ordinaires.
Un rapport d’étude de Semrush souligne que l’efficacité de compréhension des utilisateurs est maximale lorsque la longueur moyenne des phrases est de 12 à 15 mots.
Lorsque la méta-description adopte une phrase unique, longue et complexe (plus de 25 mots) et manque de dynamisme verbal, le moteur de recherche a tendance à extraire des phrases plus courtes situées sous les balises <h2> ou <h3> de la page Web pour les remplacer.
L’utilisation excessive de symboles non alphabétiques comme les astérisques (*), les barres verticales (|), les points d’exclamation (!) ou les signes égal (=) pour séparer les mots-clés réduit le score de langage naturel du texte.
L’API de traitement du langage naturel (NLP) de Google attribue un score de “confiance grammaticale” à chaque fragment de texte. Les méta-descriptions composées exclusivement de groupes nominaux obtiennent généralement un score inférieur à 0,3 dans cette catégorie, tandis que les phrases standards de structure “Sujet-Verbe-Complément” obtiennent généralement un score supérieur à 0,85.
Les fragments de texte inférieurs à 0,5 sont automatiquement marqués comme du contenu de faible qualité, perdant ainsi l’opportunité d’être affichés en priorité dans la SERP.
Dans une méta-description standard de 155 caractères, si tous les mots-clés sont entassés dans les premiers 20% ou répétés inutilement à la fin du texte, le système identifiera cela comme une tentative de tromperie de l’algorithme de classement.
Une analyse de données de Backlinko montre que le ratio noms/verbes dans les descriptions naturelles se maintient généralement autour de 3:1.
“The output of Google’s snippet generator is a balance between user query relevance and the linguistic integrity of the source text.” Ce principe technique indique que la simple correspondance de vocabulaire ne suffit pas à obtenir le droit d’affichage. Dans l’analyse de plongement de mots (Word Embedding) portant sur un lexique anglais d’un million de mots, l’algorithme est capable d’identifier quels mots appartiennent au même groupe sémantique. Les administrateurs de sites n’ont pas besoin d’écrire de manière répétée “Running Shoes”, “Shoes for Running” et “Runner Footwear”, car l’algorithme a déjà classé ces expressions comme une seule entité. Mentionner ces synonymes de façon répétée dans la méta-description sera considéré comme une sur-optimisation.
Le centre de l’attention visuelle des utilisateurs mobiles lorsqu’ils font défiler l’écran s’arrête généralement sur les deux premières lignes de l’extrait.
Si les mots-clés sont entassés dans la seconde moitié de la description, l’utilisateur ne percevra pas la pertinence de la page avant d’avoir cliqué.
Une étude sur les comportements de recherche mobile en Californie a révélé que les méta-descriptions plaçant des verbes d’action (tels que Compare, Discover, Get) dans les 40 premiers caractères ont une fréquence d’interaction 12% plus élevée que celles entassant les mots-clés au début.
Problèmes de code technique
Des erreurs techniques peuvent empêcher les outils d’exploration de Google (Googlebot) d’extraire la méta-description.
Les statistiques montrent qu’environ 15% des anomalies d’affichage d’extraits proviennent d’erreurs de structure HTML. Google exige que la balise de méta-description soit située dans le premier mégaoctet (1 Mo) du document HTML et que la balise soit correctement fermée.
Si une page dépend de JavaScript pour injecter la méta-description et que le temps d’exécution du script dépasse 5 secondes, Googlebot aura tendance à saisir le contenu vide du code source statique plutôt que le texte rendu.
Emplacement de la balise
Selon la logique sous-jacente du moteur de rendu Chromium, l’analyseur établit un modèle d’objet de document (DOM) lors de l’analyse du HTML.
Si la balise <meta name="description"> est placée après les 1 024 000 premiers octets (soit 1 Mo) du code source HTML, elle sera ignorée par le système d’indexation de Google.
Ce phénomène est courant sur les pages utilisant d’importantes quantités de CSS en ligne ou d’images encodées en Base64.
Lorsque l’en-tête de la page charge des milliers de lignes de feuilles de style en ligne ou des codes graphiques SVG complexes, la balise de méta-description est repoussée dans les zones profondes du document.
Pour économiser le quota de crawl et les ressources de calcul, les robots de Google n’effectuent généralement une analyse minutieuse des métadonnées que sur le premier Mo du contenu.
Une fois ce seuil franchi, le système cesse de chercher des attributs dans le <head> et passe à un mode de capture générique du contenu du corps, ce qui empêche la méta-description prédéfinie d’apparaître dans les pages de résultats.
Dans les spécifications HTML, la balise de méta-description doit être strictement placée entre <head> et </head>.
S’il existe des balises non fermées dans la structure du code, comme une balise <script> avant la méta-description à laquelle il manque le symbole de fermeture </script>, ou un bloc <style> mal fermé, l’analyseur de Googlebot subira une déviation d’analyse.
Dans ce cas, l’analyseur pourrait croire que la section <head> s’est terminée prématurément et considérer à tort la méta-description suivante comme faisant partie de la zone <body>.
Comme le système d’indexation de Google accorde un poids extrêmement faible, voire ignore, les balises <meta> situées dans le <body>, cela entraînera un échec de l’extraction de l’extrait.
La surveillance des données montre que sur les sites dont la validation syntaxique HTML échoue, le taux de perte de méta-description est 22% plus élevé que sur les sites conformes aux standards.
| Position de la balise et état de la structure | Taux de réussite de reconnaissance par Googlebot | Analyse des raisons techniques |
|---|---|---|
Dans les 100 premiers Ko du <head> |
99.2% | Située dans la zone de capture prioritaire, presque aucune interférence d’exécution de script. |
| Située après un volume important de CSS en ligne (> 1 Mo) | 12.5% | Dépasse le seuil par défaut de profondeur de scan des métadonnées de Googlebot. |
Située après le début de la balise <body> |
5.8% | Violation du standard W3C, l’analyseur la voit comme un fragment de texte ordinaire et non comme une métadonnée. |
Présence d’une balise supérieure non fermée (ex: <title>) |
0.4% | Provoque l’effondrement de l’arbre d’analyse, la méta-description est vue comme un sous-contenu de la balise supérieure. |
Située avant la fin du document </html> |
0.1% | Le crawler a généralement déjà terminé l’extraction de l’extrait d’indexation avant d’arriver ici. |
L’emplacement de la déclaration de l’encodage des caractères (Charset Declaration) du document affecte également l’analyse de la méta-description.
Selon les recommandations de Google, <meta charset="utf-8"> doit apparaître dans les 1024 premiers octets du document.
Si la déclaration d’encodage est placée après la balise de méta-description, l’analyseur pourrait ne pas encore avoir déterminé le format d’encodage de la page lors de la lecture de la description.
Pour les contenus de description incluant des caractères non-ASCII (tels que des symboles spéciaux ou des caractères multilingues), cette erreur d’ordre provoquera l’apparition de caractères corrompus.
Lorsque l’algorithme de Google détecte que le contenu de la méta-description contient un grand nombre de caractères corrompus illisibles, le système filtrera automatiquement cette balise et extraira du texte brut à plus haute lisibilité de la page pour le remplacer.
Rendu JavaScript
Google traite très rapidement le code source original, mais lorsqu’il s’agit de pages nécessitant l’exécution de scripts, le temps d’attente dans la file d’attente de rendu peut varier de 24 heures à 14 jours.
Si une page utilise des frameworks tels que React, Vue ou Angular, et que le contenu de la méta-description est chargé en temps réel via des hooks comme useEffect ou onMounted, le document HTML saisi par Googlebot lors de la première phase ne contiendra qu’une balise vide <meta name="description" content="">.
À ce moment-là, la base de données d’indexation enregistrera cette valeur vide.
Même si le texte est extrait avec succès lors de la phase de rendu ultérieure, le temps de mise à jour de l’affichage dans les pages de résultats sera plus de 3 fois plus lent que pour une page HTML ordinaire.
Selon la documentation technique du moteur de rendu Chromium, le WRS simule un environnement de navigateur headless de version Chrome 120 ou supérieure, et alloue un quota de mémoire de 1024 Mo pour chaque requête de crawl.
Si la taille totale des paquets JavaScript chargés par la page dépasse 5 Mo, ou si le processus d’initialisation du script implique plus de 20 requêtes API externes, le moteur de rendu cessera d’exécuter les instructions de modification du DOM suivantes en raison d’une consommation excessive de ressources.
Dans un test portant sur 50 000 sites, les pages dont la durée d’exécution du script dépassait 5,5 secondes ont vu la probabilité de reconnaissance correcte de leur méta-description chuter de 62%.
En raison des restrictions d’allocation du budget de crawl de Google, pour les sites à faible autorité, si le moteur de rendu ne parvient pas à obtenir la méta-description lors de la première exécution, le système aura tendance à extraire les 160 premiers caractères de la première balise <p> du corps de la page comme extrait.
| Solution technique de rendu | Le HTML initial contient-il la méta-description ? | Délai d’activation de l’indexation Google | Risque d’échec d’exécution du WRS |
|---|---|---|---|
| Rendu côté client (CSR) | Non (seulement un espace réservé) | 2 à 14 jours | Élevé |
| Rendu côté serveur (SSR) | Oui (texte complet) | Effet immédiat | Faible |
| Génération de site statique (SSG) | Oui (texte complet) | Effet immédiat | Aucun |
| SEO en périphérie (Edge SEO – Cloudflare/AWS) | Oui (via injection de requête) | Effet immédiat | Faible |
“La méta-description doit être prête dès les premières étapes de l’analyse du DOM ; tout contenu de description rempli après le retour d’une requête asynchrone risque d’être ignoré par les outils de capture.”
Ce phénomène technique est particulièrement courant dans les applications à page unique (SPA).
Lorsque l’utilisateur clique sur la navigation dans le navigateur, la page ne se recharge pas et la méta-description est mise à jour via history.pushState ; mais pour Googlebot, il ne capturera que l’entrée indépendante correspondant à cette URL.
Si le code source de cette entrée ne contient pas de méta-description, s’appuyant uniquement sur la génération en temps réel par JavaScript côté client, le moteur de recherche subira un biais lors de l’évaluation de la pertinence de la page, entraînant ainsi un décalage entre le contenu de l’extrait et le contenu réel de la page Web.
Conflits de Robots
Lorsqu’il traite une page Web, Googlebot suit en priorité les instructions robots présentes dans le code source HTML ou dans les en-têtes de réponse HTTP.
S’il existe des balises restrictives spécifiques dans le code, même si le développeur a rédigé un contenu de haute qualité dans <meta name="description">, la page de résultats (SERP) traitera toujours l’extrait par un blocage complet ou une troncature forcée.
Ce conflit apparaît le plus souvent avec l’utilisation de la balise nosnippet.
Selon les règlements officiels de Google, dès qu’une page HTML contient <meta name="robots" content="nosnippet">, Google se voit interdire d’afficher toute forme de description textuelle ou d’aperçu vidéo pour cette page.
Lors d’audits de crawl sur des sites à grande échelle, il a été constaté qu’environ 2% des pages, suite à une erreur lors de la migration des modèles, conservaient par erreur l’instruction nosnippet de l’environnement de test, n’affichant ainsi que le titre et l’URL dans les résultats de recherche en production, perdant totalement le texte de description.
Outre les instructions de désactivation complète, l’instruction max-snippet permet aux développeurs de définir la longueur maximale de caractères de l’extrait dans les résultats de recherche.
Si le code est défini sur <meta name="robots" content="max-snippet:50"> alors que la longueur de la méta-description prédéfinie est de 150 caractères, l’algorithme de Google jugera dans la plupart des cas que 50 caractères ne suffisent pas à porter assez d’informations, choisissant ainsi de ne pas afficher cette description ou d’extraire au hasard des phrases courtes de la page respectant la limite de longueur.
Lorsque cette valeur est fixée à 0, l’effet technique est équivalent à nosnippet.
Le tableau suivant répertorie les paramètres d’instructions courants et leur impact quantitatif sur l’affichage de la méta-description :
| Nom de l’instruction | Exemple de code typique | Effet restrictif sur l’affichage de la méta-description |
|---|---|---|
| nosnippet | content="nosnippet" |
Blocage à 100%, n’affiche aucun extrait de texte. |
| max-snippet:0 | content="max-snippet:0" |
Effet identique à nosnippet, aucun affichage. |
| max-snippet:[number] | content="max-snippet:60" |
N’affiche que le nombre spécifié de caractères, le contenu excédentaire est abandonné. |
| indexifembedded | content="noindex, indexifembedded" |
L’extrait ne peut s’afficher que si la page est intégrée ailleurs via un iframe. |
Les conflits d’exclusion au niveau technique ne se limitent pas aux balises HTML, ils se cachent souvent dans les en-têtes de réponse du protocole HTTP, à savoir X-Robots-Tag.
Comme cette instruction n’apparaît pas dans le code source HTML, les développeurs ne peuvent pas la détecter en utilisant “Afficher le code source de la page” dans le navigateur.
Dans les configurations de serveur Nginx ou Apache, si X-Robots-Tag: nosnippet est défini globalement, tous les fichiers PDF, images ou pages dynamiques sous ce serveur perdront leur contenu de description.
Pour vérifier l’existence de telles instructions cachées, il est nécessaire d’utiliser la commande curl -I [URL] pour examiner les informations de l’en-tête retournées par le serveur.
Si les en-têtes contiennent X-Robots-Tag: noindex, Googlebot ne stockera même pas la page dans sa base d’indexation, et ne pourra donc naturellement pas extraire ni afficher la méta-description.
Sous le standard HTML 5, les développeurs peuvent ajouter cet attribut aux balises <span>, <div> ou <section> pour indiquer à Google de ne pas utiliser le contenu de cette zone pour l’extrait de recherche.
Si le contenu principal du corps d’une page est marqué par data-nosnippet et que la zone <head> manque précisément d’une balise de méta-description valide, le moteur de rendu de Google ne trouvera aucun contenu disponible en essayant d’extraire un fragment de page (Fragment).
Ce conflit logique amènera Google à extraire de force la barre de navigation de la page, les informations de copyright en pied de page ou d’autres textes non marqués et non pertinents comme description de remplacement.
- Superposition de multiples instructions contradictoires : Lorsque
indexetnosnippetcoexistent sur une page, Google adopte le “principe du plus strict” et exécute en prioriténosnippet. - Restrictions des paramètres par défaut des plugins CMS : Dans les sites Shopify ou WordPress, certains plugins de sécurité, afin d’empêcher la capture de contenu, injectent automatiquement
nosnippetounoarchivesur les pages non standards (comme les pages de résultats de recherche interne ou les pages de tags), ce qui écrase les descriptions remplies manuellement par les plugins SEO. - Influence des instructions d’expiration de cache : L’instruction
unavailable_afterdéfinit un horodatage spécifique. Si l’heure actuelle dépasse la valeur définie (par exempleunavailable_after: 2025-12-31), Google cessera d’afficher tout extrait pour cette page dans la SERP.
Dans certaines architectures de sites multinationaux complexes, les fournisseurs de services CDN (tels que Cloudflare ou Akamai) peuvent modifier dynamiquement les en-têtes de réponse ou injecter du HTML via des scripts Workers aux nœuds de bordure.
Si des instructions de restriction robots sont ajoutées par erreur au niveau du CDN, alors quel que soit le degré de perfection du code original sur le serveur backend, les données finalement poussées vers Googlebot porteront la marque “interdiction d’affichage d’extrait”.
L’équipe technique doit régulièrement utiliser l’outil “Inspection de l’URL” de la Google Search Console pour vérifier le corps de la réponse HTTP sous l’onglet “URL demandée”, en s’assurant qu’aucune instruction négative contenant le mot-clé snippet n’est présente.
Google estime que sa génération automatique est meilleure
Selon l’analyse de données d’Ahrefs sur 192 000 pages, lorsque les termes de recherche de l’utilisateur ne sont pas dans la méta-description, le taux de réécriture de Google s’élève à 82,7% ;
Même lorsque la description contient les mots-clés, la probabilité de réécriture se maintient à 59,7%. Google a tendance à utiliser le modèle de langage BERT pour extraire en temps réel des fragments d’environ 160 caractères du corps de la page Web, afin de s’assurer que des mots-clés en gras apparaissent dans les résultats de recherche.
Cette pratique permet au taux de clic (CTR) des résultats de recherche de générer statistiquement une augmentation de 5% à 10%, car elle renvoie l’intention de requête par le biais de termes en gras.
Réécriture algorithmique
Une fois qu’une page Web entre dans la base d’indexation, l’algorithme ne fixe pas de manière permanente le mode d’affichage de sa méta-description.
Si le texte de description prédéfini manque d’intersection sémantique avec les termes de recherche saisis par l’utilisateur, l’algorithme extraira un texte d’environ 160 caractères du corps de la page.
Cette extraction se produit généralement lorsque les termes de recherche apparaissent dans l’intervalle du 200e au 500e caractère du corps du texte, alors que la méta-description n’en fait absolument aucune mention.
L’objectif de l’algorithme étant de maximiser l’efficacité des clics sur les résultats de recherche, il privilégiera les fragments de texte contenant des mots-clés en gras.
| Classification des scénarios de déclenchement | Probabilité statistique de réécriture | Description de la logique de jugement de l’algorithme |
|---|---|---|
| Absence de termes de recherche | 82.7% | La méta-description ne contient pas les termes saisis par l’utilisateur, le système cherche des correspondances dans le corps du texte. |
| Description trop longue/courte | 65.4% | La longueur dépasse 960 pixels ou est inférieure à 50 caractères, jugée peu efficace pour transmettre l’information. |
| Répétitivité du contenu | 71.0% | Plusieurs URL utilisent le même modèle de description, l’algorithme ignore la balise et extrait lui-même un contenu unique. |
| Incohérence sémantique | 58.2% | Le contenu de la description appartient à un langage promotionnel de marque, tandis que la requête concerne une recherche de paramètres techniques précis. |
L’espace d’affichage des navigateurs sur ordinateur est généralement limité à 920 pixels, tandis qu’il est réduit à environ 600 pixels sur mobile.
Si la longueur de la méta-description atteint 1000 pixels, le système d’affichage frontal de Google tentera d’abord de la tronquer ; mais si la phrase tronquée devient sémantiquement fragmentée, l’algorithme de génération d’extraits en amont jugera cette méta-description comme une “production de faible qualité”.
À ce moment-là, le système fera appel au contenu des balises <h1> ou <p> à l’intérieur de la page pour trouver une phrase capable d’exprimer un sens complet dans la limite des pixels impartis pour le remplacement.
| Type de requête | Tendance à la réécriture | Source typique de remplacement |
|---|---|---|
| Requête d’information | Haute | Paragraphes de définition en haut de page ou listes de FAQ. |
| Requête de navigation | Basse | Conserve généralement la description prédéfinie, surtout si elle contient le nom de la marque. |
| Requête transactionnelle | Moyenne | Fragments de texte contenant le prix, les spécifications ou la mention “livraison gratuite”. |
| Requête de longue traîne | Très haute | La première phrase sous le titre H2 correspondant au mot spécifique de longue traîne. |
Pour une même URL, Google peut générer des centaines d’extraits différents.
Par exemple, lorsqu’une page concernant un “Guide d’achat de services Cloud” est classée sous deux termes d’intentions différentes tels que “Comparaison des prix des services Cloud” et “Tests de sécurité des services Cloud”, une méta-description statique peut difficilement couvrir simultanément ces deux dimensions.
Le mécanisme de réécriture dynamique de Google analyse la structure du corps de la page ; s’il découvre un tableau listant les prix en détail, l’algorithme extraira automatiquement le texte proche du tableau comme extrait lorsque l’utilisateur recherche “prix”.
Si le corps de la page manque d’une structure de paragraphes logiquement claire, l’algorithme pourrait saisir le menu de navigation, le texte du pied de page ou les liens de la barre latérale, produisant ainsi un extrait de recherche dénué de toute logique, ce qui est généralement dû à un manque d’efficacité de la densité textuelle du corps de la page.
Lors du traitement de pages contenant de nombreuses spécifications techniques ou attributs de produits, si la page utilise le balisage Schema Product ou Review mais que la méta-description ne reflète pas ces attributs clés, Google réécrira souvent la description pour y inclure la note, le prix ou l’état des stocks.
Si la méta-description est simplement “Consultez notre dernière collection de chaussures de sport” alors que le corps du texte contient des données concrètes comme une “note de résistance à l’usure de 9,5” ou un “poids de 250g”, l’algorithme jugera que ces dernières ont plus de valeur de référence pour l’utilisateur.
Pour maintenir l’affichage de la description prédéfinie, il faut s’assurer que la densité d’information dans la description n’est pas inférieure au niveau moyen des 300 premiers caractères du corps du texte.
Réduire les réécritures
Si la méta-description prédéfinie ne contient pas les trois principaux termes de recherche pour lesquels la page est classée, la probabilité de réécriture automatique par Google grimpera à plus de 80%.
Pour réduire cette intervention, il convient d’insérer naturellement les termes à haute fréquence exportés de la GSC dans les 65 premiers caractères de la description.
En pratique, il est nécessaire de maintenir une haute cohérence sémantique entre le contenu de la description, la balise H1 de la page et le premier paragraphe du corps du texte.
Lors de la rédaction, il faut éviter les termes promotionnels vagues et privilégier des phrases déclaratives contenant des paramètres spécifiques, des noms de marque ou des instructions d’action claires.
- Contrôle précis des caractères et des pixels : La limite de largeur d’affichage des résultats sur ordinateur est d’environ 920 à 960 pixels, contre 600 à 680 pixels sur mobile. Comme différents caractères occupent des pixels différents, le simple comptage des caractères n’est pas précis. Il est conseillé d’utiliser des outils de vérification de pixels pour s’assurer que la description se termine dans les 920 pixels, évitant ainsi une information incomplète due à une troncature finale, car les phrases incomplètes sont souvent jugées comme des affichages de faible qualité par l’algorithme, déclenchant ainsi la réécriture automatique.
- Élimination du contenu de modèle répétitif : Lors de la gestion de grands sites d’e-commerce possédant des milliers de pages, évitez que tout le site partage le même modèle de méta-description. Si les descriptions d’un grand nombre d’URL ne présentent que des différences minimes, les outils de capture de Google ignoreront ces balises, les jugeant trop peu spécifiques. Il est recommandé de rédiger manuellement des descriptions uniques pour les pages à fort trafic et de s’assurer que les fragments générés par programme pour les pages de longue traîne sont suffisamment distinctifs.
- Choix de verbes correspondant à l’intention de recherche : Pour les requêtes d’information (Informational Queries), le début de la description devrait utiliser des verbes directeurs comme “Apprendre”, “Comparer” ou “Découvrir” ; pour les requêtes transactionnelles (Transactional Queries), elle devrait inclure des mots concrets comme “Acheter”, “Télécharger” ou “Prix”. Ajuster le ton de la description pour qu’il corresponde au style des autres résultats les mieux classés dans la SERP peut efficacement aider à maintenir la description.
Dans les audits SEO réels, on constate que de nombreux sites, bien qu’ayant défini des méta-descriptions, ont un contenu en décalage avec le sujet principal de la page.
Par exemple, une page sur les “meilleures chaussures de course” dont la méta-description discute de l’histoire de la marque provoquera l’intervention de l’algorithme en raison de ce décalage sémantique.
Concevoir la méta-description comme un résumé précis du contenu de la page, incluant 2 à 3 termes de longue traîne, peut augmenter significativement sa fréquence d’affichage dans les résultats de recherche.
Il faut veiller à éviter les caractères spéciaux en HTML ; certains symboles non échappés peuvent causer des erreurs d’analyse, empêchant Google de lire l’intégralité de la méta-description et le poussant à extraire des fragments aléatoires des paragraphes de texte.
- Logique d’optimisation basée sur les données : Vérifiez régulièrement les fluctuations du CTR dans la GSC. Si le classement moyen d’une page ne change pas mais que son CTR subit une baisse de plus de 3%, vérifiez si l’extrait dans la SERP a été réécrit. Si vous constatez que le contenu réécrit provient principalement de la section FAQ de la page, cela signifie que la méta-description originale ne couvrait pas les questions des utilisateurs ; il convient alors de réajuster la structure logique de la méta-description en s’inspirant du fragment réécrit.
- Distribution du poids sémantique : Placez l’information la plus importante au tout début de la phrase. Les études montrent que l’attention des outils de capture de Google portée au début de la méta-description est bien supérieure à celle portée à la fin. Les 50 premiers caractères doivent pouvoir exprimer indépendamment la proposition de valeur principale de la page.
- Éviter l’utilisation excessive de ponctuation : Trop de points d’exclamation ou de points de suspension consécutifs réduisent le professionnalisme de la description, et l’algorithme aura tendance à masquer ce type de contenu aux caractéristiques de spam. Gardez une structure de phrase sobre, neutre et conforme aux normes d’expression académique ou professionnelle.
Lors du traitement des données structurées (Schema Markup), si la page utilise une architecture FAQ ou Product, la méta-description doit jouer un rôle de liaison et d’annonce plutôt que de s’y répéter totalement.
Pour les pages contenant de nombreuses spécifications techniques, essayez d’inclure des données chiffrées concrètes dans la description, comme “Poids de seulement 1,2 kg” ou “Supporte la résolution 4K”.


