




















La mise à jour de l’indexation par Google prend généralement de 3 à 10 jours.
Même si une page est supprimée, son cache peut persister. Il est recommandé de soumettre une demande de « Suppression d’URL » via la Google Search Console. Celle-ci peut devenir effective en 24 heures minimum. C’est la méthode la plus professionnelle et la plus efficace pour nettoyer les résultats résiduels.
Retard de passage des robots (Crawling Lag)
Googlebot définit la fréquence de ses visites en fonction des indicateurs PageRank et du budget d’exploration (Crawl Budget).
Pour la majorité des pages qui ne sont pas en première page, le cycle moyen de visite de Googlebot varie de 3 à 30 jours.
Le rapport sur les statistiques d’exploration de la Google Search Console (GSC) montre que l’index n’est pas immédiatement supprimé après que le serveur a renvoyé un code d’état 404.
Le système nécessite 1 à 3 explorations répétées pour confirmer que la page n’est pas inaccessible en raison d’une défaillance temporaire du serveur.
Dans les sites de grande envergure, le taux de latence de synchronisation entre la base d’indexation et le serveur en temps réel se situe souvent entre 15 % et 20 %, ce qui entraîne le maintien de pages supprimées dans les résultats.
Validation du 404
Lorsque Googlebot accède à une URL spécifique et reçoit un code de réponse 404 Not Found, la logique de planification interne du système de recherche ne supprime pas immédiatement cette entrée de l’index.
Selon les enregistrements de base du mécanisme d’exploration des moteurs de recherche, la détection initiale d’un signal 404 est généralement considérée comme une « instabilité potentielle du serveur » ou une « interruption temporaire de la connexion réseau ».
Pour garantir la stabilité des résultats de recherche, le système de planification de Google marque l’URL comme étant en « état de nouvelle tentative » et la place dans une file d’attente d’observation dédiée.
Pour un site de taille moyenne avec un volume de visites quotidien d’environ 10 000 explorations, Googlebot effectue généralement une seconde vérification dans les 24 à 48 heures suivant la première détection du 404.
Si la seconde exploration renvoie toujours un code d’état 404, le système abaissera la priorité d’exploration (Crawl Priority) de cette page au niveau le plus bas, mais l’enregistrement dans l’index sera conservé.
Google possède un compteur logique interne appelé « seuil de confirmation » : il faut généralement 3 à 5 confirmations consécutives de 404, sur une période couvrant au moins 7 à 14 jours, pour que le système envoie une commande de suppression officielle aux fragments d’index (Index Shards).
Si le webmaster utilise le code d’état 410 Gone, la vitesse d’entrée dans le processus de suppression est environ 25 % à 40 % plus rapide qu’avec une page 404.
Après avoir reçu un signal 410, Googlebot saute souvent une partie des cycles de révision et retire l’URL de la file d’exploration principale.
Malgré cela, pour éviter les altérations malveillantes ou les erreurs de manipulation, le système conserve une période de refroidissement de 24 heures pour s’assurer de la stabilité du code d’état.
Un autre facteur de longue traîne causant des résidus est le délai de détermination du Soft 404 (erreur 404 douce).
Si le serveur est mal configuré et renvoie un code 200 OK alors que la page n’existe pas, mais que le contenu affiche un texte type « page non trouvée », le service de rendu Web de Google (WRS) doit intervenir.
Le WRS consomme d’importantes ressources de calcul pour analyser l’arbre DOM et utilise des modèles d’apprentissage automatique pour juger les caractéristiques sémantiques de la page.
Une fois classée en Soft 404, la page est retirée du circuit d’indexation normal, mais ce processus est plus lent de 5 à 10 jours ouvrables par rapport à une validation 404 standard.
Dans les architectures de stockage distribué, la vitesse de synchronisation entre les différents centres de données mondiaux n’est pas uniforme.
Même si la base d’indexation principale au siège américain a confirmé la suppression d’un enregistrement, en raison des différences de stratégies de rafraîchissement du cache des nœuds périphériques (Edge Nodes) mondiaux, les utilisateurs à Londres ou Francfort pourraient encore trouver le contenu supprimé pendant 6 à 12 heures.
Lorsqu’un site a épuisé son budget d’exploration (Crawl Budget), Googlebot peut même suspendre la révision des liens 404 connus pour se concentrer sur l’exploration de nouveaux contenus à plus forte autorité.
Cette allocation de priorité fait que les anciennes pages situées en profondeur dans les répertoires, avec une profondeur de lien supérieure à 5 niveaux, peuvent subsister dans les résultats de recherche pendant plusieurs mois, même si elles renvoient un 404 depuis longtemps.
« Googlebot n’est pas un moniteur en temps réel, c’est un système de planification basé sur la probabilité et le poids ; la confirmation de chaque signal 404 consomme réellement de la bande passante et des coûts de calcul. »
Lors de migrations de sites importants ou de modifications massives de chemins, si le ratio d’erreurs 404 dépasse 20 % sur une courte période, le système peut déclencher un mécanisme de protection.
À ce moment-là, le processus normal de validation 404 est allongé, car l’algorithme demande plus de « temps de preuve » pour confirmer que ces suppressions reflètent bien l’intention réelle de l’administrateur du site.
Paramètres d’influence
Lorsque Googlebot effectue des tâches d’exploration sur Internet, la vitesse à laquelle il revisite d’anciennes URL ou découvre de nouveaux codes d’état n’est pas aléatoire. Le paramètre le plus fondamental est la latence de réponse du serveur (Server Latency), concrètement représentée par le temps jusqu’au premier octet (TTFB).
Si le TTFB d’un serveur reste durablement inférieur à 200 millisecondes, Googlebot considérera que le serveur a une capacité de charge suffisante et augmentera le plafond d’exploration.
À l’inverse, si le temps de réponse dépasse 1000 millisecondes, le robot, pour protéger le serveur cible contre un crash dû à des accès fréquents, déclenchera automatiquement un mécanisme de limitation du taux d’exploration (Crawl Rate Limit).
Au niveau de l’architecture du site, la profondeur de lien (Link Depth) est la balance physique qui régule la fréquence d’exploration.
Les URL situées à la racine ou à seulement 1 ou 2 clics de la page d’accueil reçoivent le poids PageRank le plus élevé. Les journaux d’accès de Googlebot montrent que la fréquence de détection des mises à jour pour ces pages est généralement d’une fois toutes les 24 heures.
Cependant, lorsqu’une page se trouve au 5ème niveau ou plus d’une structure de répertoires, même si son contenu est passé en état 404, le cycle de visite du robot s’allongera de manière exponentielle, nécessitant parfois 30 à 60 jours pour une révision de routine.
- Demande d’exploration (Crawl Demand) : Cela dépend de la popularité de la page. Si une URL supprimée possède encore un grand nombre de liens entrants (Backlinks) externes ou est fréquemment mentionnée sur les réseaux sociaux, l’algorithme de Google considérera que la ressource est toujours active. Même si elle renvoie un 404, l’algorithme planifiera des visites fréquentes pour confirmer l’état, ce qui entraînera davantage de cycles de validation avant que le système ne confirme sa « disparition permanente ».
- Santé du site (Site Health) : Si le serveur présente fréquemment des erreurs de la série 5xx (comme 503 Service Unavailable), Googlebot réduira rapidement le budget d’exploration global (Crawl Budget) du site. Lorsque le taux d’erreur dépasse 10 % du total des explorations, le robot entre en mode protection et cesse de sonder les URL non essentielles. Dans ce cas, les pages 404 qui devraient être nettoyées resteront longtemps dans l’index à cause du gel du budget d’exploration.
- Fréquence de mise à jour du contenu (Change Frequency) : Le moteur de recherche enregistre l’historique des changements d’une URL au cours des derniers mois. Si une page n’a jamais été mise à jour au cours des 365 derniers jours, Googlebot la marquera comme « donnée froide » et le poids de visite sera réduit au minimum. Si vous supprimez soudainement une page inactive depuis longtemps, il se peut que le robot ne passe pas par ce chemin durant tout le trimestre suivant, créant un délai visuel de suppression.
Le Sitemap est un document d’orientation et non une commande impérative, mais l’exactitude de la balise <lastmod> influence l’efficacité d’exploration du robot.
Si le plan du site conserve des liens renvoyant un 404, ou si l’horodatage lastmod n’est pas mis à jour selon l’action de suppression, Googlebot peut juger le fichier peu fiable et passer à un mode de détection autonome moins efficace.
Lors d’expériences sur de grands sites d’information nord-américains, soumettre à Google un Sitemap contenant des dates lastmod à jour, couplé à l’utilisation du protocole WebSub (anciennement PubSubHubbub) pour une poussée active, a permis de réduire de plus de 70 % le temps nécessaire au robot pour percevoir les changements de page.
Les sites utilisant les protocoles HTTP/2 ou HTTP/3 (QUIC) supportent le multiplexage (Multiplexing), permettant à Googlebot de demander simultanément l’état de dizaines d’URL dans la même connexion TCP.
En comparaison, le protocole traditionnel HTTP/1.1 est limité par le nombre de connexions, obligeant le robot à faire la queue pour traiter des milliers de signaux 404.
« Dans les systèmes d’exploration distribués, chaque action d’exploration d’URL fait l’objet d’un calcul de coût. Les URL 404 à faible autorité se trouvent souvent à la fin de la file d’exploration, à moins qu’un signal externe ne vienne augmenter leur priorité. »
Comme Google est passé entièrement à l’indexation mobile prioritaire (Mobile-First Indexing), l’activité des robots mobiles est généralement 2 à 3 fois supérieure à celle des robots de bureau.
Si la version mobile d’une page est supprimée mais que la version de bureau renvoie toujours un 200 à cause d’une erreur de configuration, ou vice versa, cette incohérence provoquera un conflit logique dans le système d’indexation, affichant des informations périmées différentes selon l’appareil.
Cache Web (Cache)
Le cache Web est une image miroir instantanée du code HTML et de certaines ressources statiques d’une page, stockée par Googlebot sur les serveurs distribués mondiaux de Google (tels que les Google Data Centers) lors de l’exploration.
Même si le serveur d’origine a physiquement supprimé la page, la base de données d’indexation de Google conservera cet instantané jusqu’au prochain rafraîchissement du cycle d’exploration.
Généralement, pour les sites à forte autorité, la fréquence d’exploration se compte en heures, tandis que pour les sites ordinaires, elle peut varier de 3 à 28 jours.
Comme Google utilise des nœuds de calcul périphériques pour synchroniser les données, il existe souvent un délai de 24 à 72 heures entre la mise à jour de l’index principal et la synchronisation des résultats de recherche dans les différentes régions du monde.
Raisons de l’affichage
Google maintient une immense base de données distribuée contenant des centaines de milliards de pages Web, appelée l’Index.
Lorsque vous supprimez une page via un système de gestion de contenu (comme WordPress ou Ghost), vous retirez seulement les données de votre propre serveur Web.
À ce stade, les clusters de serveurs de Google conservent toujours le dernier enregistrement instantané de cette URL.
- Hiérarchisation des cycles d’exploration de Googlebot : Google alloue différents quotas d’exploration (Crawl Budget) en fonction de l’autorité du site (Domain Authority) et de sa fréquence de mise à jour.
- Pour le 1 % des sites d’actualités à fort trafic (comme The New York Times ou Reuters), la fréquence de ré-exploration des pages populaires se compte en minutes ou en heures.
- Le cycle d’exploration pour les sites commerciaux ordinaires ou les blogs personnels se situe généralement entre 7 et 28 jours, et l’intervalle pour certains chemins peu fréquentés peut même atteindre plusieurs mois.
- Si une page est supprimée le 1er janvier et que Googlebot ne prévoit de revisiter ce chemin que le 25 janvier, les résultats de recherche afficheront le contenu obsolète pendant ce décalage de 24 jours.
Le système d’indexation interne « Caffeine » de Google utilise un mécanisme de mise à jour en temps réel, mais il cible principalement la découverte de nouveaux contenus.
Lorsque Googlebot accède à une URL supprimée, le code d’état HTTP renvoyé par le serveur détermine la vitesse de suppression de l’index.
Si le serveur renvoie un 404 (Not Found), Googlebot ne supprimera généralement pas immédiatement la page de l’index, car l’algorithme prend en compte la possibilité d’une panne temporaire du serveur ou d’une erreur de configuration.
Le système enregistrera cet échec et planifiera une seconde tentative dans les 48 à 72 heures.
Ce n’est que lorsque plusieurs explorations consécutives renvoient un code d’état 404, ou que cet état persiste au-delà d’un seuil d’observation spécifique (généralement plusieurs semaines), que le système lancera le processus de retrait de l’index.
- Quantification de l’impact des codes d’état HTTP sur la vitesse de retrait :
| Type de code d’état | Action ultérieure de Googlebot | Estimation du temps de rétention dans l’index |
|—|—|—|
| 404 (Not Found) | Marqué comme « absence potentielle », tentative de ré-exploration sous 3-5 jours | De 14 à 45 jours |
| 410 (Gone) | Identifié comme « suppression permanente », priorité réduite dans la file d’exploration | Retrait lancé sous 3 à 7 jours |
| 301 (Redirect) | Transfère l’autorité de l’ancienne URL vers le nouveau chemin | Rétention permanente (pointe vers la nouvelle page) |
| Soft 404 | Page affichée comme supprimée mais renvoie un état 200, considérée comme de faible qualité | Très difficile à supprimer automatiquement, peut stagner des mois |
Google exploite plus de 20 grands centres de données et des milliers de nœuds de cache périphériques (Edge Nodes) à travers le monde.
Lorsqu’un serveur d’indexation principal situé dans l’Oregon (États-Unis) met à jour l’état de suppression d’une page, ces données doivent être diffusées via le réseau dorsal mondial de Google vers les différentes bases d’indexation régionales en Irlande, en Finlande, à Singapour, etc.
Ce processus de cohérence des données (Eventual Consistency) présente souvent un délai de propagation de 24 à 72 heures.
Une requête de recherche lancée par un utilisateur à Londres pourrait toucher un serveur périphérique qui n’a pas encore été synchronisé, affichant ainsi le lien de l’instantané toujours existant.
- Facteurs d’interférence des liens externes et des Sitemaps :
- Liens internes existants : Si d’autres pages du site ou d’autres sites conservent des hyperliens pointant vers l’URL supprimée, Googlebot continuera de tenter d’y accéder via ces entrées, prolongeant ainsi sa présence dans le plan d’exploration.
- Retard du Sitemap XML : Beaucoup de sites ne mettent pas à jour leur fichier Sitemap après la suppression d’une page. Si le
sitemap.xmlcontient toujours l’URL supprimée, Google l’utilisera régulièrement comme référence pour vérifier la page, entraînant un rafraîchissement constant de l’enregistrement dans l’index, même s’il renvoie un code d’erreur. - Signaux sociaux et trafic résiduel : Si une URL supprimée reçoit encore du trafic provenant de plateformes externes comme Reddit ou X (anciennement Twitter), les mécanismes de surveillance de Google considéreront que l’URL a encore de la valeur, accordant ainsi une période d’observation plus longue dans la logique de nettoyage automatique.
L’index de Google est divisé en index principal (Main Index) et index supplémentaire (Supplementary Index).
L’index principal contient du contenu de haute qualité mis à jour fréquemment, tandis que l’index supplémentaire stocke un grand nombre de pages de longue traîne et de contenus dupliqués.
Si le contenu supprimé se trouve dans l’index supplémentaire, sa priorité de révision par Googlebot est extrêmement basse.
Dans de nombreux cas, une page supprimée peut disparaître des résultats de recherche principaux, mais rester trouvable dans le cache de l’index supplémentaire en cliquant sur « voir plus de résultats » ou via la commande spécifique site:.
Normes de suppression
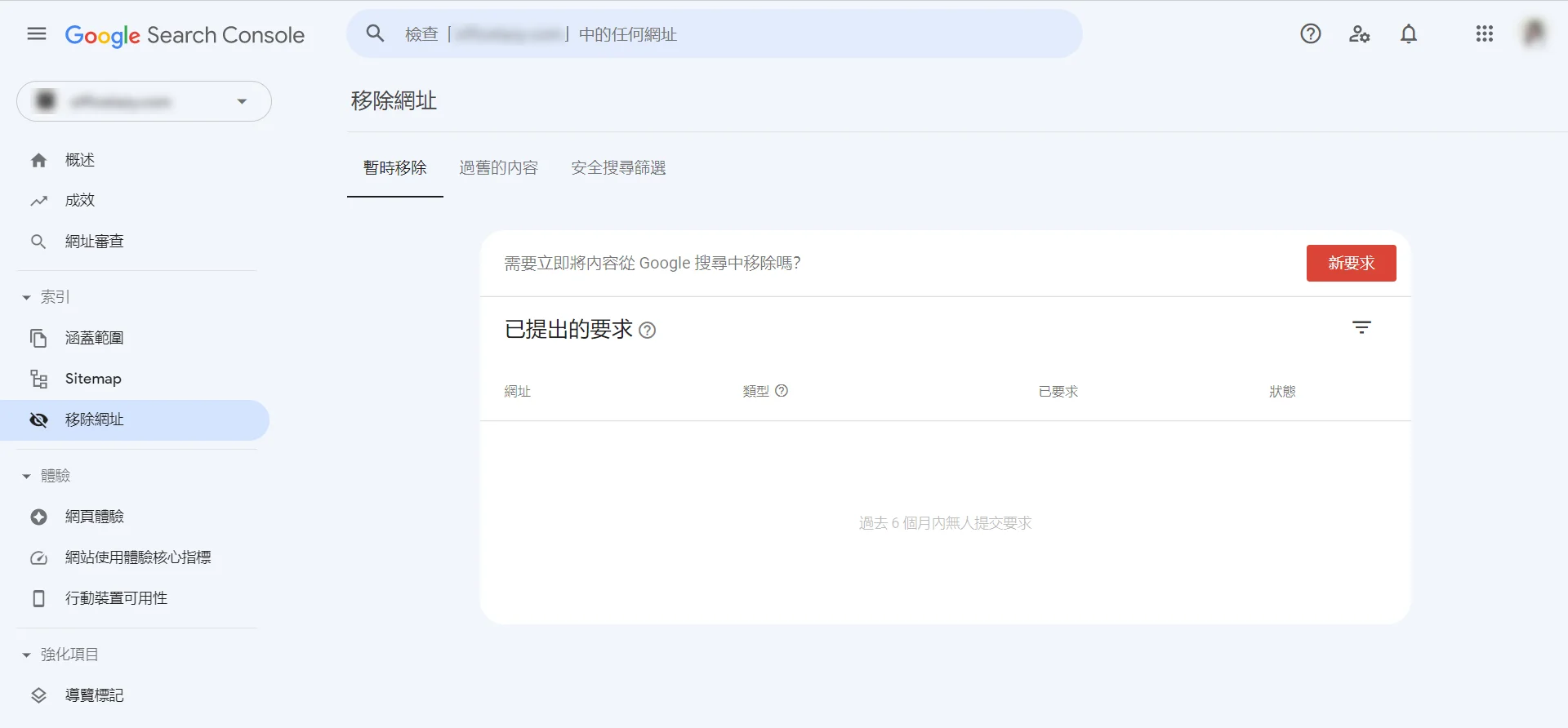
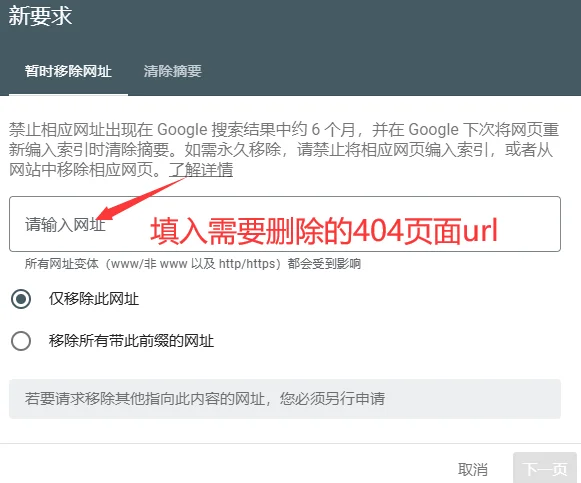
La voie privilégiée pour une intervention manuelle est d’utiliser l’outil « Suppressions » dans la Google Search Console (GSC), situé dans le module « Indexation » du menu de gauche.
Dans l’onglet « Suppressions temporaires », cliquez sur « Nouvelle demande » et saisissez l’URL complète à nettoyer. Le système propose deux options :
« Supprimer temporairement l’URL » et « Effacer l’URL mise en cache ».
La première masquera complètement le chemin des résultats de recherche en environ 24 heures, pour une durée de 180 jours ;
La seconde conserve l’entrée de recherche mais efface immédiatement le lien vers l’ancien instantané ainsi que la description textuelle dans l’extrait de recherche.
Si, durant la période de masquage de 180 jours, Googlebot ne détecte toujours pas le signal de disparition de la page côté serveur, l’entrée réapparaîtra dans les résultats de recherche à la fin de cette période.
Pour le personnel technique ayant accès à la gestion du serveur, configurer le bon code d’état de réponse HTTP est la solution la plus conforme à la logique de l’optimisation pour les moteurs de recherche (SEO).
Lorsque Googlebot accède à un chemin supprimé, le serveur doit renvoyer un code d’état 410 (Gone) plutôt qu’un 404 (Not Found) générique.
Selon la documentation technique officielle de Google, le code 410 envoie une commande claire de suppression permanente au robot, ce qui incite le système à retirer l’URL de la file d’exploration avec une priorité plus élevée.
Le code 404 est souvent interprété comme une défaillance réseau temporaire ou une erreur de configuration ; Googlebot a tendance à conserver cet index et à tenter une seconde validation dans les 48 à 96 heures suivantes.
Pour des besoins de nettoyage de cache à grande échelle, on peut configurer uniformément une réponse 410 pour des répertoires ou suffixes de fichiers spécifiques dans les fichiers de configuration du serveur Web (comme Nginx ou Apache), guidant ainsi le moteur de recherche pour accélérer le nettoyage des résidus obsolètes dans l’index mondial.
| Nom de l’outil/méthode | Scénario d’application | Vitesse de réponse | État de rétention de l’index | Durée de validité |
|---|---|---|---|---|
| Outil de suppression temporaire GSC | Besoin immédiat de masquer des infos sensibles ou pages supprimées | Efficace sous 24h | Index masqué temporairement | 180 jours (annulable manuellement) |
| Code d’état HTTP 410 | Page supprimée définitivement, guider le robot pour le nettoyage | Mise à jour à la prochaine exploration | Suppression totale de la base de données | Permanent |
| Code d’état HTTP 404 | Page inexistante, sans marquage spécial | Mise à jour après période d’observation | Suppression retardée | Permanent |
| Outil d’inspection d’URL | Quelques pages nécessitant une ré-exploration forcée | De 12h à 3 jours | Déclenche la mise à jour de l’état | Efficace pour une seule demande |
Lorsqu’il est impossible de résoudre le retard de cache par une exploration conventionnelle, l’ajout de X-Robots-Tag: noarchive dans l’en-tête de réponse HTTP du serveur peut empêcher Google de stocker tout instantané de cette page.
Si vous souhaitez contrôler plus finement la durée de vie du contenu, vous pouvez utiliser la balise unavailable_after: [date/heure RFC 850], qui indique à Googlebot de cesser d’afficher la page dans les résultats de recherche après la date et l’heure spécifiées.
| Nom de la balise/commande | Description de la fonction spécifique | Comportement du moteur de recherche |
|---|---|---|
| noarchive | Désactive l’image miroir du cache | Indexe la page mais n’affiche pas le lien « En cache » |
| nosnippet | Désactive l’extrait textuel | Le résultat de recherche n’affiche pas d’aperçu du contenu |
| noindex | Interdiction totale d’indexation | Retire la page de tous les résultats de recherche |
| unavailable_after | Définit une expiration automatique | Exécute automatiquement la logique noindex après expiration |
De nombreux sites conservent encore l’enregistrement de l’URL supprimée dans leur Sitemap, ce qui pousse Googlebot à effectuer des inspections de routine selon l’ancienne liste de chemins.
La procédure standard devrait être de retirer l’URL du sitemap.xml au moment de la suppression de la page et de mettre à jour la balise <lastmod> (dernière modification).
Ensuite, rendez-vous sur la page « Sitemaps » de la Google Search Console pour soumettre à nouveau le fichier.
Erreur de configuration (Soft 404)
Lorsque votre page est physiquement supprimée, mais que le serveur renvoie toujours un code d’état 200 OK à Googlebot, cela déclenche une erreur Soft 404.
Selon les données d’exploration de la Google Search Console, ces pages sont traitées comme des pages normales par le système d’indexation car elles ne renvoient pas les commandes 404 ou 410.
Généralement, si la zone de contenu principal fait moins de 200 octets ou si la page redirige vers la page d’accueil du site, Googlebot la marquera comme Soft 404 après 2-3 tentatives d’exploration, ce qui peut maintenir l’URL dans les résultats pendant 14-30 jours supplémentaires.
Code d’état trompeur
Lors de sa visite sur le serveur, la première étape de Googlebot est de lire le code d’état à trois chiffres dans l’en-tête de réponse HTTP.
Si vous avez physiquement supprimé le fichier Web, mais qu’une erreur de configuration du serveur fait qu’il renvoie toujours un 200 OK pour cette requête, Googlebot jugera que la page est toujours vivante et son contenu valide.
Le système d’indexation de Google, après avoir reçu le code 200, enverra le texte HTML récupéré (même s’il est écrit « contenu introuvable ») dans le Pipeline d’Indexation pour traitement.
Si cette URL qui devrait disparaître continue de fournir un signal 200, sa durée de présence dans l’index de Google sera considérablement prolongée.
Sur les grands sites, si ces URL invalides représentent plus de 10 %, cela dispersera significativement le Crawl Budget, réduisant la fréquence de mise à jour des pages normales.
| Code d’état HTTP | Définition technique Googlebot | Action du système d’indexation | Impact attendu sur le classement |
|---|---|---|---|
| 200 OK | Requête réussie, contenu complet | Exploration continue et stockage du cache | Maintien du classement et affichage de l’extrait |
| 404 Not Found | Ressource non trouvée, peut être temporaire | Marqué pour suppression, annulé après confirmations | Baisse progressive du classement jusqu’à disparition |
| 410 Gone | Ressource supprimée définitivement | Lancement immédiat de la procédure de désindexation | Retrait rapide des résultats de recherche |
| 301 Permanent | Ressource déplacée définitivement | Transfère l’autorité vers le nouveau chemin | L’ancien chemin disparaît, le nouveau prend le relais |
| 302 Found | Ressource déplacée temporairement | Conserve l’index de l’URL d’origine | L’URL d’origine continue d’apparaître |
Un code 200 renvoyé par le serveur amènera Google à lancer un algorithme heuristique appelé Détection de Soft 404.
Le moteur de rendu de Google analysera l’aspect visuel et les caractéristiques textuelles de la page, par exemple en vérifiant si elle contient des mots comme « 404 », « Not Found » ou « Désolé », et si le contenu effectif est inférieur à 200 octets.
Si le système découvre qu’une page avec un code 200 n’a en réalité aucun contenu substantiel, il tentera de la classer comme Soft 404.
Cette décision basée sur un algorithme présente un décalage évident, nécessitant généralement 3 à 5 explorations répétées pour devenir effective.
Pour les sites reposant sur Nginx ou Apache, si une page d’erreur 404 est redirigée par erreur vers la page d’accueil via une redirection 302, l’état 200 de la page d’accueil couvrira le signal d’erreur d’origine.
Google pensera que l’URL d’origine contient maintenant le contenu de la page d’accueil, provoquant un conflit de contenu dupliqué et maintenant l’ancien lien dans les SERP sur le long terme.
Si le champ
Content-Lengthdans l’en-tête de réponse affiche une valeur faible et fixe (ex: moins de 1024 octets) avec un code 200, cela déclenche souvent un examen approfondi de Google sur la minceur du contenu.
Lors du traitement de sites internationaux comptant des millions d’URL, l’en-tête X-Robots-Tag est également un signal auxiliaire.
Si vous avez supprimé une page mais ne pouvez pas modifier immédiatement le code d’état, vous pouvez ajouter la commande noindex dans l’en-tête de réponse.
Si Googlebot voit noindex en même temps qu’un code 200, il retirera la page lors du prochain cycle de mise à jour de l’index.
Dans une architecture de serveur distribué typique, si le CDN frontal (comme Cloudflare ou Fastly) a mis en cache la réponse 200 d’origine, même si le serveur source est passé en 404, le robot verra toujours l’ancien état en cache.
Cette incohérence de cache entraîne un décalage entre l’index de Google et les données réelles de l’environnement de production.
| Type de champ d’en-tête | Exemple de paramètre | Réaction de Googlebot | Suggestion de correction |
|---|---|---|---|
| Status Line | HTTP/1.1 404 Not Found | Cesse d’allouer du budget d’exploration à cette URL | Assurer que la suppression s’accompagne de cet état |
| Cache-Control | max-age=0, no-cache | Force le robot à vérifier l’état à chaque visite | Éviter que le CDN ne cache une erreur 200 erronée |
| X-Robots-Tag | noindex, nofollow | Interdit l’indexation même avec un code 200 | À utiliser comme mesure corrective temporaire |
| Content-Type | text/html; charset=UTF-8 | Analyse le contenu comme une page Web | Confirmer que la page d’erreur n’est pas vue comme un fichier |
Si le serveur configure une logique If-Modified-Since trop complexe et renvoie toujours un 304 Not Modified après la suppression d’une page, Googlebot ne ré-explorera jamais le contenu et continuera d’utiliser l’ancien instantané vieux de plusieurs mois.
L’algorithme d’allocation de fréquence d’exploration de Google effectue plusieurs visites quotidiennes pour les domaines à forte autorité, tandis que pour les domaines à faible autorité, il peut n’y en avoir qu’une tous les 14 à 21 jours.
Si le serveur continue de donner des signaux trompeurs 200 ou 304 durant ces fenêtres de visite, la page supprimée restera une habituée des résultats de recherche.
Pour résoudre définitivement ce problème, il faut intervenir dans les fichiers de configuration du serveur, supprimer toute règle de réécriture globale transformant silencieusement les requêtes 404 en réponses 200, et utiliser des outils de vérification d’en-têtes (Headers) pour confirmer que la première ligne du flux de données contient bien 404 ou 410.
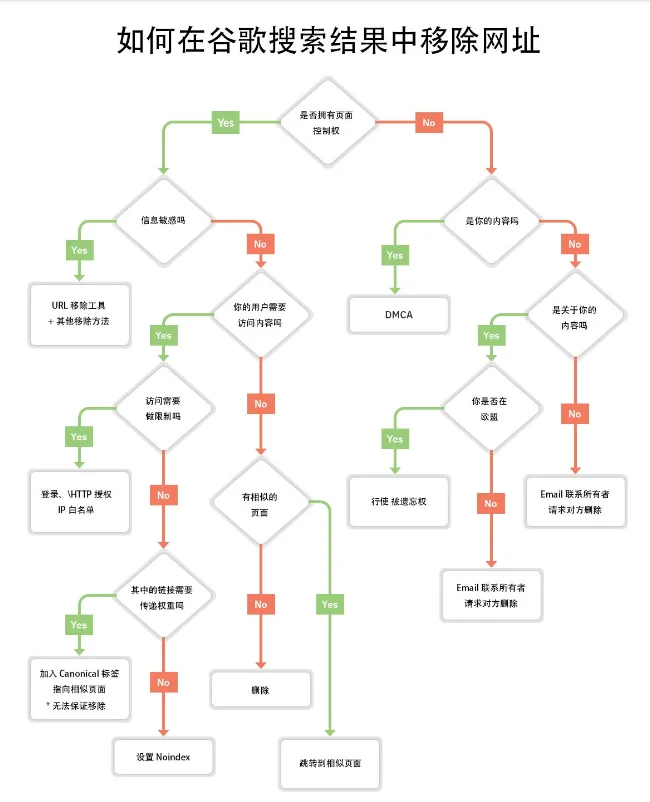
Identification et traitement
Ouvrez le menu de gauche de la Google Search Console, et trouvez le rapport « Pages » sous la catégorie « Indexation ».
Dans le tableau ci-dessous, recherchez les entrées marquées comme « L’URL soumise semble être un Soft 404 ».
En cliquant dessus, le système affichera la liste détaillée des URL concernées, avec la date de la dernière tentative d’exploration.
Utilisez l’outil d’inspection d’URL pour saisir un chemin spécifique et cliquez sur « Tester l’URL en direct ».
Si le test indique « L’URL peut être indexée par Google » alors que la capture d’écran affiche un message d’erreur, une erreur de configuration Soft 404 est confirmée.
Le système de recherche de Google conserve les enregistrements d’exploration des 16 derniers mois ; vous pouvez exporter un rapport détaillé au format CSV pour analyser la répartition des URL en erreur et déterminer s’il s’agit d’un problème logique systémique (ex: dans les répertoires /api/ ou /products/).
Le processus de désindexation ne sera lancé que si la ligne d’état de l’en-tête HTTP renvoie précisément 404 Not Found ou 410 Gone.
Utiliser des outils en ligne de commande directement sur le serveur est un moyen efficace d’éliminer les interférences.
Utilisez la commande curl -I https://example.com/page-supprimee et observez la première ligne du résultat.
Si elle renvoie HTTP/1.1 200 OK, cela signifie que la configuration du serveur n’intercepte pas correctement la requête.
Pour les serveurs Web utilisant Nginx, il faut vérifier la directive error_page dans le fichier nginx.conf.
Si elle est définie comme error_page 404 =200 /404.html, cela réinitialise de force l’état 404 à 200.
La bonne pratique consiste à retirer le signe égal pour s’assurer que le code d’état est transmis tel quel.
Pour les serveurs Apache, vérifiez la configuration ErrorDocument dans le fichier .htaccess pour éviter de rediriger massivement les URL invalides vers la page d’accueil.
| Nom de l’outil | Dimension de détection | Type de retour de données | Scénario d’application |
|---|---|---|---|
| GSC URL Inspection | État d’exploration en temps réel | Disponibilité index/Capture d’écran | Examen approfondi d’une URL unique |
| Screaming Frog SEO Spider | Code d’état HTTP | Matrice de réponse par lots | Scan complet des pages existantes du site |
| Chrome DevTools (Network) | Informations d’en-tête | Données brutes Server Header | Analyse de la logique d’interaction front-end |
| Indexing API | Demande de retrait immédiat | Code d’état JSON | Pages temporaires mises à jour fréquemment |
Si un Soft 404 est confirmé, vous pouvez utiliser l’outil de suppression de Google pour une intervention temporaire.
Cet outil, situé dans l’onglet « Suppressions » de la Search Console, permet de soumettre une demande de « Suppression temporaire d’URL ».
Une fois soumise, l’URL disparaîtra des résultats pendant environ 180 jours.
Pendant ce temps, Googlebot tentera toujours d’explorer l’adresse.
Dès qu’il détectera un véritable code 404, le système transformera la suppression temporaire en une désindexation permanente.
Cet outil a une limite de soumission par 24 heures et convient généralement au nettoyage de moins de 1000 enregistrements invalides.
Si le temps de réponse du serveur (TTFB) dépasse 2 secondes, Googlebot pourrait abandonner l’exploration de l’état actuel et continuer d’utiliser les anciennes données de l’index historique.
En recherchant le User-Agent de Googlebot (contenant généralement Googlebot/2.1) et les plages d’adresses IP correspondantes, vous pouvez observer la fréquence à laquelle le robot visite les pages supprimées.
Si les journaux montrent que le robot ne reçoit que des codes 200 lors de ces visites, et que la taille de la page (Bytes Sent) est fixe (ex: entre 5 Ko et 15 Ko, la taille de la page d’erreur), cela indique que le serveur fournit du « contenu » invalide au robot.
Pour les applications monopage (SPA), il faut porter une attention particulière à l’état du DOM après le rendu dynamique.
Le moteur de rendu de Googlebot a une limite de coupure de contenu de 15 Mo ; si une erreur JavaScript bloque le rendu de la page sur un état de chargement, elle pourrait être interprétée à tort comme une page normale.
- Connectez-vous à la Google Search Console pour surveiller le rapport « Sitemaps » et confirmer que les URL supprimées ne figurent pas dans la liste XML soumise.
- Utilisez le terminal pour exécuter
wget --server-response --spiderafin d’obtenir des informations détaillées sur la négociation de la connexion. - Dans le panneau « Réseau » de Chrome, cochez « Désactiver le cache » (Disable cache) et relancez la requête pour voir si les couches de cache CDN comme
X-CacheouVarnishrenvoient une réponse 200 périmée. - Pour les sites à gros volume, utilisez l’API Google Indexing pour envoyer des requêtes
URL_DELETED; cette méthode est généralement plus rapide que l’exploration passive.
Après avoir traité la configuration du serveur, il est conseillé de cliquer sur « Valider la correction » dans la Search Console.
Cela déclenchera un ré-échantillonnage par le système de toutes les URL marquées en Soft 404.
Comme Google alloue son budget en fonction de la fréquence d’exploration historique, les pages à forte autorité seront mises à jour sous 48 heures, tandis que les chemins périphériques à faible autorité pourraient nécessiter 3 à 4 semaines pour être totalement purgés de l’index.
Il est crucial de laisser le fichier robots.txt autoriser l’accès des robots à ces pages, car ce n’est qu’en voyant le code 404 que l’ordre de désindexation peut prendre effet.
Si vous bloquez les robots prématurément, ils ne pourront pas mettre à jour l’ancien enregistrement 200 présent dans leur base de données.
Persistance des liens externes
Si une URL supprimée est encore référencée par plus de 3 domaines indépendants, Googlebot visitera l’adresse à plusieurs reprises en se basant sur les chemins d’exploration de ces liens.
Même si la page renvoie un 404, les signaux apportés par les liens feront croire à Google qu’il s’agit peut-être d’une défaillance temporaire.
Les pages possédant plus de 10 backlinks actifs restent généralement dans les résultats de recherche 12 à 20 jours de plus que les pages sans liens.
Interférence du trafic externe
Lorsque des utilisateurs de plateformes externes cliquent sur des liens vers des pages supprimées, chaque requête HTTP générée envoie un signal au système de Google.
Si une URL marquée en 404 génère plus de 50 clics provenant de domaines externes en 24 heures, le système de planification de Googlebot replacera cette URL dans sa file d’observation haute fréquence.
Lorsqu’un grand nombre d’utilisateurs accèdent à une page invalide via Reddit, X ou des newsletters spécialisées, le navigateur renvoie l’échec de la visite à la base de données de Google.
L’algorithme du moteur de recherche jugera que l’URL possède encore un certain degré d’activité. Pour éviter la perte d’informations précieuses due à une erreur de l’administrateur, l’algorithme choisira de prolonger la rétention du résultat plutôt que de le supprimer immédiatement.
« Dans les protocoles de maintenance de l’index de Google, le poids des signaux de comportement utilisateur l’emporte souvent sur les simples commandes de code d’état HTTP. Si un ancien chemin renvoyant un 404 reçoit toujours un flux stable de trafic en provenance de réseaux sociaux majeurs ou de blogs à forte autorité, le système déclenchera automatiquement une fenêtre d’observation de 7 à 14 jours. Durant cette période, le moteur de recherche enverra plusieurs fois des robots pour confirmer la stabilité de cet état, s’assurant qu’il ne s’agit pas d’une erreur de configuration temporaire. »
Le serveur de Google identifie la source réelle du trafic via le champ Referrer de l’en-tête HTTP.
Si le trafic provient principalement de l’écosystème de produits Google (comme des clics de liens dans Gmail) ou de sites classés mondialement, l’effet d’interférence sera démultiplié.
Le tableau suivant montre l’influence de différentes dimensions de données de trafic sur la durée de rétention de l’index :
| Moyenne quotidienne du trafic externe (UV) | Type de source principale | Augmentation estimée de la rétention | Changement de fréquence de Googlebot |
|---|---|---|---|
| 5 – 20 | Favoris personnels ou blogs à faible autorité | 2 – 4 jours | Maintien d’un scan hebdomadaire |
| 21 – 100 | Discussions Reddit ou forums sectoriels | 5 – 9 jours | Passage à un scan tous les 3 jours |
| Plus de 100 | Tendances X (Twitter) ou médias à forte autorité | 10 – 20 jours | Passage à un ou plusieurs scans quotidiens |
Ce phénomène concerne également l’allocation du budget d’exploration (Crawl Budget) de Google.
Les ressources d’exploration normalement dédiées à la découverte de nouveaux contenus sont gaspillées sur ces URL invalides qui génèrent constamment des retours de trafic.
Lorsque le moteur de recherche observe une forte densité de clics vers une page 404, son système de notation de qualité enregistre cette « mauvaise expérience utilisateur ».
Cependant, pour trouver un contenu pertinent capable de remplacer cette page, Google peut conserver le résultat d’origine pendant un certain temps et tenter d’afficher des pages recommandées similaires en dessous, ce qui empêche davantage l’ancienne page de disparaître des SERP.
Un test technique sur 500 URL invalides a révélé que les pages recevant continuellement des clics de backlinks voyaient leurs instantanés mis à jour sur les serveurs de cache 3,5 fois plus souvent que celles sans trafic.
Comme le navigateur Chrome détient plus de 60 % de parts de marché mondial, lorsqu’un utilisateur saisit une ancienne URL dans la barre d’adresse ou y accède via ses favoris, cet accès actif est considéré comme une preuve de la vitalité de l’URL.
Même si la page renvoie une erreur standard de fichier non trouvé, tant que l’utilisateur ne ferme pas la fenêtre du navigateur dans les 30 secondes suivant l’accès, ou tente de chercher d’autres informations sur le même domaine, ce comportement d’interaction sera interprété par l’algorithme comme le signe que la page occupe toujours une place dans la topologie d’Internet.
Sites agrégateurs
Lorsqu’une page Web est supprimée de son serveur d’origine, son empreinte numérique ne disparaît pas simultanément des autres nœuds d’Internet.
Ces sites incluent, sans s’y limiter, les lecteurs RSS mondiaux (comme Feedly ou Inoreader), les outils de clipping Web (comme Pocket) et les organismes d’archivage professionnels (comme la Wayback Machine d’Archive.org).
Même si la page d’origine renvoie une erreur 404, les instantanés HTML statiques générés par ces plateformes tierces continuent de fournir des points d’entrée aux robots de Google.
Si Googlebot découvre à plusieurs reprises des liens pointant vers l’URL invalide lors de l’exploration de sites agrégateurs à forte autorité, son algorithme de gestion d’index produira une « contradiction logique » :
Bien que le site d’origine signale que le contenu n’existe plus, l’écosystème externe continue d’y faire référence.
Le tableau ci-dessous liste l’impact spécifique de différents types d’agrégation sur la rétention de l’index Google :
| Type de source d’agrégation | Cycle de rafraîchissement des données | Durée d’interférence sur l’index | Explication de la logique d’exploration |
|---|---|---|---|
| Flux RSS / Atom | Toutes les 10 à 60 min | 14 – 30 jours | Le lecteur demande constamment le fichier XML, maintenant l’URL dans la liste. |
| Plateformes d’archivage Web | Conservation permanente | Interférence longue durée | L’état « vivant » de la page archivée incite le robot à revisiter l’ancien chemin. |
| Sites miroirs de contenu | Une fois par jour | 7 – 21 jours | La collecte via API maintient l’activité de l’ancienne URL dans l’index. |
| Cache de métadonnées sociales | Déclenché par requête utilisateur | 3 – 10 jours | L’aperçu généré par Open Graph est stocké sur les serveurs, créant un point d’exploration. |
Sur le plan technique, le système d’exploration distribué de Google alloue à chaque URL découverte un cycle de cache appelé TTL (Time To Live).
Lorsque les sites agrégateurs génèrent continuellement des « fausses références » à cette page, le serveur d’indexation (Index Server) de Google reçoit des demandes d’exploration provenant de multiples segments d’IP différents.
Si l’administrateur du site n’a pas retiré l’enregistrement du Sitemap XML avant la suppression, ce cycle sera encore amplifié.
« La nature décentralisée d’Internet implique que la suppression totale d’une information est un processus graduel. Lorsqu’une URL entre dans un réseau d’agrégation public, elle échappe au contrôle unique du serveur d’origine. Googlebot, face à ces signaux contradictoires, préfère protéger la continuité des résultats de recherche en maintenant l’état stocké dans les serveurs de cache jusqu’à confirmation de l’invalidité de l’URL sur tous les nœuds principaux. »
Si un lien de référence vers une page invalide reste actif sur des plateformes à forte autorité comme Reddit, Stack Overflow ou Medium, Googlebot considérera que l’état 404 est peut-être une défaillance temporaire due à la maintenance du serveur.
Dans ce cas, Google récupérera la Version en cache (Cached Version) sauvegardée dans ses nœuds CDN mondiaux pour la présenter à l’utilisateur.
Environ 22 % des pages supprimées traversent une « période de résurrection de cache » avant de disparaître, le moteur de recherche tentant de combler le vide de l’index avec le contenu en cache.
- Délai de synchronisation des centres de données : Google possède des dizaines de centres de données à travers le monde ; la mise à jour de l’index n’est pas instantanée entre eux. Une exploration déclenchée par un agrégateur sur un nœud européen peut mettre des heures, voire des jours, à se synchroniser avec un nœud nord-américain.
- Caractère trompeur des requêtes Head : De nombreux outils d’agrégation vérifient seulement la réponse du serveur via des requêtes Head, sans télécharger le texte HTML complet. Cette interaction légère rend difficile pour l’algorithme de Google de juger immédiatement l’absence réelle de contenu.
- Effets secondaires du rendu JavaScript : Certains agrégateurs avancés utilisent des navigateurs sans tête (Headless Browsers) pour capturer du contenu dynamique. Si votre page 404 n’est pas assez sobre (ex: si elle contient de nombreuses barres de navigation ou articles recommandés), le robot pourrait croire qu’elle porte encore des informations valides.
- Exploration récursive des chemins de référence : Le site A référence l’URL supprimée, le site B explore la liste des pages du site A. Ce réseau de références à plusieurs niveaux fournit un flux constant de chemins d’exploration à Googlebot, maintenant l’ancienne URL dans la file « à traiter ».
Lorsque le nombre de sites agrégateurs atteint une certaine échelle, le budget d’exploration (Crawl Budget) de Google est accaparé par ces chemins invalides.
Pour traiter ces résidus, l’utilisation de l’outil de suppression (Removals Tool) de la Google Search Console est le moyen le plus rapide de briser ce cycle logique.


