




















Проверка URL в GSC
Введите URL в Search Console, нажмите “Проверить просканированную страницу”, сравните исходный код HTML и убедитесь, что основное содержимое не исчезает после рендеринга.
Сравнение текстовых различий
Сравните количество текстовых символов в режимах “Просмотр кода страницы” и “Просмотреть код элемента”. Если разница в тексте превышает 20%, существует чрезвычайно высокий риск проблем с индексацией.
Rich Results Test
Используйте инструмент проверки расширенных результатов Google для просмотра скриншотов, чтобы убедиться, что критически важный контент на первом экране полностью загружается в течение 5-секундного окна рендеринга.
Официальные инструменты Google
Инструмент проверки URL в Google Search Console (GSC) — это основной способ получить данные о реальном сканировании Googlebot.
С помощью функции “Проверить URL на опубликованной странице” можно вызвать службу веб-рендеринга (WRS) для создания полной структуры DOM в течение 60–90 секунд.
GSC предоставляет отрендеренный HTML, скриншоты экрана и список загруженных ресурсов.
В настоящее время Googlebot использует последнее стабильное ядро Chrome, но устанавливает порог около 5 секунд для выполнения скриптов на одной странице.
В сочетании с “Проверкой расширенных результатов” можно сравнить разницу в байтах между исходным ответом и финальным результатом рендеринга, а также выявить ошибки загрузки скриптов 403 или 404, вызванные блокировкой в Robots.txt.
Google Search Console
В боковой панели навигации Google Search Console после ввода конкретного URL система извлечет снимок данных последнего сканирования из базы данных индекса Google.
Если статус страницы указывает “URL есть в индексе Google”, вы можете увидеть, были ли ошибки парсинга HTML или проблемы с мобильной оптимизацией во время сканирования.
Для глубокого анализа отсутствия контента, вызванного рендерингом JavaScript, необходимо нажать кнопку “Проверить URL на опубликованной странице”.
Это действие заставит WRS (Web Rendering Service) запустить безголовый браузер на базе последней стабильной версии Chromium для доступа к целевой странице в реальном времени.
При выполнении рендеринга WRS устанавливает ширину области просмотра 1280 пикселей и использует стратегию сканирования Mobile-First.
На панели “Просмотр отрендеренной страницы” вкладка HTML отображает полную структуру DOM после завершения работы всех скриптов.
Техническим специалистам следует провести количественное сравнение количества строк кода или объема байтов HTML, отображаемого здесь, с “Исходным кодом страницы” (исходный ответ сервера), доступным через контекстное меню браузера.
Если исходный HTML занимает всего 2 КБ, а отрендеренный HTML увеличивается до 50 КБ, это означает, что страница сильно зависит от клиентского рендеринга (CSR).
Если в отрендеренном HTML отсутствуют основные текстовые блоки или теги списков товаров, рендеринг считается неудачным.
Googlebot выделяет ограниченные вычислительные ресурсы для выполнения скриптов на одной странице. Хотя официального лимита времени нет, многочисленные эксперименты показывают, что если загрузка контента занимает более 5 секунд, вероятность того, что эти данные будут пропущены на этапе индексации, значительно возрастает.
“Googlebot не ждет бесконечно долго завершения всех асинхронных задач JavaScript. Его бюджет на рендеринг ограничен скоростью загрузки страницы, задержкой ответа сервера (TTFB) и сложностью парсинга скриптов. Если время ответа API превышает 2000 мс, это часто приводит к тому, что в момент создания снимка рендеринга контент все еще находится в состоянии загрузки (Loading).”
В списке “Ресурсы страницы” на вкладке “Дополнительная информация” перечислены все файлы JS и CSS, которые не удалось загрузить.
Коды состояния 403 или 404 явно указывают на ошибки конфигурации прав сервера или неверные пути к ресурсам, но наибольшее внимание стоит уделить статусу “Заблокировано в robots.txt”.
Поскольку многие одностраничные приложения (SPA) инкапсулируют логику маршрутизации и рендеринга данных в специфических файлах скриптов, наличие правил вроде Disallow: /assets/ в файле /robots.txt помешает Googlebot получить доступ к основным скриптам, и WRS не сможет построить полное дерево DOM.
Результатом станет то, что даже если пользователи видят страницу целиком, для поисковой системы она может выглядеть пустой или содержать только базовый каркас.
При поиске ошибок в скриптах следует сосредоточиться на области “Сообщения консоли JavaScript”.
Здесь фиксируются исключения, возникающие при выполнении кода в WRS.
Если команда разработчиков использовала новые функции ES6+ без полифиллов (например, BigInt, ResizeObserver и т. д.), а версия Chromium, используемая при сканировании, еще не полностью совместима с некоторыми нестандартными API, в консоли появится ошибка Uncaught ReferenceError или SyntaxError.
Такие ошибки прерывают весь процесс парсинга скриптов, делая недействительной всю последующую логику вставки контента.
Наблюдая за конкретными номерами строк и именами файлов в журнале ошибок, можно точно определить, какой библиотечный файл или блок бизнес-логики препятствует сканированию.
Отрендеренный “Скриншот” — еще один метод количественной проверки.
Например, некоторые скрипты динамически вычисляют высоту или прозрачность элементов. Если на скриншоте видны большие пустые области, даже при наличии текста в тегах HTML, алгоритм Google может счесть страницу неудобной для пользователя, что снизит приоритет индексации.
При работе с высокодинамичными сайтами необходимо обеспечить завершение рендеринга всего контента на первом экране (Above the Fold) в течение 2 секунд.
Проверка расширенных результатов
Инструмент проверки расширенных результатов — это общедоступная среда тестирования от Google. В отличие от Search Console, которая требует подтверждения прав собственности на сайт, этот инструмент позволяет любому пользователю анализировать любой URL или вставленный фрагмент кода.
После ввода URL и запуска теста система активирует безголовый браузер на базе последней стабильной версии Chromium, имитируя поведение Googlebot Smartphone или Googlebot Desktop.
Для SPA-приложений, построенных на JavaScript-фреймворках, таких как React, Angular или Vue.js, функция “Просмотреть протестированную страницу” является стандартом для определения того, успешно ли контент попал в дерево DOM.
Так как Googlebot имеет лимит ресурсов на обработку скриптов, если странице на этапе инициализации требуется выполнить большой объем интенсивных вычислений или отправить более 20 асинхронных запросов API, WRS может завершить захват HTML до окончания выполнения всех скриптов.
При проведении проверки в реальном времени система создает снимок отрендеренного HTML.
С помощью этого снимка технические специалисты могут точно сравнить разницу в байтах между исходным ответом сервера и финальным результатом рендеринга.
Например, страница с чисто клиентским рендерингом (CSR) часто имеет исходный HTML менее 5 КБ, состоящий из базового шаблона. Если после рендеринга объем HTML достигает более 100 КБ, это означает, что Googlebot успешно выполнил скрипты и подтянул динамический контент.
Напротив, если объем отрендеренного HTML остается на уровне 5 КБ и не содержит тегов основного контента, это свидетельствует о прерывании выполнения скриптов на уровне WRS.
Движок рендеринга Google устанавливает строгие тайм-ауты для загрузки отдельных ресурсов; обычно время загрузки одного JS-файла не должно превышать 2000 мс.
Если сторонние библиотеки или API отвечают слишком медленно, во вкладке “Ресурсы страницы” будут отмечены соответствующие ошибки загрузки.
- Режим тестирования фрагмента кода: Поддерживает вставку неопубликованного HTML-кода, что критически важно для проверки соответствия логики JS-рендеринга стандартам сканирования на этапе Staging. Таким образом можно проверить, корректно ли распознается динамически созданная разметка Schema до слияния кода с основной веткой.
- Переключение имитации User-Agent: Хотя по умолчанию используется мобильное сканирование, при работе с сайтами со сложной адаптивной логикой переключение на имитацию десктопного устройства помогает выявить влияние приоритетов загрузки CSS на порядок выполнения JS.
- Сравнение снимков рендеринга: Предоставляемые скриншоты — это не только визуальная справка, но и основа для выявления “смещения контента” или “дрожания макета” (layout shift), так как резкие изменения макета могут привести к неверной оценке удобства страницы со стороны Googlebot.
“Тест расширенных результатов — это не только проверка структурированных данных, но и лаборатория для тестирования видимости динамического контента. Если текст на странице загружается асинхронно через JS, поиск этого текста в разделе ‘Просмотреть протестированную страницу’ — самый быстрый способ проверить вероятность успешной SEO-индексации.”
Когда страница содержит JSON-LD или Microdata, внедренные через скрипт, инструмент извлекает эту структурированную информацию из отрендеренного DOM.
Если в коде есть синтаксические ошибки или если ошибка JS привела к остановке скрипта до внедрения разметки Schema, инструмент выдаст сообщение “Расширенные результаты не обнаружены”.
Это особенно важно для сайтов электронной коммерции или отзывов, так как Google должен распознавать такие атрибуты, как цена, статус наличия и рейтинг, одновременно со сканированием.
Если эти атрибуты отсутствуют в HTML “Протестированной страницы”, то даже при корректном отображении на фронтенде, в результатах поиска (SERP) не будут отображаться звезды рейтинга или превью цен.
Следует обратить особое внимание на ошибки в консоли, так как среда WRS имеет более строгие ограничения по использованию памяти, чем браузер обычного пользователя.
Если скрипт потребляет слишком много ресурсов CPU, Googlebot может отказаться от рендеринга страницы, сохранив в индексе лишь пустой шаблон-оболочку.
- Общее количество загружаемых ресурсов: Рекомендуется ограничить количество JS-ресурсов для одной страницы до 50. Слишком большое количество параллельных запросов вызывает задержки в планировании WRS, повышая риск сбоя рендеринга.
- Мониторинг ошибок выполнения скриптов: Инструмент фиксирует критические исключения, такие как
ReferenceErrorилиTypeError, которые разрывают цепочку рендеринга. Если вы видите ошибки несовместимости спецификаций ES из-за отсутствия полифиллов, следует немедленно скорректировать цель компиляции в инструментах сборки. - Валидность ответов API: Проверьте все эндпоинты API для динамического контента через список ресурсов. Если статус отображается как “Заблокировано” или “Тайм-аут”, это означает, что Googlebot блокируется брандмауэром или производительность API не соответствует порогу сканирования.
Каждое “Предупреждение” или “Ошибка” в отчете этого инструмента соответствует поведению Googlebot в реальной среде индексации.
Если инструмент сообщает, что “не удалось загрузить некоторые скрипты”, даже если они нормально работают в Chrome у обычного пользователя, этому стоит уделить внимание. Возможно, сервер ограничивает скорость доступа (Rate Limiting) для IP-диапазонов поисковых роботов Google.
Chrome DevTools
В локальной среде разработки панель “Сетевые условия” (Network conditions) в Chrome DevTools является отправной точкой для имитации поведения Googlebot.
Нажмите F12 или выберите “Просмотреть код”, чтобы открыть панель инструментов, затем через меню “три точки” в правом верхнем углу перейдите в More tools -> Network conditions.
Снимите флажок “Использовать настройки браузера по умолчанию” (Use browser default) и вручную выберите Googlebot из выпадающего списка.
Это действие изменит строку User-Agent, отправляемую браузером, например, на Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html).
Этот шаг нужен для проверки того, нет ли на сервере специфической логики для поисковых роботов.
Если сервер настроен на возврат разного HTML-кода в зависимости от UA, локальная среда сразу покажет результат, отличный от того, что видит обычный пользователь.
Техническим специалистам следует сравнить заголовки ответа, проверяя, не изменились ли Content-Type или директивы Cache-Control.
Если сервер возвращает ошибку 403 или неожиданный редирект 301 для Googlebot, значит, путь поисковой системе заблокирован на уровне сервера.
Для имитации “первой волны индексации” (First-wave indexing) Googlebot необходимо протестировать поведение страницы при отключенном JavaScript.
Зайдите в настройки DevTools (Settings), в разделе предпочтений найдите пункт “Отладчик” (Debugger) и установите флажок “Отключить JavaScript” (Disable JavaScript).
После обновления страницы браузер отобразит только исходную структуру HTML, выданную сервером.
Для сайтов на базе SPA это часто приводит к появлению абсолютно пустой страницы или только анимации загрузки.
Если основная текстовая информация, навигационное меню или списки товаров исчезают после отключения скриптов, это означает, что поисковая система должна пройти сложную “вторую волну индексации” (этап рендеринга WRS) для получения контента.
В этот момент следует зафиксировать объем байтов исходного HTML (например, 15 КБ базового каркаса) и сравнить его с полностью отрендеренным DOM, чтобы определить объем контента, внедряемого через JS.
“В локальной среде имитации отключение JavaScript — это самый жесткий стресс-тест. Если в исходном HTML страницы отсутствуют теги H1 или абзацы текста с основной семантикой, риск того, что страница будет проиндексирована как пустая при колебаниях сети или нехватке квот на рендеринг у Google, крайне высок.”
Googlebot работает не в высокопроизводительной десктопной среде. Используя панель “Производительность” (Performance) в DevTools, можно более реалистично имитировать вычислительные мощности Googlebot.
В настройках производительности установите “Ограничение CPU” (CPU Throttling) на уровне 4-кратного или 6-кратного замедления.
Если задача рендеринга, которая на мощном MacBook занимает всего 800 мс, при 6-кратном замедлении вырастает до 5500 мс, вы уже достигли типичного порога рендеринга Googlebot в 5 секунд.
Изучая “Длинные задачи” (Long Tasks) на Flame Chart, можно определить, какие тяжелые JS-библиотеки блокируют основной поток, вызывая задержку рендеринга.
Если количественный показатель, такой как общее время блокировки (TBT), в этой среде превышает 2000 мс, это обычно предвещает, что Googlebot может прекратить ожидание и захватить неполный снимок DOM до полной генерации контента.
Ручная проверка в браузере
Ручная проверка подтверждает статус рендеринга путем сравнения различий в данных между Initial HTML и Rendered DOM.
Googlebot использует новейший движок рендеринга Chrome, но если выполнение JS превышает порог в 5 секунд или количество запросов ресурсов на одной странице превышает 50, контент может быть не проиндексирован.
При ручном тестировании следует обращать внимание на цепочку загрузки ресурсов, следя за тем, чтобы атрибут href тегов <a> присутствовал в исходном коде HTML, а не создавался динамически через событие onclick, чтобы гарантировать доступность путей для краулера.
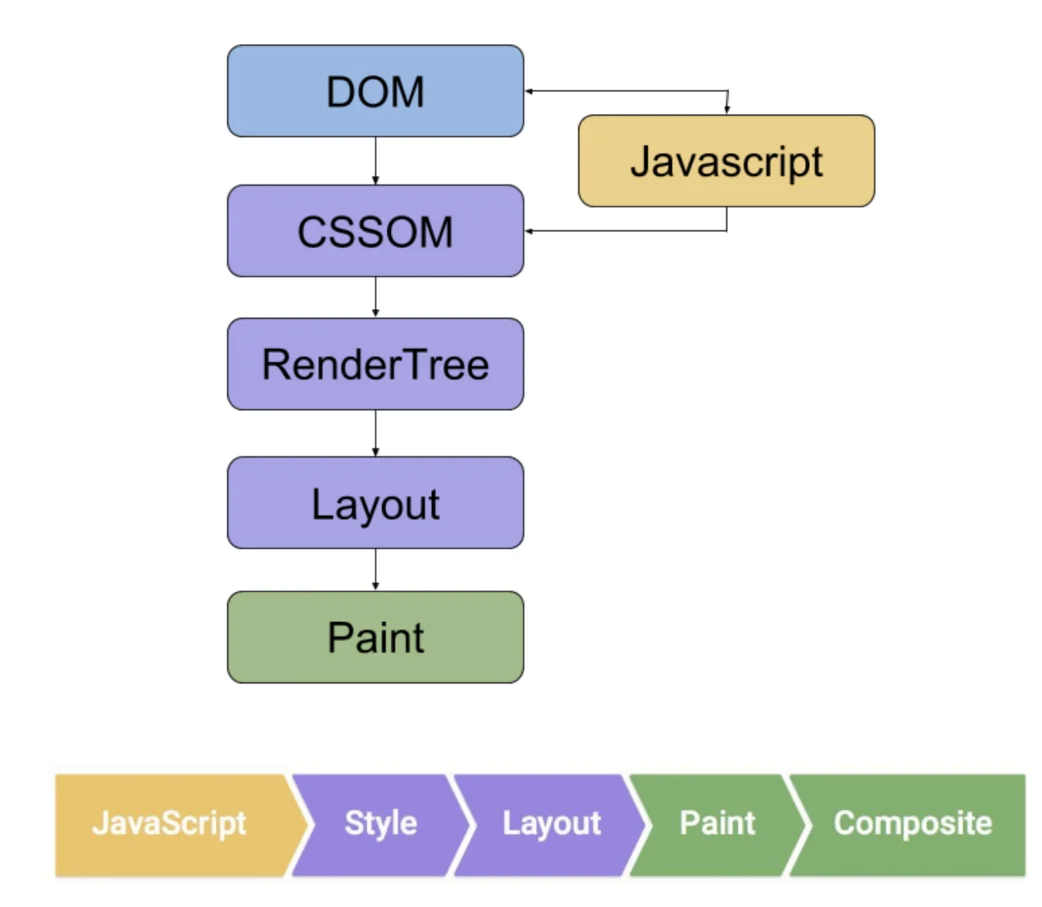
Исходный код и живой DOM
Код, просматриваемый в браузере через view-source, отражает исходный поток текста, отправленный сервером, в то время как панель Elements в инструментах разработчика показывает объектную модель документа (DOM) в памяти после обработки движком рендеринга, выполнения скриптов и исправления ошибок.
Для сайтов с архитектурой SPA исходный код часто содержит только пустой контейнер с id="app" или id="root" и несколько ссылок на скрипты общим объемом более 500 КБ.
Сравните количество чисто текстовых символов в исходном коде с количеством текстовых символов в отрендеренном DOM. Когда это соотношение превышает 1:20 (например, в исходном HTML всего 100 слов, а после рендеринга их 2000), первая волна сканирования поисковой системы практически не сможет получить полезную семантическую информацию.
Такая разница приводит к тому, что страница на начальном этапе индексации находится в состоянии “контентного вакуума”, ожидая вторичной обработки в очереди рендеринга.
| Аспект сравнения | Признаки данных Initial HTML | Признаки данных Rendered DOM | Влияние на индексацию |
|---|---|---|---|
| Общее число узлов DOM | Обычно менее 50 узлов, структура крайне плоская. | Может превышать 1500 узлов, глубина иерархии возрастает. | Резкий рост числа узлов говорит о полной зависимости контента от JS. |
| Статус Meta-тегов | Содержит общие заголовки или жестко заданные заглушки. | Содержит специфические SEO-теги, внедренные скриптом. | Краулер может зафиксировать неверные метаданные до выполнения скриптов. |
| Тег Canonical | Отсутствует или указывает на главную страницу сайта. | Динамически обновляется на абсолютный путь текущей страницы. | Несоответствие тегов вызывает конфликты при разборе атрибутов страницы. |
| JSON-LD данные | Фрагмент кода пуст или содержит базовый каркас. | Заполнен полными данными о ценах, отзывах или остатках. | Определяет, будут ли в результатах поиска (SERP) расширенные сниппеты. |
| Внутренние ссылки | Навигация может быть пустой, ссылки еще не созданы. | Содержит полные теги <a> и динамические пути. |
Влияет на эффективность обнаружения краулером глубоких URL сайта. |
При проведении глубокого сравнения ввод document.body.innerText.length в консоли позволит получить общее количество символов после рендеринга для сопоставления с размером файла исходного кода.
Если размер исходного кода составляет 30 КБ, а отрендеренный innerText достигает 15 000 символов, значит, основной текстовый вес сосредоточен в слое рендеринга.
В этом случае, если в скрипте есть рекурсивная функция, выполнение которой занимает более 200 мс, или используется внешний API с временем загрузки более 2.0 с, движок рендеринга Googlebot может прекратить запись до полного внедрения контента из-за стратегии распределения ресурсов.
| Количественный показатель | Порог риска | Последствия для сканирования и индексации |
|---|---|---|
| Text Ratio Gap (Разрыв текста) | > 80% текста генерируется через JS | Страница может быть признана “малоценной” в среде без JS. |
| Успех извлечения ссылок | < 5 валидных тегов <a> в исходнике |
Краулинговый бюджет (Crawl Budget) будет потрачен на бесконечное ожидание. |
| Потребление памяти скриптами | Расход памяти стека более 50 МБ | Сервер рендеринга может принудительно завершить задачу из-за лимита памяти. |
| Полнота HTML первого экрана | < 10% контента видно в исходном коде | Пользователи на медленном интернете увидят долгий белый экран, что ухудшит ранжирование. |
Проверьте навигационное меню в панели Elements: если ссылка выглядит как <a href="javascript:void(0)" onclick="navigateTo('/page')">, в отрендеренном DOM она кажется ссылкой, но для поискового робота это тупик, который невозможно отследить.
Стандартный атрибут href должен либо уже существовать в исходном HTML от сервера, либо генерироваться после выполнения скрипта в формате <a href="/target-path">.
Сайты с полной структурой ссылок в исходном HTML индексируются на 40–70% быстрее, чем сайты, полностью полагающиеся на внедрение ссылок через JS.
Если в исходном коде присутствует мета-тег noindex, а логика скрипта пытается удалить его после рендеринга и заменить на index, такая практика обычно неэффективна.
Поисковые системы обычно отдают приоритет директивам, найденным в начальном HTML, что может помешать нормальному процессу индексации страницы.
Проверка симуляции среды
В браузере Chrome откройте DevTools, нажмите Ctrl+Shift+P, введите Disable JavaScript и нажмите Enter — это отправная точка для имитации первого обращения поисковой системы.
Перезагрузите страницу с отключенными скриптами. Если экран стал пустым, это означает, что Initial HTML от сервера не содержит никакого существенного текстового контента.
Для HTML-файла объемом 100 КБ, где 90% текста зависит от последующей загрузки JS-пакета объемом 2 МБ, риск того, что поисковая система зафиксирует пустой тег-контейнер при сетевых задержках, крайне велик.
| Параметр симуляции | Стандарт настройки | Наблюдаемые показатели |
|---|---|---|
| Network Throttling | Fast 3G (1.5 Mbps, 40ms задержка) | Если рендеринг основного контента занимает более 5000 мс, Google может прекратить ожидание. |
| CPU Throttling | 4x slowdown (имитация мобильного CPU) | Если Script Evaluation занимает более 1.5 с, основной поток будет заблокирован, задерживая рендеринг. |
| User-Agent | Googlebot Smartphone | Проверьте, не возвращает ли сервер ошибку 403 или специфический код для мобильных устройств. |
| Viewport | 411 x 731 пикселей (стандарт мобильных) | Убедитесь, что контент загружается автоматически без кликов или скроллинга. |
Измените строку User-Agent браузера на актуальную строку Googlebot (например, Chrome 120 Mobile Safari).
В панели Network установите флажок Disable cache и пронаблюдайте цепочку загрузки ресурсов от лица Googlebot.
В стандартном процессе Googlebot обычно не загружает все медиафайлы, отдавая приоритет тексту и структурированным данным.
Если страница определяет User-Agent через скрипт и применяет иную логику (например, отключает асинхронные интерфейсы для роботов), структура DOM в панели Elements будет отличаться от того, что видит обычный пользователь.
В панели Performance запишите процесс загрузки, обращая внимание на активность потока Main.
Если суммарное время Evaluate Script занимает более 70% цикла загрузки, в реальной среде сканирования движок рендеринга может сделать снимок до полной отрисовки контента.
Если интервал между First Contentful Paint (FCP) и Largest Contentful Paint (LCP) увеличивается до 3+ секунд из-за JS, вероятность захвата неполной страницы возрастает примерно на 40%.
Используйте вкладку Sensors для имитации различных географических положений. Узлы сканирования Googlebot в основном находятся в США. Если JS-логика сайта выполняет редиректы по IP, это может привести к несоответствию версии страницы для целевой аудитории.
В панели Console проверяйте сообщения об ошибках, особенно ReferenceError или TypeError.
Хотя Googlebot (Evergreen) обновляется, поддержка самых новых Web API (например, WebGPU) может отличаться. Без надлежащих полифиллов скрипт может упасть на середине выполнения.
- Лимит количества запросов: Рекомендуется держать количество JS/CSS ресурсов до 50 на страницу.
- Статус Shadow DOM: Убедитесь, что Shadow DOM находится в режиме Open, так как содержимое в режиме Closed невидимо для краулеров.
- Валидация формата ссылок: Убедитесь, что все ссылки имеют атрибут
href. Переходы черезwindow.location.hrefбез стандартных якорей мешают поисковику находить подстраницы. - Lazy Load изображений: Используйте стандартный атрибут
loading="lazy", так как сложные JS-слушатели событийscrollработают нестабильно при сканировании.
Если разница в охвате текста между исходником и DOM превышает 80%, SEO сайта критически зависит от эффективности рендеринга.
Если Total Blocking Time (TBT) превышает 300 мс, это предвещает проблемы с разбором DOM краулером.
Используйте панель Coverage для проверки использования JS: если 80% кода скрипта объемом 500 КБ не выполняется при первой загрузке, этот балласт бесполезно расходует вычислительные мощности сервера рендеринга.
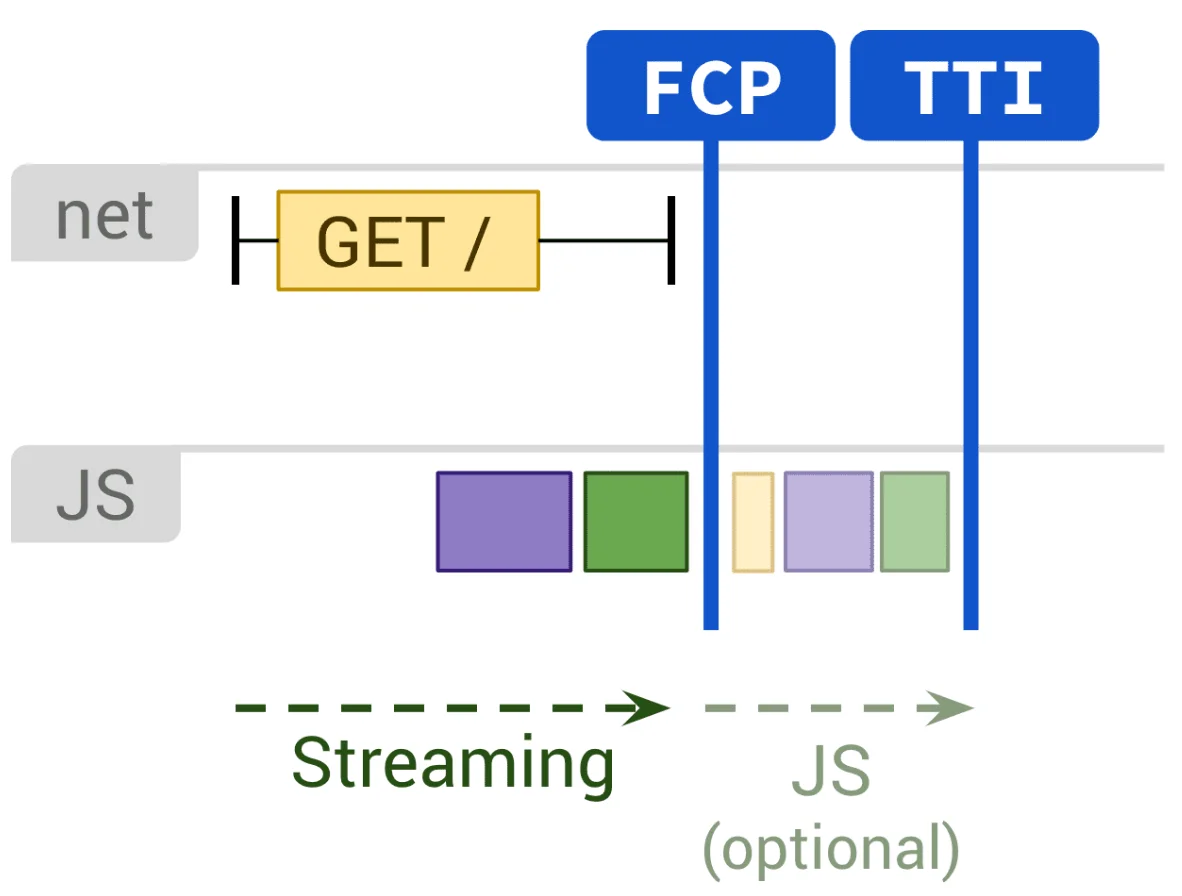
Профессиональные инструменты сканирования
Профессиональные краулеры способны имитировать среду Chrome (например, Screaming Frog v20+).
Данные показывают, что затраты на сканирование с выполнением скриптов в 20 раз выше, чем для статического HTML.
Когда разница в количестве слов “до” и “после” рендеринга превышает 10% или разница в обнаруженных внутренних ссылках более 5%, успех индексации обычно снижается.
При проверке нужно обращать внимание на коэффициент завершения рендеринга в течение 5 секунд и на ошибки загрузки скриптов из-за статус-кодов 403.
Screaming Frog SEO Spider
При использовании Screaming Frog переключение режима рендеринга с “Text Only” на “JavaScript” превращает поведение краулера из простых HTTP-запросов в полноценную симуляцию браузера.
Программа запускает экземпляры Headless Chrome для парсинга каждого файла скрипта.
В конфигурации необходимо выбрать опцию JavaScript в меню Configuration > Spider > Rendering.
Потребность в оперативной памяти (RAM) при выполнении JavaScript возрастает в 5–10 раз. Для сканирования 100 000 страниц на тяжелых фреймворках рекомендуется выделить программе не менее 16–32 ГБ RAM.
| Категория показателя | Исходный HTML (Source) | Отрендеренный HTML (Rendered) | Рекомендуемый порог разницы |
|---|---|---|---|
| Количество слов (Word Count) | Только каркас и метаданные | Включает асинхронный текст | Разница > 15% требует проверки |
| Внутренние ссылки | 0 или минимум заглушек | Динамическая навигация и товары | Разница > 0 указывает на риски |
| Тег Canonical | Может отсутствовать | Финальная версия после JS | Приоритет у отрендеренной версии |
| Размер страницы | Обычно < 50 КБ | Может вырасти до 500 КБ – 2 МБ | Слишком большой размер ведет к обрезке |
Тайм-аут AJAX Timeout по умолчанию обычно составляет 5 секунд, что совпадает со стратегией Googlebot.
Если интерфейсы данных отвечают медленно, Screaming Frog получит “пустую оболочку” страницы. Это можно увидеть, сравнив колонку Word Count.
Для крупных сайтов функция “JavaScript Rendering Table” в меню “Bulk Export” позволяет выгрузить отчет о различиях рендеринга для всего сайта, включая изменения тегов Title, Meta Description и H1.
Вкладка “Resource” фиксирует HTTP-статусы каждого скрипта. Если скрипт возвращает 403 Forbidden, это часто означает, что брандмауэр (WAF) сервера ошибочно принял Headless Chrome за вредоносную атаку.
| Статус ресурса рендеринга | Причина | Влияние на сканирование |
|---|---|---|
| Blocked by robots.txt | Путь к скрипту закрыт Disallow | Googlebot не читает JS, рендеринг падает |
| Status Code: 429 | Слишком высокая частота запросов | Ресурсы загружены не полностью |
| Status Code: 404 | Путь к файлу скрипта недействителен | Динамические компоненты не отображаются |
| Timeout (Exceeded 5s) | Медленный API или сложная логика | HTML пуст или содержит ошибку |
Режим “Rendered Page” позволяет визуально сравнить снимки до и после, выявляя контент, скрытый за вкладками (Tabs), который отображается только после клика.
Screaming Frog также ловит Console Errors. При обнаружении критических синтаксических ошибок программа выделит их в отчете.
Lumar (DeepCrawl)
Lumar использует распределенные облачные мощности для автоматического сканирования сайтов с миллионами URL.
В то время как локальные инструменты ограничены физической памятью (например, 32 ГБ потянут 20–50 параллельных потоков рендеринга), Lumar может масштабироваться до 500+ потоков в облаке, завершая полный рендеринг 1 миллиона страниц за 24 часа.
Если выполнение скрипта превышает 5000 мс, система пометит URL как “высокозатратную страницу”, что в реальности Googlebot часто приводит к пустому индексу.
В проектах на React или Vue рост объема DOM может составлять от 100 раз и более (с 5 КБ до 800 КБ), что указывает на критическую зависимость от скриптов.
Показатель DOM Node Count от Lumar помогает выявить страницы, где количество узлов превышает рекомендованные Google 1500 единиц, что снижает эффективность рендеринга.
Отчеты включают процент скриптов со статусами 4xx и 5xx. Если 20% скриптов заблокированы (Robots.txt или WAF), результат рендеринга будет неполным.
Lumar создает “карту различий рендеринга”, показывая, как меняется количество внутренних ссылок. Если без JS количество ссылок падает с 200 до 0, структура сайта полностью зависит от динамики, что замедляет обнаружение новых страниц Googlebot.
Показатель Rendered Page Word Count в сравнении с Source HTML позволяет выявить “разрыв рендеринга” (Rendering Gap). При разрыве более 80% задержка индексации обычно увеличивается на 3–7 дней.


