




















Да, параметры URL (такие как сортировка ?sort, фильтрация ?color или идентификаторы отслеживания) являются основной причиной повторного индексирования Google.
Для того чтобы поисковый трафик точно направлялся на целевую страницу, рекомендуется предпринять следующие действия:
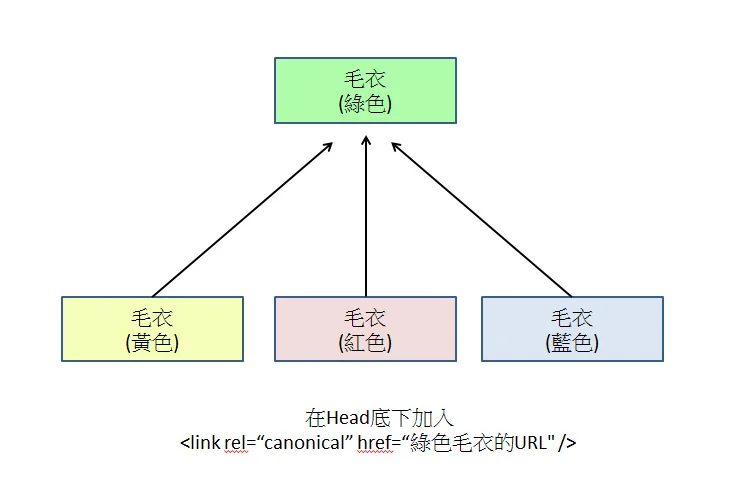
Настройка канонических тегов
Добавьте rel="canonical" в HTML-код всех страниц-вариантов, указывая на единственный основной URL.
Управление путями сканирования
Используйте Robots.txt для блокировки ненужных маркетинговых параметров отслеживания (например, utm_*).
Агрегация сигналов ранжирования
Это поможет Google сосредоточить «очки доверия» всех страниц с параметрами на основной странице, предотвращая падение трафика из-за внутренней конкуренции.
Избыточность контента
Параметры URL приводят к созданию большого количества дублирующих адресов для одной и той же страницы.
Например, страница электронной коммерции с 5 фильтрами по цвету и 3 способами сортировки породит более 15 различных URL.
На крупных сайтах около 40% лимита на сканирование часто расходуется на эти варианты с параметрами.
Когда Google индексирует 200 идентичных главных страниц с суффиксами UTM-отслеживания, поисковый вес основной страницы распределяется, что приводит к снижению позиций в рейтинге примерно на 25%.
Размытие ссылочной массы
В механизме индексации Google URL-адреса с разными суффиксами рассматриваются как независимые сущности.
Например, если страница технической документации получила обратные ссылки с 50 различных доменов, но 20 из них указывают на версию с ?utm_medium=email, а еще 10 — на версию с ?ref=footer, то основной URL фактически получит только 40% общего веса.
Согласно выборочному анализу данных Ahrefs, это явление размытия веса приводит к тому, что при конкуренции за сложные ключевые слова фактическая позиция страницы оказывается на 3–5 пунктов ниже ожидаемой.
Роботы при идентификации таких разрозненных путей не будут автоматически суммировать силу всех ссылок для исходной страницы, если в исходном коде сайта явно не настроена логика обработки.
В вычислительной модели PageRank передача ссылочного веса следует математической закономерности, основанной на коэффициенте затухания 0,85.
Каждая ссылка, ведущая на сайт, накапливает вес для конкретного URL.
Когда этот вес распределяется по динамически генерируемым суффиксам, таким как ?sessionid или ?click_id, «показатель доверия» основной страницы не может достичь порога, необходимого для вывода страницы в топ.
В конкурентной борьбе в индустрии SaaS на рынке США страницы из первой тройки обычно имеют очень «чистые» ссылочные профили.
Если вес страницы распределяется между более чем 5 версиями с параметрами, Google может попеременно показывать эти страницы в результатах поиска, и это состояние внутренней конкуренции не позволит показателям основной страницы стабилизироваться.
Многие платформы электронной коммерции, использующие архитектуру Magento или Salesforce Commerce Cloud, генерируют внутренние ссылки с большим количеством параметров в навигационных цепочках (breadcrumbs) или боковых фильтрах.
Если внутренняя навигация часто ссылается на category?sort=newest вместо статического адреса категории, поток веса внутри сайта будет смещаться.
Когда поисковый робот в процессе сканирования обнаруживает несколько входов для одной цели с разной структурой URL, приоритет планирования для этой страницы снижается.
Платформы социальных сетей и сторонние рекламные системы часто принудительно добавляют собственные параметры при переходе, такие как ?fbclid или ?gclid.
Если на странице отсутствуют эффективные теги rel=”canonical”, алгоритм Google может после нескольких недель цикла сканирования ошибочно выбрать страницу с рекламными параметрами в качестве представителя этого контента в поиске.
Это может привести к снижению CTR примерно на 15%, так как пользователи в результатах поиска гораздо реже кликают на длинные URL-адреса с непонятными символами, чем на лаконичные статические адреса.
Как только внешние ссылки накапливаются на этих временных версиях с параметрами, попытка полностью вернуть эту силу на основную страницу с помощью последующих технических средств часто требует длительного процесса переиндексации (до нескольких месяцев).
Эффект умножения путей
В современных архитектурах электронной коммерции (таких как Shopify или Magento), когда базовая страница категории обладает несколькими атрибутами фильтрации, каждое новое измерение параметров комбинируется с существующими параметрами.
Возьмем в качестве примера стандартную страницу категории кроссовок: если она предлагает 10 вариантов цвета, 12 размеров, 5 брендов и 4 диапазона цен для сортировки, то количество теоретически создаваемых независимых путей URL достигнет 10 × 12 × 5 × 4 = 2400.
Если программная логика допускает изменение порядка параметров (например, путь при выборе сначала цвета, а потом размера отличается от пути при выборе сначала размера, а потом цвета), это число возрастет еще больше.
В условиях этого эффекта умножения путей страница, которая изначально имела только одну единицу реального контента, превращается в глазах робота Google в тысячи различных точек входа.
Такие избыточные пути при отсутствии эффективного управления занимают более 65% квоты на сканирование средних и крупных сайтов, из-за чего страницы с описанием товаров, которые действительно нуждаются в обновлении, не получают достаточной частоты сканирования.
| Этап комбинации параметров | Масштаб факторов переменных | Количество уникальных сгенерированных URL | Оценка использования ресурсов сканирования |
|---|---|---|---|
| Исходная страница категории | 1 | 1 | 0.01% |
| Фильтрация по атрибутам (цвет + бренд) | 10 x 8 | 80 | 2.5% |
| Наложение спецификаций (цвет + бренд + размер) | 80 x 12 | 960 | 18.0% |
| Полное наложение функций (атрибуты + спецификации + сортировка + пагинация) | 960 x 3 x 10 | 28,800 | Более 70% |
Когда Googlebot сталкивается с таким «бесконечным пространством», созданным нагромождением параметров, и пространство URL-адресов сайта чрезмерно раздувается, доля эффективного сканирования, которое робот может выполнить за единицу времени, резко падает.
Анализ логов одного транснационального ритейлера показал, что робот за 24 часа просканировал 15 000 URL, но только 1 200 из них были статическими страницами с потенциалом ранжирования, остальные 92% действий по сканированию были потрачены на варианты параметров, состоящие из комбинаций ?color=, ?size= и ?sort=.
В процессе попытки алгоритма выбрать одну «каноническую версию» из 200 похожих путей, при отсутствии четких технических сигналов, часто выбирается URL, не являющийся стандартной страницей, ожидаемой разработчиком, что приводит к отображению адресов с непонятными параметрами в результатах поиска.
Каждый раз, когда Googlebot запрашивает URL со сложной комбинацией параметров, серверной базе данных обычно требуется выполнить запросы с объединением нескольких таблиц для генерации соответствующего вида.
Под давлением высокочастотного сканирования слишком большое количество запросов к комбинациям параметров может привести к увеличению TTFB (времени отклика до первого байта) на 300–800 миллисекунд.
Увеличение задержки ответа активирует защитные механизмы Googlebot, что в свою очередь снижает частоту сканирования всего домена.
Согласно отчету об исследовании 500 глобальных сайтов электронной коммерции, страницы с глубиной параметров URL более 3 уровней имеют на 42% меньшую вероятность успешной индексации Google по сравнению с плоскими URL.
Неупорядоченное расположение параметров ведет к глубокому распаду ссылочных сигналов: когда на страницу с конкретным рекламным параметром ?promo=winter ссылается внешний сайт, а внутренняя навигация указывает на версию ?sort=new, сигналы веса этих двух страниц в базе данных Google полностью изолированы друг от друга.
На сайтах, где не внедрена стратегия нормализации URL, в среднем каждая популярная страница товара имеет 14 различных вариантов параметров, что приводит к размытию CTR этого товара в результатах поиска по различным подпутям.
При обработке такой масштабной избыточности путей простая блокировка через robots.txt часто не может решить уже существующие проблемы индексации.
Официальные рекомендации Google Search Central склоняются к использованию тега rel=”canonical” для принудительного объединения этих путей, возникших в результате эффекта умножения.
После правильного развертывания канонических тегов поисковая видимость соответствующих страниц категорий в среднем увеличилась на 22% в течение 60 дней.
Растрата краулингового бюджета
У Googlebot есть лимит на количество запросов на сканирование сайта за единицу времени.
Когда система генерирует десятки тысяч URL с параметрами (например, ?variant=123 или ?sort=desc), робот в первую очередь тратит ресурсы на эти низкокачественные пути.
Согласно механизму сканирования Google, если количество дублирующихся URL более чем в 10 раз превышает объем реального контента, частота сканирования важных страниц снижается более чем на 50%.
Это приводит к тому, что новые опубликованные страницы могут не обнаруживаться в течение 72 часов, а частота сканирования оригинальных URL без параметров будет значительно сокращена.
Влияние параметров
Система планирования сканирования поисковых систем классифицирует параметры на «активные» и «пассивные» в зависимости от того, насколько они фактически изменяют содержание страницы.
Идентификаторы сессий (Session IDs) занимают лидирующее место по разрушительному воздействию на ресурсы сканирования среди всех типов параметров.
Такие параметры, как ?sid=9928374 или ?sessionid=abc123, обычно генерируются динамически на бэкенде для отслеживания пользователей в протоколе HTTP без сохранения состояния.
Поскольку каждый посетитель и даже каждый визит робота может получить совершенно новый ID, это создает теоретически бесконечное количество URL для одного и того же HTML-документа.
Анализ серверных логов показывает, что если не настроить правила фильтрации, Googlebot может попытаться просканировать одну и ту же статью сотни раз за 24 часа, каждый раз используя разные строки сессии.
Это поведение приводит к накоплению огромного количества недействительных запросов в очереди сканирования, вытесняя квоту, которая должна была быть выделена для свежеопубликованных страниц (Fresh Content).
«При мониторинге логов крупных сайтов электронной коммерции дублирующиеся запросы на сканирование, вызванные ID сессий, часто составляют от 30% до 50% от общего объема сканирования. Это вынуждает Googlebot часто активировать ограничение “crawl delay” для защиты производительности сервера».
Когда пользователь выбирает цвет, размер, материал и другие опции, к URL добавляются суффиксы типа ?color=blue&size=xl&material=cotton.
Хотя такие параметры изменяют отображаемую часть контента, они часто не создают совершенно новых метаданных.
С технической точки зрения эти параметры следуют логике декартова произведения (Cartesian Product).
| Тип параметра | Пример типичной структуры | Влияние на видимость для Googlebot | Степень растраты ресурсов сканирования |
|---|---|---|---|
| Отслеживание сессии | ?sid=xyz_987 |
Создает почти бесконечные пути дублирующихся URL | Экстремально высокая (9/10) |
| Множественная фильтрация | ?size=m&color=red |
Пути растут в геометрической прогрессии, легко приводит к зацикливанию | Высокая (8/10) |
| Логика сортировки | ?sort=price_desc |
Изменяется порядок контента, нет существенно новой информации | Средняя (5/10) |
| Рекламное отслеживание | ?click_id=ad_01 |
Указывает на контент, на 100% идентичный исходной странице | Средне-высокая (7/10) |
| Язык/Регион | ?lang=en-us |
Указывает на валидные страницы с разным переведенным контентом | Низкая (2/10) |
Параметры сортировки (Sorting Parameters), такие как ?sort=highest_price или ?order=newest, в глазах Googlebot обычно помечаются как низкоприоритетные.
Поскольку основной текст страницы, заголовки и метаописания после сортировки остаются неизменными, алгоритм дедупликации поисковой системы быстро распознает эти URL как копии канонической страницы (Canonical Page).
Если на сайте неправильно настроен rel="canonical", указывающий на основной путь, Googlebot все равно будет тратить около 15% частоты сканирования на проверку того, не обновился ли контент на этих страницах сортировки.
Для сайта ритейлера со 100 000 SKU всего одна функция «сортировка по рейтингу» может заставить робота посетить дополнительно 100 000 бессмысленных ссылок.
Параметры отслеживания (Tracking Parameters), такие как ?utm_source=google или ?affiliate_id=123, негативно влияют на SEO в основном за счет «затрат на соединение».
Хотя эти параметры совершенно не меняют контент страницы, Googlebot все равно должен установить TCP-соединение и отправить запрос, чтобы убедиться, что возвращаемое по этому URL содержимое совпадает с основной страницей.
Согласно наблюдениям за высокотрафиковыми сайтами, если внутри сайта существует большое количество внутренних ссылок с параметрами UTM, скорость обнаружения валидных исходных путей роботом падает примерно на 25%.
Googlebot при обработке таких полностью дублирующихся URL будет постепенно снижать частоту их сканирования, но до этого драгоценная «квота первого сканирования» уже будет исчерпана этими избыточными кодами отслеживания.
«Технический аудит показывает, что удаление параметров отслеживания из внутренних ссылок и перенос статистической логики на прослушивание событий на стороне браузера может увеличить общий ежедневный объем сканирования страниц роботом Googlebot более чем на 18%».
Параметры пагинации (Pagination Parameters), такие как ?page=2, обрабатываются несколько иначе.
В прошлом Google полагался на rel="next/prev", но теперь он в основном понимает структуру пагинации с помощью алгоритмов.
Если не вмешиваться, робот может углубиться в сканирование до 500-й страницы и далее, хотя ценность ранжирования этих глубоких страниц крайне низка.
Если параметры пагинации сочетаются с параметрами фильтрации (например: синяя рубашка на 5-й странице), сложность URL будет возрастать экспоненциально.
Выявление и контроль
Изучая записи доступа на бэкенде сервера и используя регулярные выражения для ведения статистики частоты URL, содержащих вопросительный знак (?), можно четко отследить траекторию посещений робота.
На международном сайте электронной коммерции с ежедневным трафиком более 100 000 посещений, если логи показывают, что Googlebot ежедневно отправляет более 40 000 запросов к путям с суффиксами ?sessionid= или ?track_id=, при этом возвращаемый контент страниц полностью совпадает с оригинальным HTML, это означает, что около 40% ресурсов сканирования тратится на бессмысленные пути.
Техническая команда должна рассчитать «долю эффективного сканирования», а именно:
Количество сканирований канонических страниц / Общее количество сканирований.
Если это значение ниже 20%, это обычно указывает на то, что робот застрял в лабиринте URL-адресов, созданных параметрами.
Использование инструментов анализа логов, таких как Kibana или Splunk, позволяет наблюдать за распределением нагрузки сканирования при различных комбинациях параметров, выявляя пути, которые генерируют сотни тысяч вариантов, но не приносят трафик.
С помощью отчета «Статистика сканирования» в Google Search Console можно получить реальное распределение данных с точки зрения поисковой системы.
В этом отчете необходимо обратить особое внимание на измерение «Сканирование по целям»:
- Доля запросов на обнаружение (Discovery): относится к случаям, когда робот впервые находит новый URL. Для часто обновляемых сайтов эта доля должна составлять более 30%. Если она слишком низка, это означает, что новый контент блокируется путями со старыми параметрами.
- Частота запросов на обновление (Refresh): относится к повторному посещению роботом уже известных страниц. Если запросы на обновление массово концентрируются на URL с параметрами, а не на основных страницах сайта, это признак неверного распределения ресурсов.
- Показатели распределения кодов состояния ответов: отслеживайте долю 200 (OK), 304 (Not Modified) и 404 (Not Found). Если URL с параметрами вызывают большое количество ошибок 404 или редиректов 301, Googlebot снизит лимит сканирования сайта (Crawl Capacity Limit) из-за слишком высокой стоимости соединений.
- Мониторинг среднего времени загрузки: если сложная фильтрация параметров вызывает тяжелые запросы к базе данных, в результате чего время загрузки страницы превышает 2000 мс, Googlebot быстро сократит количество одновременных сканирований, чтобы не перегрузить сервер.
После подтверждения источников избыточных параметров, хотя тег Canonical может справиться с дублями на стороне индексации, только Robots.txt способен перехватить запросы до установления HTTP-соединения.
Установив Disallow: /*?*sort= или Disallow: /*?*price_min=, можно принудительно заставить Googlebot прекратить доступ к конкретным комбинациям сортировки или фильтрации цен.
Этот метод позволяет немедленно высвободить количество соединений, тратившихся на эти страницы, для канонических URL из Sitemap.xml.
При настройке правил следует избегать широкого Disallow: /*?, чтобы не отсечь полезные для SEO языковые параметры (например, ?hl=en) или параметры пагинации (например, ?p=2).
Тонкая логика управления должна сочетаться с результатами анализа логов, блокируя только те фильтры, которые создают бесконечные комбинации путей.
Для фасетной навигации (Faceted Navigation) использование загрузки AJAX или технологии pushState позволяет изолировать робота.
Когда пользователь нажимает кнопку фильтра, содержимое страницы меняется, но URL не генерирует сканируемый суффикс, или используется только идентификатор фрагмента (#) для смены вида. Такие подходы прозрачны для Googlebot, так как роботы обычно игнорируют все символы после #.
В случаях, когда использование параметров необходимо, можно реализовать логику ограничения измерений:
- Ограничение глубины пути: в программном коде прописывается правило: когда комбинация параметров превышает три измерения (например: цвет + размер + материал), система автоматически вставляет тег
noindexв заголовок HTML и гарантирует, что эта страница не появится ни в каких внутренних ссылках. - Применение атрибута Nofollow: использование
rel="nofollow"в ссылках боковой панели фильтров подает поисковой системе сигнал о том, что «этот путь не важен», снижая вероятность входа робота в глубокие комбинации фильтров. - Директива канонической консолидации: убедитесь, что все страницы с параметрами через
rel="canonical"указывают на самую лаконичную каноническую версию. Даже если робот выполнит сканирование, это направит систему индексации на объединение веса с основным путем.
Если главная страница или основные навигационные панели содержат большое количество ссылок с параметрами отслеживания UTM, Googlebot будет в приоритетном порядке сканировать эти «зашумленные» пути.
Рекомендуется перенести всю статистику внутреннего трафика на отслеживание событий на стороне браузера, тем самым сохраняя URL чистыми. При обработке логики пагинации, хотя Google больше не использует специальные теги пагинации, поддержание четкой структуры путей (например, /page/2/ вместо ?page=2) помогает алгоритму более стабильно распознавать списки.
В течение двух недель после внедрения блокировки в Robots.txt или логики консолидации параметров следует постоянно отслеживать отчет «Покрытие индекса» в Google Search Console.
Идеальная тенденция:
Количество страниц с пометкой «Просканировано — на данный момент не проиндексировано» или «Дублирующая страница» значительно снижается, а «Время последнего сканирования» основных страниц становится более частым.
Если цикл сканирования страницы сократился с одного раза в 10 дней до одного раза в 24 часа, и запросы с ответом 200 в серверных логах больше сосредоточены на канонических URL, это доказывает, что квота на сканирование распределена разумно.
Размытие сигналов
Когда несколько URL, содержащих разные параметры (например, ?sort=price или ?sessionid=abc), указывают на один и тот же контент, Google рассматривает их как независимые страницы.
Изначальные 100% авторитетности ссылок и сигналов кликов пользователей будут распределены между этими вариантами.
Если страница создает 5 копий с параметрами, PageRank, получаемый отдельным URL, составит всего 20%, что не позволит ему достичь порога веса для попадания в топ-10 результатов поиска.
На сайтах электронной коммерции с более чем 50 000 URL необработанные параметры приведут к тому, что более 50% ежедневной частоты сканирования Googlebot будет тратиться на дублирующиеся пути, замедляя скорость индексации новых страниц.
Распределение веса
В оригинальной логике алгоритма PageRank способность страницы к ранжированию определяется количеством и качеством ссылок, указывающих на этот URL.
Когда сайт генерирует варианты путей, содержащие ?sort=newest, ?filter=price-low или ?sessionid=xyz, внешние сайты очень часто ссылаются на эти различные варианты.
Конкретные данные показывают: если оригинальный URL товара — example.com/item, а 40% внешних ссылок указывают на example.com/item?source=social, Link Graph Google зафиксирует эти два URL как отдельные записи.
Хотя алгоритм попытается выполнить каноническое распознавание, в процессе реальной передачи веса около 10–15% баллов будет потеряно в таком нестандартном сопоставлении.
«При обработке параметризованных URL Googlebot должен решить, в какую конкретную сущность влить PageRank; при отсутствии четкого руководства через Canonical этот процесс вливания становится случайным и фрагментированным». — На основе технических публичных разъяснений команды качества поиска Google.
Данные реального анализа логов показывают, что крупные международные платформы e-commerce при обработке фасетной навигации (Faceted Navigation), если они не ограничивают сканирование параметров, накапливают PageRank на своих основных страницах категорий на 30% медленнее, чем конкуренты с уникальными путями.
Когда 5000 внутренних ссылок сайта указывают на 50 различных комбинаций параметров, толчок, который мог бы вывести страницу на первую страницу результатов поиска, разделяется на 50 частей — слабых сигналов, недостаточных для ранжирования.
Когда сходство контента двух URL достигает более 98%, система запускает механизм дедупликации.
Согласно наблюдениям за 500 000 североамериканских сайтов, страницы, признанные Google «дубликатами», но не перенаправленные физически, часто имеют замороженный вес оригинальных ссылок, который не переносится автоматически на 100% на основную страницу.
Для сайтов с более чем 100 000 URL неэффективные пути сканирования, созданные параметрами, ограничивают глубину доступа Googlebot.
На сайтах без управления параметрами время пребывания робота на страницах с невалидными параметрами составляет 65% от общего времени сканирования. Это приводит к тому, что новому качественному контенту может потребоваться 14 дней или даже больше для индексации, тогда как на оптимизированных сайтах этот цикл обычно сокращается до 24 часов.
«Каждое изменение символа в URL создает новый узел в базе данных; даже если содержимое идентично, эти узлы на начальном этапе алгоритма находятся в отношениях конкуренции, а не сотрудничества». — Из экспериментального отчета международного исследовательского института SEO.
В некоторых архитектурах, использующих балансировку нагрузки или сети доставки контента (CDN), запросы с параметрами могут кэшироваться как разные статические копии.
Если в заголовках HTTP-ответов не настроены должным образом Vary: User-Agent или Link: rel="canonical", Googlebot может решить, что эти страницы с параметрами предназначены для отображения разного контента для пользователей из разных регионов.
При такой ошибке алгоритм еще больше расщепит авторитетность всего сайта по каждому измерению параметров, создавая ситуацию «дефицита веса».
Чтобы количественно оценить потери от такого распределения на техническом уровне, можно обратиться к «модели потери веса»:
Предположим, основной странице нужно 100 единиц сигналов, чтобы войти в тройку лидеров. Если существует 4 варианта с параметрами, и каждый вариант оттягивает на себя 15% сигналов, то основная страница в итоге сохранит лишь 40 единиц. Такая страница будет находиться в крайне невыгодном положении в конкурентной борьбе.
При техническом аудите зарубежных магазинов на таких платформах, как Shopify, после отключения в GSC (Google Search Console) параметров, не меняющих контент (таких как sort_by, view и page), было замечено, что количество эффективных показов целевых страниц в среднем выросло на 55% за 60 дней.
Решения
В глобальных архитектурах электронной коммерции корпоративного уровня, таких как Adobe Commerce (бывший Magento) или Salesforce Commerce Cloud, система индексации Google в процессе сканирования в приоритетном порядке считывает директиву rel="canonical" в заголовке HTML или HTTP-ответе.
Когда система генерирует сложные комбинации фильтров типа ?color=blue&size=xl, серверная программа принудительно устанавливает канонический адрес этой страницы на корневой URL без каких-либо параметров.
После правильного внедрения этого решения точность распознавания Google дублирующегося контента на сайте может вырасти с 60% до более чем 99%. Баллы PageRank, ранее разбросанные повсюду, физически объединятся в течение 2–4 недель цикла обновления индекса.
Для транснациональных сайтов с миллионным количеством SKU такая логика гарантирует, что основные пути поиска получат более 95% авторитетности внутренних ссылок сайта.
- Объявление ссылок в заголовках ответов HTTP: при обработке документов PDF или других не-HTML файлов с параметрами сервер отправляет заголовок
Link:, предотвращая ситуацию, когда поисковая система рассматривает ссылку на скачивание с параметрами отслеживания как новый контент. - Принудительное объединение через 301 редирект: для параметров маркетингового отслеживания, которые уже утратили актуальность (например,
?utm_campaign=2023_saleтрехлетней давности), основным подходом является настройка правил на уровне сервера Nginx или Apache, перенаправляющая все запросы с этим устаревшим параметром на стандартную страницу. Это гарантирует 100% перенос исторически накопленного веса внешних ссылок. - Игнорирование параметров без состояния на стороне сервера: в бэкенд-разработке через конфигурации настраивается очистка Session ID или других параметров, используемых только для внутренней логики, чтобы URL, которые видят разные пользователи, оставались физически уникальными.
- Блокировка категорий параметров в Google Search Console: в панели управления Google технические специалисты помечают параметры как «пассивные» (Passive Parameters), четко сообщая роботу, что эти символы не меняют содержание страницы. Это побуждает Googlebot проактивно пропускать сканирование таких URL.
В масштабной SEO-практике для одностраничных приложений (SPA) со сложными системами фильтрации (например, на React или Angular) разработчики предпочитают использовать Fragment Identifier (#) вместо традиционных строк запроса (?).
Например, изменение URL фильтрации с /shoes?brand=nike на /shoes#brand=nike. Все действия пользователя по нажатию и фильтрации выполняются на стороне клиента, а поисковая система всегда видит только один путь /shoes.
При использовании глобальных сетей доставки контента (CDN), таких как Cloudflare или Akamai, технические команды настраивают правила «игнорирования параметров в Cache Key».
Независимо от того, обращается ли пользователь к example.com/page?id=1 или example.com/page?id=1&from=email, CDN вернет один и тот же закэшированный экземпляр как поисковой системе, так и пользователю, и выдаст унифицированный канонический результат в заголовке ответа.
Для таких платформ с огромными массивами данных, как Amazon или eBay, логика обработки больше ориентирована на перезапись структуры путей (URL Rewriting).
Система преобразует исходный формат параметров /product.php?id=123&variant=blue в более семантичный формат каталога /product/123/blue/.
В ходе выборочного исследования 100 000 зарубежных независимых сайтов было обнаружено, что те сайты, которые маскируют функциональные параметры (сортировка, переключение видов) через API window.history.pushState в JavaScript без изменения физического адреса запроса, имеют стабильность рейтинга страниц в среднем в 2,8 раза выше, чем обычные сайты.


