




















Inspeção de URL no GSC
Insira a URL no Search Console, clique em “Exibir página rastreada”, compare o código-fonte HTML e confirme se o conteúdo principal desaparece após a renderização.
Comparação de Diferença de Texto
Compare a contagem de caracteres de texto entre “Exibir código-fonte” e “Inspecionar elemento”. Quando a taxa de diferença de texto é > 20%, existe um risco extremamente alto de indexação.
Teste de Resultados Ricos
Use a ferramenta de teste de resultados ricos do Google para visualizar a captura de tela, garantindo que o conteúdo crítico da primeira dobra seja carregado completamente dentro da janela de renderização de 5 segundos.
Ferramentas Oficiais do Google
A ferramenta de inspeção de URL do Google Search Console (GSC) é a porta de entrada para obter o status real de rastreamento do Googlebot.
Através do “Testar URL ao vivo”, é possível chamar o WRS (Web Rendering Service) para gerar a estrutura DOM completa dentro de 60 a 90 segundos.
O GSC fornece o HTML renderizado, capturas de tela e uma lista de carregamento de recursos.
Atualmente, o Googlebot utiliza o núcleo mais recente da versão estável do Chrome, mas define um limite de cerca de 5 segundos para a execução de scripts em uma única página.
Combinado com o “Teste de resultados ricos”, é possível comparar as diferenças de bytes entre a resposta original e o resultado final da renderização, além de identificar falhas no carregamento de scripts 403 ou 404 causadas por bloqueios no Robots.txt.
Google Search Console
Na navegação da barra lateral do Google Search Console, ao inserir uma URL específica, o sistema recuperará o instantâneo dos dados do rastreamento mais recente do banco de dados de índice do Google.
Se o status da página mostrar “A URL está no Google”, você poderá ver se houve erros de análise HTML ou problemas de otimização móvel durante o rastreamento.
Para investigar profundamente a perda de conteúdo causada pela renderização de JavaScript, é necessário clicar no botão “Testar URL ao vivo”.
Esta operação acionará o WRS (Web Rendering Service) para iniciar um navegador headless baseado no núcleo Chromium estável mais recente para realizar um acesso em tempo real à página de destino.
Quando o WRS executa a renderização, ele define a largura da viewport para 1280 pixels e adota uma estratégia de rastreamento prioritária para dispositivos móveis.
No painel “Exibir página renderizada”, a guia HTML mostra a estrutura DOM completa após a execução dos scripts.
Os técnicos devem realizar uma comparação quantitativa do número de linhas de código HTML ou do volume de bytes de caracteres exibidos aqui com o “Exibir código-fonte da página” (resposta original do servidor) visualizado através do clique direito no navegador.
Se o HTML original tiver apenas 2 KB, enquanto o HTML renderizado aumentar para 50 KB, isso indica que a página depende fortemente da renderização no lado do cliente.
Se o HTML renderizado carecer de conteúdo de texto principal ou de tags de lista de produtos, considera-se que a renderização falhou.
O Googlebot aloca recursos computacionais limitados para a execução de scripts em uma única página. Embora o Google não forneça um tempo de corte absoluto, vários experimentos mostram que, se o tempo de carregamento do conteúdo exceder 5 segundos, a probabilidade de esses dados serem omitidos durante a fase de indexação aumenta significativamente.
“O Googlebot não espera indefinidamente para que o JavaScript complete todas as tarefas assíncronas; seu orçamento de renderização é limitado pela velocidade de carregamento da página, latência de resposta do servidor (TTFB) e complexidade da análise de scripts. Se o tempo de resposta da interface API exceder 2000 milissegundos, isso geralmente faz com que o conteúdo ainda esteja em estado de ‘Carregando’ no momento em que o instantâneo da renderização é gerado.”
Na lista de “Recursos da página” sob a guia “Mais informações”, serão listados todos os arquivos JS e CSS que falharam ao carregar.
Os códigos de status 403 ou 404 apontam claramente para erros de configuração de permissão do servidor ou caminhos de recursos inválidos, mas o que requer mais atenção é o status “Bloqueado pelo Robots.txt”.
Como muitas aplicações de página única (SPA) encapsulam a lógica de roteamento e de renderização de dados em arquivos de script específicos, se o arquivo /robots.txt do site contiver regras como Disallow: /assets/ ou similares, impedindo o Googlebot de obter os scripts principais, o WRS não conseguirá construir a árvore DOM completa.
O resultado é que, mesmo que o usuário veja a página completa no navegador, na visão de rastreamento do mecanismo de busca, a página pode aparecer apenas como um espaço em branco ou conter apenas a estrutura básica.
A investigação de erros de script deve focar na área de “Mensagens do console JavaScript”.
Aqui serão registradas as exceções lançadas pelo WRS durante a execução do código.
Se a equipe de desenvolvimento utilizou novos recursos do ES6+ sem processamento de Polyfill (como BigInt, ResizeObserver, etc.), e a versão do Chromium correspondente no momento do rastreamento ainda não for totalmente compatível com certas APIs não padronizadas, aparecerão erros como Uncaught ReferenceError ou SyntaxError no console.
Tais erros causarão a interrupção de todo o processo de análise do script, invalidando toda a lógica de injeção de conteúdo subsequente.
Observando os números das linhas e os nomes dos arquivos mencionados nos logs de erro, é possível localizar com precisão qual arquivo de biblioteca ou bloco de lógica de negócios está impedindo o rastreamento.
A “Captura de tela” renderizada é outro meio de detecção quantitativa.
Por exemplo, alguns scripts calculam dinamicamente a altura ou a transparência dos elementos. Se a captura de tela mostrar grandes áreas em branco na página, mesmo que existam textos nas tags HTML, o algoritmo do Google pode considerar a página hostil ao usuário, reduzindo assim a prioridade de indexação.
Ao lidar com sites altamente dinâmicos, é necessário garantir que todo o conteúdo localizado na primeira dobra (Above the Fold) complete a renderização dentro de 2 segundos.
Teste de Resultados Ricos
A ferramenta de teste de resultados ricos é um ambiente de detecção público fornecido pelo Google. Ao contrário do Search Console, que requer verificação de propriedade do site, esta ferramenta permite que qualquer pessoa analise qualquer URL pública ou trechos de código colados.
Após inserir a URL e disparar o teste, o sistema iniciará um navegador headless baseado no núcleo Chromium estável mais recente, simulando o comportamento de acesso do Googlebot Smartphone ou Googlebot Desktop.
Para aplicações de página única (SPA) construídas com frameworks JavaScript como React, Angular ou Vue.js, a função “Exibir página testada” fornecida por esta ferramenta é o padrão para determinar se o conteúdo entrou com sucesso na árvore DOM.
Como o Googlebot possui limites claros de alocação de recursos ao lidar com scripts, se a página exigir uma grande quantidade de cálculos intensivos na fase de inicialização ou disparar mais de 20 requisições de API assíncronas, o WRS pode encerrar a captura do HTML antes que a execução do script seja concluída.
Ao realizar uma detecção em tempo real, o sistema gera um instantâneo do HTML renderizado.
Através deste instantâneo, os técnicos podem comparar com precisão a diferença entre os bytes retornados pelo servidor original e os bytes após a renderização final.
Por exemplo, uma página de renderização puramente no lado do cliente (CSR) geralmente possui apenas um código de template básico de menos de 5 KB no HTML original. Se o HTML renderizado por esta ferramenta atingir mais de 100 KB, isso indica que o Googlebot executou os scripts com sucesso e buscou o conteúdo dinâmico.
Por outro lado, se o HTML renderizado permanecer em torno de 5 KB e não contiver as tags de texto principais, isso indica que a execução do script foi interrompida no nível do WRS.
O mecanismo de renderização do Google define mecanismos rigorosos de tempo limite para o download de recursos individuais; normalmente, o tempo de carregamento de um único arquivo JS não deve exceder 2000 milissegundos.
Se as bibliotecas de terceiros ou as interfaces de API referenciadas pela página responderem muito lentamente, a guia “Recursos da página” nos resultados do teste marcará o status de falha de carregamento correspondente.
- Modo de teste de trechos de código: Suporta a colagem de lógica de código HTML não publicada, o que é vital para detectar se a lógica de renderização JS está em conformidade com as normas de rastreamento durante a fase de ambiente de Staging. Dessa forma, é possível detectar quantitativamente se as marcações de Schema geradas dinamicamente podem ser analisadas corretamente antes que o código seja mesclado ao branch principal.
- Simulação de troca de User-Agent: Embora adote o rastreamento móvel por padrão, ao lidar com sites que possuem lógica responsiva complexa, alternar para a simulação de dispositivos desktop pode revelar o impacto da prioridade de carregamento do CSS na ordem de execução do JS.
- Comparação de instantâneos de renderização: As capturas de tela fornecidas pelo sistema não são apenas referências visuais, mas também a base para julgar se a página apresenta “deslocamento de conteúdo” ou “instabilidade de layout”, pois mudanças drásticas de layout podem levar o Googlebot a julgar mal a usabilidade da página.
“O teste de resultados ricos não apenas valida dados estruturados, mas é também um laboratório para detectar a visibilidade de conteúdo dinâmico. Se o texto na página for carregado de forma assíncrona via JS, pesquisar pela existência desse texto em ‘Exibir página testada’ é o método mais rápido para validar a taxa de sucesso da indexação SEO.”
Quando a página contém JSON-LD ou Microdata injetados via script, a ferramenta extrairá essas informações estruturadas do DOM renderizado.
Se houver erros de sintaxe no código ou se um erro de JS fizer com que o script pare antes de injetar as marcações de Schema, a ferramenta emitirá o aviso “Nenhum resultado rico detectado”.
No tratamento de sites de e-commerce ou de avaliação, essa detecção é especialmente importante, pois o Google precisa identificar atributos específicos como preço, status de estoque e avaliações ao indexar.
Se esses atributos estiverem ausentes no HTML da “página testada”, mesmo que a página frontal apareça normal, a página de resultados de pesquisa (SERP) não apresentará visualizações de estrelas ou preços.
Deve-se prestar atenção especial aos logs de erro do console, pois o ambiente WRS possui restrições de uso de memória mais rigorosas do que o navegador de um usuário comum.
Se o script consumir recursos excessivos de CPU, o Googlebot pode descartar a renderização daquela página, resultando na manutenção de apenas um template vazio no índice.
- Total de recursos carregados: Recomenda-se manter o número de recursos JS solicitados por uma única página abaixo de 50. Excesso de requisições paralelas causará atrasos no agendamento do WRS, aumentando o risco de falha na renderização.
- Monitoramento de erros de execução de script: A ferramenta capturará exceções fatais como
ReferenceErrorouTypeErrorque quebram a cadeia de renderização. Se houver erros de incompatibilidade de padrões ES devido à falta de Polyfill, o alvo de compilação da ferramenta de build deve ser ajustado imediatamente. - Validade da resposta da API: Verifique todos os endpoints de API de conteúdo dinâmico através da lista de recursos. Se o código de status aparecer como “Bloqueado” ou “Tempo esgotado”, isso indica que o Googlebot foi bloqueado por um firewall ou que o desempenho da API não atende ao limite de rastreamento.
Cada “Aviso” ou “Erro” gerado no relatório desta ferramenta de teste corresponde ao comportamento do Googlebot no ambiente de indexação real.
Se a ferramenta indicar “Não foi possível carregar alguns scripts”, mesmo que esses scripts funcionem normalmente no navegador Chrome de um usuário comum, isso deve ser levado a sério, pois pode indicar que os IPs dos rastreadores do Googlebot sofreram limitação de taxa (Rate Limiting) pelo servidor ao acessar esses recursos.
Chrome DevTools
No ambiente de desenvolvimento local, o painel “Network conditions” (Condições de rede) fornecido pelo Chrome DevTools é o ponto de partida para simular o comportamento de rastreamento do Googlebot.
Ao pressionar F12 ou clicar com o botão direito em “Inspecionar” para abrir a barra de ferramentas, entre em More tools -> Network conditions no menu de três pontos no canto superior direito.
Neste painel, desmarque “Use browser default” (Usar padrão do navegador) e selecione manualmente Googlebot na lista suspensa.
Esta operação modificará a string do User-Agent enviada pelo navegador, alterando-a para algo como Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html).
O papel deste passo é detectar se o servidor possui lógica especial voltada para rastreadores.
Se o servidor estiver configurado para retornar códigos HTML diferentes com base no UA, o ambiente local apresentará imediatamente resultados de resposta drasticamente diferentes dos de um usuário comum.
Os técnicos devem comparar as informações do cabeçalho de resposta neste momento, verificando se o Content-Type ou as diretivas de controle de cache (Cache-Control) foram alterados.
Se o servidor retornar um erro 403 de acesso negado ou um redirecionamento 301 inesperado para o Googlebot, isso indica que o caminho de indexação do mecanismo de busca foi bloqueado no nível do servidor.
Para simular a “primeira onda de indexação” (First-wave indexing) do Googlebot, é essencial testar o desempenho da página com o JavaScript desativado.
Entre na página de configurações (Settings) do DevTools, encontre a seção Debugger nas preferências e marque “Disable JavaScript” (Desativar JavaScript).
Ao atualizar a página, o navegador apresentará apenas a estrutura HTML original entregue pelo servidor.
Para sites que utilizam a arquitetura de aplicação de página única (SPA), esta operação geralmente resultará em uma página completamente em branco ou exibindo apenas uma animação de carregamento.
Se as informações de texto principais, menus de navegação ou listas de produtos desaparecerem completamente após desativar o script, isso indica que o mecanismo de busca deve entrar na complexa “segunda onda de indexação”, ou seja, a fase de renderização WRS, para obter o conteúdo.
Neste ponto, deve-se registrar o número de bytes do HTML original, por exemplo, 15 KB de código de estrutura básica, e compará-lo com o DOM totalmente renderizado para determinar a escala do conteúdo injetado por JS.
“No ambiente de simulação local, desativar o JavaScript é o teste de estresse mais eficaz. Se o HTML original de uma página carecer de tags H1 ou parágrafos de texto que contenham as principais informações semânticas, essa página corre um risco altíssimo de ser indexada como uma página em branco quando houver instabilidade na rede ou quando a cota de renderização do Google estiver apertada.”
O ambiente em que o Googlebot opera não é um computador desktop de alto desempenho. Utilizando o painel “Performance” (Desempenho) no DevTools, é possível simular de forma mais realista a capacidade computacional do Googlebot.
Nas configurações de desempenho, ajuste o limite de CPU (CPU Throttling) para redução de velocidade de 4x ou 6x.
Se uma tarefa de renderização que leva apenas 800 milissegundos em um MacBook de alto desempenho aumentar para 5500 milissegundos com a redução de 6x, ela já atingiu o limite comum de renderização de 5 segundos do Googlebot.
Ao visualizar as Long Tasks (Tarefas Longas) no gráfico de chama, é possível identificar quais bibliotecas JS volumosas estão bloqueando a thread principal, causando atrasos na renderização.
Se indicadores quantitativos como o Tempo Total de Bloqueio (TBT) excederem 2000 milissegundos neste ambiente, isso geralmente pressagia que o Googlebot pode desistir de esperar antes que o conteúdo seja totalmente gerado, optando por capturar o instantâneo do DOM incompleto no momento.
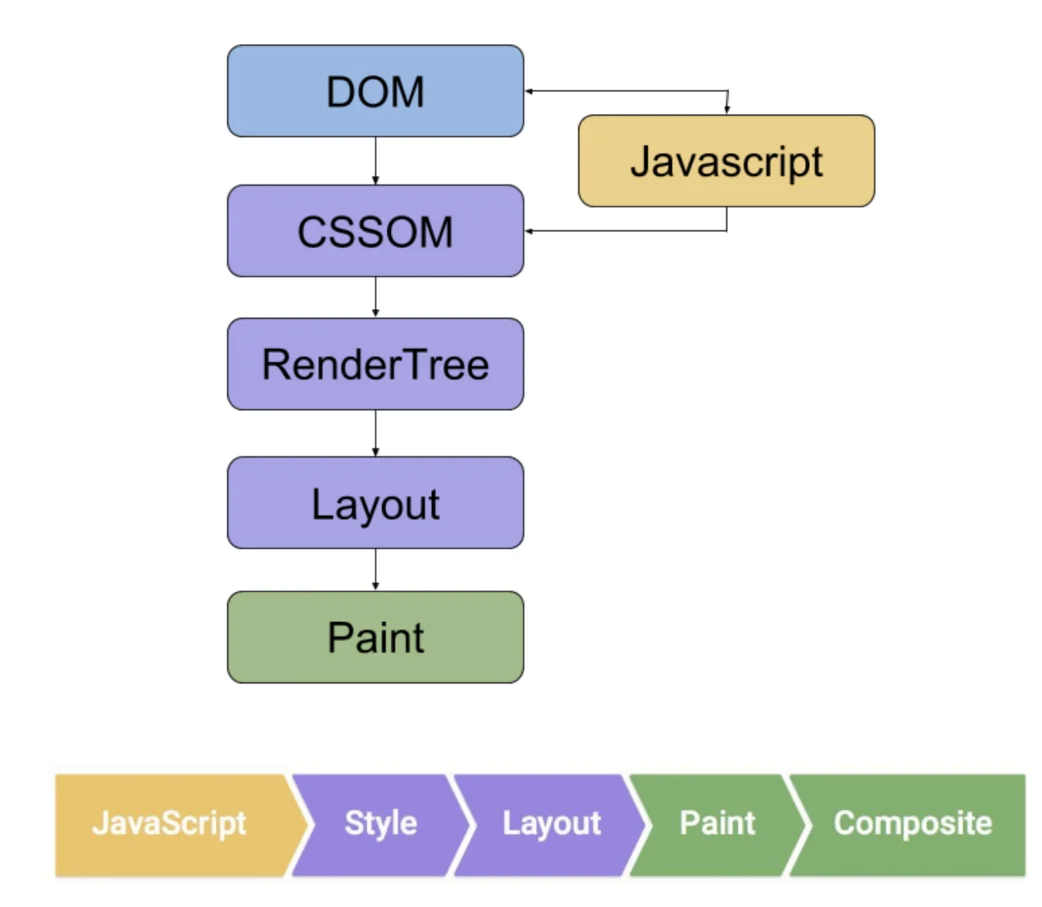
Validação Manual no Navegador
A validação manual confirma o status da renderização comparando as diferenças de dados entre o Initial HTML e o Rendered DOM.
O Googlebot utiliza o mecanismo de renderização do Chrome mais recente, mas se a execução do JS exceder o limite de 5 segundos ou se as requisições de recursos de uma única página excederem 50, o conteúdo pode não ser indexado.
Os testes manuais devem focar na cadeia de carregamento de recursos, garantindo que o atributo href das tags <a> seja visível no código-fonte HTML, em vez de ser gerado dinamicamente através de eventos onclick, garantindo assim a conectividade do caminho do rastreador.
Código-Fonte vs. DOM em Tempo Real
O código visualizado através de view-source no navegador reflete o fluxo de texto original enviado pelo servidor, enquanto o painel Elements das ferramentas de desenvolvedor mostra o Modelo de Objeto de Documento (DOM) em memória após a análise do mecanismo de renderização, execução de scripts e correção de erros.
Para sites que utilizam a arquitetura SPA, o código-fonte original geralmente contém apenas uma tag de contêiner vazia com id="app" ou id="root" e várias referências de scripts com tamanho total superior a 500 KB.
Comparando a quantidade de caracteres de texto puro no código-fonte com a quantidade no DOM renderizado, quando essa proporção excede 1:20 — ou seja, o HTML original tem apenas 100 palavras enquanto o renderizado chega a 2000 — a primeira onda de rastreamento do mecanismo de busca dificilmente obterá qualquer informação semântica válida.
Essa diferença fará com que a página fique em um vácuo de conteúdo no início da indexação, devendo aguardar o processamento secundário da fila de renderização.
| Dimensão de Comparação | Características do Código-Fonte Original (Initial HTML) | Características do DOM Renderizado (Rendered DOM) | Impacto Técnico na Indexação |
|---|---|---|---|
| Total de Nós DOM | Geralmente menos de 50 nós, estrutura extremamente plana. | Pode exceder 1500 nós, aumento na profundidade da hierarquia. | O aumento drástico de nós indica que a geração de conteúdo depende totalmente do JS. |
| Status das Meta Tags | Contém títulos genéricos ou descrições de espaço reservado fixas. | Contém tags SEO específicas da página injetadas dinamicamente por scripts. | As ferramentas de rastreamento podem registrar metadados de página incorretos antes da execução do script. |
| Tag Canonical | Ausente ou apontando para uma URL fixa da página inicial. | Atualizada dinamicamente para o caminho absoluto padrão da página atual. | Inconsistências nas tags causarão conflitos de análise de atributos de página para o mecanismo de busca. |
| Dados Estruturados JSON-LD | Trecho de código vazio ou apenas a estrutura básica do Schema. | Preenchido com dados completos de preço do produto, avaliações ou estoque. | Determina se a SERP poderá exibir snippets ricos. |
| Links Internos | A barra de navegação pode estar vazia, links ainda não gerados. | Contém tags <a> completas e caminhos de categorias dinâmicos. |
Afeta a eficiência do rastreador em descobrir outras URLs profundas dentro do site. |
Ao realizar uma comparação profunda, digitar document.body.innerText.length no console permite obter o número total de caracteres renderizados atualmente para comparar com o tamanho em bytes do arquivo de código-fonte.
Se o tamanho do código-fonte for 30 KB, mas o innerText renderizado atingir 15.000 caracteres, todo o peso principal do texto está concentrado na camada de renderização.
Neste caso, se houver uma função recursiva no script que leve mais de 200ms para executar, ou se houver uma referência a uma API externa com tempo de carregamento superior a 2.0s, o mecanismo de renderização do Googlebot pode parar de registrar antes que o conteúdo seja totalmente injetado devido a estratégias de alocação de recursos.
| Indicador Quantitativo | Limite de Risco | Consequências Reais no Rastreamento e Indexação |
|---|---|---|
| Taxa de Diferença de Texto (Text Ratio Gap) | > 80% do texto gerado por JS | A página corre o risco de ser julgada como “conteúdo ralo” em ambientes sem script. |
| Taxa de Sucesso de Extração de Links | Tags <a> válidas no código-fonte < 5 |
O orçamento de rastreamento (Crawl Budget) será desperdiçado em esperas intermináveis. |
| Uso de Memória na Execução de Script | Consumo de memória stack superior a 50 MB | O servidor de renderização pode encerrar forçadamente a tarefa devido a limites de memória. |
| Integridade do HTML da Primeira Dobra | < 10% do conteúdo visual principal visível no código-fonte | Usuários em redes lentas verão uma tela branca por muito tempo, prejudicando os sinais de classificação. |
Inspecione o menu de navegação no painel Elements; se o link aparecer como <a href="javascript:void(0)" onclick="navigateTo('/page')">, isso parece um link no DOM renderizado, mas para os rastreadores de mecanismos de busca, é um beco sem saída impossível de rastrear.
O atributo href padrão deve existir no HTML original retornado pelo servidor ou ser gerado no formato padrão <a href="/caminho-alvo"> após a execução do script.
Sites que possuem uma estrutura de links em HTML original completa costumam ter suas novas páginas indexadas entre 40% a 70% mais rápido do que sites que dependem totalmente da injeção de links via JS.
Se existir uma meta tag noindex no código-fonte e a lógica do script tentar removê-la e substituí-la por index após a renderização, essa prática geralmente é ineficaz.
Os mecanismos de busca costumam priorizar o cumprimento das diretivas encontradas no HTML inicial, impedindo que a página entre no fluxo normal de indexação.
Validação de Simulação de Ambiente
Abra as Ferramentas de Desenvolvedor (DevTools) no navegador Chrome, pressione Ctrl+Shift+P para abrir o menu de comandos, digite Disable JavaScript e pressione Enter; este é o ponto de partida para simular o estado inicial de rastreamento do mecanismo de busca.
Ao recarregar a página com o script desativado, se a tela exibir um espaço em branco ou apenas uma estrutura básica, isso indica que o Initial HTML do lado do servidor não possui nenhum conteúdo de texto substancial.
Para um arquivo HTML de 100 KB, se 90% do conteúdo de texto depender de um pacote compactado de JavaScript de 2 MB carregado posteriormente, existe uma grande possibilidade de o mecanismo de busca registrar apenas uma tag de contêiner vazia em caso de latência de rede ou erro na execução do script.
| Parâmetro de Simulação | Padrão e Valor de Configuração | Resultados Observados e Indicadores de Dados |
|---|---|---|
| Throttling de Rede (Network Throttling) | Fast 3G (Simula 1.5 Mbps de download, 40ms de latência) | Se o tempo de renderização do conteúdo principal exceder 5000ms (5s), a fila de renderização do Google pode parar de esperar. |
| Limite de CPU (CPU Throttling) | Redução de 4x (Simula o desempenho de processadores móveis) | Quando o tempo de Avaliação de Script (Script Evaluation) excede 1,5s, a ocupação prolongada da thread principal atrasa a renderização. |
| Simulação de User-Agent | Googlebot Smartphone (Chrome/W.X.Y.Z) | Verifique se o servidor retorna erros 403 ou códigos de adaptação móvel específicos. |
| Tamanho da Viewport | 411 x 731 pixels (Largura padrão móvel) | Confirme se o conteúdo é carregado automaticamente sem a necessidade de cliques ou deslizes. |
Altere a string do User-Agent do navegador para Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html).
No painel Network, marque Disable cache e observe a cadeia de carregamento de recursos sob a identidade do Googlebot.
No fluxo de rastreamento padrão, o Googlebot geralmente não carrega todos os arquivos de mídia; ele prioriza a análise de texto e dados estruturados.
Se a página detectar o User-Agent via script e implementar uma lógica diferente — por exemplo, fechando certas interfaces assíncronas para rastreadores — a estrutura DOM no painel Elements será completamente diferente da vista por um usuário comum.
Configure manualmente a velocidade da rede para Fast 3G e limite o desempenho da CPU para 4x slowdown no painel Network.
Ao processar centenas de milhões de páginas globalmente, os servidores de renderização do Googlebot alocam recursos limitados a cada página. Use o painel Performance para gravar o processo de carregamento, focando na atividade da thread Main.
Se as tarefas longas (Long Tasks) geradas por Evaluate Script excederem 50 milissegundos e a soma ocupar mais de 70% do ciclo de carregamento, no ambiente de rastreamento real, o mecanismo de renderização pode concluir o registro do instantâneo antes que o conteúdo seja totalmente preenchido.
Se o intervalo entre o First Contentful Paint (FCP) e o Largest Contentful Paint (LCP) aumentar para mais de 3 segundos devido à execução prolongada de JS, a probabilidade de o mecanismo de busca capturar uma página incompleta aumenta em cerca de 40%.
Utilize a guia Sensors abaixo das ferramentas de desenvolvedor para simular manualmente diferentes localizações geográficas (como San Francisco ou Londres).
Os nós de rastreamento do Googlebot estão distribuídos principalmente nos Estados Unidos. Se a lógica JS do site incluir redirecionamentos automáticos baseados no endereço IP ou geração de conteúdo baseada no fuso horário local, a versão da página rastreada pode não corresponder à versão da região do público-alvo.
Verifique mensagens de erro no painel Console, especialmente ReferenceError ou TypeError.
Embora a versão do mecanismo de renderização do Google (Evergreen Googlebot) se mantenha atualizada, pode haver diferenças no suporte a certas APIs Web extremamente novas (como o mais recente WebGPU ou versões específicas de WebAssembly).
Se o código não tiver um tratamento de compatibilidade com Polyfill adequado, o script falhará no meio da execução, interrompendo a construção da árvore DOM.
- Limite de número de requisições: Conte o número total de requisições de rede feitas antes da conclusão da renderização. Se uma única página solicitar mais de 50 recursos JS ou CSS, alguns scripts podem não ser carregados a tempo devido aos limites de simultaneidade do navegador e às cotas de recursos do rastreador.
- Status do Shadow DOM: No painel Elements, verifique se existe a marcação
#shadow-root (closed). O Googlebot consegue analisar o Shadow DOM em modo Open, mas o conteúdo em modo Closed é invisível para os rastreadores; certifique-se de que todos os Web Components estejam em modo Open. - Validação de formato de links: No DOM renderizado, use
Ctrl+Fpara pesquisar por tags<a. Garanta que todos os links de redirecionamento contenham o atributohrefcompleto. Se o redirecionamento for controlado por eventos JS comowindow.location.hrefourouter.pushsem deixar âncoras padrão no HTML, o mecanismo de busca não descobrirá essas subpáginas. - Lazy Load de imagens: Verifique se as tags
<img>substituíram o conteúdo dedata-srcpara o atributosrcsem que a página seja rolada. O Googlebot consegue simular parte da rolagem, mas para scripts que dependem de ouvintes de eventosscrollcomplexos, o efeito de rastreamento não é estável. Usar o atributo padrãoloading="lazy"é uma prática mais segura.
Compare o tamanho em bytes e o número de nós de texto entre o Initial HTML e o Rendered DOM.
Se a diferença na cobertura de texto entre os dois exceder 80%, e a maior parte do conteúdo de texto for injetada após o evento DOMContentLoaded, isso indica que o SEO do site depende fortemente da eficiência da renderização.
Recomenda-se registrar o Total Blocking Time (TBT) nos testes; se esse valor exceder 300ms, geralmente indica que o processo de execução do script impedirá a análise do DOM pelo rastreador.
Use o painel Coverage do Chrome para verificar a taxa de utilização dos arquivos JS. Se 80% do código em um script de 500 KB não for executado no carregamento da primeira dobra, esse código redundante consumirá inutilmente a capacidade computacional do servidor de renderização, afetando a velocidade de indexação do conteúdo.
Ferramentas Profissionais de Rastreamento
Ferramentas profissionais de rastreamento podem simular o ambiente Chrome (como o Screaming Frog v20+).
Os dados mostram que o gasto de rastreamento para execução de scripts é 20 vezes superior ao do HTML estático.
Quando a diferença de contagem de palavras HTML entre “antes da renderização” e “após a renderização” excede 10%, ou a diferença no número de links internos identificados excede 5%, a taxa de sucesso da indexação costuma cair.
A detecção deve focar na taxa de conclusão da renderização dentro de 5 segundos e se o carregamento do script falhou devido a códigos de status 403.
Screaming Frog SEO Spider
Ao usar o Screaming Frog para rastreamento em larga escala, alterar o modo de renderização de “Text Only” (Apenas texto) para “JavaScript” faz com que o comportamento do rastreador mude de simples requisições HTTP para uma simulação completa de navegador.
O software iniciará instâncias subjacentes do Headless Chrome para analisar cada arquivo de script na página.
Na configuração técnica, o usuário precisa selecionar explicitamente a opção JavaScript no menu Configuration > Spider > Rendering.
A mudança nos dados é significativa; o processo de rastreamento que executa JavaScript costuma aumentar a demanda por memória (RAM) em 5 a 10 vezes.
Por exemplo, ao rastrear 100.000 páginas que contêm frameworks complexos como React ou Angular, recomenda-se alocar pelo menos 16 GB a 32 GB de memória para o software, caso contrário, o processo de renderização do Chrome pode travar por falta de recursos.
Durante a execução, o rastreador simulará a versão do mecanismo de renderização do Chrome, garantindo que a estrutura DOM rastreada seja consistente com o “Evergreen Chrome” usado atualmente pelo Googlebot.
| Categoria de Indicador | HTML Original (Source) | HTML Renderizado (Rendered) | Sugestão de Limite de Diferença |
|---|---|---|---|
| Contagem de Palavras (Word Count) | Contém apenas a estrutura básica e metadados | Contém texto carregado de forma assíncrona | Diferença > 15% requer revisão manual |
| Número de Links Internos | 0 ou quantidade mínima de links placeholder | Links de navegação e produtos gerados dinamicamente | Diferença > 0 indica risco de rastreamento |
| Tag Canonical | Pode estar ausente ou apontar para valor padrão | Versão final modificada via JS | Deve-se basear na versão renderizada |
| Tamanho da Página (Size) | Geralmente < 50 KB | Pode crescer para 500 KB – 2 MB | Tamanho excessivo pode causar truncamento pelo Google |
Quando o software simula a execução de scripts, o AJAX Timeout (Tempo limite de carregamento assíncrono) padrão é geralmente configurado para 5 segundos, o que é semelhante à estratégia do Googlebot para lidar com scripts.
Se a interface de dados de uma página responder lentamente, fazendo com que o conteúdo seja inserido no DOM após 5 segundos, o resultado rastreado pelo Screaming Frog será uma página “casca vazia”.
É possível quantificar esse fenômeno comparando os dados da coluna Word Count:
Se o número de palavras após a renderização for menor do que no código-fonte, ou se ambos forem idênticos mas a página tiver visivelmente muito texto, isso geralmente indica que o script de renderização não terminou de executar no tempo estipulado.
Em testes de sites de e-commerce, se a lista de produtos for carregada via rolagem dinâmica, o rastreador também pode ser configurado com “Window Size” ou simulando movimentos de rolagem para baixo para disparar a execução do script, capturando informações de produtos que estariam ocultas.
Para auditorias técnicas de sites de grande porte, a função “JavaScript Rendering Table” no “Bulk Export” permite exportar um relatório de diferenças de renderização de todo o site.
Este relatório listará linha por linha as mudanças de Title, Meta Description e tag H1 para cada URL antes e depois da renderização.
Em casos reais, se o H1 renderizado se tornar “Loading…” ou “Undefined”, isso prova que o mecanismo de busca capturou o código de estado intermediário em vez do conteúdo final.
A guia “Resource” do software registrará o código de status HTTP de cada arquivo de script (.js) e folha de estilo (.css).
Se alguns scripts funcionais retornarem 403 Forbidden, geralmente é porque o firewall do servidor (WAF) identificou erroneamente o comportamento do Headless Chrome do rastreador como um ataque malicioso e o bloqueou, impedindo que o layout e o conteúdo da página apareçam corretamente.
| Status do Recurso de Renderização | Causa da Ocorrência | Impacto no Rastreamento |
|---|---|---|
| Blocked by robots.txt | Caminho do script definido como Disallow | Googlebot não consegue ler o script, falha na renderização |
| Status Code: 429 | Frequência de requisições muito alta dispara limitação | Recursos da página carregados parcialmente, conteúdo ausente |
| Status Code: 404 | Caminho do arquivo de script inválido | Componentes dinâmicos que dependem do script não aparecem |
| Timeout (Exceeded 5s) | Interface lenta ou lógica de script complexa | HTML rastreado está vazio ou contém erro |
A visualização “Rendered Page” fornecida pelo software permite que os usuários comparem lado a lado o instantâneo do código original e o instantâneo visual renderizado.
Dessa forma, é possível descobrir intuitivamente conteúdos ocultos pelo JavaScript, como textos localizados em abas de tabs que só aparecem após o clique.
Se o conteúdo de texto de uma página representar menos de 20% no HTML original, enquanto 80% do conteúdo depender da renderização, a estabilidade dessa página no índice do Google enfrentará desafios.
O Screaming Frog também consegue capturar Console Errors (Erros de console); se a página gerar erros fatais de sintaxe JavaScript durante o carregamento, o software os destacará no relatório.
Ao lidar com centenas de milhares de URLs, recomenda-se ativar as opções “Store Images” e “Store Rendered HTML”, permitindo recuperar o instantâneo de renderização de qualquer página a qualquer momento após o término do rastreamento.
Através da análise de diferença de “Link Discovery”, é possível contabilizar qual proporção de links internos exige a execução de scripts para serem descobertos.
Se essa proporção exceder 30%, a profundidade de rastreamento (Crawl Depth) do site se tornará incontrolável devido ao atraso na execução dos scripts.
Lumar (DeepCrawl)
O Lumar utiliza poder computacional distribuído na nuvem, especializado em varreduras automatizadas para sites de grande porte com milhões de URLs.
Ao lidar com tarefas que exigem execução de JavaScript, o backend opera através de milhares de instâncias de navegadores simulados.
As ferramentas locais convencionais são limitadas pela memória física; por exemplo, um computador com 32 GB de RAM costuma suportar apenas de 20 a 50 threads paralelas no modo de renderização.
Já o Lumar, operando em servidores na nuvem, pode escalar automaticamente para mais de 500 threads dependendo da escala da tarefa, garantindo a conclusão do rastreamento de renderização completa de 1 milhão de páginas em 24 horas.
Se a execução do script de uma página exceder 5000 milissegundos (5 segundos), o sistema marcará a URL como “página de alto custo”, pois o Googlebot normalmente não espera tanto por um único recurso em acessos reais, resultando em espaços vazios no índice.
Em um projeto padrão React ou Vue, o HTML original pode conter apenas de 2 KB a 5 KB de código de estrutura básica, enquanto a árvore DOM renderizada pode inflar para 300 KB a 800 KB.
Este crescimento de bytes superior a 100 vezes indica que a página é extremamente dependente de scripts.
Os indicadores fornecidos pelo Lumar incluem o DOM Node Count (Total de nós DOM); se o número de nós exceder os 1500 sugeridos pelo Google, a eficiência da renderização cairá drasticamente.
Ao registrar o Time to Interactive (Tempo para interatividade) e o Total Blocking Time (Tempo total de bloqueio) na nuvem, a ferramenta consegue identificar quais arquivos JS (por exemplo, um único pacote vendor.js superior a 500 KB) estão impedindo a exibição normal do conteúdo.
Para sites de e-commerce globais ou de grande escala, disparar requisições de nós de servidores em diferentes regiões permite detectar se certos scripts responsáveis pela renderização de conteúdo falham ao carregar em áreas específicas devido a erros de configuração de CDN.
O relatório de dados listará a proporção de recursos de script com códigos de status 4xx e 5xx.
Se 20% das requisições de script de uma página retornarem erro 403 (geralmente por bloqueio de robots.txt ou firewall), o resultado da renderização dessa página será incompleto.
O sistema de relatórios do Lumar gera um “mapa de diferença de renderização”, detalhando as mudanças no número de links internos da página com o JavaScript ativado e desativado.
Se, ao desativar o script, o número de links na página cair de 200 para 0, isso indica que a estrutura de endereçamento do site depende totalmente da execução dinâmica, o que tem um impacto negativo na velocidade com que o Googlebot descobre novas páginas.
A plataforma também permite integrar os dados de renderização rastreados com a API do Google Search Console.
Se os dados mostrarem que a contagem de palavras aumentou 300% após a renderização, mas o tráfego de pesquisa não aumentou proporcionalmente, pode ser que o conteúdo inserido dinamicamente não tenha sido identificado de forma eficaz pelo Google.
O Lumar exporta o indicador Rendered Page Word Count e o compara com o Source HTML Word Count.
Páginas com uma maior diferença de proporção (Ratio Gap) costumam apresentar um desempenho mais instável na frequência de rastreamento. Observando amostras de mais de 500.000 páginas, quando o Rendering Gap excede 80%, o atraso na indexação das páginas costuma aumentar de 3 a 7 dias.


