




















Sim, os parâmetros de URL (como ordenação ?sort, filtragem ?color ou IDs de rastreamento) são os principais indutores de conteúdo duplicado no Google.
Para garantir que o tráfego de pesquisa seja direcionado com precisão para a página de destino, recomenda-se as seguintes ações:
Configurar a tag Canonical
Adicione rel="canonical" no HTML de todas as páginas variantes, apontando para a URL principal exclusiva.
Gerenciar caminhos de rastreamento
Bloqueie parâmetros de rastreamento de marketing desnecessários (como utm_*) via Robots.txt.
Agregação de sinais de classificação
Isso ajuda o Google a concentrar a “pontuação de crédito” de todas as páginas com parâmetros na página principal, evitando a queda de tráfego causada pela competição interna.
Redundância de Conteúdo
Parâmetros de URL podem fazer com que a mesma página gere um grande número de endereços duplicados.
Por exemplo, uma página de e-commerce com 5 filtros de cores e 3 modos de ordenação gerará mais de 15 URLs diferentes.
Em sites grandes, cerca de 40% da cota de rastreamento é frequentemente ocupada por essas variantes de parâmetros.
Quando o Google indexa 200 páginas iniciais idênticas com sufixos de rastreamento UTM, a autoridade de pesquisa da página principal é diluída, resultando em uma queda de cerca de 25% no desempenho do ranking.
Dispersão de Links
No mecanismo de indexação do Google, URLs com sufixos diferentes são tratadas como entidades independentes.
Por exemplo, se uma página de documentação técnica recebe backlinks de 50 domínios diferentes, mas 20 desses links apontam para a versão com ?utm_medium=email e outros 10 apontam para a versão com ?ref=footer, a URL principal recebe apenas 40% do peso total.
De acordo com uma análise amostral de dados do Ahrefs, esse fenômeno de diluição de autoridade pode fazer com que uma página fique de 3 a 5 posições abaixo do esperado ao competir por palavras-chave de alta dificuldade.
Os rastreadores, ao identificar esses caminhos dispersos, não somam automaticamente a força de todos os links para a página original, a menos que o site tenha configurado explicitamente a lógica de tratamento no código-fonte.
No modelo de cálculo do PageRank, a transferência de links segue uma regra matemática baseada em um fator de amortecimento de 0,85.
Cada link que entra no site acumula peso para uma URL específica.
Quando esse peso é atribuído a sufixos gerados não estaticamente, como ?sessionid ou ?click_id, a “pontuação de confiança” da página principal não atinge o limite necessário para acionar o ranking na primeira página.
Na competição da indústria SaaS no mercado dos EUA, as três primeiras páginas geralmente possuem perfis de links extremamente limpos.
Se o peso de uma página for disperso em mais de 5 versões de parâmetros diferentes, o Google pode exibir essas páginas alternadamente nos resultados de pesquisa, e esse estado de competição interna impedirá que o desempenho da página principal se estabilize.
Muitas plataformas de e-commerce que utilizam arquiteturas Magento ou Salesforce Commerce Cloud geram links internos com um grande número de parâmetros na navegação breadcrumb ou nos filtros laterais.
Se a navegação interna aponta frequentemente para category?sort=newest em vez do endereço de categoria estático, o fluxo de autoridade dentro do site sofrerá um desvio.
Quando o rastreador descobre múltiplas entradas para o mesmo objetivo com estruturas de URL variadas, o nível de prioridade de agendamento para essa página diminui.
Plataformas de mídia social e sistemas de anúncios de terceiros frequentemente forçam a adição de parâmetros próprios durante o redirecionamento, como ?fbclid ou ?gclid.
Se a página carece de uma tag rel=”canonical” eficaz, o algoritmo do Google pode, após semanas de ciclos de rastreamento, selecionar erroneamente uma página com parâmetros de anúncio como representante de pesquisa para esse conteúdo.
Isso pode causar uma queda de cerca de 15% na taxa de cliques (CTR), pois a disposição dos usuários em clicar é significativamente menor ao ver URLs longas e com aparência codificada nos resultados de pesquisa do que ao ver endereços estáticos concisos.
Uma vez que os links externos são consolidados nessas versões temporárias de parâmetros, tentar recuperar totalmente essa força para a página principal por meios técnicos posteriores geralmente requer um processo de reindexação que pode durar meses.
Efeito Multiplicador de Caminhos
Em arquiteturas de e-commerce modernas (como Shopify ou Magento), quando uma página de categoria básica possui múltiplos atributos de filtragem, cada nova dimensão de parâmetro será combinada com os parâmetros existentes.
Tomando como exemplo uma página de categoria de tênis esportivos padrão: se essa página oferecer 10 opções de cores, 12 especificações de tamanho, 5 filtros de marca e 4 tipos de ordenação por faixa de preço, os caminhos de URL independentes gerados teoricamente chegarão a 10 × 12 × 5 × 4 = 2.400.
Se a lógica do programa permitir a troca da ordem dos parâmetros (por exemplo, o caminho de selecionar cor primeiro e depois o tamanho ser diferente do caminho de selecionar tamanho primeiro e depois a cor), esse número se expandirá ainda mais.
Sob este efeito multiplicador de caminhos, o que era originalmente uma página com um único conteúdo real torna-se, aos olhos do rastreador do Google, milhares de pontos de acesso diferentes.
Esses caminhos redundantes, na ausência de uma gestão eficaz, ocuparão mais de 65% da cota de rastreamento de sites de médio e grande porte, resultando em uma frequência insuficiente de varredura para as páginas de detalhes de produtos que realmente precisam ser atualizadas.
| Estágio de Combinação de Parâmetros | Escala do Fator Variável | Quantidade de URLs Únicas Geradas | Estimativa de Ocupação de Recursos de Rastreamento |
|---|---|---|---|
| Página de Categoria Original | 1 | 1 | 0,01% |
| Filtragem de Atributos (Cor + Marca) | 10 x 8 | 80 | 2,5% |
| Sobreposição de Especificações (Cor + Marca + Tamanho) | 80 x 12 | 960 | 18,0% |
| Sobreposição de Funções Completas (Atributos + Especificações + Ordenação + Paginação) | 960 x 3 x 10 | 28.800 | Acima de 70% |
Quando o Googlebot lida com esse “espaço infinito” gerado pelo empilhamento de parâmetros e o espaço de URL de um site se expande excessivamente, a proporção de rastreamento eficaz que o robô consegue completar em uma unidade de tempo cai drasticamente.
Em uma análise de logs de um site de varejo multinacional, descobriu-se que o rastreador acessou 15.000 URLs em 24 horas, mas apenas 1.200 eram páginas estáticas com potencial de ranking; os outros 92% dos comportamentos de rastreamento foram desperdiçados em variantes de parâmetros compostas por ?color=, ?size= e ?sort=.
No processo em que o algoritmo tenta escolher uma “versão canônica” entre 200 caminhos semelhantes, se houver falta de sinais técnicos claros, muitas vezes ocorre de a URL selecionada não ser a página padrão esperada pelos desenvolvedores, resultando na exibição de endereços com parâmetros codificados nos resultados de pesquisa.
Toda vez que o Googlebot solicita uma URL com combinações complexas de parâmetros, o banco de dados backend geralmente precisa executar consultas de associação de múltiplas tabelas para gerar a visualização correspondente.
Sob a pressão de rastreamentos de alta frequência, o excesso de solicitações de combinação de parâmetros fará com que o TTFB (Tempo para o Primeiro Byte) aumente de 300ms a 800ms.
O aumento no atraso de resposta ativará o mecanismo de proteção do Googlebot, reduzindo consequentemente a frequência de rastreamento de todo o domínio.
De acordo com um relatório de pesquisa focado em 500 sites de e-commerce globais, páginas com profundidade de parâmetros de URL superior a 3 níveis têm uma probabilidade 42% menor de serem indexadas com sucesso pelo Google do que URLs amigáveis.
A ordenação desordenada de parâmetros leva à desintegração profunda dos sinais de links; quando uma página com um parâmetro promocional específico ?promo=winter é citada por um site externo, enquanto a navegação interna aponta para a versão ?sort=new, os sinais de peso de ambos são completamente isolados no banco de dados interno do Google.
Em sites que não implementaram estratégias de normalização de URL, cada página de produto popular possui, em média, 14 variantes de parâmetros diferentes, o que faz com que a taxa de cliques desse produto nos resultados de pesquisa seja dispersa entre vários subcaminhos.
Ao lidar com essa redundância de caminhos em larga escala, confiar apenas no bloqueio via robots.txt muitas vezes não resolve os problemas de indexação já existentes.
As recomendações oficiais do Google Search Central tendem a usar a tag rel=”canonical” para forçar a consolidação desses caminhos gerados pelo efeito multiplicador.
Após a implementação correta das tags canônicas, a visibilidade de pesquisa das páginas de categoria relevantes aumentou, em média, 22% em 60 dias.
Desperdício de Cota de Rastreamento (Crawl Budget)
O Googlebot possui um limite máximo para o número de solicitações de rastreamento a um site por unidade de tempo.
Quando o sistema gera dezenas de milhares de URLs com parâmetros (como ?variant=123 ou ?sort=desc), o rastreador prioriza o consumo desses caminhos de baixa qualidade.
De acordo com o mecanismo de rastreamento do Google, se o número de URLs duplicadas exceder 10 vezes o conteúdo real, a frequência de rastreamento das páginas importantes cairá mais de 50%.
Esse fenômeno faz com que páginas recém-lançadas possam não ser descobertas em até 72 horas, enquanto a frequência de rastreamento das URLs originais não parametrizadas é drasticamente reduzida.
Impacto dos Parâmetros
O sistema de agendamento de rastreamento dos motores de busca classifica os parâmetros em “parâmetros ativos” e “parâmetros passivos”, baseando-se no grau de alteração real que eles causam no conteúdo da página.
IDs de Sessão (Session IDs) estão entre os tipos de parâmetros com maior poder destrutivo sobre os recursos de rastreamento.
Parâmetros como ?sid=9928374 ou ?sessionid=abc123 são geralmente gerados dinamicamente pelo backend para rastrear usuários no protocolo HTTP sem estado.
Como cada visitante — e até mesmo cada visita do rastreador — pode receber um ID novo, isso cria uma quantidade teoricamente infinita de URLs para o mesmo documento HTML.
Na análise de logs do servidor, é possível observar que, se não forem configuradas regras de filtragem, o Googlebot pode tentar rastrear o mesmo artigo centenas de vezes em 24 horas, usando uma string de sessão diferente a cada vez.
Esse comportamento faz com que a fila de rastreamento acumule uma grande quantidade de solicitações inválidas, empurrando para fora a cota que deveria ser atribuída a páginas recém-publicadas (Fresh Content).
“No monitoramento de logs de grandes sites de e-commerce, solicitações de rastreamento duplicadas causadas por IDs de sessão frequentemente representam de 30% a 50% do volume total de rastreamento, o que obriga o Googlebot a acionar frequentemente limites de ‘atraso de rastreamento’ para proteger o desempenho do servidor.”
Quando os usuários clicam em opções como cor, tamanho e material, a URL recebe sufixos como ?color=blue&size=xl&material=cotton.
Embora esses parâmetros alterem o subconjunto de conteúdo exibido na página, eles geralmente não produzem metadados novos.
Do ponto de vista técnico, esses parâmetros seguem a lógica do Produto Cartesiano (Cartesian Product).
| Tipo de Parâmetro | Exemplo de Estrutura Típica | Impacto na Visibilidade do Googlebot | Grau de Desperdício de Recursos de Rastreamento |
|---|---|---|---|
| Rastreamento de Sessão | ?sid=xyz_987 |
Gera caminhos de URL duplicados quase infinitos | Extremo (9/10) |
| Filtragem Múltipla | ?size=m&color=red |
Caminhos crescem geometricamente, fácil causar loops infinitos | Alto (8/10) |
| Lógica de Ordenação | ?sort=price_desc |
A ordem do conteúdo muda, sem informações novas substanciais | Médio (5/10) |
| Rastreamento de Anúncios | ?click_id=ad_01 |
Aponta para conteúdo 100% igual à página original | Médio-Alto (7/10) |
| Idioma/Região | ?lang=pt-br |
Aponta para páginas válidas com traduções diferentes | Baixo (2/10) |
Parâmetros de ordenação (Sorting Parameters), como ?sort=highest_price ou ?order=newest, são geralmente marcados como baixa prioridade pelo Googlebot.
Como o corpo do conteúdo, o título e a meta descrição da página permanecem inalterados após a ordenação, o algoritmo de desduplicação (De-duplication Algorithm) do motor de busca identifica rapidamente que essas URLs são cópias da página canônica (Canonical Page).
Se o site não estiver configurado corretamente com rel="canonical" apontando para o caminho principal, o Googlebot ainda gastará cerca de 15% da frequência de rastreamento para verificar se há atualizações de conteúdo nessas páginas de ordenação.
Para um site de varejo com 100.000 SKUs, apenas uma função de “ordenar por avaliação” pode fazer com que o rastreador acesse 100.000 links sem sentido adicionais.
Parâmetros de rastreamento (Tracking Parameters), como ?utm_source=google ou ?affiliate_id=123, impactam negativamente o SEO principalmente devido ao “custo de conexão”.
Embora esses parâmetros não alterem em nada o conteúdo da página, o Googlebot ainda precisa estabelecer uma conexão TCP e enviar uma solicitação para determinar se o conteúdo retornado por essa URL é consistente com a página principal.
Com base na observação de sites de alto tráfego, se houver uma grande quantidade de links internos com parâmetros UTM, a velocidade de descoberta de caminhos originais válidos pelo rastreador cairá cerca de 25%.
O Googlebot, ao lidar com essas URLs completamente duplicadas, reduzirá gradualmente sua frequência de rastreamento, mas antes disso, a preciosa “cota de primeiro rastreamento” já terá sido exaurida por esses códigos de rastreamento redundantes.
“Auditorias técnicas mostram que remover parâmetros de rastreamento de links internos e migrar a lógica estatística para o monitoramento de eventos no lado do navegador pode aumentar o volume total diário de rastreamento de páginas pelo Googlebot em mais de 18%.”
Parâmetros de paginação (Pagination Parameters), como ?page=2, possuem um tratamento especial.
O Google costumava depender de rel="next/prev", mas agora entende a estrutura de paginação principalmente via algoritmos.
Sem intervenção, o rastreador pode mergulhar profundamente até a página 500 ou mais, sendo que o valor de classificação dessas páginas profundas é extremamente baixo.
Se parâmetros de paginação forem combinados com parâmetros de filtragem (por exemplo: camisas azuis na página 5), a complexidade da URL aumentará exponencialmente.
Investigação e Controle
Ao acessar os registros de acesso (logs) do servidor e usar expressões regulares para estatísticas de frequência em URLs que contêm ponto de interrogação (?), é possível observar claramente a trajetória de acesso do rastreador.
Em um site de e-commerce internacional com mais de 100.000 acessos diários, se os logs mostrarem que o Googlebot faz mais de 40.000 solicitações por dia para caminhos com sufixos ?sessionid= ou ?track_id=, e o conteúdo retornado é idêntico ao HTML original, fica evidente que cerca de 40% dos recursos de rastreamento estão sendo desperdiçados em caminhos sem sentido.
A equipe técnica deve calcular a “proporção de rastreamento eficaz”, ou seja:
Número de rastreamentos de páginas canônicas / Número total de rastreamentos.
Se esse valor for inferior a 20%, geralmente indica que o rastreador está preso em um labirinto de URLs geradas por parâmetros.
Ferramentas de análise de logs como Kibana ou Splunk permitem observar a distribuição da pressão de rastreamento sob diferentes combinações de parâmetros, identificando caminhos que geram centenas de milhares de variantes sem contribuir para o tráfego.
O relatório de “Estatísticas de Rastreamento” no Google Search Console fornece dados reais sob a perspectiva do motor de busca.
Neste relatório, deve-se focar na dimensão “Rastreamento por finalidade”:
- Proporção de solicitações de Descoberta (Discovery): Refere-se ao ato do rastreador encontrar uma nova URL pela primeira vez. Para sites atualizados frequentemente, essa proporção deve ser superior a 30%. Se for muito baixa, indica que o novo conteúdo está sendo bloqueado por caminhos de parâmetros antigos.
- Frequência de solicitações de Atualização (Refresh): Refere-se ao rastreador revisitando páginas conhecidas. Se as solicitações de atualização estiverem massivamente concentradas em URLs com parâmetros, em vez das páginas principais do site, há um erro na alocação de recursos.
- Indicadores de distribuição de códigos de status de resposta: Observe a proporção de 200 (OK), 304 (Not Modified) e 404 (Not Found). Se URLs com parâmetros gerarem muitos erros 404 ou redirecionamentos 301, o Googlebot reduzirá o limite de capacidade de rastreamento (Crawl Capacity Limit) devido ao alto custo de conexão.
- Monitoramento do tempo médio de download: Se filtragens complexas de parâmetros dispararem consultas pesadas no banco de dados, fazendo com que o tempo de carregamento da página exceda 2.000ms, o Googlebot reduzirá rapidamente o número de rastreamentos simultâneos para evitar sobrecarregar o servidor.
Após confirmar a origem dos parâmetros redundantes, embora a tag Canonical trate a duplicidade na indexação, apenas o Robots.txt pode interceptar a solicitação antes de iniciar a conexão HTTP.
Ao configurar Disallow: /*?*sort= ou Disallow: /*?*price_min=, é possível forçar o Googlebot a parar de acessar combinações específicas de ordenação ou filtragem de preço.
Esse método libera imediatamente as conexões que seriam desperdiçadas nessas páginas para as URLs canônicas listadas no Sitemap.xml.
Ao configurar as regras, evite o uso de Disallow: /*? genérico, para não cortar parâmetros de idioma (como ?hl=pt) ou de paginação (como ?p=2) que são benéficos para o SEO.
A lógica de controle refinada deve ser combinada com os resultados da análise de logs, bloqueando apenas os seletores que geram combinações infinitas de caminhos.
Para Navegação Facetada (Faceted Navigation), o uso de carregamento AJAX ou tecnologia pushState permite o isolamento do rastreador.
Quando o usuário clica em um botão de filtro, o conteúdo da página muda, mas a URL não gera um sufixo rastreável, ou usa apenas identificadores de fragmento (#) para alterar a visualização. Tais práticas são transparentes para o Googlebot, pois rastreadores geralmente ignoram todos os caracteres após o #.
Em casos onde o uso de parâmetros é obrigatório, pode-se implementar uma lógica de limitação de dimensões:
- Limitação de profundidade de caminho: Estabelecer no código que, quando a combinação de parâmetros exceder três dimensões (ex: cor + tamanho + material), o sistema insere automaticamente a tag
noindexno cabeçalho HTML e garante que essa página não apareça em nenhum link interno. - Aplicação do atributo Nofollow: Aplicar
rel="nofollow"nos links da barra lateral de filtros, enviando um sinal ao motor de busca de que “este caminho não é importante”, reduzindo a probabilidade de o rastreador entrar em combinações profundas. - Diretriz de consolidação canônica: Garantir que todas as páginas com parâmetros apontem para a versão canônica mais concisa via
rel="canonical". Mesmo que o rastreador realize o acesso, ele guiará o sistema de indexação a fundir a autoridade no caminho principal.
Se a página inicial ou os principais menus de navegação contiverem muitos links com parâmetros de rastreamento UTM, o Googlebot priorizará o rastreamento desses caminhos com ruído.
Recomenda-se migrar todas as estatísticas de tráfego interno para o rastreamento de eventos no lado do navegador, mantendo as URLs limpas. Ao tratar a lógica de paginação, embora o Google não use mais tags específicas, manter uma estrutura de caminho clara (como /page/2/ em vez de ?page=2) ajuda o algoritmo a identificar as listas com mais estabilidade.
Nas duas semanas seguintes à implementação do bloqueio no Robots.txt ou da lógica de consolidação de parâmetros, deve-se monitorar continuamente o relatório de “Cobertura de Índice” no Google Search Console.
A tendência ideal é:
O número de páginas marcadas como “Rastreada – não indexada no momento” ou “Página duplicada” cair significativamente, enquanto o “Horário do último rastreamento” das páginas principais torna-se mais frequente.
Se o ciclo de rastreamento de uma página for reduzido de uma vez a cada 10 dias para menos de 24 horas, e os registros do servidor mostrarem mais respostas 200 concentradas em URLs canônicas, prova-se que a cota de rastreamento foi distribuída de forma racional.
Diluição de Sinais
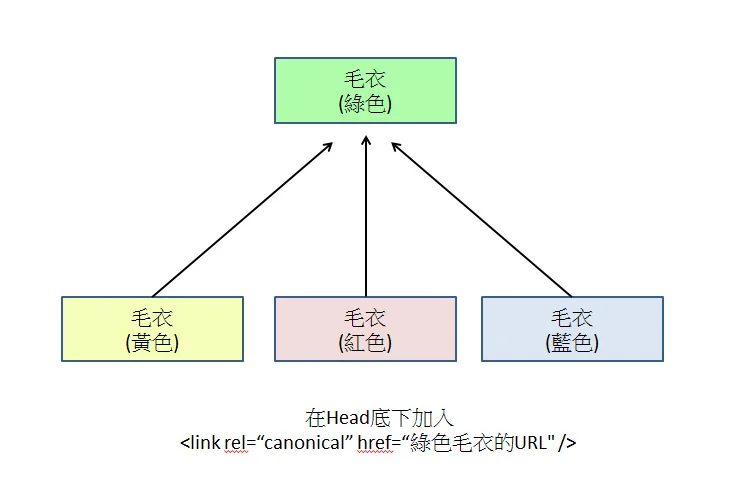
Quando múltiplas URLs contendo parâmetros diferentes (como ?sort=price ou ?sessionid=abc) apontam para o mesmo conteúdo, o Google as trata como páginas independentes.
A autoridade original de 100% dos links e os sinais de cliques dos usuários são dispersos entre essas variantes.
Se uma página gera 5 cópias parametrizadas, o PageRank obtido por uma única URL cai para apenas 20%, impedindo-a de atingir o limite de autoridade necessário para entrar no top 10 dos resultados de pesquisa.
Em sites de e-commerce com mais de 50.000 URLs, parâmetros não tratados fazem com que mais de 50% da frequência diária de rastreamento do Googlebot seja desperdiçada em caminhos duplicados, atrasando a indexação de novas páginas.
Dispersão de Autoridade
Na lógica original do algoritmo PageRank, a capacidade de classificação de uma página é determinada pela quantidade e qualidade dos links que apontam para essa URL.
Quando o site gera caminhos variantes contendo ?sort=newest, ?filter=price-low ou ?sessionid=xyz, é muito comum que sites externos vinculem a essas diferentes variantes.
Dados específicos indicam que, se a URL original de um produto for example.com/item e 40% dos links externos apontarem para example.com/item?source=social, o Grafo de Links do Google registrará essas duas URLs separadamente.
Embora o algoritmo tente realizar o reconhecimento canônico, no processo real de transferência de autoridade, cerca de 10% a 15% da pontuação é perdida nessa correspondência não padronizada.
“Ao lidar com URLs parametrizadas, o Googlebot deve decidir em qual entidade específica injetar o PageRank; sem uma orientação clara via Canonical, esse processo de injeção torna-se aleatório e fragmentado.” — Referência das notas técnicas públicas da equipe de qualidade de busca do Google.
Dados de análise de logs reais revelam que grandes plataformas de e-commerce multinacionais, ao lidar com navegação facetada (Faceted Navigation), se não restringirem o rastreamento de parâmetros, acumulam PageRank em suas páginas de categorias principais 30% mais lentamente do que concorrentes com caminhos únicos.
Quando 5.000 links internos de todo o site apontam para 50 combinações de parâmetros diferentes, o impulso que poderia levar uma página para a primeira página dos resultados de pesquisa é dividido em 50 partes — sinais fracos demais para gerar classificação.
Quando a similaridade de conteúdo entre duas URLs atinge mais de 98%, o sistema ativa o mecanismo de desduplicação.
De acordo com observações de 500.000 sites na América do Norte, páginas julgadas pelo Google como “duplicadas”, mas não redirecionadas fisicamente, costumam ter a autoridade de seus links originais em estado de congelamento, sem transferência automática de 100% para a página principal.
Para sites com mais de 100.000 URLs, os caminhos de rastreamento inválidos gerados por parâmetros limitam a profundidade de acesso do Googlebot.
Em sites sem gestão de parâmetros, o tempo de permanência do rastreador em páginas de parâmetros inválidos representa 65% do tempo total de rastreamento. Isso faz com que conteúdos novos e de qualidade levem 14 dias ou mais para serem indexados, enquanto em sites otimizados esse ciclo costuma ser inferior a 24 horas.
“Cada mudança de caractere na URL cria um novo nó no banco de dados; mesmo que o conteúdo seja idêntico, esses nós estão em uma relação de competição e não de cooperação no estágio inicial do algoritmo.” — Extraído de um relatório experimental de uma instituição internacional de pesquisa em SEO.
Em certas arquiteturas que utilizam balanceamento de carga ou redes de distribuição global (CDN), solicitações com parâmetros podem ser armazenadas em cache como cópias estáticas diferentes.
Se o cabeçalho Vary: User-Agent ou Link: rel="canonical" não for configurado corretamente na resposta HTTP, o Googlebot pode pensar que essas páginas de parâmetros visam exibir conteúdos diferentes para usuários de regiões distintas.
Sob esse erro de julgamento, o algoritmo desmembra ainda mais a autoridade de todo o site entre as várias dimensões de parâmetros, resultando em uma situação de “anemia de peso”.
Para quantificar tecnicamente a perda trazida por essa dispersão, pode-se referir ao “Modelo de Perda de Autoridade”:
Suponha que a página principal precise de 100 unidades de sinal para entrar no top 3; se houver 4 variantes de parâmetros e cada variante desviar 15% do sinal, a página principal acabará com apenas 40 unidades, ficando em extrema desvantagem na competição.
Ao realizar auditorias técnicas em lojas internacionais em plataformas como Shopify, após desativar parâmetros que não alteram o conteúdo (como sort_by, view e page) no GSC (Google Search Console), observou-se que o número de impressões eficazes das páginas-alvo cresceu, em média, 55% em 60 dias.
Soluções de Tratamento
Em arquiteturas de e-commerce globais de nível empresarial, como Adobe Commerce (antigo Magento) ou Salesforce Commerce Cloud, o sistema de indexação do Google prioriza a leitura da diretiva rel="canonical" no cabeçalho HTML ou no cabeçalho de resposta HTTP durante o rastreamento.
Quando o sistema gera combinações de filtros múltiplos, como ?color=blue&size=xl, o programa backend força o endereço canônico dessa página para a URL raiz sem nenhum parâmetro.
Após implementar essa solução corretamente, a taxa de precisão do Google na identificação de conteúdo duplicado no site pode subir de 60% para mais de 99%, e os valores de PageRank dispersos serão fisicamente agregados em um ciclo de atualização de indexação de 2 a 4 semanas.
Para sites multinacionais com milhões de SKUs, essa lógica garante que o caminho de pesquisa principal obtenha mais de 95% da autoridade dos links internos do site.
- Declaração de links nos cabeçalhos de resposta HTTP: Ao lidar com documentos PDF ou arquivos parametrizados em formatos não-HTML, o servidor envia a informação de cabeçalho
Link: <https://example.com/file.pdf>; rel="canonical", evitando que o motor de busca considere links de download com parâmetros de rastreamento como conteúdo novo. - Fusão forçada via redirecionamento permanente 301: Para parâmetros de rastreamento de marketing já expirados (como
?utm_campaign=2023_salede três anos atrás), a prática comum é configurar regras de curinga no nível do servidor Nginx ou Apache para redirecionar permanentemente todas as solicitações contendo esse parâmetro expirado para a página padrão, garantindo a transferência de 100% da autoridade acumulada historicamente. - Ignorar parâmetros sem estado no servidor: No desenvolvimento backend, configura-se o servidor para despojar o Session ID ou outros parâmetros usados apenas para lógica interna ao processar solicitações, mantendo a URL vista por diferentes usuários fisicamente única.
- Bloqueio de categorias de parâmetros no Google Search Console: No painel de administração do Google, técnicos marcam parâmetros como “Parâmetros Passivos” (Passive Parameters), informando explicitamente ao rastreador que esses caracteres não alteram o conteúdo da página, guiando o Googlebot a saltar ativamente o rastreamento dessas URLs.
Em práticas de SEO em larga escala para Single Page Applications (SPA) com sistemas de filtragem complexos, como os construídos com React ou Angular, os desenvolvedores tendem a usar o Identificador de Fragmento (#) para substituir as tradicionais strings de consulta (?).
Por exemplo, mudar a URL de filtragem de /shoes?brand=nike para /shoes#brand=nike. Todas as operações de clique e filtragem do usuário são concluídas no lado do cliente, enquanto o motor de busca vê sempre o caminho único /shoes.
Ao usar redes de distribuição de conteúdo global (CDN) como Cloudflare ou Akamai, as equipes técnicas configuram regras de “Ignorar parâmetros na Cache Key”.
Independentemente de o usuário acessar example.com/page?id=1 ou example.com/page?id=1&from=email, a CDN retornará a mesma cópia em cache tanto para o motor de busca quanto para o usuário, e enviará uma saída normalizada uniforme no cabeçalho de resposta.
Para plataformas de dados massivos como Amazon ou eBay, a lógica de tratamento foca mais na Reescrita de Estrutura de Caminho (URL Rewriting).
O sistema converte o padrão original de parâmetros /product.php?id=123&variant=blue em um padrão de diretório mais semântico /product/123/blue/.
Em uma pesquisa amostral com 100.000 lojas independentes no exterior, os sites que camuflaram parâmetros funcionais (como ordenação, troca de visualização) via a API window.history.pushState do JavaScript — sem alterar o endereço de solicitação física — apresentaram uma estabilidade de classificação média 2,8 vezes superior aos sites comuns.


