




















GSC URL निरीक्षण
Search Console में URL दर्ज करें, “क्रॉल किया गया पेज देखें” पर क्लिक करें, HTML सोर्स कोड की तुलना करें और पुष्टि करें कि क्या रेंडरिंग के बाद मुख्य सामग्री गायब हो जाती है।
टेक्स्ट अंतर तुलना
“सोर्स कोड देखें” और “तत्वों का निरीक्षण करें” के बीच टेक्स्ट कैरेक्टर की संख्या की तुलना करें। जब टेक्स्ट अंतर दर > 20% होती है, तो इंडेक्सिंग का बहुत अधिक जोखिम होता है।
Rich Results Test
स्क्रीनशॉट देखने के लिए Google के रिच रिजल्ट टेस्ट टूल का उपयोग करें और सुनिश्चित करें कि पहले फोल्ड की मुख्य सामग्री 5-सेकंड के रेंडरिंग विंडो के भीतर पूरी तरह से लोड हो गई है।
Google आधिकारिक उपकरण
Google Search Console (GSC) का URL निरीक्षण टूल Googlebot की लाइव क्रॉलिंग स्थिति तक पहुँचने का प्रवेश द्वार है।
“लाइव URL का परीक्षण करें” के माध्यम से, आप 60-90 सेकंड के भीतर पूर्ण DOM संरचना उत्पन्न करने के लिए WRS (वेब रेंडरिंग सर्विस) को कॉल कर सकते हैं।
GSC रेंडर किया गया HTML, स्क्रीनशॉट और संसाधन लोडिंग सूची प्रदान करता है।
वर्तमान में Googlebot नवीनतम Chrome स्थिर संस्करण कर्नेल का उपयोग करता है, लेकिन एकल पृष्ठ पर स्क्रिप्ट निष्पादन के लिए लगभग 5 सेकंड की सीमा निर्धारित है।
“रिच रिजल्ट टेस्ट” के साथ मिलकर, आप मूल प्रतिक्रिया और अंतिम रेंडरिंग परिणाम के बीच बाइट अंतर की तुलना कर सकते हैं, और Robots.txt द्वारा ब्लॉक की गई 403 या 404 स्क्रिप्ट लोडिंग विफलता समस्याओं की पहचान कर सकते हैं।
Google Search Console
Google Search Console के साइडबार नेविगेशन में, एक विशिष्ट URL दर्ज करने के बाद, सिस्टम Google इंडेक्स डेटाबेस से नवीनतम क्रॉल किए गए डेटा स्नैपशॉट को प्राप्त करेगा।
यदि पेज की स्थिति “URL Google पर है” दिखाती है, तो आप देख सकते हैं कि क्रॉलिंग के समय क्या कोई HTML पार्सिंग त्रुटि या मोबाइल अनुकूलन समस्या थी।
JavaScript रेंडरिंग के कारण होने वाली सामग्री की कमी की गहराई से जांच करने के लिए, आपको “लाइव URL का परीक्षण करें” बटन पर क्लिक करना होगा।
यह क्रिया WRS (वेब रेंडरिंग सर्विस) को नवीनतम स्थिर Chromium कर्नेल पर आधारित एक हेडलेस ब्राउज़र लॉन्च करने के लिए ट्रिगर करेगी, ताकि लक्ष्य पृष्ठ पर रीयल-टाइम विज़िट की जा सके।
रेंडरिंग करते समय, WRS व्यूपोर्ट चौड़ाई को 1280 पिक्सेल पर सेट करता है और मोबाइल-फर्स्ट क्रॉलिंग रणनीति अपनाता है।
“रेंडर किया गया पेज देखें” पैनल में, HTML टैब स्क्रिप्ट चलने के बाद की पूरी DOM संरचना दिखाता है।
तकनीकी कर्मियों को यहां प्रदर्शित HTML कोड लाइनों या वर्णों की मात्रा की तुलना ब्राउज़र में राइट-क्लिक करके देखे गए “पेज सोर्स देखें” (मूल सर्वर प्रतिक्रिया) के साथ करनी चाहिए।
यदि मूल HTML केवल 2KB है, और रेंडर किया गया HTML 50KB तक बढ़ जाता है, तो इसका मतलब है कि यह पेज क्लाइंट-साइड रेंडरिंग पर बहुत अधिक निर्भर है।
यदि रेंडर किए गए HTML में मुख्य टेक्स्ट सामग्री या उत्पाद सूची टैग की कमी है, तो इसे रेंडरिंग विफलता माना जाता है।
Googlebot एक पेज के स्क्रिप्ट निष्पादन के लिए सीमित कंप्यूटिंग संसाधन आवंटित करता है। हालांकि आधिकारिक तौर पर कोई पूर्ण समय सीमा नहीं दी गई है, लेकिन कई प्रयोगों से पता चलता है कि यदि सामग्री लोड होने का समय 5 सेकंड से अधिक हो जाता है, तो इंडेक्सिंग चरण के दौरान उस डेटा के छूट जाने की संभावना काफी बढ़ जाती है।
“Googlebot JavaScript के सभी एसिंक्रोनस कार्यों को पूरा करने के लिए अनिश्चित काल तक प्रतीक्षा नहीं करता है। इसका रेंडरिंग बजट पेज लोड गति, सर्वर प्रतिक्रिया विलंब (TTFB) और स्क्रिप्ट पार्सिंग जटिलता द्वारा सीमित होता है। यदि API प्रतिक्रिया समय 2000 मिलीसेकंड से अधिक हो जाता है, तो रेंडरिंग स्नैपशॉट बनने के क्षण में सामग्री अक्सर Loading स्थिति में ही रह जाती है।”
“अधिक जानकारी” टैब के तहत “पेज संसाधन” सूची में, लोड होने में विफल रही सभी JS और CSS फाइलें सूचीबद्ध होंगी।
स्टेटस कोड 403 या 404 स्पष्ट रूप से सर्वर अनुमति कॉन्फ़िगरेशन त्रुटि या संसाधन पथ की विफलता की ओर इशारा करते हैं, लेकिन सबसे महत्वपूर्ण स्थिति “Robots.txt द्वारा ब्लॉक” है।
चूंकि कई सिंगल पेज एप्लिकेशन (SPA) रूटिंग लॉजिक और डेटा रेंडरिंग लॉजिक को विशिष्ट स्क्रिप्ट फाइलों में रखते हैं, यदि वेबसाइट की /robots.txt फ़ाइल में Disallow: /assets/ या समान नियम हैं, जिसके कारण Googlebot मुख्य स्क्रिप्ट प्राप्त नहीं कर पाता है, तो WRS एक पूर्ण DOM ट्री नहीं बना पाएगा।
इसका परिणाम यह होता है कि भले ही उपयोगकर्ता ब्राउज़र में पेज को पूरा देखते हैं, लेकिन सर्च इंजन की दृष्टि में, वह पेज केवल एक खाली स्थान या केवल एक बुनियादी ढांचा हो सकता है।
स्क्रिप्ट त्रुटियों की जांच के लिए, “JavaScript कंसोल संदेश” क्षेत्र पर ध्यान केंद्रित किया जाना चाहिए।
यहाँ WRS द्वारा कोड निष्पादित करते समय आने वाली त्रुटियाँ रिकॉर्ड की जाएंगी।
यदि विकास टीम ने ऐसी ES6+ नई विशेषताओं का उपयोग किया है जिनमें Polyfill प्रसंस्करण नहीं है (जैसे BigInt, ResizeObserver, आदि), और क्रॉलिंग के समय संबंधित Chromium संस्करण कुछ गैर-मानक API के साथ पूरी तरह से संगत नहीं था, तो कंसोल में Uncaught ReferenceError या SyntaxError दिखाई देगा।
इस प्रकार की त्रुटि पूरी स्क्रिप्ट पार्सिंग प्रक्रिया में बाधा डालती है, और बाद के सभी सामग्री इंजेक्शन लॉजिक विफल हो जाते हैं।
त्रुटि लॉग में उल्लिखित विशिष्ट लाइन नंबर और फ़ाइल नाम को देखकर, आप सटीक रूप से पता लगा सकते हैं कि कौन सी लाइब्रेरी फ़ाइल या व्यावसायिक लॉजिक ब्लॉक क्रॉलिंग में बाधा डाल रहा है।
रेंडरिंग के बाद का “स्क्रीनशॉट” एक अन्य मात्रात्मक पहचान पद्धति है।
उदाहरण के लिए, कुछ स्क्रिप्ट गतिशील रूप से तत्वों की ऊंचाई या पारदर्शिता की गणना करती हैं। यदि स्क्रीनशॉट पेज पर बड़े खाली स्थान दिखाता है, भले ही HTML टैग में टेक्स्ट मौजूद हो, Google एल्गोरिदम उस पेज को उपयोगकर्ता के अनुकूल नहीं मान सकता है, जिससे इंडेक्सिंग प्राथमिकता कम हो सकती है।
अत्यधिक गतिशील साइटों के साथ काम करते समय, यह सुनिश्चित करना आवश्यक है कि पहले फोल्ड (Above the Fold) की सभी सामग्री 2 सेकंड के भीतर रेंडर हो जानी चाहिए।
रिच रिजल्ट टेस्ट
रिच रिजल्ट टेस्ट टूल Google द्वारा प्रदान किया गया एक सार्वजनिक परीक्षण वातावरण है। Search Console के विपरीत, जिसमें साइट स्वामित्व सत्यापन की आवश्यकता होती है, यह टूल किसी को भी इंटरनेट पर किसी भी URL या पेस्ट किए गए कोड स्निपेट का विश्लेषण करने की अनुमति देता है।
URL दर्ज करने और परीक्षण शुरू करने के बाद, प्रणाली नवीनतम स्थिर Chromium कर्नेल पर आधारित एक हेडलेस ब्राउज़र लॉन्च करेगी, जो Googlebot स्मार्टफोन या Googlebot डेस्कटॉप के व्यवहार का अनुकरण करेगा।
React, Angular या Vue.js जैसे JavaScript फ्रेमवर्क पर आधारित सिंगल पेज एप्लिकेशन (SPA) के लिए, इस टूल द्वारा प्रदान किया गया “परीक्षण किया गया पेज देखें” फीचर यह तय करने का मानक है कि सामग्री सफलतापूर्वक DOM ट्री में प्रवेश कर गई है या नहीं।
चूंकि Googlebot स्क्रिप्ट के प्रसंस्करण में संसाधन आवंटन की सीमा रखता है, यदि पेज को प्रारंभिक चरण में बड़ी संख्या में गणनाओं की आवश्यकता होती है या 20 से अधिक एसिंक्रोनस API अनुरोध शुरू होते हैं, तो WRS स्क्रिप्ट निष्पादन समाप्त होने से पहले ही HTML क्रॉलिंग को रोक सकता है।
रीयल-टाइम जांच करते समय, सिस्टम एक रेंडर किए गए HTML का स्नैपशॉट तैयार करेगा।
इस स्नैपशॉट के माध्यम से, तकनीकी कर्मी मूल सर्वर द्वारा लौटाए गए बाइट्स और अंतिम रेंडर किए गए बाइट्स के बीच अंतर की सटीक तुलना कर सकते हैं।
उदाहरण के लिए, एक शुद्ध क्लाइंट-साइड रेंडरिंग (CSR) पेज के मूल HTML में अक्सर 5KB से कम का बुनियादी टेम्पलेट कोड होता है। यदि इस टूल के माध्यम से रेंडर किया गया HTML 100KB से ऊपर पहुँच जाता है, तो इसका मतलब है कि Googlebot ने सफलतापूर्वक स्क्रिप्ट निष्पादित की और गतिशील सामग्री प्राप्त की।
इसके विपरीत, यदि रेंडर किया गया HTML अभी भी 5KB के आसपास रहता है और इसमें मुख्य सामग्री टैग नहीं होते हैं, तो यह दर्शाता है कि WRS स्तर पर स्क्रिप्ट निष्पादन बाधित हुआ था।
Google का रेंडरिंग इंजन एकल संसाधनों के डाउनलोड के लिए सख्त टाइमआउट तंत्र सेट करता है, आमतौर पर एकल JS फ़ाइल का लोडिंग समय 2000 मिलीसेकंड से अधिक नहीं होना चाहिए।
यदि पेज द्वारा संदर्भित तृतीय-पक्ष लाइब्रेरी या API प्रतिक्रिया बहुत धीमी है, तो परीक्षण परिणामों में “पेज संसाधन” टैब संबंधित लोडिंग विफलता स्थिति को चिह्नित करेगा।
- कोड स्निपेट टेस्ट मोड: अप्रकाशित HTML कोड लॉजिक को पेस्ट करने का समर्थन करता है। यह स्टेजिंग वातावरण के दौरान यह जांचने के लिए महत्वपूर्ण है कि क्या JS रेंडरिंग लॉजिक क्रॉलिंग विनिर्देशों का अनुपालन करता है। इस तरह, कोड को मुख्य शाखा में मर्ज करने से पहले, आप मात्रात्मक रूप से जांच सकते हैं कि क्या गतिशील रूप से उत्पन्न स्कीमा मार्कअप सही ढंग से पार्स किया जा सकता है।
- User-Agent सिमुलेशन स्विचिंग: हालांकि मोबाइल क्रॉलिंग डिफ़ॉल्ट रूप से उपयोग की जाती है, जटिल रिस्पॉन्सिव लॉजिक वाली कुछ साइटों के साथ काम करते समय, डेस्कटॉप डिवाइस सिमुलेशन पर स्विच करने से JS निष्पादन क्रम पर CSS लोडिंग प्राथमिकता के प्रभाव का पता चल सकता है।
- रेंडरिंग स्नैपशॉट तुलना: सिस्टम द्वारा प्रदान किया गया स्क्रीनशॉट न केवल दृश्य संदर्भ है, बल्कि यह निर्णय लेने का आधार भी है कि क्या पेज पर “सामग्री शिफ्ट” या “लेआउट जिटर” हो रहा है, क्योंकि बड़े लेआउट परिवर्तन के कारण Googlebot पेज की उपयोगिता का गलत अनुमान लगा सकता है।
“रिच रिजल्ट टेस्ट न केवल स्ट्रक्चर्ड डेटा को सत्यापित कर सकता है, बल्कि गतिशील सामग्री की दृश्यता की जांच करने के लिए एक प्रयोगशाला भी है। यदि पेज पर टेक्स्ट JS के माध्यम से एसिंक्रोनस रूप से लोड किया गया है, तो ‘परीक्षण किया गया पेज देखें’ में उस टेक्स्ट को खोजना SEO इंडेक्सिंग सफलता दर को सत्यापित करने का सबसे तेज़ तरीका है।”
जब पेज में स्क्रिप्ट के माध्यम से इंजेक्ट किए गए JSON-LD या माइक्रोडेटा (Microdata) होते हैं, तो यह टूल रेंडर किए गए DOM से इस स्ट्रक्चर्ड जानकारी को निकालेगा।
यदि कोड में सिंटैक्स त्रुटि है, या JS त्रुटि के कारण स्कीमा मार्कअप इंजेक्शन से पहले स्क्रिप्ट रुक जाती है, तो टूल “रिच रिजल्ट नहीं मिले” का संकेत देगा।
ई-कॉमर्स वेबसाइटों या समीक्षा साइटों के साथ काम करते समय यह विशेष रूप से महत्वपूर्ण है, क्योंकि Google को इंडेक्स करते समय कीमत, स्टॉक स्थिति और रेटिंग जैसे विशिष्ट गुणों को पहचानने की आवश्यकता होती है।
यदि ये गुण “परीक्षण किए गए पेज” के HTML में गायब हैं, भले ही फ्रंट-एंड पेज सामान्य रूप से प्रदर्शित हो, सर्च इंजन परिणाम पृष्ठ (SERP) स्टार रेटिंग या कीमत का पूर्वावलोकन नहीं दिखाएगा।
कंसोल त्रुटि लॉग पर विशेष ध्यान दिया जाना चाहिए, क्योंकि WRS वातावरण में मेमोरी उपयोग की सीमाएं सामान्य उपयोगकर्ता के ब्राउज़र की तुलना में अधिक सख्त होती हैं।
यदि स्क्रिप्ट बहुत अधिक CPU संसाधनों का उपयोग करती है, तो Googlebot उस पेज की रेंडरिंग को छोड़ सकता है, जिससे इंडेक्स में केवल एक खाली शेल टेम्पलेट रह जाता है।
- लोड किए गए संसाधनों की कुल संख्या: एक ही पेज द्वारा अनुरोधित JS संसाधनों को 50 के भीतर रखने की सिफारिश की जाती है। बहुत अधिक समानांतर अनुरोध WRS शेड्यूलिंग में देरी पैदा करेंगे और रेंडरिंग विफलता का जोखिम बढ़ाएंगे।
- स्क्रिप्ट निष्पादन त्रुटि निगरानी: टूल
ReferenceErrorयाTypeErrorजैसी घातक विसंगतियों को पकड़ेगा जो रेंडरिंग श्रृंखला को तोड़ सकती हैं। यदि आप Polyfill की कमी के कारण ES मानक असंगति त्रुटि देखते हैं, तो आपको तुरंत बिल्ड टूल के संकलन लक्ष्य को समायोजित करना चाहिए। - API प्रतिक्रिया वैधता: संसाधन सूची के माध्यम से गतिशील रूप से खींची गई सामग्री के सभी API एंडपॉइंट्स की जाँच करें। यदि स्थिति कोड “ब्लॉक” या “टाइमआउट” दिखाता है, तो इसका मतलब है कि Googlebot को फ़ायरवॉल द्वारा रोका गया है या API प्रदर्शन क्रॉलिंग सीमा को पूरा नहीं कर सकता है।
इस परीक्षण टूल द्वारा उत्पन्न रिपोर्ट में प्रत्येक “चेतावनी” या “त्रुटि” वास्तविक इंडेक्सिंग वातावरण में Googlebot के व्यवहार के अनुरूप होती है।
यदि टूल संकेत देता है कि “कुछ स्क्रिप्ट लोड नहीं की जा सकीं”, भले ही वे स्क्रिप्ट सामान्य उपयोगकर्ता के Chrome ब्राउज़र में ठीक से काम करती हों, तो भी इस पर ध्यान दिया जाना चाहिए। इसका कारण यह हो सकता है कि Googlebot का IP रेंज इन संसाधनों तक पहुँचते समय सर्वर द्वारा रेट लिमिटिंग (Rate Limiting) का सामना कर रहा है।
Chrome DevTools
स्थानीय विकास वातावरण में, Chrome DevTools में “नेटवर्क स्थितियाँ” (Network conditions) पैनल Googlebot के क्रॉलिंग व्यवहार का अनुकरण करने का शुरुआती बिंदु है।
F12 दबाकर या राइट-क्लिक करके “निरीक्षण करें” चुनकर टूलबार खोलें, और ऊपरी दाएं कोने में तीन डॉट्स वाले मेनू से More tools -> Network conditions पर जाएँ।
इस पैनल में, “ब्राउज़र डिफ़ॉल्ट सेटिंग्स का उपयोग करें” (Use browser default) को अनचेक करें और ड्रॉप-डाउन सूची से मैन्युअल रूप से Googlebot चुनें।
यह क्रिया ब्राउज़र द्वारा भेजे गए User-Agent स्ट्रिंग को बदल देगी, उदाहरण के लिए इसे Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) में बदल देगी।
इस चरण का कार्य यह जाँचना है कि क्या सर्वर में क्रॉलर के लिए कोई विशेष लॉजिक है।
यदि सर्वर को UA के आधार पर अलग-अलग HTML कोड लौटाने के लिए कॉन्फ़िगर किया गया है, तो स्थानीय वातावरण तुरंत सामान्य उपयोगकर्ता की विज़िट से बहुत अलग परिणाम दिखाएगा।
तकनीकी कर्मियों को इस समय रिस्पॉन्स हेडर जानकारी की तुलना करनी चाहिए और यह जांचना चाहिए कि क्या Content-Type या कैश कंट्रोल निर्देश (Cache-Control) बदल गए हैं।
यदि सर्वर Googlebot के लिए 403 एक्सेस अस्वीकृत या 301 अनपेक्षित रीडायरेक्ट लौटाता है, तो इसका मतलब है कि सर्वर स्तर पर ही सर्च इंजन का इंडेक्सिंग पथ अवरुद्ध कर दिया गया है।
Googlebot के “प्रथम तरंग इंडेक्सिंग” (First-wave indexing) का अनुकरण करने के लिए, आपको JavaScript अक्षम होने की स्थिति में पेज के प्रदर्शन का परीक्षण करना होगा।
DevTools के सेटिंग पेज (Settings) पर जाएँ, प्राथमिकता सेटिंग्स में डिबगर (Debugger) अनुभाग खोजें और “JavaScript अक्षम करें” (Disable JavaScript) को चेक करें।
पेज को रिफ्रेश करने के बाद, ब्राउज़र केवल सर्वर द्वारा भेजे गए मूल HTML ढांचे को ही प्रदर्शित करेगा।
सिंगल पेज एप्लिकेशन (SPA) आर्किटेक्चर का उपयोग करने वाली साइटों के लिए, यह क्रिया अक्सर पेज को पूरी तरह से खाली कर देती है या केवल Loading एनीमेशन दिखाती है।
यदि स्क्रिप्ट अक्षम करने के बाद पेज की मुख्य टेक्स्ट जानकारी, नेविगेशन मेनू या उत्पाद सूची पूरी तरह से गायब हो जाती है, तो इसका मतलब है कि सर्च इंजन को सामग्री प्राप्त करने के लिए जटिल “द्वितीय तरंग इंडेक्सिंग” यानी WRS रेंडरिंग चरण में प्रवेश करना होगा।
इस समय, आपको मूल HTML के बाइट्स को रिकॉर्ड करना चाहिए, जैसे कि 15KB का बुनियादी ढांचा कोड, और सामग्री के पैमाने को निर्धारित करने के लिए पूर्ण रेंडर किए गए DOM के साथ तुलना करनी चाहिए।
“स्थानीय सिमुलेशन वातावरण में, JavaScript को अक्षम करना सबसे महत्वपूर्ण स्ट्रेस टेस्ट है। यदि किसी पेज के मूल HTML में मुख्य सिमेंटिक जानकारी वाले H1 टैग या मुख्य पैराग्राफ की कमी है, तो नेटवर्क उतार-चढ़ाव या Google रेंडरिंग कोटा की कमी होने पर उस पेज के खाली पेज के रूप में इंडेक्स होने का जोखिम बहुत अधिक होता है।”
Googlebot जिस वातावरण में चलता है वह उच्च प्रदर्शन वाला डेस्कटॉप कंप्यूटर नहीं है। DevTools में “प्रदर्शन” (Performance) पैनल का उपयोग करके, आप Googlebot की कंप्यूटिंग क्षमता का अधिक वास्तविकता से अनुकरण कर सकते हैं।
प्रदर्शन सेटिंग्स में, CPU थ्रॉटलिंग (CPU Throttling) को 4x या 6x स्लोडाउन पर समायोजित करें।
यदि एक उच्च प्रदर्शन वाले MacBook पर केवल 800 मिलीसेकंड में पूरा होने वाला रेंडरिंग कार्य 6 गुना स्लोडाउन के तहत 5500 मिलीसेकंड तक बढ़ जाता है, तो यह पहले से ही Googlebot की सामान्य 5-सेकंड की रेंडरिंग सीमा को छू चुका है।
फ्लेम चार्ट में लंबे कार्यों (Long Tasks) को देखकर, आप यह पहचान सकते हैं कि किन विशाल JS लाइब्रेरीज़ ने मुख्य थ्रेड को ब्लॉक किया है, जिससे रेंडरिंग में देरी हो रही है।
यदि इस वातावरण में कुल ब्लॉकिंग समय (TBT) जैसे मात्रात्मक संकेतक 2000 मिलीसेकंड से अधिक हो जाते हैं, तो यह आमतौर पर संकेत देता है कि Googlebot सामग्री पूरी तरह से उत्पन्न होने से पहले प्रतीक्षा करना छोड़ सकता है और वर्तमान अपूर्ण DOM स्नैपशॉट को क्रॉल कर सकता है।
ब्राउज़र मैनुअल सत्यापन
मैन्युअल सत्यापन रेंडरिंग स्थिति की पुष्टि करने के लिए प्रारंभिक HTML और रेंडर किए गए DOM के बीच डेटा अंतर की तुलना करता है।
Googlebot नवीनतम Chrome रेंडरिंग इंजन का उपयोग करता है, लेकिन यदि JS निष्पादन 5-सेकंड की सीमा से अधिक हो जाता है या एकल पेज संसाधन अनुरोध 50 से अधिक हो जाते हैं, तो सामग्री इंडेक्स नहीं हो पाएगी।
मैन्युअल परीक्षण के दौरान संसाधन लोडिंग श्रृंखला पर ध्यान देना चाहिए, यह सुनिश्चित करते हुए कि <a> टैग का href विशेषता HTML सोर्स कोड में पहले से मौजूद हो, न कि onclick इवेंट के माध्यम से गतिशील रूप से उत्पन्न हो, ताकि क्रॉलर पथ की निरंतरता सुनिश्चित हो सके।
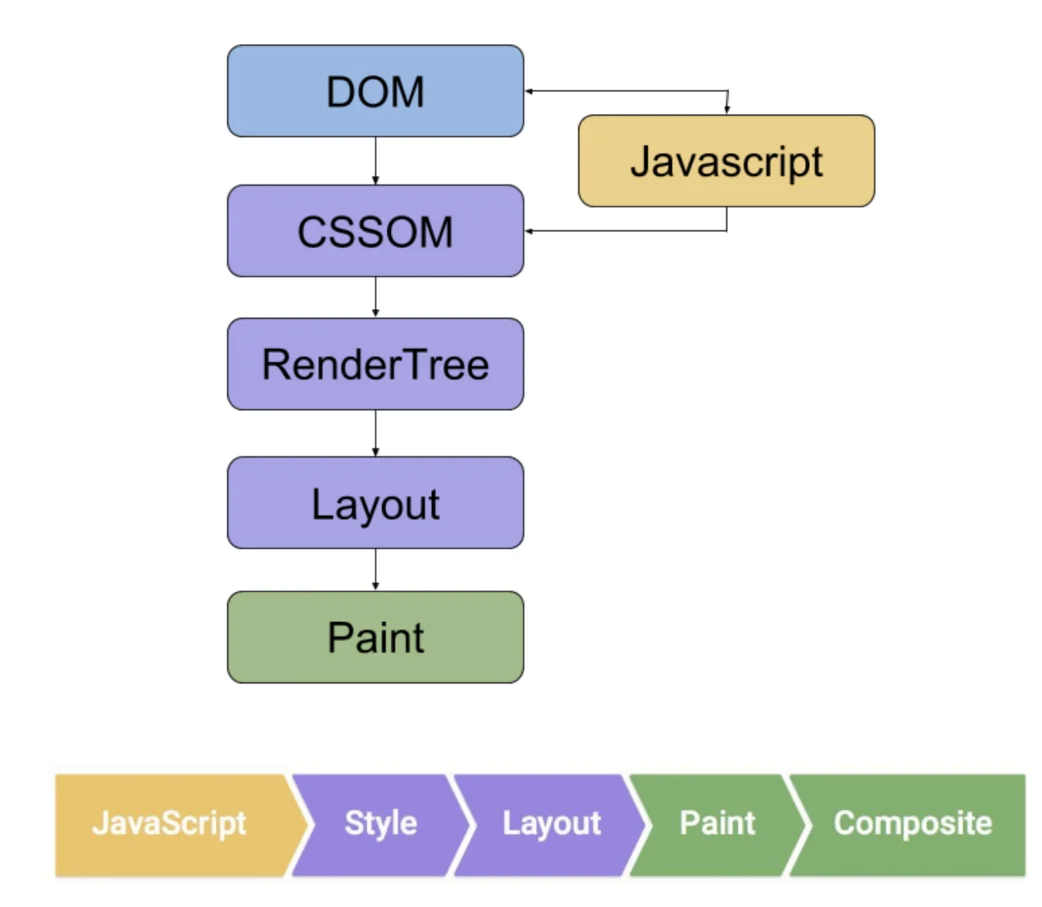
सोर्स कोड और रीयल-टाइम DOM
ब्राउज़र में view-source के माध्यम से देखा गया कोड सर्वर द्वारा भेजे गए मूल टेक्स्ट स्ट्रीम को दर्शाता है, जबकि डेवलपर टूल का Elements पैनल रेंडरिंग इंजन द्वारा पार्स किए गए, स्क्रिप्ट निष्पादित और त्रुटि-सुधार के बाद मेमोरी ऑब्जेक्ट मॉडल (DOM) को प्रदर्शित करता है।
सिंगल पेज एप्लिकेशन (SPA) आर्किटेक्चर वाली साइटों के लिए, मूल सोर्स कोड में अक्सर केवल id="app" या id="root" वाला एक खाली कंटेनर टैग और 500KB से अधिक आकार के कई स्क्रिप्ट संदर्भ होते हैं।
सोर्स कोड में शुद्ध टेक्स्ट कैरेक्टर की संख्या की तुलना रेंडर किए गए DOM में टेक्स्ट कैरेक्टर की संख्या से करें। जब यह अनुपात 1:20 से अधिक हो जाता है (यानी मूल HTML में केवल 100 शब्द हैं और रेंडरिंग के बाद 2000 शब्द हो जाते हैं), तो सर्च इंजन की पहली तरंग क्रॉलिंग लगभग किसी भी प्रभावी सिमेंटिक जानकारी को प्राप्त करने में विफल रहती है।
यह अंतर पेज को इंडेक्सिंग के शुरुआती चरण में सामग्री शून्य स्थिति में रखता है, और इसे रेंडरिंग कतार के माध्यमिक प्रसंस्करण की प्रतीक्षा करनी पड़ती है।
| तुलना आयाम | प्रारंभिक HTML डेटा विशेषताएं | रेंडर किया गया DOM डेटा विशेषताएं | इंडेक्सिंग पर तकनीकी प्रभाव |
|---|---|---|---|
| कुल DOM नोड्स | आमतौर पर 50 से कम नोड्स, संरचना अत्यंत सपाट। | 1500 से अधिक नोड्स संभव, पदानुक्रम गहराई में वृद्धि। | नोड्स में भारी वृद्धि दर्शाती है कि सामग्री पूरी तरह JS पर निर्भर है। |
| मेटा टैग स्थिति | सामान्य शीर्षक या हार्ड-कोडेड प्लेसहोल्डर विवरण। | स्क्रिप्ट द्वारा इंजेक्ट किए गए विशिष्ट पेज SEO टैग। | क्रॉलर स्क्रिप्ट चलने से पहले गलत मेटाडेटा रिकॉर्ड कर सकता है। |
| Canonical टैग | गायब या साइट के होमपेज URL पर स्थिर। | वर्तमान पेज के मानक पूर्ण पथ पर गतिशील रूप से अपडेटेड। | टैग में विसंगति से सर्च इंजन पेज गुणों को लेकर भ्रमित हो सकता है। |
| JSON-LD स्ट्रक्चर्ड डेटा | कोड स्निपेट खाली या केवल बुनियादी स्कीमा ढांचा। | पूर्ण उत्पाद मूल्य, समीक्षा या स्टॉक डेटा भरा हुआ। | यह निर्धारित करता है कि SERP रिच स्निपेट दिखाएगा या नहीं। |
| आंतरिक लिंक (Internal Links) | नेविगेशन बार खाली हो सकता है, लिंक अभी उत्पन्न नहीं हुए। | पूर्ण <a> टैग और गतिशील श्रेणी पथ शामिल। |
साइट के भीतर अन्य गहरे URL खोजने की क्रॉलर की दक्षता को प्रभावित करता है। |
गहरी तुलना करते समय, कंसोल में document.body.innerText.length दर्ज करके वर्तमान रेंडर किए गए कुल वर्णों की संख्या प्राप्त की जा सकती है, और इसकी तुलना सोर्स कोड फ़ाइल के बाइट आकार से की जा सकती है।
यदि सोर्स कोड का आकार 30KB है, लेकिन रेंडर किए गए innerText में 15,000 वर्ण हैं, तो प्रमुख टेक्स्ट वेट रेंडरिंग लेयर पर केंद्रित है।
इस समय, यदि स्क्रिप्ट में 200ms से अधिक समय लेने वाला कोई रिकर्सिव फंक्शन है, या लोड होने में 2.0s से अधिक समय लेने वाला कोई बाहरी API संदर्भित है, तो Googlebot का रेंडरिंग इंजन सामग्री पूरी तरह से इंजेक्ट होने से पहले रिकॉर्डिंग बंद कर सकता है।
| मात्रात्मक संकेतक | जोखिम सीमा | क्रॉलिंग और इंडेक्सिंग का वास्तविक परिणाम |
|---|---|---|
| कोड टेक्स्ट अंतर दर (Text Ratio Gap) | > 80% टेक्स्ट JS द्वारा उत्पन्न | बिना स्क्रिप्ट के पेज के “पतली सामग्री” (Thin Content) माने जाने का उच्च जोखिम। |
| लिंक निष्कर्षण सफलता दर | सोर्स में वैध <a> टैग < 5 |
क्रॉल बजट अंतहीन प्रतीक्षा में बर्बाद हो जाएगा। |
| स्क्रिप्ट निष्पादन मेमोरी उपयोग | 50MB से अधिक स्टैक मेमोरी खपत | रेंडरिंग सर्वर मेमोरी सीमा के कारण रेंडरिंग कार्य को जबरन समाप्त कर सकता है। |
| पहले फोल्ड की HTML पूर्णता | सोर्स में < 10% मुख्य विजुअल सामग्री दृश्य | धीमे नेटवर्क पर उपयोगकर्ताओं को लंबे समय तक सफेद स्क्रीन दिखेगी, जिससे रैंकिंग संकेतों को नुकसान होगा। |
Elements पैनल में नेविगेशन मेनू की जाँच करें, यदि लिंक <a href="javascript:void(0)" onclick="navigateTo('/page')"> के रूप में दिखाई देता है, तो हालांकि यह रेंडर किए गए DOM में लिंक जैसा दिखता है, सर्च इंजन क्रॉलर के लिए यह एक डेड एंड (बंद गली) है जिसका पीछा नहीं किया जा सकता।
मानक href विशेषता सर्वर द्वारा लौटाए गए मूल HTML में पहले से मौजूद होनी चाहिए, या स्क्रिप्ट चलने के बाद मानक <a href="/target-path"> प्रारूप में उत्पन्न होनी चाहिए।
पूर्ण मूल HTML लिंक संरचना वाली साइटों के नए पृष्ठों को इंडेक्स करने की गति अक्सर पूरी तरह से JS इंजेक्शन लिंक पर निर्भर साइटों की तुलना में 40% से 70% तेज़ होती है।
यदि सोर्स कोड में noindex मेटा टैग मौजूद है, और स्क्रिप्ट लॉजिक रेंडरिंग के बाद इसे हटाकर index से बदलने की कोशिश करता है, तो यह अभ्यास अक्सर अप्रभावी होता है।
सर्च इंजन आमतौर पर प्रारंभिक HTML में मिले निर्देशों का पालन करने को प्राथमिकता देते हैं, जिससे पेज सामान्य इंडेक्सिंग प्रक्रिया में प्रवेश नहीं कर पाता है।
पर्यावरण सिमुलेशन सत्यापन
Chrome ब्राउज़र में डेवलपर टूल (DevTools) खोलें, कमांड मेनू लाने के लिए Ctrl+Shift+P दबाएँ, Disable JavaScript दर्ज करें और एंटर दबाएँ। यह सर्च इंजन की पहली क्रॉल स्थिति का अनुकरण करने का शुरुआती बिंदु है।
स्क्रिप्ट अक्षम होने पर पेज को फिर से लोड करें। यदि इस समय स्क्रीन खाली दिखाई देती है या केवल एक बुनियादी ढांचा है, तो इसका मतलब है कि सर्वर-साइड प्रारंभिक HTML में कोई वास्तविक टेक्स्ट सामग्री नहीं है।
100KB की HTML फ़ाइल के लिए, यदि इसकी 90% टेक्स्ट सामग्री बाद में लोड होने वाले 2MB JavaScript पैकेज पर निर्भर है, तो नेटवर्क विलंब या स्क्रिप्ट त्रुटि होने पर सर्च इंजन केवल एक खाली कंटेनर टैग रिकॉर्ड कर सकता है।
| सिमुलेशन पैरामीटर | सेटिंग मानक और मान | अवलोकन परिणाम और डेटा संकेतक |
|---|---|---|
| नेटवर्क थ्रॉटलिंग (Network Throttling) | Fast 3G (1.5 Mbps डाउनलोड, 40ms विलंब) | यदि मुख्य सामग्री रेंडरिंग समय 5000ms (5 सेकंड) से अधिक है, तो Google रेंडरिंग कतार प्रतीक्षा करना बंद कर सकती है। |
| CPU सीमा (CPU Throttling) | 4x slowdown (मोबाइल प्रोसेसर प्रदर्शन) | जब स्क्रिप्ट मूल्यांकन (Script Evaluation) का समय 1.5 सेकंड से अधिक हो जाता है, तो मुख्य थ्रेड का लंबे समय तक कब्जा सामग्री रेंडरिंग में देरी का कारण बनता है। |
| User-Agent सिमुलेशन | Googlebot Smartphone (Chrome/W.X.Y.Z) | जाँच करें कि क्या सर्वर 403 त्रुटि या विशिष्ट मोबाइल अनुकूलन कोड लौटाता है। |
| व्यूपोर्ट आकार (Viewport) | 411 x 731 पिक्सेल (मानक मोबाइल चौड़ाई) | पुष्टि करें कि क्या सामग्री क्लिक या स्लाइड जैसी बातचीत के बिना स्वचालित रूप से लोड होती है। |
ब्राउज़र के User-Agent स्ट्रिंग को बदलकर Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html) कर दें।
Network पैनल में Disable cache को चेक करें और Googlebot पहचान के तहत संसाधन लोडिंग श्रृंखला का निरीक्षण करें।
एक मानक क्रॉलिंग प्रक्रिया में, Googlebot आमतौर पर सभी मीडिया फ़ाइलों को लोड नहीं करता है; यह टेक्स्ट और स्ट्रक्चर्ड डेटा को पार्स करने को प्राथमिकता देता है।
यदि पेज स्क्रिप्ट के माध्यम से User-Agent का पता लगाता है और अलग लॉजिक लागू करता है (जैसे क्रॉलर के लिए कुछ एसिंक्रोनस इंटरफेस बंद करना), तो Elements पैनल में DOM संरचना सामान्य उपयोगकर्ताओं द्वारा देखी गई संरचना से पूरी तरह अलग होगी।
Network पैनल में मैन्युअल रूप से नेटवर्क गति को Fast 3G पर सेट करें और CPU प्रदर्शन को 4x slowdown तक सीमित करें।
Googlebot के रेंडरिंग सर्वर के पास दुनिया भर के अरबों पृष्ठों को संसाधित करते समय एकल पृष्ठ के लिए सीमित कंप्यूटिंग संसाधन होते हैं। Performance पैनल के माध्यम से लोडिंग प्रक्रिया को रिकॉर्ड करें और Main थ्रेड की गतिविधि पर ध्यान केंद्रित करें।
यदि Evaluate Script द्वारा उत्पन्न लंबे कार्य (Long Tasks) 50 मिलीसेकंड से अधिक हैं और कुल लोडिंग चक्र का 70% से अधिक हिस्सा लेते हैं, तो वास्तविक क्रॉलिंग वातावरण में रेंडरिंग इंजन सामग्री पूरी तरह भरने से पहले ही स्नैपशॉट रिकॉर्ड कर सकता है।
यदि First Contentful Paint (FCP) और Largest Contentful Paint (LCP) के बीच का अंतराल JS निष्पादन के कारण 3 सेकंड से अधिक बढ़ जाता है, तो सर्च इंजन द्वारा अधूरे पेज को क्रॉल करने की संभावना लगभग 40% बढ़ जाती है।
डेवलपर टूल के नीचे Sensors टैब का उपयोग करके मैन्युअल रूप से विभिन्न भौगोलिक स्थानों (जैसे सैन फ्रांसिस्को या लंदन) का अनुकरण करें।
Googlebot के क्रॉलिंग नोड्स मुख्य रूप से संयुक्त राज्य अमेरिका में स्थित हैं। यदि वेबसाइट के JS लॉजिक में IP पते के आधार पर स्वचालित रीडायरेक्ट या स्थानीय टाइमस्टैम्प के आधार पर सामग्री उत्पन्न करने का लॉजिक है, तो यह क्रॉल किए गए पेज के संस्करण को लक्षित दर्शकों के क्षेत्र के संस्करण से अलग कर सकता है।
Console पैनल में त्रुटि संदेशों की जाँच करें, विशेष रूप से ReferenceError या TypeError।
हालांकि Google रेंडरिंग इंजन (Evergreen Googlebot) का संस्करण अपडेट रहता है, लेकिन यह बहुत नए वेब API (जैसे नवीनतम WebGPU या WebAssembly के विशिष्ट संस्करण) के लिए समर्थन में भिन्न हो सकता है।
यदि कोड में Polyfill संगतता प्रसंस्करण सही ढंग से नहीं किया गया है, तो स्क्रिप्ट निष्पादन के बीच में क्रैश हो जाएगी, जिससे DOM ट्री का निर्माण रुक जाएगा।
- अनुरोध संख्या सीमा: रेंडरिंग पूरा होने से पहले पेज द्वारा भेजे गए कुल नेटवर्क अनुरोधों की गणना करें। यदि एक पेज 50 से अधिक JS या CSS संसाधनों का अनुरोध करता है, तो ब्राउज़र की समानांतर सीमाओं और क्रॉलर के संसाधन कोटा के कारण कुछ स्क्रिप्ट समय पर लोड नहीं हो सकती हैं।
- Shadow DOM स्थिति: Elements पैनल में जाँच करें कि क्या
#shadow-root (closed)मार्क मौजूद है। Googlebot Open मोड के Shadow DOM को पार्स कर सकता है, लेकिन Closed मोड की सामग्री क्रॉलर के लिए अदृश्य है। सुनिश्चित करें कि सभी Web Components Open स्थिति में हैं। - लिंक प्रारूप सत्यापन: रेंडर किए गए DOM में,
<aटैग खोजने के लिएCtrl+Fका उपयोग करें। सुनिश्चित करें कि सभी जंप लिंक में पूर्णhrefविशेषता है। यदि जंपwindow.location.hrefयाrouter.pushजैसे JS इवेंट के माध्यम से नियंत्रित किया जाता है और HTML में कोई मानक एंकर नहीं छोड़ा गया है, तो सर्च इंजन इन उप-पृष्ठों को नहीं खोज पाएगा। - छवि लेज़ी लोड (Image Lazy Load): जाँच करें कि क्या
<img>टैग ने पेज को स्क्रॉल किए बिनाdata-srcकी सामग्री कोsrcविशेषता से बदल दिया है। Googlebot आंशिक स्क्रॉलिंग का अनुकरण कर सकता है, लेकिन जटिलscrollइवेंट लिस्टनर्स पर निर्भर स्क्रिप्ट के लिए इसकी क्रॉलिंग दक्षता स्थिर नहीं है। मानकloading="lazy"विशेषता का उपयोग करना अधिक सुरक्षित तरीका है।
प्रारंभिक HTML और रेंडर किए गए DOM के बाइट आकार और टेक्स्ट नोड्स की संख्या की तुलना करें।
यदि दोनों के बीच टेक्स्ट कवरेज का अंतर 80% से अधिक है, और अधिकांश टेक्स्ट सामग्री DOMContentLoaded इवेंट के बाद ही इंजेक्ट की गई है, तो इसका मतलब है कि साइट का SEO पूरी तरह से रेंडरिंग दक्षता पर निर्भर है।
परीक्षण के दौरान Total Blocking Time (TBT) रिकॉर्ड करने की सिफारिश की जाती है। यदि यह मान 300ms से अधिक है, तो यह आमतौर पर इंगित करता है कि स्क्रिप्ट निष्पादन प्रक्रिया क्रॉलर द्वारा DOM पार्सिंग में बाधा डालेगी।
Chrome के Coverage पैनल के माध्यम से JS फ़ाइलों की उपयोग दर देखें। यदि 500KB की स्क्रिप्ट का 80% कोड पहले फोल्ड के लोड होने के दौरान निष्पादित नहीं होता है, तो यह अनावश्यक कोड रेंडरिंग सर्वर की कंप्यूटिंग शक्ति को बर्बाद कर देगा, जिससे सामग्री की इंडेक्सिंग गति प्रभावित होगी।
व्यावसायिक क्रॉलर उपकरण
व्यावसायिक क्रॉलर उपकरण Chrome वातावरण का अनुकरण कर सकते हैं (जैसे Screaming Frog v20+)।
डेटा से पता चलता है कि स्क्रिप्ट निष्पादित करने की क्रॉलिंग लागत स्थिर HTML की तुलना में 20 गुना अधिक है।
जब “रेंडरिंग से पहले” और “रेंडरिंग के बाद” के HTML शब्दों की संख्या में 10% से अधिक का अंतर होता है, या आंतरिक लिंक पहचान में 5% से अधिक का अंतर होता है, तो इंडेक्सिंग सफलता दर आमतौर पर गिर जाती है।
जांच में 5 सेकंड के भीतर रेंडरिंग पूर्णता दर पर ध्यान देना चाहिए, और क्या 403 स्टेटस कोड के कारण स्क्रिप्ट लोडिंग विफलता हुई है।
Screaming Frog SEO Spider
Screaming Frog के साथ बड़े पैमाने पर क्रॉलिंग करते समय, रेंडरिंग मोड को “केवल टेक्स्ट (Text Only)” से “JavaScript” पर स्विच करने से क्रॉलर का व्यवहार सरल HTTP अनुरोध से पूर्ण ब्राउज़र सिमुलेशन में बदल जाएगा।
सॉफ्टवेयर वेब पेज पर प्रत्येक स्क्रिप्ट फ़ाइल को पार्स करने के लिए अंतर्निहित Headless Chrome इंस्टेंस लॉन्च करेगा।
तकनीकी कॉन्फ़िगरेशन में, उपयोगकर्ताओं को Configuration > Spider > Rendering मेनू में स्पष्ट रूप से JavaScript विकल्प चुनना होगा।
डेटा स्तर पर परिवर्तन बहुत महत्वपूर्ण हैं। JavaScript निष्पादित करने की क्रॉलिंग प्रक्रिया के लिए मेमोरी (RAM) की आवश्यकता आमतौर पर 5 से 10 गुना बढ़ जाती है।
उदाहरण के लिए, जटिल React या Angular फ्रेमवर्क वाले 100,000 पृष्ठों को क्रॉल करते समय, सॉफ्टवेयर को कम से कम 16GB से 32GB RAM आवंटित करने की सिफारिश की जाती है, अन्यथा संसाधनों की कमी के कारण Chrome रेंडरिंग प्रक्रिया क्रैश हो सकती है।
क्रॉलर चलते समय Chrome के रेंडरिंग इंजन संस्करण का अनुकरण करेगा, यह सुनिश्चित करते हुए कि क्रॉल की गई DOM संरचना Googlebot द्वारा उपयोग किए जा रहे “Evergreen Chrome” के अनुरूप है।
| संकेतक श्रेणी | मूल HTML (Source) | रेंडर किया गया HTML (Rendered) | अंतर सीमा सुझाव |
|---|---|---|---|
| शब्द संख्या (Word Count) | केवल बुनियादी ढांचा और मेटाडेटा | एसिंक्रोनस रूप से लोड टेक्स्ट शामिल | अंतर > 15% होने पर मैन्युअल समीक्षा आवश्यक |
| आंतरिक लिंक संख्या (Internal Links) | 0 या बहुत कम प्लेसहोल्डर लिंक | गतिशील रूप से उत्पन्न नेविगेशन और उत्पाद लिंक | अंतर > 0 क्रॉलिंग जोखिम का संकेत देता है |
| Canonical टैग | गायब या डिफ़ॉल्ट मान पर | JS के माध्यम से संशोधित अंतिम संस्करण | रेंडर किए गए संस्करण को ही मानक माना जाना चाहिए |
| पेज आकार (Size) | आमतौर पर < 50 KB | 500 KB – 2 MB तक बढ़ सकता है | बहुत बड़ा आकार Google द्वारा काटे जाने का कारण बन सकता है |
जब सॉफ्टवेयर स्क्रिप्ट निष्पादित करता है, तो AJAX Timeout (एसिंक्रोनस लोडिंग टाइमआउट) डिफ़ॉल्ट सेटिंग आमतौर पर 5 सेकंड होती है, जो स्क्रिप्ट को संभालने की Googlebot की रणनीति के समान है।
यदि किसी पेज का डेटा इंटरफेस प्रतिक्रिया देने में धीमा है, जिसके कारण सामग्री 5 सेकंड के बाद DOM में भरी जाती है, तो Screaming Frog द्वारा क्रॉल किया गया परिणाम एक “खाली शेल” पेज होगा।
Word Count कॉलम के डेटा की तुलना करके इस घटना को मात्रात्मक रूप से देखा जा सकता है:
यदि रेंडर किए गए शब्दों की संख्या सोर्स कोड शब्दों की संख्या से कम है, या दोनों पूरी तरह से समान हैं लेकिन पेज पर वास्तव में बहुत सारे टेक्स्ट हैं, तो यह आमतौर पर इंगित करता है कि रेंडरिंग स्क्रिप्ट निर्धारित समय के भीतर निष्पादन पूरा करने में विफल रही।
ई-कॉमर्स वेबसाइटों के परीक्षण में, यदि उत्पाद सूची गतिशील स्क्रॉलिंग के माध्यम से लोड की जाती है, तो क्रॉलर “Window Size” को कॉन्फ़िगर करके या स्क्रिप्ट निष्पादन को ट्रिगर करने के लिए नीचे की ओर स्क्रॉल करने का अनुकरण करके उन उत्पाद जानकारियों को क्रॉल कर सकता है जो मूल रूप से छिपी हुई थीं।
बड़ी साइटों के तकनीकी ऑडिट के लिए, “Bulk Export” फंक्शन में “JavaScript Rendering Table” का उपयोग करके पूरी साइट की रेंडरिंग अंतर रिपोर्ट निर्यात की जा सकती है।
यह रिपोर्ट रेंडरिंग से पहले और बाद में प्रत्येक URL के Title, Meta Description और H1 टैग में परिवर्तनों को पंक्ति दर पंक्ति सूचीबद्ध करेगी।
वास्तविक मामलों में, यदि रेंडर किया गया H1 टैग “Loading…” या “Undefined” में बदल जाता है, तो यह साबित करता है कि सर्च इंजन ने अंतिम सामग्री के बजाय मध्यवर्ती स्थिति कोड क्रॉल किया है।
सॉफ्टवेयर का “Resource” टैब प्रत्येक स्क्रिप्ट फ़ाइल (.js) और स्टाइलशीट (.css) के HTTP स्टेटस कोड को रिकॉर्ड करेगा।
यदि कुछ कार्यात्मक स्क्रिप्ट 403 Forbidden लौटाती हैं, तो यह आमतौर पर इसलिए होता है क्योंकि सर्वर के फ़ायरवॉल (WAF) ने क्रॉलर के Headless Chrome व्यवहार को दुर्भावनापूर्ण हमले के रूप में पहचान लिया और उसे ब्लॉक कर दिया, जिससे पूरे पेज का लेआउट और सामग्री सामान्य रूप से प्रदर्शित नहीं हो पाएगी।
| रेंडरिंग संसाधन स्थिति | कारण | क्रॉलिंग पर प्रभाव |
|---|---|---|
| Robots.txt द्वारा ब्लॉक | स्क्रिप्ट पथ Disallow पर सेट | Googlebot स्क्रिप्ट नहीं पढ़ सकता, रेंडरिंग विफल |
| Status Code: 429 | उच्च अनुरोध आवृत्ति से रेट लिमिट ट्रिगर | पेज के संसाधन पूरी तरह लोड नहीं, सामग्री गायब |
| Status Code: 404 | स्क्रिप्ट फ़ाइल पथ अमान्य | उस स्क्रिप्ट पर निर्भर गतिशील घटक प्रदर्शित नहीं |
| Timeout (5 सेकंड से अधिक) | धीमी प्रतिक्रिया या जटिल स्क्रिप्ट लॉजिक | क्रॉल किया गया HTML खाली या त्रुटि संदेश युक्त |
सॉफ्टवेयर द्वारा प्रदान किया गया “Rendered Page” व्यू उपयोगकर्ताओं को मूल कोड स्नैपशॉट और रेंडर किए गए विज़ुअल स्नैपशॉट की साथ-साथ तुलना करने की अनुमति देता है।
इस तरह, उन सामग्रियों को आसानी से खोजा जा सकता है जो JavaScript द्वारा छिपाई गई हैं, जैसे कि टैब विकल्पों के भीतर का टेक्स्ट जो क्लिक करने के बाद ही दिखाई देता है।
यदि किसी पेज की टेक्स्ट सामग्री मूल HTML में 20% से कम है और 80% सामग्री रेंडरिंग पर निर्भर है, तो Google इंडेक्स में उस पेज की स्थिरता को चुनौती का सामना करना पड़ेगा।
Screaming Frog कंसोल त्रुटियों (Console Errors) को भी पकड़ सकता है। यदि पेज लोडिंग के दौरान घातक JavaScript सिंटैक्स त्रुटियां उत्पन्न करता है, तो सॉफ्टवेयर रिपोर्ट में उन्हें हाइलाइट करेगा।
लाखों URL के साथ काम करते समय, “Store Images” और “Store Rendered HTML” विकल्पों को सक्षम करने की सिफारिश की जाती है, जो क्रॉलिंग समाप्त होने के बाद किसी भी समय किसी भी पेज के रेंडरिंग स्नैपशॉट को प्राप्त करने की अनुमति देते हैं।
“Link Discovery” अंतर का विश्लेषण करके, आप यह गणना कर सकते हैं कि आंतरिक लिंक का कितना प्रतिशत स्क्रिप्ट चलाने के बाद ही खोजा जा सकता है।
यदि यह अनुपात 30% से अधिक है, तो स्क्रिप्ट निष्पादन में देरी के कारण वेबसाइट की क्रॉल गहराई (Crawl Depth) अनियंत्रित हो सकती है।
Lumar (DeepCrawl)
Lumar वितरित क्लाउड कंप्यूटिंग शक्ति का उपयोग करता है और विशेष रूप से लाखों URL वाली बड़ी साइटों के लिए स्वचालित स्कैनिंग प्रदान करता है।
JavaScript निष्पादन की आवश्यकता वाले कार्यों को संसाधित करते समय, यह हजारों सिम्युलेटेड ब्राउज़र इंस्टेंस के माध्यम से बैकग्राउंड में चलता है।
पारंपरिक स्थानीय उपकरण भौतिक मेमोरी द्वारा सीमित होते हैं; उदाहरण के लिए, 32GB RAM वाला कंप्यूटर रेंडरिंग मोड चलाते समय आमतौर पर केवल 20 से 50 समानांतर थ्रेड्स का समर्थन कर सकता है।
इसके विपरीत, Lumar क्लाउड सर्वर पर चलता है और कार्य के पैमाने के आधार पर स्वचालित रूप से 500 से अधिक थ्रेड्स तक विस्तार कर सकता है, यह सुनिश्चित करते हुए कि 10 लाख पृष्ठों की पूर्ण रेंडरिंग क्रॉलिंग 24 घंटों के भीतर पूरी हो जाए।
यदि किसी पेज का स्क्रिप्ट निष्पादन 5000 मिलीसेकंड (यानी 5 सेकंड) से अधिक समय लेता है, तो सिस्टम उस URL को “उच्च लागत वाला पेज” चिह्नित करेगा, क्योंकि वास्तविक विज़िट में Googlebot आमतौर पर एकल संसाधन के लिए बहुत अधिक प्रतीक्षा नहीं करता है, जिससे इंडेक्स में सामग्री खाली रह सकती है।
एक मानक React या Vue प्रोजेक्ट में, मूल HTML में केवल 2KB से 5KB का बुनियादी ढांचा कोड हो सकता है, जबकि रेंडर किया गया DOM ट्री 300KB से 800KB तक फैल सकता है।
बाइट्स में यह 100 गुना से अधिक की वृद्धि दर्शाती है कि पेज स्क्रिप्ट पर बहुत अधिक निर्भर है।
Lumar द्वारा प्रदान किए गए संकेतकों में कुल DOM नोड्स (DOM Node Count) शामिल है। यदि नोड्स की संख्या Google द्वारा अनुशंसित 1500 से अधिक हो जाती है, तो रेंडरिंग दक्षता काफी कम हो जाएगी।
क्लाउड में Time to Interactive (इंटरैक्टिव होने का समय) और Total Blocking Time (कुल ब्लॉकिंग समय) रिकॉर्ड करके, यह टूल पहचान सकता है कि कौन सी JS फ़ाइलें (जैसे 500KB से बड़ी एकल vendor.js फ़ाइल) सामग्री के सामान्य प्रदर्शन में बाधा डाल रही हैं।
बड़े ई-कॉमर्स या बहुराष्ट्रीय साइटों के लिए, विभिन्न क्षेत्रों के सर्वर नोड्स से अनुरोध शुरू करके यह पता लगाया जा सकता है कि क्या सामग्री रेंडर करने वाली कुछ स्क्रिप्ट CDN गलत कॉन्फ़िगरेशन के कारण विशिष्ट क्षेत्रों में लोड होने में विफल हो रही हैं।
डेटा रिपोर्ट में 4xx और 5xx स्टेटस कोड वाले स्क्रिप्ट संसाधनों का अनुपात सूचीबद्ध होगा।
यदि किसी पेज के 20% स्क्रिप्ट अनुरोध 403 त्रुटि लौटाते हैं (आमतौर पर robots.txt अवरोधन या फ़ायरवॉल ब्लॉक के कारण), तो उस पेज का रेंडरिंग परिणाम अधूरा होगा।
Lumar की रिपोर्टिंग प्रणाली एक “रेंडरिंग अंतर मानचित्र” तैयार करेगी, जो JavaScript चालू और बंद होने की स्थिति में पेज के भीतर आंतरिक लिंक की संख्या में परिवर्तन को विस्तार से चिह्नित करेगा।
यदि स्क्रिप्ट बंद करने के बाद पेज पर लिंक की संख्या 200 से घटकर 0 हो जाती है, तो इसका मतलब है कि साइट की एड्रेसिंग संरचना पूरी तरह से गतिशील निष्पादन पर निर्भर है, जिसका Googlebot द्वारा नए पृष्ठों की खोज की गति पर नकारात्मक प्रभाव पड़ता है।
यह प्लेटफ़ॉर्म क्रॉल किए गए रेंडरिंग डेटा को Google Search Console के API के साथ एकीकृत करने का भी समर्थन करता है।
यदि डेटा दिखाता है कि रेंडरिंग के बाद शब्दों की संख्या में 300% की वृद्धि हुई है, लेकिन सर्च ट्रैफ़िक में कोई संबंधित वृद्धि नहीं हुई है, तो इसका मतलब यह हो सकता है कि गतिशील रूप से इंजेक्ट की गई सामग्री को Google द्वारा प्रभावी ढंग से नहीं पहचाना गया है।
Lumar Rendered Page Word Count संकेतक आउटपुट करेगा और इसकी तुलना Source HTML Word Count से करेगा।
अनुपात अंतर (Ratio Gap) जितना बड़ा होगा, क्रॉलिंग आवृत्ति उतनी ही अस्थिर होगी। 500,000 से अधिक नमूनों के अवलोकन के माध्यम से, जब Rendering Gap 80% से अधिक होता है, तो पृष्ठ की इंडेक्सिंग में देरी आमतौर पर 3 से 7 दिन बढ़ जाती है।


