




















हाँ, URL पैरामीटर (जैसे सॉर्टिंग ?sort, फ़िल्टरिंग ?color या ट्रैकिंग ID) Google द्वारा डुप्लिकेट इंडेक्सिंग के मुख्य कारण हैं।
यह सुनिश्चित करने के लिए कि सर्च ट्रैफ़िक सटीक रूप से लक्षित पेज पर निर्देशित हो, निम्नलिखित कदम उठाने का सुझाव दिया जाता है:
Canonical टैग सेट करें
सभी वैरिएंट पेजों के HTML में rel="canonical" जोड़ें, जो एकमात्र मुख्य URL की ओर इशारा करता हो।
क्रॉल पथ प्रबंधित करें
Robots.txt के माध्यम से अनावश्यक मार्केटिंग ट्रैकिंग पैरामीटर (जैसे utm_*) को ब्लॉक करें।
रैंकिंग सिग्नल को एकत्रित करें
यह Google को सभी पैरामीटर पेजों के “क्रेडिट स्कोर” को मुख्य पेज पर केंद्रित करने में मदद करता है, जिससे आंतरिक प्रतिस्पर्धा के कारण ट्रैफ़िक में गिरावट को रोका जा सकता है।
कंटेंट रिडंडेंसी (सामग्री की अधिकता)
URL पैरामीटर एक ही पेज के लिए बड़ी संख्या में डुप्लिकेट पते उत्पन्न कर सकते हैं।
उदाहरण के लिए, 5 रंग फिल्टर और 3 सॉर्टिंग विकल्पों वाला एक ई-कॉमर्स पेज 15 से अधिक विभिन्न URL बना सकता है।
बड़ी साइटों के लगभग 40% क्रॉल कोटा अक्सर इन पैरामीटर वैरिएंट्स द्वारा घेर लिए जाते हैं।
जब Google UTM ट्रैकिंग वाले 200 समान होमपेजों को इंडेक्स करता है, तो मुख्य पेज का सर्च वेट (Search Weight) विभाजित हो जाता है, जिससे रैंकिंग प्रदर्शन में लगभग 25% की गिरावट आती है।
लिंक का बिखराव
Google के इंडेक्सिंग तंत्र में, अलग-अलग प्रत्यय (suffix) वाले URL को स्वतंत्र इकाइयों के रूप में माना जाता है।
उदाहरण के लिए, यदि किसी तकनीकी दस्तावेज़ पेज को 50 अलग-अलग डोमेन से बैकलिंक मिलते हैं, लेकिन उनमें से 20 लिंक ?utm_medium=email वाले वर्ज़न की ओर इशारा करते हैं और अन्य 10 लिंक ?ref=footer की ओर, तो मुख्य URL को वास्तव में कुल वेट का केवल 40% ही प्राप्त होता है।
Ahrefs डेटा के विश्लेषण के अनुसार, यह वेट डाइल्यूशन (Weight Dilution) की घटना कठिन कीवर्ड के लिए प्रतिस्पर्धा करते समय पेज की रैंकिंग को अपेक्षित स्थिति से 3 से 5 स्थान नीचे धकेल सकती है।
बिखरे हुए पथों की पहचान करते समय, क्रॉलर स्वचालित रूप से सभी लिंक की शक्ति को मूल पेज में नहीं जोड़ते हैं, जब तक कि वेबसाइट के सोर्स कोड में इसके लिए स्पष्ट रूप से लॉजिक कॉन्फ़िगर न किया गया हो।
PageRank गणना मॉडल में, लिंक का स्थानांतरण 0.85 डैम्पिंग फैक्टर पर आधारित गणितीय नियम का पालन करता है।
साइट में प्रवेश करने वाला प्रत्येक लिंक एक विशिष्ट URL के लिए वेट जमा करता है।
जब यह वेट ?sessionid या ?click_id जैसे गैर-स्थिर प्रत्ययों को आवंटित किया जाता है, तो मुख्य पेज का “ट्रस्ट स्कोर” होमपेज रैंकिंग को ट्रिगर करने के लिए आवश्यक सीमा तक नहीं पहुंच पाता है।
अमेरिकी बाज़ार के SaaS उद्योग में, शीर्ष तीन पेजों में आमतौर पर बहुत ही साफ़-सुथरे लिंक फीचर्स होते हैं।
यदि किसी पेज का वेट 5 से अधिक विभिन्न पैरामीटर वर्ज़न में बिखरा हुआ है, तो Google सर्च रिज़ल्ट में इन पेजों को बारी-बारी से दिखा सकता है, और यह आंतरिक प्रतिस्पर्धा मुख्य पेज के प्रदर्शन को अस्थिर कर देगी।
Magento या Salesforce Commerce Cloud आर्किटेक्चर का उपयोग करने वाले कई ई-कॉमर्स प्लेटफॉर्म ब्रेडक्रंब नेविगेशन या साइडबार फिल्टर में बड़ी संख्या में पैरामीटर वाले इंटरनल लिंक उत्पन्न करते हैं।
यदि आंतरिक नेविगेशन बार-बार स्थिर श्रेणी पते के बजाय category?sort=newest की ओर इशारा करता है, तो साइट के भीतर वेट का प्रवाह विचलित हो जाएगा।
जब क्रॉलर क्रॉलिंग प्रक्रिया के दौरान एक ही गंतव्य के लिए कई प्रवेश बिंदु और अलग-अलग URL संरचनाएं पाता है, तो उस पेज की प्राथमिकता क्रॉलिंग रेटिंग कम हो जाती है।
सोशल मीडिया प्लेटफॉर्म और थर्ड-पार्टी विज्ञापन सिस्टम अक्सर जंपिंग प्रक्रिया के दौरान अपने स्वयं के पैरामीटर जोड़ते हैं, जैसे ?fbclid या ?gclid।
यदि पेज में प्रभावी rel=”canonical” टैग की कमी है, तो Google का एल्गोरिदम हफ़्तों के क्रॉलिंग चक्र के बाद गलती से विज्ञापन पैरामीटर वाले पेज को उस सामग्री के सर्च रिप्रजेंटेटिव के रूप में चुन सकता है।
यह स्थिति क्लिक-थ्रू रेट (CTR) को लगभग 15% कम कर सकती है, क्योंकि सर्च रिज़ल्ट में लंबी और अजीब दिखने वाली URL देखने पर उपयोगकर्ताओं की क्लिक करने की इच्छा संक्षिप्त स्थिर पते की तुलना में काफी कम होती है।
एक बार जब बाहरी लिंक इन अस्थायी पैरामीटर वर्ज़न पर जमा हो जाते हैं, तो तकनीकी साधनों के माध्यम से इन शक्तियों को पूरी तरह से मुख्य पेज पर वापस लाना अक्सर महीनों की पुन: इंडेक्सिंग प्रक्रिया लेता है।
पाथ मल्टीप्लिकेशन इफेक्ट (पथ गुणन प्रभाव)
आधुनिक ई-कॉमर्स आर्किटेक्चर (जैसे Shopify या Magento) में, जब एक बुनियादी श्रेणी पेज में कई फ़िल्टरिंग गुण होते हैं, तो प्रत्येक नया पैरामीटर मौजूदा पैरामीटर के साथ संयोजित हो जाता है।
एक मानक स्पोर्ट्स शू कैटेगरी पेज का उदाहरण लें: यदि वह पेज 10 रंग विकल्प, 12 आकार विनिर्देश, 5 ब्रांड फ़िल्टर और 4 मूल्य सीमा सॉर्टिंग प्रदान करता है, तो सैद्धांतिक रूप से उत्पन्न स्वतंत्र URL पथों की संख्या 10 × 12 × 5 × 4 = 2400 तक पहुँच जाएगी।
यदि प्रोग्राम का लॉजिक पैरामीटर के क्रम को बदलने की अनुमति देता है (उदाहरण के लिए पहले रंग चुनना फिर आकार, और पहले आकार चुनना फिर रंग, दोनों के पथ अलग हैं), तो यह संख्या और भी बढ़ जाएगी।
इस पाथ मल्टीप्लिकेशन इफेक्ट के तहत, जो वास्तव में केवल एक सामग्री वाला पेज था, वह Google क्रॉलर की नज़र में हज़ारों अलग-अलग प्रवेश द्वारों में बदल जाता है।
प्रभावी प्रबंधन के बिना, इस तरह के रिडंडेंट पाथ मध्यम और बड़ी साइटों के 65% से अधिक क्रॉल कोटा को खा जाते हैं, जिससे वास्तव में अपडेट होने वाले उत्पाद विवरण पेजों को पर्याप्त स्कैनिंग आवृत्ति नहीं मिल पाती है।
| पैरामीटर संयोजन चरण | वेरिएबल फैक्टर स्केल | उत्पन्न अद्वितीय URL की संख्या | क्रॉल संसाधन उपयोग का अनुमान |
|---|---|---|---|
| मूल श्रेणी पेज | 1 | 1 | 0.01% |
| गुण फ़िल्टरिंग (रंग + ब्रांड) | 10 x 8 | 80 | 2.5% |
| विनिर्देश ओवरले (रंग + ब्रांड + आकार) | 80 x 12 | 960 | 18.0% |
| पूर्ण फ़ंक्शन ओवरले (गुण + विनिर्देश + सॉर्ट + पेजिंग) | 960 x 3 x 10 | 28,800 | 70% से अधिक |
जब पैरामीटर स्टैकिंग के कारण किसी साइट का URL स्पेस अत्यधिक फैल जाता है, तो Googlebot द्वारा इकाई समय में क्रॉल किए जा सकने वाले प्रभावी पेजों का अनुपात काफी गिर जाता है।
एक बहुराष्ट्रीय रिटेल साइट के लॉग विश्लेषण में पाया गया कि क्रॉलर ने 24 घंटों में 15,000 URL क्रॉल किए, लेकिन उनमें से केवल 1,200 ही रैंकिंग क्षमता वाले स्थिर पेज थे, बाकी 92% क्रॉलिंग व्यवहार ?color=, ?size= और ?sort= के संयोजनों पर खर्च किए गए थे।
जब एल्गोरिदम 200 समान पथों में से एक “कैनोनिकल वर्ज़न” चुनने की कोशिश करता है, तो स्पष्ट तकनीकी संकेतों के बिना, अक्सर वह URL चुन लिया जाता है जो डेवलपर का मानक पेज नहीं होता, जिससे सर्च रिज़ल्ट में पैरामीटर वाले पते दिखाई देने लगते हैं।
जब भी Googlebot एक जटिल संयोजन पैरामीटर वाले URL का अनुरोध करता है, तो बैकएंड डेटाबेस को संबंधित दृश्य उत्पन्न करने के लिए अक्सर कई टेबल संबद्ध क्वेरी निष्पादित करनी पड़ती है।
उच्च आवृत्ति वाले क्रॉल के दबाव में, बहुत अधिक पैरामीटर संयोजन अनुरोध TTFB (Time To First Byte) को 300 मिलीसेकंड से 800 मिलीसेकंड तक बढ़ा सकते हैं।
प्रतिक्रिया विलंब में वृद्धि Googlebot के सुरक्षा तंत्र को सक्रिय कर देती है, जिससे पूरे डोमेन की क्रॉलिंग आवृत्ति कम हो जाती है।
500 वैश्विक ई-कॉमर्स साइटों पर एक शोध रिपोर्ट के अनुसार, 3 स्तरों से अधिक URL पैरामीटर गहराई वाले पेजों के Google द्वारा सफलतापूर्वक इंडेक्स किए जाने की संभावना फ़्लैट URL की तुलना में 42% कम थी।
पैरामीटर का अव्यवस्थित क्रम लिंक सिग्नल के गहरे विघटन का कारण बनता है। जब एक विशिष्ट प्रचार पैरामीटर ?promo=winter वाले पेज को बाहरी वेबसाइट द्वारा उद्धृत किया जाता है, जबकि साइट के भीतर नेविगेशन ?sort=new की ओर इशारा करता है, तो दोनों के वेट सिग्नल Google के आंतरिक डेटाबेस में पूरी तरह से अलग होते हैं।
URL सामान्यीकरण (normalization) रणनीति के बिना साइटों में, प्रत्येक लोकप्रिय उत्पाद पेज में औसतन 14 अलग-अलग पैरामीटर वैरिएंट होते हैं, जिससे उस उत्पाद का क्लिक-थ्रू रेट विभिन्न उप-पथों में बिखर जाता है।
इस बड़े पैमाने के पाथ रिडंडेंसी से निपटने के लिए, केवल robots.txt पर भरोसा करना अक्सर मौजूदा इंडेक्सिंग समस्याओं को हल नहीं कर पाता है।
Google Search Central की आधिकारिक सलाह इन गुणन प्रभावों द्वारा उत्पन्न पथों को जबरन मर्ज करने के लिए rel=”canonical” टैग का उपयोग करने का सुझाव देती है।
कैनोनिकल टैग के सही परिनियोजन के बाद, संबंधित श्रेणी पेजों की सर्च विज़िबिलिटी 60 दिनों के भीतर औसतन 22% बढ़ गई।
क्रॉल बजट की बर्बादी
Googlebot द्वारा इकाई समय में किसी साइट पर किए जाने वाले क्रॉल अनुरोधों की एक ऊपरी सीमा होती है।
जब सिस्टम हज़ारों पैरामीटर वाले URL (जैसे ?variant=123 या ?sort=desc) उत्पन्न करता है, तो क्रॉलर इन निम्न-गुणवत्ता वाले पथों को पहले उपभोग करता है।
Google के क्रॉलिंग तंत्र के अनुसार, यदि डुप्लिकेट URL की संख्या वास्तविक सामग्री से 10 गुना अधिक है, तो महत्वपूर्ण पेजों की क्रॉलिंग आवृत्ति 50% से अधिक कम हो जाएगी।
यह घटना नए प्रकाशित पेजों को 72 घंटों के भीतर भी न खोजे जाने का कारण बन सकती है, और गैर-पैरामीट्रिक मूल URL की क्रॉलिंग आवृत्ति में भारी कटौती की जाती है।
पैरामीटर का प्रभाव
सर्च इंजन का क्रॉल शेड्यूलिंग सिस्टम पेजों की सामग्री में वास्तविक परिवर्तन के आधार पर पैरामीटर को “एक्टिव पैरामीटर” और “पैसिव पैरामीटर” में वर्गीकृत करता है।
सेशन ID (Session IDs) क्रॉल संसाधनों को नष्ट करने के मामले में शीर्ष पर हैं।
?sid=9928374 या ?sessionid=abc123 जैसे पैरामीटर आमतौर पर बैकएंड द्वारा उपयोगकर्ताओं को ट्रैक करने के लिए गतिशील रूप से उत्पन्न होते हैं।
चूंकि प्रत्येक विज़िटर और यहां तक कि क्रॉलर की प्रत्येक विज़िट को एक नई ID मिल सकती है, यह एक ही HTML दस्तावेज़ के लिए सैद्धांतिक रूप से अनंत URL बना सकता है।
सर्वर लॉग विश्लेषण में देखा जा सकता है कि फ़िल्टरिंग नियमों के बिना, Googlebot 24 घंटों के भीतर एक ही लेख को क्रॉल करने के लिए सैकड़ों बार प्रयास कर सकता है, हर बार एक अलग सेशन स्ट्रिंग का उपयोग करके।
यह व्यवहार क्रॉल कतार में बड़ी संख्या में अमान्य अनुरोधों को जमा कर देता है, जिससे नए प्रकाशित पेजों (Fresh Content) को मिलने वाला कोटा कम हो जाता है।
“बड़ी ई-कॉमर्स साइटों की लॉग मॉनिटरिंग में, सेशन ID के कारण होने वाले डुप्लिकेट क्रॉल अनुरोध अक्सर कुल क्रॉल वॉल्यूम का 30% से 50% होते हैं, जिससे Googlebot को सर्वर प्रदर्शन की सुरक्षा के लिए अक्सर ‘क्रॉल डिले’ सीमा ट्रिगर करने के लिए मजबूर होना पड़ता है।”
जब उपयोगकर्ता रंग, आकार, सामग्री जैसे विकल्पों पर क्लिक करते हैं, तो URL में ?color=blue&size=xl&material=cotton जैसे प्रत्यय जुड़ जाते हैं।
हालांकि ये पैरामीटर पेज पर दिखाई देने वाली सामग्री के उपसमूह को बदलते हैं, लेकिन वे अक्सर नया मेटाडेटा उत्पन्न नहीं करते हैं।
तकनीकी दृष्टिकोण से, ये पैरामीटर कार्टेशियन उत्पाद (Cartesian Product) लॉजिक का पालन करते हैं।
| पैरामीटर प्रकार | विशिष्ट संरचना उदाहरण | Googlebot की दृश्यता पर प्रभाव | क्रॉल संसाधन की बर्बादी का स्तर |
|---|---|---|---|
| सेशन ट्रैकिंग | ?sid=xyz_987 |
लगभग अनंत डुप्लिकेट URL पथ बनाता है | अत्यधिक उच्च (9/10) |
| मल्टीपल फ़िल्टरिंग | ?size=m&color=red |
पथ ज्यामितीय रूप से बढ़ते हैं, डेड लूप का कारण बन सकते हैं | उच्च (8/10) |
| सॉर्टिंग लॉजिक | ?sort=price_desc |
पेज सामग्री का क्रम बदलता है, कोई ठोस नई जानकारी नहीं | मध्यम (5/10) |
| विज्ञापन ट्रैकिंग | ?click_id=ad_01 |
मूल पेज के 100% समान सामग्री की ओर इशारा करता है | मध्यम उच्च (7/10) |
| भाषा/क्षेत्र | ?lang=hi-in |
विभिन्न अनुवादित सामग्री वाले वैध पेजों की ओर इशारा करता है | निम्न (2/10) |
सॉर्टिंग पैरामीटर (जैसे ?sort=highest_price या ?order=newest) को Googlebot आमतौर पर कम प्राथमिकता के रूप में चिह्नित करता है।
चूंकि सॉर्टिंग के बाद पेज की मुख्य सामग्री, शीर्षक और मेटा विवरण समान रहते हैं, इसलिए सर्च इंजन का डी-डुप्लिकेशन एल्गोरिदम जल्दी पहचान लेता है कि ये URL कैनोनिकल पेज की प्रतियां हैं।
यदि साइट ने मुख्य पथ की ओर इशारा करने के लिए rel="canonical" सही ढंग से कॉन्फ़िगर नहीं किया है, तो Googlebot अभी भी यह जांचने के लिए लगभग 15% क्रॉलिंग आवृत्ति खर्च करेगा कि क्या इन सॉर्टिंग पेजों में कोई सामग्री अपडेट है।
1 लाख SKU वाली रिटेल वेबसाइट के लिए, केवल “रेटिंग द्वारा सॉर्ट” का एक फ़ंक्शन क्रॉलर को 1 लाख अतिरिक्त अर्थहीन लिंक विज़िट करने पर मजबूर कर सकता है।
ट्रैकिंग पैरामीटर (जैसे ?utm_source=google या ?affiliate_id=123) का SEO पर नकारात्मक प्रभाव मुख्य रूप से “कनेक्शन ओवरहेड” में दिखता है।
हालांकि ये पैरामीटर सामग्री को बिल्कुल नहीं बदलते हैं, फिर भी Googlebot को TCP कनेक्शन स्थापित करने और यह निर्धारित करने के लिए अनुरोध भेजने की आवश्यकता होती है कि क्या उस URL द्वारा लौटाई गई सामग्री मुख्य पेज के समान है।
उच्च ट्रैफ़िक साइटों के अवलोकन के अनुसार, यदि साइट के भीतर UTM पैरामीटर वाले बड़ी संख्या में इंटरनल लिंक हैं, तो क्रॉलर द्वारा प्रभावी मूल पथों को खोजने की गति लगभग 25% कम हो जाती है।
Googlebot इन पूरी तरह से डुप्लिकेट URL को क्रॉल करने की आवृत्ति धीरे-धीरे कम कर देगा, लेकिन उससे पहले, बहुमूल्य “प्रथम क्रॉल कोटा” इन रिडंडेंट ट्रैकिंग कोड्स के कारण पहले ही समाप्त हो चुका होता है।
“तकनीकी ऑडिट से पता चलता है कि इंटरनल लिंक से ट्रैकिंग पैरामीटर हटाने और सांख्यिकीय लॉजिक को ब्राउज़र-साइड इवेंट लिसनिंग पर माइग्रेट करने से Googlebot द्वारा पेजों की दैनिक कुल क्रॉलिंग संख्या में 18% से अधिक की वृद्धि हो सकती है।”
पेजिनेशन पैरामीटर (जैसे ?page=2) के साथ व्यवहार थोड़ा विशेष है।
Google पहले rel="next/prev" पर निर्भर था, लेकिन अब मुख्य रूप से एल्गोरिदम के माध्यम से पेजिनेशन संरचना को समझता है।
हस्तक्षेप के बिना, क्रॉलर 500वें पेज या उससे भी गहरे पेजों को क्रॉल कर सकता है, जबकि इन गहरे पेजों का रैंकिंग मूल्य बहुत कम होता है।
यदि पेजिनेशन पैरामीटर फ़िल्टर पैरामीटर के साथ संयोजित हो जाते हैं (उदाहरण के लिए: नीली शर्ट का पेज 5), तो URL की जटिलता तेजी से बढ़ जाती है।
जांच और नियंत्रण
सर्वर बैकएंड के एक्सेस रिकॉर्ड के माध्यम से, प्रश्न चिह्न (?) वाले URL की आवृत्ति सांख्यिकी के लिए रेगुलर एक्सप्रेशन का उपयोग करके क्रॉलर के पथ को स्पष्ट रूप से देखा जा सकता है।
एक अंतरराष्ट्रीय ई-कॉमर्स साइट पर, यदि लॉग दिखाते हैं कि Googlebot प्रतिदिन ?sessionid= या ?track_id= वाले पथों के लिए 40,000 से अधिक अनुरोध करता है, जबकि सामग्री मूल HTML के समान है, तो यह स्पष्ट है कि लगभग 40% क्रॉल संसाधन अर्थहीन पथों पर नष्ट हो रहे हैं।
तकनीकी टीम को “प्रभावी क्रॉल अनुपात” की गणना करनी चाहिए, जो है:
कैनोनिकल पेज क्रॉल संख्या / कुल क्रॉल संख्या।
यदि यह मान 20% से कम है, तो यह आमतौर पर इंगित करता है कि क्रॉलर पैरामीटर द्वारा उत्पन्न URL भूलभुलैया में फंसा हुआ है।
Kibana या Splunk जैसे लॉग विश्लेषण उपकरणों का उपयोग करके, विभिन्न पैरामीटर संयोजनों के तहत क्रॉल दबाव के वितरण को देखा जा सकता है, जिससे उन पथों की पहचान की जा सके जो लाखों वैरिएंट बनाते हैं लेकिन ट्रैफ़िक में योगदान नहीं देते।
Google Search Console में “क्रॉल सांख्यिकी” रिपोर्ट का उपयोग करके सर्च इंजन के दृष्टिकोण से वास्तविक डेटा वितरण प्राप्त किया जा सकता है।
इस रिपोर्ट में, “उद्देश्य के आधार पर क्रॉल” आयाम पर ध्यान देने की आवश्यकता है:
- डिस्कवरी (Discovery) अनुरोध अनुपात: यह क्रॉलर द्वारा पहली बार नए URL खोजने के व्यवहार को संदर्भित करता है। अक्सर अपडेट होने वाली साइटों के लिए, यह अनुपात 30% से ऊपर होना चाहिए। यदि यह बहुत कम है, तो इसका मतलब है कि नई सामग्री पुराने पैरामीटर पथों द्वारा अवरुद्ध है।
- रिफ्रेश (Refresh) अनुरोध आवृत्ति: यह क्रॉलर द्वारा ज्ञात पेजों पर फिर से विज़िट करने को संदर्भित करता है। यदि रिफ़्रेश अनुरोध साइट के मुख्य पेजों के बजाय पैरामीटर वाले URL पर केंद्रित हैं, तो यह संसाधनों के गलत आवंटन का संकेत है।
- रिस्पॉन्स स्टेटस कोड वितरण संकेतक: 200 (OK), 304 (Not Modified) और 404 (Not Found) के अनुपात को देखें। यदि पैरामीटर वाले URL बड़ी संख्या में 404 त्रुटियां या 301 रीडायरेक्ट उत्पन्न करते हैं, तो Googlebot उच्च कनेक्शन लागत के कारण साइट की क्रॉल सीमा (Crawl Capacity Limit) को कम कर देगा।
- औसत डाउनलोड समय मॉनिटरिंग: यदि जटिल पैरामीटर फ़िल्टरिंग भारी डेटाबेस क्वेरी को ट्रिगर करती है, जिससे पेज लोड समय 2000 मिलीसेकंड से अधिक हो जाता है, तो Googlebot सर्वर को ओवरलोड होने से बचाने के लिए समवर्ती क्रॉल की संख्या को तुरंत कम कर देगा।
रिडंडेंट पैरामीटर के स्रोतों की पुष्टि करने के बाद, हालांकि कैनोनिकल टैग इंडेक्सिंग पक्ष पर डुप्लीकेट को संभाल सकता है, लेकिन केवल Robots.txt ही HTTP कनेक्शन शुरू होने से पहले अनुरोधों को रोक सकता है।
Disallow: /*?*sort= या Disallow: /*?*price_min= सेट करके, Googlebot को विशिष्ट सॉर्टिंग या मूल्य फ़िल्टर संयोजनों पर जाने से रोका जा सकता है।
यह विधि इन पेजों पर खर्च होने वाले कनेक्शनों को तुरंत Sitemap.xml में मौजूद कैनोनिकल URL के लिए खाली कर देती है।
नियम कॉन्फ़िगर करते समय व्यापक Disallow: /*? के उपयोग से बचना चाहिए, ताकि SEO के लिए फायदेमंद भाषा पैरामीटर (जैसे ?hl=hi) या पेजिनेशन पैरामीटर (जैसे ?p=2) न कट जाएं।
सटीक नियंत्रण लॉजिक को लॉग विश्लेषण परिणामों के साथ जोड़ा जाना चाहिए, केवल उन्हीं फ़िल्टरों को ब्लॉक करें जो अनंत पथ संयोजन बनाते हैं।
Faceted Navigation के लिए AJAX लोडिंग या pushState तकनीक का उपयोग करके क्रॉलर अलगाव प्राप्त किया जा सकता है।
जब उपयोगकर्ता फ़िल्टर बटन पर क्लिक करता है, तो सामग्री बदल जाती है लेकिन URL कोई क्रॉल करने योग्य प्रत्यय उत्पन्न नहीं करता है, या दृश्य बदलने के लिए केवल फ्रैगमेंट आइडेंटिफायर (#) का उपयोग करता है। यह तरीका Googlebot के लिए पारदर्शी है क्योंकि क्रॉलर आमतौर पर # के बाद के सभी वर्णों को अनदेखा कर देते हैं।
उन मामलों में जहां पैरामीटर का उपयोग करना आवश्यक है, आयाम सीमा लॉजिक लागू किया जा सकता है:
- पथ गहराई सीमा: कोड में यह निर्धारित करें कि जब पैरामीटर संयोजन तीन आयामों (जैसे: रंग+आकार+सामग्री) से अधिक हो जाता है, तो सिस्टम स्वचालित रूप से HTML हेडर में
noindexटैग डाल देता है। - Nofollow एट्रिब्यूट का अनुप्रयोग: फ़िल्टर साइडबार के लिंक पर
rel="nofollow"लागू करें, जिससे सर्च इंजन को यह सिग्नल मिले कि “यह पथ महत्वपूर्ण नहीं है”। - कैनोनिकलाइजेशन निर्देश: सुनिश्चित करें कि सभी पैरामीटर वाले पेज
rel="canonical"के माध्यम से सबसे संक्षिप्त वर्ज़न की ओर इशारा करते हैं।
Robots.txt ब्लॉकिंग या पैरामीटर मर्जिंग लॉजिक लागू करने के दो सप्ताह के भीतर, Google Search Console में “इंडेक्स कवरेज” रिपोर्ट की लगातार निगरानी की जानी चाहिए।
आदर्श प्रवृत्ति यह है:
“क्रॉल किया गया – वर्तमान में इंडेक्स नहीं किया गया” या “डुप्लिकेट पेज” के रूप में चिह्नित संख्या में महत्वपूर्ण गिरावट आती है, जबकि मुख्य पेजों का “अंतिम क्रॉल समय” अधिक बार होने लगता है।
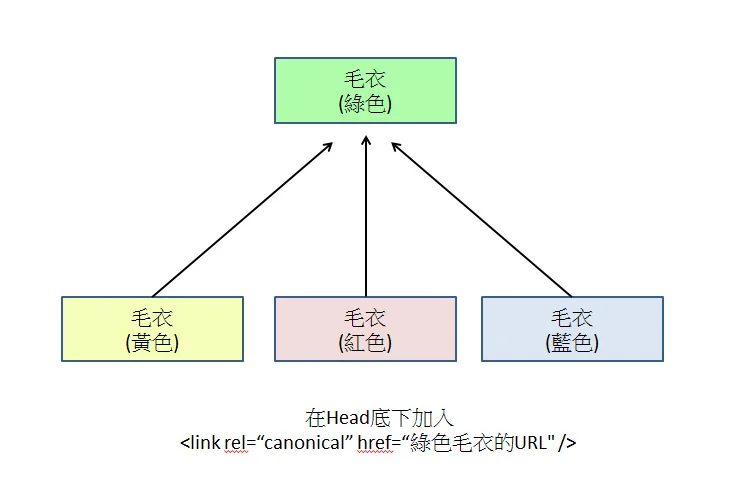
सिग्नल डाइल्यूशन (सिग्नल का कमजोर होना)
जब विभिन्न पैरामीटर (जैसे ?sort=price या ?sessionid=abc) वाले कई URL एक ही सामग्री की ओर इशारा करते हैं, तो Google उन्हें स्वतंत्र पेजों के रूप में मानता है।
मूल रूप से 100% लिंक अथॉरिटी और उपयोगकर्ता क्लिक सिग्नल इन वैरिएंट्स में बिखर जाते हैं।
यदि एक पेज 5 पैरामीटर प्रतियां बनाता है, तो एकल URL द्वारा प्राप्त PageRank केवल 20% रह जाता है, जिससे वह सर्च रिज़ल्ट के टॉप 10 में प्रवेश करने के लिए आवश्यक अथॉरिटी सीमा तक नहीं पहुंच पाता है।
50,000 से अधिक URL वाली ई-कॉमर्स साइटों में, अनप्रोसैस्ड पैरामीटर के कारण Googlebot की दैनिक क्रॉलिंग आवृत्ति का 50% से अधिक डुप्लिकेट पथों पर खर्च हो जाता है, जिससे नए पेजों की इंडेक्सिंग की गति धीमी हो जाती है।
अथॉरिटी का बिखराव
PageRank एल्गोरिदम के मूल लॉजिक में, किसी पेज की रैंकिंग क्षमता उस URL की ओर इशारा करने वाले लिंक की संख्या और गुणवत्ता द्वारा निर्धारित की जाती है।
जब साइट ?sort=newest, ?filter=price-low या ?sessionid=xyz जैसे वर्ज़न पाथ बनाती है, तो बाहरी साइटों का इन विभिन्न वर्ज़न से लिंक करना बहुत आसान हो जाता है।
डेटा इंगित करता है कि यदि किसी उत्पाद का मूल URL example.com/item है, और बाहर से 40% लिंक पैरामीटर वाले example.com/item?source=social की ओर इशारा करते हैं, तो Google का लिंक ग्राफ इन दो URL को अलग-अलग रिकॉर्ड करेगा।
हालांकि एल्गोरिदम कैनोनिकलाइजेशन पहचान करने की कोशिश करेगा, लेकिन अथॉरिटी स्थानांतरण की वास्तविक प्रक्रिया में, इस गैर-मानक मैपिंग में लगभग 10% से 15% स्कोर खो जाता है।
“पैरामीट्रिक URL के साथ व्यवहार करते समय, Googlebot को यह तय करना होता है कि PageRank को किस विशिष्ट इकाई में इंजेक्ट किया जाए; स्पष्ट कैनोनिकल मार्गदर्शन के बिना, यह प्रक्रिया रैंडम और खंडित हो जाती है।” — Google सर्च क्वालिटी टीम के तकनीकी नोटों से संदर्भित।
बड़े अंतरराष्ट्रीय ई-कॉमर्स प्लेटफॉर्म में Faceted Navigation को संभालते समय, यदि पैरामीटर क्रॉलिंग को सीमित नहीं किया जाता है, तो मुख्य श्रेणी पेजों की PageRank संचय की गति अद्वितीय पथ वाले प्रतिस्पर्धियों की तुलना में 30% से अधिक धीमी होती है।
जब कंटेंट की समानता 98% से अधिक हो जाती है, तो सिस्टम डी-डुप्लिकेशन तंत्र शुरू करता है।
उत्तरी अमेरिका की 5 लाख साइटों के अवलोकन के अनुसार, Google द्वारा “डुप्लिकेट” माने गए लेकिन भौतिक रूप से रीडायरेक्ट नहीं किए गए पेजों की मूल लिंक अथॉरिटी अक्सर फ्रोज़न स्थिति में रहती है और स्वचालित रूप से 100% मुख्य पेज पर स्थानांतरित नहीं होती है।
“URL के प्रत्येक वर्ण में परिवर्तन डेटाबेस में एक नया नोड बनाता है; भले ही सामग्री समान हो, ये नोड एल्गोरिदम के शुरुआती चरणों में सहयोग के बजाय प्रतिस्पर्धा की स्थिति में होते हैं।” — एक अंतरराष्ट्रीय SEO अनुसंधान संस्थान की रिपोर्ट से उद्धृत।
तकनीकी स्तर पर इस नुकसान को मापने के लिए, “अथॉरिटी लॉस मॉडल” का संदर्भ लिया जा सकता है:
मान लें कि मुख्य पेज को टॉप 3 में प्रवेश करने के लिए 100 यूनिट सिग्नल की आवश्यकता है, यदि 4 पैरामीटर वैरिएंट मौजूद हैं और प्रत्येक 15% सिग्नल डाइवर्ट करता है, तो मुख्य पेज के पास अंत में केवल 40 यूनिट सिग्नल ही रह जाएंगे, जिससे वह प्रतिस्पर्धा में बहुत पीछे रह जाएगा।
समाधान योजना
Adobe Commerce (पूर्व में Magento) या Salesforce Commerce Cloud जैसे वैश्विक उद्यम ई-कॉमर्स आर्किटेक्चर में, Google का इंडेक्सिंग सिस्टम HTML हेडर या HTTP रिस्पॉन्स हेडर में rel="canonical" निर्देशों को प्राथमिकता देता है।
जब प्रणाली ?color=blue&size=xl जैसे मल्टी-फ़िल्टर संयोजन बनाती है, तो बैकएंड प्रोग्राम उस पेज के कैनोनिकल पते को बिना किसी पैरामीटर वाले रूट URL की ओर इंगित करने के लिए बाध्य करता है।
इस योजना के सही कार्यान्वयन के बाद, साइट की डुप्लिकेट सामग्री की पहचान करने की सटीकता 60% से बढ़कर 99% से अधिक हो सकती है।
- HTTP रिस्पॉन्स हेडर में लिंक घोषणा: PDF या गैर-HTML फ़ाइलों के लिए, सर्वर
Link: <https://example.com/file.pdf>; rel="canonical"भेजकर ट्रैक किए गए लिंक को नई सामग्री के रूप में मानने से रोकता है। - 301 परमानेंट रीडायरेक्ट: पुराने मार्केटिंग पैरामीटर (जैसे
?utm_campaign=2023_sale) के लिए, Nginx या Apache सर्वर स्तर पर वाइल्डकार्ड नियमों का उपयोग करके उन्हें मानक पेज पर रीडायरेक्ट करना सबसे अच्छा अभ्यास है। - सर्वर-साइड पैरामीटर इग्नोर करना: बैकएंड विकास में, सर्वर को सेशन ID या अन्य आंतरिक पैरामीटर को हटाने के लिए कॉन्फ़िगर करना।
- Google Search Console पैरामीटर ब्लॉकिंग: Google के व्यवस्थापक बैकएंड में पैरामीटर को “पैसिव पैरामीटर” (Passive Parameters) के रूप में चिह्नित करना।
बड़े पैमाने के SEO अभ्यास में, React या Angular के साथ निर्मित SPA के लिए, डेवलपर्स पारंपरिक क्वेरी स्ट्रिंग (?) के स्थान पर Fragment Identifier (#) का उपयोग करना पसंद करते हैं।
उदाहरण के लिए, फ़िल्टर URL को /shoes?brand=nike से बदलकर /shoes#brand=nike करना। उपयोगकर्ता की सभी क्रियाएं क्लाइंट साइड पर पूरी होती हैं, जबकि सर्च इंजन को हमेशा /shoes का एकल पथ दिखाई देता है।
Cloudflare या Akamai जैसे CDN का उपयोग करते समय, तकनीकी टीमें “Cache Key इग्नोर पैरामीटर” नियम कॉन्फ़िगर करती हैं।
अमेज़न (Amazon) या eBay जैसे विशाल डेटा वाले प्लेटफार्मों के लिए, लॉजिक URL Rewriting (URL पुनर्लेखन) पर अधिक केंद्रित है।
प्रणाली मूल पैरामीटर मोड /product.php?id=123&variant=blue को अधिक अर्थपूर्ण निर्देशिका मोड /product/123/blue/ में बदल देती है।
1 लाख विदेशी स्वतंत्र साइटों के सर्वेक्षण में, जिन साइटों ने कार्यात्मक पैरामीटर (जैसे सॉर्टिंग, व्यू स्विचिंग) को जावास्क्रिप्ट के window.history.pushState API के माध्यम से छिपाया, उनकी रैंकिंग स्थिरता सामान्य साइटों की तुलना में 2.8 गुना अधिक थी।


