




















Controllo URL GSC
Inserisci l’URL in Search Console, fai clic su “Visualizza pagina sottoposta a scansione” e confronta il codice sorgente HTML per confermare se il contenuto principale scompare dopo il rendering.
Confronto delle differenze testuali
Confronta il numero di caratteri testuali tra “Visualizza sorgente pagina” e “Ispeziona elemento”; quando la differenza di testo è > 20%, esiste un rischio molto elevato di mancata indicizzazione.
Test dei risultati multimediali
Utilizza lo strumento di test dei risultati multimediali di Google per visualizzare lo screenshot e assicurarti che il contenuto critico above-the-fold venga caricato completamente entro una finestra di rendering di 5 secondi.
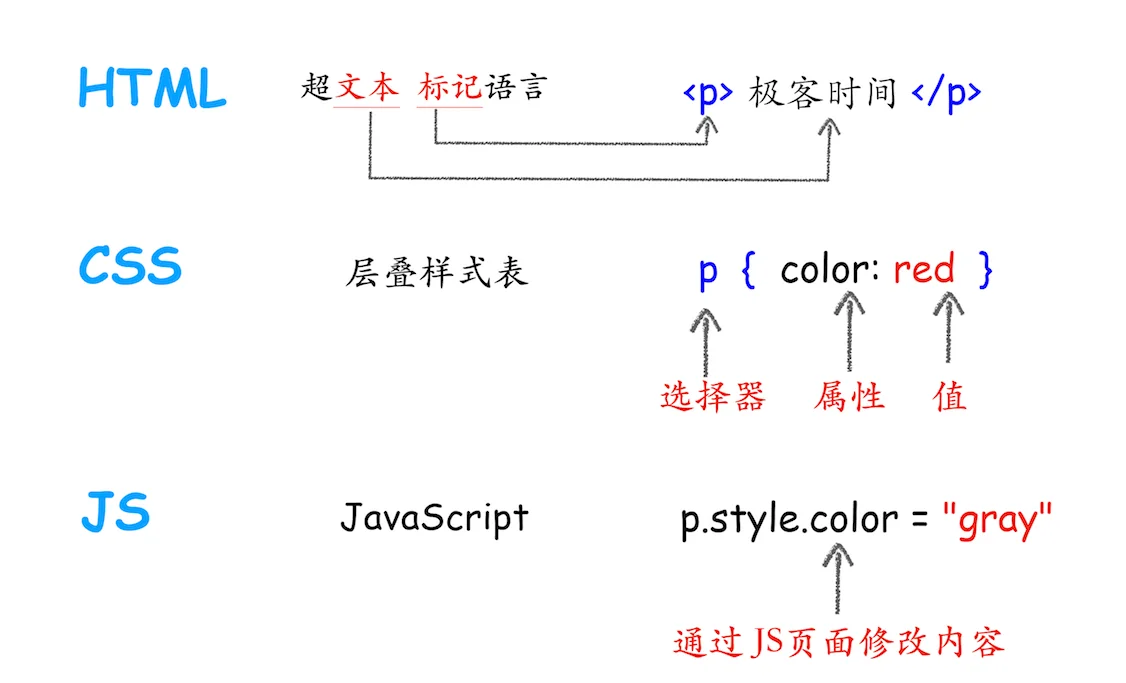
Strumenti ufficiali di Google
Lo strumento di controllo URL di Google Search Console (GSC) è il punto di accesso per ottenere lo stato in tempo reale della scansione di Googlebot.
Tramite il “Test URL pubblicato”, è possibile richiamare il WRS (Web Rendering Service) per generare la struttura DOM completa entro 60-90 secondi.
GSC fornisce l’HTML renderizzato, gli screenshot e l’elenco delle risorse caricate.
Attualmente, Googlebot adotta l’ultimo core stabile di Chrome, ma imposta una soglia di circa 5 secondi per l’esecuzione degli script su una singola pagina.
In combinazione con il “Test dei risultati multimediali”, è possibile confrontare la differenza di byte tra la risposta originale e il risultato finale del rendering, identificando problemi di caricamento degli script (403 o 404) causati dai blocchi del file Robots.txt.
Google Search Console
Nella navigazione della barra laterale di Google Search Console, dopo aver inserito un URL specifico, il sistema recupererà uno snapshot degli ultimi dati scansionati dal database dell’indice di Google.
Se lo stato della pagina mostra “L’URL è su Google”, è possibile vedere se al momento della scansione esistevano errori di analisi HTML o problemi di ottimizzazione per dispositivi mobili.
Per indagare a fondo sulla mancanza di contenuti causata dal rendering JavaScript, è necessario fare clic sul pulsante “Test URL pubblicato”.
Questa operazione attiverà il WRS (Web Rendering Service), che avvierà un browser headless basato sull’ultima versione stabile di Chromium per accedere alla pagina target in tempo reale.
Durante l’esecuzione del rendering, il WRS imposterà la larghezza della viewport a 1280 pixel e adotterà una strategia di scansione mobile-first.
Nel pannello “Visualizza pagina renderizzata”, la scheda HTML mostra la struttura DOM completa dopo l’esecuzione degli script.
Il personale tecnico dovrebbe confrontare quantitativamente il numero di righe di codice HTML o il volume di byte di caratteri visualizzati qui con la “Sorgente pagina” (risposta originale del server) visualizzata tramite il tasto destro del browser.
Se l’HTML originale è di soli 2 KB, mentre l’HTML renderizzato cresce fino a 50 KB, significa che la pagina dipende fortemente dal rendering lato client (CSR).
Se nell’HTML renderizzato mancano il testo principale o i tag dell’elenco prodotti, il rendering è considerato fallito.
Googlebot assegna risorse di calcolo limitate per l’esecuzione degli script su una singola pagina; sebbene non sia stato fornito un tempo limite assoluto ufficiale, numerosi esperimenti dimostrano che se il caricamento dei contenuti supera i 5 secondi, la probabilità che tali dati vengano omessi nella fase di indicizzazione aumenta drasticamente.
“Googlebot non attende all’infinito che JavaScript completi tutte le attività asincrone; il suo budget di rendering è limitato dalla velocità di caricamento della pagina, dalla latenza di risposta del server (TTFB) e dalla complessità dell’analisi degli script. Se il tempo di risposta dell’interfaccia API supera i 2000 millisecondi, spesso i contenuti rimarranno in stato di caricamento nel momento in cui viene generato lo snapshot del rendering.”
Nella scheda “Altre informazioni”, sotto l’elenco “Risorse della pagina”, verranno elencati tutti i file JS e CSS che non sono stati caricati correttamente.
I codici di stato 403 o 404 indicano chiaramente errori di configurazione dei permessi del server o percorsi delle risorse non validi, ma lo stato a cui prestare maggiore attenzione è “Bloccato da Robots.txt”.
Poiché molte Single Page Application (SPA) incapsulano la logica di routing e di rendering dei dati in file di script specifici, se nel file /robots.txt del sito esistono regole come Disallow: /assets/ che impediscono a Googlebot di accedere agli script principali, il WRS non sarà in grado di costruire l’albero DOM completo.
Il risultato è che, anche se l’utente vede la pagina completa nel browser, agli occhi del motore di ricerca la pagina potrebbe apparire vuota o contenere solo il framework di base.
La risoluzione dei problemi relativi agli errori degli script dovrebbe concentrarsi sull’area “Messaggi della console JavaScript”.
Qui verranno registrate le eccezioni generate dal WRS durante l’esecuzione del codice.
Se il team di sviluppo utilizza nuove funzionalità ES6+ senza Polyfill (come BigInt, ResizeObserver, ecc.) e la versione di Chromium corrispondente al momento della scansione non è ancora pienamente compatibile con alcune API non standard, nella console apparirà Uncaught ReferenceError o SyntaxError.
Tali errori causano l’interruzione dell’intero processo di analisi dello script, rendendo inefficace tutta la successiva logica di iniezione dei contenuti.
Osservando il numero di riga specifico e il nome del file menzionati nel log degli errori, è possibile individuare con precisione quale libreria o blocco di logica aziendale stia ostacolando la scansione.
Lo “Screenshot” renderizzato è un altro metodo di rilevamento quantitativo.
Ad esempio, alcuni script calcolano dinamicamente l’altezza o la trasparenza degli elementi; se lo screenshot mostra ampie aree bianche, anche se i tag HTML contengono testo, l’algoritmo di Google potrebbe giudicare la pagina non user-friendly, riducendo la priorità di indicizzazione.
Quando si gestiscono siti altamente dinamici, è necessario garantire che tutti i contenuti situati Above the Fold completino il rendering entro 2 secondi.
Test dei risultati multimediali
Lo strumento di test dei risultati multimediali è un ambiente di test pubblico fornito da Google che, a differenza di Search Console (che richiede la verifica della proprietà del sito), consente a chiunque di analizzare qualsiasi URL pubblico o frammento di codice incollato.
Dopo aver inserito l’URL e avviato il test, il sistema avvierà un browser headless basato sull’ultima versione stabile di Chromium, simulando il comportamento di accesso di Googlebot Smartphone o Googlebot Desktop.
Per le SPA costruite con framework JavaScript come React, Angular o Vue.js, la funzione “Visualizza pagina testata” fornita da questo strumento è lo standard per determinare se il contenuto è entrato con successo nell’albero DOM.
Poiché Googlebot ha un limite massimo di allocazione delle risorse per la gestione degli script, se una pagina richiede un gran numero di calcoli intensivi o effettua più di 20 richieste API asincrone nella fase iniziale, il WRS potrebbe terminare la scansione HTML prima che l’esecuzione degli script sia completata.
Durante il rilevamento in tempo reale, il sistema genererà uno snapshot HTML renderizzato.
Attraverso questo snapshot, i tecnici possono confrontare con precisione la differenza tra i byte restituiti dal server originale e quelli dopo il rendering finale.
Ad esempio, una pagina puramente CSR ha spesso solo un codice template di base inferiore a 5 KB; se l’HTML renderizzato tramite questo strumento può raggiungere oltre 100 KB, significa che Googlebot ha eseguito con successo gli script e recuperato i contenuti dinamici.
Al contrario, se l’HTML renderizzato rimane intorno ai 5 KB e non contiene i tag del testo principale, indica che l’esecuzione dello script è stata interrotta a livello di WRS.
Il motore di rendering di Google imposta un rigoroso meccanismo di timeout per il download delle singole risorse; solitamente, il tempo di caricamento di un singolo file JS non dovrebbe superare i 2000 millisecondi.
Se le librerie di terze parti o le interfacce API richiamate dalla pagina rispondono troppo lentamente, la scheda “Risorse della pagina” nei risultati del test contrassegnerà il corrispondente stato di caricamento fallito.
- Modalità test frammento di codice: supporta l’inserimento di logica di codice HTML non ancora pubblicata, il che è fondamentale per verificare se la logica di rendering JS è conforme agli standard di scansione durante la fase di ambiente di Staging. In questo modo, è possibile verificare quantitativamente se determinati markup Schema generati dinamicamente possono essere analizzati correttamente prima di unire il codice al branch principale.
- Simulazione User-Agent: sebbene adotti per impostazione predefinita la scansione mobile, quando si gestiscono siti con logiche responsive complesse, passare alla simulazione di un dispositivo desktop può rivelare l’impatto della priorità di caricamento CSS sull’ordine di esecuzione JS.
- Confronto snapshot rendering: gli screenshot forniti dal sistema non sono solo riferimenti visivi, ma basi per giudicare se la pagina presenta “spostamenti di contenuto” o “layout shift”, poiché variazioni drastiche del layout possono indurre Googlebot a giudicare erroneamente l’usabilità della pagina.
“Il test dei risultati multimediali non serve solo a convalidare i dati strutturati, ma è un laboratorio per testare la visibilità dei contenuti dinamici. Se il testo sulla pagina viene caricato in modo asincrono tramite JS, cercare la presenza di tale testo in ‘Visualizza pagina testata’ è il metodo più rapido per verificare il tasso di successo dell’indicizzazione SEO.”
Quando una pagina contiene JSON-LD o Microdati iniettati tramite script, lo strumento estrarrà queste informazioni strutturate dal DOM renderizzato.
Se sono presenti errori di sintassi nel codice o se uno script si interrompe a causa di un errore JS prima di iniettare i markup Schema, lo strumento segnalerà “Nessun risultato multimediale rilevato”.
Nella gestione di siti e-commerce o siti di recensioni, questo rilevamento è particolarmente importante perché Google deve identificare attributi specifici come prezzo, stato delle scorte e valutazioni contemporaneamente all’indicizzazione.
Se questi attributi mancano nell’HTML della “Pagina testata”, anche se la pagina frontend appare normale, la pagina dei risultati di ricerca (SERP) non mostrerà le anteprime delle stelle o dei prezzi.
Si dovrebbe prestare particolare attenzione ai log degli errori della console, poiché l’ambiente WRS ha limiti di memoria più severi rispetto ai browser degli utenti comuni.
Se uno script consuma troppe risorse CPU, Googlebot potrebbe abbandonare il rendering della pagina, lasciando nell’indice solo un template vuoto.
- Numero totale di risorse caricate: si consiglia di mantenere le risorse JS richieste da una singola pagina entro le 50 unità. Troppe richieste parallele causano ritardi nella pianificazione del WRS, aumentando il rischio di fallimento del rendering.
- Monitoraggio errori di esecuzione script: lo strumento cattura eccezioni fatali come
ReferenceErroroTypeErrorche interrompono la catena di rendering. Se si notano errori di incompatibilità con gli standard ES dovuti alla mancanza di Polyfill, è necessario regolare immediatamente il target di compilazione degli strumenti di build. - Validità risposta API: controlla tutti gli endpoint API che caricano contenuti dinamici tramite l’elenco delle risorse. Se il codice di stato risulta “Bloccato” o “Timeout”, significa che Googlebot è stato intercettato da un firewall o che le prestazioni dell’API non soddisfano la soglia di scansione.
Ogni “Avviso” o “Errore” generato nel report di questo strumento corrisponde al comportamento di Googlebot nel reale ambiente di indicizzazione.
Se lo strumento segnala “Impossibile caricare alcuni script”, anche se questi funzionano normalmente nel browser Chrome di un utente, è necessario prestare attenzione poiché gli intervalli IP dei crawler di Googlebot potrebbero aver subito limitazioni di velocità (Rate Limiting) dal server durante l’accesso a tali risorse.
Chrome DevTools
Nell’ambiente di sviluppo locale, il pannello “Network conditions” di Chrome DevTools è il punto di partenza per simulare il comportamento di scansione di Googlebot.
Aprendo la barra degli strumenti con F12 o tasto destro “Ispeziona”, entra in More tools -> Network conditions dal menu a tre punti in alto a destra.
In questo pannello, deseleziona “Use browser default” e seleziona manualmente Googlebot dall’elenco a discesa.
Questa operazione modificherà la stringa User-Agent inviata dal browser, ad esempio cambiandola in Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html).
Questo passaggio serve a rilevare se il server ha logiche specifiche per i crawler.
Se il server è configurato per restituire codici HTML diversi in base all’UA, l’ambiente locale presenterà immediatamente risultati di risposta diversi rispetto a quelli di un utente normale.
I tecnici dovrebbero confrontare le informazioni dell’intestazione (header) di risposta, controllando se il Content-Type o le direttive di controllo della cache (Cache-Control) sono cambiati.
Se il server restituisce un errore 403 Forbidden o un reindirizzamento 301 inaspettato per Googlebot, significa che il percorso di indicizzazione del motore di ricerca è bloccato a livello di server.
Per simulare la “prima ondata di indicizzazione” (First-wave indexing) di Googlebot, è fondamentale testare il comportamento della pagina con JavaScript disabilitato.
Vai alla pagina delle impostazioni di DevTools (Settings), nella sezione Preferences trova la parte Debugger e seleziona “Disable JavaScript”.
Dopo aver aggiornato la pagina, il browser presenterà solo la struttura HTML originale generata dal server.
Per i siti che utilizzano architetture SPA, questa operazione spesso rende la pagina completamente vuota o mostra solo un’animazione di caricamento.
Se le informazioni testuali principali, i menu di navigazione o gli elenchi prodotti scompaiono dopo aver disabilitato gli script, significa che il motore di ricerca deve entrare nella complessa “seconda ondata”, ovvero la fase di rendering WRS, per ottenere i contenuti.
In questo caso, si dovrebbe registrare il numero di byte dell’HTML originale, ad esempio 15 KB di codice framework di base, e confrontarlo con il DOM post-rendering per determinare l’entità dei contenuti iniettati tramite JS.
“Nell’ambiente di simulazione locale, disabilitare JavaScript è il test di stress più efficace. Se l’HTML originale di una pagina manca del tag H1 o dei paragrafi del corpo che contengono le informazioni semantiche principali, la pagina corre un rischio elevatissimo di essere indicizzata come pagina vuota in caso di instabilità della rete o saturazione della quota di rendering di Google.”
L’ambiente in cui opera Googlebot non è un computer desktop ad alte prestazioni; utilizzando il pannello “Performance” di DevTools, è possibile simulare più realisticamente la capacità di calcolo di Googlebot.
Nelle impostazioni di performance, regola il limitatore CPU (CPU Throttling) a 4x o 6x slowdown.
Se un’attività di rendering che richiede solo 800 millisecondi su un MacBook ad alte prestazioni cresce fino a 5500 millisecondi con un rallentamento di 6 volte, ha già raggiunto la soglia comune di rendering di 5 secondi di Googlebot.
Visualizzando i “Long Tasks” nel grafico a fiamma, è possibile identificare quali pesanti librerie JS bloccano il thread principale, causando ritardi nel rendering.
Indicatori quantitativi come il Total Blocking Time (TBT) che superano i 2000 millisecondi in questo ambiente solitamente indicano che Googlebot potrebbe rinunciare all’attesa prima che il contenuto sia completamente generato, acquisendo uno snapshot del DOM incompleto.
Verifica manuale del browser
La verifica manuale conferma lo stato del rendering confrontando le differenze di dati tra l’Initial HTML e il Rendered DOM.
Googlebot utilizza l’ultimo motore di rendering di Chrome, ma se l’esecuzione di JS supera la soglia di 5 secondi o le richieste di risorse per singola pagina superano le 50, i contenuti potrebbero non essere indicizzati.
Il test manuale deve concentrarsi sulla catena di caricamento delle risorse, assicurandosi che l’attributo href dei tag <a> sia presente nel sorgente HTML e non generato dinamicamente tramite eventi onclick, per garantire la connettività del percorso del crawler.
Codice sorgente e DOM in tempo reale
Il codice visualizzato nel browser tramite view-source riflette il flusso di testo originale inviato dal server, mentre il pannello Elements degli strumenti per sviluppatori mostra il modello a oggetti del documento (DOM) in memoria dopo l’analisi del motore di rendering, l’esecuzione degli script e la correzione degli errori.
Per i siti che utilizzano l’architettura SPA, il codice sorgente originale spesso contiene solo un tag contenitore vuoto con id="app" o id="root" e diversi riferimenti a script per una dimensione totale superiore a 500 KB.
Confrontando il numero di caratteri di testo normale nel codice sorgente con quelli nel DOM renderizzato, quando questo rapporto supera 1:20 (ovvero l’HTML originale ha solo 100 parole mentre il renderizzato ne raggiunge 2000), la prima scansione del motore di ricerca non riuscirà quasi a ottenere alcuna informazione semantica valida.
Questa discrepanza causa uno stato di vuoto di contenuti nella fase iniziale di indicizzazione, dovendo attendere l’elaborazione secondaria della coda di rendering.
| Dimensione di confronto | Caratteristiche dati HTML originale (Initial HTML) | Caratteristiche dati DOM renderizzato (Rendered DOM) | Impatto sull’indicizzazione delle differenze tecniche |
|---|---|---|---|
| Numero totale nodi DOM | Solitamente meno di 50 nodi, struttura estremamente piatta. | Può superare i 1500 nodi, aumento della profondità gerarchica. | L’esplosione dei nodi indica che la generazione dei contenuti dipende totalmente da JS. |
| Stato tag Meta | Contiene titoli generici o descrizioni segnaposto hard-coded. | Contiene tag SEO specifici iniettati dinamicamente dagli script. | Il crawler potrebbe registrare metadati errati prima dell’esecuzione degli script. |
| Tag Canonical | Mancante o punta a un URL fisso della home page. | Aggiornato dinamicamente al percorso assoluto standard della pagina corrente. | Incongruenze nei tag causano conflitti di analisi delle proprietà della pagina per il motore di ricerca. |
| Dati strutturati JSON-LD | Frammento di codice vuoto o solo framework Schema di base. | Popolato con dati completi su prezzi, recensioni o scorte prodotti. | Determina se la SERP può mostrare i rich snippet. |
| Link interni (Internal Links) | La barra di navigazione potrebbe essere vuota, link non ancora generati. | Contiene tag <a> completi e percorsi di categoria dinamici. |
Influenza l’efficienza del crawler nello scoprire altri URL profondi nel sito. |
Durante un confronto approfondito, inserendo document.body.innerText.length nella console è possibile ottenere il numero totale di caratteri renderizzati e confrontarlo con la dimensione in byte del file sorgente.
Se la dimensione del sorgente è 30 KB ma l’innerText renderizzato raggiunge 15.000 caratteri, il peso testuale principale è concentrato nel livello di rendering.
In questo scenario, se nello script è presente una funzione ricorsiva con un tempo di esecuzione superiore a 200ms o un riferimento a un’API esterna con caricamento superiore a 2.0s, il motore di rendering di Googlebot potrebbe interrompere la registrazione prima dell’iniezione completa dei contenuti a causa delle strategie di allocazione risorse.
| Indicatore quantitativo | Soglia di rischio | Conseguenze reali su scansione e indicizzazione |
|---|---|---|
| Differenza testo-codice (Text Ratio Gap) | > 80% del testo generato da JS | La pagina rischia fortemente di essere giudicata “thin content” senza script. |
| Successo estrazione link | Tag <a> validi nel sorgente < 5 |
Il Crawl Budget viene sprecato in attese infinite. |
| Occupazione memoria script | Oltre 50 MB di consumo memoria stack | Il server di rendering potrebbe terminare forzatamente il task per limiti di memoria. |
| Integrità HTML Above-the-fold | < 10% del contenuto visivo principale visibile nel sorgente | Gli utenti con rete lenta vedranno pagine bianche a lungo, danneggiando i segnali di ranking. |
Ispeziona il menu di navigazione nel pannello Elements; se i link appaiono come <a href="javascript:void(0)" onclick="navigateTo('/page')">, sebbene sembrino link nel DOM renderizzato, per il crawler del motore di ricerca sono vicoli ciechi non tracciabili.
L’attributo href standard deve già esistere nell’HTML originale restituito dal server o essere generato nel formato standard <a href="/target-path"> dopo l’esecuzione dello script.
I siti con una struttura di link HTML originale completa vedono le proprie nuove pagine indicizzate con una velocità superiore del 40% – 70% rispetto ai siti che dipendono totalmente dall’iniezione di link tramite JS.
Se nel codice sorgente esiste un meta tag noindex e la logica dello script tenta di rimuoverlo e sostituirlo con index dopo il rendering, questa pratica è solitamente inefficace.
I motori di ricerca di solito danno priorità alle direttive trovate nell’HTML iniziale, impedendo alla pagina di entrare nel normale processo di indicizzazione.
Verifica della simulazione ambientale
Apri i DevTools in Chrome, premi Ctrl+Shift+P per richiamare il menu dei comandi, digita Disable JavaScript e premi Invio; questo è il punto di partenza per simulare lo stato della prima scansione del motore di ricerca.
Ricarica la pagina in stato di script disabilitato; se lo schermo appare bianco o con solo il framework di base, significa che l’Initial HTML lato server non contiene alcun contenuto testuale sostanziale.
Per un file HTML da 100 KB, se il 90% del contenuto testuale dipende dal caricamento successivo di un pacchetto JavaScript compresso da 2 MB, in caso di latenza di rete o errori di esecuzione script, è molto probabile che il motore di ricerca registri solo un tag contenitore vuoto.
| Parametro di simulazione | Standard e valori di impostazione | Risultati osservati e indicatori |
|---|---|---|
| Limitazione rete (Network Throttling) | Fast 3G (simulazione 1.5 Mbps, 40ms latenza) | Se il rendering del contenuto principale supera i 5000ms (5s), la coda di rendering di Google potrebbe smettere di attendere. |
| Limitazione CPU (CPU Throttling) | 4x slowdown (simulazione prestazioni mobile) | Se il tempo di Script Evaluation supera 1.5s, l’occupazione prolungata del thread principale ritarderà il rendering. |
| Simulazione User-Agent | Googlebot Smartphone (Chrome/W.X.Y.Z) | Controlla se il server restituisce errori 403 o codici specifici per l’adattamento mobile. |
| Dimensione viewport | 411 x 731 pixel (larghezza mobile standard) | Conferma se il contenuto si carica automaticamente senza interazioni come clic o scroll. |
Cambia la stringa User-Agent del browser in Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html).
Seleziona Disable cache nel pannello Network e osserva la catena di caricamento delle risorse sotto l’identità di Googlebot.
Nel processo di scansione standard, Googlebot solitamente non carica tutti i file multimediali, dando priorità all’analisi del testo e dei dati strutturati.
Se la pagina rileva lo User-Agent tramite script e implementa logiche diverse, come la chiusura di determinate interfacce asincrone per i crawler, la struttura DOM nel pannello Elements risulterà completamente diversa da quella vista dagli utenti normali.
Imposta manualmente la velocità di rete su Fast 3G e limita le prestazioni CPU a 4x slowdown nel pannello Network.
Il server di rendering di Googlebot ha risorse di calcolo limitate per ogni pagina. Registra il processo di caricamento tramite il pannello Performance, concentrandoti sull’attività del thread Main.
Se i Long Tasks generati da Evaluate Script superano i 50 millisecondi e la loro somma occupa oltre il 70% del ciclo di caricamento, nell’ambiente di scansione reale il motore di rendering potrebbe completare lo snapshot prima del riempimento totale dei contenuti.
Se l’intervallo tra First Contentful Paint (FCP) e Largest Contentful Paint (LCP) si allunga oltre i 3 secondi a causa dell’esecuzione JS, la probabilità che il motore di ricerca scansioni una pagina incompleta aumenta di circa il 40%.
Utilizza la scheda Sensors in fondo ai DevTools per simulare manualmente diverse posizioni geografiche (come San Francisco o Londra).
I nodi di scansione di Googlebot sono distribuiti principalmente negli Stati Uniti; se la logica JS del sito include reindirizzamenti automatici basati sull’indirizzo IP o generazione di contenuti basata sul timestamp locale, la versione della pagina scansionata potrebbe non corrispondere a quella dell’area di destinazione del pubblico.
Controlla i messaggi di errore nel pannello Console, specialmente ReferenceError o TypeError.
Sebbene la versione del motore di rendering di Google (Evergreen Googlebot) rimanga aggiornata, potrebbero esistere differenze nel supporto per alcune Web API nuovissime (come WebGPU o versioni specifiche di WebAssembly).
Se il codice non è gestito correttamente con Polyfill per la compatibilità, lo script andrà in crash a metà esecuzione, interrompendo la costruzione dell’albero DOM.
- Limite del numero di richieste: conta il numero totale di richieste di rete inviate prima del completamento del rendering. Se una singola pagina richiede più di 50 risorse JS o CSS, a causa dei limiti di concorrenza del browser e delle quote di risorse dei crawler, alcuni script potrebbero non essere caricati in tempo.
- Stato Shadow DOM: controlla nel pannello Elements se esiste il tag
#shadow-root (closed). Googlebot è in grado di analizzare lo Shadow DOM in modalità Open, ma i contenuti in modalità Closed sono invisibili ai crawler; assicurati che tutti i Web Components siano in modalità Open. - Validazione formato link: nel DOM renderizzato, usa
Ctrl+Fper cercare i tag<a. Assicurati che tutti i link di navigazione contengano l’attributohrefcompleto. Se il salto è controllato da eventi JS comewindow.location.hreforouter.pushsenza lasciare anchor standard nell’HTML, il motore di ricerca non scoprirà queste sottopagine. - Lazy Load immagini: controlla se i tag
<img>hanno sostituito il contenuto didata-srcnell’attributosrcsenza scorrere la pagina. Googlebot può simulare parte dello scorrimento, ma per gli script che dipendono da complessi listener di eventiscroll, l’efficacia della scansione non è stabile. L’uso dell’attributo standardloading="lazy"è la pratica più sicura.
Confronta la dimensione in byte e il numero di nodi testuali tra Initial HTML e Rendered DOM.
Se la differenza di copertura testuale tra i due supera l’80% e la maggior parte del testo viene iniettata dopo l’evento DOMContentLoaded, la SEO del sito dipende fortemente dall’efficienza del rendering.
Si consiglia di registrare il Total Blocking Time (TBT) durante i test; se questo valore supera i 300ms, solitamente indica che l’esecuzione dello script ostacolerà l’analisi del DOM da parte del crawler.
Utilizza il pannello Coverage di Chrome per visualizzare il tasso di utilizzo dei file JS; se l’80% del codice in uno script da 500 KB non viene eseguito al caricamento iniziale, questo codice ridondante sprecherà potenza di calcolo del server di rendering, influenzando la velocità di indicizzazione dei contenuti.
Strumenti di scansione professionali
Gli strumenti di scansione professionali possono simulare l’ambiente Chrome (come Screaming Frog v20+).
I dati mostrano che il costo di scansione per l’esecuzione degli script è 20 volte superiore a quello dell’HTML statico.
Quando la differenza nel numero di parole HTML tra “pre-rendering” e “post-rendering” supera il 10%, o la differenza nel numero di link interni identificati supera il 5%, il tasso di successo dell’indicizzazione solitamente diminuisce.
Il rilevamento deve concentrarsi sul tasso di completamento del rendering entro 5 secondi e se il caricamento dello script fallisce a causa di codici di stato 403.
Screaming Frog SEO Spider
Quando si utilizza Screaming Frog per scansioni su larga scala, passare dalla modalità di rendering “Text Only” a “JavaScript” trasforma il comportamento del crawler da semplici richieste HTTP a una simulazione completa del browser.
Il software avvierà istanze sottostanti di Headless Chrome per analizzare ogni singolo file di script sulla pagina web.
Nella configurazione tecnica, l’utente deve selezionare esplicitamente l’opzione JavaScript nel menu Configuration > Spider > Rendering.
Il cambiamento a livello di dati è molto significativo: il processo di scansione che esegue JavaScript solitamente aumenta la richiesta di memoria (RAM) di 5-10 volte.
Ad esempio, durante la scansione di 100.000 pagine contenenti framework complessi come React o Angular, si consiglia di allocare almeno 16 GB – 32 GB di RAM al software, altrimenti il processo di rendering di Chrome potrebbe andare in crash per mancanza di risorse.
Il crawler simulerà la versione del motore di rendering di Chrome durante l’esecuzione, assicurando che la struttura DOM scansionata sia coerente con l’attuale “Evergreen Chrome” utilizzato da Googlebot.
| Categoria indicatore | HTML originale (Source) | HTML renderizzato (Rendered) | Soglia di differenza consigliata |
|---|---|---|---|
| Conteggio parole (Word Count) | Contiene solo framework di base e metadati | Contiene testo caricato asincronamente | Differenza > 15% richiede revisione manuale |
| Numero link interni (Internal Links) | 0 o pochissimi link segnaposto | Link di navigazione e prodotti generati dinamicamente | Differenza > 0 indica rischio di scansione |
| Tag Canonical | Potrebbe mancare o puntare al valore predefinito | Versione finale modificata tramite JS | Deve basarsi sulla versione renderizzata |
| Dimensione pagina (Size) | Solitamente < 50 KB | Può crescere fino a 500 KB – 2 MB | Troppo grande può causare troncamenti da parte di Google |
Quando il software simula l’esecuzione degli script, il timeout AJAX predefinito è solitamente di 5 secondi, simile alla strategia di Googlebot.
Se l’interfaccia dati di una pagina risponde lentamente, facendo sì che il contenuto venga inserito nel DOM dopo 5 secondi, i risultati scansionati da Screaming Frog saranno una pagina “guscio vuoto”.
Attraverso il confronto dei dati nella colonna Word Count, è possibile quantificare questo fenomeno:
Se il numero di parole renderizzate è inferiore a quello del codice sorgente, o se i due sono identici ma la pagina ha effettivamente molto testo, solitamente significa che lo script di rendering non è riuscito a completarsi entro il tempo stabilito.
Nei test per siti e-commerce, se l’elenco prodotti viene caricato tramite scorrimento dinamico, il crawler può anche attivare l’esecuzione dello script configurando “Window Size” o simulando un’azione di scorrimento verso il basso, catturando così le informazioni sui prodotti originariamente nascoste.
Per gli audit tecnici di siti di grandi dimensioni, l’uso della “JavaScript Rendering Table” nella funzione “Bulk Export” consente di esportare un report sulle differenze di rendering dell’intero sito.
Questo report elenca riga per riga le modifiche di Title, Meta Description e tag H1 per ogni URL prima e dopo il rendering.
In casi reali, se si scopre che il tag H1 renderizzato diventa “Loading…” o “Undefined”, ciò prova che il motore di ricerca sta scansionando un codice di stato intermedio invece del contenuto finale.
La scheda “Resource” del software registrerà il codice di stato HTTP per ogni file di script (.js) e foglio di stile (.css).
Se alcuni script funzionali restituiscono un 403 Forbidden, solitamente è perché il firewall (WAF) del server ha erroneamente identificato il comportamento Headless Chrome del crawler come un attacco malevolo e lo ha bloccato, impedendo la corretta visualizzazione del layout e del contenuto dell’intera pagina.
| Stato risorsa rendering | Causa dell’evento | Impatto sulla scansione |
|---|---|---|
| Blocked by robots.txt | Percorso script impostato su Disallow | Googlebot non può leggere lo script, rendering fallito |
| Status Code: 429 | Frequenza richieste troppo alta, attiva limitazione | Risorse della pagina caricate parzialmente, contenuti mancanti |
| Status Code: 404 | Percorso file script non valido | Componenti dinamici dipendenti dallo script non visualizzati |
| Timeout (Exceeded 5s) | Risposta API lenta o logica script complessa | L’HTML scansionato è vuoto o contiene messaggi di errore |
La vista “Rendered Page” fornita dal software consente agli utenti di confrontare fianco a fianco lo snapshot del codice originale e lo snapshot visuale renderizzato.
In questo modo, è possibile individuare intuitivamente i contenuti nascosti da JavaScript, come il testo all’interno di schede (tab) che appaiono solo dopo un clic.
Se il contenuto testuale di una pagina rappresenta meno del 20% nell’HTML originale e l’80% dipende dal rendering, la stabilità di tale pagina nell’indice di Google sarà messa alla prova.
Screaming Frog può anche catturare i Console Errors; se la pagina genera errori fatali di sintassi JavaScript durante il caricamento, il software li evidenzierà nel report.
Quando si gestiscono centinaia di migliaia di URL, si consiglia di attivare le opzioni “Store Images” e “Store Rendered HTML”, che consentono di richiamare lo snapshot di rendering di qualsiasi pagina in qualsiasi momento dopo la fine della scansione.
Analizzando le differenze di “Link Discovery”, è possibile calcolare quale percentuale di link interni richiede l’esecuzione di script per essere scoperta.
Se questa percentuale supera il 30%, la profondità di scansione (Crawl Depth) del sito diventerà incontrollabile a causa dei ritardi nell’esecuzione degli script.
Lumar (DeepCrawl)
Lumar utilizza potenza di calcolo distribuita in cloud, specializzata nella scansione automatizzata di siti di grandi dimensioni con milioni di URL.
Nella gestione di task che richiedono l’esecuzione di JavaScript, il backend opera attraverso migliaia di istanze di browser simulati.
I normali strumenti locali sono limitati dalla memoria fisica; ad esempio, un computer con 32 GB di RAM può solitamente supportare solo da 20 a 50 thread paralleli in modalità rendering.
Lumar, operando su server cloud, può scalare automaticamente a oltre 500 thread a seconda della dimensione del task, garantendo il completamento del rendering e della scansione di 1 milione di pagine entro 24 ore.
Se l’esecuzione dello script di una pagina supera i 5000 millisecondi (5 secondi), il sistema contrassegnerà l’URL come “pagina ad alto costo”, poiché Googlebot solitamente non attende troppo a lungo per una singola risorsa, il che causerebbe vuoti di contenuto nell’indice.
In un progetto React o Vue standard, l’HTML originale potrebbe contenere solo da 2 KB a 5 KB di codice framework, mentre l’albero DOM renderizzato può gonfiarsi fino a 300 KB – 800 KB.
Questa crescita di byte superiore a 100 volte indica che la pagina dipende in modo estremo dagli script.
Le metriche fornite da Lumar includono il DOM Node Count; se il numero di nodi supera i 1500 suggeriti da Google, l’efficienza del rendering diminuirà drasticamente.
Registrando nel cloud il Time to Interactive e il Total Blocking Time, lo strumento può individuare quali file JS (ad esempio un singolo pacchetto vendor.js superiore a 500 KB) ostacolano la visualizzazione normale dei contenuti.
Per siti e-commerce o multinazionali di grandi dimensioni, inviando richieste da nodi server in diverse regioni, è possibile rilevare se determinati script responsabili del rendering dei contenuti non vengono caricati in aree specifiche a causa di errori di configurazione CDN.
I report dei dati elencheranno la percentuale di risorse script con codici di stato 4xx e 5xx.
Se il 20% delle richieste di script di una pagina restituisce un errore 403 (spesso a causa di blocchi robots.txt o firewall), il risultato del rendering di tale pagina sarà incompleto.
Il sistema di reporting di Lumar genererà una “mappa delle differenze di rendering”, evidenziando dettagliatamente le variazioni del numero di link interni con JavaScript attivo o disattivato.
Se, disattivando gli script, il numero di link sulla pagina scende da 200 a 0, significa che la struttura di indirizzamento del sito dipende interamente dall’esecuzione dinamica, il che ha un impatto negativo sulla velocità con cui Googlebot scopre nuove pagine.
La piattaforma supporta anche l’integrazione dei dati di scansione renderizzati con le API di Google Search Console.
Se i dati mostrano che il numero di parole aumenta del 300% dopo il rendering, ma il traffico di ricerca non aumenta proporzionalmente, potrebbe significare che i contenuti inseriti dinamicamente non sono stati riconosciuti efficacemente da Google.
Lumar fornirà l’indicatore Rendered Page Word Count e lo confronterà con il Source HTML Word Count.
Le pagine con una differenza di rapporto (Ratio Gap) maggiore tendono a essere più instabili nella frequenza di scansione. Osservando oltre 500.000 campioni, quando il Rendering Gap supera l’80%, il ritardo di indicizzazione della pagina aumenta solitamente da 3 a 7 giorni.


