




















Sì, i parametri URL (come l’ordinamento ?sort, il filtro ?color o gli ID di tracciamento) sono i principali fattori che portano Google a indicizzare contenuti duplicati.
Per garantire che il traffico di ricerca sia diretto con precisione alla pagina di destinazione, si consiglia di intraprendere le seguenti azioni:
Impostare i tag Canonical
Aggiungere rel="canonical" nell’HTML di tutte le varianti di pagina, puntando all’unico URL principale.
Gestire i percorsi di scansione
Bloccare i parametri di tracciamento marketing non necessari (come utm_*) tramite il file Robots.txt.
Aggregare i segnali di posizionamento
Questo aiuta Google a concentrare il “punteggio di credito” di tutte le pagine parametrizzate sulla pagina principale, prevenendo cali di traffico causati dalla competizione interna.
Ridondanza dei contenuti
I parametri URL possono far sì che la stessa pagina generi un gran numero di indirizzi duplicati.
Ad esempio, una pagina di e-commerce con 5 filtri colore e 3 opzioni di ordinamento può generare più di 15 URL diversi.
Circa il 40% della quota di scansione (crawl budget) dei siti di grandi dimensioni è spesso occupato da queste varianti di parametri.
Quando Google indicizza 200 home page identiche con suffissi di tracciamento UTM, l’autorità di ricerca della pagina principale viene suddivisa, portando a un calo delle prestazioni di posizionamento di circa il 25%.
Dispersione dei link
Nel meccanismo di indicizzazione di Google, gli URL con suffissi diversi sono considerati entità indipendenti.
Ad esempio, se una pagina di documentazione tecnica riceve backlink da 50 domini diversi, ma 20 di questi link puntano alla versione con ?utm_medium=email e altri 10 link puntano alla versione con ?ref=footer, l’URL principale riceverà effettivamente solo il 40% del peso totale.
Secondo un’analisi campionaria dei dati di Ahrefs, questo fenomeno di diluizione dell’autorità può causare il posizionamento di una pagina di 3-5 posizioni più in basso rispetto al previsto quando si compete per parole chiave ad alta difficoltà.
Quando i crawler identificano questi percorsi dispersi, non aggregano automaticamente la forza di tutti i link alla pagina originale, a meno che il sito non abbia configurato esplicitamente la logica di gestione nel codice sorgente.
Nel modello di calcolo del PageRank, il trasferimento dei link segue una legge matematica basata su un coefficiente di attenuazione di 0,85.
Ogni link che entra nel sito accumula peso per un URL specifico.
Quando questo peso viene assegnato a suffissi generati in modo non statico come ?sessionid o ?click_id, il “punteggio di fiducia” della pagina principale non riesce a raggiungere la soglia necessaria per innescare il posizionamento in prima pagina.
Nella competizione del settore SaaS sul mercato statunitense, le pagine ai primi tre posti possiedono solitamente caratteristiche di link estremamente pulite.
Se il peso di una pagina è disperso in più di 5 versioni di parametri differenti, Google potrebbe visualizzare queste pagine alternativamente nei risultati di ricerca; questo stato di competizione interna impedirà alle prestazioni della pagina principale di stabilizzarsi.
Molte piattaforme di e-commerce che utilizzano l’architettura Magento o Salesforce Commerce Cloud generano link interni con un gran numero di parametri nei breadcrumb o nei filtri della barra laterale.
Se la navigazione interna punta frequentemente a category?sort=newest invece che all’indirizzo della categoria statica, il flusso di autorità all’interno del sito subirà una deviazione.
Quando il crawler scopre che lo stesso obiettivo ha più ingressi con strutture URL diverse durante il processo di scansione, il livello di priorità di pianificazione per quella pagina diminuirà.
Le piattaforme social e i sistemi pubblicitari di terze parti tendono a forzare l’aggiunta dei propri parametri durante il processo di reindirizzamento, come ?fbclid o ?gclid.
Se la pagina manca di un tag rel=”canonical” efficace, l’algoritmo di Google potrebbe erroneamente selezionare una pagina con parametri pubblicitari come rappresentante di ricerca di quel contenuto dopo un ciclo di scansione di diverse settimane.
Questa situazione può causare una diminuzione della percentuale di clic (CTR) di circa il 15%, poiché gli utenti, vedendo URL lunghi e confusi nei risultati di ricerca, hanno una propensione al clic significativamente inferiore rispetto agli indirizzi statici concisi.
Una volta che i link esterni vengono raggruppati su queste versioni temporanee di parametri, il tentativo di recuperare completamente questa forza verso la pagina principale tramite mezzi tecnici successivi richiede spesso un processo di reindicizzazione lungo mesi.
Effetto moltiplicatore dei percorsi
Nelle moderne architetture di e-commerce (come Shopify o Magento), quando una pagina di categoria di base possiede più attributi di filtro, ogni nuova dimensione di parametro aggiunta si combinerà con i parametri esistenti in permutazioni e combinazioni.
Prendendo come esempio una pagina di categoria standard per scarpe sportive, se tale pagina offre 10 opzioni di colore, 12 specifiche di taglia, 5 filtri di marca e 4 ordinamenti per fascia di prezzo, i percorsi URL indipendenti generati teoricamente raggiungeranno 10 × 12 × 5 × 4 = 2.400.
Se la logica del programma consente lo scambio dell’ordine dei parametri (ad esempio, selezionare prima il colore e poi la taglia produce un percorso diverso rispetto a selezionare prima la taglia e poi il colore), questo numero si espanderà ulteriormente.
Sotto questo effetto moltiplicatore dei percorsi, quella che originariamente era una pagina con un solo contenuto reale si trasforma agli occhi del crawler di Google in migliaia di ingressi diversi.
In mancanza di una gestione efficace, questi percorsi ridondanti occuperanno oltre il 65% della quota di scansione dei siti di medio-grandi dimensioni, impedendo alle pagine dei dettagli prodotto che hanno realmente bisogno di aggiornamenti di ottenere una frequenza di scansione sufficiente.
| Fase di combinazione dei parametri | Scala dei fattori variabili | Numero di URL univoci generati | Stima dell’occupazione delle risorse di scansione |
|---|---|---|---|
| Pagina di categoria originale | 1 | 1 | 0,01% |
| Filtro attributi (colore + marca) | 10 x 8 | 80 | 2,5% |
| Sovrapposizione specifiche (colore + marca + taglia) | 80 x 12 | 960 | 18,0% |
| Sovrapposizione completa delle funzioni (attributi + specifiche + ordinamento + paginazione) | 960 x 3 x 10 | 28.800 | Oltre il 70% |
Quando Googlebot gestisce questo “spazio infinito” generato dall’accumulo di parametri, la percentuale di scansioni efficaci che il crawler può completare nell’unità di tempo diminuirà drasticamente se lo spazio URL di un sito si espande eccessivamente.
In un’analisi dei log per un sito di vendita al dettaglio multinazionale, è stato riscontrato che il crawler ha scansionato 15.000 URL in 24 ore, ma solo 1.200 di questi erano pagine statiche con potenziale di posizionamento; il restante 92% dell’attività di scansione è stato sprecato in varianti di parametri composte da ?color=, ?size= e ?sort=.
Mentre l’algoritmo tenta di selezionare una “versione canonica” tra 200 percorsi simili, se mancano segnali tecnici chiari, spesso accade che l’URL selezionato non sia la pagina standard prevista dagli sviluppatori, causando la visualizzazione di indirizzi con parametri confusi nei risultati di ricerca.
Ogni volta che Googlebot richiede un URL con una combinazione complessa di parametri, il database backend deve solitamente eseguire query di associazione tra più tabelle per generare la vista corrispondente.
Sotto la pressione di scansioni ad alta frequenza, troppe richieste di combinazioni di parametri porteranno a un aumento del TTFB (Time To First Byte) da 300ms a 800ms.
L’aumento del ritardo di risposta attiverà i meccanismi di protezione di Googlebot, riducendo di conseguenza la frequenza di scansione dell’intero dominio.
Secondo un rapporto di ricerca su 500 siti di e-commerce globalizzati, le pagine con una profondità dei parametri URL superiore a 3 livelli hanno il 42% di probabilità in meno di essere indicizzate correttamente da Google rispetto agli URL piatti.
L’ordine disordinato dei parametri può portare a una profonda frammentazione dei segnali dei link: quando una pagina con un parametro promozionale specifico ?promo=winter viene citata da un sito esterno, mentre la navigazione interna punta alla versione ?sort=new, i segnali di autorità dei due sono completamente isolati nel database interno di Google.
Nei siti che non hanno implementato strategie di normalizzazione degli URL, ogni pagina di prodotto popolare ha in media 14 varianti di parametri differenti, il che porta la percentuale di clic del prodotto nei risultati di ricerca a disperdersi tra i vari percorsi secondari.
Nel gestire questa ridondanza di percorsi su larga scala, fare affidamento esclusivamente sul blocco tramite robots.txt spesso non risolve i problemi di indicizzazione già esistenti.
Le raccomandazioni ufficiali di Google Search Central tendono a suggerire l’uso del tag rel=”canonical” per forzare l’unione di questi percorsi generati dall’effetto moltiplicatore.
Dopo la corretta implementazione dei tag canonici, la visibilità di ricerca delle pagine di categoria pertinenti è aumentata in media del 22% entro 60 giorni.
Spreco del budget di scansione
Esiste un limite superiore al numero di richieste di scansione che Googlebot effettua su un sito nell’unità di tempo.
Quando il sistema genera decine di migliaia di URL con parametri (come ?variant=123 o ?sort=desc), il crawler consumerà prioritariamente questi percorsi di bassa qualità.
Secondo il meccanismo di scansione di Google, se il numero di URL duplicati supera di 10 volte il contenuto reale, la frequenza di scansione delle pagine importanti diminuirà di oltre il 50%.
Questo fenomeno fa sì che le nuove pagine pubblicate potrebbero non essere scoperte per oltre 72 ore, mentre la frequenza di scansione degli URL originali non parametrizzati verrà drasticamente ridotta.
L’impatto dei parametri
Il sistema di pianificazione della scansione dei motori di ricerca classifica i parametri in “parametri attivi” e “parametri passivi” in base al grado di modifica effettiva del contenuto della pagina.
Gli ID di sessione (Session IDs) sono in prima linea per il potere distruttivo sulle risorse di scansione tra tutti i tipi di parametri.
Tali parametri come ?sid=9928374 o ?sessionid=abc123 sono solitamente generati dinamicamente dal backend per tracciare gli utenti nel protocollo HTTP senza stato.
Poiché ogni visitatore, e persino ogni visita di un crawler, può ottenere un ID completamente nuovo, ciò crea un numero teoricamente infinito di URL per lo stesso documento HTML.
Dall’analisi dei log del server si può notare che, se non vengono impostate regole di filtro, Googlebot potrebbe tentare di scansionare lo stesso articolo centinaia di volte in 24 ore, utilizzando ogni volta una stringa di sessione diversa.
Questo comportamento comporta l’accumulo di un gran numero di richieste non valide nella coda di scansione, sottraendo la quota che dovrebbe essere assegnata alle nuove pagine pubblicate (Fresh Content).
“Nel monitoraggio dei log dei siti di e-commerce di grandi dimensioni, le richieste di scansione duplicate causate dagli ID di sessione spesso rappresentano dal 30% al 50% del volume totale di scansione, costringendo Googlebot a attivare frequentemente i limiti di ‘crawl delay’ per proteggere le prestazioni del server.”
Quando gli utenti cliccano su opzioni come colore, taglia, materiale, l’URL aggiungerà suffissi come ?color=blue&size=xl&material=cotton.
Sebbene questi parametri cambino il sottoinsieme di contenuti visualizzati sulla pagina, spesso non generano nuovi metadati.
Dal punto di vista tecnico, questi parametri seguono la logica del prodotto cartesiano (Cartesian Product).
| Tipo di parametro | Esempio di struttura tipica | Impatto sulla visibilità per Googlebot | Grado di spreco delle risorse di scansione |
|---|---|---|---|
| Tracciamento sessione | ?sid=xyz_987 |
Genera percorsi URL duplicati quasi infiniti | Altissimo (9/10) |
| Filtro multiplo | ?size=m&color=red |
I percorsi crescono esponenzialmente, facile causare loop infiniti | Alto (8/10) |
| Logica di ordinamento | ?sort=price_desc |
L’ordine dei contenuti cambia, nessuna nuova informazione sostanziale | Medio (5/10) |
| Tracciamento pubblicitario | ?click_id=ad_01 |
Punta a contenuti identici al 100% alla pagina originale | Medio-alto (7/10) |
| Lingua/Regione | ?lang=it-it |
Punta a pagine valide con diversi contenuti tradotti | Basso (2/10) |
I parametri di ordinamento (Sorting Parameters) come ?sort=highest_price o ?order=newest sono solitamente contrassegnati come a bassa priorità agli occhi di Googlebot.
Poiché il corpo della pagina, il titolo e la meta descrizione rimangono invariati dopo l’ordinamento, l’algoritmo di deduplicazione del motore di ricerca identificherà rapidamente questi URL come copie della pagina canonica (Canonical Page).
Se il sito non ha configurato correttamente rel="canonical" verso il percorso principale, Googlebot consumerà comunque circa il 15% della frequenza di scansione per verificare se queste pagine ordinate presentano aggiornamenti di contenuto.
Per un sito di vendita al dettaglio con 100.000 SKU, solo una funzione di “ordinamento per valutazione” potrebbe far sì che il crawler visiti 100.000 link senza senso in più.
L’impatto negativo dei parametri di tracciamento (Tracking Parameters) come ?utm_source=google o ?affiliate_id=123 sulla SEO si manifesta principalmente nel “costo di connessione”.
Sebbene questi parametri non cambino affatto il contenuto della pagina, Googlebot deve comunque stabilire una connessione TCP e inviare una richiesta per determinare se il contenuto restituito da quell’URL è coerente con la pagina principale.
In base all’osservazione dei siti ad alto traffico, se all’interno del sito sono presenti un gran numero di link interni con parametri UTM, la velocità di scoperta dei percorsi originali validi da parte del crawler diminuirà di circa il 25%.
Googlebot ridurrà gradualmente la frequenza di scansione per questi URL completamente duplicati, ma prima di allora, la preziosa “quota di scansione iniziale” è già stata esaurita da questi codici di tracciamento ridondanti.
“Gli audit tecnici mostrano che la rimozione dei parametri di tracciamento dai link interni e la migrazione della logica statistica al monitoraggio degli eventi lato browser può aumentare il volume totale di scansioni giornaliere delle pagine da parte di Googlebot di oltre il 18%.”
I parametri di paginazione (Pagination Parameters) come ?page=2 sono trattati in modo relativamente speciale nella logica di elaborazione.
In passato Google si affidava a rel="next/prev", ma ora comprende la struttura della paginazione principalmente attraverso algoritmi.
Senza intervento, il crawler potrebbe scansionare in profondità fino alla pagina 500 o anche oltre, mentre il valore di posizionamento di queste pagine profonde è estremamente basso.
Se i parametri di paginazione si combinano con i parametri di filtro (ad esempio: camicie blu a pagina 5), la complessità dell’URL aumenterà esponenzialmente.
Indagine e controllo
Accedendo ai record di accesso del backend del server e utilizzando espressioni regolari per contare la frequenza degli URL contenenti punti interrogativi (?), è possibile osservare chiaramente la traiettoria di visita del crawler.
In un sito di e-commerce internazionale con oltre 100.000 visite giornaliere, se i log mostrano che Googlebot invia ogni giorno oltre 40.000 richieste per percorsi con suffissi ?sessionid= o ?track_id=, e il contenuto della pagina restituita coincide completamente con l’HTML originale, è evidente che circa il 40% delle risorse di scansione è sprecato in percorsi senza senso.
Il team tecnico dovrebbe calcolare la “percentuale di scansioni efficaci”, ovvero:
Numero di scansioni delle pagine canoniche / Numero totale di scansioni.
Se questo valore è inferiore al 20%, solitamente indica che il crawler è intrappolato in un labirinto di URL generati dai parametri.
Utilizzando strumenti di analisi dei log come Kibana o Splunk, è possibile osservare la distribuzione della pressione di scansione sotto diverse combinazioni di parametri, individuando così i percorsi che generano centinaia di migliaia di varianti senza contribuire al traffico.
Utilizzando il rapporto “Statistiche di scansione” in Google Search Console, è possibile ottenere la distribuzione dei dati reali dal punto di vista del motore di ricerca.
In questo rapporto, è necessario concentrarsi sulla dimensione “Scansione per scopo”:
- Percentuale di richieste di Scoperta (Discovery): si riferisce al comportamento del crawler quando trova un nuovo URL per la prima volta. Per i siti che si aggiornano frequentemente, questa percentuale dovrebbe rimanere superiore al 30%. Se la percentuale è troppo bassa, significa che i nuovi contenuti sono bloccati dai percorsi dei vecchi parametri.
- Frequenza di richieste di Aggiornamento (Refresh): si riferisce alla nuova visita del crawler a pagine già note. Se le richieste di aggiornamento sono concentrate massicciamente su URL con parametri anziché sulle pagine principali del sito, è segno di un’errata distribuzione delle risorse.
- Indicatori di distribuzione dei codici di stato di risposta: osservare le percentuali di 200 (OK), 304 (Not Modified) e 404 (Not Found). Se gli URL con parametri generano un gran numero di errori 404 o reindirizzamenti 301, Googlebot abbasserà il limite massimo di scansione (Crawl Capacity Limit) per il sito a causa dell’eccessivo costo di connessione.
- Monitoraggio del tempo medio di download: se i filtri complessi dei parametri innescano query pesanti al database, causando tempi di caricamento della pagina superiori a 2000 millisecondi, Googlebot ridurrà rapidamente il numero di scansioni simultanee per evitare di mandare in crash il server.
Dopo aver confermato la fonte dei parametri ridondanti, sebbene il tag Canonical possa gestire i duplicati lato indicizzazione, solo Robots.txt può intercettare le richieste prima di avviare una connessione HTTP.
Impostando Disallow: /*?*sort= o Disallow: /*?*price_min=, è possibile richiedere forzatamente a Googlebot di smettere di accedere a specifiche combinazioni di ordinamento o filtri di prezzo.
Questo metodo può rilasciare immediatamente il numero di connessioni originariamente sprecate su queste pagine agli URL canonici nella Sitemap.xml.
Nella configurazione delle regole si dovrebbe evitare l’uso di un generico Disallow: /*?, per non interrompere i parametri linguistici utili per la SEO (come ?hl=it) o i parametri di paginazione (come ?p=2).
La logica di controllo granulare dovrebbe combinare i risultati dell’analisi dei log, bloccando solo i filtri che generano combinazioni di percorsi infiniti.
Per la navigazione a filtri multipli (Faceted Navigation), l’uso di AJAX per il caricamento o della tecnologia pushState può isolare il crawler.
Quando un utente clicca su un pulsante di filtro, il contenuto della pagina cambia ma l’URL non genera un suffisso scansionabile, oppure utilizza solo un identificatore di frammento (#) per cambiare la vista; tali pratiche sono trasparenti per Googlebot, poiché il crawler solitamente ignora tutti i caratteri dopo il #.
Nei casi in cui l’uso dei parametri sia necessario, è possibile implementare una logica di limitazione delle dimensioni:
- Limite di profondità del percorso: stabilire nel codice del programma che, quando la combinazione di parametri supera le tre dimensioni (ad esempio: colore+taglia+materiale), il sistema inserisce automaticamente il tag
noindexnell’intestazione HTML e garantisce che la pagina non appaia in alcun link interno al sito. - Applicazione dell’attributo Nofollow: applicare
rel="nofollow"sui link nella barra laterale dei filtri, inviando al motore di ricerca il segnale che “questo percorso non è importante”, riducendo la probabilità che il crawler entri in combinazioni di filtri profonde. - Direttiva di unione della normalizzazione: assicurarsi che tutte le pagine con parametri puntino alla versione canonica più concisa tramite
rel="canonical", così anche se il crawler effettua la scansione, guiderà il sistema di indicizzazione a fondere l’autorità nel percorso principale.
Se la home page o la barra di navigazione principale contengono un gran numero di link con parametri di tracciamento UTM, Googlebot darà priorità alla scansione di questi percorsi rumorosi.
Si consiglia di migrare tutte le statistiche sul traffico interno al monitoraggio degli eventi lato browser, mantenendo così gli URL puliti. Nel gestire la logica della paginazione, sebbene Google non utilizzi più tag specifici, mantenere una struttura di percorsi chiara (come /page/2/ invece di ?page/2) aiuta l’algoritmo a identificare gli elenchi in modo più stabile.
Nelle due settimane successive all’implementazione del blocco tramite Robots.txt o della logica di unione dei parametri, si dovrebbe monitorare costantemente il rapporto “Copertura dell’indice” in Google Search Console.
La tendenza ideale è:
Il numero di pagine contrassegnate come “Scansionata, ma attualmente non indicizzata” o “Pagina duplicata” diminuisce significativamente, mentre l'”Ultima scansione” delle pagine principali diventa più frequente.
Se il ciclo di scansione di una pagina si accorcia da una volta ogni 10 giorni a entro 24 ore e le risposte 200 nei log del server si concentrano maggiormente sugli URL canonici, ciò dimostra che il budget di scansione è stato distribuito in modo ragionevole.
Diluizione del segnale
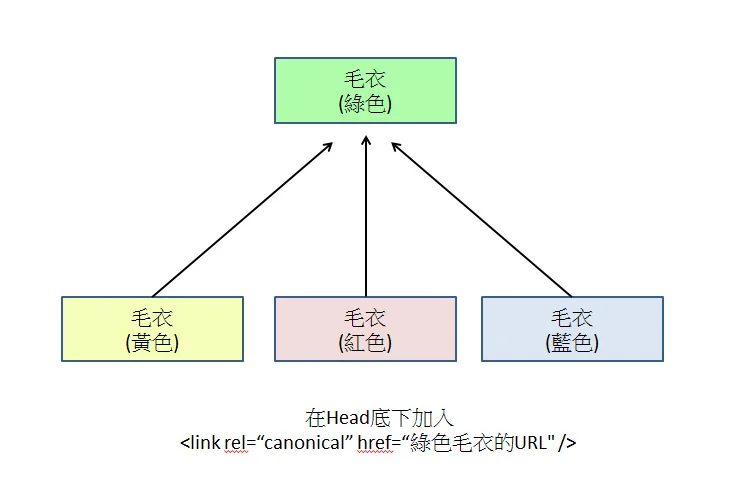
Quando più URL contenenti parametri diversi (come ?sort=price o ?sessionid=abc) puntano allo stesso contenuto, Google li considererà come pagine indipendenti.
L’autorevolezza dei link e i segnali dei clic degli utenti, originariamente al 100%, verrebbero dispersi tra queste varianti.
Se una pagina genera 5 copie parametrizzate, il PageRank ottenuto da un singolo URL scende al 20%, impedendogli di raggiungere la soglia di autorità necessaria per entrare nei primi 10 risultati di ricerca.
Nei siti di e-commerce con oltre 50.000 URL, i parametri non gestiti portano oltre il 50% della frequenza di scansione giornaliera di Googlebot a essere consumato in percorsi duplicati, ritardando la velocità di indicizzazione delle nuove pagine.
Dispersione dell’autorità
Nella logica originale dell’algoritmo PageRank, la capacità di posizionamento di una pagina è determinata dalla quantità e dalla qualità dei link che puntano a quell’URL.
Quando il sito genera percorsi varianti contenenti ?sort=newest, ?filter=price-low o ?sessionid=xyz, è estremamente facile che siti esterni creino link a queste diverse varianti.
I dati specifici indicano che se l’URL originale di un prodotto è example.com/item e il 40% dei link esterni punta a example.com/item?source=social con parametri, il Link Graph di Google registrerà questi due URL separatamente.
Sebbene l’algoritmo tenti di eseguire l’identificazione della normalizzazione, nel processo effettivo di trasferimento dell’autorità, circa il 10-15% del punteggio andrà perso in questa mappatura non standard.
“Nel gestire URL parametrizzati, Googlebot deve decidere in quale entità specifica iniettare il PageRank; in mancanza di una guida Canonical chiara, questo processo di iniezione diventa casuale e frammentario.” — Rif. dalle note tecniche pubbliche del team per la qualità della ricerca di Google.
Dai dati reali dell’analisi dei log, si riscontra che le grandi piattaforme di e-commerce multinazionali, nel gestire la navigazione sfaccettata (Faceted Navigation), se non limitano la scansione dei parametri, vedono la velocità di accumulo del PageRank delle loro pagine di categoria principali essere più lenta di oltre il 30% rispetto ai concorrenti con percorsi univoci.
Quando 5000 link interni dell’intero sito puntano rispettivamente a 50 diverse combinazioni di parametri, la spinta che originariamente poteva portare una pagina alla prima pagina dei risultati di ricerca viene suddivisa in 50 segnali deboli insufficienti a generare posizionamento.
Quando la somiglianza dei contenuti tra due URL raggiunge oltre il 98%, il sistema attiva il meccanismo di deduplicazione.
Secondo l’osservazione di 500.000 siti nordamericani, le pagine giudicate da Google come “duplicate” ma non reindirizzate fisicamente tendono ad avere l’autorità del link originale in uno stato congelato, anziché essere trasferita automaticamente al 100% alla pagina principale.
Per i siti con oltre 100.000 URL, i percorsi di scansione non validi generati dai parametri limiteranno la profondità di accesso di Googlebot.
Nei siti senza gestione dei parametri, il tempo di permanenza del crawler sulle pagine con parametri non validi rappresenta il 65% del tempo totale di scansione, il che significa che i nuovi contenuti di alta qualità potrebbero richiedere 14 giorni o più per essere indicizzati, mentre nei siti ottimizzati questo ciclo si riduce solitamente a meno di 24 ore.
“Ogni minima variazione di carattere in un URL crea un nuovo nodo nel database; anche se il contenuto è identico, questi nodi sono in competizione piuttosto che in collaborazione nelle fasi iniziali dell’algoritmo.” — Tratto da un rapporto sperimentale di un istituto di ricerca SEO internazionale.
In alcune architetture che utilizzano il bilanciamento del carico o reti di distribuzione globale (CDN), le richieste con parametri potrebbero essere memorizzate nella cache come diverse copie statiche.
Se l’intestazione della risposta HTTP non è configurata correttamente con Vary: User-Agent o Link: rel="canonical", Googlebot potrebbe pensare che queste pagine parametrizzate servano a mostrare contenuti diversi per utenti di regioni diverse.
Sotto questo errore di valutazione, l’algoritmo scomporrà ulteriormente l’autorità dell’intero sito in varie dimensioni di parametri, creando una situazione di “anemia di autorità”.
Per quantificare tecnicamente la perdita causata da questa dispersione, si può fare riferimento al “modello di perdita di autorità”:
Supponendo che la pagina principale necessiti di 100 unità di segnale per entrare nei primi tre posti, se esistono 4 varianti di parametri e ogni variante sottrae il 15% del segnale, la pagina principale manterrà alla fine solo 40 unità di segnale, trovandosi in estremo svantaggio nella competizione.
Durante l’audit tecnico dei negozi all’estero su piattaforme come Shopify, disabilitando in GSC (Google Search Console) i parametri che non cambiano il contenuto come sort_by, view e page, si è osservato che le impressioni effettive delle pagine di destinazione sono aumentate in media del 55% entro 60 giorni.
Soluzioni
Nelle architetture e-commerce globali di livello enterprise come Adobe Commerce (ex Magento) o Salesforce Commerce Cloud, il sistema di indicizzazione di Google darà priorità alla lettura delle istruzioni rel="canonical" nell’intestazione HTML o nell’intestazione della risposta HTTP durante il processo di scansione.
Quando il sistema genera combinazioni di filtri multipli come ?color=blue&size=xl, il programma backend forzerà l’indirizzo canonico di quella pagina a puntare all’URL radice senza alcun parametro.
Dopo la corretta implementazione di questa soluzione, la precisione del riconoscimento dei contenuti duplicati del sito da parte di Google può aumentare dal 60% a oltre il 99%; i punteggi PageRank originariamente sparsi ovunque completeranno l’aggregazione fisica entro un ciclo di aggiornamento dell’indice di 2-4 settimane.
Per i siti multinazionali con milioni di SKU, questa logica garantisce che il percorso di ricerca principale ottenga oltre il 95% dell’autorevolezza dei link interni al sito.
- Dichiarazione dei link nelle intestazioni di risposta HTTP: nella gestione di documenti PDF o file parametrizzati in formato non HTML, il lato server invierà informazioni nell’intestazione
Link: <https://example.com/file.pdf>; rel="canonical", impedendo al motore di ricerca di considerare i link di download con parametri di tracciamento come nuovi contenuti. - Unione forzata tramite reindirizzamenti permanenti 301: per i parametri di tracciamento marketing già scaduti (come
?utm_campaign=2023_saledi tre anni fa), la pratica prevalente è configurare regole jolly a livello di server Nginx o Apache per reindirizzare permanentemente tutte le richieste contenenti quel parametro scaduto alla pagina standard, garantendo il trasferimento al 100% dell’autorità dei link esterni accumulata storicamente. - Ignorare i parametri senza stato lato server: nello sviluppo backend, configurando il server in modo che rimuova il Session ID o altri parametri utilizzati solo per la logica interna durante l’elaborazione delle richieste, facendo sì che gli URL visti dai diversi utenti rimangano univoci a livello fisico.
- Blocco della classificazione dei parametri in Google Search Console: nel backend di gestione di Google, i tecnici contrassegneranno i parametri come “parametri passivi” (Passive Parameters), informando chiaramente il crawler che questi caratteri non cambiano il contenuto della pagina, guidando così Googlebot a saltare proattivamente la scansione di questi URL.
Nelle pratiche SEO su larga scala, per le Single Page Application (SPA) dotate di complessi sistemi di filtraggio, come le piattaforme costruite con React o Angular, gli sviluppatori tendono a usare il Fragment Identifier (#) invece delle tradizionali stringhe di query (?).
Ad esempio, cambiando l’URL del filtro da /shoes?brand=nike a /shoes#brand=nike, tutti i clic e le operazioni di filtraggio degli utenti vengono completati lato client, mentre il motore di ricerca vede sempre il percorso unico /shoes.
Quando si utilizzano reti di distribuzione dei contenuti globali (CDN) come Cloudflare o Akamai, il team tecnico configurerà le regole “Cache Key ignore parameters”.
Indipendentemente dal fatto che l’utente acceda a example.com/page?id=1 o example.com/page?id=1&from=email, la CDN restituirà la stessa copia cache al motore di ricerca e all’utente, normalizzando l’output nell’intestazione della risposta.
Per piattaforme con quantità massicce di dati come Amazon o eBay, la logica di elaborazione si concentra maggiormente sulla riscrittura della struttura dei percorsi (URL Rewriting).
Il sistema convertirà il modello di parametri originale /product.php?id=123&variant=blue in un modello di directory più semantico /product/123/blue/.
In un’indagine campionaria su 100.000 siti indipendenti all’estero, quelli che hanno mascherato i parametri funzionali (come l’ordinamento, il cambio di visualizzazione) tramite l’API window.history.pushState di JavaScript senza cambiare l’indirizzo fisico della richiesta, hanno presentato una stabilità media del posizionamento delle pagine 2,8 volte superiore rispetto ai siti ordinari.


