




















GSC 網址檢查
在 Search Console 輸入 URL,點擊“查看已抓取的網頁”,對比 HTML 源碼,確認核心內容是否在渲染後消失。
文本差異對比
對比“查看源代碼”與“檢查元素”中的文本字符數,文本差異率 > 20% 時,存在極高收錄風險。
Rich Results Test
使用 Google 富媒體搜尋結果測試工具查看截圖,確保首屏關鍵內容在 5 秒渲染窗口內完整加載。
Google 官方工具
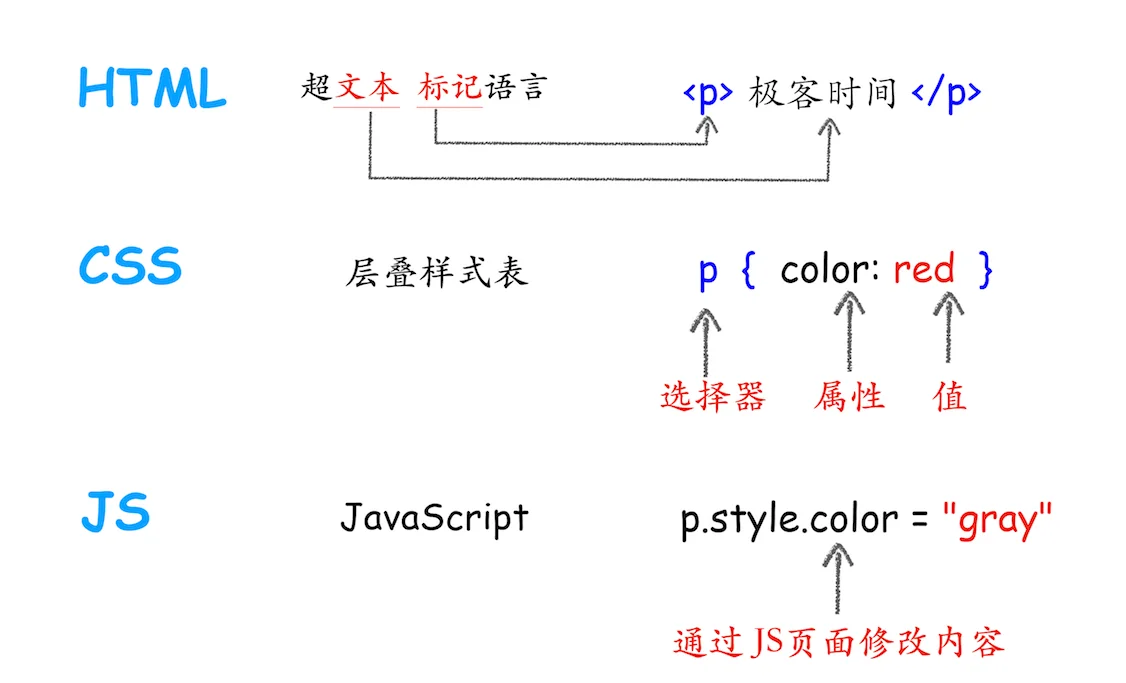
Google Search Console (GSC) 的 URL 檢查工具是獲取 Googlebot 抓取實況的入口。
通過“測試實際網址”,能在 60-90 秒內調用 WRS (Web Rendering Service) 生成完整 DOM 結構。
GSC 提供渲染後的 HTML、屏幕快照及資源加載清單。
目前 Googlebot 採用最新的 Chrome 穩定版內核,但對單個頁面的腳本執行設有約 5 秒的閾值。
結合“富媒體搜尋結果測試”,可以對比原始響應與最終渲染結果的字節差異,並識別因 Robots.txt 屏蔽導致的 403 或 404 腳本加載失敗問題。
Google Search Console
在 Google Search Console 的側邊欄導航中,輸入具體的網址後,系統會從 Google 索引數據庫中調取最近一次抓取的數據快照。
如果頁面狀態顯示“網址已在 Google 上”,則可以看到當時抓取時是否存在 HTML 解析錯誤或移動端優化問題。
要深入排查 JavaScript 渲染引起的內容缺失,必須點擊“測試實際網址”按鈕。
該操作會觸發 WRS(Web Rendering Service)啟動一個基於最新穩定版 Chromium 內核的無頭瀏覽器,對目標頁面進行實時訪問。
WRS 在執行渲染時,會將視口寬度設定為 1280 像素,並採用移動端優先的抓取策略。
在“查看經過渲染的頁面”面板中,HTML 選項卡展示的是腳本運行完畢後的完整 DOM 結構。
技術人員應當將此處顯示的 HTML 代碼行數或字符字節量,與通過瀏覽器右鍵查看到的“查看網頁源代碼”(原始服務器響應)進行量化對比。
如果原始 HTML 僅有 2KB,而渲染後的 HTML 增長到了 50KB,說明該頁面高度依賴客戶端渲染。
若渲染後的 HTML 中缺乏主幹文本內容或商品列表標籤,則判定為渲染失敗。
Googlebot 對單個頁面的腳本執行分配了有限的計算資源,雖然官方未給出絕對的截止時間,但大量實驗表明,若內容加載時間超過 5 秒,該部分數據在索引階段被遺漏的概率會大幅度提升。
“Googlebot 並非無限期等待 JavaScript 完成所有異步任務,其渲染預算受到頁面加載速度、服務器響應延遲(TTFB)以及腳本解析複雜度的共同限制。如果 API 接口響應時間超過 2000 毫秒,往往會導致內容在渲染快照生成的瞬間仍處於 Loading 狀態。”
在“更多信息”選項卡下的“網頁資源”清單中,會列出所有加載失敗的 JS 和 CSS 文件。
狀態碼 403 或 404 明確指向服務器權限配置錯誤或資源路徑失效,而最需要留心的是“因 Robots.txt 而屏蔽”這一狀態。
由於許多單頁面應用(SPA)將路由邏輯和數據渲染邏輯封裝在特定的腳本文件中,如果網站的 /robots.txt 文件中存在 Disallow: /assets/ 或類似規則,導致 Googlebot 無法獲取主幹腳本,那麼 WRS 就無法構建出完整的 DOM 樹。
其產生的結果是,即便用戶在瀏覽器中看到的網頁是完整的,但在搜尋引擎的抓取視野裡,該頁面可能只是一片空白或僅包含基礎框架。
針對腳本報錯的排查,應聚焦於“JavaScript 控制台消息”區域。
此處會記錄下 WRS 執行代碼時拋出的異常。
如果由於開發團隊使用了未經 Polyfill 處理的 ES6+ 新特性(如 BigInt、ResizeObserver 等),且抓取當時對應的 Chromium 版本尚未完全兼容某些非標準 API,控制台就會出現 Uncaught ReferenceError 或 SyntaxError。
此類報錯會造成整個腳本解析流程的中斷,後續的所有內容注入邏輯都會失效。
通過觀察錯誤日誌中提到的具體行號和文件名,可以精確定位到是哪個庫文件或業務邏輯塊阻礙了抓取。
渲染後的“屏幕截圖”是另一種量化檢測手段。
例如,某些腳本會動態計算元素的高度或透明度,如果截圖顯示頁面大面積留白,即使 HTML 標籤中存在文字,Google 算法也可能判定該頁面對用戶不友好,從而降低收錄優先級。
在處理高度動態化的站點時,需要確保所有位於首屏(Above the Fold)的内容必須在 2 秒內 完成渲染。
富媒體測試
富媒體搜尋結果測試工具是 Google 提供的公開檢測環境,與需要站點所有權驗證的 Search Console 不同,該工具允許任何人針對公網上的任意 URL 或粘貼的代碼片段進行解析。
在輸入網址並觸發測試後,系統會啟動一個基於最新穩定版 Chromium 內核的無頭瀏覽器,模擬 Googlebot Smartphone 或 Googlebot Desktop 的訪問行為。
對於高度依賴 JavaScript 框架如 React、Angular 或 Vue.js 構建的單頁面應用(SPA),該工具提供的“查看測試的網頁”功能是判定內容是否成功進入 DOM 樹的判定標準。
由於 Googlebot 在處理腳本時存在明顯的資源分配上限,如果頁面在初始化階段需要執行大量的密集型計算或發起超過 20 個以上的異步 API 請求,WRS 可能會在腳本執行完畢前就結束 HTML 的抓取。
在進行實時檢測時,系統會生成一個渲染後的 HTML 快照。
通過該快照,技術人員可以精確比對原始服務器返回的字節數與最終渲染後的字節數差異。
例如,一個純粹的客戶端渲染(CSR)頁面,其原始 HTML 往往只有不到 5KB 的基礎模板代碼,而通過該工具渲染後的 HTML 若能達到 100KB 以上,則說明 Googlebot 成功執行了腳本並拉取了動態內容。
反之,如果渲染後的 HTML 依然停留在 5KB 左右,且不包含主文案標籤,則表明腳本執行在 WRS 層面發生了中斷。
Google 的渲染引擎對單個資源的下載設定了嚴格的超時機制,通常單個 JS 文件的加載時間不應超過 2000 毫秒。
如果頁面引用的第三方庫或 API 接口響應過慢,測試結果中的“網頁資源”選項卡會標記出相應的加載失敗狀態。
- 代碼片段測試模式:支持粘貼未經發佈的 HTML 代碼邏輯,這對於在 Staging 環境階段檢測 JS 渲染邏輯是否符合抓取規範至關重要。通過這種方式,可以在代碼合併到主分支前,量化檢測某些動態生成的 Schema 標記是否能被正確解析。
- User-Agent 模擬切換:雖然默認採用移動端抓取,但在處理某些具有複雜響應式邏輯的站點時,切換到桌面端設備模擬可以發現 CSS 加載優先級對 JS 執行順序的影響。
- 渲染快照對比:系統提供的屏幕截圖不僅是視覺參考,更是判斷頁面是否出現“內容偏移”或“佈局抖動”的依據,因為劇烈的佈局變動可能導致 Googlebot 誤判頁面的可用性。
“富媒體搜尋結果測試不僅能驗證結構化數據,更是檢測動態內容可見性的實驗室。如果頁面上的文本是通過 JS 異步加載的,那麼在‘查看測試的網頁’中搜尋該文本是否存在,是驗證 SEO 索引成功率的最快方法。”
當頁面包含通過腳本注入的 JSON-LD 或微數據(Microdata)時,該工具會從渲染後的 DOM 中提取這些結構化信息。
如果代碼中存在語法錯誤,或者由於 JS 報錯導致腳本在注入 Schema 標記前就停止運行,工具會報出“檢測不到富媒體搜尋結果”的提示。
在處理電商網站或評價類站點時,這種檢測尤為重要,因為 Google 需要在收錄的同時識別出價格、庫存狀態和評分等特定屬性。
如果這些屬性在“經過測試的網頁”HTML 中缺失,即便前端頁面顯示正常,搜尋結果頁(SERP)也不會呈現星級或價格預覽。
應特別關注控制台錯誤日誌,因為 WRS 環境對內存的佔用限制比普通用戶的瀏覽器更嚴格。
如果腳本消耗了過高的 CPU 資源,Googlebot 可能會捨棄該頁面的渲染,導致索引庫中僅保留一個空的殼模板。
- 加載的資源總數:建議將單個頁面請求的 JS 資源控制在 50 個以內。過多的並行請求會導致 WRS 調度延遲,增加渲染失敗的風險。
- 腳本執行錯誤監測:工具會捕獲
ReferenceError或TypeError等導致渲染鏈條斷裂的致命異常。如果看到由於缺少 Polyfill 導致的 ES 規範不兼容報錯,應立即調整構建工具的編譯目標。 - API 響應有效性:通過資源清單檢查所有動態拉取內容的 API 終結點。如果狀態碼顯示為“已屏蔽”或“超時”,說明 Googlebot 被防火牆攔截或 API 性能無法滿足抓取閾值。
該測試工具生成的報告中,每一個“警告”或“錯誤”都對應著 Googlebot 在真實索引環境中的行為表現。
如果工具提示“無法加載某些腳本”,即使這些腳本在普通用戶的 Chrome 瀏覽器中能正常運行,也必須引起重視,因為這可能 Googlebot 的爬蟲 IP 段在訪問這些資源時遭到了服務器的速率限制(Rate Limiting)。
Chrome DevTools
在本地開發環境中,Chrome DevTools 提供的“網絡條件”(Network conditions)面板是模擬 Googlebot 抓取行為的起點。
通過按下 F12 或右鍵選擇“檢查”打開工具欄,在右上角的三個點菜單中進入 More tools -> Network conditions。
在此面板中,取消勾選“使用瀏覽器默認設置”(Use browser default),並在下拉列表中手動選擇 Googlebot。
該操作會修改瀏覽器發送的 User-Agent 字符串,例如將其變更為 Mozilla/5.0 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)。
這一步驟的作用在於檢測服務器是否存在針對爬蟲的特殊邏輯。
如果服務器配置了根據 UA 返回不同的 HTML 代碼,本地環境會立即呈現出與普通用戶訪問時截然不同的響應結果。
技術人員應當對比此時的響應頭部信息,檢查 Content-Type 或緩存控制指令(Cache-Control)是否發生了變化。
如果服務器針對 Googlebot 返回了 403 拒絕訪問或 301 意外重定向,說明在服務端層面就已阻斷了搜尋引擎的收錄路徑。
為了模擬 Googlebot 的“第一輪索引”(First-wave indexing),必須測試在禁用 JavaScript 情況下的頁面表現。
進入 DevTools 的設置頁面(Settings),在偏好設置中找到調試器(Debugger)部分,勾選“禁用 JavaScript”(Disable JavaScript)。
刷新頁面後,瀏覽器將僅呈現由服務器吐出的原始 HTML 結構。
對於採用單頁面應用(SPA)架構的站點,此操作往往會導致頁面出現完全空白或僅顯示 Loading 動畫。
如果網頁的主干文字信息、導航菜單或商品列表在禁用腳本後全部消失,說明搜尋引擎必須進入複雜的“第二輪索引”即 WRS 渲染階段才能獲取內容。
此時,應當記錄下原始 HTML 的字節數,例如 15KB 的基礎框架代碼,並與完整渲染後的 DOM 進行對比,以確定 JS 注入的內容規模。
“在本地模擬環境中,禁用 JavaScript 是最的壓力測試。如果一個頁面的原始 HTML 中缺乏包含主要語義信息的 H1 標籤或正文段落,那麼該頁面在網絡環境波動或 Google 渲染配額緊張時,面臨被收錄為空白頁面的風險極高。”
Googlebot 運行的環境並非高性能的桌面計算機,利用 DevTools 中的“性能”(Performance)面板,可以更真實地模擬 Googlebot 的計算能力。
在性能設置中,將 CPU 限制(CPU Throttling)調整為 4 倍速或 6 倍速降速(4x or 6x slowdown)。
如果在一個高性能 MacBook 上僅需 800 毫秒完成的渲染任務,在 6 倍降速下增長到了 5500 毫秒,就已經觸及了 Googlebot 常見的 5 秒渲染閾值。
通過查看火焰圖中的長任務(Long Tasks),可以識別出哪些龐大的 JS 庫阻塞了主線程,導致渲染延遲。
量化指標如總阻塞時間(TBT)在此環境下若超過 2000 毫秒,通常預示著 Googlebot 可能會在內容完全生成前就放棄等待,轉而抓取當前不完整的 DOM 快照。
瀏覽器手動驗證
手動驗證通過對比 Initial HTML 與 Rendered DOM 的數據差異來確認渲染狀態。
Googlebot 採用最新的 Chrome 渲染引擎,但若 JS 執行超過 5 秒閾值或單頁資源請求超過 50 個,內容可能無法被索引。
手動測試需關注資源加載鏈,確保 <a> 標籤的 href 屬性在 HTML 源碼中預見,而非通過 onclick 事件動態生成,以保證爬蟲路徑的連通性。
源代碼與實時 DOM
在瀏覽器中通過 view-source 查看的代碼反映的是服務器發送的原始文本流,而開發者工具 Elements 面板展示的是經過渲染引擎解析、腳本執行並糾錯後的內存對象模型(DOM)。
對於採用單頁應用(SPA)架構的站點,原始源代碼往往只包含一個帶有 id="app" 或 id="root" 的空容器標籤以及若干個總計大小超過 500KB 的腳本引用。
將源代碼中的純文本字符數量與渲染後 DOM 中的文本字符數量進行對比,當這個比例超過 1:20 時,即原始 HTML 僅有 100 個單詞而渲染後達到 2000 個單詞,搜尋引擎的第一波抓取幾乎無法獲取任何有效的語義信息。
這種差異會導致頁面在索引初期處於內容真空狀態,必須等待渲染隊列的二次處理。
| 比較維度 | 原始源代碼 (Initial HTML) 數據特徵 | 渲染後 DOM (Rendered DOM) 數據特徵 | 技術差異的索引影響 |
|---|---|---|---|
| DOM 節點總數 | 通常少於 50 個節點,結構極其扁平。 | 可能超過 1500 個節點,層級深度增加。 | 節點數劇增說明內容生成完全依賴 JS 運行。 |
| Meta 標籤狀態 | 包含通用標題或硬編碼的佔位符描述。 | 包含由腳本動態注入的特定頁面 SEO 標籤。 | 抓取工具可能在腳本運行前記錄錯誤的頁面元數據。 |
| Canonical 標籤 | 缺失或指向固定的站點首頁 URL。 | 動態更新為當前頁面的標準絕對路徑。 | 標籤不一致會導致搜尋引擎對頁面屬性產生解析衝突。 |
| JSON-LD 結構化數據 | 代碼段中為空或僅有基礎的 Schema 框架。 | 填充了完整的产品價格、評價或庫存數據。 | 決定了搜尋結果頁(SERP)是否能顯示富摘要。 |
| Internal Links | 導航欄可能為空,鏈接尚未生成。 | 包含完整的 <a> 標籤和動態分類路徑。 |
影響爬蟲發現站點內其他深層 URL 的效率。 |
在進行深度比對時,通過在控制台輸入 document.body.innerText.length 可以獲取當前渲染後的總字符數,將其與源代碼文件的字節大小進行對標。
如果源代碼大小為 30KB,但渲染後的 innerText 達到 15,000 個字符,主要的文本權重全部集中在渲染層。
此時,如果腳本中存在一個執行耗時超過 200ms 的遞歸函數,或者引用了加載時間超過 2.0s 的外部 API,Googlebot 的渲染引擎可能會因為資源分配策略而在內容完全注入前停止記錄。
| 定量指標 | 風險閾值 | 抓取與索引的實際後果 |
|---|---|---|
| 代碼文本差異率 (Text Ratio Gap) | > 80% 的文本由 JS 生成 | 頁面極易在無腳本環境下被判定為“內容薄弱”。 |
| 鏈接提取成功率 | 源碼中有效 <a> 標籤 < 5 個 |
爬蟲抓取預算(Crawl Budget)會被浪費在無盡的等待中。 |
| 腳本執行內存佔用 | 超過 50MB 的堆棧內存消耗 | 渲染服務器可能因為內存限制而強制終止渲染任務。 |
| 首屏 HTML 完整度 | < 10% 的主視覺內容在源碼中可見 | 用戶在慢速網絡下會看到長時間白屏,導致排名信號受損。 |
在 Elements 面板中檢查導航菜單,如果鏈接顯示為 <a href="javascript:void(0)" onclick="navigateTo('/page')">,這在渲染後的 DOM 中雖然看起來像一個鏈接,但對於搜尋引擎的爬蟲來說,這是一個無法追踪的死胡同。
標準的 href 屬性必須在服務器返回的原始 HTML 中就已經存在,或者在腳本運行後生成為標準的 <a href="/target-path"> 格式。
擁有完整原始 HTML 鏈接結構的站點,其新頁面被收錄的速度通常比完全依賴 JS 注入鏈接的站點快 40% 到 70%。
如果在源代碼中存在 noindex 的 meta 標籤,而腳本邏輯試圖在渲染後將其移除並替換為 index,這種做法往往是無效的。
搜尋引擎通常會優先遵守在初始 HTML 中發現的指令,導致頁面無法進入正常的索引流程。
環境模擬驗證
在 Chrome 瀏覽器中打開開發者工具(DevTools),按下 Ctrl+Shift+P 調出命令菜單,輸入 Disable JavaScript 並回車,這是模擬搜尋引擎初次抓取狀態的起點。
在禁用腳本的狀態下重新加載頁面,如果此時屏幕顯示為空白或僅有基礎框架,說明服務器端的 Initial HTML 沒有任何實質性的文本內容。
對於一個 100KB 的 HTML 文件,如果其中 90% 的文本內容是依靠後續加載的 2MB 的 JavaScript 壓縮包來生成的,那麼在網絡延遲或腳本執行出錯時,搜尋引擎極有可能只記錄到一個空的容器標籤。
| 模擬參數 | 設置標準與數值 | 觀察結果與數據指標 |
|---|---|---|
| 網絡節流 (Network Throttling) | Fast 3G (模擬 1.5 Mbps 下行, 40ms 延遲) | 主內容渲染完成時間若超過 5000ms (5秒),Google 渲染隊列可能會停止等待。 |
| CPU 限制 (CPU Throttling) | 4x slowdown (模擬移動端處理器性能) | 腳本解析 (Script Evaluation) 時間超過 1.5秒 時,主線程長時間佔用會導致內容渲染滯後。 |
| User-Agent 模擬 | Googlebot Smartphone (Chrome/W.X.Y.Z) | 檢查服務器是否返回 403 錯誤或特定的移動端適配代碼。 |
| 視口大小 (Viewport) | 411 x 731 像素 (標準移動端寬度) | 確認內容是否在不進行點擊、滑動等交互操作的情況下自動加載。 |
更改瀏覽器的 User-Agent 字符串為 Mozilla/5.0 (Linux; Android 6.0.1; Nexus 5X Build/MMB29P) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/120.0.0.0 Mobile Safari/537.36 (compatible; Googlebot/2.1; +http://www.google.com/bot.html)。
在 Network 面板中勾選 Disable cache,觀察在 Googlebot 身份下的資源加載鏈。
在標準的抓取流程中,Googlebot 通常不會加載所有的媒體文件,它會優先解析文本和結構化數據。
如果頁面通過腳本檢測 User-Agent 並實施了不同的邏輯,例如針對爬蟲關閉了某些異步接口,會導致 Elements 面板中的 DOM 結構與普通用戶看到的完全不同。
在 Network 面板中手動設置網速為 Fast 3G 並限制 CPU 性能至 4x slowdown。
Googlebot 的渲染服務器在處理全球數以億計的網頁時,分配給單個頁面的計算資源是有限的。通過 Performance 面板錄製加載過程,重點查看 Main 線程的活動情況。
如果 Evaluate Script 產生的長任務(Long Tasks)超過 50 毫秒,且總和佔據了加載週期的 70% 以上,那麼在真實的抓取環境中,渲染引擎可能會在內容完全填充前就完成快照記錄。
First Contentful Paint (FCP) 與 Largest Contentful Paint (LCP) 的間隔如果因為 JS 執行過久而拉大到 3 秒以上,搜尋引擎抓取到殘缺頁面的概率會增加 40% 左右。
利用開發者工具底下的 Sensors 選項卡,手動模擬不同的地理位置(如 San Francisco 或 London)。
Googlebot 的抓取節點主要分佈在美國境內,如果網站的 JS 邏輯中包含根據 IP 地址自動重定向或根據本地時間戳生成內容的邏輯,可能會導致抓取到的頁面版本與目標受眾區域的版本不符。
在 Console 面板中檢查報錯信息,特別是 ReferenceError 或 TypeError。
由於 Google 渲染引擎的版本(Evergreen Googlebot)雖然保持更新,但對某些極新的 Web API(如最新的 WebGPU 或特定版本的 WebAssembly)可能存在支持差異。
如果代碼中沒有做好 Polyfill 兼容性處理,腳本會在執行到一半時崩潰,導致 DOM 樹停止構建。
- 請求數量限制:統計頁面在渲染完成前發出的網絡請求總數。如果單頁面請求超過 50 個 JS 或 CSS 資源,由於瀏覽器的併發限制及爬蟲的資源配額,部分腳本可能無法被及時加載。
- Shadow DOM 狀態:在 Elements 面板查看是否存在
#shadow-root (closed)標記。Googlebot 能夠解析 Open 模式的 Shadow DOM,但 Closed 模式的内容對爬蟲是不可見的,需確保所有 Web Components 處於 Open 狀態。 - 鏈接格式驗證:在渲染後的 DOM 中,使用
Ctrl+F搜尋<a標籤。確保所有的跳轉鏈接都包含完整的href屬性。如果是通過window.location.href或router.push等 JS 事件控制跳轉,且沒有在 HTML 中留下標準錨點,搜尋引擎將無法發現這些子頁面。 - 圖片 Lazy Load:檢查
<img>標籤在不滾動頁面的情況下,是否已經將data-src中的內容替換到了src屬性。Googlebot 能夠模擬部分滾動,但對於依賴複雜scroll事件監聽器的腳本,其抓取效果並不穩定。使用標準的loading="lazy"屬性是更安全的做法。
對比 Initial HTML 與 Rendered DOM 的字節大小和文本節點數量。
如果兩者的文本覆蓋率差異超過 80%,且大部分文字內容是在 DOMContentLoaded 事件之後才被注入,這說明站點的 SEO 高度依賴於渲染效率。
建議在測試中記錄 Total Blocking Time (TBT),該數值如果超過 300ms,通常預示著腳本執行過程會阻礙爬蟲對 DOM 的解析。
通過 Chrome 的 Coverage 面板查看 JS 文件的利用率,如果一個 500KB 的腳本中有 80% 的代碼在首屏加載時未被執行,這些冗餘代碼會白白消耗渲染服務器的計算量,從而影響內容的收錄速度。
專業爬蟲工具
專業的爬蟲工具能模擬 Chrome 環境(如 Screaming Frog v20+)。
數據表明,執行腳本的抓取支出比靜態 HTML 高出 20 倍。
當“渲染前”與“渲染後”的 HTML 字數差異超過 10%,或內鏈識別數差異超過 5% 時,索引成功率通常會下降。
檢測需關注 5 秒內的渲染完成率,以及是否因 403 狀態碼導致腳本加載失敗。
Screaming Frog SEO Spider
在設置 Screaming Frog 進行大規模抓取時,將渲染模式從“僅文本(Text Only)”切換到“JavaScript”會使爬蟲的行為從簡單的 HTTP 請求轉變為完整的瀏覽器模擬。
軟件會啟動底層的 Headless Chrome 實例來解析網頁上的每一個腳本文件。
技術配置上,用戶需要在 Configuration > Spider > Rendering 菜單中明確選擇 JavaScript 選項。
數據層面的變化非常顯著,執行 JavaScript 的抓取過程對內存(RAM)的需求通常會增加 5 到 10 倍。
例如,在抓取 10 萬個包含複雜 React 或 Angular 框架的頁面時,建議分配至少 16GB 至 32GB 的內存給軟件,否則 Chrome 渲染進程可能會因資源不足而崩潰。
爬蟲在運行過程中會模擬 Chrome 的渲染引擎版本,確保抓取到的 DOM 結構與 Googlebot 當前使用的“Evergreen Chrome”保持一致。
| 指標類別 | 原始 HTML (Source) | 渲染後 HTML (Rendered) | 差異閾值建議 |
|---|---|---|---|
| 文字字數 (Word Count) | 僅包含基礎框架和元數據 | 包含異步加載的文本 | 差異 > 15% 需人工復核 |
| 內鏈數量 (Internal Links) | 0 或極少量佔位符鏈接 | 動態生成的導航與產品鏈接 | 差異 > 0 說明存在抓取風險 |
| Canonical 標籤 | 可能缺失或指向默認值 | 經由 JS 修改後的最終版本 | 必須以渲染後的版本為準 |
| 頁面體積 (Size) | 通常 < 50 KB | 可能增長至 500 KB – 2 MB | 過大可能導致 Google 截斷 |
當軟件模擬執行腳本時,AJAX Timeout(異步加載超時)默認設置通常為 5 秒,這與 Googlebot 處理腳本的策略相似。
如果一個頁面的數據接口響應緩慢,導致內容在 5 秒後才填入 DOM,那麼 Screaming Frog 抓取到的結果將是“空殼”頁面。
通過對比 Word Count 這一列的數據,可以量化這種現象:
如果渲染後的字數反而少於源代碼字數,或者兩者完全一致但頁面實際上有大量文字,通常說明渲染腳本在規定時間內未能執行完畢。
在針對電商網站的測試中,如果產品列表是通過動態滾動加載的,爬蟲還可以通過配置“Window Size”或模擬向下滾動動作來觸發腳本執行,從而抓取到那些原本處於隱藏狀態的商品信息。
對於大型站點的技術審計,利用“Bulk Export”功能中的 “JavaScript Rendering Table” 可以導出全站的渲染差異報告。
這份報告會逐行列出每一個 URL 在渲染前後的 Title、Meta Description 和 H1 標籤的变化。
在實際案例中,如果發現渲染後的 H1 標籤變成了“Loading…”或“Undefined”,這證明了搜尋引擎抓取到的是中間狀態代碼而非最終內容。
軟件的“Resource”標籤頁會記錄每一個腳本文件(.js)和樣式表(.css)的 HTTP 狀態碼。
如果某些功能腳本返回了 403 Forbidden,通常是因為服務器的防火牆(WAF)誤將爬蟲的 Headless Chrome 行為識別為惡意攻擊並進行了攔截,這將導致整個頁面的佈局和內容無法正常呈現。
| 渲染資源狀態 | 發生原因 | 對抓取的影響 |
|---|---|---|
| Blocked by robots.txt | 腳本路徑被設為 Disallow | Googlebot 無法讀取腳本,渲染失敗 |
| Status Code: 429 | 請求頻率過高導致觸發限流 | 頁面部分資源加載不全,內容缺失 |
| Status Code: 404 | 腳本文件路徑失效 | 依賴該腳本的動態組件無法顯示 |
| Timeout (Exceeded 5s) | 接口響應慢或腳本邏輯複雜 | 抓取到的 HTML 為空或包含錯誤提示 |
軟件提供的 “Rendered Page” 視圖允許用戶並排對比原始代碼快照和渲染後的視覺化快照。
通過這種方式,可以直觀地發現那些被 JavaScript 隱藏的内容,例如位於點擊後才顯示的 Tab 選項卡中的文字。
如果一個頁面的文字內容在原始 HTML 中佔比低於 20%,而 80% 的內容依賴渲染生成,那麼該頁面在 Google 索引庫中的穩定性會面臨挑戰。
Screaming Frog 還可以捕捉到 Console Errors(控制台錯誤),如果頁面在加載過程中產生了致命的 JavaScript 語法錯誤,軟件會在報告中高亮顯示。
在處理數以十萬計的網址時,建議開啟“Store Images”和“Store Rendered HTML”選項,它允許在抓取結束後隨時調取任何一個頁面的渲染快照。
通過分析 “Link Discovery” 差異,可以統計出有多少比例的內鏈是必須運行腳本才能被發現的。
如果這一比例超過 30%,網站的爬行深度(Crawl Depth)會因腳本執行的延遲而變得不可控。
Lumar (DeepCrawl)
Lumar 採用分佈式雲端算力,專門為擁有數百萬個網址的大型站點提供自動化掃描。
在處理需要 JavaScript 執行的任務時,後台通過成千上萬個模擬瀏覽器實例運行。
常規的本地工具受限於物理內存,例如一台 32GB 內存的電腦在運行渲染模式時,通常只能支持 20 到 50 個並行線程。
而 Lumar 在雲端服務器上運行,可以根據任務規模自動擴展到 500 個以上的線程,確保在 24 小時內完成對 100 萬個頁面的完整渲染抓取。
如果一個頁面的腳本運行超過了 5000 毫秒(即 5 秒),系統會將該 URL 標記為“高成本頁面”,因為 Googlebot 在實際訪問中通常不會為單個資源等待過久,這會導致內容在索引庫中出現空白。
在一個標準的 React 或 Vue 項目中,原始 HTML 可能僅包含 2KB 到 5KB 的基礎框架代碼,而渲染後的 DOM 樹(DOM Tree)可能膨脹到 300KB 到 800KB。
這種 100 倍以上的字節增長說明該網頁對腳本的依賴程度極高。
Lumar 提供的指標包括 DOM 節點總數(DOM Node Count),如果節點數超過了 Google 建議的 1500 個,渲染效率會大幅度下降。
通過在雲端記錄 Time to Interactive(可交互時間)和 Total Blocking Time(總阻塞時間),該工具能找出哪些 JS 文件(例如超過 500KB 的單個 vendor.js 包)阻礙了內容的正常顯示。
對於大型電商或跨國站點,通過在不同地區的服務器節點發起請求,可以檢測到某些負責渲染內容的腳本是否因 CDN 配置錯誤而無法在特定區域加載。
數據報告中會列出 4xx 和 5xx 狀態碼的腳本資源比例。
如果一個頁面有 20% 的腳本請求返回了 403 錯誤(通常是因為 robots.txt 攔截或防火牆屏蔽),那麼該頁面的渲染結果就會缺失。
Lumar 的報告系統會生成一份“渲染差異地圖”,詳細標注出在開啟和關閉 JavaScript 的情況下,頁面內鏈數量的變化。
如果關閉腳本後,頁面上的鏈接數從 200 個減少到 0 個,說明該站點的尋址結構完全依賴動態執行,這對 Googlebot 發現新頁面的速度有負面影響。
該平台還支持將抓取到的渲染數據與 Google Search Console 的 API 進行整合。
如果數據顯示字數在渲染後增加了 300%,但搜尋流量沒有相應提升,可能說明動態插入的内容並沒有被 Google 有效識別。
Lumar 會輸出 Rendered Page Word Count 指標,並將其與 Source HTML Word Count 進行對比。
比例差異(Ratio Gap)越大的頁面,在抓取頻率上往往表現得更不穩定。通過對 50 萬個以上的樣本進行觀察,當 Rendering Gap 超過 80% 時,頁面的索引延遲通常會增加 3 到 7 天。


