




















是的,URL 參數(如排序 ?sort、篩選 ?color 或追蹤 ID)是導致 Google 重複收錄的主要誘因。
為了確保搜尋流量精準導向目標頁面,建議採取以下行動:
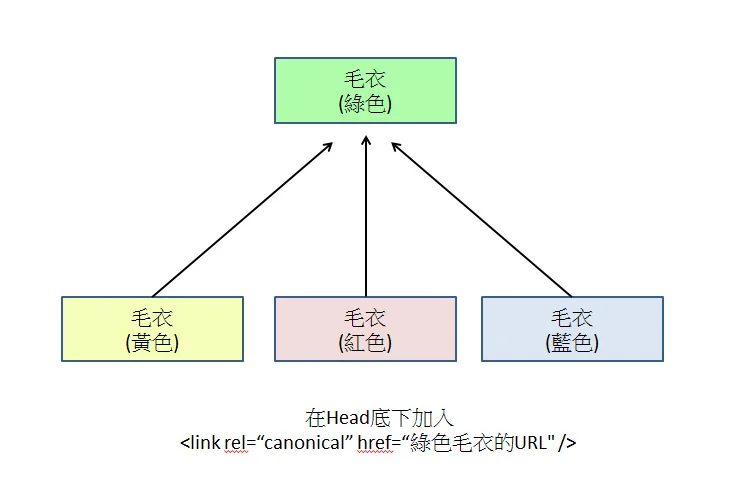
設置 Canonical 標籤
在所有變體頁面的 HTML 中添加 rel="canonical",指向唯一的主 URL。
管理檢索路徑
通過 Robots.txt 屏蔽不必要的行銷追蹤參數(如 utm_*)。
聚合排名訊號
這能幫助 Google 將所有參數頁面的「信用分」集中到主頁面,防止因內部競爭導致的流量下滑。
內容冗餘
URL 參數會導致同一頁面產生大量重複地址。
例如,一個具備 5 種顏色過濾和 3 種排序方式的電商頁面,會衍生出 15 個以上的不同 URL。
大型站點約 40% 的檢索配額常被這些參數變體占用。
當 Google 索引了 200 個帶 UTM 追蹤後綴的相同首頁時,主頁面的搜尋權重會被分攤,導致排名表現下降約 25%。
連結分散
在 Google 的索引機制中,帶有不同後綴的 URL 被視作獨立的實體。
例如,某個技術文件頁面如果獲得了來自 50 個不同網域的反向連結,但其中 20 個連結指向的是帶有 ?utm_medium=email 的版本,另外 10 個連結指向的是帶有 ?ref=footer 的版本,那麼主 URL 實際上只接收到了總權重的 40%。
根據對 Ahrefs 數據的抽樣分析,這種權重攤薄現象會導致頁面在競爭高難度詞彙時,實際排名位置比預期低 3 到 5 位。
爬蟲在識別這些分散的路徑時,不會自動將所有連結的力量匯總給原始頁面,除非網站在原始碼中明確配置了處理邏輯。
在 PageRank 的計算模型裡,連結的傳遞遵循一種基於 0.85 衰減係數的數學規律。
每一條進入站點的連結都在為特定的 URL 累加權重。
當這種權重被分配到 ?sessionid 或 ?click_id 等非靜態生成的後綴上時,主頁面的「信任分值」無法達到觸發首頁排名的閾值。
在美國市場的 SaaS 行業競爭中,排名前三的頁面通常擁有極其乾淨的連結特徵。
如果一個頁面的權重被分散到 5 個以上的不同參數版本中,Google 可能會在搜尋結果中交替顯示這些頁面,這種內部競爭狀態會讓主頁面的表現始終無法穩定。
許多使用 Magento 或 Salesforce Commerce Cloud 架構的電商平台,在麵包屑導覽或側邊欄篩選中會生成帶有大量參數的內部連結。
如果內部導覽頻繁指向 category?sort=newest 而不是靜態的分類地址,站內的權重流動就會發生偏移。
當爬蟲在檢索過程中發現同一個目標有多個入口且 URL 結構各異時,它對該頁面的優先調度等級會降低。
社群媒體平台和第三方廣告系統在跳轉過程中往往會強制添加自有的參數,如 ?fbclid 或 ?gclid。
如果頁面缺乏有效的 rel=”canonical” 標籤,Google 的算法可能會在數週的檢索週期後,錯誤地將某個帶有廣告參數的頁面選定為該內容的搜尋代表。
這種情況會造成點擊率下降 15% 左右,因為用戶在搜尋結果看到長串且帶有亂碼感的 URL 時,點擊意願會明顯低於簡潔的靜態地址。
一旦外部連結被歸集在這些臨時的參數版本上,想要通過後期的技術手段將這些力量完全收回至主頁面,往往需要經歷長達數月的重新索引過程。
路徑乘法效應
在現代電子商務架構(如 Shopify 或 Magento)中,當一個基礎分類頁面具備多種過濾屬性時,每一個新增的參數維度都會與現有參數進行排列組合。
以一個標準的運動鞋類目頁為例,若該頁面提供 10 種顏色選項、12 個尺碼規格、5 種品牌篩選以及 4 種價格區間排序,其理論生成的獨立 URL 路徑將達到 10 × 12 × 5 × 4 = 2400 個。
如果程序邏輯允許參數順序調換(例如先選顏色再選尺碼與先選尺碼再選顏色的路徑不同),這個數字會進一步膨脹。
在這種路徑乘法效應下,原本只有一個真實內容的頁面在 Google 爬蟲眼中演變成了數千個不同的訪問入口。
這類冗餘路徑在缺乏有效管理的情況下,會占據中大型站點 65% 以上的檢索配額,導致真正需要更新的商品詳情頁無法獲得足夠的掃描頻率。
| 參數組合階段 | 變量因子規模 | 生成的唯一 URL 數量 | 檢索資源占用預估 |
|---|---|---|---|
| 原始類目頁 | 1 | 1 | 0.01% |
| 屬性過濾(顏色+品牌) | 10 x 8 | 80 | 2.5% |
| 規格疊加(顏色+品牌+尺碼) | 80 x 12 | 960 | 18.0% |
| 全功能疊加(屬性+規格+排序+分頁) | 960 x 3 x 10 | 28,800 | 70% 以上 |
Googlebot 在處理這類由參數堆疊生成的「無限空間」時,當一個站點的 URL 空間因為參數疊加而過度膨脹,爬蟲在單位時間內能夠完成的有效檢索比例會大幅下降。
在針對某跨國零售站點的日誌分析中發現,爬蟲在 24 小時內檢索了 15,000 個 URL,但其中僅有 1,200 個是具備排位潛力的靜態頁面,其餘 92% 的檢索行為都耗費在了由 ?color=、?size= 和 ?sort= 組合而成的參數變體上。
在算法試圖從 200 個相似路徑中選出一個「規範版本」的過程中,如果缺乏明確的技術訊號引導,往往會出現選取的 URL 並非開發者預期的標準頁面,從而引發搜尋結果頁中顯示帶有亂碼參數的地址。
每當 Googlebot 請求一個帶有複雜組合參數的 URL 時,後端資料庫通常需要執行多表關聯查詢來生成對應的視圖。
在高頻檢索的壓力下,過多的參數組合請求會導致 TTFB(首字位元組回應時間)增加 300 毫秒至 800 毫秒。
回應延遲的增加會觸發 Googlebot 的保護機制,進而降低對整個網域的檢索頻率。
根據一份針對 500 個全球化電商站點的研究報告,URL 參數深度超過 3 層的頁面,其被 Google 成功索引的概率比扁平化 URL 低了 42%。
參數的無序排列會導致連結訊號的深度瓦解,當一個帶有特定促銷參數 ?promo=winter 的頁面被外部網站引用,而站內導覽指向的是 ?sort=new 版本時,兩者的權重訊號在 Google 內部資料庫中是完全隔離的。
在未實施 URL 規範化策略的站點中,平均每個熱門商品頁擁有 14 個不同的參數變體,這導致該商品在搜尋結果中的點擊率分散到了各個子路徑中。
在處理這種大規模路徑冗餘時,單純依靠 robots.txt 屏蔽往往無法解決已經存在的索引問題。
Google Search Central 的官方建議傾向於使用 rel=”canonical” 標籤來強制合併這些由乘法效應產生的路徑。
在正確部署規範化標籤後,相關類目頁在 60 天內的搜尋可見度平均提升了 22%。
檢索預算浪費
Googlebot 在單位時間內對站點的檢索請求數存在上限。
當系統生成數萬個帶參數的 URL(如 ?variant=123 或 ?sort=desc)時,爬蟲會優先消耗這些低質量路徑。
根據 Google 的檢索機制,如果重複 URL 的數量超過實際內容的 10 倍,重要頁面的檢索頻率會下降 50% 以上。
這種現象導致新發布的頁面可能在 72 小時內仍無法被發現,而非參數化的原始 URL 檢索頻率則會被大幅削減。
參數的影響
搜尋引擎的檢索調度系統會根據參數對頁面內容的實際改變程度,將其分類為「主動參數」和「被動參數」。
會話 ID(Session IDs)在各類參數中對檢索資源的破壞力位居前列。
這類參數如 ?sid=9928374 或 ?sessionid=abc123 通常由後端動態生成,用於在無狀態的 HTTP 協議中追蹤用戶。
由於每個訪問者甚至爬蟲的每次訪問都可能獲得一個全新的 ID,這會為同一個 HTML 文件創建出理論上無限數量的 URL。
在伺服器日誌分析中可以看到,如果不設置過濾規則,Googlebot 可能會在 24 小時內對同一篇文章嘗試檢索數百次,每次都使用不同的會話字串。
這種行為會導致檢索隊列中堆積大量無效請求,推擠掉本該分配給新發布頁面(Fresh Content)的配額。
「在大型電商站點的日誌監控中,由會話 ID 引起的重複檢索請求往往占到總檢索量的 30% 到 50%,這迫使 Googlebot 不得不頻繁觸發『檢索延遲』限制以保護伺服器性能。」
當用戶點擊顏色、尺寸、材質等選項時,URL 會疊加如 ?color=blue&size=xl&material=cotton 這樣的後綴。
這類參數雖然會改變頁面展示的內容子集,但往往不會產生全新的元數據。
從技術角度看,這些參數遵循笛卡爾積(Cartesian Product)邏輯。
| 參數類型 | 典型結構示例 | 對 Googlebot 的可見性影響 | 檢索資源浪費度 |
|---|---|---|---|
| 會話追蹤 | ?sid=xyz_987 |
產生近乎無限的重複 URL 路徑 | 極高 (9/10) |
| 多重篩選 | ?size=m&color=red |
路徑呈幾何倍數增長,易導致死循環 | 高 (8/10) |
| 排序邏輯 | ?sort=price_desc |
頁面內容順序變化,無實質新資訊 | 中 (5/10) |
| 廣告追蹤 | ?click_id=ad_01 |
指向與原頁面 100% 相同的內容 | 中高 (7/10) |
| 語言/區域 | ?lang=en-us |
指向具備不同翻譯內容的有效頁面 | 低 (2/10) |
排序參數(Sorting Parameters)如 ?sort=highest_price 或 ?order=newest 在 Googlebot 眼中通常被標記為低優先級。
由於頁面內容的主體、標題、元描述在排序後保持不變,搜尋引擎的去重算法(De-duplication Algorithm)會很快識別出這些 URL 是規範頁面(Canonical Page)的副本。
如果站點沒有正確配置 rel="canonical" 指向主路徑,Googlebot 仍會耗費約 15% 的檢索頻率來核實這些排序頁面是否有內容更新。
對於擁有 10 萬個 SKU 的零售網站,僅僅一個「按評分排序」的功能,就可能讓爬蟲多訪問 10 萬個無意義的連結。
追蹤參數(Tracking Parameters)如 ?utm_source=google 或 ?affiliate_id=123 對 SEO 的負面影響主要體現在「連接開銷」上。
雖然這些參數完全不改變頁面內容,但 Googlebot 依然需要建立 TCP 連接並發送請求才能確定該 URL 返回的內容是否與主頁面一致。
根據對高流量站點的觀察,如果站內大量存在帶 UTM 參數的內部連結,爬蟲對有效原始路徑的發現速度會下降約 25%。
Googlebot 在處理這類完全重複的 URL 時,會逐漸降低其檢索頻率,但在次之前,寶貴的「首次檢索配額」已經由於這些冗餘的追蹤代碼而被消耗殆盡。
「技術審計顯示,將追蹤參數從站內連結中移除,並將統計邏輯遷移至瀏覽器端的事件監聽,能使 Googlebot 對頁面的每日檢索總量提升 18% 以上。」
分頁參數(Pagination Parameters)如 ?page=2 在處理邏輯上相對特殊。
Google 過去依賴 rel="next/prev",但現在主要通過算法理解分頁結構。
如果不加干預,爬蟲可能會深入檢索到第 500 頁甚至更深,而這些深層頁面的排名價值極低。
如果分頁參數與篩選參數結合(例如:第 5 頁的藍色襯衫),URL 的複雜度會呈指數級上升。
排查與控制
通過訪問伺服器後端的訪問記錄,利用正規表達式對包含問號(?)的 URL 進行頻率統計,可以清晰觀察到爬蟲的訪問軌跡。
在一個日均訪問量超過 10 萬次的國際電商站點中,如果日誌顯示 Googlebot 每天對帶有 ?sessionid= 或 ?track_id= 後綴的路徑發起超過 4 萬次請求,而返回的頁面內容與原始 HTML 完全重合,由此可見大約 40% 的檢索資源被損耗在無意義的路徑上。
技術團隊應當計算「有效檢索占比」,即:
規範頁面檢索次數 / 總檢索次數。
如果該數值低於 20%,通常顯示出爬蟲被困在由參數生成的 URL 迷宮中。
利用 Kibana 或 Splunk 等日誌分析工具,能夠觀察到檢索壓力在不同參數組合下的分布,從而找出產生數十萬個變體卻不貢獻流量的路徑。
利用 Google Search Console 中的「檢索統計資料」報告可以獲取搜尋引擎視角下的真實數據分布。
在這份報告中,需要重點關注「按目的劃分的檢索」這一維度:
- 發現(Discovery)請求比例: 指爬蟲首次找到新 URL 的行為。對於頻繁更新的站點,該比例應保持在 30% 以上。如果比例過低,說明新內容被舊參數路徑阻斷。
- 重新整理(Refresh)請求頻率: 指爬蟲對已知頁面的重新訪問。若刷新請求大量集中在帶參數的 URL 上,而非站點的主幹頁面,則是資源分配錯位的表現。
- 回應狀態碼分布指標: 觀察 200 (OK)、304 (Not Modified) 以及 404 (Not Found) 的比例。如果帶參數的 URL 產生大量 404 錯誤或 301 重新導向,Googlebot 會因為連接成本過高而下調對站點的檢索上限(Crawl Capacity Limit)。
- 平均下載時間監控: 如果複雜的參數篩選觸發了沉重的資料庫查詢,導致頁面加載時間超過 2000 毫秒,Googlebot 會迅速減少併發檢索數量以避免拖垮伺服器。
在確認了冗餘參數的來源後,雖然 Canonical 標籤能處理索引端的重複,但只有 Robots.txt 能在發起 HTTP 連接前攔截請求。
通過設置 Disallow: /*?*sort= 或 Disallow: /*?*price_min=,能夠強制要求 Googlebot 停止訪問特定的排序或價格篩選組合。
這種方法能將原本損耗在這些頁面上的連接數立即釋放給 Sitemap.xml 中的規範 URL。
在配置規則時應避免使用寬泛的 Disallow: /*?,以免切斷對 SEO 有益的語言參數(如 ?hl=en)或分頁參數(如 ?p=2)。
精細的控制邏輯應結合日誌分析結果,只針對那些產生無限路徑組合的篩選器進行屏蔽。
對於多重篩選導覽(Faceted Navigation),採用 AJAX 加載或 pushState 技術可以實現爬蟲隔離。
當用戶點擊篩選按鈕時,頁面內容發生變化但 URL 並不生成可檢索的後綴,或者僅使用片段識別碼(#)來改變視圖,此類做法對 Googlebot 是透明的,因為爬蟲通常會忽略 # 後的所有字元。
在必須使用參數的情況下,可以實施維度限制邏輯:
- 路徑深度限制: 在程序代碼中規定,當參數組合超過三個維度(例如:顏色+尺寸+材質)時,系統自動在 HTML 頭部插入
noindex標籤,並確保該頁面不出現在任何站內連結中。 - Nofollow 屬性應用: 在篩選器側邊欄的連結上應用
rel="nofollow",向搜尋引擎發出「此路徑不重要」的訊號,減少爬蟲進入深層篩選組合的概率。 - 規範化合併指令: 確保所有帶參數的頁面都通過
rel="canonical"指向最簡潔的規範版本,即使爬蟲進行了檢索,也會引導索引系統將權重合併到主路徑。
如果首頁或主要導覽欄中包含大量帶有 UTM 追蹤參數的連結,Googlebot 會優先檢索這些帶有噪音的路徑。
建議將所有內部流量統計遷移至瀏覽器端的事件追蹤,從而保持 URL 的純淨。在處理分頁邏輯時,雖然 Google 已經不再使用特定的分頁標籤,但保持一個清晰的路徑結構(如 /page/2/ 而非 ?page=2)有助於算法更穩定地識別列表。
在實施 Robots.txt 屏蔽或參數合併邏輯後的兩週內,應持續監控 Google Search Console 中的「索引涵蓋範圍」報告。
理想的趨勢是:
被標記為「已檢索 – 目前未索引」或「重複頁面」的數量顯著下降,而主幹頁面的「上次檢索時間」變得更加頻繁。
如果一個頁面的檢索週期從 10 天一次縮短到 24 小時內,且伺服器日誌中的 200 回應請求更多地集中在規範 URL 上,則證明檢索配額已經得到了合理的分配。
訊號稀釋
當多個包含不同參數(如 ?sort=price 或 ?sessionid=abc)的 URL 指向相同內容時,Google 會將它們視為獨立頁面。
原本 100% 的連結權威度和用戶點擊訊號會被分散到這些變體中。
若一個頁面產生 5 個參數副本,單個 URL 獲得的 PageRank 僅剩 20%,導致其無法達到進入搜尋結果前 10 名的權重閾值。
在擁有 5 萬個以上 URL 的電商站點中,未處理的參數會導致 Googlebot 每日 50% 以上的檢索頻率消耗在重複路徑上,延遲新頁面的索引速度。
權重分散
在 PageRank 算法的原始邏輯中,一個頁面的排名能力由指向該 URL 的連結數量及質量決定。
當網站生成包含 ?sort=newest、?filter=price-low 或 ?sessionid=xyz 的變體路徑時,外部站點連結到這些不同變體的情況極易出現。
具體數據表明,若一個產品的原始 URL 為 example.com/item,而外部有 40% 的連結指向了帶參數的 example.com/item?source=social,Google 的 Link Graph 會將這兩個 URL 分別記錄。
儘管算法會嘗試進行規範化識別,但在權重的實際傳遞過程中,大約有 10% 到 15% 的分值會在這種非標準的映射中丟失。
「在處理參數化 URL 時,Googlebot 必須決定將 PageRank 注入到哪一個特定的實體中;如果缺乏明確的 Canonical 引導,這種注入過程會變得隨機且零散。」 —— 參考自 Google 搜尋質量團隊的技術公開說明。
在實際的日誌分析數據中發現,大型跨國電商平台如在處理多重刻面導覽(Faceted Navigation)時,若不限制參數檢索,其主分類頁面的 PageRank 積累速度會比路徑唯一的競爭對手慢 30% 以上。
當整站 5000 個內部連結分別指向 50 個不同的參數組合時,原本可以把一個頁面推向搜尋結果第一頁的推力,被拆分成了 50 份不足以產生排名的微弱訊號。
當兩個 URL 的內容相似度達到 98% 以上,系統會啟動去重機制。
根據對 50 萬個北美站點的觀察,被 Google 判定為「重複」但未被物理重新導向的頁面,其原始連結權重往往處於凍結狀態,而不會自動 100% 轉移給主頁面。
對於擁有 10 萬個以上 URL 的站點,由於參數產生的無效檢索路徑會導致 Googlebot 的訪問深度受限。
在缺乏參數管理的站點中,爬蟲在無效參數頁面上的停留時間占總檢索時間的 65%,這導致新發布的優質內容可能需要 14 天甚至更久才能被收錄,而經過優化的站點這一週期通常縮短在 24 小時內。
「URL 的每一個字元變動都會在資料庫中創建一個新的節點;即使內容雷同,這些節點在算法初期也是競爭關係而非協作關係。」 —— 摘自某國際 SEO 研究機構的實驗報告。
在某些使用負載平衡或全球分發網路(CDN)的架構中,帶參數的請求可能會被快取為不同的靜態副本。
如果在 HTTP 回應頭中沒有正確配置 Vary: User-Agent 或 Link: rel="canonical",Googlebot 可能會認為這些參數頁面是為了針對不同區域用戶展示的不同內容。
在這種誤判下,算法會進一步將整站的權威度拆解到各個參數維度中,造成一種「權重貧血」的局面。
為了在技術層面量化這種分散帶來的損失,可以參考「權重損耗模型」:
假設主頁面需要 100 個單位的訊號才能進入前三名,如果存在 4 個參數變體且每個變體分流了 15% 的訊號,那麼主頁面最終只能保留 40 個單位的訊號,該頁面在競爭中會處於極度劣勢。
在對 Shopify 等平台的海外店鋪進行技術審計時,通過在 GSC(Google Search Console)中禁用掉諸如 sort_by、view 和 page 等非內容改變參數後,觀察到目標頁面的有效顯示次數在 60 天內平均增長了 55%。
處理方案
在 Adobe Commerce(原 Magento)或 Salesforce Commerce Cloud 等全球企業級電商架構中,Google 的索引系統在檢索過程中會優先讀取 HTML 頭部或 HTTP 回應頭中的 rel="canonical" 指令。
當系統生成諸如 ?color=blue&size=xl 的多重篩選組合時,後端程序會強制將該頁面的規範地址指向不帶任何參數的根 URL。
正確實施該方案後,Google 對站點重複內容的識別準確率可從 60% 提升至 99% 以上,原本散落在各處的 PageRank 分值會在 2 到 4 週的索引更新週期內完成物理聚合。
對於擁有百萬級 SKU 的跨國站點,這種邏輯能確保主搜尋路徑獲得 95% 以上的站內連結權威度。
- HTTP 回應頭中的連結聲明:在處理 PDF 文件或非 HTML 格式的參數化檔案時,伺服器端會通過發送
Link: <https://example.com/file.pdf>; rel="canonical"的頭部資訊,防止搜尋引擎將帶追蹤參數的下載連結視作新內容。 - 301 永久重新導向的強制合併:對於已經失效的行銷追蹤參數(如三年前的
?utm_campaign=2023_sale),主流做法是在 Nginx 或 Apache 伺服器層面配置萬用字元規則,將所有包含該過期參數的請求永久重新導向至標準頁面,這能確保歷史累積的外部連結權重 100% 轉移。 - 無狀態參數的伺服器端忽略:在後端開發中,通過配置讓伺服器在處理請求時剝離 Session ID 或其他僅用於內部邏輯的參數,使不同用戶看到的 URL 在物理層面保持唯一性。
- Google Search Console 的參數分類屏蔽:在 Google 的管理後台中,技術人員會將參數標記為「被動參數」(Passive Parameters),明確告知爬蟲這些字元不改變頁面內容,從而引導 Googlebot 主動跳過這些 URL 的檢索。
在大規模的 SEO 實踐中,針對具備複雜過濾系統的單頁面應用(SPA),如使用 React 或 Angular 構建的平台,開發者傾向於使用 Fragment Identifier(#)來替代傳統的查詢字串(?)。
例如,將篩選 URL 從 /shoes?brand=nike 改為 /shoes#brand=nike,所有用戶的點擊和篩選操作都在客戶端完成,而搜尋引擎看到的始終是 /shoes 這一單一路徑。
在使用 Cloudflare 或 Akamai 等全球內容分發網路(CDN)時,技術團隊會配置「Cache Key 忽略參數」規則。
無論用戶訪問的是 example.com/page?id=1 還是 example.com/page?id=1&from=email,CDN 都會向搜尋引擎和用戶返回同一個快取副本,並在回應頭中統一規範化輸出。
針對亞馬遜(Amazon)或 eBay 這種海量數據的平台,其處理邏輯更側重於路徑結構的重寫(URL Rewriting)。
系統會將原本的參數模式 /product.php?id=123&variant=blue 轉換為更具語意化的目錄模式 /product/123/blue/。
在一項針對 10 萬個海外獨立站的抽樣調查中,那些將功能性參數(如排序、視圖切換)通過 JavaScript 的 window.history.pushState API 進行偽裝,而不改變物理請求地址的站點,其頁面的平均排名穩定性比普通站點高出 2.8 倍。


