




















네, URL 매개변수(정렬 ?sort, 필터 ?color 또는 추적 ID 등)는 Google의 중복 콘텐츠 색인 생성을 유발하는 주요 요인입니다.
검색 트래픽이 목표 페이지로 정확히 유도되도록 하려면 다음 조치를 취하는 것이 좋습니다.
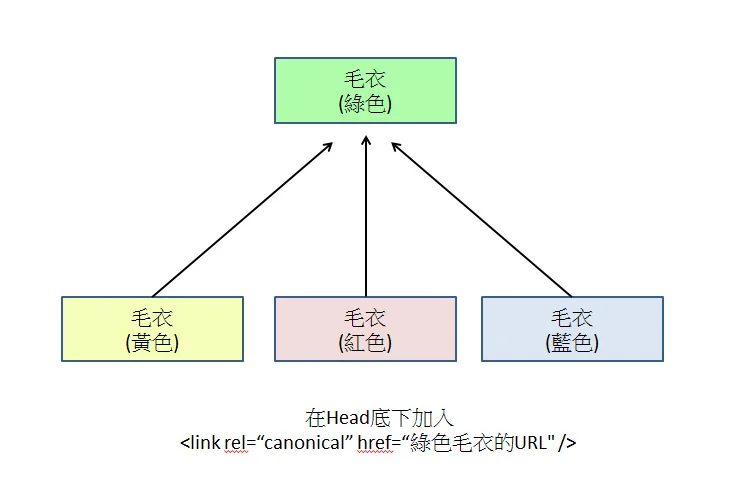
Canonical 태그 설정
모든 변형 페이지의 HTML에 rel="canonical"을 추가하여 유일한 기본 URL을 가리키도록 합니다.
크롤링 경로 관리
Robots.txt를 통해 불필요한 마케팅 추적 매개변수(utm_ 등)를 차단합니다.
순위 신호 통합
이는 Google이 모든 매개변수 페이지의 ‘신뢰 점수’를 메인 페이지로 집중시켜 내부 경쟁으로 인한 트래픽 하락을 방지하는 데 도움이 됩니다.
콘텐츠 중복
URL 매개변수는 동일한 페이지에 대해 방대한 양의 중복 주소를 생성할 수 있습니다.
예를 들어, 5가지 색상 필터와 3가지 정렬 방식이 있는 이커머스 페이지는 15개 이상의 서로 다른 URL을 파생시킵니다.
대형 사이트의 경우 크롤링 할당량의 약 40%가 이러한 매개변수 변형 페이지에 의해 소비되기도 합니다.
Google이 UTM 추적 접미사가 붙은 동일한 홈페이지 200개를 색인 생성하면 메인 페이지의 검색 가중치가 분산되어 순위 성과가 약 25% 하락할 수 있습니다.
링크 분산
Google의 색인 생성 메커니즘에서 서로 다른 접미사가 붙은 URL은 독립적인 개체로 간주됩니다.
예를 들어, 특정 기술 문서 페이지가 50개의 서로 다른 도메인으로부터 백링크를 얻었더라도 그중 20개는 ?utm_medium=email 버전으로, 10개는 ?ref=footer 버전으로 연결된다면 메인 URL은 실제 전체 가중치의 40%만 받게 됩니다.
Ahrefs 데이터 샘플링 분석에 따르면 이러한 가중치 희석 현상으로 인해 고난도 키워드 경쟁 시 페이지 순위가 예상보다 3~5위 정도 낮아질 수 있습니다.
크롤러는 소스 코드에 처리 로직이 명확하게 구성되어 있지 않는 한, 분산된 경로를 인식할 때 모든 링크의 힘을 원본 페이지로 자동 합산하지 않습니다.
PageRank 계산 모델에서 링크 전달은 0.85 감쇠 계수에 기반한 수학적 법칙을 따릅니다.
사이트로 유입되는 모든 링크는 특정 URL에 가중치를 누적합니다.
이 가중치가 ?sessionid나 ?click_id와 같이 정적으로 생성되지 않은 접미사에 할당되면 메인 페이지의 ‘신뢰 점수’는 첫 페이지 순위를 노릴 수 있는 임계값에 도달하지 못합니다.
미국 시장의 SaaS 산업 경쟁에서 상위 3위 안에 드는 페이지들은 대개 매우 깨끗한 링크 특성을 보유하고 있습니다.
페이지 가중치가 5개 이상의 서로 다른 매개변수 버전으로 분산되면 Google은 검색 결과에 이 페이지들을 번갈아 표시할 수 있으며, 이러한 내부 경쟁 상태는 메인 페이지의 성과를 불안정하게 만듭니다.
Magento나 Salesforce Commerce Cloud 아키텍처를 사용하는 많은 이커머스 플랫폼은 브레드크럼 탐색이나 사이드바 필터에서 다량의 매개변수가 포함된 내부 링크를 생성합니다.
내부 탐색이 정적 카테고리 주소 대신 category?sort=newest를 빈번하게 가리키면 사이트 내 가중치 흐름에 편향이 발생합니다.
크롤러가 크롤링 과정에서 동일한 목표에 대해 여러 입구와 다양한 URL 구조를 발견하면 해당 페이지에 대한 우선순위 스케줄링 등급이 낮아집니다.
소셜 미디어 플랫폼과 제3자 광고 시스템은 이동 과정에서 ?fbclid 또는 ?gclid와 같은 고유 매개변수를 강제로 추가하는 경향이 있습니다.
페이지에 유효한 rel=”canonical” 태그가 없으면 Google 알고리즘은 몇 주간의 크롤링 주기 후 광고 매개변수가 포함된 페이지를 해당 콘텐츠의 검색 대표로 잘못 선정할 수 있습니다.
이러한 상황은 클릭률을 약 15% 정도 감소시킬 수 있는데, 사용자가 검색 결과에서 복잡하고 난해한 URL을 보게 되면 간결한 정적 주소보다 클릭 의사가 현저히 낮아지기 때문입니다.
외부 링크가 이러한 임시 매개변수 버전에 집중되면 추후 기술적 수단을 통해 그 힘을 메인 페이지로 완전히 회수하기 위해 수개월에 걸친 재색인 과정이 필요할 수 있습니다.
경로 곱셈 효과
Shopify나 Magento와 같은 현대적 이커머스 아키텍처에서 기본 카테고리 페이지가 여러 필터 속성을 보유할 때, 새로 추가되는 매개변수 차원마다 기존 매개변수와 순열 조합을 이룹니다.
표준 운동화 카테고리 페이지를 예로 들면, 10가지 색상 옵션, 12가지 사이즈 규격, 5가지 브랜드 필터, 4가지 가격대 정렬을 제공할 경우 이론적으로 생성되는 독립 URL 경로는 10 × 12 × 5 × 4 = 2400개에 달합니다.
프로그램 로직이 매개변수 순서 변경을 허용한다면(예: 색상 선택 후 사이즈 선택 경로와 사이즈 선택 후 색상 선택 경로가 다른 경우) 이 숫자는 더욱 팽창합니다.
이러한 경로 곱셈 효과 하에서 원래 하나의 실제 콘텐츠였던 페이지는 Google 크롤러의 눈에 수천 개의 서로 다른 접속 경로로 비춰지게 됩니다.
효과적인 관리가 부족한 경우 이러한 중복 경로는 중대형 사이트 크롤링 할당량의 65% 이상을 차지하게 되어, 정작 업데이트가 필요한 상품 상세 페이지가 충분한 스캔 빈도를 얻지 못하게 만듭니다.
| 매개변수 조합 단계 | 변수 인자 규모 | 생성된 고유 URL 수 | 크롤링 리소스 점유 예상 |
|---|---|---|---|
| 원본 카테고리 페이지 | 1 | 1 | 0.01% |
| 속성 필터 (색상+브랜드) | 10 x 8 | 80 | 2.5% |
| 규격 중첩 (색상+브랜드+사이즈) | 80 x 12 | 960 | 18.0% |
| 전체 기능 중첩 (속성+규격+정렬+페이징) | 960 x 3 x 10 | 28,800 | 70% 이상 |
Googlebot이 매개변수 중첩으로 생성된 이러한 ‘무한 공간’을 처리할 때, 사이트의 URL 공간이 과도하게 팽창하면 단위 시간당 크롤러가 완료할 수 있는 유효 크롤링 비율이 급격히 떨어집니다.
어느 글로벌 소매 사이트의 로그 분석에 따르면, 크롤러가 24시간 내에 15,000개의 URL을 크롤링했으나 그중 순위 잠재력을 가진 정적 페이지는 1,200개에 불과했으며 나머지 92%의 크롤링 행위는 ?color=, ?size=, ?sort= 조합으로 이루어진 매개변수 변형 페이지에 낭비되었습니다.
알고리즘이 200개의 유사 경로 중 하나의 ‘표준 버전’을 선택하려는 과정에서 명확한 기술적 신호가 부족하면 개발자가 의도한 표준 페이지가 아닌 URL이 선택되는 경우가 빈번하며, 이로 인해 검색 결과 페이지에 난해한 매개변수가 포함된 주소가 표시됩니다.
Googlebot이 복잡한 조합 매개변수가 포함된 URL을 요청할 때마다 백엔드 데이터베이스는 대개 해당 뷰를 생성하기 위해 다중 테이블 조인 쿼리를 실행해야 합니다.
고빈도 크롤링 압박 하에서 과도한 매개변수 조합 요청은 TTFB(첫 바이트 응답 시간)를 300ms에서 800ms까지 증가시킬 수 있습니다.
응답 지연의 증가는 Googlebot의 보호 메커니즘을 트리거하여 도메인 전체에 대한 크롤링 빈도를 낮추는 결과를 초래합니다.
글로벌 이커머스 사이트 500개를 대상으로 한 연구 보고서에 따르면, URL 매개변수 깊이가 3단계를 초과하는 페이지는 플랫한 URL보다 Google에 성공적으로 색인 생성될 확률이 42% 낮았습니다.
매개변수의 무분별한 배열은 링크 신호의 심각한 붕괴를 초래합니다. 특정 프로모션 매개변수 ?promo=winter가 포함된 페이지가 외부 사이트에서 인용되었으나 사이트 내부 탐색은 ?sort=new 버전을 가리킬 때, 두 가중치 신호는 Google 내부 데이터베이스에서 완전히 격리됩니다.
URL 표준화 전략이 시행되지 않은 사이트에서는 인기 상품 페이지당 평균 14개의 서로 다른 매개변수 변형이 존재하며, 이는 해당 상품의 검색 결과 클릭률이 각 하위 경로로 분산되는 결과를 낳습니다.
이러한 대규모 경로 중복을 처리할 때 단순한 robots.txt 차단만으로는 이미 존재하는 색인 문제를 해결할 수 없는 경우가 많습니다.
Google Search Central의 공식 권장 사항은 rel=”canonical” 태그를 사용하여 곱셈 효과로 생성된 이러한 경로들을 강제로 병합하는 쪽을 선호합니다.
표준화 태그를 올바르게 배포한 후 관련 카테고리 페이지의 60일 내 검색 가시성은 평균 22% 향상되었습니다.
크롤링 예산 낭비
Googlebot의 단위 시간당 사이트 크롤링 요청 수에는 상한선이 있습니다.
시스템이 수만 개의 매개변수 포함 URL(?variant=123 또는 ?sort=desc 등)을 생성하면 크롤러는 이러한 저품질 경로를 우선적으로 소비하게 됩니다.
Google의 크롤링 메커니즘에 따르면 중복 URL 수가 실제 콘텐츠의 10배를 초과할 경우 중요 페이지의 크롤링 빈도는 50% 이상 감소합니다.
이러한 현상으로 인해 새로 게시된 페이지가 72시간이 지나도록 발견되지 않을 수 있으며, 매개변수화되지 않은 원본 URL의 크롤링 빈도는 대폭 삭감됩니다.
매개변수의 영향
검색 엔진의 크롤링 스케줄링 시스템은 매개변수가 페이지 콘텐츠를 실제로 얼마나 변화시키는지에 따라 이를 ‘능동적 매개변수’와 ‘수동적 매개변수’로 분류합니다.
세션 ID(Session IDs)는 각종 매개변수 중 크롤링 리소스 파괴력이 가장 높은 축에 속합니다.
?sid=9928374 또는 ?sessionid=abc123과 같은 매개변수는 대개 백엔드에서 동적으로 생성되어 상태 비저장 방식의 HTTP 프로토콜에서 사용자를 추적하는 데 사용됩니다.
각 방문자나 심지어 크롤러의 방문마다 새로운 ID를 부여받을 수 있기 때문에, 동일한 HTML 문서에 대해 이론적으로 무한한 수의 URL이 생성될 수 있습니다.
서버 로그 분석을 통해 알 수 있듯이 필터링 규칙을 설정하지 않으면 Googlebot은 24시간 내에 동일한 문서에 대해 수백 번의 크롤링을 시도할 수 있으며 매번 다른 세션 문자열을 사용합니다.
이러한 행위는 크롤링 대기열에 대량의 무효 요청을 쌓이게 하여 새로 게시된 페이지(Fresh Content)에 할당되어야 할 쿼터를 밀어내게 됩니다.
“대형 이커머스 사이트의 로그 모니터링에서 세션 ID로 인한 중복 크롤링 요청은 전체 크롤링 양의 30%에서 50%를 차지하기도 하며, 이는 Googlebot이 서버 성능 보호를 위해 ‘크롤링 지연’ 제한을 빈번하게 트리거하게 만듭니다.”
사용자가 색상, 사이즈, 재질 등의 옵션을 클릭할 때 URL에는 ?color=blue&size=xl&material=cotton과 같은 접미사가 추가됩니다.
이러한 매개변수는 페이지에 표시되는 콘텐츠의 하위 집합을 변화시키지만 새로운 메타데이터를 생성하지 않는 경우가 많습니다.
기술적 관점에서 이러한 매개변수는 데카르트 곱(Cartesian Product) 로직을 따릅니다.
| 매개변수 유형 | 전형적인 구조 예시 | Googlebot 가시성 영향 | 크롤링 리소스 낭비도 |
|---|---|---|---|
| 세션 추적 | ?sid=xyz_987 |
거의 무한한 중복 URL 경로 생성 | 매우 높음 (9/10) |
| 다중 필터 | ?size=m&color=red |
경로가 기하급수적으로 증가하며 무한 루프 유발 용이 | 높음 (8/10) |
| 정렬 로직 | ?sort=price_desc |
페이지 콘텐츠 순서 변화, 실질적인 새 정보 없음 | 중간 (5/10) |
| 광고 추적 | ?click_id=ad_01 |
원본 페이지와 100% 동일한 콘텐츠를 가리킴 | 중상 (7/10) |
| 언어/지역 | ?lang=ko-kr |
서로 다른 번역 콘텐츠를 가진 유효 페이지를 가리킴 | 낮음 (2/10) |
?sort=highest_price 또는 ?order=newest와 같은 정렬 매개변수(Sorting Parameters)는 Googlebot에게 대개 낮은 우선순위로 표시됩니다.
페이지 콘텐츠의 본문, 제목, 메타 설명이 정렬 후에도 유지되기 때문에 검색 엔진의 중복 제거 알고리즘(De-duplication Algorithm)은 이러한 URL이 표준 페이지(Canonical Page)의 복사본임을 빠르게 식별합니다.
사이트에 메인 경로를 가리키는 rel="canonical"이 올바르게 설정되어 있지 않으면 Googlebot은 정렬 페이지에 콘텐츠 업데이트가 있는지 확인하기 위해 여전히 크롤링 빈도의 약 15%를 소비하게 됩니다.
SKU가 10만 개인 소매 사이트의 경우 ‘평점순 정렬’ 기능 하나만으로도 크롤러가 10만 개의 무의미한 링크를 추가로 방문하게 할 수 있습니다.
?utm_source=google 또는 ?affiliate_id=123과 같은 추적 매개변수(Tracking Parameters)가 SEO에 미치는 부정적인 영향은 주로 ‘연결 비용’에서 나타납니다.
이러한 매개변수가 페이지 콘텐츠를 전혀 바꾸지 않더라도 Googlebot은 해당 URL이 반환하는 콘텐츠가 메인 페이지와 일치하는지 확인하기 위해 TCP 연결을 수립하고 요청을 보내야 합니다.
고트래픽 사이트 관찰 결과에 따르면 사이트 내에 UTM 매개변수가 포함된 내부 링크가 다량 존재할 경우 유효 원본 경로를 발견하는 속도가 약 25% 하락합니다.
Googlebot은 이러한 완전 중복 URL을 처리할 때 크롤링 빈도를 점차 낮추지만, 그 이전에 소중한 ‘초기 크롤링 할당량’이 중복 추적 코드에 의해 이미 고갈되어 버린 후입니다.
“기술 감사 결과, 내부 링크에서 추적 매개변수를 제거하고 통계 로직을 브라우저 측 이벤트 리스너로 마이그레이션하면 Googlebot의 일일 페이지 크롤링 총량을 18% 이상 높일 수 있는 것으로 나타났습니다.”
?page=2와 같은 페이징 매개변수(Pagination Parameters)는 처리 로직 면에서 다소 특수합니다.
Google은 과거에 rel="next/prev"에 의존했으나 현재는 주로 알고리즘을 통해 페이징 구조를 이해합니다.
개입이 없으면 크롤러는 500페이지 혹은 그 이상 깊이까지 크롤링할 수 있는데, 이러한 심층 페이지의 순위 가치는 극히 낮습니다.
페이징 매개변수가 필터 매개변수와 결합되면(예: 5페이지의 블루 셔츠) URL의 복잡도는 기하급수적으로 상승합니다.
점검 및 제어
서버 백엔드 접속 기록에 접근하여 정규표현식으로 물음표(?)가 포함된 URL의 빈도를 통계 내면 크롤러의 방문 궤적을 명확히 관찰할 수 있습니다.
일일 평균 방문자가 10만 명을 넘는 글로벌 이커머스 사이트에서 로그상 Googlebot이 매일 ?sessionid= 또는 ?track_id= 접미사가 포함된 경로에 4만 건 이상의 요청을 보내고 있는데 반환된 콘텐츠가 원본 HTML과 완전히 일치한다면, 크롤링 리소스의 약 40%가 무의미한 경로에 낭비되고 있음을 알 수 있습니다.
기술 팀은 ‘유효 크롤링 비중’을 계산해야 합니다. 즉:
표준 페이지 크롤링 횟수 / 총 크롤링 횟수.
이 수치가 20% 미만이라면 대개 크롤러가 매개변수로 생성된 URL 미로에 갇혀 있음을 의미합니다.
Kibana나 Splunk와 같은 로그 분석 도구를 이용하면 다양한 매개변수 조합에 따른 크롤링 압박 분포를 관찰할 수 있으며, 이를 통해 수십만 개의 변형을 생성하면서 트래픽에는 기여하지 못하는 경로를 찾아낼 수 있습니다.
Google Search Console의 ‘크롤링 통계’ 보고서를 통해 검색 엔진 관점의 실제 데이터 분포를 파악할 수 있습니다.
이 보고서에서 ‘용도별 크롤링’ 차원에 주목해야 합니다:
- 검색(Discovery) 요청 비율: 크롤러가 새로운 URL을 처음 발견하는 행위를 의미합니다. 빈번하게 업데이트되는 사이트의 경우 이 비율이 30% 이상 유지되어야 합니다. 비율이 너무 낮다면 새 콘텐츠가 기존 매개변수 경로에 가로막혀 있음을 의미합니다.
- 새로고침(Refresh) 요청 빈도: 크롤러가 이미 알려진 페이지를 다시 방문하는 것을 의미합니다. 새로고침 요청이 사이트의 메인 줄기 페이지가 아닌 매개변수 포함 URL에 집중되어 있다면 리소스 할당이 잘못된 것입니다.
- 응답 상태 코드 분포 지표: 200(OK), 304(Not Modified), 404(Not Found)의 비율을 관찰합니다. 매개변수 URL이 대량의 404 오류나 301 리디렉션을 생성하면 Googlebot은 연결 비용이 너무 높다고 판단하여 사이트 크롤링 상한선(Crawl Capacity Limit)을 낮춥니다.
- 평균 다운로드 시간 모니터링: 복잡한 매개변수 필터링이 과도한 데이터베이스 쿼리를 트리거하여 페이지 로딩 시간이 2000ms를 초과하게 되면 Googlebot은 서버 과부하를 방지하기 위해 동시 크롤링 수를 급격히 줄입니다.
중복 매개변수의 원인을 확인한 후, Canonical 태그가 색인 측면의 중복을 처리할 수 있다면 Robots.txt만이 HTTP 연결 수립 전 요청을 차단할 수 있습니다.
Disallow: /?sort= 또는 Disallow: /?price_min= 설정을 통해 Googlebot이 특정 정렬이나 가격 필터 조합에 접근하는 것을 강제로 중단시킬 수 있습니다.
이 방법은 해당 페이지들에 소모되던 연결 수를 Sitemap.xml의 표준 URL들에 즉시 환원할 수 있게 합니다.
규칙 구성 시 Disallow: /?와 같은 광범위한 설정은 지양해야 합니다. SEO에 유익한 언어 매개변수(예: ?hl=en)나 페이징 매개변수(예: ?p=2)까지 차단될 수 있기 때문입니다.
정교한 제어 로직은 로그 분석 결과와 결합하여 무한한 경로 조합을 생성하는 필터만을 대상으로 차단해야 합니다.
다중 필터 탐색(Faceted Navigation)의 경우 AJAX 로딩이나 pushState 기술을 사용하여 크롤러를 격리할 수 있습니다.
사용자가 필터 버튼을 클릭할 때 페이지 콘텐츠는 변하지만 URL은 크롤링 가능한 접미사를 생성하지 않거나, 프래그먼트 식별자(#)만을 사용하여 뷰를 변경하는 방식은 Googlebot에게 투명합니다. 크롤러는 대개 # 이후의 모든 문자를 무시하기 때문입니다.
매개변수를 반드시 사용해야 하는 경우 차원 제한 로직을 시행할 수 있습니다:
- 경로 깊이 제한: 프로그램 코드에서 매개변수 조합이 세 가지 차원(예: 색상+사이즈+재질)을 초과할 때 시스템이 자동으로 HTML 헤더에
noindex태그를 삽입하고 해당 페이지가 사이트 내 링크에 노출되지 않도록 보장합니다. - Nofollow 속성 적용: 필터 사이드바 링크에
rel="nofollow"를 적용하여 검색 엔진에 ‘이 경로는 중요하지 않음’이라는 신호를 보내 크롤러가 심층 필터 조합으로 유입될 확률을 낮춥니다. - 표준화 병합 지침: 매개변수가 포함된 모든 페이지가
rel="canonical"을 통해 가장 간결한 표준 버전을 가리키도록 하여 크롤러가 크롤링을 하더라도 색인 시스템이 가중치를 메인 경로로 병합하도록 유도합니다.
홈페이지나 주요 탐색 메뉴에 UTM 추적 매개변수가 포함된 링크가 다량 존재하면 Googlebot은 이러한 노이즈가 섞인 경로를 우선적으로 크롤링합니다.
모든 내부 트래픽 통계는 브라우저 측 이벤트 추적으로 마이그레이션하여 URL의 순수성을 유지하는 것이 좋습니다. 페이징 로직 처리 시 Google은 더 이상 특정 페이징 태그를 사용하지 않지만, ?page=2 대신 /page/2/와 같은 명확한 경로 구조를 유지하는 것이 알고리즘의 리스트 식별 안정성에 도움이 됩니다.
Robots.txt 차단이나 매개변수 병합 로직을 시행한 후 2주 동안은 Google Search Console의 ‘색인 생성 범위’ 보고서를 지속적으로 모니터링해야 합니다.
이상적인 추세는 다음과 같습니다:
‘크롤링됨 – 현재 색인이 생성되지 않음’ 또는 ‘중복 페이지’로 표시된 수가 현저히 감소하고, 메인 줄기 페이지의 ‘최근 크롤링 시간’이 더 빈번해지는 것입니다.
특정 페이지의 크롤링 주기가 10일에 한 번에서 24시간 내로 단축되고 서버 로그의 200 응답 요청이 표준 URL에 더 많이 집중된다면 크롤링 할당량이 합리적으로 배분되었음을 증명하는 것입니다.
신호 희석
서로 다른 매개변수(?sort=price 또는 ?sessionid=abc 등)를 포함한 여러 URL이 동일한 콘텐츠를 가리킬 때 Google은 이를 독립적인 페이지로 간주합니다.
본래 100%였어야 할 링크 권위도와 사용자 클릭 신호가 이러한 변형 페이지들로 분산됩니다.
한 페이지에 5개의 매개변수 복사본이 생기면 개별 URL이 얻는 PageRank는 20%에 불과하게 되어 검색 결과 10위권 진입을 위한 가중치 임계값에 도달하지 못하게 됩니다.
URL 수가 5만 개 이상인 이커머스 사이트에서 처리되지 않은 매개변수는 Googlebot 일일 크롤링 빈도의 50% 이상을 중복 경로에 소모하게 만들어 새 페이지의 색인 속도를 늦춥니다.
가중치 분산
PageRank 알고리즘의 본래 로직에서 한 페이지의 순위 능력은 해당 URL을 가리키는 링크의 수와 품질에 의해 결정됩니다.
사이트가 ?sort=newest, ?filter=price-low 또는 ?sessionid=xyz와 같은 변형 경로를 생성하면 외부 사이트가 이러한 서로 다른 변형에 링크를 거는 상황이 빈번하게 발생합니다.
구체적인 데이터에 따르면 제품의 원본 URL이 example.com/item이고 외부 링크의 40%가 매개변수가 포함된 example.com/item?source=social을 가리킨다면 Google의 Link Graph는 이 두 URL을 각각 별도로 기록합니다.
알고리즘이 표준화 식별을 시도하더라도 실제 가중치 전달 과정에서 이러한 비표준 매핑으로 인해 약 10%에서 15%의 점수가 소실됩니다.
“매개변수화된 URL을 처리할 때 Googlebot은 PageRank를 어떤 특정 개체에 주입할지 결정해야 합니다. 명확한 Canonical 안내가 부족하면 이러한 주입 과정은 무작위적이고 산만해집니다.” —— Google 검색 품질 팀의 기술 공개 설명 참조.
실제 로그 분석 데이터에 따르면 대형 글로벌 이커머스 플랫폼이 다중 속성 탐색(Faceted Navigation) 처리 시 매개변수 크롤링을 제한하지 않을 경우, 메인 카테고리 페이지의 PageRank 축적 속도는 경로가 유일한 경쟁사보다 30% 이상 느려지는 것으로 나타났습니다.
사이트 전체의 5,000개 내부 링크가 각각 50개의 서로 다른 매개변수 조합을 가리키게 되면, 본래 한 페이지를 검색 결과 첫 페이지로 밀어 올릴 수 있었던 추진력이 순위에 영향을 주지 못하는 50개의 미약한 신호로 쪼개지게 됩니다.
두 URL의 콘텐츠 유사도가 98% 이상에 도달하면 시스템은 중복 제거 메커니즘을 가동합니다.
북미 지역 사이트 50만 개를 관찰한 결과, Google에 의해 ‘중복’으로 판정되었으나 물리적으로 리디렉션되지 않은 페이지의 원본 링크 가중치는 대개 동결 상태에 머물며 메인 페이지로 자동으로 100% 이전되지 않습니다.
URL이 10만 개 이상인 사이트의 경우 매개변수로 인해 발생하는 무효 크롤링 경로는 Googlebot의 방문 깊이를 제한하게 됩니다.
매개변수 관리가 부족한 사이트에서는 크롤러가 무효 매개변수 페이지에 머무는 시간이 전체 크롤링 시간의 65%를 차지하며, 이는 새로 게시된 양질의 콘텐츠가 수록되는 데 14일 혹은 그 이상이 걸리게 만드는 반면 최적화된 사이트에서는 이 주기가 대개 24시간 내로 단축됩니다.
“URL의 문자 하나가 바뀔 때마다 데이터베이스에는 새로운 노드가 생성됩니다. 콘텐츠가 동일하더라도 알고리즘 초기 단계에서 이 노드들은 협력 관계가 아닌 경쟁 관계에 놓이게 됩니다.” —— 특정 국제 SEO 연구 기관의 실험 보고서 발췌.
부하 분산(Load Balancing)이나 콘텐츠 전송 네트워크(CDN)를 사용하는 일부 아키텍처에서는 매개변수 요청이 서로 다른 정적 복사본으로 캐싱될 수 있습니다.
HTTP 응답 헤더에 Vary: User-Agent 또는 Link: rel="canonical"이 올바르게 설정되어 있지 않으면 Googlebot은 이러한 매개변수 페이지들이 서로 다른 지역의 사용자에게 보여주기 위한 각기 다른 콘텐츠라고 오해할 수 있습니다.
이러한 오판 하에 알고리즘은 사이트 전체의 권위도를 각 매개변수 차원으로 더욱 세분화하여 ‘가중치 빈혈’ 상태를 초래합니다.
기술적 측면에서 이러한 분산으로 인한 손실을 수치화하기 위해 ‘가중치 손실 모델’을 참고할 수 있습니다:
메인 페이지가 상위 3위권에 진입하기 위해 100단위의 신호가 필요하다고 가정할 때, 4개의 매개변수 변형이 존재하고 각 변형이 신호의 15%를 분산시킨다면 메인 페이지는 최종적으로 40단위의 신호만 보유하게 되어 경쟁에서 매우 불리한 위치에 처하게 됩니다.
Shopify 등 플랫폼의 해외 쇼핑몰에 대한 기술 감사 결과, GSC(Google Search Console)에서 sort_by, view, page와 같은 비콘텐츠 변경 매개변수를 비활성화한 후 대상 페이지의 유효 노출수가 60일 내에 평균 55% 증가한 것이 관찰되었습니다.
처리 방안
Adobe Commerce(구 Magento)나 Salesforce Commerce Cloud와 같은 글로벌 기업용 이커머스 아키텍처에서 Google 색인 시스템은 크롤링 과정에서 HTML 헤더나 HTTP 응답 헤더의 rel="canonical" 지침을 우선적으로 읽습니다.
시스템이 ?color=blue&size=xl과 같은 다중 필터 조합을 생성할 때 백엔드 프로그램은 해당 페이지의 표준 주소를 매개변수가 없는 루트 URL로 강제 지정합니다.
이 방안을 올바르게 시행하면 사이트 중복 콘텐츠에 대한 Google의 식별 정확도를 60%에서 99% 이상으로 높일 수 있으며, 여기저기 흩어져 있던 PageRank 점수는 2~4주간의 색인 업데이트 주기 내에 물리적으로 통합됩니다.
SKU가 백만 단위인 글로벌 사이트의 경우 이러한 로직을 통해 메인 검색 경로가 사이트 내 링크 권위도의 95% 이상을 확보하도록 보장할 수 있습니다.
- HTTP 응답 헤더의 링크 선언: PDF 문서나 비 HTML 형식의 매개변수화된 파일을 처리할 때, 서버 측에서
Link: https://example.com/file.pdf; rel="canonical"헤더 정보를 전송하여 검색 엔진이 추적 매개변수가 포함된 다운로드 링크를 새로운 콘텐츠로 간주하는 것을 방지합니다. - 301 영구 리디렉션을 통한 강제 병합: 이미 만료된 마케팅 추적 매개변수(예: 3년 전의
?utm_campaign=2023_sale)의 경우, Nginx나 Apache 서버 레벨에서 와일드카드 규칙을 설정하여 해당 매개변수를 포함한 모든 요청을 표준 페이지로 영구 리디렉션함으로써 과거에 축적된 외부 링크 가중치를 100% 이전시키는 것이 주된 방식입니다. - 상태 비저장 매개변수의 서버 측 무시: 백엔드 개발 시 서버가 요청을 처리할 때 세션 ID나 기타 내부 로직용 매개변수를 제거하도록 구성하여, 서로 다른 사용자가 보는 URL이 물리적 레벨에서 유일성을 유지하게 합니다.
- Google Search Console의 매개변수 분류 차단: Google 관리자 도구에서 기술진은 매개변수를 ‘수동적 매개변수(Passive Parameters)’로 마킹하여 이러한 문자들이 페이지 콘텐츠를 바꾸지 않음을 크롤러에게 명시적으로 알림으로써 Googlebot이 해당 URL 크롤링을 능동적으로 건너뛰도록 유도합니다.
대규모 SEO 실무에서 React나 Angular로 구축된 플랫폼과 같이 복잡한 필터링 시스템을 갖춘 싱글 페이지 애플리케이션(SPA)의 경우, 개발자들은 기존의 쿼리 문자열(?) 대신 프래그먼트 식별자(#)를 사용하는 방식을 선호합니다.
예를 들어 필터 URL을 /shoes?brand=nike에서 /shoes#brand=nike로 변경하면 모든 사용자의 클릭과 필터링 작업은 클라이언트 측에서 완료되지만 검색 엔진은 항상 /shoes라는 단일 경로만을 보게 됩니다.
Cloudflare나 Akamai와 같은 글로벌 콘텐츠 전송 네트워크(CDN) 사용 시, 기술 팀은 ‘캐시 키 무시 매개변수’ 규칙을 구성합니다.
사용자가 example.com/page?id=1로 접속하든 example.com/page?id=1&from=email로 접속하든 CDN은 검색 엔진과 사용자에게 동일한 캐시 복사본을 반환하며 응답 헤더에서 표준화된 출력을 통합합니다.
Amazon이나 eBay와 같은 방대한 데이터를 다루는 플랫폼의 경우 경로 구조의 재작성(URL Rewriting)에 더 큰 비중을 둡니다.
시스템은 본래의 매개변수 패턴인 /product.php?id=123&variant=blue를 보다 의미론적인 디렉토리 패턴인 /product/123/blue/로 변환합니다.
해외의 독립형 사이트 10만 개를 대상으로 한 샘플링 조사에 따르면, 정렬이나 뷰 전환과 같은 기능성 매개변수를 JavaScript의 window.history.pushState API를 통해 물리적 요청 주소 변경 없이 위장 처리한 사이트는 일반 사이트보다 페이지의 평균 순위 안정성이 2.8배 높았습니다.


