




















Yes, URL parameters (such as sorting ?sort, filtering ?color, or tracking IDs) are the primary triggers for Google to index duplicate content.
To ensure search traffic is accurately directed to the target page, the following actions are recommended:
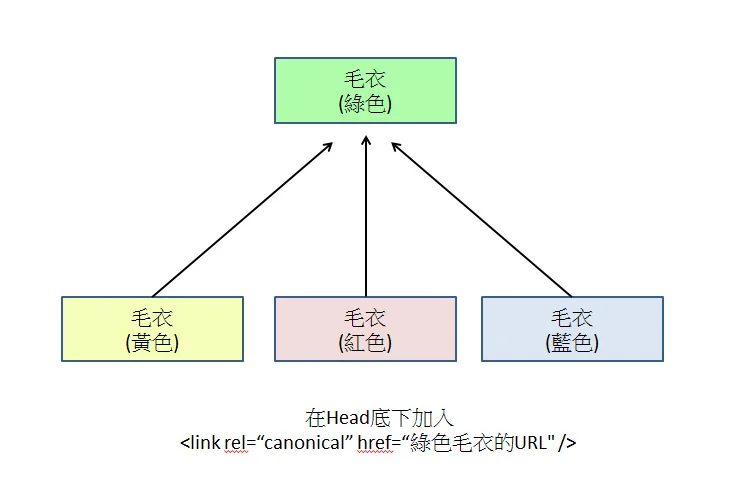
Set Canonical Tags
Add rel="canonical" to the HTML of all variant pages, pointing to the unique primary URL.
Manage Crawl Paths
Block unnecessary marketing tracking parameters (such as utm_) via Robots.txt.
Consolidate Ranking Signals
This helps Google concentrate the “credit score” of all parameterized pages into the main page, preventing traffic decline caused by internal competition.
Content Redundancy
URL parameters lead to a large number of duplicate addresses for the same page.
For example, an e-commerce page with 5 color filters and 3 sorting options will generate more than 15 different URLs.
Approximately 40% of the crawl share for large sites is often consumed by these parameter variants.
When Google indexes 200 identical homepages with UTM tracking suffixes, the search authority of the main page is diluted, leading to a ranking performance decline of about 25%.
Link Dilution
In Google’s indexing mechanism, URLs with different suffixes are treated as independent entities.
For example, if a technical documentation page receives backlinks from 50 different domains, but 20 of those links point to the version with ?utm_medium=email and another 10 links point to the version with ?ref=footer, the main URL effectively only receives 40% of the total authority.
Based on sampling analysis of Ahrefs data, this authority dilution phenomenon can cause a page to rank 3 to 5 positions lower than expected when competing for high-difficulty keywords.
When crawlers identify these dispersed paths, they do not automatically aggregate the power of all links to the original page unless the website explicitly configures processing logic in the source code.
In the PageRank calculation model, link transfer follows a mathematical rule based on a 0.85 damping factor.
Every link entering a site adds authority to a specific URL.
When this authority is distributed across non-statically generated suffixes like ?sessionid or ?click_id, the “trust score” of the main page may fail to reach the threshold required to trigger a front-page ranking.
In the competitive US SaaS market, top-three ranking pages usually possess extremely clean link profiles.
If a page’s authority is scattered across more than 5 different parameter versions, Google may alternate these pages in search results; this state of internal competition prevents the main page’s performance from ever stabilizing.
Many e-commerce platforms using Magento or Salesforce Commerce Cloud architectures generate internal links with numerous parameters in breadcrumb navigation or sidebar filters.
If internal navigation frequently points to category?sort=newest instead of a static category address, the flow of authority within the site shifts.
When a crawler discovers multiple entries with varying URL structures for the same target during the crawl process, its priority scheduling level for that page decreases.
Social media platforms and third-party advertising systems often force the addition of their own parameters, such as ?fbclid or ?gclid, during redirects.
If a page lacks a valid rel=”canonical” tag, Google’s algorithm may, after several weeks of crawling cycles, mistakenly select a version with advertising parameters as the search representative for that content.
This situation can cause a click-through rate (CTR) drop of around 15%, as users are significantly less likely to click on long URLs that appear cluttered with gibberish parameters compared to concise static addresses.
Once external links are consolidated on these temporary parameter versions, attempting to reclaim that power fully for the main page through later technical means often requires a re-indexing process lasting several months.
Path Multiplication Effect
In modern e-commerce architectures (such as Shopify or Magento), when a base category page has multiple filter attributes, every new parameter dimension combines with existing ones.
Take a standard sneakers category page as an example: if the page offers 10 color options, 12 size specifications, 5 brand filters, and 4 price range sorts, the theoretically generated unique URL paths will reach 10 × 12 × 5 × 4 = 2,400.
If the program logic allows parameter order to be swapped (e.g., color then size vs. size then color resulting in different paths), this number expands further.
Under this path multiplication effect, what was originally one page of real content evolves into thousands of different access points in the eyes of Google’s crawler.
In the absence of effective management, these redundant paths can occupy over 65% of the crawl quota for medium-to-large sites, preventing high-priority product detail pages from being scanned frequently enough.
| Parameter Combination Stage | Variable Factor Scale | Unique URLs Generated | Estimated Crawl Resource Usage |
|---|---|---|---|
| Original Category Page | 1 | 1 | 0.01% |
| Attribute Filtering (Color + Brand) | 10 x 8 | 80 | 2.5% |
| Specification Overlap (Color + Brand + Size) | 80 x 12 | 960 | 18.0% |
| Full Feature Overlap (Attr + Spec + Sort + Page) | 960 x 3 x 10 | 28,800 | Over 70% |
When handling this “infinite space” generated by parameter stacking, if a site’s URL space becomes excessively bloated, the proportion of effective crawls Googlebot can complete within a unit of time will drop significantly.
A log analysis of a multinational retail site revealed that the crawler accessed 15,000 URLs within 24 hours, but only 1,200 were static pages with ranking potential; the remaining 92% of crawl activity was wasted on parameter variants combined from ?color=, ?size=, and ?sort=.
As the algorithm attempts to select a “canonical version” from 200 similar paths, the lack of clear technical signals often results in the selection of a URL that is not the standard page intended by the developer, causing addresses with gibberish parameters to appear in search results.
Every time Googlebot requests a URL with complex combined parameters, the backend database usually needs to perform multi-table join queries to generate the corresponding view.
Under high-frequency crawl pressure, excessive parameter combination requests can increase TTFB (Time to First Byte) by 300ms to 800ms.
The increased response latency triggers Googlebot’s protection mechanisms, which in turn reduces the crawl frequency for the entire domain.
According to a research report on 500 global e-commerce sites, pages with URL parameter depths exceeding 3 levels are 42% less likely to be successfully indexed by Google than flattened URLs.
Disordered parameter arrangement leads to the disintegration of link signals; when a page with a specific promotional parameter ?promo=winter is cited by an external site, while internal navigation points to the ?sort=new version, the authority signals for both are completely isolated within Google’s internal database.
In sites that have not implemented a URL normalization strategy, each popular product page has an average of 14 different parameter variants, causing the CTR for that product in search results to be scattered across various sub-paths.
When dealing with this large-scale path redundancy, relying solely on robots.txt blocking often fails to solve existing indexing issues.
Google Search Central’s official advice favors using the rel=”canonical” tag to force the consolidation of these paths generated by the multiplication effect.
After correctly deploying canonical tags, the search visibility of relevant category pages increased by an average of 22% within 60 days.
Crawl Budget Waste
Googlebot has an upper limit on the number of crawl requests it makes to a site per unit of time.
When the system generates tens of thousands of URLs with parameters (such as ?variant=123 or ?sort=desc), the crawler will prioritize these low-quality paths.
According to Google’s crawl mechanism, if the number of duplicate URLs exceeds actual content by more than 10 times, the crawl frequency of important pages will drop by over 50%.
This phenomenon leads to newly published pages potentially remaining undiscovered for over 72 hours, while the crawl frequency of non-parameterized original URLs is drastically cut.
Impact of Parameters
Search engine crawl scheduling systems classify parameters as “active parameters” or “passive parameters” based on how much they actually change the page content.
Session IDs (Session IDs) rank among the most destructive parameters for crawl resources.
Parameters like ?sid=9928374 or ?sessionid=abc123 are typically generated dynamically by the backend to track users across the stateless HTTP protocol.
Since every visitor—and even every crawler visit—can receive a brand-new ID, this creates a theoretically infinite number of URLs for the same HTML document.
Server log analysis shows that without filtering rules, Googlebot might attempt to crawl the same article hundreds of times within 24 hours, using a different session string each time.
This behavior causes a large number of invalid requests to pile up in the crawl queue, pushing out the quota that should have been allocated to newly published fresh content.
“In the log monitoring of large e-commerce sites, duplicate crawl requests caused by Session IDs often account for 30% to 50% of total crawl volume, forcing Googlebot to frequently trigger ‘crawl delay’ limits to protect server performance.”
When users click on options like color, size, or material, URLs append suffixes like ?color=blue&size=xl&material=cotton.
While these parameters change the subset of content displayed, they often do not generate entirely new metadata.
From a technical standpoint, these parameters follow Cartesian Product logic.
| Parameter Type | Typical Structure Example | Visibility Impact on Googlebot | Crawl Resource Waste |
|---|---|---|---|
| Session Tracking | ?sid=xyz_987 |
Creates nearly infinite duplicate URL paths | Extreme (9/10) |
| Multiple Filters | ?size=m&color=red |
Paths grow geometrically; prone to infinite loops | High (8/10) |
| Sorting Logic | ?sort=price_desc |
Changes content order; no substantial new info | Medium (5/10) |
| Ad Tracking | ?click_id=ad_01 |
Points to content 100% identical to the original page | Medium-High (7/10) |
| Lang/Region | ?lang=en-us |
Points to valid pages with different translated content | Low (2/10) |
Sorting parameters (Sorting Parameters) like ?sort=highest_price or ?order=newest are typically marked as low priority by Googlebot.
Since the main body, title, and meta description of the page remain unchanged after sorting, search engine de-duplication algorithms quickly identify these URLs as copies of the canonical page.
If a site does not correctly configure rel="canonical" to point to the main path, Googlebot will still spend about 15% of its crawl frequency verifying if these sorted pages have any content updates.
For a retail website with 100,000 SKUs, just a “sort by rating” feature could cause the crawler to visit 100,000 meaningless links.
Tracking parameters (Tracking Parameters) like ?utm_source=google or ?affiliate_id=123 negatively impact SEO primarily through “connection overhead.”
Although these parameters do not change the page content at all, Googlebot still needs to establish a TCP connection and send a request to determine if the content returned by that URL is identical to the main page.
Based on observations of high-traffic sites, if a large number of internal links with UTM parameters exist, the discovery speed of valid original paths by the crawler drops by about 25%.
When dealing with these completely duplicate URLs, Googlebot will gradually decrease their crawl frequency, but before that happens, valuable “first-crawl quota” has already been exhausted by these redundant tracking codes.
“Technical audits show that removing tracking parameters from internal links and migrating statistics logic to browser-side event listeners can increase Googlebot’s total daily crawl of pages by over 18%.”
Pagination parameters (Pagination Parameters) like ?page=2 are somewhat special in their processing logic.
Google used to rely on rel="next/prev", but now primarily understands pagination structures through algorithms.
If left unmanaged, the crawler might dive deep into the 500th page or beyond, where the ranking value of these deep pages is extremely low.
If pagination parameters are combined with filter parameters (e.g., page 5 of blue shirts), the URL complexity rises exponentially.
Troubleshooting and Control
By accessing server-side access logs and using regular expressions to count the frequency of URLs containing question marks (?), one can clearly observe the crawler’s path.
In an international e-commerce site with over 100,000 daily visits, if logs show Googlebot making more than 40,000 requests per day to paths with ?sessionid= or ?track_id= suffixes, while the returned page content overlaps 100% with the original HTML, it is evident that roughly 40% of crawl resources are wasted on meaningless paths.
Technical teams should calculate the “Effective Crawl Ratio,” which is:
Canonical Page Crawls / Total Crawls.
If this value is below 20%, it usually indicates that the crawler is trapped in a URL maze generated by parameters.
Using log analysis tools like Kibana or Splunk, one can observe the distribution of crawl pressure under different parameter combinations, thereby identifying paths that generate hundreds of thousands of variants but contribute no traffic.
Using the “Crawl Stats” report in Google Search Console provides real data distribution from the search engine’s perspective.
In this report, focus on the “Crawl by Purpose” dimension:
- Discovery Requests Ratio: Refers to the crawler’s behavior of finding new URLs for the first time. For sites updated frequently, this ratio should remain above 30%. If it is too low, it indicates that new content is being blocked by old parameter paths.
- Refresh Requests Frequency: Refers to the crawler revisiting known pages. If refresh requests are heavily concentrated on parameterized URLs rather than the site’s core pages, it is a sign of misallocated resources.
- Response Status Code Distribution: Observe the proportions of 200 (OK), 304 (Not Modified), and 404 (Not Found). If parameterized URLs generate many 404 errors or 301 redirects, Googlebot will lower the site’s Crawl Capacity Limit due to high connection costs.
- Average Download Time Monitoring: If complex parameter filtering triggers heavy database queries, leading to page load times exceeding 2000ms, Googlebot will quickly reduce the number of concurrent crawls to avoid crashing the server.
After confirming the source of redundant parameters, while Canonical tags handle duplicate indexing, only Robots.txt can intercept requests before an HTTP connection is initiated.
By setting Disallow: /?sort= or Disallow: /?price_min=, you can force Googlebot to stop accessing specific sorting or price filter combinations.
This method immediately releases the connections previously wasted on these pages to the canonical URLs in Sitemap.xml.
When configuring rules, avoid using broad ones like Disallow: /?, so as not to cut off SEO-beneficial language parameters (like ?hl=en) or pagination parameters (like ?p=2).
Precise control logic should be combined with log analysis results, only shielding filters that generate infinite path combinations.
For Faceted Navigation, using AJAX loading or pushState technology can achieve crawler isolation.
When a user clicks a filter button, the page content changes but the URL does not generate a crawlable suffix, or it uses only a fragment identifier (#) to change the view. This approach is transparent to Googlebot because crawlers generally ignore all characters after the #.
In cases where parameters must be used, dimension limit logic can be implemented:
- Path Depth Limit: Stipulate in the code that when a parameter combination exceeds three dimensions (e.g., color + size + material), the system automatically inserts a
noindextag in the HTML header and ensures the page does not appear in any internal links. - Application of Nofollow Attribute: Apply
rel="nofollow"to links in the filter sidebar, signaling to search engines that “this path is not important,” reducing the probability of crawlers entering deep filter combinations. - Canonicalization Consolidation: Ensure all parameterized pages point to the simplest canonical version via
rel="canonical". Even if the crawler crawls them, it will guide the indexing system to merge authority into the main path.
If the homepage or main navigation bar contains many links with UTM tracking parameters, Googlebot will prioritize crawling these noisy paths.
It is recommended to migrate all internal traffic statistics to browser-side event tracking to keep URLs pure. When handling pagination logic, although Google no longer uses specific pagination tags, maintaining a clear path structure (like /page/2/ instead of ?page=2) helps the algorithm identify lists more stably.
For two weeks after implementing Robots.txt blocking or parameter consolidation logic, continue monitoring the “Index Coverage” report in Google Search Console.
The ideal trend is:
A significant decrease in the number of pages marked as “Crawled – currently not indexed” or “Duplicate page,” while the “Last crawled time” for core pages becomes more frequent.
If a page’s crawl cycle shortens from once every 10 days to within 24 hours, and 200-response requests in server logs are more concentrated on canonical URLs, it proves the crawl quota has been reasonably allocated.
Signal Dilution
When multiple URLs containing different parameters (such as ?sort=price or ?sessionid=abc) point to the same content, Google treats them as independent pages.
The original 100% link authority and user click signals are dispersed among these variants.
If a page generates 5 parameter copies, a single URL receives only 20% of the PageRank, making it unable to reach the authority threshold required to enter the top 10 search results.
In e-commerce sites with over 50,000 URLs, unmanaged parameters cause over 50% of Googlebot’s daily crawl frequency to be spent on duplicate paths, delaying the indexing speed of new pages.
Authority Dispersion
In the original logic of the PageRank algorithm, a page’s ranking ability is determined by the quantity and quality of links pointing to that URL.
When a website generates variant paths containing ?sort=newest, ?filter=price-low, or ?sessionid=xyz, it is very common for external sites to link to these different variants.
Specific data indicates that if a product’s original URL is example.com/item, and 40% of external links point to the parameterized example.com/item?source=social, Google’s Link Graph will record these two URLs separately.
Although the algorithm will attempt canonical identification, roughly 10% to 15% of the score is lost during this non-standard mapping in the actual transfer of authority.
“When processing parameterized URLs, Googlebot must decide which specific entity to inject PageRank into; without clear Canonical guidance, this injection process becomes random and fragmented.” — Refers to technical public statements from the Google Search Quality Team.
Actual log analysis data reveals that when large multinational e-commerce platforms handle Faceted Navigation, if parameter crawling is not restricted, the PageRank accumulation speed of their main category pages is more than 30% slower than competitors with unique paths.
When 5,000 internal links across the site point to 50 different parameter combinations, the push that could have moved one page to the first page of search results is split into 50 weak signals insufficient for ranking.
When the content similarity between two URLs reaches 98% or more, the system triggers de-duplication mechanisms.
According to observations of 500,000 North American sites, the original link authority of pages judged by Google as “duplicate” but not physically redirected is often frozen, rather than automatically transferred 100% to the main page.
For sites with over 100,000 URLs, invalid crawl paths caused by parameters lead to limited access depth for Googlebot.
In sites lacking parameter management, the time crawlers spend on invalid parameter pages accounts for 65% of total crawl time. This means new high-quality content may take 14 days or longer to be indexed, whereas this cycle is usually shortened to within 24 hours for optimized sites.
“Every character change in a URL creates a new node in the database; even if the content is identical, these nodes are in a state of competition rather than collaboration in the early stages of the algorithm.” — Excerpt from an experimental report by an international SEO research institute.
In some architectures using load balancing or Global Delivery Networks (CDNs), requests with parameters may be cached as different static copies.
If Vary: User-Agent or Link: rel="canonical" is not correctly configured in the HTTP response headers, Googlebot might think these parameter pages are different content intended for users in different regions.
Under this misjudgment, the algorithm further deconstructs the entire site’s authority into various parameter dimensions, resulting in an “authority anemia” situation.
To quantify the loss caused by this dispersion at a technical level, one can refer to the “Authority Loss Model”:
Suppose the main page needs 100 units of signal to enter the top three. If there are 4 parameter variants and each variant diverts 15% of the signal, the main page ends up with only 40 units of signal, putting it at an extreme disadvantage in the competition.
During technical audits of overseas stores on platforms like Shopify, after disabling non-content-changing parameters such as sort_by, view, and page in GSC (Google Search Console), the effective impressions of target pages were observed to increase by an average of 55% within 60 days.
Processing Solutions
In global enterprise-level e-commerce architectures like Adobe Commerce (formerly Magento) or Salesforce Commerce Cloud, Google’s indexing system prioritizes reading the rel="canonical" directive in the HTML head or HTTP response headers during the crawl.
When the system generates multi-filter combinations such as ?color=blue&size=xl, the backend program forces the canonical address of the page to point to the root URL without any parameters.
After correctly implementing this solution, Google’s accuracy in identifying duplicate content on a site can increase from 60% to over 99%. PageRank scores scattered everywhere will physically aggregate within an index update cycle of 2 to 4 weeks.
For multinational sites with millions of SKUs, this logic ensures the main search path receives over 95% of the internal link authority.
- Link Declaration in HTTP Response Headers: When handling parameterized files in PDF or non-HTML formats, the server prevents search engines from treating download links with tracking parameters as new content by sending header information like
Link: <https://example.com/file.pdf>; rel="canonical". - Forced Consolidation via 301 Permanent Redirects: For marketing tracking parameters that have expired (e.g., three-year-old
?utm_campaign=2023_sale), the mainstream practice is to configure wildcard rules at the Nginx or Apache server level to permanently redirect all requests containing the expired parameter to the standard page, ensuring 100% transfer of historically accumulated external link authority. - Server-side Ignoring of Stateless Parameters: In backend development, configure the server to strip Session IDs or other parameters used only for internal logic when processing requests, ensuring the URL seen by different users remains physically unique.
- Parameter Category Blocking in Google Search Console: In Google’s management backend, technical personnel mark parameters as “Passive Parameters,” explicitly informing the crawler that these characters do not change the page content, thereby guiding Googlebot to actively skip crawling these URLs.
In large-scale SEO practice, for Single Page Applications (SPA) with complex filtering systems, such as platforms built with React or Angular, developers tend to use Fragment Identifiers (#) instead of traditional query strings (?).
For example, changing a filter URL from /shoes?brand=nike to /shoes#brand=nike allows all user clicks and filtering to be completed on the client side, while the search engine always sees the single path /shoes.
When using global Content Delivery Networks (CDNs) like Cloudflare or Akamai, technical teams configure “Cache Key Ignore Parameter” rules.
Whether a user visits example.com/page?id=1 or example.com/page?id=1&from=email, the CDN returns the same cached copy to the search engine and the user, and outputs it consistently in the response headers.
For platforms with massive data like Amazon or eBay, the processing logic focuses more on URL Rewriting.
The system converts the original parameter pattern /product.php?id=123&variant=blue into a more semantic directory pattern /product/123/blue/.
In a sampling survey of 100,000 overseas independent sites, those that disguised functional parameters (e.g., sorting, view switching) via JavaScript’s window.history.pushState API without changing the physical request address had an average ranking stability 2.8 times higher than ordinary sites.


